
言語モデルのダイアログ状態の決定が更新されました
公開: 2022-03-16言語モデルの対話状態を決定する最初の主張
あなたがグーグルからの人間からコンピュータへの対話の特許を見たことがある可能性があります。 私は過去にいくつかについて書いたことがあります。 このようなダイアログに関する多くの詳細を提供する2つを次に示します。
- Googleでの人間とコンピュータの対話
- 人間からコンピュータへの対話における一方的なコンテンツ
人間とコンピューターの対話に関する特許を注意深く検討することに加えて、自然言語処理、および人間とコンピューター間の通信に時間を費やす価値があります。 それらのいくつかについても書いています。 ここにそれらのいくつかがあります:
- Googleアシスタントとコンテキストベースの自然言語処理
- 自然言語クエリの応答
このGoogleDeterminingDialog States For Language Modelsの特許は、今週2回更新され、最新バージョンが付与されました。 最後の最初のクレームは少し長く、いくつかの新しい単語が追加されています。
理想的には、これらの特許は、クレームの文言を深く検討することから始めなければなりません。
2018年18日に提出され、2020年2月4日に付与された言語モデルの[決定]ダイアログ状態の2番目のバージョンは、次の主張から始まります。
- 主張されているのは:
- 1.コンピュータで実施される方法。
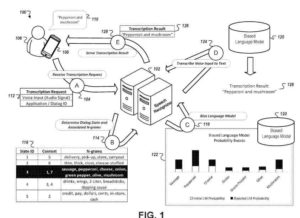
- コンピューティングデバイスによって、コンピューティングデバイスへの音声入力のための音声データを受信する。ここで、音声入力は、コンピューティングデバイスとコンピューティングデバイスのユーザとの間の多段階音声対話の未知の段階に対応する。
- 多段階音声ダイアログの未知の段階の初期予測を決定する
コンピューティングデバイスおよび音声ダイアログシステムに、- (i)コンピューティングデバイスへの音声入力のオーディオデータおよび
- (ii)多段階音声ダイアログの未知の段階の初期予測の表示
- コンピューティングデバイスによって、および音声ダイアログシステムから、音声入力の転写を受信します。この転写は、の未知の段階の洗練された予測に対応するパラメータに従ってバイアスされたモデルで音声データを処理することによって生成されました。多段音声ダイアログ。音声ダイアログシステムは、(i)多段音声ダイアログの未知のステージの初期予測および
- (ii)音声入力のコンテキストを説明する追加情報、および音声入力のコンテキストを説明する追加情報は、
- 音声入力; コンピューティングデバイスで音声入力の文字起こしを提示します。
この継続特許の最初のバージョンである、言語モデルのダイアログ状態の決定は、2016年3月16日に出願され、2018年5月22日に付与され、次の主張で始まります。
- 主張されているのは:
- 1.コンピュータで実施される方法。
- コンピューティングシステムで、コンピューティングデバイスに提供された最初の音声入力を示すオーディオデータを受信する
- 第1の音声入力が、特定のタスクに関連する一連の音声入力を受信するように配置された複数の事前定義されたダイアログ状態を含む音声ダイアログの一部であると決定する。ここで、各ダイアログ状態は、以下にマッピングされる。ダイアログ状態の音声入力を受信したときに表示するように指定されたコンテンツを特徴付けるデータを表示し、
(ii)一連のn-gram - コンピューティングシステムで、最初の音声入力がコンピューティングデバイスに提供されたときにコンピューティングデバイスの画面に表示されたコンテンツを特徴付ける最初の表示データを受信する。 コンピューティングシステムによって、第1の音声入力に対応する複数の事前定義されたダイアログ状態の特定のダイアログ状態を選択すること。これには、第1の表示データと、特定のものにマッピングされる対応する表示データのセットとの間の一致の決定が含まれる。ダイアログの状態; 特定のダイアログ状態にマップされた対応するn-gramのセット内のn-gramに対して言語モデルが示す確率スコアを調整することにより、言語モデルにバイアスをかけます。 偏った言語モデルを使用して音声入力を転記します。
この特許の最新版である言語モデルのダイアログ状態の決定における最新の最初のクレームは、2020年1月2日に提出され、2022年3月1日に付与されました。
- 主張されているのは:
- 1.コンピュータで実施される方法。
- 音声入力のトレーニングセットから音声入力のトランスクリプションを取得します。音声入力のトレーニングセット内の各音声入力は、多段階音声アクティビティの複数の段階の1つに向けられます。
- 関連する音声入力が受信されたときに表示用に指定されたコンテンツを特徴付ける音声入力のトレーニングセットから、各音声入力に関連付けられた表示データを取得する。 転写の複数のグループを生成します。ここで、転写の各グループには、音声入力のトレーニングセットからの音声入力の転写の異なるサブセットが含まれます。
- 転写の各グループを、複数の対話状態を含む対話状態モデルの異なる対話状態に割り当てる。ここで、複数の対話状態の各対話状態は、多段階音声活動の異なる段階に対応する。 そして、ダイアログ状態に割り当てられた転写のグループに関連付けられた音声入力のトレーニングセットからの音声入力が受信されたときに表示用に指定されたコンテンツを特徴付ける表示データのそれぞれのセットにマッピングされる。 転写の各グループについて、グループの代表的なn-gramのセットを決定し、グループの代表的なn-gramのセットを、グループが割り当てられているダイアログ状態モデルの対応するダイアログ状態に関連付けます。転写のグループに対して決定されたn-gramの代表的なセットは、n-gramを含みます-ダイアログ状態モデルのダイアログ状態に割り当てられた転写のグループでの発生のしきい値数を満たします
- 後続の音声入力と、後続の音声入力が受信されたときに画面に表示されたコンテンツを特徴付ける最初の表示データを受信すると、後続の音声入力は、多段階音声アクティビティの特定の段階に向けられます
マルチボイスアクティビティの特定の段階に対応するダイアログ状態モデルのダイアログ状態にマッピングされた、最初の表示データとそれぞれの表示データのセットとの間の一致を判断する - 音声認識機能、後続の音声入力、および最初の表示データを使用した処理。これには、の特定の段階に対応するダイアログ状態モデルのダイアログ状態に関連付けられたn-gramの代表的なセットを使用した音声認識機能のバイアスが含まれます。マルチボイスアクティビティ
\
言語モデルの対話状態の決定の主張の比較
これらは、私が特許の異なるバージョンで見ているいくつかの違いです:
1. 3つのバージョンはすべて、トレーニングセットの一部として機能する「音声入力」に関するものであることを示しています。
したがって、ダイアログの内容に焦点を当てた、人間とコンピュータ間のダイアログ状態に関する以前の特許とは異なり、この特許は主に口頭言語と実際の音声入力に注目しています。
2.特許の2番目と3番目のバージョンは、音声入力のトランスクリプトをngramに分割することを説明しています。これは、使用される音声入力の発生に関する統計を計算するのに役立ちます。
3.言語モデルの特許決定ダイアログの状態の最新および第3バージョンの主張は、速度認識装置の使用に言及しています。
- 主張されているのは:
- コンピューティングシステムで、コンピューティングデバイスに提供された第1の音声入力を示す音声データを受信することを含む、コンピュータで実施される方法。 第1の音声入力が、特定のタスクに関連する一連の音声入力を受信するように配置された複数の事前定義されたダイアログ状態を含む音声ダイアログの一部であることを決定し、各ダイアログ状態は以下にマッピングされる。
- (i)ダイアログ状態の音声入力を受信したときに表示するように指定されたコンテンツを特徴付ける表示データのセット。
- (ii)nグラムのセット。 コンピューティングシステムで、最初の音声入力がコンピューティングデバイスに提供されたときにコンピューティングデバイスの画面に表示されたコンテンツを特徴付ける最初の表示データを受信する。
- コンピューティングシステムによって、第1の音声入力に対応する複数の事前定義されたダイアログ状態の特定のダイアログ状態を選択すること(第1の表示データと、特定のものにマッピングされる対応する表示データのセットとの間の一致を決定することを含む)。ダイアログの状態
- 特定のダイアログ状態にマップされている対応するn-gramのセット内のn-gramに対して言語モデルが示す確率スコアを調整することにより、言語モデルにバイアスをかけます。
- 偏った言語モデルを使用して音声入力を転写します。

言語モデルのダイアログ状態の決定
発明者:Petar Aleksic、およびPedro J. Moreno Mengibar
譲受人:Google LLC
米国特許:11,264,028
付与:2022年3月1日
提出日:2020年1月2日
概要
本明細書では、音声入力に対応するダイアログ状態を決定し、決定されたダイアログ状態に基づいて言語モデルにバイアスをかけるためのシステム、方法、デバイス、および他の技術について説明する。 いくつかの実装形態では、方法は、コンピューティングシステムで、音声入力を示す音声データを受信し、音声入力に対応する複数のダイアログ状態の中から特定のダイアログ状態を決定することを含む。 音声入力に対応する特定のダイアログ状態に関連付けられているn-gramのセットを識別できます。 音声入力に対応する特定のダイアログ状態に関連付けられているn-gramのセットを識別することに応答して、言語モデルがn-のセット内のn-gramに対して示す確率スコアを調整することにより、言語モデルにバイアスをかけることができます。グラム。 音声入力は、調整された言語モデルを使用して書き写すことができます。
受信トレイに直接ニュースを検索
*必須