
Określanie stanów dialogu dla zaktualizowanych modeli językowych
Opublikowany: 2022-03-16Pierwsze twierdzenia dotyczące określania stanów dialogu dla modeli językowych
Prawdopodobnie widziałeś patenty Google dotyczące dialogu między człowiekiem a komputerem. O niektórych pisałem już w przeszłości. Oto dwa, które dostarczają wielu szczegółów na temat takiego okna dialogowego:
- Dialog człowiek-komputer w Google
- Niezamawiane treści w dialogu człowiek-komputer
Oprócz uważnego przyjrzenia się patentom dotyczącym dialogu człowieka z komputerem, warto poświęcić czas na przetwarzanie języka naturalnego i komunikację między ludźmi a komputerami. O kilku z nich też pisałem. Oto kilka z nich:
- Asystent Google i kontekstowe przetwarzanie języka naturalnego
- Odpowiedzi na zapytania w języku naturalnym
Ten patent Google Determining Dialog States For Language Models został zaktualizowany dwukrotnie, a najnowsza wersja została przyznana na początku tego tygodnia. Ostatnie pierwsze twierdzenie jest nieco dłuższe i zawiera kilka nowych słów.
Najlepiej byłoby, gdyby te patenty zaczynały się od dokładnego przyjrzenia się językowi oświadczeń.
Druga wersja dokumentu Określanie stanów okna dialogowego dla modeli językowych, zgłoszona 18 2018 r. i przyznana 4 lutego 2020 r., zaczyna się od następującego roszczenia:
- Twierdzi się, że:
- 1. Metoda realizowana komputerowo, obejmująca:
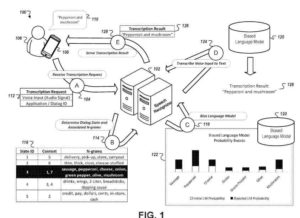
- Odbieranie za pomocą urządzenia komputerowego danych dźwiękowych do wprowadzania głosowego do urządzenia komputerowego, przy czym dane wejściowe głosowe odpowiadają nieznanemu etapowi wieloetapowego dialogu głosowego między urządzeniem komputerowym a użytkownikiem urządzenia komputerowego
- Określanie wstępnej prognozy dla nieznanego etapu wieloetapowego dialogu głosowego
Dostarczanie przez urządzenie obliczeniowe i do systemu dialogu głosowego,- (i) dane dźwiękowe do wprowadzania głosowego do urządzenia komputerowego oraz
- (ii) wskazanie wstępnej prognozy dla nieznanego etapu wieloetapowego dialogu głosowego
- Odbieranie, przez urządzenie obliczeniowe i z systemu dialogu głosowego, transkrypcji głosu, przy czym transkrypcja została wygenerowana przez przetworzenie danych audio za pomocą modelu, który był stronniczy zgodnie z parametrami, które odpowiadają udoskonalonej prognozie dla nieznanego etapu wieloetapowego dialogu głosowego, w którym system dialogu głosowego jest skonfigurowany do określania udoskonalonej predykcji dla nieznanego etapu wieloetapowego dialogu głosowego na podstawie (i) wstępnej predykcji dla nieznanego etapu wieloetapowego dialogu głosowego oraz
- (ii) dodatkowe informacje opisujące kontekst wprowadzania głosowego, przy czym dodatkowe informacje opisujące kontekst wprowadzania głosowego są niezależne od treści
- wejście głosowe; oraz prezentacja transkrypcji głosu za pomocą urządzenia komputerowego.
Pierwsza wersja tego patentu kontynuacyjnego, Określanie stanów dialogu dla modeli językowych, zgłoszona 16 marca 2016 r. i przyznana 22 maja 2018 r., zaczyna się następującym zastrzeżeniem:
- Twierdzi się, że:
- 1. Metoda realizowana komputerowo, obejmująca:
- Odbieranie w systemie komputerowym danych dźwiękowych wskazujących na pierwsze wejście głosowe przekazane do urządzenia komputerowego
- Ustalenie, że pierwsze wejście głosowe jest częścią dialogu głosowego, który zawiera wiele predefiniowanych stanów dialogu dostosowanych do odbierania serii wejść głosowych związanych z określonym zadaniem, przy czym każdy stan dialogu jest mapowany na: (i) zestaw wyświetlić dane charakteryzujące treść, która jest przeznaczona do wyświetlenia po odebraniu danych wejściowych głosowych dla stanu dialogu, oraz
(ii) zbiór n-gramów - Odbieranie, w systemie obliczeniowym, najpierw danych wyświetlania, które charakteryzują treści, które były wyświetlane na ekranie urządzenia komputerowego, gdy pierwsze wejście głosowe zostało dostarczone do urządzenia komputerowego; wybieranie przez system obliczeniowy określonego stanu dialogu spośród wielu predefiniowanych stanów dialogu, który odpowiada pierwszemu wejściu głosowemu, w tym określanie dopasowania między pierwszymi wyświetlanymi danymi a odpowiednim zestawem wyświetlanych danych, który jest odwzorowany na konkretny stan okna dialogowego; obciążanie modelu językowego przez dostosowanie wyników prawdopodobieństwa, które model językowy wskazuje dla n-gramów w odpowiednim zestawie n-gramów, które są mapowane do określonego stanu dialogu; oraz transkrypcję głosu przy użyciu tendencyjnego modelu językowego.
Najnowsze pierwsze roszczenie w najnowszej wersji tego patentu, Określanie stanów dialogu dla modeli językowych, zostało zgłoszone 2 stycznia 2020 r. i przyznane 1 marca 2022 r. Mówi nam:
- Twierdzi się, że:
- 1. Metoda realizowana komputerowo, obejmująca:
- Uzyskiwanie transkrypcji danych wejściowych głosowych ze zbioru treningowego wejść głosowych, przy czym każde wejście głosowe w zbiorze treningowym wejść głosowych jest kierowane do jednego z wielu etapów wieloetapowej czynności głosowej
- Uzyskiwanie danych wyświetlania związanych z każdym wejściem głosowym ze zbioru uczącego wejść głosowych, który charakteryzuje treść, która jest przeznaczona do wyświetlania po odebraniu skojarzonego wejścia głosowego; generowanie wielu grup transkrypcji, przy czym każda grupa transkrypcji zawiera inny podzbiór transkrypcji wejść głosowych z zestawu treningowego wejść głosowych
- Przypisywanie każdej grupy transkrypcji do innego stanu dialogu modelu stanów dialogu, który obejmuje wiele stanów dialogu, przy czym każdy stan dialogu z wielu stanów dialogu: odpowiada innemu etapowi wieloetapowej aktywności głosowej; i jest odwzorowywany na odpowiedni zestaw danych wyświetlania charakteryzujących zawartość, która jest przeznaczona do wyświetlania, gdy odbierane są wejścia głosowe z zestawu uczącego wejść głosowych, które są skojarzone z grupą transkrypcji przypisanych do stanu dialogu; dla każdej grupy transkrypcji określenie reprezentatywnego zestawu n-gramów dla grupy i powiązanie reprezentatywnego zestawu n-gramów dla grupy z odpowiednim stanem okna dialogowego modelu stanu okna dialogowego, do którego grupa jest przypisana, przy czym reprezentatywny zbiór n-gramów wyznaczony dla grupy transkrypcji zawiera n-gramy – spełniającą progową liczbę wystąpień w grupie transkrypcji przypisanych do stanu dialogu modelu stan dialogu
- Odbieranie kolejnej informacji głosowej i pierwsze wyświetlanie danych charakteryzujących treść, która była wyświetlana na ekranie po odebraniu kolejnych informacji głosowych, kolejne wprowadzanie głosowe skierowane do określonego etapu wieloetapowej czynności głosowej
Określanie dopasowania między pierwszymi wyświetlanymi danymi a odpowiednim zestawem wyświetlanych danych odwzorowanych na stan okna dialogowego w modelu stanu okna dialogowego, który odpowiada konkretnemu etapowi działania wielogłosowego - Przetwarzanie za pomocą aparatu rozpoznawania mowy kolejnych danych wejściowych głosowych i pierwszych wyświetlanych danych, w tym obciążanie aparatu rozpoznawania mowy przy użyciu reprezentatywnego zestawu n-gramów skojarzonych ze stanem okna dialogowego w modelu stanu okna dialogowego, który odpowiada konkretnemu etapowi aktywność wielogłosowa
\
Porównanie twierdzeń o określaniu stanów dialogu dla modeli językowych
Oto niektóre z różnic, które dostrzegam w różnych wersjach patentu:

1. Wszystkie trzy wersje mówią nam, że dotyczą „wprowadzania głosowego”, które działają jako część zestawu treningowego.
Tak więc w przeciwieństwie do poprzednich patentów dotyczących stanów Dialogu między ludźmi a komputerami, które koncentrowały się na treści dialogu, ten patent dotyczy przede wszystkim języka werbalnego i rzeczywistych danych wejściowych głosowych.
2. Druga i trzecia wersja patentu opisują rozbijanie transkrypcji wejść głosowych na ngramy, co może być pomocne przy obliczaniu statystyk dotyczących występowania użytych wejść głosowych.
3. Zastrzeżenie najnowszej i trzeciej wersji Patent etermining dialog states dla modeli językowych wspomina o użyciu rozpoznawania szybkości.
- Twierdzi się, że:
- 1. Sposób realizowany komputerowo, obejmujący: odbieranie w systemie komputerowym danych audio, które wskazują pierwsze wejście głosowe, które zostało dostarczone do urządzenia komputerowego; określenie, że pierwsze wejście głosowe jest częścią dialogu głosowego, który zawiera wiele predefiniowanych stanów dialogu dostosowanych do odbierania serii wejść głosowych związanych z określonym zadaniem, przy czym każdy stan dialogu jest odwzorowywany na:
- (i) zestaw wyświetlanych danych charakteryzujących treść, który jest przeznaczony do wyświetlenia po odebraniu danych wejściowych głosowych dla stanu dialogu, oraz
- (ii) zbiór n-gramów; odbieranie w systemie obliczeniowym pierwszych wyświetlanych danych, które charakteryzują treści, które były wyświetlane na ekranie urządzenia obliczeniowego, gdy pierwsze wejście głosowe zostało dostarczone do urządzenia obliczeniowego
- Wybieranie przez system obliczeniowy określonego stanu dialogu spośród wielu predefiniowanych stanów dialogu, który odpowiada pierwszemu wejściu głosowemu, w tym określanie dopasowania między pierwszymi wyświetlanymi danymi a odpowiednim zestawem wyświetlanych danych, który jest odwzorowany na konkretny stan okna dialogowego
- Promowanie modelu językowego przez dostosowanie wyników prawdopodobieństwa, które model językowy wskazuje dla n-gramów w odpowiednim zestawie n-gramów, które są mapowane do określonego stanu okna dialogowego
- Transkrypcja wprowadzania głosowego przy użyciu tendencyjnego modelu językowego.
Określanie stanów dialogów dla modeli językowych
Wynalazcy: Petar Aleksic i Pedro J. Moreno Mengibar
Pełnomocnik: Google LLC
Patent USA: 11.264.028
Przyznano: 1 marca 2022
Złożono: 2 stycznia 2020 r.
Abstrakcyjny
W niniejszym dokumencie opisano systemy, metody, urządzenia i inne techniki służące do określania stanów dialogu, które odpowiadają wprowadzanym głosom, oraz do odchylania modelu języka na podstawie określonych stanów dialogu. W niektórych implementacjach sposób obejmuje odbieranie w systemie komputerowym danych audio, które wskazują dane wejściowe głosowe i określanie określonego stanu dialogu spośród wielu stanów dialogu, które odpowiadają wprowadzaniu głosowemu. Można zidentyfikować zestaw n-gramów, które są powiązane z konkretnym stanem okna dialogowego, który odpowiada wejściu głosowemu. W odpowiedzi na zidentyfikowanie zbioru n-gramów, które są powiązane z konkretnym stanem dialogu, który odpowiada wejściu głosowemu, model językowy może zostać obciążony poprzez dostosowanie wyników prawdopodobieństwa, które model językowy wskazuje dla n-gramów w zbiorze n- gramy. Wprowadzanie głosowe można transkrybować za pomocą dostosowanego modelu językowego.
Przeszukaj wiadomości prosto do skrzynki odbiorczej
*Wymagany