
업데이트된 언어 모델에 대한 대화 상자 상태 확인
게시 됨: 2022-03-16언어 모델에 대한 대화 상태 결정의 첫 번째 주장
Google의 인간 대 컴퓨터 대화 특허를 본 적이 있을 것입니다. 나는 과거에 일부에 대해 썼습니다. 다음은 이러한 대화 상자에 대한 많은 세부 정보를 제공하는 두 가지입니다.
- Google의 Human to Computer 대화
- 인간 대 컴퓨터 대화의 원치 않는 콘텐츠
인간 대 컴퓨터 대화와 관련된 특허를 주의 깊게 살펴보는 것 외에도 자연어 처리 및 인간과 컴퓨터 간의 통신에 시간을 할애할 가치가 있습니다. 나는 또한 그 중 몇 가지에 대해 썼습니다. 다음은 그 중 몇 가지입니다.
- Google 어시스턴트 및 컨텍스트 기반 자연어 처리
- 자연어 쿼리 응답
이 Google Determining Dialog States For Language Models 특허는 현재 두 번 업데이트되었으며 최신 버전은 이번 주 초에 부여되었습니다. 마지막 첫 번째 주장은 조금 더 길며 몇 가지 새로운 단어가 추가되었습니다.
이상적으로, 이러한 특허는 청구 범위의 언어를 자세히 살펴보는 것으로 시작해야 합니다.
2018년 2월 4일에 승인된 언어 모델에 대한 대화 상태 결정의 두 번째 버전은 다음 주장으로 시작합니다.
- 주장되는 내용은 다음과 같습니다.
- 1. 컴퓨터로 구현되는 방법으로서,
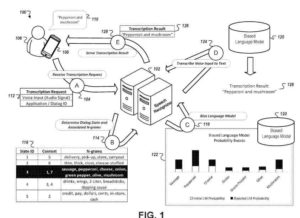
- 컴퓨팅 디바이스에 의해, 컴퓨팅 디바이스에 대한 음성 입력을 위한 오디오 데이터를 수신하고, 여기서 음성 입력은 컴퓨팅 디바이스와 컴퓨팅 디바이스의 사용자 사이의 다단계 음성 대화의 알려지지 않은 단계에 대응함
- 다단계 음성 대화의 알려지지 않은 단계에 대한 초기 예측 결정
컴퓨팅 장치에 의해 음성 대화 시스템에 제공하고,- (i) 컴퓨팅 장치에 음성 입력을 위한 오디오 데이터 및
- (ii) 다단계 음성 대화의 알려지지 않은 단계에 대한 초기 예측의 표시
- 컴퓨팅 장치에 의해 그리고 음성 대화 시스템으로부터 음성 입력의 전사를 수신하고, 여기서 전사는 의 미지의 단계에 대한 정제된 예측에 대응하는 매개변수에 따라 바이어스된 모델로 오디오 데이터를 처리함으로써 생성됨 다단계 음성 대화, 여기서 음성 대화 시스템은 (i) 다단계 음성 대화의 알려지지 않은 단계에 대한 초기 예측 및
- (ii) 음성 입력의 컨텍스트를 설명하는 추가 정보로서, 음성 입력의 컨텍스트를 설명하는 추가 정보는
- 음성 입력; 및 컴퓨팅 디바이스로 음성 입력의 전사를 제시하는 단계를 포함한다.
2016년 3월 16일에 출원되고 2018년 5월 22일에 부여된 이 연속 특허의 첫 번째 버전인 언어 모델에 대한 대화 상태 결정은 다음 주장으로 시작합니다.
- 주장되는 내용은 다음과 같습니다.
- 1. 컴퓨터로 구현되는 방법으로서,
- 컴퓨팅 시스템에서 컴퓨팅 장치에 제공된 첫 번째 음성 입력을 나타내는 오디오 데이터 수신
- 제1 음성 입력이 특정 태스크와 관련된 일련의 음성 입력을 수신하도록 배열된 복수의 미리 정의된 대화 상태를 포함하는 음성 대화의 일부임을 결정하는 단계로서, 각각의 대화 상태는 (i) 대화 상태에 대한 음성 입력이 수신될 때 표시하도록 지정된 콘텐츠를 특징화하는 데이터를 표시하고,
(ii) n-그램 세트 - 컴퓨팅 시스템에서, 제1 음성 입력이 컴퓨팅 디바이스에 제공되었을 때 컴퓨팅 디바이스의 스크린 상에 디스플레이되었던 콘텐츠를 특징짓는 제1 디스플레이 데이터를 수신하는 단계; 컴퓨팅 시스템에 의해, 제1 음성 입력에 대응하는 복수의 미리 정의된 대화 상태 중 특정 대화 상태를 선택하는 단계를 포함하고, 특정 대화 상자에 매핑되는 대응하는 디스플레이 데이터 세트와 제1 디스플레이 데이터 사이의 일치를 결정하는 것을 포함한다. 대화 상태; 특정 대화 상태에 매핑되는 대응하는 n-그램 세트의 n-그램에 대해 언어 모델이 나타내는 확률 점수를 조정하여 언어 모델을 바이어싱하는 단계; 및 편향된 언어 모델을 사용하여 음성 입력을 전사하는 단계를 포함한다.
이 특허의 최신 버전인 언어 모델에 대한 대화 상태 결정에서 가장 최근의 첫 번째 주장은 2020년 1월 2일에 제출되었으며 2022년 3월 1일에 승인되었습니다. 다음과 같이 알려줍니다.
- 주장되는 내용은 다음과 같습니다.
- 1. 컴퓨터로 구현되는 방법으로서,
- 음성 입력의 훈련 세트로부터 음성 입력의 전사를 획득하고, 여기서 음성 입력의 훈련 세트의 각 음성 입력은 다단계 음성 활동의 복수의 단계 중 하나로 지시됨
- 연관된 음성 입력이 수신될 때 디스플레이를 위해 지정된 콘텐츠를 특징짓는 음성 입력의 트레이닝 세트로부터 각각의 음성 입력과 연관된 디스플레이 데이터를 획득하는 단계; 전사의 복수의 그룹을 생성하는 단계 - 전사의 각 그룹은 음성 입력의 트레이닝 세트로부터 음성 입력의 전사의 상이한 서브세트를 포함함
- 전사의 각 그룹을 복수의 대화 상태를 포함하는 대화 상태 모델의 다른 대화 상태에 할당하고, 여기서 복수의 대화 상태의 각 대화 상태는 다단계 음성 활동의 다른 단계에 대응하고; 대화 상태에 할당된 전사의 그룹과 연관된 음성 입력의 트레이닝 세트로부터의 음성 입력이 수신될 때 디스플레이를 위해 지정된 콘텐츠를 특징화하는 디스플레이 데이터의 각각의 세트에 매핑되고; 전사의 각 그룹에 대해, 그룹에 대한 대표 n-그램 세트를 결정하고, 그룹에 대한 대표 n-그램 세트를 그룹이 할당된 대화 상태 모델의 해당 대화 상태와 연관시키는 단계를 포함하고, 전사 그룹에 대해 결정된 대표적인 n-그램 세트는 대화 상태 모델의 대화 상태에 할당된 전사 그룹에서 임계값 발생 횟수를 충족하는 n-그램을 포함합니다.
- 후속 음성 입력을 수신하고 후속 음성 입력이 수신될 때 화면에 표시되었던 콘텐츠를 특징짓는 첫 번째 디스플레이 데이터, 다단계 음성 활동의 특정 단계를 향한 후속 음성 입력 수신
다중 음성 활동의 특정 단계에 해당하는 대화 상태 모델의 대화 상태에 매핑된 각 디스플레이 데이터 세트와 첫 번째 디스플레이 데이터 사이의 일치를 결정합니다. - 음성 인식기로, 후속 음성 입력 및 첫 번째 디스플레이 데이터를 처리하는 단계는 특정 단계에 해당하는 대화 상태 모델에서 대화 상태와 관련된 n-그램의 대표 세트를 사용하여 음성 인식기를 바이어싱하는 것을 포함합니다. 다중 음성 활동
\
언어 모델에 대한 결정 대화 상태의 주장 비교
다음은 다른 버전의 특허에서 볼 수 있는 몇 가지 차이점입니다.
1. 세 가지 버전 모두 훈련 세트의 일부로 작동하는 "음성 입력"에 관한 것입니다.
따라서 대화의 내용에 중점을 둔 인간과 컴퓨터 간의 대화 상태에 대한 이전 특허와 달리 이 특허는 주로 언어 및 실제 음성 입력에 주목합니다.
2. 특허의 두 번째 및 세 번째 버전은 음성 입력의 기록을 ngram으로 나누는 방법을 설명하며, 이는 사용된 음성 입력 발생에 대한 통계를 계산하는 데 도움이 될 수 있습니다.
3. 언어 모델에 대한 특허 eterining 대화 상태의 최신 및 세 번째 버전의 주장은 속도 인식기의 사용을 언급합니다.
- 주장되는 내용은 다음과 같습니다.
- 컴퓨터로 구현되는 방법으로서, 컴퓨팅 장치에 제공된 제1 음성 입력을 나타내는 오디오 데이터를 컴퓨팅 시스템에서 수신하는 단계; 제1 음성 입력이 특정 태스크와 관련된 일련의 음성 입력을 수신하도록 배열된 복수의 미리 정의된 대화 상태를 포함하는 음성 대화의 일부라고 결정하고, 여기서 각각의 대화 상태는 다음에 매핑된다:
- (i) 대화 상태에 대한 음성 입력이 수신될 때 표시하도록 지정된 콘텐츠를 특징짓는 표시 데이터 세트, 및
- (ii) n-그램 세트; 컴퓨팅 시스템에서, 제1 음성 입력이 컴퓨팅 디바이스에 제공되었을 때 컴퓨팅 디바이스의 스크린 상에 디스플레이되었던 콘텐츠를 특징짓는 제1 디스플레이 데이터를 수신하는 것
- 컴퓨팅 시스템에 의해, 제1 음성 입력에 대응하는 복수의 사전 정의된 대화 상태 중 특정 대화 상태를 선택하는 단계는 특정 대화 상자에 매핑되는 대응하는 디스플레이 데이터 세트와 제1 디스플레이 데이터 사이의 일치를 결정하는 것을 포함합니다. 대화 상태
- 특정 대화 상태에 매핑되는 해당 n-그램 세트의 n-그램에 대해 언어 모델이 나타내는 확률 점수를 조정하여 언어 모델 바이어스
- 편향된 언어 모델을 사용하여 음성 입력을 전사합니다.

언어 모델의 대화 상태 확인
발명가: Petar Aleksic, Pedro J. Moreno Mengibar
양수인: Google LLC
미국 특허: 11,264,028
부여: 2022년 3월 1일
출원일: 2020년 1월 2일
추상적인
음성 입력에 대응하는 대화 상태를 결정하고 결정된 대화 상태에 기초하여 언어 모델을 바이어싱하기 위한 시스템, 방법, 장치 및 기타 기술이 여기에서 설명됩니다. 일부 구현들에서, 방법은 컴퓨팅 시스템에서 음성 입력을 나타내는 오디오 데이터를 수신하는 단계 및 음성 입력에 대응하는 복수의 대화 상태들 중에서 특정 대화 상태를 결정하는 단계를 포함한다. 음성 입력에 해당하는 특정 대화 상태와 관련된 n-그램 세트를 식별할 수 있습니다. 음성 입력에 해당하는 특정 대화 상태와 연관된 n-그램 집합을 식별하는 것에 응답하여 언어 모델이 n-그램 집합에서 n-그램에 대해 나타내는 확률 점수를 조정하여 언어 모델을 편향시킬 수 있습니다. 그램. 음성 입력은 조정된 언어 모델을 사용하여 전사될 수 있습니다.
받은 편지함으로 바로 뉴스 검색
*필수의