
Determinando Estados de Diálogo para Modelos de Linguagem Atualizados
Publicados: 2022-03-16As primeiras alegações de determinação de estados de diálogo para modelos de linguagem
É provável que você tenha visto patentes de diálogo humano-computador do Google. Já escrevi sobre alguns no passado. Aqui estão dois que fornecem muitos detalhes sobre esse diálogo:
- Diálogo humano para computador no Google
- Conteúdo não solicitado na caixa de diálogo Human to Computer
Além de examinar cuidadosamente as patentes que envolvem o diálogo humano-computador, vale a pena gastar tempo com Processamento de Linguagem Natural e comunicações entre seres humanos e computadores. Também escrevi sobre alguns deles. Aqui estão alguns deles:
- O Google Assistant e o processamento de linguagem natural baseado em contexto
- Respostas de consulta de linguagem natural
Esta patente do Google Determining Dialog States For Language Models foi atualizada duas vezes agora, com a versão mais recente sendo concedida no início desta semana. A última primeira reivindicação é um pouco mais longa e tem algumas palavras novas adicionadas a ela.
Idealmente, essas patentes devem começar com uma análise profunda da linguagem das reivindicações.
A segunda versão de Determinando estados de diálogo para modelos de idioma, arquivada em 18 de 2018 e concedida em 4 de fevereiro de 2020, começa com a seguinte reivindicação:
- O que é alegado é:
- 1. Método implementado por computador, caracterizado pelo fato de que compreende:
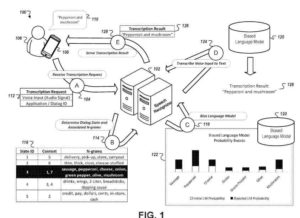
- Receber, por um dispositivo de computação, dados de áudio para uma entrada de voz para o dispositivo de computação, em que a entrada de voz corresponde a um estágio desconhecido de um diálogo de voz em vários estágios entre o dispositivo de computação e um usuário do dispositivo de computação
- Determinando uma previsão inicial para o estágio desconhecido do diálogo de voz em vários estágios
Fornecer, pelo dispositivo de computação e a um sistema de diálogo de voz,- (i) os dados de áudio para a entrada de voz para o dispositivo de computação e
- (ii) uma indicação da previsão inicial para o estágio desconhecido do diálogo de voz em vários estágios
- Receber, pelo dispositivo de computação e do sistema de diálogo de voz, uma transcrição da entrada de voz, em que a transcrição foi gerada pelo processamento dos dados de áudio com um modelo que foi enviesado de acordo com parâmetros que correspondem a uma previsão refinada para o estágio desconhecido de o diálogo de voz de múltiplos estágios, em que o sistema de diálogo de voz é configurado para determinar a previsão refinada para o estágio desconhecido do diálogo de voz de múltiplos estágios com base em (i) a previsão inicial para o estágio desconhecido do diálogo de voz de múltiplos estágios e
- (ii) informações adicionais que descrevem um contexto da entrada de voz e em que as informações adicionais que descrevem o contexto da entrada de voz são independentes do conteúdo de
- a entrada de voz; e apresentar a transcrição da entrada de voz com o dispositivo de computação.
A primeira versão desta patente de continuação, Determinando estados de diálogo para modelos de linguagem, arquivada em 16 de março de 2016 e concedida em 22 de maio de 2018, começa com esta reivindicação:
- O que é alegado é:
- 1. Método implementado por computador, caracterizado pelo fato de que compreende:
- Receber, em um sistema de computação, dados de áudio que indicam uma primeira entrada de voz que foi fornecida a um dispositivo de computação
- Determinar que a primeira entrada de voz é parte de um diálogo de voz que inclui uma pluralidade de estados de diálogo predefinidos dispostos para receber uma série de entradas de voz relacionadas a uma tarefa específica, em que cada estado de diálogo é mapeado para: (i) um conjunto de exibir dados caracterizando o conteúdo que é designado para exibição quando entradas de voz para o estado de diálogo são recebidas, e
(ii) um conjunto de n-gramas - Receber, no sistema de computação, os primeiros dados de exibição que caracterizam o conteúdo que foi exibido em uma tela do dispositivo de computação quando a primeira entrada de voz foi fornecida ao dispositivo de computação; selecionar, pelo sistema de computação, um estado de diálogo específico da pluralidade de estados de diálogo predefinidos que corresponde à primeira entrada de voz, incluindo determinar uma correspondência entre os primeiros dados de exibição e o conjunto correspondente de dados de exibição que são mapeados para o determinado estado de diálogo; enviesar um modelo de linguagem ajustando pontuações de probabilidade que o modelo de linguagem indica para n-gramas no conjunto correspondente de n-gramas que são mapeados para o estado de diálogo específico; e transcrever a entrada de voz usando o modelo de linguagem tendenciosa.
A primeira reivindicação mais recente na versão mais recente desta patente, Determinando estados de diálogo para modelos de idioma, foi arquivada em 2 de janeiro de 2020 e concedida em 1 de março de 2022. Ela nos diz:
- O que é alegado é:
- 1. Método implementado por computador, caracterizado pelo fato de que compreende:
- Obtenção de transcrições de entradas de voz de um conjunto de treinamento de entradas de voz, em que cada entrada de voz no conjunto de treinamento de entradas de voz é direcionada para um de uma pluralidade de estágios de uma atividade de voz de múltiplos estágios
- Obter dados de exibição associados a cada entrada de voz do conjunto de treinamento de entradas de voz que caracteriza o conteúdo que é designado para exibição quando a entrada de voz associada é recebida; gerar uma pluralidade de grupos de transcrições, em que cada grupo de transcrições inclui um subconjunto diferente das transcrições de entradas de voz do conjunto de treinamento de entradas de voz
- Atribuir cada grupo de transcrições a um estado de diálogo diferente de um modelo de estado de diálogo que inclui uma pluralidade de estados de diálogo, em que cada estado de diálogo da pluralidade de estados de diálogo: corresponde a um estágio diferente da atividade de voz em vários estágios; e é mapeado para um respectivo conjunto do conteúdo de caracterização de dados de exibição que é designado para exibição quando entradas de voz do conjunto de treinamento de entradas de voz que estão associadas ao grupo de transcrições atribuídas ao estado de diálogo são recebidas; para cada grupo de transcrições, determinando um conjunto representativo de n-grams para o grupo e associando o conjunto representativo de n-grams para o grupo com o estado de diálogo correspondente do modelo de estado de diálogo ao qual o grupo é atribuído, em que o conjunto representativo de n-gramas determinado para o grupo de transcrições compreende n-gramas que satisfazem um número limite de ocorrências no grupo de transcrições atribuído ao estado de diálogo do modelo de estado de diálogo
- Receber uma entrada de voz subsequente e exibir os primeiros dados de caracterização do conteúdo que foi exibido em uma tela quando a entrada de voz subsequente foi recebida, a entrada de voz subsequente direcionada para um estágio específico da atividade de voz em vários estágios
Determinar uma correspondência entre os primeiros dados de exibição e o respectivo conjunto de dados de exibição mapeados para o estado de diálogo no modelo de estado de diálogo que corresponde ao estágio específico da atividade multivoz - Processamento, com um reconhecedor de fala, a entrada de voz subsequente e os primeiros dados de exibição, incluindo a polarização do reconhecedor de fala usando o conjunto representativo de n-gramas associados ao estado de diálogo no modelo de estado de diálogo que corresponde ao estágio específico do atividade multi-voz
\
Comparando as declarações dos estados de diálogo de determinação para modelos de linguagem
Estas são algumas das diferenças que estou vendo com as diferentes versões da patente:

1. Todas as três versões nos dizem que são sobre “entradas de voz”, que atuam como parte de um conjunto de treinamento.
Assim, ao contrário das patentes anteriores sobre os estados de diálogo entre humanos e computadores, que se concentravam no conteúdo do diálogo, esta patente analisa principalmente a linguagem verbal e as entradas de voz reais.
2. A segunda e terceira versões da patente descrevem a quebra de transcrições das entradas de voz em nggramas, o que pode ser útil no cálculo de estatísticas sobre as ocorrências das entradas de voz usadas.
3. A reivindicação da versão mais recente e terceira dos estados de diálogo de determinação de patente para modelos de linguagem menciona o uso de um reconhecedor de velocidade.
- O que é alegado é:
- 1. Um método implementado por computador, compreendendo: receber, em um sistema de computação, dados de áudio que indicam uma primeira entrada de voz que foi fornecida a um dispositivo de computação; determinar que a primeira entrada de voz é parte de um diálogo de voz que inclui uma pluralidade de estados de diálogo predefinidos dispostos para receber uma série de entradas de voz relacionadas a uma tarefa específica, em que cada estado de diálogo é mapeado para:
- (i) um conjunto de dados de exibição que caracterizam o conteúdo que é designado para exibição quando as entradas de voz para o estado de diálogo são recebidas, e
- (ii) um conjunto de n-gramas; receber, no sistema de computação, os primeiros dados de exibição que caracterizam o conteúdo que foi exibido em uma tela do dispositivo de computação quando a primeira entrada de voz foi fornecida ao dispositivo de computação
- Selecionar, pelo sistema de computação, um estado de diálogo específico da pluralidade de estados de diálogo predefinidos que corresponde à primeira entrada de voz, incluindo determinar uma correspondência entre os primeiros dados de exibição e o conjunto correspondente de dados de exibição que são mapeados para o determinado estado de diálogo
- Polarizar um modelo de linguagem ajustando as pontuações de probabilidade que o modelo de linguagem indica para n-gramas no conjunto correspondente de n-gramas que são mapeados para o estado de diálogo específico
- Transcrever a entrada de voz usando o modelo de linguagem tendenciosa.
Determinando estados de diálogo para modelos de linguagem
Inventores: Petar Aleksic e Pedro J. Moreno Mengibar
Responsável: Google LLC
Patente dos EUA: 11.264.028
Concedido: 1º de março de 2022
Arquivado: 2 de janeiro de 2020
Resumo
Sistemas, métodos, dispositivos e outras técnicas são descritos neste documento para determinar estados de diálogo que correspondem a entradas de voz e para polarizar um modelo de linguagem com base nos estados de diálogo determinados. Em algumas implementações, um método inclui receber, em um sistema de computação, dados de áudio que indicam uma entrada de voz e determinar um estado de diálogo específico, dentre uma pluralidade de estados de diálogo, que corresponde à entrada de voz. Um conjunto de n-gramas pode ser identificado que está associado ao estado de diálogo específico que corresponde à entrada de voz. Em resposta à identificação do conjunto de n-gramas que estão associados ao estado de diálogo específico que corresponde à entrada de voz, um modelo de idioma pode ser enviesado ajustando as pontuações de probabilidade que o modelo de idioma indica para n-gramas no conjunto de n-gramas gramas. A entrada de voz pode ser transcrita usando o modelo de idioma ajustado.
Pesquisar notícias diretamente na sua caixa de entrada
*Requerido