
Zwycięzca nie bierze wszystkiego: jak „zdobywanie informacji” może naprawić nieprawidłowe wyniki wyszukiwania Google
Opublikowany: 2022-06-27Zwycięzcy w historii wyszukiwania
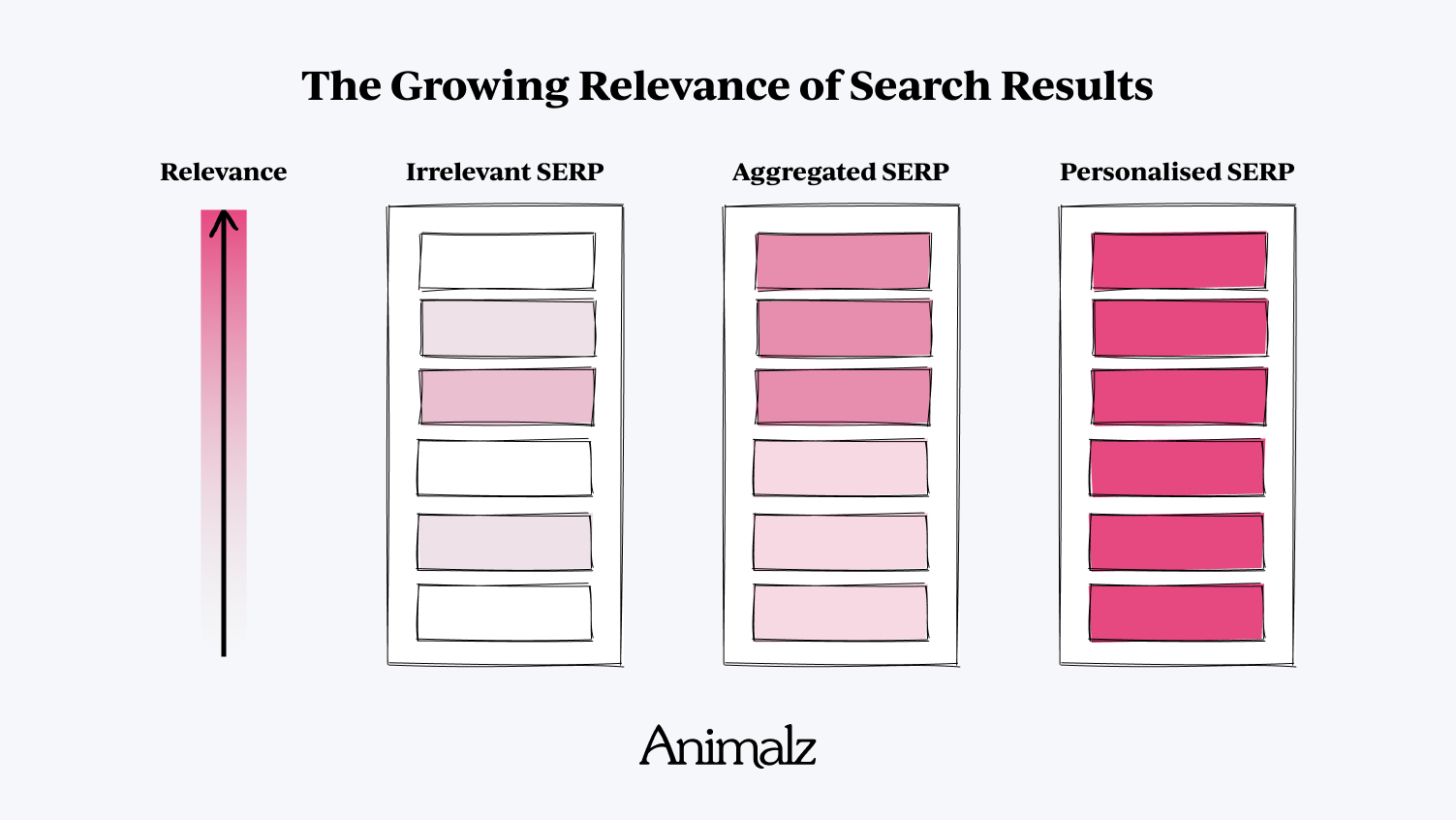
Kiedyś marketing treści był prostszy niż jest dzisiaj. Był czas, kiedy wyszukiwanie w Google dawało stronę zawierającą tylko niejasno trafne wyniki wyszukiwania; znalezienie artykułu, który odnosił się do konkretnego pytania, było rzadkie i niezwykle mile widziane. Te artykuły były zwycięzcami, zdobywając lwią część ruchu i zaangażowania w ofercie.
W miarę jak coraz więcej firm brało udział w walce o content marketing, wyszukiwarkom łatwiej było znaleźć odpowiednie informacje: prawdopodobnie można było wyłuskać przydatne fragmenty z większości najlepszych wyników wyszukiwania. Kryteria dominacji SEO przesunęły się na agregację : każdy artykuł, który skonsolidował fragmentaryczne informacje SERP w jednym wygodnym miejscu, stał się de facto zwycięzcą (stąd model wieżowca i wszystkie jego problemy).
Dziś mamy inny problem. Zamiast szukać sygnału wśród szumu, szukamy sygnału wśród… sygnału. W najbardziej dojrzałych branżach każda strona wyników wyszukiwania (SERP) sprawia wrażenie, jakby rywalizowało z nią pół tuzina wielkich marek, z długimi, bardzo kompleksowymi artykułami zbudowanymi na górach linków zwrotnych i popartymi rygorystycznym SEO na stronie. Artykuły te ogólnie wyglądają i brzmią tak samo, zawierają drobne odmiany tych samych podstawowych informacji.
Zgodnie ze starym sposobem myślenia „zwycięzca bierze wszystko”, te SERP są straconymi przyczynami. Ogromne, ugruntowane marki mogą bez końca wymieniać rankingi na pierwszej stronie; mniejsze, mniej ugruntowane blogi nigdy nie pokonają fosy autorytetu domeny i świadomości marki. Ale w ten sam sposób, w jaki z biegiem czasu ewoluował content marketing, tak samo rozwija się Google.
Zdobywanie informacji
W kwietniu 2020 r. Google zgłosił patent, który miał na celu rozwiązanie znanego problemu:
„Gdy zostanie zidentyfikowany zestaw dokumentów, które mają wspólny temat, wiele dokumentów może zawierać podobne informacje … użytkownik może wprowadzić wyszukiwanie związane z rozwiązywaniem problemu komputerowego … a następnie może otrzymać wiele dokumentów, które zawierają podobną listę rozwiązań , kroki zaradcze, zasoby itp.”
To jest Google, który rozpoznaje problem, z którym spotykamy się każdego dnia: treści naśladujące. Większość wyników wyszukiwania zawiera te same informacje. Gdy czytelnik przeczytał jeden artykuł, skutecznie przeczytał je wszystkie.
Dla Google jest to problem związany z zaangażowaniem użytkowników: treści naśladujące ograniczają podróż użytkownika, usuwając wszelkie zachęty do dalszego wyszukiwania i odkrywania dodatkowych przydatnych informacji. Dla marketerów treści jest to problem zróżnicowania: jeśli nie jesteś w stanie przewyższyć tych ogromnych artykułów o wieżowcach, nie ma zachęty do kwestionowania słowa kluczowego.
Rozwiązanie Google jest proste: nagradzaj artykuły, które przynoszą nowe informacje do tabeli.
Sugerują robienie tego poprzez coś, co nazywają zyskiem informacji, pomiar nowych informacji dostarczonych przez dany artykuł, wykraczający poza informacje zawarte w innych artykułach na ten sam temat.
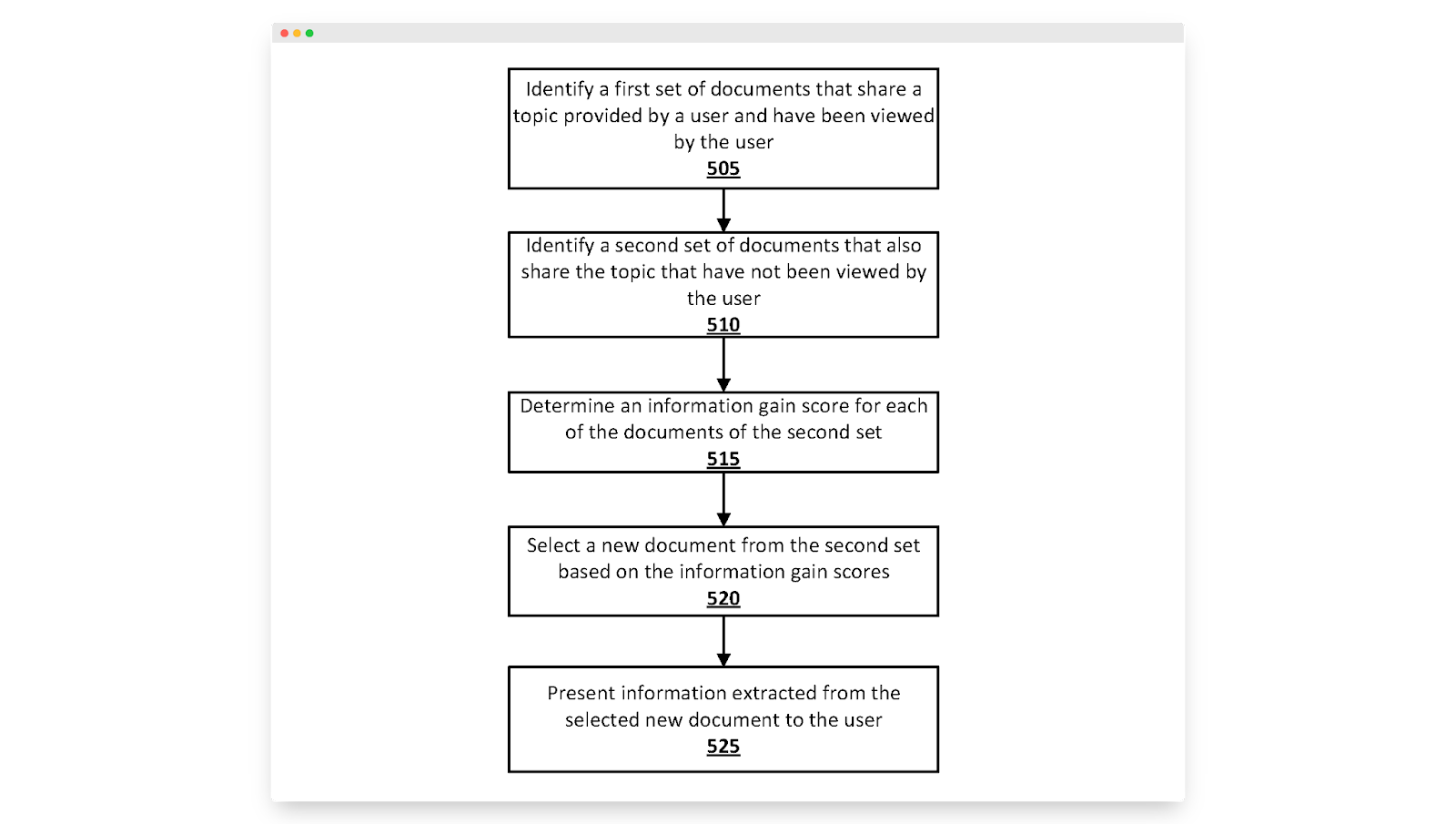
Najprostszym sposobem mierzenia przyrostu informacji jest porównanie treści danego artykułu z tymi, które już znajdują się w SERP, ale Google sugeruje pójście o krok dalej i uwzględnienie ścieżki wyszukiwania użytkownika w celu ustalenia, co stanowi „nową informację”.
Innymi słowy, zysk informacji będzie zależał od treści konkurencyjnych, ale także od artykułów przeczytanych przez każdego z wyszukiwarek .
Google sugeruje kilka sposobów wykorzystania tych informacji:
- Wyświetlanie elastycznych, spersonalizowanych wyników wyszukiwania użytkownikom, które zmieniają się w zależności od treści, które wcześniej przeczytali.
- Ułatwianie inteligentniejszych rozmów dzięki wyszukiwaniu głosowemu i chatbotom.
- Wpływanie na sposób, w jaki informacje podsumowujące są wyodrębniane z artykułów i udostępniane wyszukiwarkom.
Nagradzanie treści za bycie innym, a nie tylko lepszym
Najprostszą interpretacją tego patentu jest to, że artykuł, który dodaje coś nowego do dyskusji, może mieć wyższą pozycję niż artykuł, który powtarza te same informacje, co inne. I odwrotnie, jeśli Twój artykuł zawiera te same podstawowe informacje, co te, które już przeczytała wyszukiwarka, może zostać sklasyfikowany niżej.
Ale są szersze implikacje koncepcji zdobywania informacji:
- To otwiera drzwi do ogromnej fragmentacji każdego SERP. Idea wyników wyszukiwania jako czegoś statycznego i monolitycznego — jeden zestaw „najlepszych” artykułów służących jednemu głównemu celowi wyszukiwania — staje się coraz bardziej przestarzała. Branża content marketingu powoli wpada na pomysł pojedynczego SERP obsługującego wiele, fragmentarycznych intencji, ale ten patent sugeruje przyszłość, w której każdy użytkownik wyszukujący będzie miał swój własny, spersonalizowany zestaw wyników.
- Bycie „innym” to realna strategia wyszukiwania. Ostatecznie jest to treść nagradzająca Google za to, że jest inna , a nie tylko lepsza. W tym nowym świecie treści podejmujące ryzyko — wszystko, co różni się od istniejących wyników wyszukiwania pod względem skupienia lub opinii — mają mechanizm nagradzania. Słabsze osoby mają nowe narzędzie w walce o prześcignięcie treści drapaczy chmur.
- Istnieje zachęta do współpracy z istniejącymi treściami zamiast konkurowania. W tym kontekście sensowne jest myślenie o naszych artykułach jako o aktywnych uczestnikach wspólnego ekosystemu treści. SEO nie jest już „zwycięzcą bierze wszystko”: zamiast pojedynczego artykułu zdominowanego przez SERP dla danego tematu, istnieje teraz możliwość „wygranej” większej liczby artykułów, choć na mniejszą skalę.

Teraz powiązane z nim zgłoszenie patentowe jest właśnie tym: zgłoszeniem patentowym. Pomysły Google zawsze poprzedzają faktyczne zmiany w algorytmach wyszukiwania i nie ma gwarancji, że zostaną zrealizowane.

Ale niezależnie od dokładnej mechaniki tego, czy iw jaki sposób zaimplementowano zdobywanie informacji, największym wnioskiem płynącym z tego patentu jest po prostu to, że Google zamierza nagradzać artykuły, które zawierają informacje, których nie zawierają inne artykuły. Oznacza to, że każdy specjalista ds. marketingu treści będzie dobrze obsługiwany, jeśli to pytanie będzie miało miejsce przed wszystkim, co publikuje:
„ Jakie nowe informacje wnoszę do dyskusji? ”
Oto kilka praktycznych sposobów na uwzględnienie tego pytania w treści:
1. Twórz treści, które opierają się na swoich poprzednikach
Jeśli uznasz, że Twoje treści są częścią ekosystemu współpracy, Twój cel zmieni się z pokonania konkurencyjnych artykułów na ich uzupełnienie . Zamiast próbować beztrosko przewyższyć ten gargantuiczny artykuł o wieżowcu, załóż, że czytelnik przeczytał konkurencyjny post. Jeśli to prawda, jak możesz dodać wartość poza tym, co już przeczytali?
- Podziel się praktycznym „następnym krokiem”, czymś, co stanowi kontynuację konkurencyjnych treści.
- Opracuj kluczową ideę zawartą w konkurencyjnym artykule.
- Napisz 102 wersję ich 101, zagłębiając się w szczegóły, szczegóły i niuanse.
2. Eksperymentuj z ryzykownymi ramkami i kątami
Zdobywanie informacji nagradza artykuły za podejmowanie ryzyka i odchodzenie od status quo. Zamiast patrzeć na wyniki wyszukiwania z myślą o naśladowaniu treści o najwyższej pozycji, zachęca marketerów do różnicowania. Istnieje wiele sposobów na osiągnięcie tego celu (przy jednoczesnym spełnieniu celu wyszukiwania):
- Zaadresuj niezasłużoną intencję („Mój konkretny przypadek użycia nie jest tutaj przedstawiony”).
- Uzupełnij brakujące informacje („To dziwne, że nikt nie wspomniał tutaj o X”).
- Zakwestionuj odmienną lub błędną opinię („To przestarzałe przekonanie”).
- Popraw błędy w zrozumieniu Google („Nie to miałem na myśli przez to słowo kluczowe”).
Przeczytaj więcej: Błąd „Google wie najlepiej”
3. Zbuduj fosę informacyjną dzięki oryginalnym badaniom
Jak pisaliśmy wcześniej, „badania podstawowe są ostateczną formą zdobywania informacji”. Wszystko, co nowe i zastrzeżone, jest najbezpieczniejszym i najpewniejszym sposobem dodania nowych danych do dyskusji — z definicji nic, co tworzysz, nie można znaleźć nigdzie indziej. Chociaż „oryginalne badania” brzmią onieśmielająco, istnieje wiele sposobów na włączenie ich do treści:
- Uwzględnij osobiste perspektywy i doświadczenia firmy
- Przeprowadź ankietę wśród klientów, użytkowników lub sieci
- Dodaj cytaty od MŚP
Przeczytaj więcej: Copycat Content: Narzędzia SEO nas tu przywiodły, ludzie nas wyciągną
Wyszukiwarka Underdog
Z reguły większość marketerów treści nie lubi przyznawać się do konkurencji, jaką stwarzają istniejące wyniki wyszukiwania (lub rzeczywistość, w której czasami po prostu nie możemy z nimi konkurować).
Kiedy doceniamy konkurencję, zwykle wybieramy elementy z ich struktury, próbując stworzyć coś „lepszego”, co prowadzi do nieustającego wyścigu zbrojeń artykułów o wieżowcach, z których każdy zawiera te same męczące informacje, co artykuły, które pojawiły się wcześniej.
„Zysk informacji” to próba Google, aby ograniczyć ten problem i stworzyć mechanizm nagradzania artykułów, które dodają nowe informacje do dyskusji – i aspirują do bycia innym , a nie tylko lepszym . Przyszłość, którą przedstawia, jest dobra, tworząc ścieżkę do bardziej pomocnych, interesujących wyników wyszukiwania, ale także otwierając nowe sposoby na czerpanie korzyści z wyszukiwania przez mniejsze, słabsze firmy, po prostu odpowiadając na jedno pytanie:
„ Jakie nowe informacje wnoszę do dyskusji?”