
Identificarea relațiilor cu atributele entității
Publicat: 2022-03-02Acest brevet, acordat la 1 martie 2022, se referă la identificarea relațiilor entitate-atribut în corpuri de text.
Aplicațiile de căutare, cum ar fi motoarele de căutare și bazele de cunoștințe, încearcă să răspundă nevoilor informaționale ale celui care caută și să îi arate cele mai avantajoase resurse .
Datele structurate pot ajuta la identificarea mai bună a relațiilor de atribute
Identificarea atributelor relațiilor dintre entități se face în rezultatele de căutare structurate.
Rezultatele căutării structurate prezintă o listă de atribute cu răspunsuri pentru o entitate specificată într-o solicitare a utilizatorului, cum ar fi o interogare .
Deci, rezultatele căutării structurate pentru „Kevin Durant” pot include atribute precum salariul, echipa, anul nașterii, familia etc., împreună cu răspunsuri care oferă informații despre aceste atribute .
Construirea unor astfel de rezultate structurate de căutare poate necesita identificarea relațiilor entitate-atribut.
O relație entitate-atribut este un caz particular de relație text între o pereche de termeni.
Primul termen din perechea de termeni este o entitate, o persoană, un loc, o organizație sau un concept.
Al doilea termen este un atribut sau un șir care descrie un aspect al entității.
Exemplele includ:
- „Data nașterii” unei persoane
- „Populația” unei țări
- „Salariul” sportivului
- „CEO” al unei organizații
Furnizarea de mai multe informații în conținut și schemă (și date structurate) despre entități oferă motorului de căutare mai multe informații pentru a explora informații mai bune despre entitățile specifice, pentru a testa și a colecta date, pentru a dezambigua ceea ce știe și pentru a avea mai multă și mai bună încredere în entitățile care este conștient de.
Perechi entitate-atribut candidat
Acest brevet obține o pereche candidat entitate-atribut pentru a defini o entitate și un atribut, unde atributul este un atribut candidat al entității . Pe lângă faptul că învață din fapte despre entitățile din datele structurate, Google poate folosi informații analizând contextul respectivelor informații și poate învăța din vectori și din apariția concomitentă a altor cuvinte și fapte despre acele entități.
Aruncă o privire la brevetul de vectori de cuvinte pentru a înțelege cum un motor de căutare poate obține acum o înțelegere mai bună a semnificațiilor și contextului cuvintelor și informațiilor despre entități. (Acesta este o șansă de a învăța din explorarea brevetelor despre modul în care Google face acum unele dintre lucrurile pe care le face.) Google colectează fapte și date despre lucrurile pe care le indexează și poate afla despre entitățile pe care le are în indexul său și despre atributele pe care le cunoaște despre ele.
Face asta în:
- Determinarea, cu propoziții care includ entitatea și atributul, dacă atributul este un atribut real al entității din perechea candidat entitate-atribut
- Generarea de înglobări pentru cuvinte în setul de propoziții care includ entitatea și atributul
- Crearea, cu perechile entitate-atribut cunoscute, a unei încorporari de atribute de distribuție pentru entitate, în care încorporarea de atribute de distribuție pentru entitate specifică o încorporare pentru entitate pe baza altor atribute asociate entității din perechile entitate-atribut cunoscute.
- Pe baza înglobărilor pentru cuvinte în propoziții, încorporarea atributului distribuțional pentru entitate și pentru atribut, dacă perechea candidat entitate-atribut este un atribut esențial al entității din perechea candidat entitate-atribut.
Înglobările pentru cuvinte se fac din propoziții cu entitatea și atributul
Construirea unei prime reprezentări vectoriale specificând prima încorporare a cuvintelor între entitate și punctul din setul de propoziții
- Realizarea unei a doua reprezentări vectoriale definind o încorporare dublă pentru entitate pe baza setului de propoziții
- Construirea unei a treia reprezentări vectoriale pentru o a treia încorporare pentru atribut pe baza setului de propoziții
- Alegerea, cu un atribut de entitate cunoscut, combină încorporarea unui atribut de distribuție pentru entitate, înseamnă realizarea unei a patra reprezentări vectoriale, folosind perechile entitate-atribut disponibile, specificând încorporarea atributului de distribuție pentru entitate.
- Construirea unei înglobări de atribute de distribuție cu acele perechi entitate-atribut cunoscute înseamnă dezvoltarea unei a cincea reprezentări vectoriale cu echipe de entitate-atribut disponibile și încorporarea de atribute de distribuție pentru atributul .
- Decizând, pe baza înglobărilor pentru cuvinte din setul de propoziții, încorporarea atributului de distribuție pentru entitate și încorporarea atributului de distribuție pentru atribut, dacă atributul din perechea candidat entitate-atribut este un atribut esențial al entității din perechea candidat entitate-atribut
- Determinarea, pe baza primei reprezentări vectoriale, a doua reprezentare vectorială, a treia reprezentare vectorială, a patra reprezentare vectorială și a cincea reprezentare vectorială, dacă atributul din perechea candidat entitate-atribut este un atribut esențial al entității din entitate -atribut candidat pereche
- Alegerea, din prima reprezentare vectorială, a doua reprezentare vectorială, a treia reprezentare vectorială, a patra reprezentare vectorială și a cincea reprezentare vectorială, dacă atributul din perechea candidat entitate-atribut este un atribut esențial al entității din entitatea- pereche de atribut candidat, se efectuează utilizând o rețea feedforward.
- Alegerea, pe baza primei reprezentări vectoriale, a doua reprezentare vectorială, a treia reprezentare vectorială, a patra reprezentare vectorială și a cincea reprezentare vectorială, dacă atributul din perechea candidat entitate-atribut este un atribut esențial al entității din entitate -perechea candidat atribut, cuprinde:
- Generarea unei singure reprezentări vectoriale prin concatenarea primei reprezentări vectoriale, a doua reprezentare vectorială, a treia reprezentare vectorială, a patra reprezentare vectorială și a cincea reprezentare vectorială; introducerea reprezentării unui singur vector în rețeaua feedforward
- Determinarea, prin intermediul rețelei feedforward și folosind reprezentarea unică vectorială, dacă atributul din perechea candidat entitate-atribut este un atribut esențial al entității din perechea candidat entitate-atribut
Realizarea unei a patra reprezentări vectoriale, cu perechi entitate-atribut cunoscute, specificând încorporarea atributului de distribuție pentru entitate cuprinde:
- Identificarea unui set de atribute asociate cu entitatea în echipele entitate-atribut cunoscute, în care setul de atribute omite atributul
- Generarea unui atribut de distribuție încorporat pentru entitate prin calculul unei sume ponderate de caracteristici în setul de atribute
Alegerea unei a cincea reprezentări vectoriale, cu perechi entitate-atribut cunoscute, specificând încorporarea atributului de distribuție pentru atribut cuprinde
- Identificarea, folosind atributul, a unui set de entitati dintre cuplurile cunoscute entitate-atribut; pentru fiecare entitate din colecția de entități
- Determinarea unui set de caracteristici asociate entității, unde locația atributelor nu include atributul
- Generarea unui atribut de distribuție încorporat pentru entitate prin calculul unei sume ponderate de caracteristici în colecția de atribute
Avantajul unor relații mai precise entitate-atribut față de identificarea entitate-atribut bazată pe modele din stadiul tehnicii
Tehnicile anterioare de identificare a entitatilor-atribute utilizau abordări bazate pe model, cum ar fi caracteristicile de procesare a limbajului natural (NLP), supravegherea la distanță și modelele tradiționale de învățare automată, care identifică relațiile entitate-atribut prin reprezentarea entităților și atributelor bazate pe propoziții de date. Acești termeni apar .
În schimb, inovațiile descrise în această specificație identifică relațiile entitate-atribut în seturile de date prin utilizarea informațiilor despre modul în care entitățile și atributele sunt exprimate în datele în care apar acești termeni și prin reprezentarea entităților și atributelor folosind alte caracteristici despre care se știe că sunt asociate cu acești termeni . Acest lucru permite reprezentarea entităților și atributelor cu detalii partajate de entități similare, îmbunătățind acuratețea identificării relațiilor entitate-atribut care altfel nu pot fi deslușite luând în considerare propozițiile în care apar acești termeni .
De exemplu, luați în considerare un scenariu în care setul de date include propoziții care au două entități, „Ronaldo” și „Messi”, fiind descrise folosind un atribut „înregistrare” și o penalizare în care entitatea „Messi” este descrisă folosind un „obiective” atribut . Într-un astfel de scenariu, tehnicile din stadiul tehnicii pot identifica următoarele perechi de atribute de entitate: (Ronaldo, înregistrare), (Messi, log) și (Messi, obiective) . Inovațiile descrise în această specificație depășesc aceste abordări din stadiul tehnicii prin identificarea relațiilor entitate-atribut care ar putea să nu fie deslușite de modul în care acești termeni sunt utilizați în setul de date .
Folosind exemplul de mai sus, inovația descrisă în această specificație determină că „Ronaldo” și „Messi” sunt entități similare, deoarece împărtășesc atributul „record” și apoi reprezintă atributul „record” folosind atributul „goals” . În acest fel, inovațiile descrise în această specificație, de exemplu, pot permite identificarea relațiilor entitate-atribut, de exemplu, (Cristiano, Goals), chiar dacă o astfel de relație poate să nu fie perceptibilă din setul de date .
Brevetul de identificare a relațiilor de atribute
Identificarea relațiilor de atribute ale entității
Inventatori: Dan Iter, Xiao Yu și Fangtao Li
Cesionar: Google LLC
Brevet SUA: 11.263.400
Acordat: 1 martie 2022
Depus: 5 iulie 2019
Abstract
Metode, sisteme și aparate, inclusiv programe de calculator codificate pe un mediu de stocare computerizat, care ușurează identificarea relațiilor entitate-atribut în corpurile de text .Metodele includ determinarea dacă un atribut dintr-o pereche entitate candidată-atribut este un atribut real al entității din perechea candidat entitate-atribut .Aceasta include generarea de înglobări pentru cuvinte în setul de propoziții care includ entitatea și atributul și generarea, folosind perechi cunoscute entitate-atribut .Aceasta include, de asemenea, generarea unei înglobări distribuționale de atribut pentru entitate pe baza altor atribute asociate entității din perechile entitate-atribut cunoscute și generarea unei înglobare distribuțională a atributului pentru atribut pe baza atributelor cunoscute asociate cu entitățile cunoscute ale atributului din cele cunoscute. perechi entitate-atribut .Pe baza acestor înglobări, o rețea feedforward determină dacă atributul din perechea candidat entitate-atribut este un atribut real al entității din perechea candidat entitate-atribut .
Identificarea relațiilor cu atributele entității în text
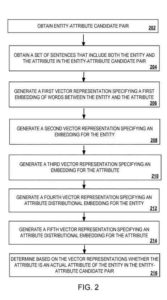
O pereche entitate candidată-atribut (unde atributul este un atribut candidat al entității) este introdusă într-un model de clasificare . Modelul de clasificare utilizează un motor de încorporare a căilor, un motor de reprezentare distribuțională, un motor de atribute și o rețea feedforward. Acesta determină dacă atributul din perechea entitate candidată-atribut este o entitate esențială în perechea entitate candidată-atribut .
Motorul de încorporare a căilor generează un vector reprezentând o încorporare a căilor sau a cuvintelor care conectează aparițiile cotidiene ale entității și atributul într-un set de propoziții (de exemplu, 30 sau mai multe propoziții) ale unui set de date . Motorul de reprezentare distribuțională generează vectori reprezentând o încorporare pentru entitate și atribute termeni în funcție de contextul în care acești termeni apar în setul de propoziții . Motorul de atribute de distribuție generează un vector reprezentând o încorporare pentru entitate și un alt vector reprezentând o încorporare pentru atribut .
Încorporarea motorului de distribuție a atributelor pentru entitate se bazează pe alte caracteristici (adică alte atribute decât atributul candidat) despre care se știe că sunt asociate cu entitatea din setul de date . Încorporarea detaliată a motorului de distribuție pentru calitate se bazează pe diferite caracteristici asociate cu entitățile cunoscute ale atributului candidat .
Modelul de clasificare concatenează reprezentările vectoriale din motorul de încorporare a drumului, motorul de reprezentare distribuțională și motorul de atribute distribuționale într-o singură reprezentare vectorială. Modelul de clasificare introduce apoi reprezentarea vectorială unică într-o rețea de tip feedforward care determină, folosind reprezentarea vectorială unică, dacă atributul din perechea entitate candidată-atribut este un atribut esențial al entității din perechea entitate-atribut candidată .
Să presupunem că rețeaua feedforward determină că punctul din perechea entitate candidată-atribut este necesar pentru entitatea din perechea entitate candidată-atribut. În acest caz, perechea entitate-atribut candidată este stocată în baza de cunoștințe împreună cu alte perechi entitate-atribut cunoscute/actuale .
Extragerea relațiilor cu atributele entității
Mediul include un model de clasificare care, pentru perechile entitate candidată-atribut dintr-o bază de cunoștințe, determină dacă un atribut dintr-o pereche entitate candidată-atribut este un atribut esențial al entității din perechea candidată . Modelul de clasificare este un model de rețea neuronală, iar componentele sunt descrise mai jos . Modelul de clasificare poate fi folosit și folosind alte modele de învățare automată supravegheate și nesupravegheate .
Baza de cunoștințe, care poate include baze de date (sau alte structuri adecvate de stocare a datelor) stocate în medii de stocare a datelor netranzitorii (de exemplu, hard disk(e), memorie flash etc.), deține un set de perechi candidate entitate-atribut . Perechile entitate-atribut candidat sunt obținute folosind un set de conținut în documente text, cum ar fi pagini web și articole de știri, obținute dintr-o sursă de date. Sursa de date poate include orice sursă de conținut, cum ar fi un site de știri, o platformă de agregare de date, o platformă de social media etc.
Sursa de date obține articole de știri de pe o platformă de agregare de date. Sursa de date poate folosi un model. Modelul de învățare automată supravegheat sau nesupravegheat (un model de procesare a limbajului natural) generează un set de perechi candidate entitate-atribut prin extragerea propozițiilor din articole și tokenizarea și etichetarea propozițiilor extrase, de exemplu, ca entități și atribute, folosind o parte de vorbire și etichetele arborelui de analiză a dependenței .
Sursa de date poate introduce propozițiile extrase într-un model de învățare automată. De exemplu, poate fi instruit folosind un set de propoziții de antrenament și perechile entitate-atribut asociate acestora . Un astfel de model de învățare automată poate scoate apoi echipele de entitate-atribut candidat pentru propozițiile extrase de intrare .
În baza de cunoștințe, sursa de date stochează perechile entitate-atribut candidat și propozițiile extrase de sursa de date care includ cuvintele perechilor entitate-atribut candidat . Perechile entitate-atribut candidat sunt stocate în baza de cunoștințe numai dacă numărul de propoziții în care sunt prezente entitatea și atributul satisface (de exemplu, îndeplinește sau depășește) un număr prag de propoziții (de exemplu, 30 de propoziții) .
Un model de clasificare determină dacă atributul dintr-o pereche entitate-atribut candidată (stocat în baza de cunoștințe) este un atribut real al entității din perechea entitate-atribut candidată . Modelul de clasificare include un motor de încorporare a căii 106, o sursă de reprezentare distribuţională, un motor de atribute şi o reţea feedforward . Așa cum este utilizat aici, termenul motor se referă la un aparat de procesare a datelor care realizează un set de sarcini. Operațiunile acestor motoare ale modelului de clasificare pentru a determina dacă atributul dintr-o pereche entitate-atribut candidată este un atribut esențial al entității .
Un exemplu de proces pentru identificarea relațiilor cu atributele entității
Operațiunile procesului sunt descrise mai jos ca fiind efectuate de componentele sistemului, iar funcțiile procesului sunt descrise mai jos doar în scopuri ilustrative. Operațiunile procesului pot fi realizate de orice dispozitiv sau sistem adecvat, de exemplu, orice aparat de prelucrare a datelor aplicabil . Funcțiile procesului pot fi, de asemenea, implementate ca instrucțiuni stocate pe un mediu netranzitoriu care poate fi citit de computer . Executarea instrucțiunilor face ca aparatele de prelucrare a datelor să efectueze operațiuni ale procesului .
Baza de cunoștințe obține o pereche candidat entitate-atribut din sursa de date.
Baza de cunoștințe obține un set de propoziții din sursa de date care includ cuvintele entității și atributul din perechea entitate-atribut candidată .
Pe baza setului de propoziții și a perechii entitate candidată-atribut, modelul de clasificare determină dacă atributul candidat este un atribut real al entității candidate . Setul de pedepse poate fi un număr mare de propoziții, de exemplu, 30 sau mai multe propoziții.
Modelul de clasificare care efectuează următoarele operații
- Înglobările pentru cuvinte în setul de propoziții care includ entitatea și atributul sunt descrise mai detaliat mai jos cu privire la procesul de mai jos
- Creat folosind perechi cunoscute entitate-atribut, un atribut de distribuție încorporat pentru entitate, care este descris mai detaliat mai jos cu privire la funcționare
- Construire, folosind perechile entitate-atribut cunoscute și încorporarea atributului de distribuție pentru atribut, care este descris mai detaliat mai jos în ceea ce privește operarea
- Alegerea, pe baza înglobărilor pentru cuvinte din setul de propoziții, încorporarea atributului de distribuție pentru entitate și încorporarea atributului de distribuție pentru atribut, dacă atributul din perechea candidat entitate-atribut este un atribut esențial al entității din perechea candidat entitate-atribut, care este descrisă mai detaliat mai jos cu privire la operațiune .
Motorul de încorporare a căii generează o primă reprezentare vectorială specificând primele cuvinte încorporate între entitate și atribut în propoziții . Motorul de încorporare a căilor detectează relațiile dintre termenii entitate-atribut candidat prin încorporarea căilor sau cuvintelor care leagă aparițiile de zi cu zi ale acestor termeni în setul de propoziții .
Pentru expresia „șarpele este o reptilă”, motorul de încorporare a căii generează o încorporare pentru piesa „este a”, care se poate obișnui pentru a detecta, de exemplu, relațiile gen-specie, care se pot obișnui apoi cu identificarea altor entitati-atribut. perechi .
Generarea cuvintelor între entitate și atribut
Motorul de încorporare a căii face următoarele pentru a genera cuvinte între entitate și atribut din propoziții . Pentru fiecare propoziție din setul de propoziții, motorul de încorporare a căii extrage mai întâi calea de dependență (care specifică un grup de cuvinte) dintre entitate și atribut . Motorul de încorporare a căii convertește propoziția dintr-un șir într-o listă, unde primul termen este entitatea, iar ultimul termen este atributul (sau primul termen este atributul și termenul anterior este entitatea) .
Fiecare termen (care se mai numește și margine) din calea dependenței este reprezentat folosind următoarele caracteristici: lema termenului, o etichetă a unei părți din vorbire, eticheta dependenței și direcția căii dependenței (stânga , dreapta sau rădăcină) . Fiecare dintre aceste caracteristici este încorporată și concatenată pentru a produce o reprezentare vectorială pentru termenul sau marginea (Ve), care cuprinde o secvență de vectori (Vl, Vpos, Vdep). , V.dir), așa cum se arată în ecuația de mai jos: {săgeata dreapta peste (v)}.e=[{săgeata dreapta peste (v)}.sub.l,{săgeata dreapta peste (v)} .sub.pos,{săgeata dreapta peste (v)}.sub.dep,{săgeata dreapta peste (v)}.sub.dir]
Motorul de încorporare a căii introduce apoi secvența de vectori pentru termenii sau marginile fiecărei căi într-o rețea de memorie pe termen scurt (LSTM), care produce o singură reprezentare vectorială pentru propoziție (Vs), așa cum este arătat de ecuația de mai jos: {săgeată la dreapta peste (v)}.s=LSTM({săgeata la dreapta peste (v)}.e.sup.(1) . . . . . . {săgeata la dreapta peste (v)}.sub .e.sup.(k))
În cele din urmă, motorul de încorporare a căii introduce reprezentarea vectorială unică pentru toate propozițiile din setul de propoziții într-un mecanism de atenție, care determină o medie ponderată a reprezentărilor propoziției (V sents(e,a)), așa cum arată sub ecuația de mai jos: {săgeată la dreapta peste (v)}.sub.sents(e,a)=ATTN({săgeata la dreapta peste (v)}.sup.(1) . . . . {săgeata dreapta peste (v) )}.sup.(n))
Modelul de reprezentare distribuțională generează o a doua reprezentare vectorială pentru entitate și o a treia reprezentare vectorială pentru atribut pe baza propozițiilor . Motorul de reprezentare distribuțională detectează relațiile dintre termenii entitate-atribut candidat pe baza contextului în care punctul și entitatea perechii entitate-atribut candidat apar în setul de propoziții . De exemplu, motorul de reprezentare distribuțională poate determina că entitatea „New York” este folosită în colecția de propoziții într-un mod care sugerează că această entitate se referă la un oraș sau un stat din Statele Unite .
Ca un alt exemplu, motorul de reprezentare distribuțională poate determina că atributul „capitală” este folosit în setul de propoziții într-un mod care sugerează că acest atribut se referă la un oraș semnificativ dintr-un stat sau o țară . Astfel, motorul de reprezentare distribuțională generează o reprezentare vectorială specificând o încorporare pentru entitatea (Ve) folosind contextul (adică, setul de propoziții) în care apare entitatea . Motorul de reprezentare distribuțională generează o reprezentare vectorială (Va) specificând o încorporare pentru atribut folosind setul de propoziții în care apare caracteristica .
Motorul de atribute de distribuție generează o a patra reprezentare vectorială care specifică o încorporare a unui atribut de distribuție pentru entitate folosind perechile entitate-atribut cunoscute . Perechile entitate-atribut cunoscute, care sunt stocate în baza de cunoștințe, sunt perechi entitate-atribut pentru care s-a confirmat (de exemplu, folosind procesarea prealabilă de către modelul de clasificare sau pe baza unei evaluări umane) că fiecare atribut din entitate- perechea de atribute este un atribut esențial al entității din cuplul entitate-atribut .
Motorul de atribute de distribuție efectuează următoarele operații pentru a determina o încorporare a unui atribut de distribuție care specifică o încorporare pentru entitate folosind unele (de exemplu, cele mai comune) sau toate celelalte atribute cunoscute dintre perechile entitate-atribut cunoscute cu care acea entitate este asociată .
Identificarea altor atribute pentru entități
Pentru entitățile din perechea candidat entitate-atribut, motorul de atribute distribuționale identifică alte atribute decât cele incluse în perechea candidat entitate-atribut asociată cu entitatea din echipele cunoscute entitate-atribut .
Pentru o entitate „Michael Jordan” din perechea candidată entitate-atribut (Michael Jordan, celebru), motorul de distribuție a atributelor poate folosi perechile entitate-atribut cunoscute pentru Michael Jordan, cum ar fi (Michael Jordan, bogat) și (Michael Jordan, înregistrare), pentru a identifica atribute precum afluent și descriere .
Motorul de distribuție a atributelor generează apoi o încorporare pentru entitate prin calculul unei sume ponderate a atributelor cunoscute identificate (așa cum este descris în paragraful precedent), unde ponderile sunt învățate folosind un mecanism de atenție, așa cum se arată în ecuația de mai jos: {dreapta: săgeată peste (v)}.e=ATTN(.epsilon.(.alfa..sub.1) . . .epsilon.(.alpha..sub.m))
Motorul de atribute de distribuție generează o a cincea reprezentare vectorială care specifică o încorporare a unui atribut de distribuție pentru atribut folosind perechile entitate-atribut cunoscute . Motorul de atribute de distribuție efectuează următoarele operații pentru a determina un model bazat pe unele (fie cele mai comune) sau pe toate atributele cunoscute asociate cu entitățile cunoscute ale atributului candidat .
Pentru punctul din perechea candidat entitate-atribut, motorul de atribute distribuționale identifică entitățile cunoscute dintre cuplurile cunoscute entitate-atribut care au calitatea .
Pentru fiecare entitate cunoscută identificată, motorul de atribute de distribuție identifică alte atribute (adică alte atribute decât cele incluse în perechea candidat entitate-atribut) asociate cu entitatea în echipele entitate-atribut cunoscute . Motorul de atribute de distribuție poate identifica un subset de atribute dintre atributele identificate prin:
(1) Clasificarea atributelor pe baza numărului de entități cunoscute asociate cu fiecare entitate, cum ar fi atribuirea unui rang mai mare atributelor asociate cu un număr mai mare de entități decât cele asociate cu mai puține entități)
Căutați știri direct în căsuța dvs. de e-mail
*Necesar