
确定语言模型的对话状态已更新
已发表: 2022-03-16为语言模型确定对话状态的第一个声明
您可能已经看过 Google 的人机对话专利。 我过去写过一些。 这里有两个提供了有关此类对话框的大量详细信息:
- Google 的人机对话
- 人机对话中未经请求的内容
除了仔细研究涉及人机对话的专利外,还值得花时间研究自然语言处理以及人机之间的通信。 我也写过其中的一些。 以下是其中的几个:
- Google 助理和基于上下文的自然语言处理
- 自然语言查询响应
Google Determining Dialog States For Language Models 专利现在已经更新了两次,最新版本在本周早些时候被授予。 最新的第一个声明稍长一些,并添加了一些新词。
理想情况下,这些专利必须从深入研究权利要求的语言开始。
2018 年 18 月 18 日提交并于 2020 年 2 月 4 日授予的第二版确定语言模型的对话状态,从以下声明开始:
- 声称的是:
- 1.一种计算机实现的方法,包括:
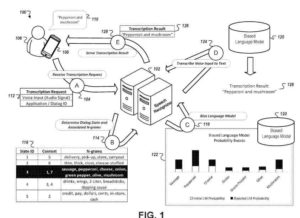
- 由计算设备接收用于向计算设备输入的语音的音频数据,其中语音输入对应于计算设备和计算设备的用户之间的多阶段语音对话的未知阶段
- 确定多阶段语音对话的未知阶段的初始预测
由计算设备向语音对话系统提供,- (i) 语音输入到计算设备的音频数据,以及
- (ii) 对多阶段语音对话的未知阶段的初始预测的指示
- 由计算设备并从语音对话系统接收语音输入的转录,其中转录是通过使用模型处理音频数据而生成的,该模型根据对应于对未知阶段的精炼预测的参数有偏差多阶段语音对话,其中语音对话系统被配置为基于(i)多阶段语音对话的未知阶段的初始预测,确定多阶段语音对话的未知阶段的精细预测,以及
- (ii)描述语音输入的上下文的附加信息,并且其中描述语音输入的上下文的附加信息独立于
- 语音输入; 并且用计算设备呈现语音输入的转录。
2016 年 3 月 16 日提交并于 2018 年 5 月 22 日获得授权的此延续专利的第一个版本,即确定语言模型的对话状态,以以下声明开头:
- 声称的是:
- 1.一种计算机实现的方法,包括:
- 在计算系统处接收指示提供给计算设备的第一语音输入的音频数据
- 确定第一语音输入是包括多个预定义对话状态的语音对话的一部分,该多个预定义对话状态被布置为接收与特定任务相关的一系列语音输入,其中每个对话状态被映射到:(i)一组当接收到对话状态的语音输入时,显示对指定显示内容进行表征的数据,以及
(ii) 一组 n-gram - 在计算系统处接收表征当第一语音输入被提供给计算设备时显示在计算设备的屏幕上的内容的第一显示数据; 由计算系统选择多个预定义对话状态中对应于第一语音输入的特定对话状态,包括确定第一显示数据和映射到特定的显示数据的对应组之间的匹配。对话状态; 通过调整语言模型为映射到特定对话状态的相应 n-gram 集合中的 n-gram 指示的概率分数来偏置语言模型; 并使用有偏语言模型转录语音输入。
该专利最新版本中的第一项权利要求,即确定语言模型的对话状态,于 2020 年 1 月 2 日提交,并于 2022 年 3 月 1 日获得授权。它告诉我们:
- 声称的是:
- 1.一种计算机实现的方法,包括:
- 从语音输入训练集中获得语音输入的转录,其中语音输入训练集中的每个语音输入被引导到多阶段语音活动的多个阶段之一
- 从语音输入的训练集中获得与每个语音输入相关联的显示数据,该数据表征在接收到相关联的语音输入时指定用于显示的内容; 生成多个转录组,其中每组转录包括来自语音输入训练集的语音输入转录的不同子集
- 将每组转录分配给包括多个对话状态的对话状态模型的不同对话状态,其中多个对话状态中的每个对话状态: 对应于多阶段语音活动的不同阶段; 当接收到来自与分配给对话状态的转录组相关联的语音输入训练集的语音输入时,将其映射到表征内容的相应显示数据集; 对于每组转录,确定该组的代表性 n-gram 集合,并将该组的代表性 n-gram 集合与分配给该组的对话状态模型的对应对话状态相关联,其中为转录组确定的代表 n-gram 集合包括 n-gram-满足分配给对话状态模型的对话状态的转录组中出现的阈值次数
- 接收后续语音输入和第一显示数据表征当接收到后续语音输入时在屏幕上显示的内容,后续语音输入指向多阶段语音活动的特定阶段
确定第一显示数据与映射到对话状态模型中对话状态的相应显示数据集之间的匹配,该对话状态对应于多语音活动的特定阶段 - 用语音识别器处理随后的语音输入和第一显示数据,包括使用与对话状态模型中对应于特定阶段的对话状态相关联的 n-gram 的代表性集合来偏置语音识别器多语音活动
\
比较确定语言模型的对话状态的声明
这些是我在不同版本的专利中看到的一些差异:
1. 所有三个版本都告诉我们它们是关于“语音输入”的,它作为训练集的一部分。
因此,与之前关于人机对话状态的专利侧重于对话的内容不同,该专利主要着眼于口头语言和实际语音输入。
2. 该专利的第二和第三版本描述了将语音输入的转录本分解为 ngram,这有助于计算有关使用的语音输入出现次数的统计数据。
3. 语言模型的专利确定对话状态的最新和第三版本的权利要求提到了速度识别器的使用。
- 声称的是:
- 1.一种计算机实现的方法,包括: 在计算系统处接收指示提供给计算设备的第一语音输入的音频数据; 确定第一语音输入是包括多个预定义对话状态的语音对话的一部分,所述多个预定义对话状态被布置为接收与特定任务相关的一系列语音输入,其中每个对话状态被映射到:
- (i) 一组显示数据表征内容,当接收到对话状态的语音输入时指定显示,以及
- (ii) 一组 n-gram; 在计算系统处接收第一显示数据,该数据表征当第一语音输入被提供给计算设备时显示在计算设备的屏幕上的内容
- 由计算系统选择多个预定义对话状态中对应于第一语音输入的特定对话状态,包括确定第一显示数据和映射到特定的显示数据的对应组之间的匹配。对话状态
- 通过调整语言模型为映射到特定对话状态的相应 n-gram 集合中的 n-gram 指示的概率分数来偏置语言模型
- 使用有偏语言模型转录语音输入。
确定语言模型的对话状态
发明人:Petar Aleksic 和 Pedro J. Moreno Mengibar
受让人:谷歌有限责任公司
美国专利:11,264,028
授予:2022 年 3 月 1 日
提交日期:2020 年 1 月 2 日
抽象的
本文描述了用于确定对应于语音输入的对话状态以及用于基于所确定的对话状态来偏置语言模型的系统、方法、设备和其他技术。 在一些实现中,一种方法包括在计算系统处接收指示语音输入的音频数据,并从多个对话状态中确定与语音输入相对应的特定对话状态。 可以识别与对应于语音输入的特定对话状态相关联的一组 n-gram。 响应于识别与对应于语音输入的特定对话状态相关联的 n-gram 集合,可以通过调整语言模型为 n-gram 集合中的 n-gram 指示的概率分数来偏置语言模型。克。 可以使用调整后的语言模型转录语音输入。

直接在您的收件箱中搜索新闻
*必需的