
Determinación de estados de diálogo para modelos de lenguaje Actualizado
Publicado: 2022-03-16Las primeras afirmaciones de determinar los estados de diálogo para los modelos de lenguaje
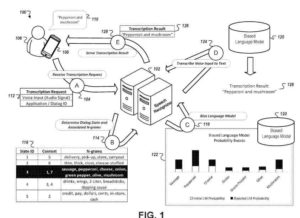
Lo más probable es que haya visto patentes de diálogo de persona a computadora de Google. He escrito sobre algunos en el pasado. Aquí hay dos que proporcionan muchos detalles sobre dicho diálogo:
- Diálogo humano a computadora en Google
- Contenido no solicitado en diálogo humano a computadora
Además de analizar detenidamente las patentes que implican el diálogo entre humanos y computadoras, vale la pena dedicar tiempo al procesamiento del lenguaje natural y las comunicaciones entre seres humanos y computadoras. También he escrito sobre algunos de ellos. Aquí hay un par de ellos:
- El Asistente de Google y el procesamiento del lenguaje natural basado en el contexto
- Respuestas a consultas en lenguaje natural
Esta patente de Google Determinating Dialog States For Language Models se actualizó dos veces y la última versión se otorgó a principios de esta semana. El último primer reclamo es un poco más largo y se le agregaron algunas palabras nuevas.
Idealmente, estas patentes deben comenzar con una mirada profunda al lenguaje de las reivindicaciones.
La segunda versión de Determinación de estados de diálogo para modelos de lenguaje, presentada el 18 de 2018 y otorgada el 4 de febrero de 2020, comienza con la siguiente afirmación:
- Lo reclamado es:
- 1. Un método implementado por computadora, que comprende:
- Recibir, por un dispositivo informático, datos de audio para una entrada de voz al dispositivo informático, donde la entrada de voz corresponde a una etapa desconocida de un diálogo de voz de múltiples etapas entre el dispositivo informático y un usuario del dispositivo informático
- Determinar una predicción inicial para la etapa desconocida del diálogo de voz de varias etapas
Proporcionar, mediante el dispositivo informático y a un sistema de diálogo de voz,- (i) los datos de audio para la entrada de voz al dispositivo informático y
- (ii) una indicación de la predicción inicial para la etapa desconocida del diálogo de voz de múltiples etapas
- Recibir, por parte del dispositivo de cómputo y del sistema de diálogo de voz, una transcripción de la entrada de voz, en donde la transcripción fue generada procesando los datos de audio con un modelo que fue sesgado de acuerdo a parámetros que corresponden a una predicción refinada para la etapa desconocida de el diálogo de voz de múltiples etapas, en el que el sistema de diálogo de voz está configurado para determinar la predicción refinada para la etapa desconocida del diálogo de voz de múltiples etapas en función de (i) la predicción inicial para la etapa desconocida del diálogo de voz de múltiples etapas y
- (ii) información adicional que describe un contexto de la entrada de voz, y donde la información adicional que describe el contexto de la entrada de voz es independiente del contenido de
- la entrada de voz; y presentar la transcripción de la entrada de voz con el dispositivo informático.
La primera versión de esta continuación de patente, Determinación de estados de diálogo para modelos de lenguaje, presentada el 16 de marzo de 2016 y otorgada el 22 de mayo de 2018, comienza con esta reivindicación:
- Lo reclamado es:
- 1. Un método implementado por computadora, que comprende:
- Recibir, en un sistema informático, datos de audio que indican una primera entrada de voz que se proporcionó a un dispositivo informático
- Determinar que la primera entrada de voz es parte de un diálogo de voz que incluye una pluralidad de estados de diálogo predefinidos dispuestos para recibir una serie de entradas de voz relacionadas con una tarea particular, donde cada estado de diálogo se asigna a: (i) un conjunto de mostrar datos que caracterizan el contenido que está designado para mostrarse cuando se reciben entradas de voz para el estado de diálogo, y
(ii) un conjunto de n-gramas - Recibir, en el sistema informático, los primeros datos de visualización que caracterizan el contenido que se mostró en una pantalla del dispositivo informático cuando se proporcionó la primera entrada de voz al dispositivo informático; seleccionando, mediante el sistema informático, un estado de diálogo particular de la pluralidad de estados de diálogo predefinidos que corresponde a la primera entrada de voz, incluida la determinación de una coincidencia entre los primeros datos de visualización y el conjunto correspondiente de datos de visualización que se asigna al particular estado de diálogo; sesgar un modelo de lenguaje ajustando las puntuaciones de probabilidad que indica el modelo de lenguaje para n-gramas en el conjunto correspondiente de n-gramas que se asignan al estado de diálogo particular; y transcribir la entrada de voz usando el modelo de lenguaje sesgado.
El primer reclamo más reciente en la última versión de esta patente, Determinación de estados de diálogo para modelos de lenguaje, se presentó el 2 de enero de 2020 y se otorgó el 1 de marzo de 2022. Nos dice:
- Lo reclamado es:
- 1. Un método implementado por computadora, que comprende:
- Obtener transcripciones de entradas de voz a partir de un conjunto de entradas de voz de entrenamiento, en el que cada entrada de voz en el conjunto de entradas de voz de entrenamiento se dirige a una de una pluralidad de etapas de una actividad de voz de múltiples etapas
- Obtener datos de visualización asociados con cada entrada de voz del conjunto de entrenamiento de entradas de voz que caracteriza el contenido que está designado para visualización cuando se recibe la entrada de voz asociada; generar una pluralidad de grupos de transcripciones, donde cada grupo de transcripciones incluye un subconjunto diferente de las transcripciones de entradas de voz del conjunto de entrenamiento de entradas de voz
- Asignar cada grupo de transcripciones a un estado de diálogo diferente de un modelo de estado de diálogo que incluye una pluralidad de estados de diálogo, en el que cada estado de diálogo de la pluralidad de estados de diálogo: corresponde a una etapa diferente de la actividad de voz de múltiples etapas; y se asigna a un conjunto respectivo de los datos de visualización que caracterizan el contenido que se designa para visualización cuando se reciben entradas de voz del conjunto de entrenamiento de entradas de voz que están asociadas con el grupo de transcripciones asignadas al estado de diálogo; para cada grupo de transcripciones, determinando un conjunto representativo de n-gramas para el grupo, y asociando el conjunto representativo de n-gramas para el grupo con el estado de diálogo correspondiente del modelo de estado de diálogo al que se asigna el grupo, donde el conjunto representativo de n-gramas determinado para el grupo de transcripciones comprende n-gramas que satisfacen un número umbral de ocurrencias en el grupo de transcripciones asignadas al estado de diálogo del modelo de estado de diálogo
- Recepción de una entrada de voz subsiguiente y primeros datos de visualización que caracterizan el contenido que se mostró en una pantalla cuando se recibió la entrada de voz subsiguiente, la entrada de voz subsiguiente dirigida hacia una etapa particular de la actividad de voz de múltiples etapas
Determinar una coincidencia entre los primeros datos de visualización y el conjunto respectivo de datos de visualización asignados al estado de diálogo en el modelo de estado de diálogo que corresponde a la etapa particular de la actividad de múltiples voces - Procesar, con un reconocedor de voz, la entrada de voz subsiguiente y los primeros datos de visualización, incluida la polarización del reconocedor de voz utilizando el conjunto representativo de n-gramas asociados con el estado de diálogo en el modelo de estado de diálogo que corresponde a la etapa particular del actividad de varias voces
\
Comparación de las afirmaciones de los estados de diálogo determinantes para los modelos de lenguaje
Estas son algunas de las diferencias que estoy viendo con las distintas versiones de la patente:

1. Las tres versiones nos dicen que se trata de "entradas de voz", que actúan como parte de un conjunto de entrenamiento.
Entonces, a diferencia de las patentes anteriores sobre los estados de diálogo entre humanos y computadoras, que se enfocaban en el contenido del diálogo, esta patente analiza principalmente el lenguaje verbal y las entradas de voz reales.
2. Las versiones segunda y tercera de la patente describen la división de transcripciones de las entradas de voz en ngramas, lo que puede ser útil para calcular estadísticas sobre las ocurrencias de las entradas de voz utilizadas.
3. El reclamo de la tercera versión más nueva de los estados de diálogo de determinación de patentes para modelos de lenguaje menciona el uso de un reconocedor de velocidad.
- Lo reclamado es:
- 1. Un método implementado por computadora, que comprende: recibir, en un sistema informático, datos de audio que indican una primera entrada de voz que se proporcionó a un dispositivo informático; determinando que la primera entrada de voz es parte de un diálogo de voz que incluye una pluralidad de estados de diálogo predefinidos dispuestos para recibir una serie de entradas de voz relacionadas con una tarea particular, donde cada estado de diálogo se asigna a:
- (i) un conjunto de datos de visualización que caracterizan el contenido designado para su visualización cuando se reciben entradas de voz para el estado de diálogo, y
- (ii) un conjunto de n-gramas; recibir, en el sistema informático, los primeros datos de visualización que caracterizan el contenido que se mostró en una pantalla del dispositivo informático cuando se proporcionó la primera entrada de voz al dispositivo informático
- Seleccionar, mediante el sistema informático, un estado de diálogo particular de la pluralidad de estados de diálogo predefinidos que corresponde a la primera entrada de voz, incluida la determinación de una coincidencia entre los primeros datos de visualización y el conjunto correspondiente de datos de visualización que se asigna al particular estado de diálogo
- Sesgar un modelo de lenguaje ajustando las puntuaciones de probabilidad que el modelo de lenguaje indica para n-gramas en el conjunto correspondiente de n-gramas que se asignan al estado de diálogo particular
- Transcripción de la entrada de voz utilizando el modelo de lenguaje sesgado.
Determinación de estados de diálogo para modelos de lenguaje
Inventores: Petar Aleksic y Pedro J. Moreno Mengibar
Cesionario: Google LLC
Patente de EE. UU.: 11,264,028
Concedido: 1 de marzo de 2022
Archivado: 2 de enero de 2020
Resumen
Los sistemas, métodos, dispositivos y otras técnicas se describen aquí para determinar los estados de diálogo que corresponden a las entradas de voz y para sesgar un modelo de lenguaje basado en los estados de diálogo determinados. En algunas implementaciones, un método incluye recibir, en un sistema informático, datos de audio que indican una entrada de voz y determinar un estado de diálogo particular, entre una pluralidad de estados de diálogo, que corresponde a la entrada de voz. Se puede identificar un conjunto de n-gramas que están asociados con el estado de diálogo particular que corresponde a la entrada de voz. En respuesta a la identificación del conjunto de n-gramas que están asociados con el estado de diálogo particular que corresponde a la entrada de voz, se puede sesgar un modelo de lenguaje ajustando las puntuaciones de probabilidad que el modelo de lenguaje indica para los n-gramas en el conjunto de n-gramas. gramos La entrada de voz se puede transcribir usando el modelo de lenguaje ajustado.
Busque noticias directamente en su bandeja de entrada
*Requerido