
Robots.txt: la guida definitiva per SEO (edizione 2021)
Pubblicato: 2021-06-10 Oggi imparerai come creare uno dei file più critici per la SEO di un sito web:
Oggi imparerai come creare uno dei file più critici per la SEO di un sito web:
(Il file robots.txt).
In particolare, ti mostrerò come utilizzare i protocolli di esclusione dei robot per bloccare i bot da pagine particolari, aumentare la frequenza di scansione, ottimizzare il budget di scansione e, in definitiva, ottenere più posizionamento della pagina giusta nelle SERP.
Sto coprendo:
- Che cos'è un file robots.txt
- Perché robots.txt è importante
- Come funziona robots.txt
- Agenti utente e direttive di Robots.txt
- Robots.txt vs meta robot
- Come trovare il tuo robots.txt
- Creazione del file robots.txt
- Procedure consigliate per il file Robots.txt
- Esempi di Robots.txt
- Come controllare il tuo robots.txt per errori
In più, molto di più. Entriamo subito.
Che cos'è un file Robots.txt? E, perché ne hai bisogno
In parole povere, un file robots.txt è un manuale di istruzioni per i robot web.
Informa i bot di tutti i tipi, quali sezioni di un sito dovrebbero (e non dovrebbero) scansionare.
Detto questo, robots.txt viene utilizzato principalmente come "codice di condotta" per controllare l'attività dei robot dei motori di ricerca (AKA web crawler).

Il robots.txt viene controllato regolarmente da tutti i principali motori di ricerca (inclusi Google, Bing e Yahoo) per istruzioni su come eseguire la scansione del sito web. Queste istruzioni sono note come direttive .
Se non ci sono direttive - o nessun file robots.txt - i motori di ricerca eseguiranno la scansione dell'intero sito Web, delle pagine private e di tutto.
Sebbene la maggior parte dei motori di ricerca siano obbedienti, è importante notare che il rispetto delle direttive robots.txt è facoltativo. Se lo desiderano, i motori di ricerca possono scegliere di ignorare il tuo file robots.txt.
Per fortuna, Google non è uno di quei motori di ricerca. Google tende a obbedire alle istruzioni in un file robots.txt.
Perché Robots.txt è importante?
Avere un file robots.txt non è fondamentale per molti siti Web, specialmente quelli piccoli.
Questo perché Google di solito può trovare e indicizzare tutte le pagine essenziali di un sito.
Inoltre, NON indicizzeranno automaticamente contenuti duplicati o pagine non importanti.
Tuttavia, non c'è una buona ragione per non avere un file robots.txt, quindi ti consiglio di averne uno.
Un robots.txt ti offre un maggiore controllo su ciò che i motori di ricerca possono e non possono eseguire la scansione del tuo sito web e ciò è utile per diversi motivi:
Consente di bloccare le pagine non pubbliche dai motori di ricerca
A volte hai pagine sul tuo sito che non vuoi indicizzare.
Ad esempio, potresti sviluppare un nuovo sito Web in un ambiente di gestione temporanea che vuoi essere sicuro sia nascosto agli utenti fino al lancio.
Oppure potresti avere pagine di accesso al sito Web che non desideri vengano visualizzate nelle SERP.
In tal caso, potresti utilizzare robots.txt per bloccare queste pagine dai crawler dei motori di ricerca.
Controlla il budget di scansione dei motori di ricerca
Se hai difficoltà a indicizzare tutte le tue pagine nei motori di ricerca, potresti avere un problema con il crawl budget.
In poche parole, i motori di ricerca stanno consumando il tempo assegnato per eseguire la scansione dei tuoi contenuti sulle pagine deadweight del tuo sito web.

Bloccando gli URL di bassa utilità con robots.txt, i robot dei motori di ricerca possono spendere più del loro budget di scansione per le pagine che contano di più.
Impedisce l'indicizzazione delle risorse
È consigliabile utilizzare la meta direttiva "no-index" per impedire l'indicizzazione di singole pagine.
Il problema è che le meta direttive non funzionano bene per le risorse multimediali, come PDF e documenti Word.
Ecco dove robots.txt è utile.
Puoi aggiungere una semplice riga di testo al tuo file robots.txt e ai motori di ricerca viene impedito di accedere a questi file multimediali.
(Ti mostrerò esattamente come farlo più avanti in questo post)
Come (esattamente) funziona un Robots.txt?
Come ho già condiviso, un file robots.txt funge da manuale di istruzioni per i robot dei motori di ricerca. Indica ai robot di ricerca dove (e dove no) dovrebbero eseguire la scansione.
Questo è il motivo per cui un crawler di ricerca cercherà un file robots.txt non appena arriva a un sito web.
Se trova il robots.txt, il crawler lo leggerà prima di continuare con la scansione del sito.
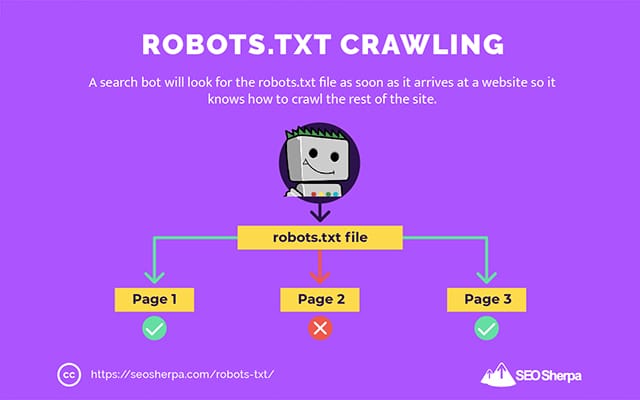
Se il web crawler non trova un robots.txt o il file non contiene direttive che impediscono l'attività dei robot di ricerca, il crawler continuerà a eseguire lo spider dell'intero sito come al solito.
Affinché un file robots.txt sia trovabile e leggibile dai robot di ricerca, un file robots.txt è formattato in un modo molto particolare.
Innanzitutto, è un file di testo senza codice di markup HTML (da cui l'estensione .txt).
In secondo luogo, viene posizionato nella cartella principale del sito Web, ad esempio https://seosherpa.com/robots.txt.
Terzo, utilizza una sintassi standard comune a tutti i file robots.txt, in questo modo:
Sitemap: [URL location of sitemap] User-agent: [bot identifier] [directive 1] [directive 2] [directive ...] User-agent: [another bot identifier] [directive 1] [directive 2] [directive ...]Questa sintassi può sembrare scoraggiante a prima vista, ma in realtà è abbastanza semplice.
In breve, definisci il bot (user-agent) a cui si applicano le istruzioni e quindi stabilisci le regole (direttive) che il bot dovrebbe seguire.
Esaminiamo queste due componenti in modo più dettagliato.
User-Agenti
Uno user-agent è il nome utilizzato per definire specifici web crawler e altri programmi attivi su Internet.
Esistono letteralmente centinaia di programmi utente, inclusi agenti per tipi di dispositivi e browser.
La maggior parte sono irrilevanti nel contesto di un file robots.txt e SEO. D'altra parte, questi dovresti sapere:
- Google: Googlebot
- Google Immagini: Googlebot-immagine
- Google Video: Googlebot-Video
- Google News: Googlebot-Notizie
- Bing: Bingbot
- Immagini e video Bing: MSNBot-Media
- Yahoo: Slurp
- Yandex: YandexBot
- Baidu : Baiduspider
- DuckDuckGo: DuckDuckBot
Indicando lo user agent, puoi impostare regole diverse per diversi motori di ricerca.

Ad esempio, se desideri che una determinata pagina venga visualizzata nei risultati di ricerca di Google ma non nelle ricerche Baidu, puoi includere due serie di comandi nel file robots.txt: una serie preceduta da "User-agent: Bingbot" e una serie preceduta di "User-agent: Baiduspider".
Puoi anche usare il carattere jolly asterisco (*) se vuoi che le tue direttive si applichino a tutti i programmi utente.
Ad esempio, supponiamo che tu voglia impedire a tutti i robot dei motori di ricerca di eseguire la scansione del tuo sito tranne DuckDuckGo. Ecco come lo faresti:
User-agent: * Disallow: / User-agent: DuckDuckBot Allow: /Nota a margine: se ci sono comandi contraddittori nel file robots.txt, il bot seguirà il comando più granulare.
Ecco perché nell'esempio precedente, DuckDuckBot sa eseguire la scansione del sito Web, anche se una precedente direttiva (applicabile a tutti i bot) diceva di non eseguire la scansione. In breve, un bot seguirà le istruzioni che più accuratamente si applicano a loro.
Direttive
Le direttive sono il codice di condotta che vuoi che lo user-agent segua. In altre parole, le direttive definiscono come il bot di ricerca dovrebbe eseguire la scansione del tuo sito web.
Ecco le direttive attualmente supportate da GoogleBot, insieme al loro utilizzo all'interno di un file robots.txt:
Non consentire
Utilizza questa direttiva per impedire ai robot di ricerca di eseguire la scansione di determinati file e pagine su un percorso URL specifico.

Ad esempio, se desideri impedire a GoogleBot di accedere alla tua wiki e a tutte le sue pagine, il tuo robots.txt dovrebbe contenere questa direttiva:
User-agent: GoogleBot Disallow: /wikiPuoi utilizzare la direttiva disallow per bloccare la scansione di un URL preciso, tutti i file e le pagine all'interno di una determinata directory e persino l'intero sito web.
Permettere
La direttiva allow è utile se desideri consentire ai motori di ricerca di eseguire la scansione di una specifica sottodirectory o pagina, in una sezione del tuo sito altrimenti non consentita.

Supponiamo che tu voglia impedire a tutti i motori di ricerca di eseguire la scansione dei post sul tuo blog tranne uno; quindi useresti la direttiva allow in questo modo:
User-agent: * Disallow: /blog Allow: /blog/allowable-postPoiché i robot di ricerca seguono sempre le istruzioni più dettagliate fornite in un file robots.txt, sanno di eseguire la scansione di /blog/allowable-post, ma non eseguiranno la scansione di altri post o file in quella directory come;
- /blog/post-uno/
- /blog/secondo post/
- /blog/nome-file.pdf
Sia Google che Bing supportano questa direttiva. Ma altri motori di ricerca no.
Mappa del sito
La direttiva Sitemap viene utilizzata per specificare la posizione delle tue Sitemap XML nei motori di ricerca.
Se non conosci le Sitemap, vengono utilizzate per elencare le pagine di cui desideri eseguire la scansione e indicizzarle nei motori di ricerca.
Includendo la direttiva sulla mappa del sito in robots.txt, aiuti i motori di ricerca a trovare la tua mappa del sito e, a loro volta, a scansionare e indicizzare le pagine più importanti del tuo sito web.
Detto questo, se hai già inviato la tua mappa del sito XML tramite Search Console, l'aggiunta delle tue mappe del sito in robots.txt è alquanto ridondante per Google. Tuttavia, è consigliabile utilizzare la direttiva sulla mappa del sito poiché indica ai motori di ricerca come Ask, Bing e Yahoo dove è possibile trovare le tue mappe del sito.
Ecco un esempio di file robots.txt che utilizza la direttiva Sitemap:
Sitemap: https://www.website.com/sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/Nota il posizionamento della direttiva Sitemap nel file robots.txt. È meglio posizionato nella parte superiore del tuo robots.txt. Può essere posizionato anche in basso.
Se hai più sitemap, dovresti includerle tutte nel tuo file robots.txt. Ecco come potrebbe apparire il file robots.txt se avessimo mappe del sito XML separate per pagine e post:
Sitemap: http://website.com/post-sitemap.xml Sitemap: http://website.com/page-sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/In ogni caso, devi menzionare ogni mappa del sito XML solo una volta poiché tutti i programmi utente supportati seguiranno la direttiva.
Nota che, a differenza di altre direttive robots.txt, che elencano i percorsi, la direttiva Sitemap deve indicare l'URL assoluto della tua Sitemap XML, inclusi il protocollo, il nome di dominio e l'estensione del dominio di primo livello.
Commenti
Il commento "direttiva" è utile per gli esseri umani ma non viene utilizzato dai robot di ricerca.

Puoi aggiungere commenti per ricordarti perché esistono determinate direttive o impedire a coloro che hanno accesso al tuo robots.txt di eliminare direttive importanti. In breve, i commenti vengono utilizzati per aggiungere note al file robots.txt.
Per aggiungere un commento, digita." #" seguito dal testo del commento.
# Don't allow access to the /wp-admin/ directory for all robots. User-agent: * Disallow: /wp-admin/Puoi aggiungere un commento all'inizio di una riga (come mostrato sopra) o dopo una direttiva sulla stessa riga (come mostrato di seguito):
User-agent: * #Applies to all robots Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.Ovunque tu scelga di scrivere il tuo commento, tutto ciò che segue l'hash verrà ignorato.
Seguendo finora?
Grande! Ora abbiamo trattato le principali direttive di cui avrai bisogno per il tuo file robots.txt: queste sono anche le uniche direttive supportate da Google.
Ma per quanto riguarda gli altri motori di ricerca? Nel caso di Bing, Yahoo e Yandex, c'è un'altra direttiva che puoi usare:
Ritardo scansione
La direttiva Crawl-delay è una direttiva non ufficiale utilizzata per impedire il sovraccarico dei server con troppe richieste di scansione.
In altre parole, lo usi per limitare la frequenza con cui un motore di ricerca può eseguire la scansione del tuo sito.

Intendiamoci, se i motori di ricerca possono sovraccaricare il tuo server eseguendo frequentemente la scansione del tuo sito Web, l'aggiunta della direttiva Crawl-delay al tuo file robots.txt risolverà il problema solo temporaneamente.
Il caso potrebbe essere che il tuo sito Web sia in esecuzione su un hosting scadente o un ambiente di hosting configurato in modo errato, ed è qualcosa che dovresti risolvere rapidamente.
La direttiva crawl delay funziona definendo il tempo in secondi tra i quali un bot di ricerca può eseguire la scansione del tuo sito web.
Ad esempio, se imposti il ritardo di scansione su 5, i robot di ricerca suddivideranno la giornata in finestre di cinque secondi, scansionando solo una pagina (o nessuna) in ciascuna finestra, per un massimo di circa 17.280 URL durante il giorno.
Detto questo, fai attenzione quando imposti questa direttiva, specialmente se hai un sito Web di grandi dimensioni. Solo 17.280 URL scansionati al giorno non sono molto utili se il tuo sito ha milioni di pagine.
Il modo in cui ciascun motore di ricerca gestisce la direttiva crawl-delay è diverso. Analizziamolo di seguito:
Crawl-delay e Bing, Yahoo e Yandex
Bing, Yahoo e Yandex supportano tutti la direttiva crawl-delay in robots.txt.
Ciò significa che puoi impostare una direttiva di crawl-delay per gli user-agent BingBot, Slurp e YandexBot e il motore di ricerca ridurrà la scansione di conseguenza.
Nota che ogni motore di ricerca interpreta il crawl-delay in un modo leggermente diverso , quindi assicurati di controllare la loro documentazione:
- Bing e Yahoo
- Yandex
Detto questo, il formato della direttiva crawl-delay per ciascuno di questi motori è lo stesso. Devi inserirlo subito dopo una direttiva disallow OR allow. Ecco un esempio:
User-agent: BingBot Allow: /widgets/ Crawl-delay: 5Crawl-delay e Google
Il crawler di Google non supporta la direttiva crawl-delay, quindi non ha senso impostare un crawl-delay per GoogleBot in robots.txt.
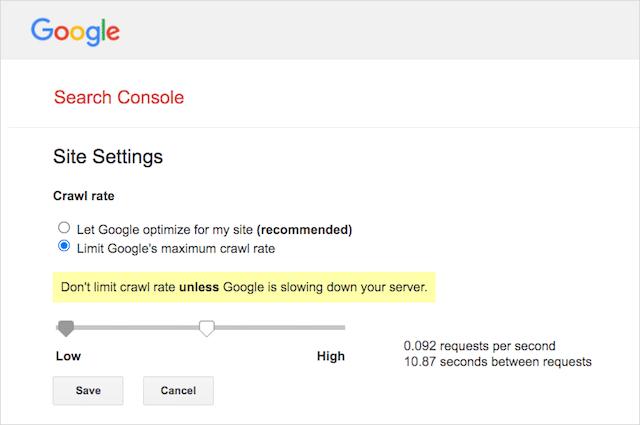
Tuttavia, Google supporta la definizione di una velocità di scansione in Google Search Console. Ecco come farlo:
- Vai alla pagina delle impostazioni di Google Search Console.
- Scegli la proprietà per la quale desideri definire la velocità di scansione
- Fai clic su "Limita la velocità di scansione massima di Google".
- Regola il dispositivo di scorrimento sulla frequenza di scansione preferita. Per impostazione predefinita, la velocità di scansione ha l'impostazione "Consenti a Google di ottimizzare per il mio sito (consigliato)".
Crawl-delay e Baidu
Come Google, Baidu non supporta la direttiva sul ritardo di scansione. Tuttavia, è possibile registrare un account Baidu Webmaster Tools in cui puoi controllare la frequenza di scansione, in modo simile a Google Search Console.
La linea di fondo? Robots.txt dice agli spider dei motori di ricerca di non eseguire la scansione di pagine specifiche del tuo sito web.
Robots.txt vs meta robot vs x-robot
Ci sono un sacco di istruzioni per i "robot" là fuori. Quali sono le differenze o sono le stesse?
Mi permetto di offrire una breve spiegazione:
Prima di tutto, robots.txt è un vero e proprio file di testo, mentre meta e x-robots sono tag all'interno del codice di una pagina web.
In secondo luogo, robots.txt offre ai robot suggerimenti su come eseguire la scansione delle pagine di un sito web. D'altra parte, le meta direttive dei robot forniscono istruzioni molto precise sulla scansione e sull'indicizzazione del contenuto di una pagina.
Al di là di quello che sono, i tre svolgono tutte funzioni diverse.
Robots.txt determina il comportamento di scansione a livello di sito o directory, mentre i meta e x-robot possono dettare il comportamento di indicizzazione a livello di singola pagina (o elemento della pagina).

In generale:
Se vuoi impedire che una pagina venga indicizzata, dovresti utilizzare il tag meta robots "no-index". Disattivare una pagina in robots.txt non garantisce che non venga mostrata nei motori di ricerca (le direttive robots.txt sono suggerimenti, dopotutto). Inoltre, un robot dei motori di ricerca potrebbe comunque trovare quell'URL e indicizzarlo se è collegato da un altro sito web.

Al contrario, se vuoi impedire l'indicizzazione di un file multimediale, robots.txt è la strada da percorrere. Non puoi aggiungere meta tag robots a file come jpeg o PDF.
Come trovare il tuo Robots.txt
Se hai già un file robots.txt sul tuo sito web, potrai accedervi su yourdomain.com/robots.txt.
Vai all'URL nel tuo browser.
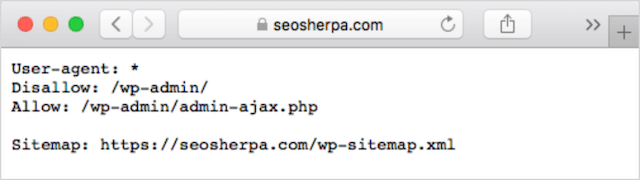
Se vedi una pagina di testo come quella sopra, allora hai un file robots.txt.
Come creare un file Robots.txt
Se non hai già un file robots.txt, crearne uno è semplice.
Innanzitutto, apri Blocco note, Microsoft Word o qualsiasi editor di testo e salva il file come "robot".
Assicurati di utilizzare il minuscolo e scegli .txt come estensione del tipo di file:

In secondo luogo, aggiungi le tue direttive. Ad esempio, se desideri impedire a tutti i robot di ricerca di eseguire la scansione della tua directory /login/, devi digitare questo:
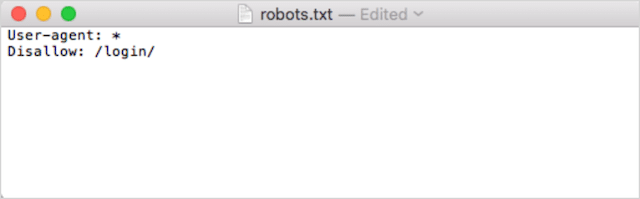
Continua ad aggiungere direttive finché non sei soddisfatto del tuo file robots.txt.
In alternativa, puoi generare il tuo robots.txt con uno strumento come questo di Ryte.

Uno dei vantaggi dell'utilizzo di uno strumento è che riduce al minimo l'errore umano.
Solo un piccolo errore nella sintassi del tuo robots.txt potrebbe finire in un disastro SEO.
Detto questo, lo svantaggio dell'utilizzo di un generatore robots.txt è che l'opportunità di personalizzazione è minima.
Ecco perché ti consiglio di imparare a scrivere tu stesso un file robot.txt. Puoi quindi creare un robots.txt esattamente secondo le tue esigenze.
Dove mettere il tuo file Robots.txt
Aggiungi il tuo file robots.txt nella directory di primo livello del sottodominio a cui si applica.
Ad esempio, per controllare il comportamento di scansione su tuodominio.com , il file robots.txt dovrebbe essere accessibile nel percorso URL tuodominio.com/robots.txt .
D'altra parte, se desideri controllare la scansione su un sottodominio come shop.yourdomain.com , il file robots.txt dovrebbe essere accessibile dal percorso URL shop.yourdomain.com/robots.txt .
Le regole d'oro sono:
- Assegna a ogni sottodominio del tuo sito web il proprio file robots.txt.
- Assegna un nome ai tuoi file robots.txt tutto in minuscolo.
- Posiziona il file nella directory principale del sottodominio a cui fa riferimento.
Se non è possibile trovare il file robots.txt nella directory principale, i motori di ricerca presumeranno che non ci siano direttive e eseguiranno la scansione del tuo sito Web nella sua interezza.
Best practice per il file Robots.txt
Quindi, trattiamo le regole dei file robots.txt. Utilizza queste best practice per evitare le insidie comuni di robots.txt:
Utilizzare una nuova riga per ogni direttiva
Ogni direttiva nel tuo robots.txt deve trovarsi su una nuova riga.
In caso contrario, i motori di ricerca si confonderanno su cosa scansionare (e indicizzare).
Questo, ad esempio, è configurato in modo errato :
User-agent: * Disallow: /folder/ Disallow: /another-folder/Questo, d'altra parte, è un file robots.txt impostato correttamente :
User-agent: * Disallow: /folder/ Disallow: /another-folder/La specificità "quasi" vince sempre
Quando si tratta di Google e Bing, la direttiva più granulare vince.
Ad esempio, questa direttiva Consenti prevale sulla direttiva Disallow perché la lunghezza dei suoi caratteri è maggiore.
User-agent: * Disallow: /about/ Allow: /about/company/Google e Bing sanno eseguire la scansione di /about/company/ ma non di altre pagine nella directory /about/.
Tuttavia, nel caso di altri motori di ricerca, è vero il contrario.
Per impostazione predefinita, per tutti i principali motori di ricerca diversi da Google e Bing, vince sempre la prima direttiva corrispondente .
Nell'esempio sopra, i motori di ricerca seguiranno la direttiva Disallow e ignoreranno la direttiva Allow, il che significa che la pagina /informazioni/azienda non verrà sottoposta a scansione.
Tienilo a mente quando crei regole per tutti i motori di ricerca.
Solo un gruppo di direttive per user-agent
Se il tuo robots.txt contenesse più gruppi di direttive per user agent, boh-oh-boy, potrebbe creare confusione?
Non necessariamente per i robot, perché uniranno tutte le regole delle varie dichiarazioni in un unico gruppo e le seguiranno tutte, ma per te.
Per evitare il potenziale errore umano, dichiarare l'agente utente una volta e quindi elencare tutte le direttive che si applicano a tale agente utente di seguito.

Mantenendo le cose pulite e semplici, è meno probabile che tu commetta un errore.
Utilizzare i caratteri jolly (*) per semplificare le istruzioni
Hai notato i caratteri jolly (*) nell'esempio sopra?
Giusto; puoi usare i caratteri jolly (*) per applicare regole a tutti gli user-agent E per far corrispondere i pattern URL quando dichiari le direttive.
Ad esempio, se desideri impedire ai robot di ricerca di accedere agli URL delle categorie di prodotti parametrizzati sul tuo sito Web, puoi elencare ciascuna categoria in questo modo:
User-agent: * Disallow: /products/watches? Disallow: /products/handbags? Disallow: /products/shoes?Oppure puoi usare un carattere jolly che applichi la regola a tutte le categorie. Ecco come sarebbe:
User-agent: * Disallow: /products/*?Questo esempio impedisce ai motori di ricerca di eseguire la scansione di tutti gli URL all'interno della sottocartella /product/ che contengono un punto interrogativo. In altre parole, qualsiasi URL di categoria di prodotto parametrizzato.
Google, Bing, Yahoo supportano l'uso di caratteri jolly all'interno delle direttive robots.txt e Ask.
Usa "$" per specificare la fine di un URL
Per indicare la fine di un URL, utilizza il simbolo del dollaro ( $ ) dopo il percorso robots.txt.
Supponiamo che tu voglia impedire ai robot di ricerca di accedere a tutti i file .doc sul tuo sito web; quindi useresti questa direttiva:
User-agent: * Disallow: /*.doc$Ciò impedirebbe ai motori di ricerca di accedere a qualsiasi URL che termina con .doc.
Ciò significa che non eseguirebbero la scansione di /media/file.doc, ma eseguirebbero la scansione di /media/file.doc?id=72491 perché quell'URL non termina con ".doc".
Ogni sottodominio ottiene il proprio robots.txt
Le direttive Robots.txt si applicano solo al (sotto)dominio su cui è ospitato il file robots.txt.
Ciò significa che se il tuo sito ha più sottodomini come:
- dominio.com
- biglietti.dominio.com
- eventi.dominio.com
Ogni sottodominio richiederà il proprio file robots.txt.
Il robots.txt dovrebbe sempre essere aggiunto nella directory principale di ogni sottodominio. Ecco come sarebbero i percorsi usando l'esempio sopra:
- dominio.com/robots.txt
- tickets.domain.com/robots.txt
- events.domain.com/robots.txt
Non utilizzare noindex nel tuo robots.txt
In poche parole, Google non supporta la direttiva no-index in robots.txt.
Sebbene Google lo abbia seguito in passato, a partire da luglio 2019 Google ha smesso di supportarlo completamente.
E se stai pensando di utilizzare la direttiva no-index robots.txt per non indicizzare il contenuto su altri motori di ricerca, ripensaci:
La direttiva non ufficiale non ha mai funzionato in Bing.
Di gran lunga, il metodo migliore per non indicizzare i contenuti nei motori di ricerca è applicare un tag meta robots senza indicizzazione alla pagina che desideri escludere.
Mantieni il tuo file robots.txt al di sotto di 512 KB
Google ha attualmente un limite per le dimensioni del file robots.txt di 500 kibibyte (512 kb).
Ciò significa che qualsiasi contenuto dopo 512 KB può essere ignorato.

Detto questo, dato che un carattere consuma solo un byte, il tuo robots.txt dovrebbe essere ENORME per raggiungere quel limite di dimensione del file (512.000 caratteri, per l'esattezza). Mantieni snello il tuo file robots.txt concentrandoti meno sulle pagine escluse individualmente e più su schemi più ampi che i caratteri jolly possono controllare.
Non è chiaro se altri motori di ricerca abbiano la dimensione massima consentita per i file robots.txt.
Esempi di Robots.txt
Di seguito sono riportati alcuni esempi di file robots.txt.
Includono combinazioni delle direttive che la nostra agenzia SEO utilizza maggiormente nei file robots.txt per i clienti. Tieni a mente, però; questi sono solo a scopo di ispirazione. Dovrai sempre personalizzare il file robots.txt per soddisfare le tue esigenze.
Consenti a tutti i robot di accedere a tutto
Questo file robots.txt non fornisce regole di disabilitazione per tutti i motori di ricerca:
User-agent: * Disallow:In altre parole, consente ai robot di ricerca di eseguire la scansione di tutto. Ha lo stesso scopo di un file robots.txt vuoto o di nessun robots.txt.
Impedisci a tutti i robot di accedere a tutto
Il file robots.txt di esempio dice a tutti i motori di ricerca di non accedere a nulla dopo la barra finale. In altre parole, l'intero dominio:
User-agent: * Disallow: /In breve, questo file robots.txt blocca tutti i robot dei motori di ricerca e potrebbe impedire la visualizzazione del tuo sito nelle pagine dei risultati di ricerca.
Impedisci a tutti i robot di eseguire la scansione di un file
In questo esempio, impediamo a tutti i robot di ricerca di eseguire la scansione di un determinato file.
User-agent: * Disallow: /directory/this-is-a-file.pdfImpedisci a tutti i robot di eseguire la scansione di un tipo di file (doc, pdf, jpg)
Poiché la non indicizzazione, un file come 'doc' o 'pdf' non può essere eseguito utilizzando un tag meta robot “no-index”; è possibile utilizzare la seguente direttiva per impedire l'indicizzazione di un particolare tipo di file.
User-agent: * Disallow: /*.doc$ Disallow: /*.pdf$ Disallow: /*.jpg$Ciò funzionerà per deindicizzare tutti i file di quel tipo, purché nessun singolo file sia collegato da altre parti del Web.
Impedisci a Google di eseguire la scansione di più directory
Potresti voler bloccare la scansione di più directory per un particolare bot o per tutti i bot. In questo esempio, stiamo impedendo a Googlebot di eseguire la scansione di due sottodirectory.
User-agent: Googlebot Disallow: /admin/ Disallow: /private/Nota, non c'è limite al numero di directory che puoi usare bock. Elenca semplicemente ciascuno sotto l'agente utente a cui si applica la direttiva.
Impedisci a Google di eseguire la scansione di tutti gli URL parametrizzati
Questa direttiva è particolarmente utile per i siti Web che utilizzano la navigazione a faccette, in cui è possibile creare molti URL parametrizzati.
User-agent: Googlebot Disallow: /*?Questa direttiva impedisce che il tuo budget di scansione venga consumato su URL dinamici e massimizza la scansione di pagine importanti. Lo uso regolarmente, in particolare sui siti di e-commerce con funzionalità di ricerca.
Impedisci a tutti i bot di eseguire la scansione di una sottodirectory ma consentendo la scansione di una pagina all'interno
A volte potresti voler impedire ai crawler di accedere a una sezione completa del tuo sito, ma lasciare una pagina accessibile. In tal caso, utilizzare la seguente combinazione di direttive "allow" e "disallow":
User-agent: * Disallow: /category/ Allow: /category/widget/Dice ai motori di ricerca di non eseguire la scansione dell'intera directory, esclusa una pagina o un file particolare.
Robots.txt per WordPress
Questa è la configurazione di base che consiglio per un file robots.txt di WordPress. Blocca la scansione delle pagine e dei tag di amministrazione e degli URL degli autori che possono creare inutili cruft su un sito Web WordPress.
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /wp-admin/ Disallow: /readme.html Disallow: /refer/ Disallow: /tag/ Disallow: /author/ Disallow: /404-error/ Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xmlQuesto file robots.txt funzionerà bene per la maggior parte dei siti Web WordPress, ma ovviamente dovresti sempre adattarlo alle tue esigenze.
Come controllare il tuo file Robots.txt per errori
Ai miei tempi, ho visto più errori che incidono sul ranking nei file robots.txt rispetto a qualsiasi altro aspetto della SEO tecnica. Con così tante direttive potenzialmente in conflitto, i problemi possono verificarsi e si verificano.
Quindi, quando si tratta di file robots.txt, vale la pena tenere d'occhio i problemi.
Per fortuna, il rapporto "Copertura" all'interno di Google Search Console ti offre un modo per controllare e monitorare i problemi di robots.txt.
Puoi anche utilizzare l'elegante strumento di test Robots.txt di Google per verificare la presenza di errori all'interno del tuo file robots live o testare un nuovo file robots.txt prima di implementarlo.
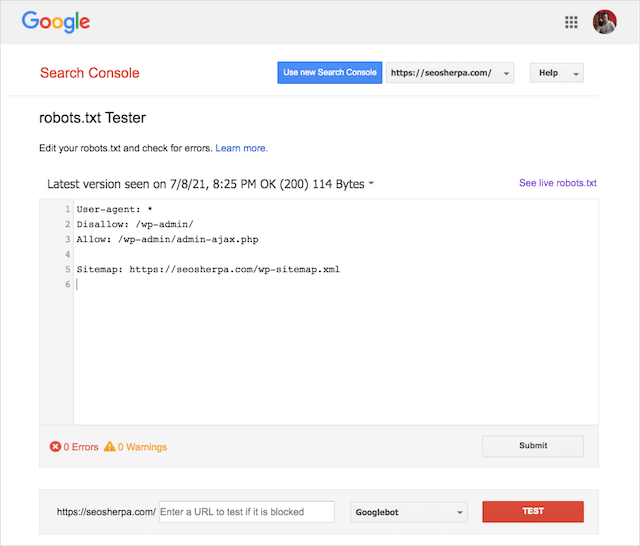
Concluderemo trattando i problemi più comuni, cosa significano e come affrontarli.
URL inviato bloccato da robots.txt
Questo errore significa che almeno uno degli URL nelle tue Sitemap inviate è bloccato da robots.txt.

Una mappa del sito impostata correttamente dovrebbe includere solo gli URL che desideri indicizzare nei motori di ricerca . Pertanto, non dovrebbe contenere pagine non indicizzate, canonizzate o reindirizzate.
Se hai seguito queste best practice, nessuna pagina inviata nella tua mappa del sito dovrebbe essere bloccata da robots.txt.
Se vedi "URL inviato bloccato da robots.txt" nel rapporto sulla copertura, dovresti esaminare quali pagine sono interessate, quindi passare al file robots.txt per rimuovere il blocco per quella pagina.
Puoi utilizzare il tester robots.txt di Google per vedere quale direttiva sta bloccando il contenuto.
Bloccato da Robots.txt
Questo "errore" significa che hai pagine bloccate dal tuo robots.txt che non sono attualmente nell'indice di Google.

Se questo contenuto ha utilità e deve essere indicizzato, rimuovi il blocco di scansione in robots.txt.
Un breve avvertimento:
"Bloccato da robots.txt" non è necessariamente un errore. In effetti, potrebbe essere proprio il risultato che desideri.
Ad esempio, potresti aver bloccato determinati file in robots.txt con l'intenzione di escluderli dall'indice di Google. D'altra parte, se hai bloccato la scansione di alcune pagine con l'intenzione di non indicizzarle, prendi in considerazione la rimozione del blocco di scansione e utilizza invece il meta tag di un robot.
Questo è l'unico modo per garantire l'esclusione dei contenuti dall'indice di Google.
Indicizzato, sebbene bloccato da Robots.txt
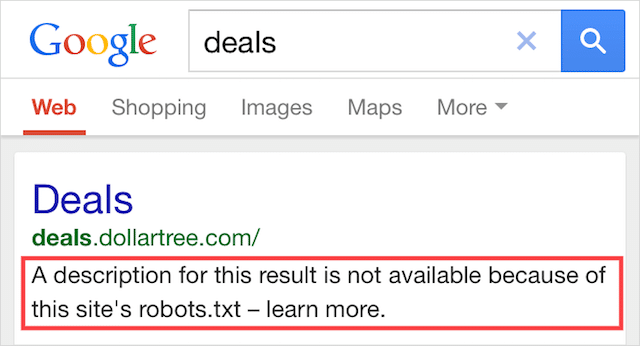
Questo errore significa che alcuni dei contenuti bloccati da robots.txt sono ancora indicizzati in Google.
Succede quando il contenuto è ancora rilevabile da Googlebot perché è collegato da altre parti del Web. In breve, Googlebot atterra su quel contenuto che esegue la scansione e quindi lo indicizza prima di visitare il file robots.txt del tuo sito web, dove vede la direttiva non consentita.
A quel punto, è troppo tardi. E viene indicizzato:
Fammi perforare questo a casa:
Se stai cercando di escludere contenuti dai risultati di ricerca di Google, robots.txt non è la soluzione corretta.
Raccomando di rimuovere il blocco di scansione e di utilizzare un tag no-index di meta robots per impedire invece l'indicizzazione.
Al contrario, se hai bloccato questo contenuto per errore e desideri mantenerlo nell'indice di Google, rimuovi il blocco di scansione in robots.txt e lascialo lì.
Questo può aiutare a migliorare la visibilità dei contenuti nella ricerca di Google.
Pensieri finali
Robots.txt può essere utilizzato per migliorare la scansione e l'indicizzazione dei contenuti del tuo sito Web, il che ti aiuta a diventare più visibile nelle SERP.
Se utilizzato in modo efficace, è il testo più importante del tuo sito web. Ma, se usato con noncuranza, sarà il tallone d'Achille nel codice del tuo sito web.
La buona notizia, con solo una conoscenza di base degli user agent e una manciata di direttive, risultati di ricerca migliori sono alla tua portata.
L'unica domanda è: quali protocolli utilizzerai nel tuo file robots.txt?
Fammi sapere nei commenti qui sotto.