
Détermination des états de dialogue pour les modèles de langage mis à jour
Publié: 2022-03-16Les premières revendications de la détermination des états de dialogue pour les modèles de langage
Il y a de fortes chances que vous ayez vu des brevets de dialogue homme-ordinateur de Google. J'ai écrit sur certains dans le passé. En voici deux qui fournissent beaucoup de détails sur un tel dialogue :
- Dialogue homme-ordinateur chez Google
- Contenu non sollicité dans le dialogue homme-ordinateur
En plus d'examiner attentivement les brevets impliquant le dialogue humain-ordinateur, il vaut la peine de passer du temps avec le traitement du langage naturel et les communications entre les êtres humains et les ordinateurs. J'ai également écrit sur quelques-uns d'entre eux. En voici quelques-uns :
- L'assistant Google et le traitement du langage naturel basé sur le contexte
- Réponses aux requêtes en langage naturel
Ce brevet Google Determining Dialog States For Language Models a été mis à jour deux fois maintenant, la dernière version ayant été accordée plus tôt cette semaine. La dernière première revendication est un peu plus longue et comporte de nouveaux mots ajoutés.
Idéalement, ces brevets doivent commencer par un examen approfondi du langage des revendications.
La deuxième version de Determining dialog states for language models, déposée le 18 2018 et accordée le 4 février 2020, commence par la revendication suivante :
- Ce qui est revendiqué est:
- 1. Procédé mis en œuvre par ordinateur, comprenant :
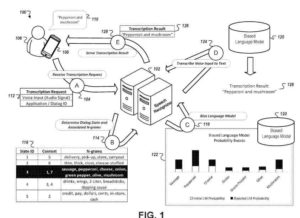
- Réception, par un dispositif informatique, de données audio pour une entrée vocale dans le dispositif informatique, l'entrée vocale correspondant à une étape inconnue d'un dialogue vocal à plusieurs étapes entre le dispositif informatique et un utilisateur du dispositif informatique
- Détermination d'une prédiction initiale pour l'étape inconnue du dialogue vocal à plusieurs étapes
Fournir, par le dispositif informatique et à un système de dialogue vocal,- (i) les données audio pour l'entrée vocale dans le dispositif informatique et
- (ii) une indication de la prédiction initiale pour l'étape inconnue du dialogue vocal à étapes multiples
- Recevoir, par le dispositif informatique et depuis le système de dialogue vocal, une transcription de l'entrée vocale, la transcription étant générée en traitant les données audio avec un modèle qui a été biaisé selon des paramètres qui correspondent à une prédiction affinée pour l'étape inconnue de le dialogue vocal multi-étapes, dans lequel le système de dialogue vocal est configuré pour déterminer la prédiction affinée pour l'étape inconnue du dialogue vocal multi-étapes sur la base (i) de la prédiction initiale pour l'étape inconnue du dialogue vocal multi-étapes et
- (ii) des informations supplémentaires qui décrivent un contexte de l'entrée vocale, et dans lequel les informations supplémentaires qui décrivent le contexte de l'entrée vocale sont indépendantes du contenu de
- l'entrée vocale ; et présenter la transcription de l'entrée vocale avec le dispositif informatique.
La première version de ce brevet de continuation, Determining dialog states for language models, déposée le 16 mars 2016 et délivrée le 22 mai 2018, commence par cette revendication :
- Ce qui est revendiqué est:
- 1. Procédé mis en œuvre par ordinateur, comprenant :
- Recevoir, au niveau d'un système informatique, des données audio qui indiquent une première entrée vocale qui a été fournie à un dispositif informatique
- déterminer que la première entrée vocale fait partie d'un dialogue vocal qui comprend une pluralité d'états de dialogue prédéfinis agencés pour recevoir une série d'entrées vocales liées à une tâche particulière, dans lequel chaque état de dialogue est mis en correspondance avec : (i) un ensemble d'états afficher des données caractérisant un contenu qui est destiné à être affiché lorsque des entrées vocales pour l'état de dialogue sont reçues, et
(ii) un ensemble de n-grammes - Recevoir, au niveau du système informatique, des premières données d'affichage qui caractérisent le contenu qui a été affiché sur un écran du dispositif informatique lorsque la première entrée vocale a été fournie au dispositif informatique ; la sélection, par le système informatique, d'un état de dialogue particulier parmi la pluralité d'états de dialogue prédéfinis qui correspond à la première entrée vocale, y compris la détermination d'une correspondance entre les premières données d'affichage et l'ensemble correspondant de données d'affichage qui est mappé à l'état particulier état du dialogue ; biaiser un modèle de langage en ajustant les scores de probabilité que le modèle de langage indique pour les n-grammes dans l'ensemble correspondant de n-grammes qui sont mappés à l'état de dialogue particulier ; et transcrire l'entrée vocale à l'aide du modèle de langage biaisé.
La première revendication la plus récente de la dernière version de ce brevet, Détermination des états de dialogue pour les modèles de langage, a été déposée le 2 janvier 2020 et accordée le 1er mars 2022. Elle nous dit :
- Ce qui est revendiqué est:
- 1. Procédé mis en œuvre par ordinateur, comprenant :
- Obtention de transcriptions d'entrées vocales à partir d'un ensemble d'entrées vocales d'apprentissage, chaque entrée vocale dans l'ensemble d'entrées vocales d'apprentissage étant dirigée vers l'une d'une pluralité d'étapes d'une activité vocale à plusieurs étapes
- obtenir des données d'affichage associées à chaque entrée vocale à partir de l'ensemble d'entraînement d'entrées vocales qui caractérise le contenu qui est désigné pour être affiché lorsque l'entrée vocale associée est reçue ; générer une pluralité de groupes de transcriptions, chaque groupe de transcriptions comprenant un sous-ensemble différent des transcriptions d'entrées vocales à partir de l'ensemble d'apprentissage d'entrées vocales
- Attribution de chaque groupe de transcriptions à un état de dialogue différent d'un modèle d'état de dialogue qui comprend une pluralité d'états de dialogue, dans lequel chaque état de dialogue de la pluralité d'états de dialogue : correspond à une étape différente de l'activité vocale à plusieurs étapes ; et est mappé sur un ensemble respectif des données d'affichage caractérisant le contenu qui est désigné pour être affiché lorsque des entrées vocales provenant de l'ensemble d'apprentissage d'entrées vocales qui sont associées au groupe de transcriptions attribuées à l'état de dialogue sont reçues ; pour chaque groupe de transcriptions, déterminer un ensemble représentatif de n-grammes pour le groupe, et associer l'ensemble représentatif de n-grammes pour le groupe à l'état de dialogue correspondant du modèle d'état de dialogue auquel le groupe est attribué, dans lequel le un ensemble représentatif de n-grammes déterminé pour le groupe de transcriptions comprend des n-grammes satisfaisant un nombre seuil d'occurrences dans le groupe de transcriptions affecté à l'état de dialogue du modèle d'état de dialogue
- Réception d'une entrée vocale ultérieure et de premières données d'affichage caractérisant le contenu qui a été affiché sur un écran lorsque l'entrée vocale ultérieure a été reçue, l'entrée vocale ultérieure dirigée vers une étape particulière de l'activité vocale à plusieurs étapes
Détermination d'une correspondance entre les premières données d'affichage et l'ensemble respectif de données d'affichage mappé à l'état de dialogue dans le modèle d'état de dialogue qui correspond à l'étape particulière de l'activité multi-voix - Le traitement, avec un système de reconnaissance vocale, de l'entrée vocale ultérieure et des premières données d'affichage, y compris la polarisation du système de reconnaissance vocale à l'aide de l'ensemble représentatif de n-grammes associé à l'état de dialogue dans le modèle d'état de dialogue qui correspond à l'étape particulière de la activité multi-voix
\
Comparaison des revendications des états de dialogue déterminants pour les modèles de langage
Voici quelques-unes des différences que je constate avec les différentes versions du brevet :

1. Les trois versions nous disent qu'elles concernent les "entrées vocales", qui font partie d'un ensemble de formation.
Ainsi, contrairement aux brevets précédents sur les états de dialogue entre les humains et les ordinateurs, qui se concentraient sur le contenu du dialogue, ce brevet porte principalement sur le langage verbal et les entrées vocales réelles.
2. Les deuxième et troisième versions du brevet décrivent la décomposition des transcriptions des entrées vocales en ngrammes, ce qui peut être utile pour calculer des statistiques sur les occurrences des entrées vocales utilisées.
3. La revendication de la version la plus récente et la troisième des états de dialogue de détermination du brevet pour les modèles de langage mentionne l'utilisation d'un reconnaisseur de vitesse.
- Ce qui est revendiqué est:
- 1. Procédé mis en œuvre par ordinateur, comprenant : la réception, au niveau d'un système informatique, de données audio qui indiquent une première entrée vocale qui a été fournie à un dispositif informatique ; déterminer que la première entrée vocale fait partie d'un dialogue vocal qui comprend une pluralité d'états de dialogue prédéfinis agencés pour recevoir une série d'entrées vocales liées à une tâche particulière, dans lequel chaque état de dialogue est mappé sur :
- (i) un ensemble de données d'affichage caractérisant un contenu qui est destiné à être affiché lorsque des entrées vocales pour l'état de dialogue sont reçues, et
- (ii) un ensemble de n-grammes ; recevoir, au niveau du système informatique, des premières données d'affichage qui caractérisent le contenu qui a été affiché sur un écran du dispositif informatique lorsque la première entrée vocale a été fournie au dispositif informatique
- La sélection, par le système informatique, d'un état de dialogue particulier parmi la pluralité d'états de dialogue prédéfinis qui correspond à la première entrée vocale, comprenant la détermination d'une correspondance entre les premières données d'affichage et l'ensemble correspondant de données d'affichage qui est mappé à l'état particulier état du dialogue
- Biais un modèle de langage en ajustant les scores de probabilité que le modèle de langage indique pour les n-grammes dans l'ensemble correspondant de n-grammes qui sont mappés à l'état de dialogue particulier
- Transcription de l'entrée vocale à l'aide du modèle de langage biaisé.
Détermination des états de dialogue pour les modèles de langage
Inventeurs : Petar Aleksic et Pedro J. Moreno Mengibar
Cessionnaire : Google LLC
Brevet américain : 11 264 028
Attribué : 1er mars 2022
Date de dépôt : 2 janvier 2020
Abstrait
L'invention concerne des systèmes, des procédés, des dispositifs et d'autres techniques pour déterminer des états de dialogue qui correspondent à des entrées vocales et pour biaiser un modèle de langage sur la base des états de dialogue déterminés. Dans certaines mises en œuvre, un procédé comprend la réception, au niveau d'un système informatique, de données audio qui indiquent une entrée vocale et la détermination d'un état de dialogue particulier, parmi une pluralité d'états de dialogue, qui correspond à l'entrée vocale. Un ensemble de n-grammes peut être identifié qui sont associés à l'état de dialogue particulier qui correspond à l'entrée vocale. En réponse à l'identification de l'ensemble de n-grammes qui sont associés à l'état de dialogue particulier qui correspond à l'entrée vocale, un modèle de langage peut être biaisé en ajustant les scores de probabilité que le modèle de langage indique pour les n-grammes dans l'ensemble de n- grammes. L'entrée vocale peut être transcrite à l'aide du modèle de langage ajusté.
Rechercher des actualités directement dans votre boîte de réception
*Obligatoire