
Determinarea stărilor de dialog pentru modelele de limbă actualizate
Publicat: 2022-03-16Primele pretenții de determinare a stărilor de dialog pentru modelele de limbă
Sunt șanse să fi văzut brevete de dialog de la om la computer de la Google. Am scris despre unele în trecut. Iată două care oferă o mulțime de detalii despre un astfel de dialog:
- Dialog de la om la computer la Google
- Conținut nesolicitat în dialogul de la om la computer
Pe lângă faptul că privim cu atenție brevetele care implică dialogul de la om la computer, merită să petreceți timp cu procesarea limbajului natural și comunicațiile dintre ființele umane și computere. Am mai scris despre câteva dintre acestea. Iată câteva dintre ele:
- Asistentul Google și procesarea limbajului natural bazat pe context
- Răspunsuri la întrebări în limbaj natural
Acest brevet Google Determining Dialog States For Language Models a fost actualizat de două ori acum, cea mai recentă versiune fiind acordată la începutul acestei săptămâni. Ultima primă afirmație este puțin mai lungă și are câteva cuvinte noi adăugate.
În mod ideal, aceste brevete trebuie să înceapă cu o privire profundă asupra limbajului revendicărilor.
Cea de-a doua versiune a „Determinarea stărilor de dialog pentru modelele de limbă”, depusă pe 18, 2018 și acordată pe 4 februarie 2020, începe cu următoarea afirmație:
- Ceea ce se pretinde este:
- 1. O metodă implementată pe calculator, cuprinzând:
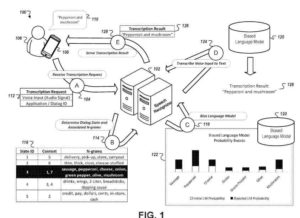
- Recepția, de către un dispozitiv de calcul, a datelor audio pentru o intrare vocală la dispozitivul de calcul, în care intrarea vocală corespunde unei etape necunoscute a unui dialog vocal în mai multe etape între dispozitivul de calcul și un utilizator al dispozitivului de calcul
- Determinarea unei predicții inițiale pentru etapa necunoscută a dialogului vocal în mai multe etape
Furnizarea, de către dispozitivul de calcul și unui sistem de dialog vocal,- (i) datele audio pentru intrarea vocală către dispozitivul de calcul și
- (ii) o indicație a predicției inițiale pentru etapa necunoscută a dialogului vocal în mai multe etape
- Primirea, de către dispozitivul de calcul și de la sistemul de dialog vocal, a unei transcripții a intrării vocale, în care transcrierea a fost generată prin procesarea datelor audio cu un model care a fost polarizat în funcție de parametrii care corespund unei predicții rafinate pentru etapa necunoscută de dialogul vocal în mai multe etape, în care sistemul de dialog vocal este configurat pentru a determina predicția rafinată pentru etapa necunoscută a dialogului vocal în mai multe etape pe baza (i) predicția inițială pentru etapa necunoscută a dialogului vocal în mai multe etape și
- (ii) informații suplimentare care descriu un context al intrării vocale și în care informațiile suplimentare care descriu contextul intrării vocale sunt independente de conținutul
- intrarea vocală; și prezentarea transcripției intrării vocale cu dispozitivul de calcul.
Prima versiune a acestui brevet de continuare, Determinarea stărilor de dialog pentru modelele de limbă, depusă la 16 martie 2016 și acordată la 22 mai 2018, începe cu această revendicare:
- Ceea ce se pretinde este:
- 1. O metodă implementată pe calculator, cuprinzând:
- Primirea, la un sistem de calcul, a datelor audio care indică o primă intrare vocală care a fost furnizată unui dispozitiv de calcul
- Determinarea faptului că prima intrare vocală face parte dintr-un dialog vocal care include o multitudine de stări de dialog predefinite aranjate pentru a primi o serie de intrări vocale legate de o anumită sarcină, în care fiecare stare de dialog este mapată la: (i) un set de afișarea datelor care caracterizează conținutul care este desemnat pentru afișare atunci când sunt primite intrări vocale pentru starea de dialog și
(ii) un set de n-grame - Primirea, la sistemul de calcul, a datelor de afișare mai întâi care caracterizează conținutul care a fost afișat pe un ecran al dispozitivului de calcul atunci când prima intrare vocală a fost furnizată dispozitivului de calcul; selectarea, de către sistemul de calcul, a unei anumite stări de dialog din multitudinea de stări de dialog predefinite care corespunde primei intrări vocale, inclusiv determinarea unei potriviri între primele date de afișare și setul corespunzător de date de afișare care este mapat la respectivul stare de dialog; polarizarea unui model de limbaj prin ajustarea scorurilor de probabilitate pe care modelul de limbaj le indică pentru n-grame din setul corespunzător de n-grame care sunt mapate la starea de dialog particulară; și transcrierea intrării vocale folosind modelul de limbaj părtinitor.
Prima revendicare cea mai recentă din cea mai recentă versiune a acestui brevet, Determinarea stărilor de dialog pentru modelele de limbă, a fost depusă la 2 ianuarie 2020 și a fost acordată la 1 martie 2022. Ne spune:
- Ceea ce se pretinde este:
- 1. O metodă implementată pe calculator, cuprinzând:
- Obținerea transcripțiilor de intrări vocale dintr-un set de antrenament de intrări vocale, în care fiecare intrare vocală din setul de antrenament de intrări vocale este direcționată către una din multitudinea de etape ale unei activități vocale în mai multe etape
- Obţinerea datelor de afişare asociate cu fiecare intrare vocală din setul de antrenament de intrări vocale care caracterizează conţinutul care este desemnat pentru afişare atunci când este recepţionată intrarea vocală asociată; generarea unei multitudini de grupuri de transcripții, în care fiecare grup de transcripții include un subset diferit de transcripții de intrări vocale din setul de antrenament de intrări vocale
- Atribuirea fiecărui grup de transcriere la o stare de dialog diferită a unui model de stare de dialog care include o multitudine de stări de dialog, în care fiecare stare de dialog a multitudinii de stări de dialog: corespunde unei etape diferite a activității vocale în mai multe etape; și este mapat la un set respectiv de date de afișare care caracterizează conținutul care este desemnat pentru afișare atunci când sunt recepționate intrări vocale din setul de antrenament de intrări vocale care sunt asociate cu grupul de transcripții atribuit stării de dialog; pentru fiecare grup de transcripții, determinarea unui set reprezentativ de n-grame pentru grup și asocierea setului reprezentativ de n-grame pentru grup cu starea de dialog corespunzătoare a modelului de stare de dialog căruia îi este alocat grupul, în care set reprezentativ de n-grame determinat pentru grupul de transcripții cuprind n-grame-satisfăcând un număr prag de apariții în grupul de transcripții atribuit stării de dialog a modelului de stare de dialog
- Primirea unei intrări vocale ulterioare și prima afișare a datelor care caracterizează conținutul care a fost afișat pe un ecran atunci când a fost primită intrarea vocală ulterioară, intrarea vocală ulterioară a fost direcționată către o anumită etapă a activității vocale în mai multe etape
Determinarea unei potriviri între primele date de afișare și setul respectiv de date de afișare mapate la starea de dialog în modelul de stare de dialog care corespunde etapei particulare a activității cu mai multe voci - Procesarea, cu un dispozitiv de recunoaștere a vorbirii, a intrării vocale ulterioare și a primelor date de afișare, inclusiv polarizarea dispozitivului de recunoaștere a vorbirii utilizând setul reprezentativ de n-grame asociate cu starea de dialog în modelul de stare de dialog care corespunde etapei particulare a activitate cu mai multe voci
\
Compararea revendicărilor stărilor de dialog de determinare pentru modelele de limbaj
Acestea sunt câteva dintre diferențele pe care le văd cu diferitele versiuni ale brevetului:

1. Toate cele trei versiuni ne spun că sunt despre „intrări vocale”, care acționează ca parte a unui set de antrenament.
Așadar, spre deosebire de brevetele anterioare despre stările de dialog între oameni și computere, care s-au concentrat pe conținutul dialogului, acest brevet se referă în primul rând la limbajul verbal și la intrările reale de voce.
2. A doua și a treia versiune a brevetului descriu ruperea transcrierilor intrărilor vocale în ngrame, ceea ce poate fi util în calcularea statisticilor despre apariția intrărilor vocale utilizate.
3. Revendicarea celei mai noi și a treia versiune a stărilor de dialog pentru stabilirea brevetelor pentru modelele de limbă menționează utilizarea unui dispozitiv de recunoaștere a vitezei.
- Ceea ce se pretinde este:
- 1. O metodă implementată pe calculator, cuprinzând: primirea, la un sistem de calcul, a datelor audio care indică o primă intrare de voce care a fost furnizată unui dispozitiv de calcul; determinarea faptului că prima intrare vocală face parte dintr-un dialog vocal care include o multitudine de stări de dialog predefinite aranjate pentru a primi o serie de intrări vocale legate de o anumită sarcină, în care fiecare stare de dialog este mapată la:
- (i) un set de date de afișare care caracterizează conținutul care este desemnat pentru afișare atunci când sunt primite intrări vocale pentru starea de dialog și
- (ii) un set de n-grame; primirea, la sistemul de calcul, a primelor date de afișare care caracterizează conținutul care a fost afișat pe un ecran al dispozitivului de calcul atunci când prima intrare vocală a fost furnizată dispozitivului de calcul
- Selectarea, de către sistemul de calcul, a unei anumite stări de dialog din multitudinea de stări de dialog predefinite care corespunde primei intrări vocale, inclusiv determinarea unei potriviri între primele date de afișare și setul corespunzător de date de afișare care este mapat la respectivul starea de dialog
- Denaturarea unui model de limbă prin ajustarea scorurilor de probabilitate pe care modelul de limbă le indică pentru n-grame din setul corespunzător de n-grame care sunt mapate la starea de dialog particulară
- Transcrierea intrării vocale folosind modelul de limbaj părtinitor.
Determinarea stărilor de dialog pentru modelele de limbaj
Inventatori: Petar Aleksic și Pedro J. Moreno Mengibar
Cesionar: Google LLC
Brevet SUA: 11.264.028
Acordat: 1 martie 2022
Depus: 2 ianuarie 2020
Abstract
Sisteme, metode, dispozitive și alte tehnici sunt descrise aici pentru determinarea stărilor de dialog care corespund intrărilor vocale și pentru polarizarea unui model de limbaj pe baza stărilor de dialog determinate. în unele implementări, o metodă include recepţionarea, la un sistem de calcul, a datelor audio care indică o intrare vocală şi determinarea unei anumite stări de dialog, dintr-o multitudine de stări de dialog, care corespunde intrării vocale. Se poate identifica un set de n-grame care sunt asociate cu starea de dialog particulară care corespunde intrării vocale. Ca răspuns la identificarea setului de n-grame care sunt asociate cu starea de dialog particulară care corespunde intrării vocale, un model de limbă poate fi părtinit prin ajustarea scorurilor de probabilitate pe care modelul de limbă le indică pentru n-grame din setul de n-grame. grame. Intrarea vocală poate fi transcrisă folosind modelul de limbă ajustat.
Căutați știri direct în căsuța dvs. de e-mail
*Necesar