
Bestimmen von Dialogzuständen für Sprachmodelle aktualisiert
Veröffentlicht: 2022-03-16Die ersten Behauptungen zur Bestimmung von Dialogzuständen für Sprachmodelle
Die Chancen stehen gut, dass Sie Patente für den Mensch-Computer-Dialog von Google gesehen haben. Ich habe in der Vergangenheit über einige geschrieben. Hier sind zwei, die viele Details zu einem solchen Dialog liefern:
- Mensch-Computer-Dialog bei Google
- Unerwünschte Inhalte im Mensch-zu-Computer-Dialog
Neben der sorgfältigen Betrachtung von Patenten, die den Dialog zwischen Mensch und Computer betreffen, lohnt es sich, Zeit mit der Verarbeitung natürlicher Sprache und der Kommunikation zwischen Menschen und Computern zu verbringen. Über einige habe ich auch schon geschrieben. Hier sind ein paar davon:
- Der Google Assistant und die kontextbasierte Verarbeitung natürlicher Sprache
- Abfrageantworten in natürlicher Sprache
Dieses Google-Patent zur Bestimmung von Dialogzuständen für Sprachmodelle wurde jetzt zweimal aktualisiert, wobei die neueste Version Anfang dieser Woche erteilt wurde. Die letzte erste Behauptung ist etwas länger und hat einige neue Wörter hinzugefügt.
Idealerweise müssen diese Patente mit einem tiefen Blick auf die Sprache der Ansprüche beginnen.
Die am 18. Februar 2018 eingereichte und am 4. Februar 2020 erteilte zweite Version von Determining dialog states for language models beginnt mit dem folgenden Anspruch:
- Was behauptet wird ist:
- 1. Computerimplementiertes Verfahren, umfassend:
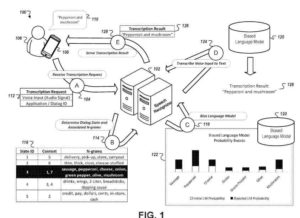
- Empfangen von Audiodaten für eine Spracheingabe in das Computergerät durch ein Computergerät, wobei die Spracheingabe einer unbekannten Stufe eines mehrstufigen Sprachdialogs zwischen dem Computergerät und einem Benutzer des Computergeräts entspricht
- Bestimmen einer anfänglichen Vorhersage für die unbekannte Stufe des mehrstufigen Sprachdialogs
Bereitstellen, durch das Computergerät und an ein Sprachdialogsystem,- (i) die Audiodaten für die Spracheingabe in das Computergerät und
- (ii) eine Angabe der Anfangsvorhersage für die unbekannte Stufe des mehrstufigen Sprachdialogs
- Empfangen einer Transkription der Spracheingabe durch das Computergerät und von dem Sprachdialogsystem, wobei die Transkription durch Verarbeiten der Audiodaten mit einem Modell erzeugt wurde, das gemäß Parametern, die einer verfeinerten Vorhersage für das unbekannte Stadium von entsprechen, voreingenommen wurde den mehrstufigen Sprachdialog, wobei das Sprachdialogsystem konfiguriert ist zum Bestimmen der verfeinerten Vorhersage für die unbekannte Stufe des mehrstufigen Sprachdialogs basierend auf (i) der anfänglichen Vorhersage für die unbekannte Stufe des mehrstufigen Sprachdialogs und
- (ii) Zusatzinformationen, die einen Kontext der Spracheingabe beschreiben, und wobei die Zusatzinformationen, die den Kontext der Spracheingabe beschreiben, inhaltsunabhängig sind
- die Spracheingabe; und Präsentieren der Transkription der Spracheingabe mit dem Computergerät.
Die erste Version dieses Fortsetzungspatents, Bestimmung von Dialogzuständen für Sprachmodelle, eingereicht am 16. März 2016 und erteilt am 22. Mai 2018, beginnt mit diesem Anspruch:
- Was behauptet wird ist:
- 1. Computerimplementiertes Verfahren, umfassend:
- Empfangen von Audiodaten an einem Computersystem, die eine erste Spracheingabe angeben, die einem Computergerät bereitgestellt wurde
- Bestimmen, dass die erste Spracheingabe Teil eines Sprachdialogs ist, der mehrere vordefinierte Dialogzustände enthält, die zum Empfangen einer Reihe von Spracheingaben in Bezug auf eine bestimmte Aufgabe angeordnet sind, wobei jeder Dialogzustand abgebildet ist auf: (i) einen Satz von Daten anzuzeigen, die den Inhalt charakterisieren, der zur Anzeige bestimmt ist, wenn Spracheingaben für den Dialogzustand empfangen werden, und
(ii) ein Satz von n-Grammen - Empfangen von ersten Anzeigedaten am Computersystem, die Inhalt charakterisieren, der auf einem Bildschirm des Computergeräts angezeigt wurde, als die erste Spracheingabe an dem Computergerät bereitgestellt wurde; Auswählen eines bestimmten Dialogzustands aus der Vielzahl von vordefinierten Dialogzuständen, der der ersten Spracheingabe entspricht, durch das Computersystem, einschließlich Bestimmen einer Übereinstimmung zwischen den ersten Anzeigedaten und dem entsprechenden Satz von Anzeigedaten, der dem bestimmten zugeordnet ist Dialogzustand; Beeinflussen eines Sprachmodells durch Anpassen von Wahrscheinlichkeitsbewertungen, die das Sprachmodell für n-Gramme in dem entsprechenden Satz von n-Grammen angibt, die dem bestimmten Dialogzustand zugeordnet sind; und Transkribieren der Spracheingabe unter Verwendung des voreingenommenen Sprachmodells.
Der jüngste erste Anspruch in der neuesten Version dieses Patents, Bestimmung von Dialogzuständen für Sprachmodelle, wurde am 2. Januar 2020 eingereicht und am 1. März 2022 erteilt. Er sagt uns:
- Was behauptet wird ist:
- 1. Computerimplementiertes Verfahren, umfassend:
- Erhalten von Transkriptionen von Spracheingaben aus einem Trainingssatz von Spracheingaben, wobei jede Spracheingabe in dem Trainingssatz von Spracheingaben zu einer von mehreren Stufen einer mehrstufigen Sprachaktivität geleitet wird
- Erhalten von Anzeigedaten, die jeder Spracheingabe zugeordnet sind, aus dem Trainingssatz von Spracheingaben, die Inhalt charakterisieren, der zur Anzeige bestimmt ist, wenn die zugeordnete Spracheingabe empfangen wird; Erzeugen mehrerer Gruppen von Transkriptionen, wobei jede Gruppe von Transkriptionen eine andere Teilmenge der Transkriptionen von Spracheingaben aus dem Trainingssatz von Spracheingaben enthält
- Zuordnen jeder Gruppe von Transkriptionen zu einem anderen Dialogzustand eines Dialogzustandsmodells, das eine Vielzahl von Dialogzuständen enthält, wobei jeder Dialogzustand der Vielzahl von Dialogzuständen: einer anderen Stufe der mehrstufigen Sprachaktivität entspricht; und auf einen jeweiligen Satz von Anzeigedaten abgebildet wird, die Inhalt charakterisieren, der zur Anzeige bestimmt ist, wenn Spracheingaben aus dem Trainingssatz von Spracheingaben, die der Gruppe von Transkriptionen zugeordnet sind, die dem Dialogzustand zugeordnet sind, empfangen werden; für jede Gruppe von Transkriptionen, Bestimmen eines repräsentativen Satzes von n-Grammen für die Gruppe und Zuordnen des repräsentativen Satzes von n-Grammen für die Gruppe zu dem entsprechenden Dialogzustand des Dialogzustandsmodells, dem die Gruppe zugeordnet ist, wobei die ein repräsentativer Satz von n-Grammen, der für die Gruppe von Transkriptionen bestimmt wird, n-Gramme umfasst, die eine Schwellenanzahl von Vorkommen in der Gruppe von Transkriptionen erfüllen, die dem Dialogzustand des Dialogzustandsmodells zugeordnet sind
- Empfangen einer nachfolgenden Spracheingabe und erster Anzeigedaten, die Inhalt charakterisieren, der auf einem Bildschirm angezeigt wurde, als die nachfolgende Spracheingabe empfangen wurde, wobei die nachfolgende Spracheingabe auf eine bestimmte Stufe der mehrstufigen Sprachaktivität gerichtet ist
Bestimmen einer Übereinstimmung zwischen den ersten Anzeigedaten und dem jeweiligen Satz von Anzeigedaten, die dem Dialogzustand in dem Dialogzustandsmodell zugeordnet sind, der der bestimmten Stufe der Mehrstimmigkeitsaktivität entspricht - Verarbeiten der nachfolgenden Spracheingabe und der ersten Anzeigedaten mit einem Spracherkenner, einschließlich Beeinflussen des Spracherkenners unter Verwendung des repräsentativen Satzes von n-Grammen, die dem Dialogzustand in dem Dialogzustandsmodell zugeordnet sind, der der bestimmten Stufe des entspricht mehrstimmige Aktivität
\
Vergleich der Ansprüche der bestimmenden Dialogzustände für Sprachmodelle
Dies sind einige der Unterschiede, die ich bei den verschiedenen Versionen des Patents sehe:

1. Alle drei Versionen sagen uns, dass es sich um „Spracheingaben“ handelt, die als Teil eines Trainingssets fungieren.
Im Gegensatz zu den vorherigen Patenten über Dialogzustände zwischen Menschen und Computern, die sich auf den Inhalt des Dialogs konzentrierten, befasst sich dieses Patent in erster Linie mit der verbalen Sprache und tatsächlichen Spracheingaben.
2. Die zweite und dritte Version des Patents beschreiben das Zerlegen von Transkripten der Spracheingaben in Ngrams, was bei der Berechnung von Statistiken über das Auftreten der verwendeten Spracheingaben hilfreich sein kann.
3. Der Anspruch der neuesten und dritten Version des Patents zur Bestimmung von Dialogzuständen für Sprachmodelle erwähnt die Verwendung eines Geschwindigkeitserkenners.
- Was behauptet wird ist:
- 1. Computerimplementiertes Verfahren, umfassend: Empfangen von Audiodaten, die eine erste Spracheingabe angeben, die einer Computervorrichtung bereitgestellt wurde, an einem Computersystem; Bestimmen, dass die erste Spracheingabe Teil eines Sprachdialogs ist, der eine Vielzahl von vordefinierten Dialogzuständen enthält, die so angeordnet sind, dass sie eine Reihe von Spracheingaben empfangen, die sich auf eine bestimmte Aufgabe beziehen, wobei jeder Dialogzustand abgebildet ist auf:
- (i) einen Satz von Anzeigedaten, die den Inhalt charakterisieren, der zur Anzeige bestimmt ist, wenn Spracheingaben für den Dialogzustand empfangen werden, und
- (ii) ein Satz von n-Grammen; Empfangen von ersten Anzeigedaten an dem Computersystem, die Inhalt charakterisieren, der auf einem Bildschirm des Computergeräts angezeigt wurde, als die erste Spracheingabe an dem Computergerät bereitgestellt wurde
- Auswählen eines bestimmten Dialogzustands aus der Vielzahl von vordefinierten Dialogzuständen, der der ersten Spracheingabe entspricht, durch das Computersystem, einschließlich Bestimmen einer Übereinstimmung zwischen den ersten Anzeigedaten und dem entsprechenden Satz von Anzeigedaten, der dem bestimmten zugeordnet ist Dialogzustand
- Beeinflussen eines Sprachmodells durch Anpassen von Wahrscheinlichkeitsbewertungen, die das Sprachmodell für n-Gramme in dem entsprechenden Satz von n-Grammen angibt, die dem bestimmten Dialogzustand zugeordnet sind
- Transkribieren der Spracheingabe unter Verwendung des voreingenommenen Sprachmodells.
Bestimmen von Dialogzuständen für Sprachmodelle
Erfinder: Petar Aleksic und Pedro J. Moreno Mengibar
Zessionar: Google LLC
US-Patent: 11.264.028
Gewährt: 1. März 2022
Eingereicht: 2. Januar 2020
Abstrakt
Systeme, Verfahren, Geräte und andere Techniken werden hierin beschrieben, um Dialogzustände zu bestimmen, die Spracheingaben entsprechen, und um ein Sprachmodell basierend auf den bestimmten Dialogzuständen zu beeinflussen. In einigen Implementierungen umfasst ein Verfahren das Empfangen von Audiodaten, die eine Spracheingabe angeben, und das Bestimmen eines bestimmten Dialogzustands aus einer Vielzahl von Dialogzuständen, der der Spracheingabe entspricht, an einem Computersystem. Ein Satz von N-Grammen kann identifiziert werden, die dem bestimmten Dialogzustand zugeordnet sind, der der Spracheingabe entspricht. Als Reaktion auf das Identifizieren des Satzes von n-Grammen, die dem bestimmten Dialogzustand zugeordnet sind, der der Spracheingabe entspricht, kann ein Sprachmodell voreingenommen werden, indem Wahrscheinlichkeitswerte angepasst werden, die das Sprachmodell für n-Gramme in dem Satz von n- Gramm. Die Spracheingabe kann mit dem angepassten Sprachmodell transkribiert werden.
Suchen Sie Nachrichten direkt in Ihren Posteingang
*Erforderlich