
Câștigătorul nu ia totul: cum poate „obținerea de informații” să repare rezultatele căutării necorespunzătoare ale Google
Publicat: 2022-06-27Câștigători prin istoria căutării
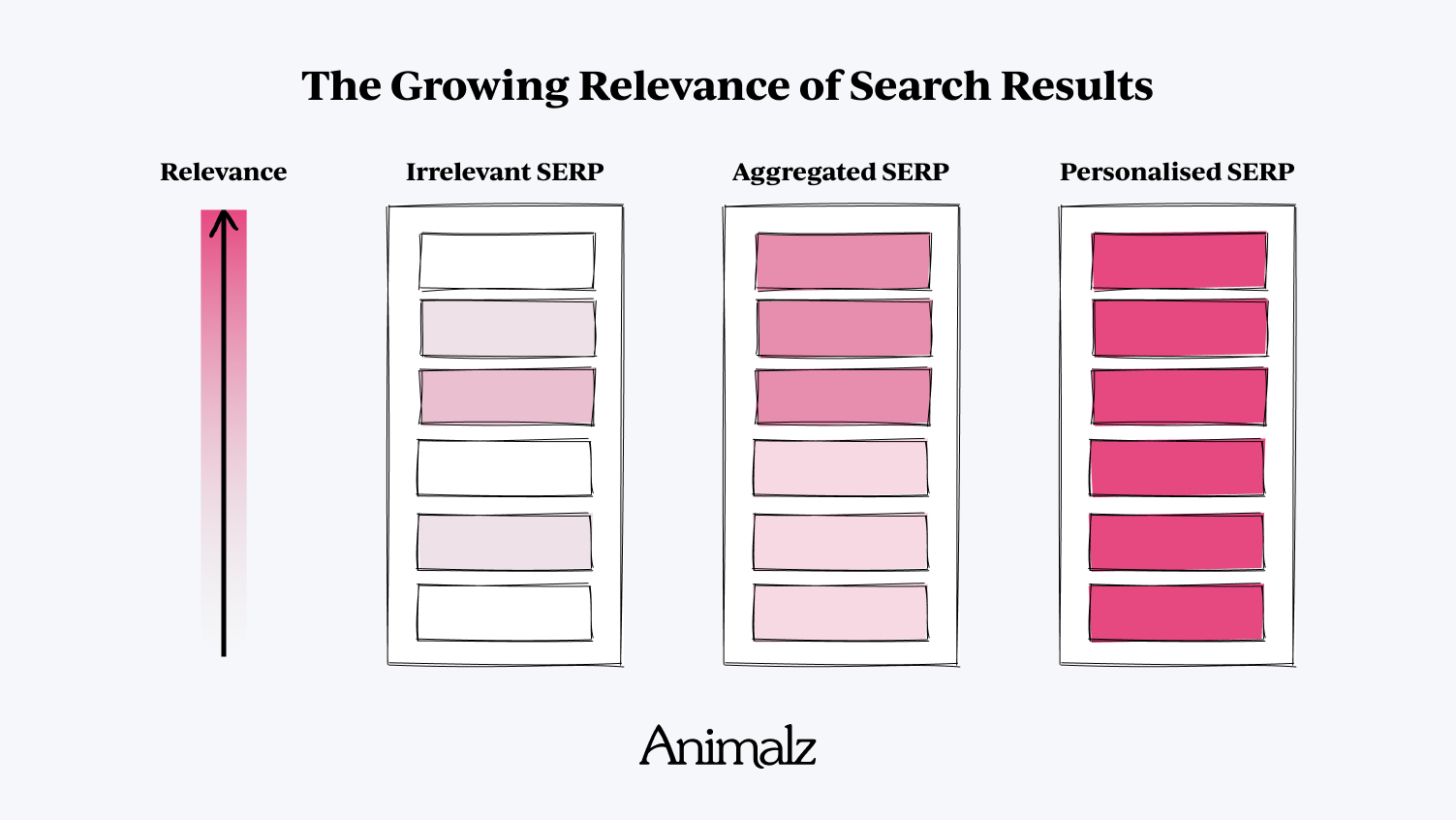
Marketingul de conținut era odinioară mai simplu decât este astăzi. A existat o perioadă în care o căutare pe Google ar genera o pagină cu rezultate ale căutării doar vag relevante; găsirea unui articol care abordează întrebarea dvs. specifică a fost rară și incredibil de binevenită. Aceste articole au fost câștigătoare, câștigând partea leului din trafic și implicare oferite.
Pe măsură ce mai multe companii au intrat în lupta de marketing de conținut, a devenit mai ușor pentru cei care caută să găsească informații relevante: probabil că ați putea smulge fragmente utile din majoritatea rezultatelor căutării de top. Criteriile pentru dominarea SEO au trecut la agregare : orice articol care consolida informațiile fragmentate ale SERP într-un singur loc convenabil a devenit câștigătorul de facto (de unde modelul zgârie-nori și toate problemele sale).
Astăzi avem o altă problemă. În loc să căutăm semnal printre zgomot, căutăm semnal printre... semnal. În cele mai mature industrii, fiecare pagină de rezultate a motorului de căutare (SERP) pare a fi contestată de o jumătate de duzină de mărci uriașe, cu articole lungi, ultra-comprehensive, construite pe munți de backlink-uri și susținute de SEO riguros pe pagină. În general, aceste articole arată și sună la fel, conținând variații minore ale acelorași informații de bază.
Prin vechea mentalitate de „câștigatorul ia tot”, aceste SERP-uri sunt cauze pierdute. Mărcile uriașe și consacrate pot schimba clasamentele de pe prima pagină înainte și înapoi pe termen nelimitat; blogurile mai mici, mai puțin stabilite, nu vor depăși niciodată șanțul autorității de domeniu și a cunoașterii mărcii. Dar, în același mod în care marketingul de conținut a evoluat de-a lungul timpului, la fel a evoluat și Google.
Câștig de informații
În aprilie 2020, Google a depus un brevet care urmărea să rezolve o problemă familiară:
„Atunci când este identificat un set de documente care împărtășesc un subiect, multe dintre documente pot include informații similare... un utilizator poate trimite o căutare legată de rezolvarea unei probleme de computer... și ulterior i se pot furniza mai multe documente care includ o listă similară de soluții. , pași de remediere, resurse etc.”
Acesta este Google care recunoaște problema cu care ne confruntăm în fiecare zi: conținutul imitat. Majoritatea rezultatelor căutării conțin aceleași informații. Odată ce un cititor a citit un articol, le-a citit efectiv pe toate.
Pentru Google, aceasta este o problemă de implicare a utilizatorilor: conținutul imitator limitează călătoria utilizatorului, eliminând orice stimulent de a continua căutarea și descoperirea de informații utile suplimentare. Pentru marketerii de conținut, aceasta este o problemă de diferențiere: cu excepția cazului în care reușiți să depășiți acele articole uriașe de zgârie-nori, există puține motive să vă deranjați să contestați cuvântul cheie.
Soluția Google este simplă: recompensează articolele care aduc informații noi pe masă.
Ei sugerează să faceți acest lucru prin ceva pe care ei îl numesc câștig de informații, o măsurare a informațiilor noi furnizate de un articol dat, peste informațiile prezente în alte articole pe aceeași temă.
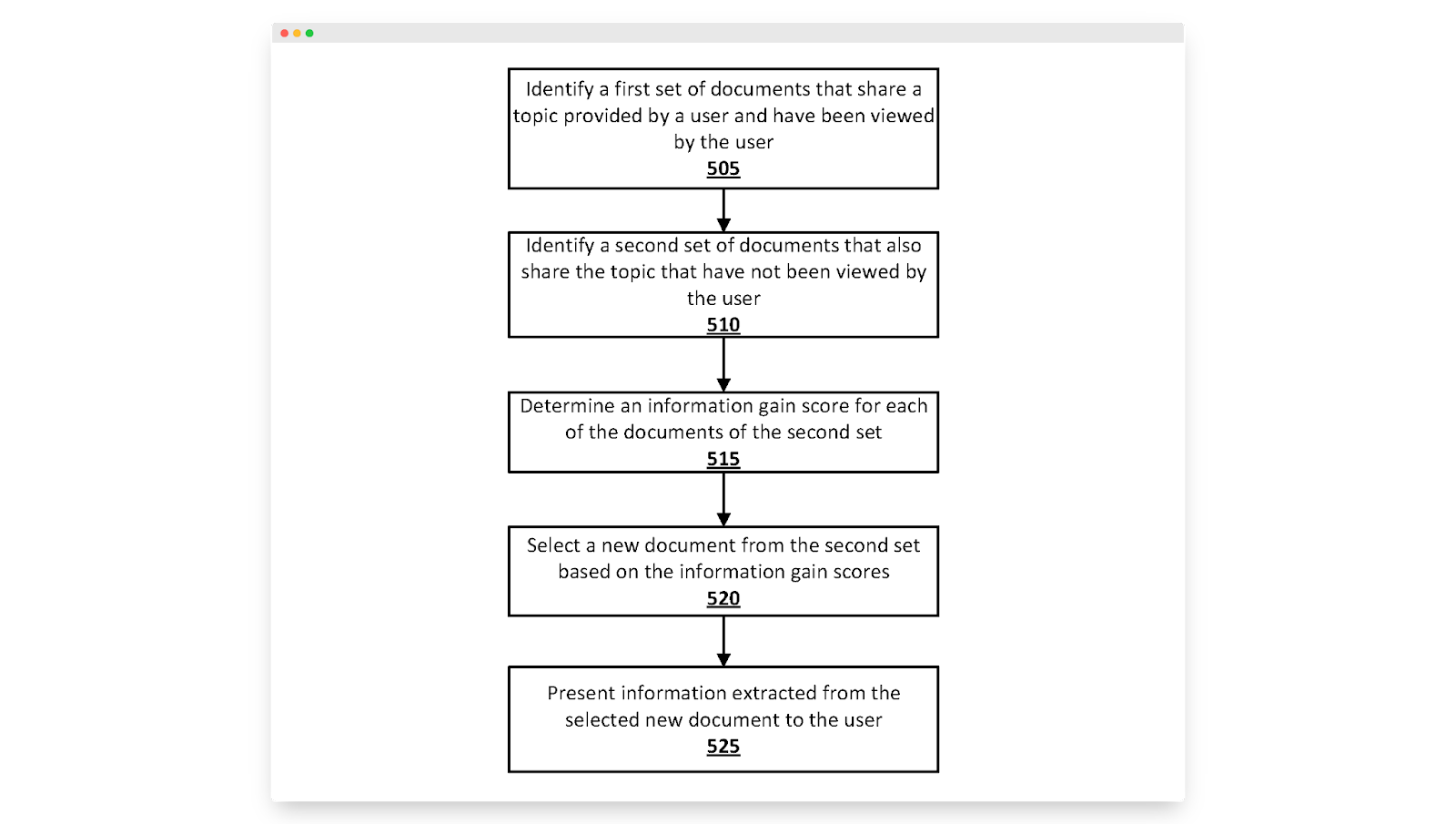
Cea mai simplă modalitate de a măsura câștigul de informații este să comparați conținutul unui articol dat cu cele care se clasifică deja în SERP, dar Google sugerează să faceți un pas mai departe și să luați în considerare călătoria de căutare a utilizatorului pentru a afla ce reprezintă „informații noi”.
Cu alte cuvinte, câștigul de informații va fi relativ la conținutul concurent, dar și la articolele citite de fiecare căutător .
Google sugerează câteva moduri de a utiliza aceste informații:
- Afișează utilizatorilor rezultate de căutare receptive și personalizate care se modifică în funcție de conținutul pe care l-au citit anterior.
- Facilitarea conversațiilor mai inteligente cu căutarea vocală și chatbots.
- Influențarea modului în care informațiile rezumate sunt extrase din articole și partajate cu cei care caută.
Recompensează conținut pentru a fi diferit, nu doar mai bun
Cea mai simplă interpretare a acestui brevet este că un articol care adaugă ceva nou la discuție se poate clasa mai bine decât un articol care repetă aceleași informații ca și alții. În schimb, dacă articolul dvs. oferă aceleași informații de bază ca și cea pe care a citit-o deja utilizatorul, acesta ar putea fi clasat mai jos.
Dar există implicații mai largi ale conceptului de câștig de informații:
- Acest lucru deschide ușa către o fragmentare uriașă a fiecărui SERP. Ideea rezultatelor căutării ca ceva static și monolitic – un singur set de „cele mai bune” articole care servesc o singură intenție de căutare primară – devine din ce în ce mai depășită. Industria de marketing de conținut se îndreaptă încet la ideea unui singur SERP care să servească mai multe intenții fragmentate, dar acest brevet sugerează un viitor în care fiecare cautator are propriul set personalizat de rezultate.
- A fi „diferit” este o strategie de căutare viabilă. În cele din urmă, acesta este conținutul Google care recompensează pentru că este diferit și nu doar mai bun. În această lume nouă, conținutul care își asumă riscuri – orice diferă de rezultatele căutării existente în ceea ce privește focalizarea sau opinia – are un mecanism de recompensare. Persoanele defavorizate au un nou instrument în lupta lor de a depăși conținutul zgârie-nori.
- Există un stimulent pentru a colabora cu conținutul existent în loc să concurezi. În acest context, este logic să ne gândim la articolele noastre ca fiind participanți activi la un ecosistem colaborativ de conținut. SEO nu mai este „câștigătorul ia tot”: în loc ca un singur articol să domine SERP pentru un anumit subiect, acum există posibilități ca multe mai multe articole să „câștigă”, deși la scară mai mică.

Acum, cererea de brevet legată este doar asta: o cerere de brevet. Ideile Google preced întotdeauna modificările reale ale algoritmilor de căutare și nu există nicio garanție că acestea se vor realiza.

Dar, indiferent de mecanica precisă a dacă și cum este implementat câștigul de informații, cea mai mare concluzie din acest brevet este pur și simplu că Google intenționează să recompenseze articolele care conțin informații pe care alte articole nu le au. Aceasta înseamnă că fiecare agent de marketing de conținut va fi bine servit dacă ține cont de această întrebare pentru tot ceea ce publică:
„ Ce informații noi aduc în discuție? ”
Iată câteva modalități practice de a include această întrebare în conținutul dvs.:
1. Creați conținut care se bazează pe predecesorii săi
Dacă recunoașteți ideea că conținutul dvs. face parte dintr-un ecosistem colaborativ, obiectivul dvs. trece de la a învinge articolele rivale la a le completa . În loc să încerci să depășești cu bucurie acel articol de zgârie-nori uriaș, lucrează pe presupunerea că cititorul a citit postul concurent. Dacă este adevărat, cum poți adăuga valoare dincolo de ceea ce au citit deja?
- Partajați un „pas următor” practic, ceva care acționează ca o continuare a conținutului concurent.
- Elaborați o idee cheie conținută în articolul concurent.
- Scrieți versiunea 102 a lui 101, intrând în mai multă profunzime, detalii și nuanțe.
2. Experimentați cu cadre și unghiuri riscante
Câștigul de informații recompensează articolele pentru asumarea de riscuri și abaterea de la status quo. În loc să se uite la rezultatele căutării cu scopul de a emula conținutul de top, încurajează specialiștii în marketing să se diferențieze. Există o mulțime de modalități de a atinge acest obiectiv (în același timp îndeplinind intenția de căutare):
- Adresați intenția neservită („Cazul meu de utilizare specific nu este reprezentat aici”).
- Completați informațiile care lipsesc („Este ciudat că nimeni nu a menționat X aici”).
- Contestați o opinie diferită sau eronată („Aceasta este o credință învechită”).
- Corectați greșelile în înțelegerea Google („Nu la asta am vrut să spun prin acest cuvânt cheie”).
Citiți mai multe: Falația „Google Knows Best”.
3. Construiți un șanț informațional cu cercetări originale
După cum am scris mai devreme, „cercetarea primară este forma supremă de obținere a informațiilor”. Orice lucru nou și proprietar este cel mai sigur și mai sigur mod de a adăuga date noi în discuție - prin definiție, orice creați nu poate fi găsit în altă parte. În timp ce „cercetarea originală” sună intimidant, există o mulțime de moduri de a o încorpora în conținutul tău:
- Includeți perspective personale și experiențe ale companiei
- Sondajează-ți clienții, utilizatorii sau rețeaua
- Adăugați cotații de la IMM-uri
Citiți mai multe: Conținut Copycat: Instrumentele SEO ne-au adus aici, oamenii ne vor scoate
Motorul de căutare Underdog
Ca regulă generală, celor mai mulți marketeri de conținut nu le place să recunoască concurența pe care o reprezintă rezultatele căutării existente (sau realitatea că, uneori, pur și simplu nu putem concura cu ei).
Când recunoaștem concurența, este de obicei să alegem elemente din structura lor, în încercarea de a crea ceva „mai bun”, ceea ce duce la cursa continuă a înarmărilor articolelor zgârie-nori, fiecare conținând aceleași informații obosite ca și articolele care au apărut înainte.
„Câștig de informații” este încercarea Google de a reduce această problemă și de a crea un mecanism de recompensă pentru articolele care adaugă informații noi în discuție - și aspiră să fie diferit , în loc să fie doar mai buni . Viitorul pe care îl prezintă este bun, creând o cale către rezultate de căutare mai utile și mai interesante, dar și deblochând noi modalități pentru companiile mai mici, defavorizate, de a beneficia de căutare pur și simplu, răspunzând la întrebarea:
„ Ce informații noi aduc în discuție?”