
Menentukan Status Dialog Untuk Model Bahasa Diperbarui
Diterbitkan: 2022-03-16Klaim Pertama Menentukan Status Dialog Untuk Model Bahasa
Kemungkinannya adalah Anda telah melihat paten dialog manusia-ke-komputer dari Google. Saya telah menulis tentang beberapa di masa lalu. Berikut adalah dua yang memberikan banyak detail tentang dialog tersebut:
- Dialog Manusia ke Komputer di Google
- Konten yang Tidak Diminta dalam Dialog Manusia ke Komputer
Selain melihat dengan cermat paten yang melibatkan dialog manusia ke komputer, ada baiknya menghabiskan waktu dengan Pemrosesan Bahasa Alami, dan komunikasi antara manusia dan komputer. Saya juga telah menulis tentang beberapa dari mereka. Berikut adalah beberapa di antaranya:
- Asisten Google dan Pemrosesan Bahasa Alami Berbasis Konteks
- Respons Kueri Bahasa Alami
Paten Google Menentukan Status Dialog Untuk Model Bahasa ini telah diperbarui dua kali sekarang, dengan versi terbaru diberikan awal minggu ini. Klaim pertama terbaru sedikit lebih lama dan memiliki beberapa kata baru yang ditambahkan ke dalamnya.
Idealnya, paten ini harus dimulai dengan pandangan mendalam pada bahasa klaim.
Versi Kedua dari Status dialog Menentukan untuk model bahasa, diajukan pada 18, 2018, dan diberikan pada 4 Februari 2020, dimulai dengan klaim berikut:
- Yang diklaim adalah:
- 1. Metode yang diterapkan komputer, terdiri dari:
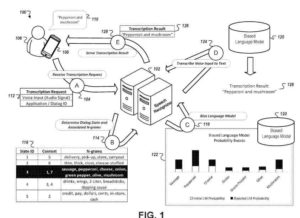
- Menerima, oleh perangkat komputasi, data audio untuk input suara ke perangkat komputasi, di mana input suara sesuai dengan tahap yang tidak diketahui dari dialog suara multi-tahap antara perangkat komputasi dan pengguna perangkat komputasi
- Menentukan prediksi awal untuk tahap yang tidak diketahui dari dialog suara multi-tahap
Menyediakan, oleh perangkat komputasi dan sistem dialog suara,- (i) data audio untuk input suara ke perangkat komputasi dan
- (ii) indikasi prediksi awal untuk tahap yang tidak diketahui dari dialog suara multi-tahap
- Menerima, oleh perangkat komputasi dan dari sistem dialog suara, transkripsi input suara, di mana transkripsi dihasilkan dengan memproses data audio dengan model yang bias menurut parameter yang sesuai dengan prediksi yang disempurnakan untuk tahap yang tidak diketahui dari dialog suara multi-tahap, di mana sistem dialog suara dikonfigurasi untuk menentukan prediksi yang disempurnakan untuk tahap yang tidak diketahui dari dialog suara multi-tahap berdasarkan (i) prediksi awal untuk tahap yang tidak diketahui dari dialog suara multi-tahap dan
- (ii) informasi tambahan yang menjelaskan konteks input suara, dan di mana informasi tambahan yang menjelaskan konteks input suara tidak bergantung pada konten
- masukan suara; dan menyajikan transkripsi input suara dengan perangkat komputasi.
Versi pertama dari paten lanjutan ini, Menentukan status dialog untuk model bahasa, diajukan 16 Maret 2016, dan diberikan 22 Mei 2018, dimulai dengan klaim ini:
- Yang diklaim adalah:
- 1. Metode yang diterapkan komputer, terdiri dari:
- Menerima, pada sistem komputasi, data audio yang menunjukkan input suara pertama yang diberikan ke perangkat komputasi
- Menentukan bahwa input suara pertama adalah bagian dari dialog suara yang mencakup sejumlah status dialog yang telah ditentukan sebelumnya yang diatur untuk menerima serangkaian input suara yang terkait dengan tugas tertentu, di mana setiap status dialog dipetakan ke: (i) satu set menampilkan data yang mencirikan konten yang ditujukan untuk ditampilkan saat input suara untuk status dialog diterima, dan
(ii) satu set n-gram - Menerima, pada sistem komputasi, data tampilan pertama yang mencirikan konten yang ditampilkan pada layar perangkat komputasi ketika input suara pertama diberikan ke perangkat komputasi; memilih, oleh sistem komputasi, keadaan dialog tertentu dari pluralitas keadaan dialog yang telah ditentukan sebelumnya yang sesuai dengan input suara pertama, termasuk menentukan kecocokan antara data tampilan pertama dan kumpulan data tampilan yang sesuai yang dipetakan ke keadaan dialog; membiaskan model bahasa dengan menyesuaikan skor probabilitas yang ditunjukkan oleh model bahasa untuk n-gram dalam set n-gram yang sesuai yang dipetakan ke status dialog tertentu; dan menyalin input suara menggunakan model bahasa bias.
Klaim pertama terbaru dalam versi terbaru dari paten ini, Menentukan status dialog untuk model bahasa, diajukan pada 2 Januari 2020, dan diberikan pada 1 Maret 2022. Klaim tersebut memberi tahu kita:
- Yang diklaim adalah:
- 1. Metode yang diterapkan komputer, terdiri dari:
- Memperoleh transkripsi input suara dari set pelatihan input suara, di mana setiap input suara dalam set pelatihan input suara diarahkan ke salah satu dari sejumlah tahapan aktivitas suara multi-tahap
- Memperoleh data tampilan yang terkait dengan setiap input suara dari set pelatihan input suara yang mencirikan konten yang ditujukan untuk tampilan saat input suara terkait diterima; menghasilkan sejumlah kelompok transkripsi, di mana setiap kelompok transkripsi mencakup subset yang berbeda dari transkripsi input suara dari set pelatihan input suara
- Menetapkan setiap kelompok transkripsi ke keadaan dialog yang berbeda dari model keadaan dialog yang mencakup sejumlah keadaan dialog, di mana setiap keadaan dialog dari pluralitas keadaan dialog: sesuai dengan tahap yang berbeda dari aktivitas suara multi-tahap; dan dipetakan ke masing-masing set data tampilan yang mencirikan konten yang ditujukan untuk tampilan saat input suara dari set pelatihan input suara yang terkait dengan grup transkripsi yang ditetapkan ke status dialog diterima; untuk setiap grup transkripsi, menentukan himpunan perwakilan n-gram untuk grup, dan mengasosiasikan himpunan perwakilan n-gram untuk grup dengan keadaan dialog yang sesuai dari model keadaan-dialog di mana kelompok ditugaskan, di mana himpunan perwakilan n-gram yang ditentukan untuk grup transkripsi terdiri dari n-gram-memenuhi ambang batas jumlah kemunculan dalam grup transkripsi yang ditetapkan ke status dialog model status dialog
- Menerima input suara berikutnya dan data tampilan pertama yang mencirikan konten yang ditampilkan pada layar saat input suara berikutnya diterima, input suara berikutnya diarahkan ke tahap tertentu dari aktivitas suara multi-tahap
Menentukan kecocokan antara data tampilan pertama dan kumpulan data tampilan masing-masing yang dipetakan ke status dialog dalam model status dialog yang sesuai dengan tahap tertentu dari aktivitas multi-suara - Pemrosesan, dengan pengenal ucapan, input suara berikutnya, dan data tampilan pertama, termasuk membiaskan pengenal ucapan menggunakan set perwakilan n-gram yang terkait dengan status dialog dalam model status dialog yang sesuai dengan tahap tertentu dari aktivitas multi-suara
\
Membandingkan Klaim dari Menentukan Status Dialog untuk Model Bahasa
Ini adalah beberapa perbedaan yang saya lihat dengan berbagai versi paten:

1. Ketiga versi memberi tahu kami bahwa itu adalah tentang "input suara", yang bertindak sebagai bagian dari set pelatihan.
Jadi tidak seperti paten sebelumnya tentang status Dialog antara manusia dan komputer, yang berfokus pada konten dialog, paten ini terutama melihat bahasa verbal dan input suara yang sebenarnya.
2. Paten versi kedua dan ketiga menjelaskan pemecahan transkrip input suara ke dalam ngram, yang dapat membantu n menghitung statistik tentang kemunculan input suara yang digunakan.
3. Klaim versi terbaru dan ketiga dari status dialog penetapan Paten untuk model bahasa menyebutkan penggunaan pengenal kecepatan.
- Yang diklaim adalah:
- 1. Metode yang diterapkan komputer, terdiri dari: menerima, pada sistem komputasi, data audio yang menunjukkan input suara pertama yang diberikan ke perangkat komputasi; menentukan bahwa input suara pertama adalah bagian dari dialog suara yang mencakup sejumlah status dialog yang telah ditentukan sebelumnya yang diatur untuk menerima serangkaian input suara yang terkait dengan tugas tertentu, di mana setiap status dialog dipetakan ke:
- (i) satu set data tampilan yang mencirikan konten yang ditujukan untuk tampilan saat input suara untuk status dialog diterima, dan
- (ii) satu set n-gram; menerima, pada sistem komputasi, data tampilan pertama yang mencirikan konten yang ditampilkan pada layar perangkat komputasi ketika input suara pertama diberikan ke perangkat komputasi
- Memilih, oleh sistem komputasi, keadaan dialog tertentu dari pluralitas keadaan dialog yang telah ditentukan sebelumnya yang sesuai dengan input suara pertama, termasuk menentukan kecocokan antara data tampilan pertama dan kumpulan data tampilan yang sesuai yang dipetakan ke keadaan dialog
- Bias model bahasa dengan menyesuaikan skor probabilitas yang ditunjukkan oleh model bahasa untuk n-gram dalam set n-gram yang sesuai yang dipetakan ke status dialog tertentu
- Transkripsi input suara menggunakan model bahasa bias.
Menentukan status dialog untuk model bahasa
Penemu: Petar Aleksic, dan Pedro J. Moreno Mengibar
Penerima tugas: Google LLC
Paten AS: 11.264.028
Diberikan: 1 Maret 2022
Diarsipkan: 2 Januari 2020
Abstrak
Sistem, metode, perangkat, dan teknik lainnya dijelaskan di sini untuk menentukan status dialog yang sesuai dengan input suara dan untuk membiaskan model bahasa berdasarkan status dialog yang ditentukan. Dalam beberapa implementasi, suatu metode mencakup penerimaan, pada sistem komputasi, data audio yang menunjukkan input suara dan menentukan status dialog tertentu, dari antara sejumlah status dialog, yang sesuai dengan input suara. Satu set n-gram dapat diidentifikasi yang terkait dengan status dialog tertentu yang sesuai dengan input suara. Sebagai tanggapan untuk mengidentifikasi himpunan n-gram yang terkait dengan status dialog tertentu yang sesuai dengan input suara, model bahasa dapat dibias dengan menyesuaikan skor probabilitas yang ditunjukkan oleh model bahasa untuk n-gram dalam himpunan n- gram. Masukan suara dapat ditranskripsikan menggunakan model bahasa yang disesuaikan.
Cari Berita Langsung Ke Kotak Masuk Anda
*Diperlukan