
Aggiornata la determinazione degli stati di dialogo per i modelli linguistici
Pubblicato: 2022-03-16Le prime affermazioni sulla determinazione degli stati di dialogo per i modelli linguistici
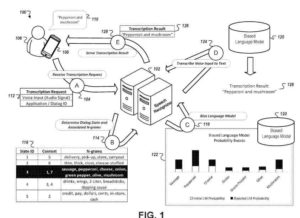
È probabile che tu abbia visto i brevetti di dialogo da uomo a computer di Google. Ne ho scritto di alcuni in passato. Eccone due che forniscono molti dettagli su tale finestra di dialogo:
- Dialogo da uomo a computer su Google
- Contenuto non richiesto nella finestra di dialogo da uomo a computer
Oltre a esaminare attentamente i brevetti che coinvolgono il dialogo da uomo a computer, vale la pena dedicare tempo all'elaborazione del linguaggio naturale e alle comunicazioni tra esseri umani e computer. Ho anche scritto di alcuni di questi. Eccone un paio:
- L'Assistente Google e l'elaborazione del linguaggio naturale basata sul contesto
- Risposte alle query in linguaggio naturale
Questo brevetto Google Determining Dialog States For Language Models è stato aggiornato due volte, con l'ultima versione rilasciata all'inizio di questa settimana. L'ultima prima affermazione è un po' più lunga e ha alcune nuove parole aggiunte.
Idealmente, questi brevetti devono iniziare con uno sguardo approfondito al linguaggio delle rivendicazioni.
La seconda versione degli stati di dialogo per la determinazione dei modelli linguistici, depositata il 18 2018 e concessa il 4 febbraio 2020, inizia con la seguente affermazione:
- Ciò che si sostiene è:
- 1. Un metodo implementato al computer, comprendente:
- Ricezione, da parte di un dispositivo informatico, di dati audio per un input vocale al dispositivo informatico, in cui l'input vocale corrisponde a una fase sconosciuta di un dialogo vocale a più stadi tra il dispositivo informatico e un utente del dispositivo informatico
- Determinazione di una previsione iniziale per la fase sconosciuta del dialogo vocale multifase
Fornire, tramite il dispositivo informatico e un sistema di dialogo vocale,- (i) i dati audio per l'input vocale al dispositivo informatico e
- (ii) un'indicazione della previsione iniziale per lo stadio sconosciuto del dialogo vocale multistadio
- Ricevere, dal dispositivo informatico e dal sistema di dialogo vocale, una trascrizione dell'input vocale, in cui la trascrizione è stata generata elaborando i dati audio con un modello che è stato distorto secondo parametri che corrispondono a una predizione raffinata per lo stadio sconosciuto di il dialogo vocale multistadio, in cui il sistema di dialogo vocale è configurato per determinare la predizione raffinata per la fase sconosciuta del dialogo vocale multistadio in base a (i) la previsione iniziale per la fase sconosciuta del dialogo vocale multistadio e
- (ii) informazioni aggiuntive che descrivono un contesto dell'input vocale e in cui le informazioni aggiuntive che descrivono il contesto dell'input vocale sono indipendenti dal contenuto di
- l'input vocale; e presentare la trascrizione della voce immessa con il dispositivo informatico.
La prima versione di questo brevetto di continuazione, Determinazione degli stati di dialogo per i modelli linguistici, depositata il 16 marzo 2016 e rilasciata il 22 maggio 2018, inizia con questa affermazione:
- Ciò che si sostiene è:
- 1. Un metodo implementato al computer, comprendente:
- Ricezione, in un sistema informatico, di dati audio che indicano un primo input vocale fornito a un dispositivo informatico
- Determinare che il primo input vocale fa parte di un dialogo vocale che include una pluralità di stati di dialogo predefiniti predisposti per ricevere una serie di input vocali relativi a un compito particolare, in cui ogni stato del dialogo è mappato su: (i) un insieme di visualizzare i dati che caratterizzano il contenuto designato per la visualizzazione quando vengono ricevuti input vocali per lo stato del dialogo e
(ii) un insieme di n-grammi - Ricevere, presso il sistema informatico, i primi dati di visualizzazione che caratterizzano il contenuto che è stato visualizzato su uno schermo del dispositivo informatico quando è stato fornito il primo input vocale al dispositivo informatico; selezionando, da parte del sistema informatico, un particolare stato di dialogo della pluralità di stati di dialogo predefiniti che corrisponde al primo input vocale, inclusa la determinazione di una corrispondenza tra i primi dati di visualizzazione e il corrispondente insieme di dati di visualizzazione che è mappato al particolare stato del dialogo; distorcere un modello linguistico regolando i punteggi di probabilità che il modello linguistico indica per n-grammi nel corrispondente insieme di n-grammi che sono mappati al particolare stato del dialogo; e trascrivere l'input vocale utilizzando il modello linguistico parziale.
La prima richiesta più recente nell'ultima versione di questo brevetto, Determinazione degli stati di dialogo per i modelli linguistici, è stata depositata il 2 gennaio 2020 e concessa il 1 marzo 2022. Ci dice:
- Ciò che si sostiene è:
- 1. Un metodo implementato al computer, comprendente:
- Ottenere trascrizioni di input vocali da un set di addestramento di input vocali, in cui ogni input vocale nel set di addestramento di input vocali è diretto a uno di una pluralità di fasi di un'attività vocale a più stadi
- Ottenere i dati di visualizzazione associati a ciascun input vocale dal set di addestramento degli input vocali che caratterizza il contenuto designato per la visualizzazione quando viene ricevuto l'input vocale associato; generare una pluralità di gruppi di trascrizioni, in cui ciascun gruppo di trascrizioni include un diverso sottoinsieme delle trascrizioni di input vocali dal set di addestramento di input vocali
- Assegnare ciascun gruppo di trascrizioni a uno stato di dialogo diverso di un modello di stato di dialogo che include una pluralità di stati di dialogo, in cui ogni stato di dialogo della pluralità di stati di dialogo: corrisponde a un diverso stadio dell'attività vocale a più stadi; ed è mappato su un rispettivo insieme di dati di visualizzazione che caratterizzano il contenuto che è designato per la visualizzazione quando vengono ricevuti input vocali dall'insieme di addestramento di input vocali che sono associati al gruppo di trascrizioni assegnate allo stato di dialogo; per ciascun gruppo di trascrizioni, determinando un insieme rappresentativo di n-grammi per il gruppo e associando l'insieme rappresentativo di n-grammi per il gruppo con il corrispondente stato di dialogo del modello di stato di dialogo a cui è assegnato il gruppo, in cui il insieme rappresentativo di n-grammi determinato per il gruppo di trascrizioni comprende n-grammi che soddisfano un numero soglia di occorrenze nel gruppo di trascrizioni assegnato allo stato di dialogo del modello di stato di dialogo
- Ricezione di un successivo input vocale e prima visualizzazione dei dati che caratterizzano il contenuto che è stato visualizzato su uno schermo quando è stato ricevuto il successivo input vocale, il successivo input vocale diretto verso una fase particolare dell'attività vocale a più stadi
Determinazione di una corrispondenza tra i primi dati di visualizzazione e il rispettivo set di dati di visualizzazione mappati allo stato del dialogo nel modello dello stato del dialogo che corrisponde alla fase particolare dell'attività a più voci - Elaborazione, con un riconoscitore vocale, del successivo input vocale e dei primi dati di visualizzazione, inclusa la polarizzazione del riconoscitore vocale utilizzando l'insieme rappresentativo di n-grammi associato allo stato del dialogo nel modello dello stato del dialogo che corrisponde allo stadio particolare del attività a più voci
\
Confrontando le affermazioni degli stati di dialogo determinanti per i modelli linguistici
Queste sono alcune delle differenze che vedo con le diverse versioni del brevetto:

1. Tutte e tre le versioni ci dicono che si tratta di "input vocali", che agiscono come parte di un set di formazione.
Quindi, a differenza dei precedenti brevetti sugli stati di dialogo tra esseri umani e computer, incentrati sul contenuto del dialogo, questo brevetto esamina principalmente il linguaggio verbale e gli input vocali effettivi.
2. La seconda e la terza versione del brevetto descrivono la suddivisione delle trascrizioni degli input vocali in ngram, che possono essere utili nel calcolo di statistiche sulle occorrenze degli input vocali utilizzati.
3. La rivendicazione della versione più recente e della terza versione degli stati di dialogo per l'eliminazione dei brevetti per i modelli linguistici menziona l'uso di un riconoscitore di velocità.
- Ciò che si sostiene è:
- 1. Un metodo implementato da computer, comprendente: ricevere, in un sistema informatico, dati audio che indicano un primo input vocale fornito a un dispositivo informatico; determinare che il primo input vocale fa parte di un dialogo vocale che include una pluralità di stati di dialogo predefiniti predisposti per ricevere una serie di input vocali relativi a un'attività particolare, in cui ogni stato del dialogo è mappato a:
- (i) un insieme di dati di visualizzazione che caratterizzano il contenuto che è designato per la visualizzazione quando vengono ricevuti input vocali per lo stato del dialogo, e
- (ii) un insieme di n-grammi; ricevere, presso il sistema informatico, i primi dati di visualizzazione che caratterizzano il contenuto che è stato visualizzato su uno schermo del dispositivo informatico quando è stato fornito il primo input vocale al dispositivo informatico
- Selezionando, da parte del sistema informatico, un particolare stato di dialogo della pluralità di stati di dialogo predefiniti che corrisponde al primo input vocale, inclusa la determinazione di una corrispondenza tra i primi dati di visualizzazione e il corrispondente insieme di dati di visualizzazione che è mappato al particolare stato del dialogo
- Distorcere un modello linguistico regolando i punteggi di probabilità che il modello linguistico indica per n-grammi nel corrispondente insieme di n-grammi che sono mappati al particolare stato del dialogo
- Trascrivere l'input vocale utilizzando il modello linguistico parziale.
Determinazione degli stati di dialogo per i modelli linguistici
Inventori: Petar Aleksic e Pedro J. Moreno Mengibar
Assegnatario: Google LLC
Brevetto USA: 11.264.028
Concesso: 1 marzo 2022
Archiviato: 2 gennaio 2020
Astratto
Sistemi, metodi, dispositivi e altre tecniche sono descritti nel presente documento per determinare gli stati di dialogo che corrispondono a input vocali e per influenzare un modello linguistico basato sugli stati di dialogo determinati. In alcune implementazioni, un metodo include ricevere, in un sistema informatico, dati audio che indicano un input vocale e determinare un particolare stato di dialogo, tra una pluralità di stati di dialogo, che corrisponde all'input vocale. È possibile identificare un insieme di n-grammi associati al particolare stato del dialogo che corrisponde all'input vocale. In risposta all'identificazione dell'insieme di n-grammi associati al particolare stato del dialogo che corrisponde all'input vocale, un modello linguistico può essere distorto regolando i punteggi di probabilità che il modello linguistico indica per n-grammi nell'insieme di n- grammi. L'input vocale può essere trascritto utilizzando il modello linguistico adattato.
Cerca notizie direttamente nella tua casella di posta
*Necessario