
Robots.txt:SEOの究極のガイド(2021年版)
公開: 2021-06-10 今日は、ウェブサイトのSEOにとって最も重要なファイルの1つを作成する方法を学びます。
今日は、ウェブサイトのSEOにとって最も重要なファイルの1つを作成する方法を学びます。
(robots.txtファイル)。
具体的には、ロボット除外プロトコルを使用して特定のページからボットをブロックし、クロール頻度を増やし、クロール予算を最適化し、最終的にSERPで適切なページのランキングを上げる方法を紹介します。
私がカバーしている:
- robots.txtファイルとは
- robots.txtが重要な理由
- robots.txtの仕組み
- Robots.txtユーザーエージェントとディレクティブ
- Robots.txtとメタロボット
- robots.txtを見つける方法
- robots.txtファイルを作成する
- Robots.txtファイルのベストプラクティス
- Robots.txtの例
- robots.txtのエラーを監査する方法
さらに、もっとたくさん。 すぐに飛び込みましょう。
Robots.txtファイルとは何ですか? そして、なぜあなたはそれを必要とするのか
簡単に言うと、robots.txtファイルはWebロボットの取扱説明書です。
これは、すべてのタイプのボットに、サイトのどのセクションをクロールする必要があるか(およびクロールすべきでないか)を通知します。
とはいえ、robots.txtは主に、検索エンジンロボット(別名Webクローラー)のアクティビティを制御するための「行動規範」として使用されます。

robots.txtは、すべての主要な検索エンジン(Google、Bing、Yahooを含む)によって定期的にチェックされ、Webサイトをクロールする方法が示されます。 これらの命令は、ディレクティブと呼ばれます。
ディレクティブがない場合、またはrobots.txtファイルがない場合、検索エンジンはWebサイト全体、プライベートページ、およびすべてをクロールします。
ほとんどの検索エンジンは従順ですが、robots.txtディレクティブに従うことはオプションであることに注意することが重要です。 必要に応じて、検索エンジンはrobots.txtファイルを無視することを選択できます。
ありがたいことに、Googleはそれらの検索エンジンの1つではありません。 Googleはrobots.txtファイルの指示に従う傾向があります。
Robots.txtが重要なのはなぜですか?
robots.txtファイルがあることは、多くのWebサイト、特に小さなWebサイトにとって重要ではありません。
これは、Googleが通常、サイト上の重要なページをすべて検索してインデックスに登録できるためです。
また、重要でない重複コンテンツやページには自動的にインデックスが付けられません。
それでも、robots.txtファイルを持たない理由はありません。そのため、持っておくことをお勧めします。
robots.txtを使用すると、検索エンジンがWebサイトをクロールできるものとできないものをより細かく制御できます。これは、いくつかの理由で役立ちます。
非公開ページを検索エンジンからブロックできるようにします
インデックスを作成したくないページがサイトにある場合があります。
たとえば、ステージング環境で新しいWebサイトを開発していて、起動するまでユーザーから確実に隠されている場合があります。
または、SERPに表示したくないWebサイトのログインページがある場合もあります。
この場合、robots.txtを使用して、これらのページを検索エンジンのクローラーからブロックできます。
検索エンジンのクロール予算を管理する
検索エンジンですべてのページのインデックスを作成するのに苦労している場合は、クロール予算の問題が発生している可能性があります。
簡単に言えば、検索エンジンはあなたのウェブサイトのデッドウェイトページであなたのコンテンツをクロールするために割り当てられた時間を使い果たしています。

robots.txtでユーティリティの低いURLをブロックすることで、検索エンジンロボットは、最も重要なページにより多くのクロール予算を費やすことができます。
リソースのインデックス作成を防止します
「no-index」メタディレクティブを使用して、個々のページがインデックスに登録されないようにすることをお勧めします。
問題は、メタディレクティブがPDFやWordドキュメントなどのマルチメディアリソースではうまく機能しないことです。
そこでrobots.txtが便利です。
robots.txtファイルに簡単なテキスト行を追加すると、検索エンジンがこれらのマルチメディアファイルにアクセスできなくなります。
(この投稿の後半で、その方法を正確に説明します)
Robots.txtはどのように(正確に)機能しますか?
すでに共有したように、robots.txtファイルは検索エンジンロボットの取扱説明書として機能します。 これは、検索ボットにクロールする場所(およびクロールしない場所)を指示します。
これが、検索クローラーがWebサイトに到着するとすぐにrobots.txtファイルを検索する理由です。
robots.txtが見つかった場合、クローラーはサイトのクロールを続行する前に最初にそれを読み取ります。
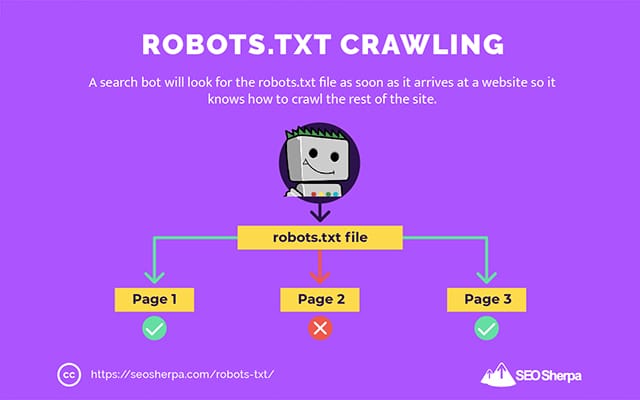
Webクローラーがrobots.txtを見つけられない場合、またはファイルに検索ボットのアクティビティを禁止するディレクティブが含まれていない場合、クローラーは通常どおりサイト全体をスパイダーし続けます。
robots.txtファイルを検索ボットが検索して読み取り可能にするために、robots.txtは非常に特殊な方法でフォーマットされています。
まず、これはHTMLマークアップコードのないテキストファイルです(したがって、拡張子は.txtです)。
次に、https://seosherpa.com/robots.txtなどのWebサイトのルートフォルダーに配置されます。
第三に、次のように、すべてのrobots.txtファイルに共通の標準構文を使用します。
Sitemap: [URL location of sitemap] User-agent: [bot identifier] [directive 1] [directive 2] [directive ...] User-agent: [another bot identifier] [directive 1] [directive 2] [directive ...]この構文は一見気が遠くなるように見えるかもしれませんが、実際には非常に単純です。
簡単に言うと、指示が適用されるボット(ユーザーエージェント)を定義してから、ボットが従う必要のあるルール(ディレクティブ)を記述します。
これらの2つのコンポーネントについて詳しく見ていきましょう。
ユーザーエージェント
ユーザーエージェントは、特定のWebクローラー、およびインターネット上でアクティブな他のプログラムを定義するために使用される名前です。
デバイスタイプやブラウザのエージェントを含む、文字通り何百ものユーザーエージェントがあります。
ほとんどはrobots.txtファイルとSEOのコンテキストでは無関係です。 一方、あなたが知っておくべきこれらは:
- Google: Googlebot
- Google画像検索: Googlebot-画像
- Googleビデオ: Googlebot-ビデオ
- Googleニュース: Googlebot-ニュース
- Bing: Bingbot
- Bingの画像とビデオ: MSNBot-メディア
- Yahoo: Slurp
- Yandex: YandexBot
- Baidu :Baiduspider
- DuckDuckGo: DuckDuckBot
ユーザーエージェントを指定することで、検索エンジンごとに異なるルールを設定できます。

たとえば、特定のページをGoogle検索結果に表示したいが、Baidu検索には表示したくない場合は、robots.txtファイルに2セットのコマンドを含めることができます。1セットは「User-agent:Bingbot」が前にあり、もう1セットは前にあります。 「ユーザーエージェント:Baiduspider」による。
ディレクティブをすべてのユーザーエージェントに適用する場合は、スター(*)ワイルドカードを使用することもできます。
たとえば、DuckDuckGoを除くすべての検索エンジンロボットがサイトをクロールするのをブロックしたいとします。 これがあなたがそれをする方法です:
User-agent: * Disallow: / User-agent: DuckDuckBot Allow: /補足: robots.txtファイルに矛盾するコマンドがある場合、ボットはより詳細なコマンドに従います。
そのため、上記の例では、以前のディレクティブ(すべてのボットに適用)がクロールしないと言っていたとしても、DuckDuckBotはWebサイトをクロールすることを知っています。 つまり、ボットは最も正確に適用される指示に従います。
ディレクティブ
ディレクティブは、ユーザーエージェントに従わせたい行動規範です。 つまり、ディレクティブは、検索ボットがWebサイトをクロールする方法を定義します。
GoogleBotが現在サポートしているディレクティブと、robots.txtファイル内での使用は次のとおりです。
禁止する
このディレクティブを使用して、検索ボットが特定のURLパス上の特定のファイルやページをクロールすることを禁止します。

たとえば、GoogleBotがウィキとそのすべてのページにアクセスするのをブロックしたい場合は、robots.txtに次のディレクティブを含める必要があります。
User-agent: GoogleBot Disallow: /wikidisallowディレクティブを使用して、正確なURL、特定のディレクトリ内のすべてのファイルとページ、さらにはWebサイト全体のクロールをブロックできます。
許可する
allowディレクティブは、サイトの許可されていないセクションで、検索エンジンが特定のサブディレクトリまたはページをクロールすることを許可する場合に役立ちます。

1つを除いて、すべての検索エンジンがブログの投稿をクロールしないようにしたいとします。 次に、次のようなallowディレクティブを使用します。
User-agent: * Disallow: /blog Allow: /blog/allowable-post検索ボットは常にrobots.txtファイルで指定された最も詳細な指示に従うため、 / blog / allowable-postをクロールすることは知っていますが、そのディレクトリ内の他の投稿やファイルをクロールすることはありません。
- / blog / post-one /
- / blog / post-two /
- /blog/file-name.pdf
GoogleとBingの両方がこのディレクティブをサポートしています。 しかし、他の検索エンジンはそうではありません。
サイトマップ
サイトマップディレクティブは、検索エンジンへのXMLサイトマップの場所を指定するために使用されます。
サイトマップを初めて使用する場合は、検索エンジンでクロールしてインデックスに登録するページを一覧表示するために使用されます。
robots.txtにサイトマップディレクティブを含めることで、検索エンジンがサイトマップを見つけ、ウェブサイトの最も重要なページをクロールしてインデックスに登録できるようになります。
そうは言っても、検索コンソールを介してXMLサイトマップを既に送信している場合、robots.txtにサイトマップを追加することはGoogleにとっていくぶん冗長です。 それでも、サイトマップディレクティブを使用することをお勧めします。これは、Ask、Bing、Yahooなどの検索エンジンにサイトマップの場所を通知するためです。
次に、sitemapディレクティブを使用したrobots.txtファイルの例を示します。
Sitemap: https://www.website.com/sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/robots.txtファイルにサイトマップディレクティブが配置されていることに注意してください。 robots.txtの一番上に配置するのが最適です。 下部に配置することもできます。
複数のサイトマップがある場合は、それらすべてをrobots.txtファイルに含める必要があります。 ページと投稿に別々のXMLサイトマップがある場合、robots.txtファイルは次のようになります。
Sitemap: http://website.com/post-sitemap.xml Sitemap: http://website.com/page-sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/いずれにせよ、サポートされているすべてのユーザーエージェントはディレクティブに従うため、各XMLサイトマップについて言及する必要があるのは1回だけです。
パスを一覧表示する他のrobots.txtディレクティブとは異なり、sitemapディレクティブは、プロトコル、ドメイン名、トップレベルドメイン拡張子など、XMLサイトマップの絶対URLを指定する必要があることに注意してください。
コメントコメント
コメント「ディレクティブ」は人間には役立ちますが、検索ボットでは使用されません。

コメントを追加して、特定のディレクティブが存在する理由を思い出させたり、robots.txtにアクセスできるディレクティブが重要なディレクティブを削除しないようにすることができます。 つまり、コメントはrobots.txtファイルにメモを追加するために使用されます。
コメントを追加するには、と入力します。」 #"の後にコメントテキストが続きます。
# Don't allow access to the /wp-admin/ directory for all robots. User-agent: * Disallow: /wp-admin/行の先頭(上記のように)または同じ行のディレクティブの後に(以下に示すように)コメントを追加できます。
User-agent: * #Applies to all robots Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.コメントを書くことを選択した場合は常に、ハッシュの後のすべてが無視されます。
これまでのところフォローしていますか?
すごい! これで、robots.txtファイルに必要な主なディレクティブについて説明しました。これらは、Googleでサポートされている唯一のディレクティブでもあります。
しかし、他の検索エンジンはどうですか? Bing、Yahoo、Yandexの場合、使用できるディレクティブがもう1つあります。
クロール遅延
Crawl-delayディレクティブは、サーバーがあまりにも多くのクロール要求で過負荷になるのを防ぐために使用される非公式のディレクティブです。
つまり、検索エンジンがサイトをクロールできる頻度を制限するために使用します。

検索エンジンがウェブサイトを頻繁にクロールしてサーバーに過負荷をかける可能性がある場合は、robots.txtファイルにCrawl-delayディレクティブを追加しても、問題は一時的に修正されるだけです。
場合によっては、あなたのウェブサイトが安っぽいホスティングまたは誤って構成されたホスティング環境で実行されている可能性があり、それはあなたが迅速に修正する必要があるものです。
クロール遅延ディレクティブは、検索ボットがWebサイトをクロールできる時間を秒単位で定義することで機能します。
たとえば、クロール遅延を5に設定すると、検索ボットは1日を5秒のウィンドウにスライスし、各ウィンドウで1ページのみ(またはまったくクロールしない)、1日で最大約17,280のURLをクロールします。
そのため、特に大規模なWebサイトを使用している場合は、このディレクティブを設定するときに注意してください。 サイトに数百万のページがある場合、1日あたり17,280のURLがクロールされるだけではあまり役に立ちません。
各検索エンジンがcrawl-delayディレクティブを処理する方法は異なります。 以下に分解してみましょう。
クロール遅延とBing、Yahoo、Yandex
Bing、Yahoo、Yandexはすべて、robots.txtのcrawl-delayディレクティブをサポートしています。
これは、BingBot、Slurp、およびYandexBotユーザーエージェントにクロール遅延ディレクティブを設定できることを意味し、検索エンジンはそれに応じてクロールを抑制します。
ただし、各検索エンジンはクロール遅延をわずかに異なる方法で解釈することに注意してください。そのため、必ずドキュメントを確認してください。
- BingとYahoo
- Yandex
とはいえ、これらの各エンジンのクロール遅延ディレクティブの形式は同じです。 disallowまたはallowディレクティブの直後に配置する必要があります。 次に例を示します。
User-agent: BingBot Allow: /widgets/ Crawl-delay: 5クロール遅延とGoogle
Googleのクローラーはcrawl-delayディレクティブをサポートしていないため、robots.txtでGoogleBotのクロール遅延を設定しても意味がありません。
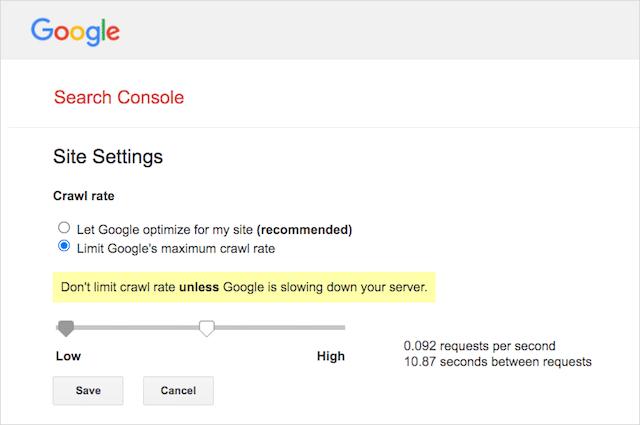
ただし、GoogleはGoogle検索コンソールでのクロール速度の定義をサポートしています。 方法は次のとおりです。
- Google検索コンソールの設定ページに移動します。
- クロール速度を定義するプロパティを選択します
- [Googleの最大クロール速度を制限する]をクリックします。
- スライダーをお好みのクロール速度に調整します。 デフォルトでは、クロール速度は「Googleに自分のサイト用に最適化させる(推奨)」に設定されています。
クロール遅延とBaidu
Googleと同様に、Baiduはクロール遅延ディレクティブをサポートしていません。 ただし、Google Search Consoleと同様に、クロールの頻度を制御できるBaiduWebmasterToolsアカウントを登録することは可能です。
結論は? Robots.txtは、検索エンジンのスパイダーにWebサイトの特定のページをクロールしないように指示します。
Robots.txtとメタロボットとxロボット
そこにはたくさんの「ロボット」の指示があります。 違いは何ですか、それとも同じですか?
簡単な説明をさせてください。
まず、robots.txtは実際のテキストファイルですが、metaおよびx-robotsはWebページのコード内のタグです。
次に、robots.txtは、Webサイトのページをクロールする方法についてボットに提案します。 一方、ロボットのメタディレクティブは、ページのコンテンツのクロールとインデックス作成に関する非常に堅固な指示を提供します。
それらが何であるかを超えて、3つはすべて異なる機能を果たします。
Robots.txtはサイトまたはディレクトリ全体のクロール動作を指示しますが、メタロボットとxロボットは個々のページ(またはページ要素)レベルでのインデックス作成動作を指示できます。

一般に:
ページがインデックスに登録されないようにする場合は、「インデックスなし」のメタロボットタグを使用する必要があります。 robots.txtでページを禁止しても、検索エンジンに表示されないことを保証するものではありません(robots.txtディレクティブは結局のところ提案です)。 さらに、検索エンジンロボットは、別のWebサイトからリンクされている場合でも、そのURLを見つけてインデックスを作成できます。
逆に、メディアファイルのインデックス作成を停止したい場合は、robots.txtが最適です。 jpegやPDFなどのファイルにメタロボットタグを追加することはできません。
Robots.txtを見つける方法
ウェブサイトにrobots.txtファイルが既にある場合は、yourdomain.com/robots.txtからアクセスできます。

ブラウザでURLに移動します。
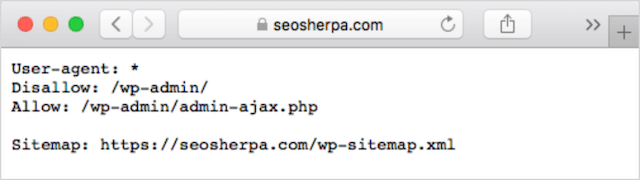
上記のようなテキストベースのページが表示された場合は、robots.txtファイルがあります。
Robots.txtファイルを作成する方法
robots.txtファイルをまだ持っていない場合は、作成するのは簡単です。
まず、メモ帳、Microsoft Word、または任意のテキストエディタを開き、ファイルを「ロボット」として保存します。
必ず小文字を使用し、ファイルタイプ拡張子として.txtを選択してください。

次に、ディレクティブを追加します。 たとえば、すべての検索ボットが/ login /ディレクトリをクロールすることを禁止したい場合は、次のように入力します。
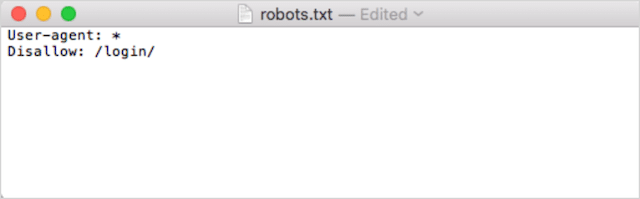
robots.txtファイルに満足するまで、ディレクティブを追加し続けます。
または、Ryteのこのようなツールを使用してrobots.txtを生成することもできます。

ツールを使用する利点の1つは、人的エラーを最小限に抑えることです。
robots.txtの構文に小さな間違いが1つあるだけで、SEOの惨事に終わる可能性があります。
とはいえ、robots.txtジェネレーターを使用することの欠点は、カスタマイズの機会が最小限に抑えられることです。
そのため、robot.txtファイルを自分で作成する方法を学ぶことをお勧めします。 次に、要件に正確に一致するrobots.txtを作成できます。
Robots.txtファイルを配置する場所
適用するサブドメインの最上位ディレクトリにrobots.txtファイルを追加します。
たとえば、 yourdomain.comでのクロール動作を制御するには、 yourdomain.com /robots.txtURLパスでrobots.txtファイルにアクセスできる必要があります。
一方、 shop.yourdomain.comなどのサブドメインでクロールを制御する場合は、 shop.yourdomain.com /robots.txtURLパスでrobots.txtにアクセスできる必要があります。
ゴールデンルールは次のとおりです。
- ウェブサイト上のすべてのサブドメインに独自のrobots.txtファイルを割り当てます。
- ファイルにrobots.txtという名前をすべて小文字で付けます。
- 参照するサブドメインのルートディレクトリにファイルを配置します。
robots.txtファイルがルートディレクトリに見つからない場合、検索エンジンはディレクティブがないと見なし、Webサイト全体をクロールします。
Robots.txtファイルのベストプラクティス
次に、robots.txtファイルのルールについて説明します。 一般的なrobots.txtの落とし穴を回避するには、次のベストプラクティスを使用してください。
ディレクティブごとに新しい行を使用する
robots.txtの各ディレクティブは新しい行に配置する必要があります。
そうでない場合、検索エンジンは何をクロール(およびインデックス作成)するかについて混乱します。
たとえば、これは正しく構成されていません。
User-agent: * Disallow: /folder/ Disallow: /another-folder/一方、これは正しく設定されたrobots.txtファイルです。
User-agent: * Disallow: /folder/ Disallow: /another-folder/特異性は「ほぼ」常に勝ちます
GoogleとBingに関しては、よりきめ細かいディレクティブが優先されます。
たとえば、このAllowディレクティブは、文字の長さが長いため、Disallowディレクティブよりも優先されます。
User-agent: * Disallow: /about/ Allow: /about/company/GoogleとBingは、/ about / company /をクロールすることを知っていますが、/about/ディレクトリ内の他のページはクロールしません。
ただし、他の検索エンジンの場合は、その逆になります。
デフォルトでは、GoogleとBing以外のすべての主要な検索エンジンでは、最初に一致するディレクティブが常に優先されます。
上記の例では、検索エンジンはDisallowディレクティブに従い、Allowディレクティブを無視します。これは、/ about/companyページがクロールされないことを意味します。
すべての検索エンジンのルールを作成するときは、このことに注意してください。
ユーザーエージェントごとに1つのディレクティブグループのみ
robots.txtにユーザーエージェントboh-oh-boyごとにディレクティブの複数のグループが含まれている場合、混乱する可能性がありますか?
ロボットは必ずしも必要ではありません。さまざまな宣言のすべてのルールを1つのグループにまとめて、それらすべてに従うためですが、あなたのためです。
人為的エラーの可能性を回避するために、ユーザーエージェントを一度記述してから、そのユーザーエージェントに適用されるすべてのディレクティブを以下にリストします。

物事をきちんとシンプルに保つことで、失敗する可能性が低くなります。
手順を簡略化するためにワイルドカード(*)を使用する
上記の例のワイルドカード(*)に気づきましたか?
それは正しい; ワイルドカード(*)を使用して、すべてのユーザーエージェントにルールを適用し、ディレクティブを宣言するときにURLパターンを一致させることができます。
たとえば、検索ボットがWebサイト上のパラメーター化された製品カテゴリのURLにアクセスしないようにする場合は、次のように各カテゴリを一覧表示できます。
User-agent: * Disallow: /products/watches? Disallow: /products/handbags? Disallow: /products/shoes?または、すべてのカテゴリにルールを適用するワイルドカードを使用することもできます。 外観は次のとおりです。
User-agent: * Disallow: /products/*?この例では、検索エンジンが疑問符を含む/product/サブフォルダー内のすべてのURLをクロールするのをブロックします。 つまり、パラメータ化された製品カテゴリのURL。
Google、Bing、Yahooは、robots.txtディレクティブおよびAsk内でのワイルドカードの使用をサポートしています。
「$」を使用してURLの終わりを指定します
URLの終わりを示すには、robots.txtパスの後にドル記号( $ )を使用します。
Webサイト上のすべての.docファイルにアクセスする検索ボットを停止したいとします。 次に、このディレクティブを使用します。
User-agent: * Disallow: /*.doc$これにより、検索エンジンが.docで終わるURLにアクセスできなくなります。
つまり、/ media / file.docはクロールしませんが、URLが「.doc」で終わっていないため、/ media / file.doc?id=72491をクロールします。
各サブドメインは独自のrobots.txtを取得します
Robots.txtディレクティブは、robots.txtファイルがホストされている(サブ)ドメインにのみ適用されます。
これは、サイトに次のような複数のサブドメインがある場合を意味します。
- domain.com
- ticket.domain.com
- events.domain.com
各サブドメインには、独自のrobots.txtファイルが必要です。
robots.txtは、常に各サブドメインのルートディレクトリに追加する必要があります。 上記の例を使用すると、パスは次のようになります。
- domain.com/robots.txt
- ticket.domain.com/robots.txt
- events.domain.com/robots.txt
robots.txtでnoindexを使用しないでください
簡単に言えば、Googleはrobots.txtのno-indexディレクティブをサポートしていません。
グーグルは過去にそれをフォローしていましたが、2019年7月の時点で、グーグルはそれを完全にサポートすることをやめました。
また、no-index robots.txtディレクティブを使用して他の検索エンジンのコンテンツにインデックスを付けないことを考えている場合は、もう一度考えてみてください。
非公式のインデックスなしディレクティブは、Bingでは機能しませんでした。
これまでのところ、検索エンジンでコンテンツのインデックスを作成しない最善の方法は、除外するページにインデックスなしのメタロボットタグを適用することです。
robots.txtファイルを512KB未満に保ちます
Googleには現在、500キビバイト(512キロバイト)のrobots.txtファイルサイズ制限があります。
これは、512KB以降のコンテンツは無視される可能性があることを意味します。

とはいえ、1文字が1バイトしか消費しない場合、そのファイルサイズ制限(正確には512,000文字)に達するには、robots.txtが巨大である必要があります。 個別に除外されたページに焦点を当てず、ワイルドカードで制御できるより広範なパターンに焦点を当てることで、robots.txtファイルを無駄のない状態に保ちます。
他の検索エンジンがrobots.txtファイルの最大許容ファイルサイズを持っているかどうかは不明です。
Robots.txtの例
以下はrobots.txtファイルのいくつかの例です。
これらには、SEOエージェンシーがクライアントのrobots.txtファイルで最もよく使用するディレクティブの組み合わせが含まれています。 ただし、覚えておいてください。 これらはインスピレーションの目的でのみ使用されます。 要件を満たすために、robots.txtファイルを常にカスタマイズする必要があります。
すべてのロボットにすべてへのアクセスを許可する
このrobots.txtファイルは、すべての検索エンジンに禁止ルールを提供していません。
User-agent: * Disallow:つまり、検索ボットがすべてをクロールできるようにします。 これは、robots.txtファイルが空であるか、robots.txtがまったくない場合と同じ目的で機能します。
すべてのロボットがすべてにアクセスするのをブロックする
サンプルのrobots.txtファイルは、すべての検索エンジンに、末尾のスラッシュの後に何にもアクセスしないように指示しています。 言い換えれば、ドメイン全体:
User-agent: * Disallow: /つまり、このrobots.txtファイルはすべての検索エンジンロボットをブロックし、検索結果ページにサイトが表示されなくなる可能性があります。
すべてのロボットが1つのファイルをクロールするのをブロックします
この例では、すべての検索ボットが特定のファイルをクロールするのをブロックします。
User-agent: * Disallow: /directory/this-is-a-file.pdfすべてのロボットが1つのファイルタイプ(doc、pdf、jpg)をクロールするのをブロックします
インデックスが作成されていないため、メタロボットの「インデックスなし」タグを使用して「doc」や「pdf」などのファイルを作成することはできません。 次のディレクティブを使用して、特定のファイルタイプのインデックス作成を停止できます。
User-agent: * Disallow: /*.doc$ Disallow: /*.pdf$ Disallow: /*.jpg$これは、個々のファイルがWeb上の他の場所からリンクされていない限り、そのタイプのすべてのファイルのインデックスを解除するために機能します。
Googleが複数のディレクトリをクロールするのをブロックする
特定のボットまたはすべてのボットの複数のディレクトリのクロールをブロックしたい場合があります。 この例では、Googlebotが2つのサブディレクトリをクロールするのをブロックしています。
User-agent: Googlebot Disallow: /admin/ Disallow: /private/bockを使用できるディレクトリの数に制限はありません。 ディレクティブが適用されるユーザーエージェントの下にそれぞれをリストするだけです。
Googleがパラメータ化されたすべてのURLをクロールするのをブロックする
このディレクティブは、多くのパラメーター化されたURLを作成できるファセットナビゲーションを使用するWebサイトで特に役立ちます。
User-agent: Googlebot Disallow: /*?このディレクティブは、クロールバジェットが動的URLで消費されるのを防ぎ、重要なページのクロールを最大化します。 私はこれを定期的に使用しています。特に、検索機能を備えたeコマースWebサイトで使用しています。
すべてのボットが1つのサブディレクトリをクロールするのをブロックしますが、その中の1つのページをクロールできるようにします
クローラーがサイトのセクション全体にアクセスするのをブロックしたいが、1つのページにはアクセスできるようにしておきたい場合があります。 その場合は、「allow」ディレクティブと「disallow」ディレクティブを次のように組み合わせて使用します。
User-agent: * Disallow: /category/ Allow: /category/widget/これは、特定の1つのページまたはファイルを除いて、ディレクトリ全体をクロールしないように検索エンジンに指示します。
WordPress用のRobots.txt
これは、WordPressrobots.txtファイルに推奨する基本構成です。 これは、管理ページ、タグ、および作成者のURLのクロールをブロックし、WordPressWebサイトに不要な問題を引き起こす可能性があります。
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /wp-admin/ Disallow: /readme.html Disallow: /refer/ Disallow: /tag/ Disallow: /author/ Disallow: /404-error/ Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xmlこのrobots.txtファイルは、ほとんどのWordPress Webサイトでうまく機能しますが、もちろん、常に独自の要件に合わせて調整する必要があります。
Robots.txtファイルのエラーを監査する方法
私の時代には、robots.txtファイルで、おそらく技術的なSEOの他のどの側面よりもランクに影響を与えるエラーが多く見られました。 競合する可能性のあるディレクティブが非常に多いため、問題が発生する可能性があります。
したがって、robots.txtファイルに関しては、問題に注意を払う必要があります。
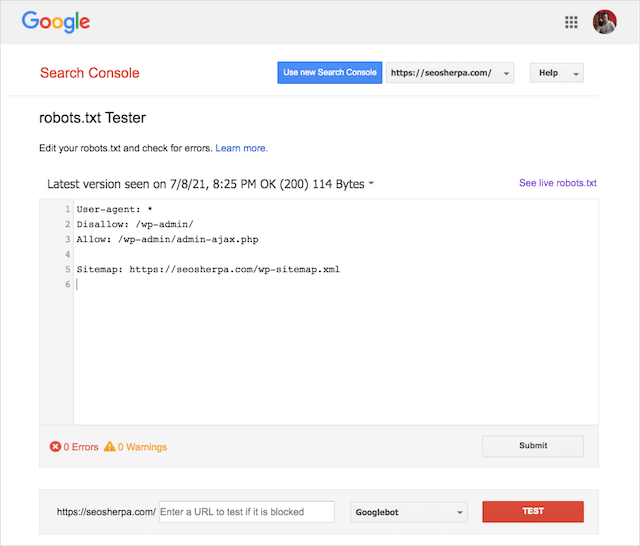
ありがたいことに、Google Search Console内の「カバレッジ」レポートは、robots.txtの問題を確認および監視する方法を提供します。
また、Googleの気の利いたRobots.txtテストツールを使用して、ライブロボットファイル内のエラーをチェックしたり、新しいrobots.txtファイルをデプロイする前にテストしたりすることもできます。
最後に、最も一般的な問題、それらの意味、およびそれらに対処する方法について説明します。
robots.txtによってブロックされた送信済みURL
このエラーは、送信されたサイトマップのURLの少なくとも1つがrobots.txtによってブロックされていることを意味します。

正しく設定されたサイトマップには、検索エンジンでインデックスを作成するURLのみを含める必要があります。 そのため、インデックス付けされていない、正規化された、またはリダイレクトされたページを含めることはできません。
これらのベストプラクティスに従っている場合は、サイトマップで送信されたページがrobots.txtによってブロックされないようにする必要があります。
カバレッジレポートに「送信されたURLがrobots.txtによってブロックされています」と表示されている場合は、影響を受けるページを調査してから、robots.txtファイルを切り替えてそのページのブロックを削除する必要があります。
Googleのrobots.txtテスターを使用して、どのディレクティブがコンテンツをブロックしているかを確認できます。
Robots.txtによってブロックされました
この「エラー」は、現在Googleのインデックスに含まれていないページがrobots.txtによってブロックされていることを意味します。

このコンテンツに有用性があり、インデックスを作成する必要がある場合は、robots.txtのクロールブロックを削除してください。
警告の短い言葉:
「robots.txtによってブロックされました」は必ずしもエラーではありません。 実際、それはまさにあなたが望む結果かもしれません。
たとえば、robots.txt内の特定のファイルをブロックして、Googleのインデックスから除外しようとしている可能性があります。 一方、インデックスを作成しない目的で特定のページのクロールをブロックした場合は、クロールブロックを削除して、代わりにロボットのメタタグを使用することを検討してください。
これが、Googleのインデックスからコンテンツが除外されることを保証する唯一の方法です。
Robots.txtによってブロックされていますが、インデックスに登録されています
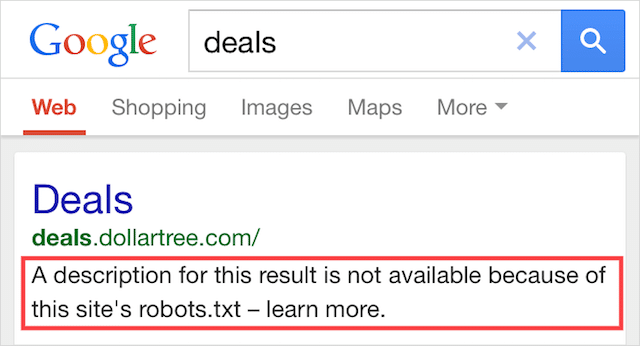
このエラーは、robots.txtによってブロックされたコンテンツの一部が引き続きGoogleでインデックスに登録されていることを意味します。
これは、コンテンツがWeb上の他の場所からリンクされているために、コンテンツがまだGooglebotによって検出可能である場合に発生します。 つまり、Googlebotはそのコンテンツをクロールし、インデックスを作成してから、ウェブサイトのrobots.txtファイルにアクセスします。このファイルには、許可されていないディレクティブが表示されます。
それまでには、手遅れです。 そしてそれは索引付けされます:
これを家にドリルさせてください:
Googleの検索結果からコンテンツを除外しようとしている場合、robots.txtは正しい解決策ではありません。
クロールブロックを削除し、代わりにインデックス作成を防ぐためにメタロボットのインデックスなしタグを使用することをお勧めします。
逆に、このコンテンツを誤ってブロックし、Googleのインデックスに残したい場合は、robots.txtのクロールブロックを削除してそのままにしておきます。
これは、Google検索でのコンテンツの可視性を向上させるのに役立つ場合があります。
最終的な考え
Robots.txtを使用すると、ウェブサイトのコンテンツのクロールとインデックス作成を改善できます。これにより、SERPでより目立つようになります。
効果的に使用すると、それはあなたのウェブサイトで最も重要なテキストです。 しかし、不注意に使用すると、Webサイトのコードのアキレス腱になります。
良いニュースは、ユーザーエージェントの基本的な理解と少数のディレクティブだけで、より良い検索結果があなたの手の届くところにあります。
唯一の問題は、 robots.txtファイルで使用するプロトコルを教えてください。
以下のコメントで教えてください。