
Robots.txt:SEO 终极指南(2021 版)
已发表: 2021-06-10 今天,您将学习如何为网站的 SEO 创建最关键的文件之一:
今天,您将学习如何为网站的 SEO 创建最关键的文件之一:
(robots.txt 文件)。
具体来说,我将向您展示如何使用机器人排除协议来阻止机器人进入特定页面,增加抓取频率,优化抓取预算,并最终在 SERP 中获得更多正确页面的排名。
我正在报道:
- robots.txt 文件是什么
- 为什么 robots.txt 很重要
- robots.txt 的工作原理
- Robots.txt 用户代理和指令
- Robots.txt 与元机器人
- 如何找到您的 robots.txt
- 创建您的 robots.txt 文件
- Robots.txt 文件最佳实践
- Robots.txt 示例
- 如何审核您的 robots.txt 是否有错误
另外,还有很多。 让我们潜入水中。
什么是 Robots.txt 文件? 而且,为什么你需要一个
简单来说,robots.txt 文件是网络机器人的指导手册。
它通知所有类型的机器人,它们应该(和不应该)抓取网站的哪些部分。
也就是说,robots.txt 主要用作“行为准则”来控制搜索引擎机器人(AKA 网络爬虫)的活动。

每个主要搜索引擎(包括谷歌、必应和雅虎)都会定期检查 robots.txt,以获取有关如何抓取网站的说明。 这些指令称为指令。
如果没有指令——或者没有 robots.txt 文件——搜索引擎将抓取整个网站、私人页面等等。
尽管大多数搜索引擎都很听话,但需要注意的是,遵守 robots.txt 指令是可选的。 如果他们愿意,搜索引擎可以选择忽略您的 robots.txt 文件。
值得庆幸的是,谷歌不是这些搜索引擎之一。 Google 倾向于遵守 robots.txt 文件中的说明。
为什么 Robots.txt 很重要?
拥有 robots.txt 文件对于很多网站来说并不重要,尤其是小型网站。
这是因为 Google 通常可以找到并索引网站上的所有重要页面。
而且,他们会自动不索引重复的内容或不重要的页面。
但是,没有充分的理由不拥有 robots.txt 文件——所以我建议你拥有一个。
robots.txt 可让您更好地控制搜索引擎可以在您的网站上抓取和不能抓取的内容,这很有帮助,原因如下:
允许从搜索引擎阻止非公共页面
有时,您的网站上有不想编入索引的页面。
例如,您可能正在一个临时环境中开发一个新网站,您希望确保在启动之前对用户隐藏。
或者,您可能有不想出现在 SERP 中的网站登录页面。
如果是这种情况,您可以使用 robots.txt 从搜索引擎爬虫中阻止这些页面。
控制搜索引擎抓取预算
如果您很难让所有页面都在搜索引擎中编入索引,那么您可能会遇到抓取预算问题。
简而言之,搜索引擎正在用尽分配的时间来抓取您网站无用页面上的内容。

通过使用 robots.txt 阻止低效用 URL,搜索引擎机器人可以将更多的抓取预算花在最重要的页面上。
防止资源索引
最佳实践是使用“no-index”元指令来阻止单个页面被索引。
问题是,元指令不适用于多媒体资源,如 PDF 和 Word 文档。
这就是 robots.txt 派上用场的地方。
您可以在 robots.txt 文件中添加简单的文本行,搜索引擎就会被阻止访问这些多媒体文件。
(我将在本文后面向您展示如何做到这一点)
Robots.txt 如何(确切地)工作?
正如我已经分享的,robots.txt 文件充当搜索引擎机器人的指导手册。 它告诉搜索机器人他们应该在哪里(以及不应该在哪里)爬行。
这就是为什么搜索爬虫一到达网站就会查找 robots.txt 文件的原因。
如果它找到 robots.txt,爬虫会先读取它,然后再继续爬取网站。
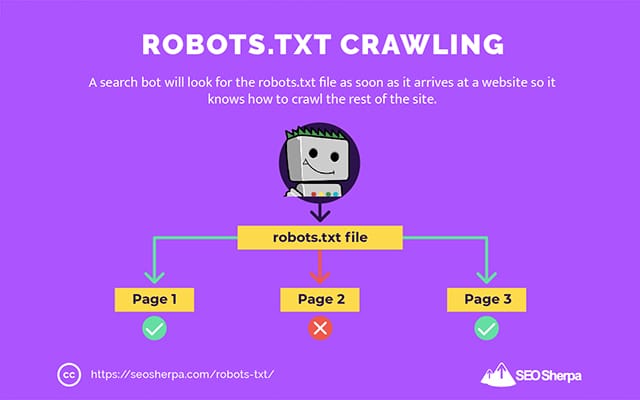
如果网络爬虫没有找到 robots.txt,或者该文件不包含禁止搜索机器人活动的指令,爬虫将继续像往常一样爬取整个网站。
为了让搜索机器人可以找到和读取 robots.txt 文件,robots.txt 以非常特殊的方式格式化。
首先,它是一个没有 HTML 标记代码的文本文件(因此扩展名为 .txt)。
其次,它被放置在网站的根文件夹中,例如 https://seosherpa.com/robots.txt。
第三,它使用所有 robots.txt 文件通用的标准语法,如下所示:
Sitemap: [URL location of sitemap] User-agent: [bot identifier] [directive 1] [directive 2] [directive ...] User-agent: [another bot identifier] [directive 1] [directive 2] [directive ...]这种语法乍一看可能令人生畏,但实际上非常简单。
简而言之,您定义了指令适用的机器人(用户代理),然后说明机器人应遵循的规则(指令)。
让我们更详细地探讨这两个组件。
用户代理
用户代理是用于定义特定网络爬虫的名称——以及其他在互联网上活动的程序。
实际上有数百个用户代理,包括设备类型和浏览器的代理。
大多数与 robots.txt 文件和 SEO 的上下文无关。 另一方面,这些你应该知道:
- 谷歌:谷歌机器人
- 谷歌图片:谷歌机器人图片
- 谷歌视频: Googlebot-视频
- Google 新闻: Googlebot 新闻
- 必应: Bingbot
- 必应图像和视频: MSNBot-Media
- 雅虎:啜饮
- Yandex: YandexBot
- 百度:百度蜘蛛
- DuckDuckGo:鸭鸭机器人
通过说明用户代理,您可以为不同的搜索引擎设置不同的规则。

例如,如果您希望某个页面显示在 Google 搜索结果中而不是百度搜索中,您可以在 robots.txt 文件中包含两组命令:一组以“User-agent: Bingbot”开头,一组以通过“用户代理:Baiduspider”。
如果您希望指令适用于所有用户代理,也可以使用星号 (*) 通配符。
例如,假设您想阻止除 DuckDuckGo 之外的所有搜索引擎机器人抓取您的网站。 以下是你的做法:
User-agent: * Disallow: / User-agent: DuckDuckBot Allow: /旁注:如果 robots.txt 文件中有相互矛盾的命令,机器人将遵循更细化的命令。
这就是为什么在上面的示例中,DuckDuckBot 知道要抓取网站,即使之前的指令(适用于所有机器人)说不抓取。 简而言之,机器人将遵循最准确适用于它们的指令。
指令
指令是您希望用户代理遵循的行为准则。 换句话说,指令定义了搜索机器人应该如何爬取你的网站。
以下是 GoogleBot 当前支持的指令,以及它们在 robots.txt 文件中的使用:
不允许
使用此指令禁止搜索机器人抓取特定 URL 路径上的某些文件和页面。

例如,如果您想阻止 GoogleBot 访问您的 wiki 及其所有页面,您的 robots.txt 应包含以下指令:
User-agent: GoogleBot Disallow: /wiki您可以使用 disallow 指令来阻止抓取精确的 URL、某个目录中的所有文件和页面,甚至您的整个网站。
允许
如果您想允许搜索引擎在您网站的其他不允许的部分中抓取特定的子目录或页面,则允许指令很有用。

假设您想阻止所有搜索引擎抓取您博客上的帖子,除了一个; 然后你会像这样使用允许指令:
User-agent: * Disallow: /blog Allow: /blog/allowable-post由于搜索机器人始终遵循 robots.txt 文件中给出的最细粒度的指令,它们知道抓取/blog/allowable-post,但不会抓取该目录中的其他帖子或文件,例如:
- /博客/后一/
- /博客/后二/
- /blog/文件名.pdf
Google 和 Bing 都支持此指令。 但其他搜索引擎没有。
网站地图
sitemap 指令用于向搜索引擎指定 XML 站点地图的位置。
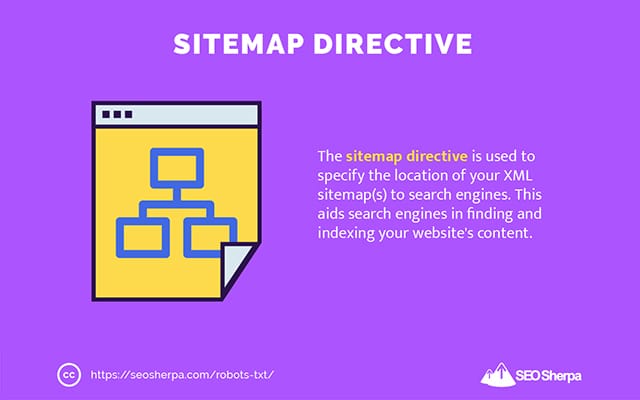
如果您不熟悉站点地图,它们用于列出您希望在搜索引擎中被抓取和索引的页面。
通过在 robots.txt 中包含站点地图指令,您可以帮助搜索引擎找到您的站点地图,进而抓取和索引您网站上最重要的页面。
话虽如此,如果您已经通过 Search Console 提交了 XML 站点地图,那么在 robots.txt 中添加站点地图对 Google 来说有些多余。 尽管如此,最好还是使用站点地图指令,因为它会告诉诸如 Ask、Bing 和 Yahoo 之类的搜索引擎在哪里可以找到您的站点地图。
以下是使用站点地图指令的 robots.txt 文件的示例:
Sitemap: https://www.website.com/sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/请注意 robots.txt 文件中站点地图指令的位置。 它最好放在 robots.txt 的最顶部。 也可以放在底部。
如果您有多个站点地图,则应将所有站点地图都包含在您的 robots.txt 文件中。 如果我们为页面和帖子使用单独的 XML 站点地图,robots.txt 文件的外观如下:
Sitemap: http://website.com/post-sitemap.xml Sitemap: http://website.com/page-sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/无论哪种方式,您只需要提及每个 XML 站点地图一次,因为所有受支持的用户代理都将遵循该指令。
请注意,与列出路径的其他 robots.txt 指令不同,站点地图指令必须说明 XML 站点地图的绝对 URL,包括协议、域名和顶级域扩展名。
注释
注释“指令”对人类有用,但搜索机器人不使用。

您可以添加评论以提醒您为什么存在某些指令,或阻止有权访问您的 robots.txt 的人删除重要指令。 简而言之,注释用于向您的 robots.txt 文件添加注释。
要添加评论,请键入。” #"后跟注释文本。
# Don't allow access to the /wp-admin/ directory for all robots. User-agent: * Disallow: /wp-admin/您可以在行首(如上所示)或同一行的指令之后(如下所示)添加注释:
User-agent: * #Applies to all robots Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.无论您选择在哪里写评论,散列之后的所有内容都将被忽略。
一直追到现在?
伟大的! 我们现在介绍了您的 robots.txt 文件所需的主要指令——这些也恰好是 Google 支持的唯一指令。
但是其他搜索引擎呢? 对于 Bing、Yahoo 和 Yandex,您可以使用另外一个指令:
爬行延迟
Crawl-delay 指令是一个非官方指令,用于防止服务器因过多的爬网请求而过载。
换句话说,您使用它来限制搜索引擎可以抓取您的网站的频率。

请注意,如果搜索引擎可以通过频繁抓取您的网站来使您的服务器过载,那么将 Crawl-delay 指令添加到您的 robots.txt 文件中只会暂时解决问题。
情况可能是,您的网站在蹩脚的主机或配置错误的主机环境上运行,您应该迅速修复这些问题。
抓取延迟指令通过定义搜索机器人可以抓取您的网站的时间(以秒为单位)来工作。
例如,如果您将抓取延迟设置为 5,搜索机器人会将一天分成 5 秒的窗口,在每个窗口中只抓取一个页面(或不抓取),一天内最多抓取大约 17,280 个 URL。
既然如此,在设置这个指令时要小心,特别是如果你有一个大型网站。 如果您的网站有数百万个页面,那么每天仅抓取 17,280 个 URL 并不是很有帮助。
每个搜索引擎处理 crawl-delay 指令的方式都不同。 让我们在下面分解它:
抓取延迟和 Bing、Yahoo 和 Yandex
Bing、Yahoo 和 Yandex 都支持 robots.txt 中的 crawl-delay 指令。
这意味着您可以为 BingBot、Slurp 和 YandexBot 用户代理设置爬网延迟指令,搜索引擎将相应地限制其爬网。
请注意,每个搜索引擎对 crawl-delay 的解释方式略有不同,因此请务必查看他们的文档:
- 必应和雅虎
- Yandex
也就是说,每个引擎的 crawl-delay 指令的格式都是相同的。 您必须将它放在 disallow OR allow 指令之后。 这是一个例子:
User-agent: BingBot Allow: /widgets/ Crawl-delay: 5爬行延迟和谷歌
Google 的爬虫不支持 crawl-delay 指令,因此在 robots.txt 中为 GoogleBot 设置 crawl-delay 是没有意义的。
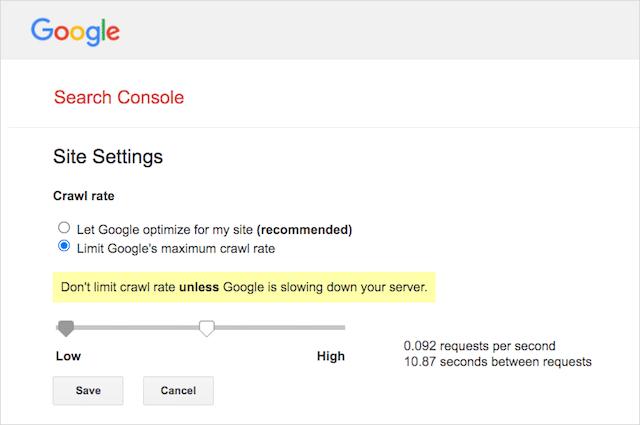
但是,Google 确实支持在 Google Search Console 中定义抓取速度。 这是如何做到的:
- 转到 Google Search Console 的设置页面。
- 选择要为其定义爬网率的属性
- 点击“限制 Google 的最大抓取速度”。
- 将滑块调整为您喜欢的抓取速度。 默认情况下,抓取速度设置为“让 Google 优化我的网站(推荐)”。
爬行延迟和百度
和谷歌一样,百度也不支持抓取延迟指令。 但是,可以注册一个百度站长工具帐户,您可以在其中控制抓取频率,类似于 Google Search Console。
底线? Robots.txt 告诉搜索引擎蜘蛛不要抓取您网站上的特定页面。
Robots.txt vs meta robots vs x-robots
那里有很多“机器人”指令。 有什么区别,或者它们是否相同?
让我提供一个简短的解释:
首先,robots.txt 是一个实际的文本文件,而 meta 和 x-robots 是网页代码中的标签。
其次,robots.txt 为机器人提供了如何抓取网站页面的建议。 另一方面,robots 的元指令为抓取和索引页面内容提供了非常明确的指令。
除了它们是什么之外,这三个都具有不同的功能。
Robots.txt 指示站点或目录范围的爬网行为,而元和 x-robots 可以指示单个页面(或页面元素)级别的索引行为。

一般来说:
如果你想阻止一个页面被索引,你应该使用“no-index”元机器人标签。 在 robots.txt 中禁止页面并不能保证它不会在搜索引擎中显示(毕竟,robots.txt 指令是建议)。 另外,如果它是从另一个网站链接的,搜索引擎机器人仍然可以找到该 URL 并将其编入索引。
相反,如果你想阻止媒体文件被索引,robots.txt 是要走的路。 您不能将元机器人标签添加到 jpeg 或 PDF 等文件中。
如何找到你的 Robots.txt
如果您的网站上已有 robots.txt 文件,则可以通过 yourdomain.com/robots.txt 访问它。

导航到浏览器中的 URL。
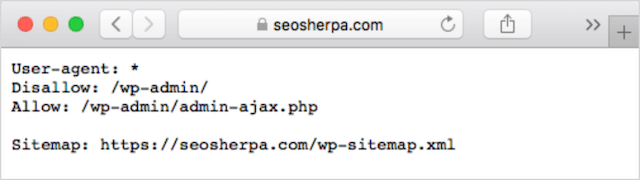
如果您看到像上面这样的基于文本的页面,那么您有一个 robots.txt 文件。
如何创建 Robots.txt 文件
如果您还没有 robots.txt 文件,创建一个很简单。
首先,打开记事本、Microsoft Word 或任何文本编辑器并将文件保存为“机器人”。
请务必使用小写字母,并选择 .txt 作为文件类型扩展名:

其次,添加您的指令。 例如,如果你想禁止所有搜索机器人爬取你的 /login/ 目录,你可以输入:
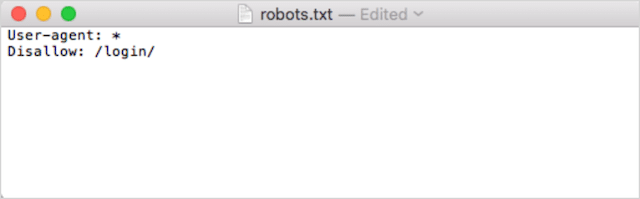
继续添加指令,直到您对 robots.txt 文件感到满意为止。
或者,您可以使用 Ryte 提供的类似工具生成 robots.txt。

使用工具的一个优点是可以最大限度地减少人为错误。
robots.txt 语法中的一个小错误可能会导致 SEO 灾难。
也就是说,使用 robots.txt 生成器的缺点是定制的机会很小。
这就是为什么我建议您学习自己编写一个 robots.txt 文件。 然后,您可以完全按照您的要求构建 robots.txt。
将 Robots.txt 文件放在哪里
将您的 robots.txt 文件添加到它适用的子域的顶级目录中。
例如,要控制yourdomain.com上的抓取行为,robots.txt 文件应该可以通过yourdomain.com/robots.txt URL 路径访问。
另一方面,如果您想控制对像shop.yourdomain.com这样的子域的抓取,robots.txt 应该可以在shop.yourdomain.com/robots.txt URL 路径上访问。
黄金法则是:
- 为您网站上的每个子域提供其自己的 robots.txt 文件。
- 将您的文件命名为robots.txt ,全部小写。
- 将文件放在它引用的子域的根目录中。
如果在根目录中找不到 robots.txt 文件,搜索引擎将假定没有指令,并将完整地抓取您的网站。
Robots.txt 文件最佳实践
接下来,让我们介绍一下 robots.txt 文件的规则。 使用这些最佳实践来避免常见的 robots.txt 陷阱:
为每个指令使用一个新行
robots.txt 中的每个指令都必须换行。
否则,搜索引擎会对要抓取的内容(和索引)感到困惑。
例如,此配置不正确:
User-agent: * Disallow: /folder/ Disallow: /another-folder/另一方面,这是一个正确设置的 robots.txt 文件:
User-agent: * Disallow: /folder/ Disallow: /another-folder/特异性“几乎”总是获胜
对于 Google 和 Bing,更精细的指令胜出。
例如,这个 Allow 指令胜过 Disallow 指令,因为它的字符长度更长。
User-agent: * Disallow: /about/ Allow: /about/company/Google 和 Bing 知道抓取 /about/company/,但不知道抓取 /about/ 目录中的任何其他页面。
然而,在其他搜索引擎的情况下,情况恰恰相反。
默认情况下,对于除 Google 和 Bing 之外的所有主要搜索引擎,第一个匹配的指令总是会获胜。
在上面的示例中,搜索引擎将遵循 Disallow 指令并忽略 Allow 指令,这意味着不会抓取 /about/company 页面。
在为所有搜索引擎创建规则时请记住这一点。
每个用户代理只有一组指令
如果您的 robots.txt 包含每个用户代理的多组指令,boh-oh-boy,它会让人感到困惑吗?
不一定适用于机器人,因为它们会将来自各种声明的所有规则组合成一组并遵循它们,但对于您而言。
为避免潜在的人为错误,请声明一次用户代理,然后在下面列出适用于该用户代理的所有指令。

通过保持整洁和简单,你不太可能犯错误。
使用通配符 (*) 简化说明
您注意到上面示例中的通配符 (*) 了吗?
这是正确的; 您可以使用通配符 (*) 将规则应用于所有用户代理并在声明指令时匹配 URL 模式。
例如,如果您想阻止搜索机器人访问您网站上的参数化产品类别 URL,您可以像这样列出每个类别:
User-agent: * Disallow: /products/watches? Disallow: /products/handbags? Disallow: /products/shoes?或者,您可以使用将规则应用于所有类别的通配符。 下面是它的外观:
User-agent: * Disallow: /products/*?此示例阻止搜索引擎抓取 /product/ 子文件夹中包含问号的所有 URL。 换句话说,任何参数化的产品类别 URL。
Google、Bing、Yahoo 支持在 robots.txt 指令和 Ask 中使用通配符。
使用“$”指定 URL 的结尾
要指示 URL 的结尾,请在 robots.txt 路径后使用美元符号 ( $ )。
假设您想阻止搜索机器人访问您网站上的所有 .doc 文件; 那么你会使用这个指令:
User-agent: * Disallow: /*.doc$这将阻止搜索引擎访问任何以 .doc 结尾的 URL。
这意味着他们不会抓取 /media/file.doc,但他们会抓取 /media/file.doc?id=72491,因为该 URL 不以“.doc”结尾。
每个子域都有自己的 robots.txt
Robots.txt 指令仅适用于 robots.txt 文件所在的(子)域。
这意味着如果您的网站有多个子域,例如:
- 域名.com
- 门票.domain.com
- events.domain.com
每个子域都需要自己的 robots.txt 文件。
robots.txt 应始终添加到每个子域的根目录中。 以下是使用上述示例的路径:
- domain.com/robots.txt
- ticket.domain.com/robots.txt
- events.domain.com/robots.txt
不要在 robots.txt 中使用 noindex
简单来说,Google 不支持 robots.txt 中的 no-index 指令。
虽然谷歌过去确实遵循它,但截至 2019 年 7 月,谷歌完全停止支持它。
如果您正在考虑使用 no-index robots.txt 指令对其他搜索引擎上的内容进行无索引,请再想一想:
非官方的无索引指令从未在 Bing 中起作用。
到目前为止,在搜索引擎中无索引内容的最佳方法是将无索引元机器人标签应用于您要排除的页面。
将 robots.txt 文件保持在 512 KB 以下
Google 目前的 robots.txt 文件大小限制为 500 千字节(512 千字节)。
这意味着可以忽略 512 KB 之后的任何内容。

也就是说,假设一个字符只消耗一个字节,您的 robots.txt 将需要很大才能达到该文件大小限制(准确地说是 512,000 个字符)。 通过减少对单独排除的页面的关注,更多地关注通配符可以控制的更广泛的模式,保持您的 robots.txt 文件精简。
目前尚不清楚其他搜索引擎是否具有 robots.txt 文件的最大允许文件大小。
Robots.txt 示例
以下是 robots.txt 文件的一些示例。
它们包括我们的 SEO 机构最常用于客户的 robots.txt 文件中的指令组合。 但请记住; 这些仅用于启发目的。 您始终需要自定义 robots.txt 文件以满足您的要求。
允许所有机器人访问所有内容
这个 robots.txt 文件没有为所有搜索引擎提供禁止规则:
User-agent: * Disallow:换句话说,它允许搜索机器人抓取所有内容。 它与空的 robots.txt 文件或根本没有 robots.txt 的用途相同。
阻止所有机器人访问所有内容
示例 robots.txt 文件告诉所有搜索引擎不要访问尾部斜杠后的任何内容。 换句话说,整个域:
User-agent: * Disallow: /简而言之,这个 robots.txt 文件会阻止所有搜索引擎机器人,并可能会阻止您的网站显示在搜索结果页面上。
阻止所有机器人抓取一个文件
在此示例中,我们阻止所有搜索机器人抓取特定文件。
User-agent: * Disallow: /directory/this-is-a-file.pdf阻止所有机器人抓取一种文件类型(doc、pdf、jpg)
由于没有索引,像“doc”或“pdf”这样的文件不能使用元机器人“no-index”标签来完成; 您可以使用以下指令来阻止特定文件类型被索引。
User-agent: * Disallow: /*.doc$ Disallow: /*.pdf$ Disallow: /*.jpg$只要没有单个文件从网络上的其他地方链接到该文件,这将有助于对该类型的所有文件取消索引。
阻止 Google 抓取多个目录
您可能希望阻止对特定机器人或所有机器人的多个目录的爬取。 在此示例中,我们阻止 Googlebot 抓取两个子目录。
User-agent: Googlebot Disallow: /admin/ Disallow: /private/请注意,您可以使用 bock 的目录数量没有限制。 只需在指令适用的用户代理下方列出每一项。
阻止 Google 抓取所有参数化网址
该指令对于使用分面导航的网站特别有用,其中可以创建许多参数化 URL。
User-agent: Googlebot Disallow: /*?该指令阻止您的抓取预算被消耗在动态 URL 上,并最大限度地抓取重要页面。 我经常使用它,尤其是在具有搜索功能的电子商务网站上。
阻止所有机器人抓取一个子目录,但允许抓取其中的一个页面
有时您可能希望阻止爬虫访问您网站的完整部分,但保留一个页面可访问。 如果这样做,请使用以下“允许”和“禁止”指令的组合:
User-agent: * Disallow: /category/ Allow: /category/widget/它告诉搜索引擎不要抓取完整的目录,不包括一个特定的页面或文件。
用于 WordPress 的 Robots.txt
这是我为 WordPress robots.txt 文件推荐的基本配置。 它会阻止对管理页面和标签以及作者 URL 的爬取,这可能会在 WordPress 网站上造成不必要的垃圾。
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /wp-admin/ Disallow: /readme.html Disallow: /refer/ Disallow: /tag/ Disallow: /author/ Disallow: /404-error/ Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xml这个 robots.txt 文件适用于大多数 WordPress 网站,但当然,您应该始终根据自己的要求对其进行调整。
如何审核您的 Robots.txt 文件中的错误
在我的时代,我在 robots.txt 文件中看到的影响排名的错误可能比技术 SEO 的任何其他方面都多。 有这么多可能相互冲突的指令,问题可能而且确实会发生。
因此,当涉及到 robots.txt 文件时,留意问题是值得的。
值得庆幸的是,Google Search Console 中的“覆盖率”报告为您提供了一种检查和监控 robots.txt 问题的方法。
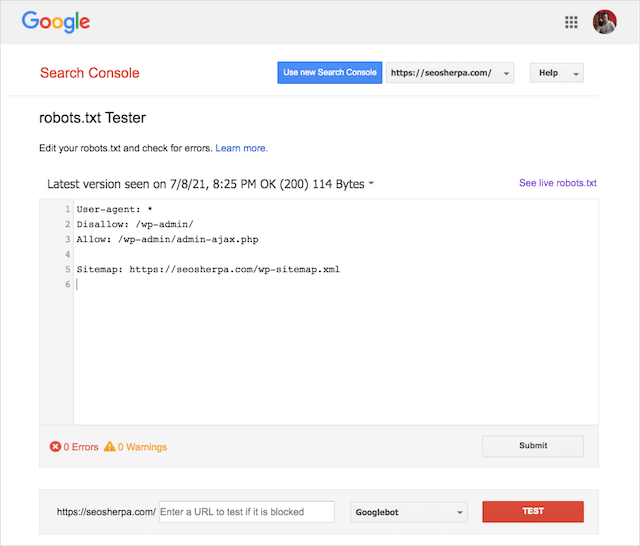
您还可以使用 Google 漂亮的 Robots.txt 测试工具来检查实时机器人文件中的错误,或者在部署新的 robots.txt 文件之前对其进行测试。
最后,我们将介绍最常见的问题、它们的含义以及如何解决它们。
提交的 URL 被 robots.txt 阻止
此错误意味着您提交的站点地图中至少有一个 URL 被 robots.txt 阻止。

正确设置的站点地图应仅包含您希望在搜索引擎中编入索引的 URL 。 因此,它不应包含任何无索引、规范化或重定向的页面。
如果您遵循了这些最佳做法,那么在您的站点地图中提交的任何页面都不会被 robots.txt 阻止。
如果您在覆盖率报告中看到“提交的 URL 被 robots.txt 阻止”,您应该调查哪些页面受到影响,然后切换您的 robots.txt 文件以删除该页面的阻止。
您可以使用 Google 的 robots.txt 测试器来查看哪个指令阻止了内容。
被 Robots.txt 屏蔽
此“错误”表示您的 robots.txt 阻止了当前不在 Google 索引中的页面。

如果此内容具有实用性并应被编入索引,请删除 robots.txt 中的抓取块。
一个简短的警告:
“被 robots.txt 阻止”不一定是错误。 事实上,这可能正是你想要的结果。
例如,您可能阻止了 robots.txt 中的某些文件,打算将它们从 Google 的索引中排除。 另一方面,如果您阻止对某些页面的抓取是为了不对它们编制索引,请考虑删除抓取块并改用机器人的元标记。
这是保证内容从 Google 索引中排除的唯一方法。
已编入索引,但已被 Robots.txt 阻止
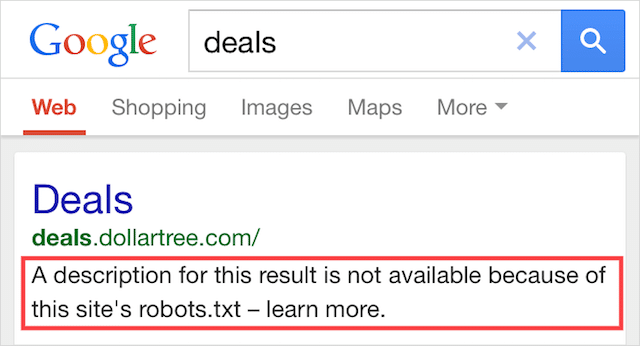
此错误意味着某些被 robots.txt 屏蔽的内容仍在 Google 中被编入索引。
当内容仍然可以被 Googlebot 发现时会发生这种情况,因为它是从网络上的其他地方链接到的。 简而言之,Googlebot 在访问您网站的 robots.txt 文件之前会抓取该内容并对其编制索引,在该文件中会看到不允许的指令。
到那时,为时已晚。 它被索引:
让我钻这个家:
如果您尝试从 Google 的搜索结果中排除内容,robots.txt 不是正确的解决方案。
我建议删除爬网块并使用元机器人无索引标签来防止索引。
相反,如果您不小心屏蔽了此内容并希望将其保留在 Google 的索引中,请删除 robots.txt 中的抓取块并保留它。
这可能有助于提高内容在 Google 搜索中的可见度。
最后的想法
Robots.txt 可用于改进网站内容的抓取和索引,这有助于您在 SERP 中更加可见。
如果使用得当,它是您网站上最重要的文字。 但是,如果使用不慎,它将成为您网站代码中的致命弱点。
好消息是,只需对用户代理和一些指令有基本的了解,就可以得到更好的搜索结果。
唯一的问题是,您将在 robots.txt 文件中使用哪些协议?
请在下面的评论中告诉我。