
識別實體屬性關係
已發表: 2022-03-02該專利於 2022 年 3 月 1 日授予,旨在識別文本正文中的實體-屬性關係。
搜索應用程序,如搜索引擎和知識庫,試圖滿足搜索者的信息需求,並向搜索者展示最有利的資源。
結構化數據可能有助於更好地識別屬性關係
識別屬性實體關係在結構化搜索結果中完成。
結構化搜索結果顯示屬性列表,其中包含用戶請求中指定的實體的答案,例如查詢。
因此,“Kevin Durant”的結構化搜索結果可能包括諸如薪水、團隊、出生年份、家庭等屬性,以及提供有關這些屬性信息的答案。
構建這樣的結構化搜索結果可能需要識別實體-屬性關係。
實體-屬性關係是一對術語之間的文本關係的特例。
這對術語中的第一個術語是實體、人、地點、組織或概念。
第二項是描述實體方面的屬性或字符串。
示例包括:
- 一個人的“出生日期”
- 一個國家的“人口”
- 運動員的“薪水”
- 組織的“CEO”
在有關實體的內容和模式(以及結構化數據)中提供更多信息,可為搜索引擎提供更多信息,以探索有關特定實體的更好信息,測試和收集數據,消除其所知道的歧義,並對實體有更多更好的信心它知道。
實體-屬性候選對
本專利獲取實體-屬性候選對來定義實體和屬性,其中屬性為實體的候選屬性。 除了從結構化數據中有關實體的事實中學習之外,Google 還可以通過查看該信息的上下文來使用信息,並從向量以及其他單詞和有關這些實體的事實的共現中學習。
查看單詞向量專利,了解搜索引擎現在如何更好地了解單詞的含義和上下文以及有關實體的信息。 (這是一個從專利探索中了解谷歌現在如何做它正在做的事情的機會。)谷歌收集關於它索引的事物的事實和數據,並可能了解它在其索引中擁有的實體,以及它知道的關於它們的屬性。
它在:
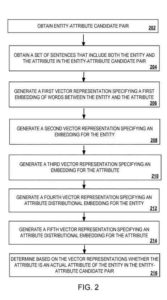
- 用包含實體和屬性的句子確定屬性是否是實體-屬性候選對中實體的實際屬性
- 為包含實體和屬性的句子集中的單詞生成嵌入
- 使用已知實體-屬性對創建實體的分佈式屬性嵌入,其中實體的分佈式屬性嵌入基於與來自已知實體-屬性對的實體相關聯的其他屬性指定實體的嵌入
- 基於句子中單詞的嵌入,實體的分佈屬性嵌入,以及屬性,實體-屬性候選對是否是實體-屬性候選對中實體的本質屬性。
詞的嵌入由帶有實體和屬性的句子組成
構建第一個向量表示,指定實體和句子集中的點之間的單詞的第一個嵌入
- 製作第二個向量表示,根據句子集為實體定義雙重嵌入
- 基於句子集為屬性的第三個嵌入構造第三個向量表示
- Picking 與已知的實體屬性相結合,結合實體的分佈屬性嵌入,意味著使用可用的實體-屬性對製作第四個向量表示,指定實體的分佈屬性嵌入。
- 使用那些已知的實體-屬性對構建分佈式屬性嵌入意味著開發第五個向量表示,其中包含可用的實體-屬性團隊和屬性的分佈式屬性嵌入。
- 根據句子集中詞的嵌入、實體的分佈屬性嵌入和屬性的分佈屬性嵌入,判斷實體-屬性候選對中的屬性是否是實體中實體的本質屬性實體屬性候選對
- 基於第一向量表示、第二向量表示、第三向量表示、第四向量表示和第五向量表示確定實體-屬性候選對中的屬性是否是實體中實體的本質屬性- 屬性候選對
- 從第一個向量表示、第二個向量表示、第三個向量表示、第四個向量表示和第五個向量表示中選擇實體-屬性候選對中的屬性是否是實體-屬性中的實體的本質屬性-屬性候選對,使用前饋網絡執行。
- 根據第一個向量表示、第二個向量表示、第三個向量表示、第四個向量表示和第五個向量表示來挑選實體-屬性候選對中的屬性是否是實體中實體的本質屬性-屬性候選對,包括:
- 通過連接第一向量表示、第二向量表示、第三向量表示、第四向量表示和第五向量表示來生成單個向量表示; 將單個向量表示輸入到前饋網絡中
- 通過前饋網絡,使用單向量表示來確定實體-屬性候選對中的屬性是否是實體-屬性候選對中實體的本質屬性
使用已知的實體-屬性對製作第四個向量表示,指定實體的分佈屬性嵌入包括:
- 識別與已知實體-屬性組中的實體相關聯的一組屬性,其中該組屬性省略了該屬性
- 通過計算屬性集中特徵的加權和來為實體生成分佈屬性嵌入
選擇具有已知實體-屬性對的第五個向量表示,指定屬性的分佈屬性嵌入包括
- 使用屬性從已知的實體-屬性對中識別一組實體; 對於實體集合中的每個實體
- 確定與實體關聯的一組特徵,其中屬性的位置不包括屬性
- 通過計算屬性集合中特徵的加權和來為實體生成分佈屬性嵌入
更準確的實體-屬性關係相對於現有技術的基於模型的實體-屬性識別的優勢
早期藝術實體屬性識別技術使用基於模型的方法,例如自然語言處理 (NLP) 特徵、遠程監督和傳統機器學習模型,這些方法通過基於數據句子表示實體和屬性來識別實體-屬性關係。 這些術語出現。
相比之下,本規範中描述的創新通過使用有關實體和屬性如何在出現這些術語的數據中表達的信息以及通過使用已知與之相關聯的其他特徵來表示實體和屬性來識別數據集中的實體-屬性關係這些條款。 這使得能夠用相似實體共享的細節來表示實體和屬性,從而提高識別實體-屬性關係的準確性,否則這些關係無法通過考慮這些術語出現的句子來辨別。
例如,考慮一個場景,其中數據集包含具有兩個實體的句子,“羅納爾多”和“梅西”,使用“記錄”屬性進行描述,以及使用“目標”描述實體“梅西”的懲罰屬性。 在這種情況下,現有技術可以識別以下實體屬性對:(羅納爾多,記錄)、(梅西,日誌)和(梅西,進球) 。 本規範中描述的創新超越了這些現有技術方法,通過識別可能無法通過這些術語在數據集中的使用方式來識別的實體-屬性關係。
使用上面的例子,本說明書中描述的創新確定“C羅”和“梅西”是相似的實體,因為它們共享“記錄”屬性,然後使用“進球”屬性表示“記錄”屬性。 以這種方式,例如,本說明書中描述的創新能夠識別實體-屬性關係,例如(Cristiano,Goals),即使這種關係可能無法從數據集中辨別。
識別屬性關係專利
識別實體屬性關係
發明人:丹伊特爾、肖宇、李方濤
受讓人:谷歌有限責任公司
美國專利:11,263,400
授予:2022 年 3 月 1 日
提交日期:2019 年 7 月 5 日
抽象的
方法、系統和裝置,包括在計算機存儲介質上編碼的計算機程序,可輕鬆識別文本語料庫中的實體-屬性關係。方法包括確定候選實體-屬性對中的屬性是否是實體-屬性候選對中的實體的實際屬性。這包括為包含實體和屬性的句子集中的單詞生成嵌入,並使用已知的實體-屬性對生成。這還包括基於與來自已知實體-屬性對的實體相關聯的其他屬性為實體生成屬性分佈嵌入,以及基於與已知實體中的屬性的已知實體相關聯的已知屬性為屬性生成屬性分佈嵌入。實體-屬性對。基於這些嵌入,前饋網絡確定實體-屬性候選對中的屬性是否是實體-屬性候選對中實體的實際屬性。
識別文本中的實體屬性關係
候選實體-屬性對(其中屬性是實體的候選屬性)被輸入到分類模型。 分類模型使用路徑嵌入引擎、分佈表示引擎、屬性引擎和前饋網絡。 它確定候選實體-屬性對中的屬性是否是候選實體-屬性對中的必要實體。
路徑嵌入引擎生成一個向量,該向量表示連接數據集的一組句子(例如,30 個或更多句子)中實體和屬性的日常出現的路徑或詞的嵌入。 分佈式表示引擎基於這些術語出現在句子集中的上下文生成表示實體和屬性術語嵌入的向量。 分佈式屬性引擎生成一個表示實體嵌入的向量和另一個表示屬性嵌入的向量。
實體的屬性分佈引擎嵌入基於已知與數據集中的實體相關聯的其他特徵(即,候選屬性以外的屬性) 。 質量的詳細分佈引擎嵌入基於與候選屬性的已知實體相關聯的不同特徵。
分類模型將來自路徑嵌入引擎、分佈表示引擎和分佈屬性引擎的向量表示連接成單個向量表示。 然後分類模型將單個向量表示輸入到前饋網絡中,該網絡使用單個向量表示確定候選實體-屬性對中的屬性是否是候選實體-屬性對中實體的本質屬性。
假設前饋網絡確定候選實體-屬性對中的點對於候選實體-屬性對中的實體是必要的。 在這種情況下,候選實體-屬性對與其他已知/實際實體-屬性對一起存儲在知識庫中。
提取實體屬性關係
該環境包括分類模型,對於知識庫中的候選實體-屬性對,該分類模型確定候選實體-屬性對中的屬性是否是候選對中實體的本質屬性。 分類模型是神經網絡模型,組件描述如下。 分類模型也可以使用其他有監督和無監督機器學習模型。
可以包括存儲在非暫時性數據存儲介質(例如,硬盤驅動器、閃存等)中的數據庫(或其他適當的數據存儲結構)的知識庫保存一組候選實體-屬性對。 候選實體-屬性對是使用從數據源獲得的文本文檔(例如網頁和新聞文章)中的一組內容獲得的。 數據源可以包括任何內容源,例如新聞網站、數據聚合平台、社交媒體平台等。
數據源從數據聚合平台獲取新聞文章。 數據源可以使用模型。 有監督或無監督機器學習模型(自然語言處理模型)通過從文章中提取句子並使用詞性將提取的句子標記和標記為實體和屬性來生成一組候選實體-屬性對和依賴解析樹標籤。
數據源可以將提取的句子輸入到機器學習模型中。 例如,它可以使用一組訓練句子及其關聯的實體屬性對進行訓練。 然後,這樣的機器學習模型可以為輸入提取的句子輸出候選實體屬性團隊。
在知識庫中,數據源存儲候選實體-屬性對和數據源提取的包含候選實體-屬性對單詞的句子。 只有存在實體和屬性的句子數量滿足(例如,滿足或超過)句子的閾值數量(例如,30個句子)時,才將候選實體-屬性對存儲在知識庫中。
分類模型確定候選實體-屬性對中的屬性(存儲在知識庫中)是否是候選實體-屬性對中實體的實際屬性。 分類模型包括路徑嵌入引擎106、分佈表示源、屬性引擎和前饋網絡。 如本文所用,術語引擎指的是執行一組任務的數據處理裝置。 分類模型的這些引擎在確定候選實體-屬性對中的屬性是否是實體的本質屬性時的操作。
識別實體屬性關係的示例過程
該過程的操作在下文描述為由系統的組件執行,並且該過程的功能在下文描述僅用於說明目的。 該過程的操作可以通過任何適當的設備或系統來完成,例如任何適用的數據處理裝置。 該過程的功能也可以作為存儲在非暫時性計算機可讀介質上的指令來實現。 指令的執行導致數據處理設備執行處理的操作。
知識庫從數據源中獲取實體-屬性候選對。
知識庫從數據源中獲取一組句子,其中包括實體的詞和候選實體-屬性對中的屬性。
基於句子集合和候選實體-屬性對,分類模型確定候選屬性是否是候選實體的實際屬性。 懲罰的集合可以是大量的句子,例如30個或更多的句子。
執行以下操作的分類模型
- 包含實體和屬性的句子集中詞的嵌入將在下面關於以下過程進行更詳細的描述
- 使用已知的實體-屬性對創建,實體的分佈屬性嵌入,下面將更詳細地描述有關操作
- 構建,使用已知的實體-屬性對和屬性的分佈屬性嵌入,下面將更詳細地描述操作
- 根據句子集中詞的嵌入、實體的分佈屬性嵌入和屬性的分佈屬性嵌入,選擇實體-屬性候選對中的屬性是否是實體中實體的本質屬性實體屬性候選對,下面將更詳細地描述操作。
路徑嵌入引擎生成第一個向量表示,指定句子中實體和屬性之間嵌入的第一個詞。 路徑嵌入引擎通過嵌入連接句子集中這些術語的日常出現的路徑或單詞來檢測候選實體屬性術語之間的關係。
對於短語“snake is a reptile”,路徑嵌入引擎為軌道“is a”生成一個嵌入,可以用來檢測例如屬-種關係,然後可以用來識別其他實體-屬性對。
在實體和屬性之間生成單詞
路徑嵌入引擎執行以下操作以在句子中的實體和屬性之間生成單詞。 對於句子集中的每個句子,路徑嵌入引擎首先提取實體和屬性之間的依賴路徑(指定一組詞) 。 路徑嵌入引擎將句子從字符串轉換為列表,其中第一項是實體,最後一項是屬性(或者,第一項是屬性,前一項是實體) 。
依賴路徑中的每個術語(也稱為邊)使用以下特徵表示:術語的引理、詞性標籤、依賴標籤和依賴路徑的方向(左, 右或根) . 這些特徵中的每一個都被嵌入並連接起來以產生術語或邊 (V.sub.e) 的向量表示,它包含一系列向量 (V.sub.l, V.sub.pos, V.sub.dep , V.sub.dir),如下式所示: {右箭頭在 (v)}.sub.e=[{右箭頭在 (v)}.sub.l,{右箭頭在 (v)} .sub.pos,{右箭頭越過 (v)}.sub.dep,{右箭頭越過 (v)}.sub.dir]
然後,路徑嵌入引擎將每條路徑中的術語或邊的向量序列輸入到長短期記憶 (LSTM) 網絡中,該網絡為句子 (V.sub.s) 生成單個向量表示,如下所示下面的等式: {右箭頭在 (v)}.sub.s=LSTM({右箭頭在 (v)}.sub.e.sup.(1) . . . {右箭頭在 (v)}.sub .e.sup.(k))
最後,路徑嵌入引擎將句子集中所有句子的單個向量表示輸入到注意力機制中,該機制確定句子表示的加權平均值 (V.sub.sents(e,a)),如下面的等式: {右箭頭在 (v)}.sub.sents(e,a)=ATTN({右箭頭在 (v)}.sub.s.sup.(1) . . . {右箭頭在 (v ) )}.sub.s.sup.(n))
分佈表示模型基於句子生成實體的第二個向量表示和屬性的第三個向量表示。 分佈表示引擎基於上下文中的點和候選實體-屬性對的實體在句子集中出現的上下文來檢測候選實體-屬性項之間的關係。 例如,分佈式表示引擎可以確定實體“紐約”在句子集合中的使用方式表明該實體指的是美國的一個城市或州。
作為另一個示例,分佈表示引擎可以確定屬性“capital”在句子集中以暗示該屬性指的是州或國家內的重要城市的方式被使用。 因此,分佈式表示引擎使用實體出現的上下文(即句子集)生成一個向量表示,指定實體(V.sub.e)的嵌入。 分佈式表示引擎生成一個向量表示(V.sub.a),使用出現該特徵的句子集為該屬性指定一個嵌入。
分佈屬性引擎使用已知的實體-屬性對生成第四個向量表示,指定實體的分佈屬性嵌入。 存儲在知識庫中的已知實體-屬性對是實體-屬性對,已確認(例如,使用分類模型的先前處理或基於人工評估)實體中的每個屬性-屬性對是實體-屬性對中實體的本質屬性。
分佈屬性引擎執行以下操作以確定分佈屬性嵌入,該分佈屬性嵌入使用與該實體相關聯的已知實體-屬性對中的一些(例如,最常見的)或所有其他已知屬性來指定實體的嵌入。
識別實體的其他屬性
對於實體-屬性候選對中的實體,分佈屬性引擎識別與已知實體-屬性團隊中的實體相關聯的實體-屬性候選對之外的屬性。
對於候選實體-屬性對(邁克爾·喬丹,著名)中的一個實體“邁克爾·喬丹”,屬性分佈引擎可以使用邁克爾·喬丹的已知實體-屬性對,例如(邁克爾·喬丹,富有)和(邁克爾·喬丹,記錄),以識別屬性,例如 affluent 和 description 。
然後,屬性分佈引擎通過計算識別的已知屬性的加權和(如前一段所述)為實體生成嵌入,其中權重通過注意力機制學習,如下面的等式所示:箭頭 (v)}.sub.e=ATTN(.epsilon.(.alpha..sub.1) . . . .epsilon.(.alpha..sub.m))
分佈屬性引擎使用已知的實體-屬性對生成第五個向量表示,指定屬性的分佈屬性嵌入。 分佈屬性引擎執行以下操作以基於與候選屬性的已知實體相關聯的一些(無論是最常見的)或所有已知屬性來確定模型。
對於實體-屬性候選對中的點,分佈屬性引擎識別已知實體-屬性對中具有質量的已知實體。
對於每個識別的已知實體,分佈屬性引擎識別與已知實體-屬性團隊中的實體相關聯的其他屬性(即,除了包含在實體-屬性候選對中的屬性之外的屬性) 。 分佈式屬性引擎可以通過以下方式從已識別屬性中識別屬性子集:
(1)根據與每個實體關聯的已知實體的數量對屬性進行排名,例如為與更多實體關聯的屬性比與更少實體關聯的屬性分配更高的等級)
直接在您的收件箱中搜索新聞
*必需的