
Le gagnant ne prend pas tout : comment le « gain d'informations » peut réparer les résultats de recherche erronés de Google
Publié: 2022-06-27Gagnants à travers l'histoire de la recherche
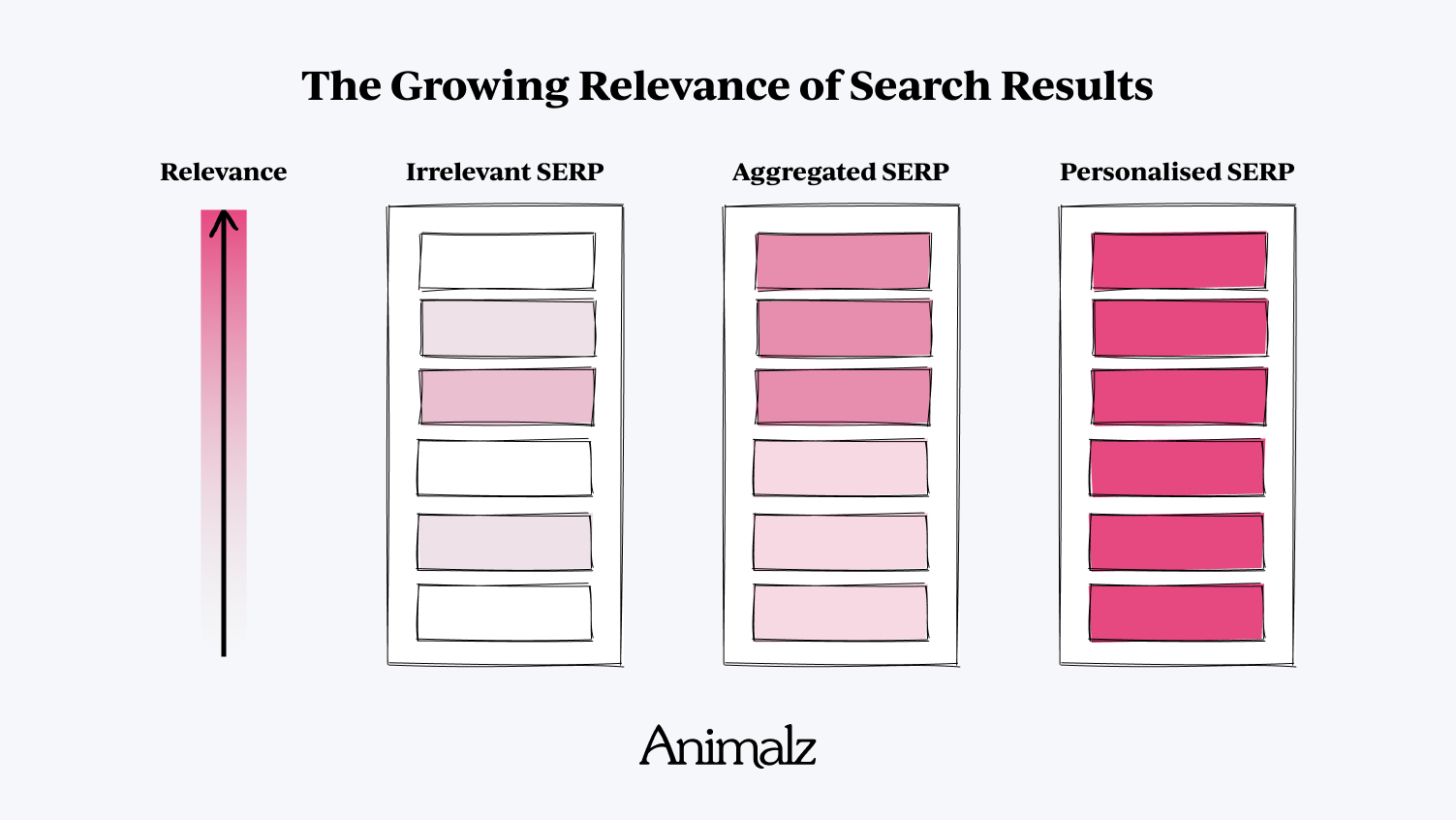
Le marketing de contenu était autrefois plus simple qu'il ne l'est aujourd'hui. Il fut un temps où une recherche sur Google ne donnait qu'une page de résultats de recherche vaguement pertinents ; trouver un article qui répondait à votre question spécifique était rare et incroyablement bienvenu. Ces articles ont été les gagnants, gagnant la part du lion du trafic et de l'engagement proposés.
Au fur et à mesure que de plus en plus d'entreprises entraient dans la mêlée du marketing de contenu, il devenait plus facile pour les chercheurs de trouver des informations pertinentes : vous pourriez probablement extraire des extraits utiles de la plupart des résultats de recherche les mieux classés. Les critères de domination SEO se sont déplacés vers l' agrégation : tout article qui consolidait les informations fragmentées du SERP en un seul endroit pratique devenait le gagnant de facto (d'où le modèle du gratte-ciel et tous ses problèmes).
Aujourd'hui, nous avons un autre problème. Au lieu de chasser le signal parmi le bruit, nous recherchons le signal parmi… le signal. Dans les industries les plus matures, chaque page de résultats de moteur de recherche (SERP) donne l'impression d'être contestée par une demi-douzaine de grandes marques, avec des articles longs et ultra-complets construits sur des montagnes de backlinks et soutenus par un référencement rigoureux sur la page. Ces articles ont généralement le même aspect et le même son, contenant des variations mineures des mêmes informations de base.
Grâce à l'ancien état d'esprit du « le gagnant prend tout », ces SERP sont des causes perdues. Les grandes marques établies peuvent échanger indéfiniment les classements de première page ; les blogs plus petits et moins établis ne surmonteront jamais le fossé de l'autorité de domaine et de la notoriété de la marque. Mais de la même manière que le marketing de contenu a évolué au fil du temps, Google aussi.
Gain d'informations
En avril 2020, Google a déposé un brevet visant à résoudre un problème familier :
"Lorsqu'un ensemble de documents partageant un sujet est identifié, de nombreux documents peuvent inclure des informations similaires... un utilisateur peut soumettre une recherche liée à la résolution d'un problème informatique... et peut ensuite recevoir plusieurs documents qui incluent une liste similaire de solutions , mesures correctives, ressources, etc.
C'est Google qui reconnaît le problème que nous rencontrons tous les jours : le contenu copié. La plupart des résultats de recherche contiennent les mêmes informations. Une fois qu'un lecteur a lu un article, il les a effectivement tous lus.
Pour Google, il s'agit d'un problème d'engagement des utilisateurs : le contenu copié raccourcit le parcours de l'utilisateur, supprimant toute incitation à continuer à rechercher et à découvrir des informations utiles supplémentaires. Pour les spécialistes du marketing de contenu, il s'agit d'un problème de différenciation : à moins que vous ne soyez en mesure de surclasser ces énormes articles de gratte-ciel, il y a peu d'incitation à s'embêter à contester le mot-clé.
La solution de Google est simple : récompensez les articles qui apportent de nouvelles informations sur la table.
Ils suggèrent de le faire par ce qu'ils appellent le gain d'information, une mesure des nouvelles informations fournies par un article donné, en plus des informations présentes dans d'autres articles sur le même sujet.
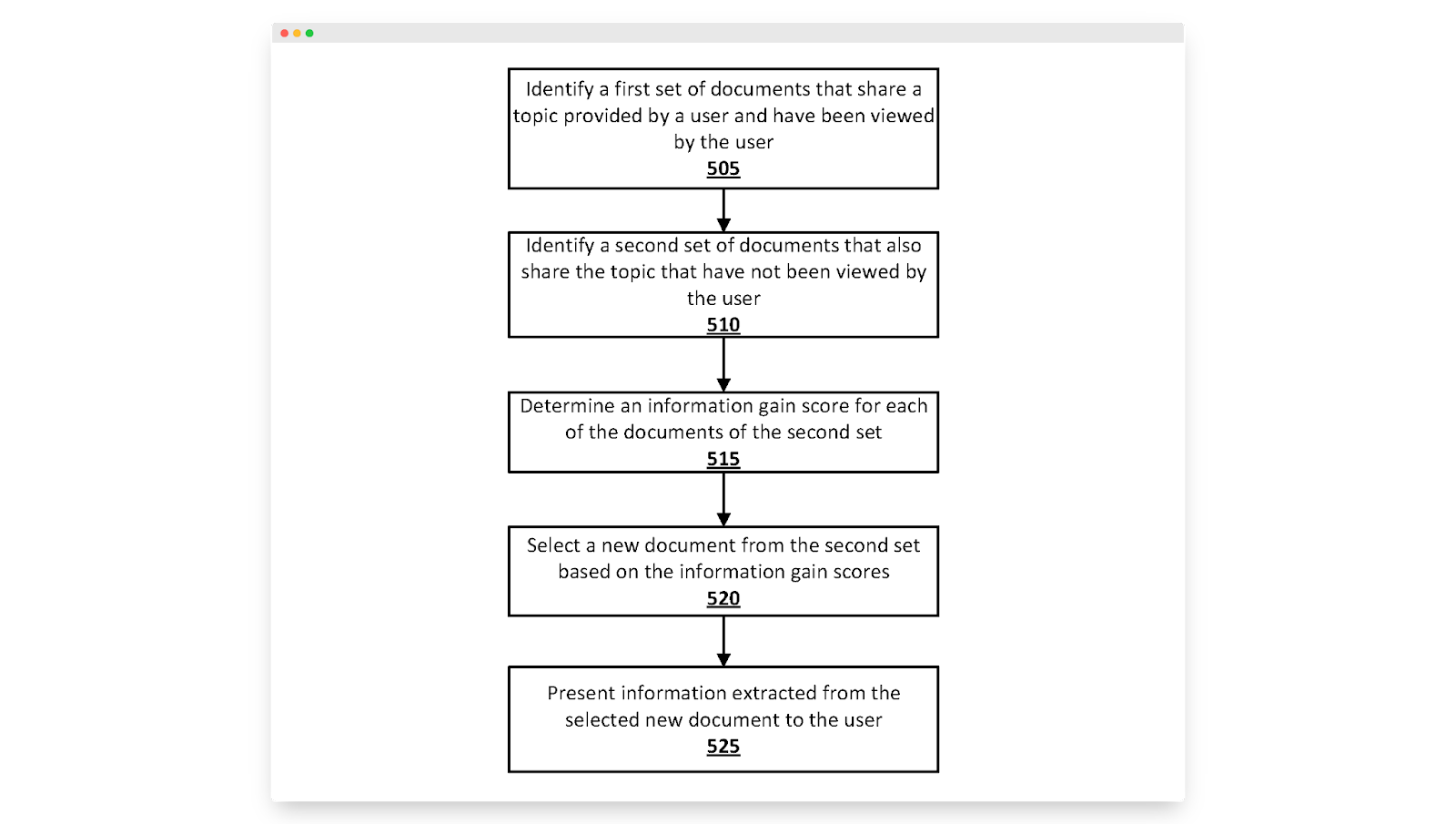
Le moyen le plus simple de mesurer le gain d'informations est de comparer le contenu d'un article donné à ceux déjà classés dans le SERP, mais Google suggère d'aller plus loin et de prendre en compte le parcours de recherche de l'utilisateur pour déterminer ce qui constitue une "nouvelle information".
En d'autres termes, le gain d'information sera relatif au contenu concurrent mais aussi aux articles lus par chaque chercheur .
Google suggère plusieurs manières d'utiliser ces informations :
- Afficher des résultats de recherche réactifs et personnalisés aux utilisateurs qui changent en fonction du contenu qu'ils ont lu précédemment.
- Faciliter des conversations plus intelligentes avec la recherche vocale et les chatbots.
- Influencer la façon dont les informations récapitulatives sont extraites des articles et partagées avec les chercheurs.
Récompenser le contenu pour être différent, pas seulement meilleur
L'interprétation la plus simple de ce brevet est qu'un article qui ajoute quelque chose de nouveau à la discussion peut se classer plus haut qu'un article qui répète les mêmes informations que d'autres. Inversement, si votre article offre les mêmes informations de base que celui que le chercheur a déjà lu, il pourrait être moins bien classé.
Mais il y a des implications plus larges du concept de gain d'information :
- Cela ouvre la porte à une énorme fragmentation de chaque SERP. L'idée des résultats de recherche comme quelque chose de statique et monolithique - un ensemble unique de "meilleurs" articles servant une seule intention de recherche principale - devient de plus en plus obsolète. L'industrie du marketing de contenu s'adapte lentement à l'idée d'un seul SERP servant plusieurs intentions fragmentées, mais ce brevet suggère un avenir où chaque chercheur a son propre ensemble de résultats personnalisés.
- Être « différent » est une stratégie de recherche viable. En fin de compte, il s'agit d'un contenu récompensant Google pour être différent et pas seulement meilleur. Dans ce nouveau monde, le contenu à risque - tout ce qui diffère des résultats de recherche existants en termes d'orientation ou d'opinion - a un mécanisme pour être récompensé. Les outsiders ont un nouvel outil dans leur lutte pour surpasser le contenu des gratte-ciel.
- Il y a une incitation à collaborer avec le contenu existant au lieu de rivaliser. Dans ce contexte, il est logique de considérer nos articles comme des participants actifs dans un écosystème collaboratif de contenu. Le référencement n'est plus "le gagnant prend tout" : au lieu d'un seul article dominant le SERP pour un sujet donné, il existe désormais des possibilités pour beaucoup plus d'articles de "gagner", bien qu'à plus petite échelle.

Maintenant, la demande de brevet liée n'est que cela : une demande de brevet. Les idées de Google précèdent toujours les changements réels apportés aux algorithmes de recherche, et rien ne garantit qu'ils se concrétiseront.

Mais quelle que soit la mécanique précise de la mise en œuvre et de la manière dont le gain d'informations est mis en œuvre, le plus gros avantage de ce brevet est simplement que Google a l'intention de récompenser les articles qui contiennent des informations que d'autres articles ne contiennent pas. Cela signifie que chaque spécialiste du marketing de contenu sera bien servi en gardant cette question à l'esprit pour tout ce qu'il publie :
« Quelles nouvelles informations est-ce que j'apporte à la discussion ? »
Voici quelques façons pratiques de tenir compte de cette question dans votre contenu :
1. Créez du contenu qui s'appuie sur ses prédécesseurs
Si vous reconnaissez l'idée que votre contenu fait partie d'un écosystème collaboratif, votre objectif passe de battre les articles rivaux à les compléter . Au lieu d'essayer de surclasser allègrement cet article de gratte-ciel gargantuesque, partez du principe que le lecteur a lu le message concurrent. Si c'est vrai, comment pouvez-vous ajouter de la valeur au-delà de ce qu'ils ont déjà lu ?
- Partagez une « étape suivante » pratique, quelque chose qui agit comme une continuation du contenu concurrent.
- Développez une idée clé contenue dans l'article concurrent.
- Écrivez la version 102 de leur 101, en allant plus en profondeur, en détail et en nuance.
2. Expérimentez avec des cadres et des angles risqués
Le gain d'informations récompense les articles qui prennent des risques et s'écartent du statu quo. Au lieu de regarder les résultats de recherche dans le but d'imiter le contenu le mieux classé, cela encourage les spécialistes du marketing à se différencier. Il existe de nombreuses façons d'atteindre cet objectif (tout en respectant l'intention de recherche) :
- Traiter l'intention non servie (« Mon cas d'utilisation spécifique n'est pas représenté ici. »)
- Remplissez les informations manquantes ("C'est bizarre que personne n'ait mentionné X ici.")
- Remettez en question une opinion différente ou erronée ("C'est une croyance dépassée".)
- Corrigez les erreurs de compréhension de Google ("Ce n'est pas ce que je voulais dire par ce mot-clé.")
Lire la suite : Le sophisme "Google sait mieux"
3. Construire une douve d'information avec des recherches originales
Comme nous l'avons déjà écrit, "la recherche primaire est la forme ultime d'obtention d'informations". Tout ce qui est nouveau et exclusif est le moyen le plus sûr et le plus sûr d'ajouter de nouvelles données à la discussion - par définition, tout ce que vous créez ne peut être trouvé nulle part ailleurs. Bien que la « recherche originale » semble intimidante, il existe de nombreuses façons de l'intégrer à votre contenu :
- Inclure les perspectives personnelles et les expériences de l'entreprise
- Sondez vos clients, vos utilisateurs ou votre réseau
- Ajouter des citations de PME
Lire la suite : Copier le contenu : les outils de référencement nous ont amenés ici, les humains nous en sortiront
Le moteur de recherche Underdog
En règle générale, la plupart des spécialistes du marketing de contenu n'aiment pas reconnaître la concurrence posée par les résultats de recherche existants (ou la réalité que parfois, nous ne pouvons tout simplement pas rivaliser avec eux).
Lorsque nous reconnaissons la concurrence, c'est généralement pour choisir des éléments de leur structure dans le but de créer quelque chose de "meilleur", conduisant à la poursuite de la course aux armements d'articles de gratte-ciel, chacun contenant les mêmes informations fatiguées que les articles précédents.
Le « gain d'informations » est la tentative de Google de réduire ce problème et de créer un mécanisme de récompense pour les articles qui ajoutent de nouvelles informations à la discussion - et aspirent à être différents au lieu de simplement meilleurs . L'avenir qu'il présente est bon, créant un chemin vers des résultats de recherche plus utiles et intéressants, mais aussi ouvrant de nouvelles façons pour les petites entreprises négligées de bénéficier de la recherche simplement en répondant à une seule question :
« Quelles nouvelles informations est-ce que j'apporte à la discussion ? »