
Победитель не получает все: как «получение информации» может исправить неверные результаты поиска Google
Опубликовано: 2022-06-27Победители в истории поиска
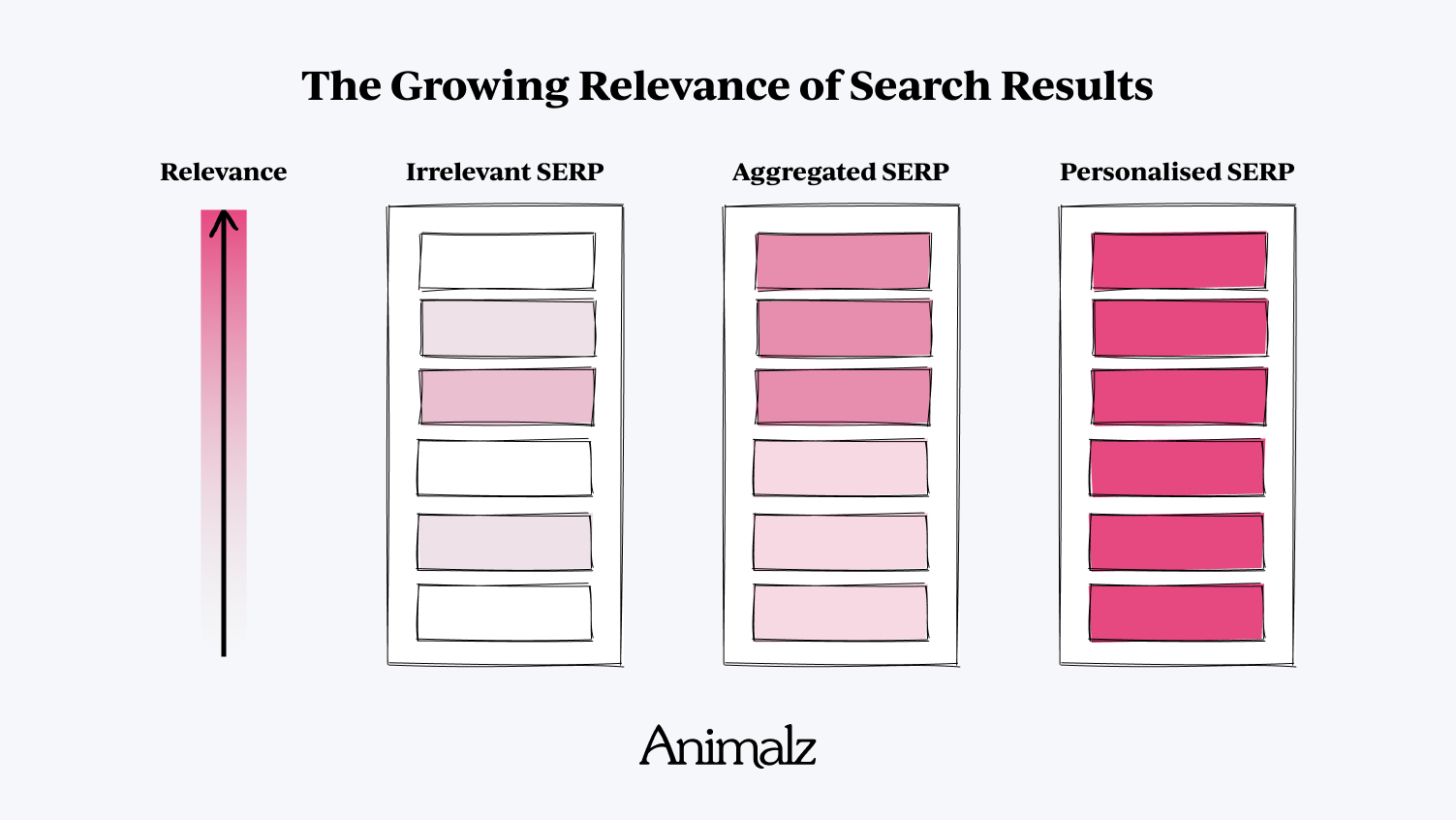
Раньше контент-маркетинг был проще, чем сегодня. Было время, когда поиск в Google выдавал страницу лишь смутно релевантных результатов поиска; найти статью, посвященную вашему конкретному вопросу, было редкостью, и это было невероятно приятно. Эти статьи стали победителями, заработав львиную долю трафика и вовлеченности в предложение.
По мере того, как все больше компаний участвовало в контент-маркетинге, поисковикам становилось легче находить нужную информацию: вы, вероятно, могли бы извлечь полезные фрагменты из большинства результатов поиска в самом верху. Критерии доминирования SEO перешли к агрегации : любая статья, объединяющая разрозненную информацию поисковой выдачи в одном удобном месте, становилась победителем де-факто (отсюда модель небоскреба и все ее проблемы).
Сегодня у нас другая проблема. Вместо того, чтобы искать сигнал среди шума, мы ищем сигнал среди… сигнала. В самых зрелых отраслях каждая страница результатов поисковой системы (SERP) выглядит так, как будто ее оспаривают полдюжины крупных брендов, с длинными, ультра-подробными статьями, построенными на горах обратных ссылок и подкрепленными строгим SEO на странице. Эти статьи обычно выглядят и звучат одинаково, содержат незначительные вариации одной и той же базовой информации.
Из-за старого мышления «победитель получает все» эти SERP являются безнадежными. Огромные, авторитетные бренды могут бесконечно менять позицию на первой странице; Меньшие, менее авторитетные блоги никогда не преодолеют ров авторитета домена и узнаваемости бренда. Но точно так же, как со временем развивался контент-маркетинг, развивался и Google.
Получение информации
В апреле 2020 года Google подала патент на решение знакомой проблемы:
«Когда идентифицируется набор документов, имеющих общую тему, многие из документов могут содержать схожую информацию… пользователь может выполнить поиск, связанный с решением проблемы с компьютером… и впоследствии ему может быть предоставлено несколько документов, содержащих аналогичный список решений. , меры по исправлению положения, ресурсы и т. д.».
Google осознает проблему, с которой мы сталкиваемся каждый день: подражание контенту. Большинство результатов поиска содержат одну и ту же информацию. Как только читатель прочитал одну статью, он фактически прочитал их все.
Для Google это проблема вовлечения пользователей: подражательный контент сокращает путь пользователя, лишая его возможности продолжать поиск и находить дополнительную полезную информацию. Для контент-маркетологов это проблема дифференциации: если вы не можете превзойти эти огромные статьи-небоскребы, у вас мало стимулов для оспаривания ключевого слова.
Решение Google простое: вознаграждайте статьи, которые приносят новую информацию.
Они предлагают делать это с помощью того, что они называют получением информации, измерением новой информации, предоставленной данной статьей, помимо информации, представленной в других статьях по той же теме.
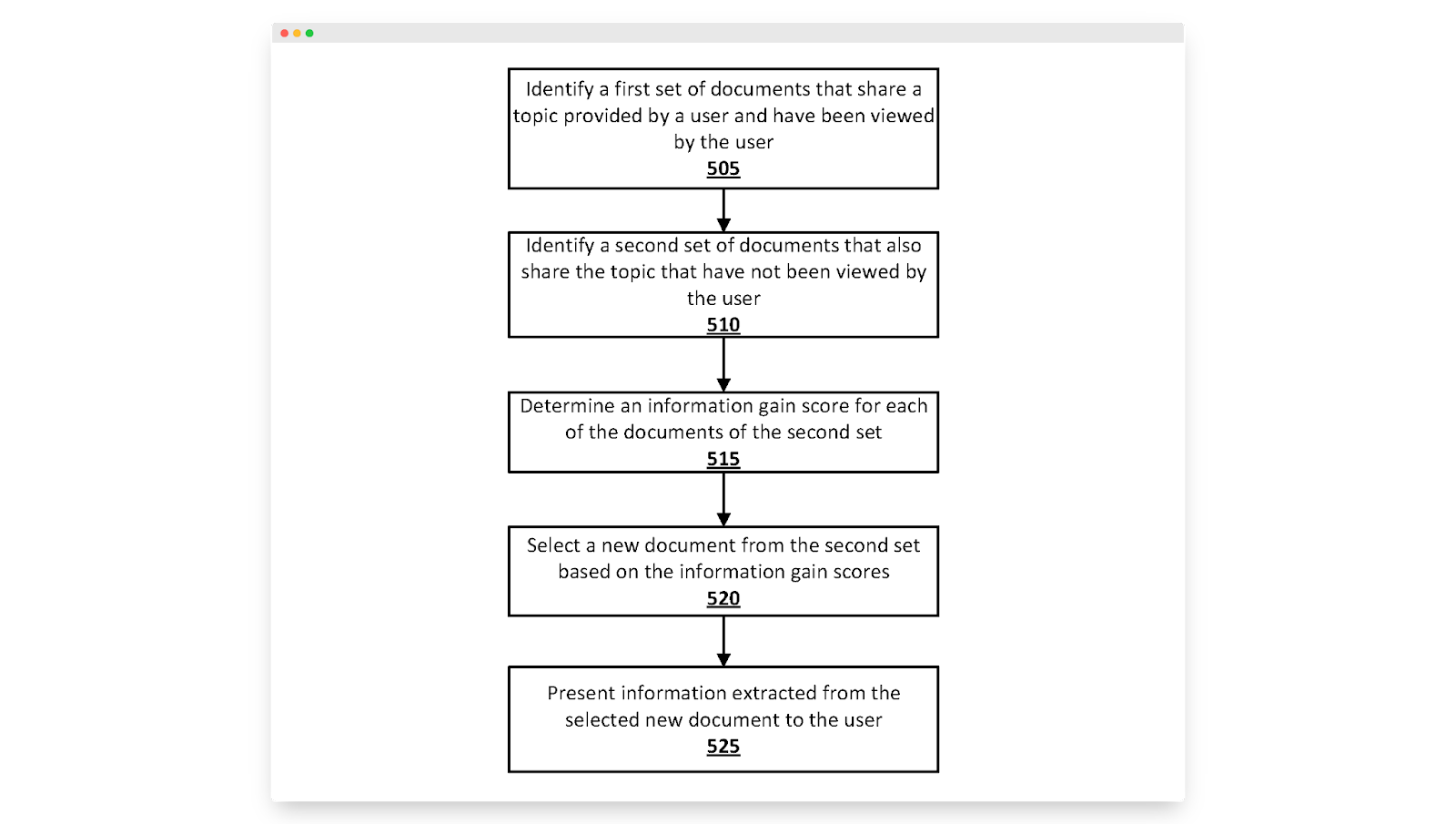
Самый простой способ измерить прирост информации — сравнить содержание данной статьи с теми, которые уже ранжируются в поисковой выдаче, но Google предлагает пойти еще дальше и принять во внимание поисковый путь пользователя, чтобы выяснить, что представляет собой «новая информация».
Другими словами, прирост информации будет зависеть от конкурирующего контента, а также от статей, которые прочитал каждый пользователь.
Google предлагает несколько способов использования этой информации:
- Отображение адаптивных, персонализированных результатов поиска для пользователей, которые меняются в зависимости от ранее прочитанного контента.
- Облегчение умных разговоров с помощью голосового поиска и чат-ботов.
- Влияние на то, как сводная информация извлекается из статей и передается пользователям, выполняющим поиск.
Награждение контента за то, что он отличается, а не просто лучше
Самая простая интерпретация этого патента заключается в том, что статья, которая добавляет что-то новое к обсуждению, может иметь более высокий рейтинг, чем статья, которая повторяет ту же информацию, что и другие. И наоборот, если ваша статья предлагает ту же основную информацию, что и статья, уже прочитанная пользователем, она может быть оценена ниже.
Но есть и более широкие последствия концепции получения информации:
- Это открывает дверь для огромной фрагментации каждой поисковой выдачи. Представление о результатах поиска как о чем-то статичном и монолитном — едином наборе «лучших» статей, обслуживающих единую основную цель поиска, — становится все более и более устаревшим. Индустрия контент-маркетинга медленно продвигается к идее единой поисковой выдачи, обслуживающей несколько фрагментированных намерений, но этот патент предполагает будущее, в котором у каждого пользователя будет свой собственный набор результатов.
- Быть «другим» — жизнеспособная стратегия поиска. В конечном счете, этот контент вознаграждает Google за то, что он отличается от других, а не просто лучше. В этом новом мире рискованный контент — все, что отличается от существующих результатов поиска с точки зрения направленности или мнений — имеет механизм вознаграждения. У аутсайдеров есть новый инструмент в их борьбе за то, чтобы превзойти контент небоскребов.
- Есть стимул сотрудничать с существующим контентом, а не конкурировать. На этом фоне имеет смысл думать о наших статьях как об активных участниках совместной экосистемы контента. SEO больше не является принципом «победитель получает все»: вместо одной статьи, доминирующей в поисковой выдаче по заданной теме, теперь есть возможности для «выиграть» гораздо больше статей, хотя и в меньшем масштабе.

Теперь связанная с патентной заявкой — это просто патентная заявка. Идеи Google всегда предшествуют реальным изменениям алгоритмов поиска, и нет никакой гарантии, что они воплотятся в жизнь.

Но независимо от точной механики того, реализуется ли и как осуществляется получение информации, самый большой вывод из этого патента заключается просто в том, что Google намерен вознаграждать статьи, которые содержат информацию, которой нет в других статьях. Это означает, что каждый контент-маркетолог будет хорошо обслуживаться, если будет помнить об этом вопросе во всем, что он публикует:
« Какую новую информацию я приношу к обсуждению? »
Вот несколько практических способов отразить этот вопрос в вашем контенте:
1. Создавайте контент, основанный на своих предшественниках
Если вы признаете идею о том, что ваш контент является частью совместной экосистемы, ваша цель сместится с победы над конкурирующими статьями на их дополнение . Вместо того, чтобы беззаботно пытаться превзойти эту статью о гигантском небоскребе, работайте над предположением, что читатель действительно читал конкурирующий пост. Если это правда, как вы можете повысить ценность того, что они уже прочитали?
- Поделитесь практическим «следующим шагом», чем-то, что действует как продолжение конкурирующего контента.
- Разработайте ключевую идею, содержащуюся в конкурирующей статье.
- Напишите 102 версию их 101, вдаваясь в глубину, детали и нюансы.
2. Экспериментируйте с рискованными кадрами и углами
Статьи о получении информации вознаграждают за риск и отклонение от статус-кво. Вместо того, чтобы смотреть на результаты поиска с целью подражания высокорейтинговому контенту, он поощряет маркетологов к дифференциации. Есть много способов достичь этой цели (при этом все еще удовлетворяя цель поиска):
- Обратитесь к неудовлетворенному намерению («Мой конкретный вариант использования здесь не представлен».)
- Заполните недостающую информацию («Странно, что здесь никто не упомянул X».)
- Бросьте вызов другому или ошибочному мнению («Это устаревшее убеждение»).
- Исправьте ошибки в понимании Google («Это не то, что я имел в виду под этим ключевым словом»).
Подробнее: Заблуждение «Google знает лучше всех»
3. Создайте информационный ров с оригинальными исследованиями
Как мы уже писали ранее, «первичное исследование — это высшая форма получения информации». Все новое и проприетарное — это самый безопасный и надежный способ добавить новые данные в обсуждение — по определению все, что вы создаете, нельзя найти где-либо еще. Хотя «оригинальное исследование» звучит пугающе, существует множество способов включить его в свой контент:
- Включите личные взгляды и опыт компании
- Опросите своих клиентов, пользователей или сеть
- Добавить котировки от МСП
Подробнее: Подражание контенту: SEO-инструменты привели нас сюда, люди нас вытащат
Поисковая система аутсайдеров
Как правило, большинство контент-маркетологов не любят признавать конкуренцию, создаваемую существующими результатами поиска (или тот факт, что иногда мы просто не можем конкурировать с ними).
Когда мы признаем конкуренцию, обычно это выбор элементов из их структуры в попытке создать что-то «лучшее», что приводит к продолжающейся гонке вооружений статей о небоскребах, каждая из которых содержит ту же утомительную информацию, что и предыдущие статьи.
«Получение информации» — это попытка Google сократить эту проблему и создать механизм вознаграждения за статьи, которые добавляют новую информацию к обсуждению — и стремятся отличаться , а не просто быть лучше . Будущее, которое он представляет, хорошее, открывая путь к более полезным и интересным результатам поиска, а также открывая новые способы для небольших компаний-неудачников извлечь выгоду из поиска, просто ответив на один-единственный вопрос:
« Какую новую информацию я приношу к обсуждению?»