
Căutarea cotaților de entități modificate la Google
Publicat: 2022-02-19Brevetul din spatele căutării cotaților de entități a fost modificat din nou prin continuarea brevetului
Când Google actualizează unele procese, este posibil să depună un brevet actualizat pentru a proteja proprietatea intelectuală din spatele procesului. Aceasta poate însemna depunerea unui brevet în cazul în care cea mai mare parte a descrierii brevetului este identică sau aproape o copie a versiunilor anterioare ale brevetului. Titlurile se schimbă uneori puțin, dar lista autorilor rămâne în cea mai mare parte aceeași (am văzut una în care a fost adăugat un autor nou.)
Brevetul Google „Sisteme și metode de căutare a cotațiilor de entități folosind o bază de date” a fost actualizat a doua oară. Pentru a încerca să înțelegeți ce s-a schimbat a implicat să citiți revendicările brevetului și să vedeți cum s-a schimbat descrierea din spatele modului în care funcționează brevetul.
Când USPTO decide dacă acordă sau nu un brevet, agenții de urmărire penală trec prin revendicări pentru a vedea dacă sunt noi, neevidente și utile. Deoarece un brevet de continuare încearcă să actualizeze protecția și să folosească data brevetului inițial ca începutul perioadei de excludere, agentul de brevete se asigură că acele noi revendicări sunt valabile înainte de a acorda un brevet de continuare.
Am scris pentru prima dată despre acest brevet într-o postare anterioară la Go Fish Digital: Google Searching Quotes of Entities. Dacă doriți o idee bună despre modul în care a funcționat procesul din spatele acelui brevet când a apărut inițial, v-aș recomanda să citiți acea postare înainte de a merge prea mult mai departe aici.
Am continuat cu o postare la SEObythesea: Căutarea citatelor actualizată la Google pentru a se concentra pe videoclipuri. Descrie modificările aduse procesului descris în revendicările la post, după primul brevet de continuare.
Acele afirmații au fost actualizate din nou și oferă indicii despre modul în care Google tratează informațiile despre entități care ar fi putut fi păstrate inițial în graficul de cunoștințe.
Compararea revendicărilor din cotațiile de căutare ale versiunilor de brevete ale entităților
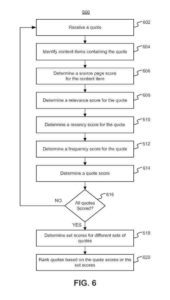
8 august 2017 – Sisteme și metode de căutare a cotațiilor entităților folosind o bază de date:
1. Sistem computerizat de căutare și identificare a cotațiilor, sistemul cuprinzând: un dispozitiv de memorie care stochează un set de instrucțiuni; şi cel puţin un procesor care execută setul de instrucţiuni pentru a: primi o interogare de căutare pentru o cotaţie de la un utilizator; analizați interogarea pentru a identifica unul sau mai multe cuvinte cheie; potriviți unul sau mai multe cuvinte cheie cu elementele graficului de cunoștințe asociate cu entitățile subiect candidat într-un grafic de cunoștințe stocat într-una sau mai multe baze de date, în care graficul de cunoștințe include o multitudine de elemente asociate cu o multitudine de entități subiect și o pluralitate de relații între pluralitate de articole; determina, pe baza itemilor din graficul de cunoștințe de potrivire, un scor de relevanță pentru fiecare dintre entitățile subiect candidate; identifica, dintre entitățile subiect candidat, una sau mai multe entități subiect pentru interogare pe baza scorurilor de relevanță asociate entităților subiect candidat; identificarea unui set de citate corespunzătoare uneia sau mai multor entități subiect; determina scorurile citatelor pentru citatele identificate pe baza a cel puțin una dintre relațiile fiecărui citat cu una sau mai multe entități subiect, recentitatea fiecărui citat sau popularitatea fiecărui citat; selectați citate din citatele identificate pe baza scorurilor citatelor; și transmite informații către un dispozitiv de afișare pentru a afișa citatele selectate către utilizator.
5 februarie 2019 – Sisteme și metode de căutare a cotațiilor entităților folosind o bază de date:
1. O metodă care cuprinde următoarele operaţii efectuate de unul sau mai multe procesoare: recepţionarea conţinutului audio de la un dispozitiv client al unui utilizator; efectuarea de analize audio asupra conținutului audio pentru a identifica un citat în conținutul audio; determinarea utilizatorului ca autor al conținutului audio pe baza recunoașterii utilizatorului ca vorbitor al conținutului audio; identificarea, pe baza cuvintelor sau expresiilor extrase din citat, a uneia sau mai multor entități subiect asociate citatului; stocarea, într-o bază de date, a citatului și a unei asocieri a citatului la entitățile subiect și la utilizatorul care este autor; ulterior stocării cotației și asocierii: primirea, de la utilizator, a unei interogări de căutare; analizarea interogării de căutare pentru a identifica că interogarea de căutare solicită una sau mai multe citate de către utilizator despre una sau mai multe dintre entitățile subiect; identificarea, din baza de date și receptiv la interogarea de căutare, a unui set de citate de către utilizator corespunzător uneia sau mai multor entități subiect, setul de citate incluzând citatul; selectarea citatului din ghilimele setului pe baza cel puțin parțial pe recentitatea fiecărui citat; şi transmiterea, ca răspuns la interogarea de căutare, a informaţiilor pentru prezentarea cotaţiei selectate către utilizator prin intermediul dispozitivului client sau al unui dispozitiv client suplimentar al utilizatorului.
Comparați primele două revendicări cu prima revendicare din cea mai nouă versiune a brevetului, care a fost acordată la începutul acestei săptămâni. Are câteva modificări față de primele două versiuni.
15 februarie 2022 – Sisteme și metode de căutare a cotațiilor entităților folosind o bază de date:
1. Un sistem informatic, sistemul cuprinzând: un dispozitiv de memorie care stochează un set de instrucțiuni; şi cel puţin un procesor care execută setul de instrucţiuni pentru: a prelua o resursă electronică, în care resursa electronică este o pagină web sau este un document; analizați resursa electronică pentru a identifica unul sau mai multe cuvinte cheie; potriviți unul sau mai multe cuvinte cheie cu o entitate subiect dintr-o bază de date de entitate subiect; identificarea unei multitudini de citate pe baza entității subiect a bazei de date a entității subiect, în care fiecare citat din multitudinea de citate este identificat dintr-o resursă electronică suplimentară care cuprinde o pagină web; să identifice o entitate subiect suplimentară care este asociată cu entitatea subiect din baza de date a entității subiect; selectați un subset al pluralității identificate de citate pe baza subsetului de citate identificate care sunt asociate cu entitatea subiect suplimentară; determinați scorurile citatelor pentru subsetul de citate identificate, în care fiecare dintre scorurile citatelor este pentru una dintre citatele corespunzătoare din subsetul și este determinată pe baza unuia sau multiplu dintre: o relație a citatului corespunzător cu entitatea subiect, o recentitate a citatului corespunzător și o popularitate a citatului corespunzător; selectați, pe baza scorurilor citate, un citat din subsetul de citate identificate; şi transmiterea informaţiilor către un dispozitiv client care accesează resursa electronică, în care transmiterea informaţiilor determină ca dispozitivul client să afişeze oferta selectată şi un hyperlink selectabil către pagina web din care a fost identificat oferta selectată.

Titlurile brevetelor nu s-au schimbat și nu au fost adăugați autori. Desenele și majoritatea descrierilor sunt aceleași.
- Prima afirmație se referă la „potrivirea cuvintelor cheie cu elementele graficului de cunoștințe”.
- A doua First Claim nu include graficul de cunoștințe și spune că procesul este despre „efectuarea unei analize audio asupra conținutului audio pentru a identifica un citat în conținutul audio”.
- Cea mai nouă primă revendicare înlocuiește graficul de cunoștințe din prima versiune când spune că „va potrivi unul sau mai multe cuvinte cheie cu o entitate subiect dintr-o bază de date de entitate subiect”.
- Spre deosebire de primele două versiuni, cea mai nouă revendicare primară descrie ca informațiile despre cotație să fie atribuibile.
Așa că am rămas cu întrebări despre căutarea citatelor entităților
- De ce este introdusă o bază de date de entitate subiect și de ce ar putea fi diferită de graficul de cunoștințe? Se pare că ar putea fi un tezaur de informații care nu poate fi navigat și transparent pentru cei care caută, așa cum ar putea fi informațiile din graficul de cunoștințe. Sunt și alte informații despre entități păstrate separat de graficul de cunoștințe, până când se decide cum să se afișeze cel mai bine aceste informații?
- Unde sunt stocate cotațiile? A doua primă afirmație ne spune că conținutul audio este analizat în loc să se uite în graficul de cunoștințe. În a treia primă revendicare, căutarea citatelor entităților se face prin căutarea citatelor din baza de date a entităților subiect. Când am citit pentru prima dată a doua versiune a brevetului, am înțeles că informațiile despre citate erau păstrate într-un index de informații video. Este, totuși, probabil ca Google să aibă informații despre unele citate pentru care nu are neapărat un videoclip.
- De unde provin informațiile despre cotații? A treia prima afirmație ne spune că poate oferi celui care caută un „hyperlink selectabil către pagina web din care a fost identificat citatul selectat”. Cele două versiuni anterioare afirmă că citatul poate fi prezentat unui căutător, dar nu menționează în niciun fel atribuirea sursei citatului sau informații despre acesta. Atribuirea pare acum mai importantă pentru Google, unde a doua primă afirmație părea să presupună că informațiile pot proveni de la YouTube.
Cea mai nouă versiune a brevetului de căutare a cotațiilor de entități
Sisteme și metode de căutare a cotațiilor de entități folosind o bază de date
Inventatori: Eyal Segalis, Gal Chechik, Yossi Matias, Yaniv Leviathan și Yoav Tzur
Cesionar: GOOGLE LLC
Brevet SUA: 11.250.052
Acordat: 15 februarie 2022
Depus: 26 decembrie 2018
Abstract
Sunt furnizate sisteme și metode pentru căutarea și identificarea citatelor ca răspuns la o interogare a unui utilizator.
În concordanță cu anumite exemple de realizare, sunt furnizate sisteme și metode pentru identificarea uneia sau mai multor entități subiect asociate cu interogarea și identificarea, dintr-o bază de date sau rezultate de căutare obținute ca răspuns la interogare, a unui set de citate corespunzător uneia sau mai multor entități subiect.
Mai mult, sunt furnizate sisteme și metode pentru determinarea scorurilor citatelor pentru citatele identificate pe baza a cel puțin una dintre relațiile fiecărui citat cu una sau mai multe entități subiect, recentitatea fiecărui citat și popularitatea fiecărui citat.
În plus, sunt furnizate sisteme și metode pentru organizarea cotațiilor identificate într-o ordine de clasare pe baza scorurilor cotațiilor și selectarea cotațiilor pe baza ordinii de rang sau scorurile cotațiilor. În plus, sunt furnizate sisteme și metode pentru transmiterea de informații pentru a afișa cotațiile selectate pe un dispozitiv de afișare.
Căutați știri direct în căsuța dvs. de e-mail
*Necesar