
การกำหนดสถานะไดอะล็อกสำหรับแบบจำลองภาษา อัปเดต
เผยแพร่แล้ว: 2022-03-16การอ้างสิทธิ์ครั้งแรกในการกำหนดสถานะไดอะล็อกสำหรับแบบจำลองภาษา
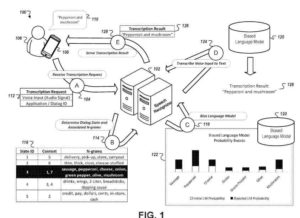
มีโอกาสที่คุณจะได้เห็นสิทธิบัตรการโต้ตอบระหว่างมนุษย์กับคอมพิวเตอร์จาก Google ผมเคยเขียนถึงบางเรื่องในอดีต ต่อไปนี้คือสองรายละเอียดที่ให้รายละเอียดมากมายเกี่ยวกับกล่องโต้ตอบดังกล่าว:
- มนุษย์กับคอมพิวเตอร์กล่องโต้ตอบที่ Google
- เนื้อหาที่ไม่พึงประสงค์ในกล่องโต้ตอบระหว่างมนุษย์กับคอมพิวเตอร์
นอกเหนือจากการพิจารณาสิทธิบัตรที่เกี่ยวข้องกับการโต้ตอบระหว่างมนุษย์กับคอมพิวเตอร์อย่างรอบคอบแล้ว ยังคุ้มค่าที่จะใช้เวลากับการประมวลผลภาษาธรรมชาติ และการสื่อสารระหว่างมนุษย์กับคอมพิวเตอร์ ฉันยังเขียนเกี่ยวกับบางส่วนเหล่านั้น นี่คือคู่ของพวกเขา:
- Google Assistant และการประมวลผลภาษาธรรมชาติตามบริบท
- การตอบแบบสอบถามภาษาธรรมชาติ
สิทธิบัตร Google Determining Dialog States For Language Models ได้รับการอัปเดตสองครั้งแล้ว โดยเวอร์ชันล่าสุดจะได้รับเมื่อต้นสัปดาห์นี้ การอ้างสิทธิ์ครั้งแรกครั้งสุดท้ายจะยาวขึ้นเล็กน้อยและมีคำใหม่เพิ่มเข้าไป
ตามหลักการแล้ว สิทธิบัตรเหล่านี้ต้องเริ่มต้นด้วยการมองลึกถึงภาษาของการอ้างสิทธิ์
เวอร์ชันที่สองของการระบุสถานะกล่องโต้ตอบสำหรับแบบจำลองภาษา ยื่นเมื่อวันที่ 18 2018 และได้รับวันที่ 4 กุมภาพันธ์ 2020 เริ่มต้นด้วยการอ้างสิทธิ์ต่อไปนี้:
- สิ่งที่อ้างสิทธิ์คือ:
- 1. วิธีการดำเนินการด้วยคอมพิวเตอร์ ซึ่งประกอบด้วย
- การรับข้อมูลเสียงสำหรับการป้อนข้อมูลด้วยเสียงไปยังอุปกรณ์คำนวณโดยอุปกรณ์คอมพิวเตอร์ โดยที่การป้อนข้อมูลด้วยเสียงจะสอดคล้องกับขั้นตอนที่ไม่รู้จักของกล่องโต้ตอบเสียงแบบหลายขั้นตอนระหว่างอุปกรณ์คอมพิวเตอร์กับผู้ใช้อุปกรณ์คอมพิวเตอร์
- กำหนดคำทำนายเบื้องต้นสำหรับระยะที่ไม่รู้จักของกล่องโต้ตอบเสียงแบบหลายขั้นตอน
โดยอุปกรณ์คอมพิวเตอร์และระบบโต้ตอบด้วยเสียง- (i) ข้อมูลเสียงสำหรับการป้อนข้อมูลด้วยเสียงไปยังอุปกรณ์คอมพิวเตอร์และ
- (ii) ข้อบ่งชี้ของการทำนายเบื้องต้นสำหรับระยะที่ไม่รู้จักของกล่องโต้ตอบเสียงแบบหลายขั้นตอน
- การรับโดยอุปกรณ์คอมพิวเตอร์และจากระบบสนทนาด้วยเสียง การถอดเสียงอินพุตเสียง ซึ่งการถอดความถูกสร้างขึ้นโดยการประมวลผลข้อมูลเสียงด้วยแบบจำลองที่มีความเอนเอียงตามพารามิเตอร์ที่สอดคล้องกับการคาดการณ์อย่างละเอียดสำหรับขั้นตอนที่ไม่รู้จักของ ไดอะล็อกเสียงแบบหลายขั้นตอน ซึ่งระบบไดอะล็อกเสียงได้รับการกำหนดค่าเพื่อกำหนดการคาดการณ์ขั้นสูงสำหรับสเตจที่ไม่รู้จักของไดอะล็อกเสียงแบบหลายขั้นตอนตาม (i) การคาดคะเนเริ่มต้นสำหรับสเตจที่ไม่รู้จักของไดอะล็อกเสียงแบบหลายขั้นตอนและ
- (ii) ข้อมูลเพิ่มเติมที่อธิบายบริบทของการป้อนข้อมูลด้วยเสียง และที่ซึ่งข้อมูลเพิ่มเติมที่อธิบายบริบทของการป้อนข้อมูลด้วยเสียงนั้นไม่ขึ้นกับเนื้อหาของ
- อินพุตเสียง; และนำเสนอการถอดเสียงอินพุตด้วยอุปกรณ์คอมพิวเตอร์
รุ่นแรกของสิทธิบัตรความต่อเนื่องนี้ การกำหนดสถานะกล่องโต้ตอบสำหรับแบบจำลองภาษา ยื่นเมื่อวันที่ 16 มีนาคม 2016 และได้รับวันที่ 22 พฤษภาคม 2018 เริ่มต้นด้วยการอ้างสิทธิ์นี้:
- สิ่งที่อ้างสิทธิ์คือ:
- 1. วิธีการดำเนินการด้วยคอมพิวเตอร์ ซึ่งประกอบด้วย
- การรับที่ระบบคอมพิวเตอร์ ข้อมูลเสียงที่ระบุการป้อนข้อมูลด้วยเสียงครั้งแรกที่จัดเตรียมให้กับอุปกรณ์คอมพิวเตอร์
- การพิจารณาว่าการป้อนข้อมูลด้วยเสียงครั้งแรกเป็นส่วนหนึ่งของกล่องโต้ตอบเสียงที่มีสถานะการโต้ตอบที่กำหนดไว้ล่วงหน้าจำนวนหนึ่งซึ่งจัดเรียงเพื่อรับชุดของอินพุตเสียงที่เกี่ยวข้องกับงานเฉพาะ โดยที่แต่ละสถานะการโต้ตอบจะถูกจับคู่กับ: (i) ชุดของ แสดงข้อมูลลักษณะเนื้อหาที่กำหนดไว้สำหรับการแสดงผลเมื่อได้รับอินพุตเสียงสำหรับสถานะการโต้ตอบและ
(ii) ชุดของ n-grams - การรับที่ระบบคอมพิวเตอร์ ขั้นแรกจะแสดงข้อมูลที่แสดงลักษณะเนื้อหาที่แสดงบนหน้าจอของอุปกรณ์คอมพิวเตอร์เมื่อมีการป้อนข้อมูลด้วยเสียงครั้งแรกให้กับอุปกรณ์คอมพิวเตอร์ การเลือกโดยระบบคำนวณ สถานะการโต้ตอบเฉพาะของสถานะกล่องโต้ตอบที่กำหนดไว้ล่วงหน้าจำนวนหนึ่งซึ่งสอดคล้องกับอินพุตเสียงแรก รวมถึงการพิจารณาการจับคู่ระหว่างข้อมูลที่แสดงครั้งแรกกับชุดข้อมูลการแสดงผลที่สอดคล้องกันซึ่งจับคู่กับข้อมูลเฉพาะ สถานะการโต้ตอบ การให้น้ำหนักแบบจำลองภาษาโดยการปรับคะแนนความน่าจะเป็นที่แบบจำลองภาษาระบุสำหรับ n-grams ในชุดของ n-gram ที่สอดคล้องกันซึ่งถูกแมปกับสถานะการโต้ตอบเฉพาะ และถอดเสียงการป้อนข้อมูลด้วยเสียงโดยใช้แบบจำลองภาษาลำเอียง
การอ้างสิทธิ์ครั้งแรกครั้งล่าสุดในเวอร์ชันล่าสุดของสิทธิบัตรนี้ การกำหนดสถานะกล่องโต้ตอบสำหรับแบบจำลองภาษา ถูกยื่นฟ้องเมื่อวันที่ 2 มกราคม 2020 และได้รับสิทธิ์ในวันที่ 1 มีนาคม 2022 โดยบอกเราว่า:
- สิ่งที่อ้างสิทธิ์คือ:
- 1. วิธีการดำเนินการด้วยคอมพิวเตอร์ ซึ่งประกอบด้วย
- รับการถอดเสียงอินพุตเสียงจากชุดการฝึกของอินพุตเสียง โดยแต่ละอินพุตเสียงในชุดฝึกของอินพุตเสียงจะถูกส่งไปยังหนึ่งในหลายขั้นตอนของกิจกรรมเสียงแบบหลายขั้นตอน
- การรับข้อมูลการแสดงผลที่เกี่ยวข้องกับอินพุตเสียงแต่ละรายการจากชุดการฝึกของอินพุตเสียงที่กำหนดลักษณะเนื้อหาที่กำหนดไว้สำหรับการแสดงผลเมื่อได้รับอินพุตเสียงที่เกี่ยวข้อง การสร้างกลุ่มของการถอดความจำนวนมาก โดยที่แต่ละกลุ่มการถอดความประกอบด้วยชุดย่อยที่แตกต่างกันของการถอดความของอินพุตเสียงจากชุดการฝึกของอินพุตเสียง
- การกำหนดแต่ละกลุ่มของการถอดความให้กับสถานะการสนทนาที่แตกต่างกันของแบบจำลองสถานะการโต้ตอบที่มีสถานะการโต้ตอบจำนวนมาก โดยที่แต่ละสถานะการโต้ตอบของสถานะการสนทนาส่วนใหญ่: สอดคล้องกับขั้นตอนที่แตกต่างกันของกิจกรรมเสียงแบบหลายขั้นตอน และถูกแมปกับชุดของเนื้อหาที่แสดงลักษณะข้อมูลที่แสดงซึ่งกำหนดไว้สำหรับแสดงผลเมื่อได้รับอินพุตเสียงจากชุดการฝึกของอินพุตเสียงที่เกี่ยวข้องกับกลุ่มการถอดเสียงเป็นคำที่กำหนดให้กับสถานะการโต้ตอบ สำหรับแต่ละกลุ่มของการถอดความ กำหนดชุดตัวแทนของ n-grams สำหรับกลุ่ม และเชื่อมโยงชุดตัวแทนของ n-grams สำหรับกลุ่มกับสถานะการโต้ตอบที่สอดคล้องกันของแบบจำลองสถานะไดอะล็อกที่กลุ่มได้รับมอบหมาย โดยที่ ชุดตัวแทนของ n-grams ที่กำหนดสำหรับกลุ่มของการถอดความประกอบด้วย n-grams- ตอบสนองจำนวนเกณฑ์ที่เกิดขึ้นในกลุ่มของการถอดความที่กำหนดให้กับสถานะไดอะล็อกของแบบจำลองสถานะไดอะล็อก
- การรับอินพุตเสียงที่ตามมาและการแสดงข้อมูลที่แสดงครั้งแรกของเนื้อหาที่แสดงบนหน้าจอเมื่อได้รับการป้อนข้อมูลด้วยเสียงที่ตามมา การป้อนข้อมูลด้วยเสียงที่ตามมาจะมุ่งไปยังขั้นตอนเฉพาะของกิจกรรมเสียงแบบหลายขั้นตอน
การระบุการจับคู่ระหว่างข้อมูลที่แสดงครั้งแรกกับชุดข้อมูลการแสดงผลที่แมปกับสถานะไดอะล็อกในแบบจำลองสถานะไดอะล็อกที่สอดคล้องกับขั้นตอนเฉพาะของกิจกรรมหลายเสียง - การประมวลผลด้วยโปรแกรมจดจำคำพูด การป้อนข้อมูลด้วยเสียงที่ตามมา และข้อมูลที่แสดงครั้งแรก รวมถึงการให้น้ำหนักตัวรู้จำเสียงพูดโดยใช้ชุดตัวแทนของ n-grams ที่เกี่ยวข้องกับสถานะการโต้ตอบในแบบจำลองสถานะการโต้ตอบที่สอดคล้องกับขั้นตอนเฉพาะของ กิจกรรมหลายเสียง
\
การเปรียบเทียบการอ้างสิทธิ์ของการกำหนดสถานะไดอะล็อกสำหรับแบบจำลองภาษา
นี่คือความแตกต่างบางอย่างที่ฉันเห็นในสิทธิบัตรเวอร์ชันต่างๆ:

1. ทั้งสามเวอร์ชันบอกเราว่าเกี่ยวกับ "อินพุตเสียง" ซึ่งเป็นส่วนหนึ่งของชุดการฝึก
สิทธิบัตรนี้ไม่เหมือนกับสิทธิบัตรก่อนหน้าเกี่ยวกับสถานะของ Dialog ระหว่างมนุษย์กับคอมพิวเตอร์ ซึ่งเน้นที่เนื้อหาของบทสนทนา สิทธิบัตรนี้เน้นที่ภาษาวาจาและการป้อนข้อมูลด้วยเสียงจริงเป็นหลัก
2. สิทธิบัตรรุ่นที่สองและสามอธิบายการถอดเสียงอินพุตเสียงออกเป็น ngram ซึ่งอาจเป็นประโยชน์ในการคำนวณสถิติเกี่ยวกับการเกิดขึ้นของอินพุตเสียงที่ใช้
3. การอ้างสิทธิ์ในเวอร์ชันล่าสุดและเวอร์ชันที่สามของสถานะกล่องโต้ตอบการยุติสิทธิบัตรสำหรับแบบจำลองภาษากล่าวถึงการใช้ตัวจดจำความเร็ว
- สิ่งที่อ้างสิทธิ์คือ:
- 1. วิธีการแบบใช้คอมพิวเตอร์ ประกอบด้วย: การรับ ที่ระบบคอมพิวเตอร์ ข้อมูลเสียงที่ระบุการป้อนข้อมูลด้วยเสียงครั้งแรกที่จัดเตรียมให้กับอุปกรณ์คอมพิวเตอร์ การพิจารณาว่าการป้อนข้อมูลด้วยเสียงครั้งแรกเป็นส่วนหนึ่งของกล่องโต้ตอบเสียงที่มีสถานะการโต้ตอบที่กำหนดไว้ล่วงหน้าจำนวนหนึ่งซึ่งจัดเรียงเพื่อรับชุดของอินพุตเสียงที่เกี่ยวข้องกับงานใดงานหนึ่ง โดยที่แต่ละสถานะการโต้ตอบจะถูกจับคู่กับ:
- (i) ชุดของข้อมูลการแสดงผลที่แสดงลักษณะเนื้อหาที่กำหนดไว้สำหรับการแสดงผลเมื่อได้รับอินพุตเสียงสำหรับสถานะการโต้ตอบ และ
- (ii) ชุดของ n-grams; การรับที่ระบบคอมพิวเตอร์จะแสดงข้อมูลที่เป็นลักษณะเฉพาะของเนื้อหาที่แสดงบนหน้าจอของอุปกรณ์คอมพิวเตอร์ก่อน เมื่อป้อนข้อมูลด้วยเสียงครั้งแรกไปยังอุปกรณ์คอมพิวเตอร์
- การเลือกโดยระบบคำนวณ สถานะกล่องโต้ตอบเฉพาะของสถานะกล่องโต้ตอบที่กำหนดไว้ล่วงหน้าจำนวนหนึ่งซึ่งสอดคล้องกับอินพุตเสียงแรก รวมถึงการกำหนดการจับคู่ระหว่างข้อมูลที่แสดงครั้งแรกกับชุดข้อมูลการแสดงผลที่สอดคล้องกันซึ่งจับคู่กับข้อมูลเฉพาะ สถานะกล่องโต้ตอบ
- การให้น้ำหนักแบบจำลองภาษาโดยการปรับคะแนนความน่าจะเป็นที่แบบจำลองภาษาระบุสำหรับ n-grams ในชุดของ n-gram ที่สอดคล้องกันซึ่งถูกแมปกับสถานะการโต้ตอบเฉพาะ
- การถอดเสียงการป้อนข้อมูลด้วยเสียงโดยใช้แบบจำลองภาษาลำเอียง
การกำหนดสถานะไดอะล็อกสำหรับโมเดลภาษา
ผู้ประดิษฐ์: Petar Aleksic และ Pedro J. Moreno Mengibar
ผู้รับมอบหมาย: Google LLC
สิทธิบัตรสหรัฐอเมริกา: 11,264,028
ได้รับ: 1 มีนาคม 2022
ยื่น: 2 มกราคม 2020
เชิงนามธรรม
ระบบ วิธีการ อุปกรณ์ และเทคนิคอื่นๆ ได้อธิบายไว้ในที่นี้เพื่อกำหนดสถานะไดอะล็อกที่สอดคล้องกับอินพุตเสียงและสำหรับการให้น้ำหนักโมเดลภาษาตามสถานะไดอะล็อกที่กำหนด ในการใช้งานบางอย่าง วิธีการรวมถึงการรับข้อมูลเสียงที่ระบบคอมพิวเตอร์ซึ่งระบุการป้อนข้อมูลด้วยเสียงและการกำหนดสถานะการโต้ตอบเฉพาะจากสถานะการสนทนาส่วนใหญ่ซึ่งสอดคล้องกับการป้อนข้อมูลด้วยเสียง สามารถระบุชุดของ n-gram ที่เกี่ยวข้องกับสถานะการโต้ตอบเฉพาะที่สอดคล้องกับการป้อนข้อมูลด้วยเสียง เพื่อตอบสนองต่อการระบุชุดของ n-gram ที่เกี่ยวข้องกับสถานะการโต้ตอบเฉพาะที่สอดคล้องกับการป้อนข้อมูลด้วยเสียง โมเดลภาษาสามารถลำเอียงได้โดยการปรับคะแนนความน่าจะเป็นที่แบบจำลองภาษาระบุสำหรับ n-grams ในชุดของ n- กรัม การป้อนข้อมูลด้วยเสียงสามารถถอดเสียงได้โดยใช้รูปแบบภาษาที่ปรับแล้ว
ค้นหาข่าวตรงไปยังกล่องจดหมายของคุณ
*ที่จำเป็น