
確定語言模型的對話狀態已更新
已發表: 2022-03-16為語言模型確定對話狀態的第一個聲明
您可能已經看過 Google 的人機對話專利。 我過去寫過一些。 這裡有兩個提供了有關此類對話框的大量詳細信息:
- Google 的人機對話
- 人機對話中未經請求的內容
除了仔細研究涉及人機對話的專利外,還值得花時間研究自然語言處理以及人機之間的通信。 我也寫過其中的一些。 以下是其中的幾個:
- Google 助理和基於上下文的自然語言處理
- 自然語言查詢響應
Google Determining Dialog States For Language Models 專利現在已經更新了兩次,最新版本在本週早些時候被授予。 最新的第一個聲明稍長一些,並添加了一些新詞。
理想情況下,這些專利必須從深入研究權利要求的語言開始。
2018 年 18 月 18 日提交並於 2020 年 2 月 4 日授予的第二版確定語言模型的對話狀態,從以下聲明開始:
- 聲稱的是:
- 1.一種計算機實現的方法,包括:
- 由計算設備接收用於向計算設備輸入的語音的音頻數據,其中語音輸入對應於計算設備和計算設備的用戶之間的多階段語音對話的未知階段
- 確定多階段語音對話的未知階段的初始預測
由計算設備向語音對話系統提供,- (i) 語音輸入到計算設備的音頻數據,以及
- (ii) 對多階段語音對話的未知階段的初始預測的指示
- 由計算設備並從語音對話系統接收語音輸入的轉錄,其中轉錄是通過使用模型處理音頻數據而生成的,該模型根據對應於對未知階段的精煉預測的參數有偏差多階段語音對話,其中語音對話系統被配置為基於(i)多階段語音對話的未知階段的初始預測,確定多階段語音對話的未知階段的精細預測,以及
- (ii)描述語音輸入的上下文的附加信息,並且其中描述語音輸入的上下文的附加信息獨立於
- 語音輸入; 並且用計算設備呈現語音輸入的轉錄。
2016 年 3 月 16 日提交並於 2018 年 5 月 22 日獲得授權的此延續專利的第一個版本,即確定語言模型的對話狀態,以以下聲明開頭:
- 聲稱的是:
- 1.一種計算機實現的方法,包括:
- 在計算系統處接收指示提供給計算設備的第一語音輸入的音頻數據
- 確定第一語音輸入是包括多個預定義對話狀態的語音對話的一部分,該多個預定義對話狀態被佈置為接收與特定任務相關的一系列語音輸入,其中每個對話狀態被映射到:(i)一組當接收到對話狀態的語音輸入時,顯示對指定顯示內容進行表徵的數據,以及
(ii) 一組 n-gram - 在計算系統處接收表徵當第一語音輸入被提供給計算設備時顯示在計算設備的屏幕上的內容的第一顯示數據; 由計算系統選擇多個預定義對話狀態中對應於第一語音輸入的特定對話狀態,包括確定第一顯示數據和映射到特定的顯示數據的對應組之間的匹配。對話狀態; 通過調整語言模型為映射到特定對話狀態的相應 n-gram 集合中的 n-gram 指示的概率分數來偏置語言模型; 並使用有偏語言模型轉錄語音輸入。
該專利最新版本中的第一項權利要求,即確定語言模型的對話狀態,於 2020 年 1 月 2 日提交,並於 2022 年 3 月 1 日獲得授權。它告訴我們:
- 聲稱的是:
- 1.一種計算機實現的方法,包括:
- 從語音輸入訓練集中獲得語音輸入的轉錄,其中語音輸入訓練集中的每個語音輸入被引導到多階段語音活動的多個階段之一
- 從語音輸入的訓練集中獲得與每個語音輸入相關聯的顯示數據,該數據表徵在接收到相關聯的語音輸入時指定用於顯示的內容; 生成多個轉錄組,其中每組轉錄包括來自語音輸入訓練集的語音輸入轉錄的不同子集
- 將每組轉錄分配給包括多個對話狀態的對話狀態模型的不同對話狀態,其中多個對話狀態中的每個對話狀態: 對應於多階段語音活動的不同階段; 當接收到來自與分配給對話狀態的轉錄組相關聯的語音輸入訓練集的語音輸入時,將其映射到表徵內容的相應顯示數據集; 對於每組轉錄,確定該組的代表性 n-gram 集合,並將該組的代表性 n-gram 集合與分配給該組的對話狀態模型的對應對話狀態相關聯,其中為轉錄組確定的代表 n-gram 集合包括 n-gram-滿足分配給對話狀態模型的對話狀態的轉錄組中出現的閾值次數
- 接收後續語音輸入和第一顯示數據表徵當接收到後續語音輸入時在屏幕上顯示的內容,後續語音輸入指向多階段語音活動的特定階段
確定第一顯示數據與映射到對話狀態模型中對話狀態的相應顯示數據集之間的匹配,該對話狀態對應於多語音活動的特定階段 - 使用語音識別器處理後續語音輸入和第一顯示數據,包括使用與對話狀態模型中對應於特定階段的對話狀態相關聯的 n-gram 的代表性集合來偏置語音識別器多語音活動
\
比較確定語言模型的對話狀態的聲明
這些是我在不同版本的專利中看到的一些差異:
1. 所有三個版本都告訴我們它們是關於“語音輸入”的,它作為訓練集的一部分。
因此,與之前關於人機對話狀態的專利側重於對話的內容不同,該專利主要著眼於口頭語言和實際語音輸入。
2. 該專利的第二和第三版本描述了將語音輸入的轉錄本分解為 ngram,這有助於計算有關使用的語音輸入出現次數的統計數據。
3. 語言模型的專利確定對話狀態的最新和第三版本的權利要求提到了速度識別器的使用。
- 聲稱的是:
- 1.一種計算機實現的方法,包括: 在計算系統處接收指示提供給計算設備的第一語音輸入的音頻數據; 確定第一語音輸入是包括多個預定義對話狀態的語音對話的一部分,所述多個預定義對話狀態被佈置為接收與特定任務相關的一系列語音輸入,其中每個對話狀態被映射到:
- (i) 一組顯示數據表徵內容,當接收到對話狀態的語音輸入時指定顯示,以及
- (ii) 一組 n-gram; 在計算系統處接收第一顯示數據,該數據表徵當第一語音輸入被提供給計算設備時顯示在計算設備的屏幕上的內容
- 通過計算系統選擇多個預定義對話狀態中對應於第一語音輸入的特定對話狀態,包括確定第一顯示數據和映射到特定的顯示數據的對應組之間的匹配。對話狀態
- 通過調整語言模型為映射到特定對話狀態的相應 n-gram 集合中的 n-gram 指示的概率分數來偏置語言模型
- 使用有偏語言模型轉錄語音輸入。
確定語言模型的對話狀態
發明人:Petar Aleksic 和 Pedro J. Moreno Mengibar
受讓人:谷歌有限責任公司
美國專利:11,264,028
授予:2022 年 3 月 1 日
提交日期:2020 年 1 月 2 日
抽象的
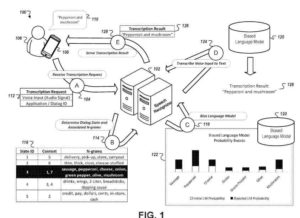
本文描述了用於確定對應於語音輸入的對話狀態以及用於基於所確定的對話狀態來偏置語言模型的系統、方法、設備和其他技術。 在一些實現中,一種方法包括在計算系統處接收指示語音輸入的音頻數據,並從多個對話狀態中確定與語音輸入相對應的特定對話狀態。 可以識別與對應於語音輸入的特定對話狀態相關聯的一組 n-gram。 響應於識別與對應於語音輸入的特定對話狀態相關聯的 n-gram 集合,可以通過調整語言模型為 n-gram 集合中的 n-gram 指示的概率分數來偏置語言模型。克。 可以使用調整後的語言模型轉錄語音輸入。

直接在您的收件箱中搜索新聞
*必需的