
Определение состояний диалога для языковых моделей обновлено
Опубликовано: 2022-03-16Первые утверждения об определении состояний диалога для языковых моделей
Скорее всего, вы видели патенты на диалог человека с компьютером от Google. О некоторых я уже писал. Вот два, которые предоставляют много деталей о таком диалоге:
- Диалог человека с компьютером в Google
- Нежелательный контент в диалоге человека с компьютером
В дополнение к внимательному рассмотрению патентов, связанных с диалогом человека с компьютером, стоит уделить время обработке естественного языка и общению между людьми и компьютерами. Я также писал о некоторых из них. Вот некоторые из них:
- Google Assistant и контекстная обработка естественного языка
- Ответы на запросы на естественном языке
Этот патент Google, определяющий состояния диалога для языковых моделей, уже дважды обновлялся, последняя версия была предоставлена ранее на этой неделе. Последнее первое утверждение немного длиннее и к нему добавлено несколько новых слов.
В идеале эти патенты должны начинаться с глубокого изучения языка формулы изобретения.
Вторая версия определения состояний диалога для языковых моделей, поданная 18 февраля 2018 г. и предоставленная 4 февраля 2020 г., начинается со следующего утверждения:
- Что заявлено:
- 1. Реализуемый компьютером способ, включающий:
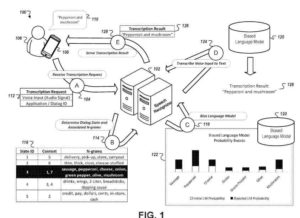
- Прием вычислительным устройством аудиоданных для речевого ввода в вычислительное устройство, при этом речевой ввод соответствует неизвестному этапу многоэтапного речевого диалога между вычислительным устройством и пользователем вычислительного устройства
- Определение начального прогноза для неизвестного этапа многоэтапного голосового диалога
Обеспечение, вычислительным устройством и системой голосового диалога,- (i) аудиоданные для голосового ввода в вычислительное устройство и
- (ii) указание начального прогноза для неизвестного этапа многоэтапного голосового диалога
- Прием вычислительным устройством и системой голосового диалога транскрипции голосового ввода, при этом транскрипция была сгенерирована путем обработки аудиоданных с помощью модели, которая была смещена в соответствии с параметрами, которые соответствуют уточненному прогнозу для неизвестной стадии многоэтапный речевой диалог, при этом система речевого диалога сконфигурирована для определения уточненного прогноза для неизвестного этапа многоэтапного речевого диалога на основе (i) начального прогноза для неизвестного этапа многоэтапного речевого диалога и
- (ii) дополнительная информация, описывающая контекст голосового ввода, причем дополнительная информация, описывающая контекст голосового ввода, не зависит от содержания
- голосовой ввод; и представление транскрипции голосового ввода с помощью вычислительного устройства.
Первая версия этого продолженного патента «Определение состояний диалога для языковых моделей», поданного 16 марта 2016 г. и выданного 22 мая 2018 г., начинается с этого утверждения:
- Что заявлено:
- 1. Реализуемый компьютером способ, включающий:
- Прием в вычислительной системе аудиоданных, указывающих на первый голосовой ввод, который был предоставлен вычислительному устройству.
- Определение того, что первый голосовой ввод является частью голосового диалога, который включает в себя множество предопределенных состояний диалога, предназначенных для приема ряда голосовых вводов, связанных с конкретной задачей, при этом каждое состояние диалога отображается в: (i) набор отображать данные, характеризующие содержимое, предназначенное для отображения, когда принимаются голосовые вводы для состояния диалога, и
(ii) набор n-грамм - прием в вычислительной системе первых отображаемых данных, которые характеризуют контент, который отображался на экране вычислительного устройства, когда первый речевой ввод был предоставлен вычислительному устройству; выбор компьютерной системой конкретного состояния диалога из множества предварительно определенных состояний диалога, которое соответствует первому голосовому вводу, включая определение соответствия между первыми данными отображения и соответствующим набором данных отображения, который отображается на конкретный состояние диалога; смещение языковой модели путем корректировки показателей вероятности, которые языковая модель указывает для n-грамм в соответствующем наборе n-грамм, которые отображаются на конкретное состояние диалога; и расшифровка голосового ввода с использованием предвзятой языковой модели.
Самая последняя первая заявка в последней версии этого патента «Определение состояний диалога для языковых моделей» была подана 2 января 2020 г. и удовлетворена 1 марта 2022 г. В нем говорится:
- Что заявлено:
- 1. Реализуемый компьютером способ, включающий:
- Получение транскрипций речевых вводов из обучающего набора речевых вводов, при этом каждый речевой ввод в обучающем наборе речевых вводов направляется на один из множества этапов многоэтапной голосовой активности.
- получение данных отображения, связанных с каждым речевым вводом, из обучающего набора речевых вводов, которые характеризуют контент, предназначенный для отображения, когда принимается соответствующий речевой ввод; создание множества групп транскрипций, при этом каждая группа транскрипций включает в себя различные подмножества транскрипций голосовых вводов из обучающего набора голосовых вводов
- Присвоение каждой группе транскрипций различному состоянию диалога модели состояний диалога, которая включает в себя множество состояний диалога, при этом каждое состояние диалога из множества состояний диалога: соответствует другому этапу многоэтапной голосовой активности; и сопоставляется с соответствующим набором данных отображения, характеризующих контент, предназначенный для отображения, когда принимаются речевые вводы из обучающего набора речевых вводов, которые связаны с группой транскрипций, назначенных для состояния диалога; для каждой группы транскрипций определение репрезентативного набора n-грамм для группы и связывание репрезентативного набора n-грамм для группы с соответствующим состоянием диалога модели состояния диалога, которой назначена группа, при этом репрезентативный набор n-грамм, определенный для группы транскрипций, включает n-граммы, удовлетворяющие пороговому количеству вхождений в группе транскрипций, назначенных диалоговому состоянию модели диалогового состояния
- Получение последующего речевого ввода и первого отображения данных, характеризующих контент, который отображался на экране при получении последующего речевого ввода, причем последующий речевой ввод направлен на определенный этап многоэтапной голосовой активности.
Определение соответствия между первыми данными отображения и соответствующим набором данных отображения, сопоставленным с состоянием диалога в модели состояния диалога, которая соответствует конкретному этапу многоголосовой активности. - Обработка с помощью распознавателя речи последующего голосового ввода и данных первого отображения, включая смещение распознавателя речи с использованием репрезентативного набора n-грамм, связанных с состоянием диалога в модели состояния диалога, которая соответствует конкретному этапу многоголосая активность
\
Сравнение утверждений определяющих состояний диалога для языковых моделей
Вот некоторые из различий, которые я вижу в разных версиях патента:

1. Все три версии говорят нам, что речь идет о «голосовом вводе», который действует как часть обучающего набора.
Таким образом, в отличие от предыдущих патентов о состояниях диалога между людьми и компьютерами, которые были сосредоточены на содержании диалога, этот патент в первую очередь рассматривает вербальный язык и реальный голосовой ввод.
2. Вторая и третья версии патента описывают разбиение расшифровок голосовых вводов на энграммы, что может быть полезно при подсчете статистики об использовании голосовых вводов.
3. В заявлении новейшей и третьей версии Патента, определяющего диалоговые состояния для языковых моделей, упоминается использование распознавателя скорости.
- Что заявлено:
- 1. Реализуемый компьютером способ, включающий прием в вычислительной системе аудиоданных, указывающих на первый речевой ввод, который был предоставлен вычислительному устройству; определение того, что первый голосовой ввод является частью голосового диалога, который включает в себя множество предопределенных состояний диалога, предназначенных для приема ряда голосовых вводов, связанных с конкретной задачей, при этом каждое состояние диалога отображается на:
- (i) набор данных отображения, характеризующих контент, предназначенный для отображения, когда принимается голосовой ввод для состояния диалога, и
- (ii) набор n-грамм; получение в вычислительной системе первых отображаемых данных, которые характеризуют контент, который отображался на экране вычислительного устройства, когда первый речевой ввод был предоставлен вычислительному устройству
- Выбор компьютерной системой конкретного состояния диалога из множества предварительно определенных состояний диалога, которое соответствует первому голосовому вводу, включая определение соответствия между первыми данными отображения и соответствующим набором данных отображения, который отображается на конкретный состояние диалога
- Смещение языковой модели путем корректировки оценок вероятности, которые языковая модель указывает для n-грамм в соответствующем наборе n-грамм, которые отображаются на конкретное состояние диалога.
- Расшифровка голосового ввода с использованием предвзятой языковой модели.
Определение состояний диалога для языковых моделей
Изобретатели: Петар Алексич и Педро Дж. Морено Менгибар.
Правопреемник: Google LLC
Патент США: 11 264 028
Выдано: 1 марта 2022 г.
Подано: 2 января 2020 г.
Абстрактный
Здесь описаны системы, способы, устройства и другие способы для определения состояний диалога, которые соответствуют голосовым вводам, и для смещения языковой модели на основе определенных состояний диалога. В некоторых реализациях способ включает в себя прием в вычислительной системе аудиоданных, которые указывают голосовой ввод, и определение конкретного состояния диалога из множества состояний диалога, которое соответствует голосовому вводу. Можно определить набор n-грамм, связанных с конкретным состоянием диалога, соответствующим голосовому вводу. В ответ на идентификацию набора n-грамм, связанных с конкретным состоянием диалога, которое соответствует голосовому вводу, языковая модель может быть смещена путем корректировки показателей вероятности, которые языковая модель указывает для n-грамм в наборе n- грамм. Голосовой ввод может быть транскрибирован с использованием скорректированной языковой модели.
Поиск новостей прямо в папку «Входящие»
*Необходимый