
Robots.txt: Полное руководство по SEO (издание 2021 г.)
Опубликовано: 2021-06-10 Сегодня вы узнаете, как создать один из самых важных файлов для SEO веб-сайта:
Сегодня вы узнаете, как создать один из самых важных файлов для SEO веб-сайта:
(Файл robots.txt).
В частности, я покажу вам, как использовать протоколы исключения роботов, чтобы заблокировать ботов на определенных страницах, увеличить частоту сканирования, оптимизировать бюджет сканирования и, в конечном итоге, получить более высокий рейтинг нужной страницы в поисковой выдаче.
Я покрываю:
- Что такое файл robots.txt
- Почему robots.txt важен
- Как работает robots.txt
- Пользовательские агенты и директивы robots.txt
- Robots.txt против мета-роботов
- Как найти файл robots.txt
- Создание файла robots.txt
- Рекомендации по работе с файлом robots.txt
- Примеры robots.txt
- Как проверить файл robots.txt на наличие ошибок
Плюс многое другое. Давайте погрузимся прямо в.
Что такое файл robots.txt? И зачем он вам нужен
Проще говоря, файл robots.txt представляет собой руководство по работе с веб-роботами.
Он сообщает ботам всех типов, какие разделы сайта они должны (и не должны) сканировать.
Тем не менее, robots.txt используется в основном как «кодекс поведения» для контроля активности роботов поисковых систем (веб-сканеров).

Каждая крупная поисковая система (включая Google, Bing и Yahoo) регулярно проверяет файл robots.txt на наличие инструкций о том, как им следует сканировать веб-сайт. Эти инструкции известны как директивы .
Если нет директив или файла robots.txt, поисковые системы будут сканировать весь веб-сайт, частные страницы и все такое.
Хотя большинство поисковых систем послушны, важно отметить, что соблюдение директив robots.txt не является обязательным. При желании поисковые системы могут игнорировать ваш файл robots.txt.
К счастью, Google не является одной из таких поисковых систем. Google склонен подчиняться инструкциям в файле robots.txt.
Почему файл robots.txt важен?
Наличие файла robots.txt не критично для многих веб-сайтов, особенно для небольших.
Это потому, что Google обычно может найти и проиндексировать все основные страницы сайта.
И они автоматически НЕ будут индексировать дублированный контент или страницы, которые не важны.
Тем не менее, нет веских причин не иметь файл robots.txt, поэтому я рекомендую вам его иметь.
Файл robots.txt дает вам больший контроль над тем, что поисковые системы могут и не могут сканировать на вашем веб-сайте, и это полезно по нескольким причинам:
Позволяет блокировать непубличные страницы от поисковых систем
Иногда на вашем сайте есть страницы, которые вы не хотите индексировать.
Например, вы можете разрабатывать новый веб-сайт в тестовой среде, который вы хотите скрыть от пользователей до запуска.
Или у вас могут быть страницы входа на веб-сайт, которые вы не хотите отображать в поисковой выдаче.
Если бы это было так, вы могли бы использовать robots.txt, чтобы заблокировать эти страницы от сканеров поисковых систем.
Контролирует бюджет сканирования поисковой системы
Если вам трудно проиндексировать все ваши страницы в поисковых системах, возможно, у вас проблема с краулинговым бюджетом.
Проще говоря, поисковые системы тратят время, отведенное на сканирование вашего контента на мертвых страницах вашего веб-сайта.

Блокируя URL-адреса с низкой полезностью с помощью robots.txt, роботы поисковых систем могут тратить больше своего краулингового бюджета на наиболее важные страницы.
Предотвращает индексацию ресурсов
Лучше всего использовать мета-директиву «no-index», чтобы предотвратить индексацию отдельных страниц.
Проблема в том, что мета-директивы плохо работают с мультимедийными ресурсами, такими как PDF-файлы и документы Word.
Вот где robots.txt удобен.
Вы можете добавить простую строку текста в файл robots.txt, и поисковые системы не смогут получить доступ к этим мультимедийным файлам.
(Я покажу вам, как именно это сделать позже в этом посте)
Как (точно) работает файл robots.txt?
Как я уже говорил, файл robots.txt служит инструкцией для роботов поисковых систем. Он сообщает поисковым ботам, где (и где нельзя) им сканировать.
Вот почему поисковый робот будет искать файл robots.txt, как только он попадет на веб-сайт.
Если он найдет файл robots.txt, сканер сначала прочитает его, прежде чем продолжить сканирование сайта.
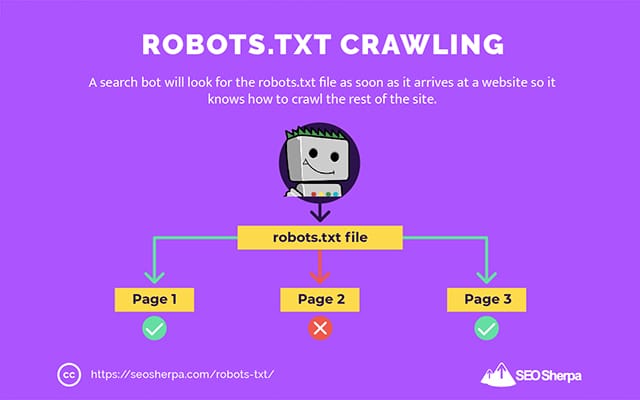
Если поисковый робот не найдет файл robots.txt или файл не содержит директив, запрещающих деятельность поисковых роботов, сканер продолжит сканирование всего сайта в обычном режиме.
Чтобы файл robots.txt был доступен для поиска и чтения поисковыми ботами, файл robots.txt форматируется особым образом.
Во-первых, это текстовый файл без кода разметки HTML (отсюда и расширение .txt).
Во-вторых, он помещается в корневую папку сайта, например, https://seosherpa.com/robots.txt.
В-третьих, он использует стандартный синтаксис, общий для всех файлов robots.txt, например:
Sitemap: [URL location of sitemap] User-agent: [bot identifier] [directive 1] [directive 2] [directive ...] User-agent: [another bot identifier] [directive 1] [directive 2] [directive ...]Этот синтаксис может показаться сложным на первый взгляд, но на самом деле он довольно прост.
Короче говоря, вы определяете бота (агента пользователя), к которому применяются инструкции, а затем устанавливаете правила (директивы), которым должен следовать бот.
Рассмотрим эти два компонента более подробно.
Пользовательские агенты
Пользовательский агент — это имя, используемое для определения определенных поисковых роботов и других программ, активных в Интернете.
Существуют буквально сотни пользовательских агентов, включая агенты для типов устройств и браузеров.
Большинство из них не имеет значения в контексте файла robots.txt и SEO. С другой стороны, это вы должны знать:
- Гугл: Гуглбот
- Изображения Google: Googlebot-изображение
- Видео Google: Googlebot-видео
- Новости Google: Googlebot-Новости
- Бинг: Бингбот
- Изображения и видео Bing: MSNBot-Media
- Yahoo: Хлюпать
- Яндекс: ЯндексБот
- Baidu : Байдуспайдер
- DuckDuckGo: DuckDuckBot
Указав пользовательский агент, вы можете установить разные правила для разных поисковых систем.

Например, если вы хотите, чтобы определенная страница отображалась в результатах поиска Google, но не в результатах поиска Baidu, вы можете включить в файл robots.txt два набора команд: перед одним набором стоит «User-agent: Bingbot», а перед другим — от «Пользовательского агента: Baiduspider».
Вы также можете использовать подстановочный знак звездочки (*), если хотите, чтобы ваши директивы применялись ко всем пользовательским агентам.
Например, допустим, вы хотите запретить всем роботам поисковых систем сканировать ваш сайт, кроме DuckDuckGo. Вот как это сделать:
User-agent: * Disallow: / User-agent: DuckDuckBot Allow: /Примечание: если в файле robots.txt есть противоречивые команды, бот будет следовать более детализированной команде.
Вот почему в приведенном выше примере DuckDuckBot знает, что нужно сканировать веб-сайт, хотя предыдущая директива (применимая ко всем ботам) запрещала сканировать. Короче говоря, бот будет следовать инструкции, которая наиболее точно относится к нему.
Директивы
Директивы — это кодекс поведения, которому должен следовать пользовательский агент. Другими словами, директивы определяют, как поисковый бот должен сканировать ваш сайт.
Вот директивы, которые в настоящее время поддерживает GoogleBot, а также их использование в файле robots.txt:
Запретить
Используйте эту директиву, чтобы запретить поисковым роботам сканировать определенные файлы и страницы по определенному URL-адресу.

Например, если вы хотите запретить роботу GoogleBot доступ к вашей вики и всем ее страницам, файл robots.txt должен содержать следующую директиву:
User-agent: GoogleBot Disallow: /wikiВы можете использовать директиву disallow, чтобы заблокировать сканирование определенного URL-адреса, всех файлов и страниц в определенном каталоге и даже всего вашего веб-сайта.
Разрешать
Директива allow полезна, если вы хотите разрешить поисковым системам сканировать определенный подкаталог или страницу в запрещенном разделе вашего сайта.

Допустим, вы хотите запретить всем поисковым системам сканировать сообщения в вашем блоге, кроме одной; тогда вы должны использовать директиву allow следующим образом:
User-agent: * Disallow: /blog Allow: /blog/allowable-postПоскольку поисковые боты всегда следуют наиболее подробным инструкциям, данным в файле robots.txt, они знают, что нужно сканировать /blog/allowable-post, но они не будут сканировать другие сообщения или файлы в этом каталоге, например;
- /блог/запись один/
- /блог/пост-два/
- /блог/имя-файла.pdf
И Google, и Bing поддерживают эту директиву. Но других поисковых систем нет.
Карта сайта
Директива карты сайта используется для указания местоположения ваших карт сайта в формате XML для поисковых систем.
Если вы новичок в картах сайта, они используются для перечисления страниц, которые вы хотите просканировать и проиндексировать в поисковых системах.
Включив директиву карты сайта в robots.txt, вы поможете поисковым системам найти вашу карту сайта и, в свою очередь, просканировать и проиндексировать наиболее важные страницы вашего веб-сайта.
При этом, если вы уже отправили свою XML-карту сайта через консоль поиска, добавление вашей карты сайта в robots.txt несколько избыточно для Google. Тем не менее, лучше всего использовать директиву карты сайта, поскольку она сообщает поисковым системам, таким как Ask, Bing и Yahoo, где можно найти ваши карты сайта.
Вот пример файла robots.txt с использованием директивы карты сайта:
Sitemap: https://www.website.com/sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/Обратите внимание на размещение директивы карты сайта в файле robots.txt. Лучше всего разместить его в самом верху файла robots.txt. Его также можно разместить внизу.
Если у вас несколько файлов Sitemap, вы должны включить их все в файл robots.txt. Вот как мог бы выглядеть файл robots.txt, если бы у нас были отдельные карты сайта XML для страниц и сообщений:
Sitemap: http://website.com/post-sitemap.xml Sitemap: http://website.com/page-sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/В любом случае вам нужно будет упомянуть каждую XML-карту сайта только один раз, поскольку все поддерживаемые пользовательские агенты будут следовать директиве.
Обратите внимание, что в отличие от других директив robots.txt, в которых перечислены пути, в директиве карты сайта должен быть указан абсолютный URL-адрес вашей XML-карты сайта, включая протокол, имя домена и расширение домена верхнего уровня.
Комментарии
Комментарий «директива» полезен для человека, но не используется поисковыми ботами.

Вы можете добавить комментарии, чтобы напомнить вам, почему существуют определенные директивы, или помешать тем, у кого есть доступ к вашему robots.txt, удалить важные директивы. Короче говоря, комментарии используются для добавления заметок в файл robots.txt.
Чтобы добавить комментарий, введите». #" , за которым следует текст комментария.
# Don't allow access to the /wp-admin/ directory for all robots. User-agent: * Disallow: /wp-admin/Вы можете добавить комментарий в начале строки (как показано выше) или после директивы в той же строке (как показано ниже):
User-agent: * #Applies to all robots Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.Везде, где вы решите написать свой комментарий, все после хэша будет проигнорировано.
До сих пор следишь?
Большой! Теперь мы рассмотрели основные директивы, которые вам понадобятся для файла robots.txt — это также единственные директивы, поддерживаемые Google.
Но как насчет других поисковых систем? В случае с Bing, Yahoo и Яндекс можно использовать еще одну директиву:
Задержка сканирования
Директива Crawl-delay — это неофициальная директива, используемая для предотвращения перегрузки серверов слишком большим количеством запросов на сканирование.
Другими словами, вы используете его, чтобы ограничить частоту, с которой поисковая система может сканировать ваш сайт.

Имейте в виду, что если поисковые системы могут перегружать ваш сервер из-за частого сканирования вашего веб-сайта, добавление директивы Crawl-delay в файл robots.txt только временно устранит проблему.
Дело может быть в том, что ваш сайт работает на дрянном хостинге или в неправильно настроенной среде хостинга, и это то, что вы должны быстро исправить.
Директива задержки сканирования определяет время в секундах, в течение которого поисковый бот может сканировать ваш веб-сайт.
Например, если вы установите задержку сканирования на 5, поисковые роботы будут разбивать день на пятисекундные окна, сканируя только одну страницу (или ни одной) в каждом окне, максимум около 17 280 URL-адресов в течение дня.
При этом будьте осторожны при установке этой директивы, особенно если у вас большой сайт. Всего 17 280 URL-адресов, просканированных в день, не очень полезны, если на вашем сайте миллионы страниц.
То, как каждая поисковая система обрабатывает директиву задержки сканирования, отличается. Давайте разберем это ниже:
Crawl-delay и Bing, Yahoo и Яндекс
Bing, Yahoo и Яндекс поддерживают директиву задержки сканирования в файле robots.txt.
Это означает, что вы можете установить директиву задержки сканирования для пользовательских агентов BingBot, Slurp и YandexBot, и поисковая система соответствующим образом ограничит сканирование.
Обратите внимание, что каждая поисковая система интерпретирует задержку сканирования немного по-разному , поэтому обязательно ознакомьтесь с их документацией:
- Бинг и Яху
- Яндекс
При этом формат директивы crawl-delay для каждого из этих движков одинаков. Вы должны поместить его сразу после директивы «запретить» или «разрешить». Вот пример:
User-agent: BingBot Allow: /widgets/ Crawl-delay: 5Задержка сканирования и Google
Сканер Google не поддерживает директиву Crawl-delay, поэтому нет смысла устанавливать задержку сканирования для GoogleBot в файле robots.txt.
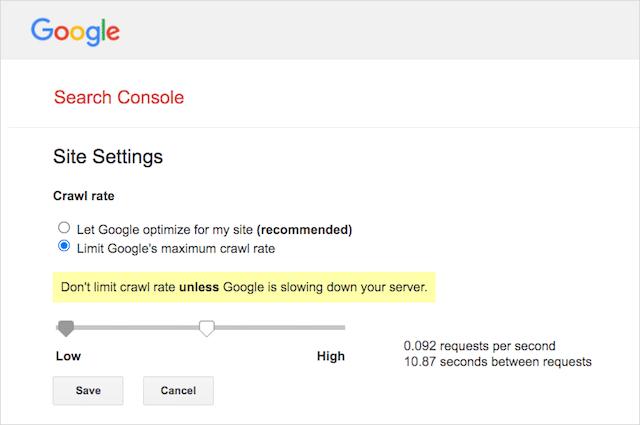
Однако Google поддерживает определение скорости сканирования в Google Search Console. Вот как это сделать:
- Перейдите на страницу настроек Google Search Console.
- Выберите свойство, для которого вы хотите определить скорость сканирования.
- Нажмите «Ограничить максимальную скорость сканирования Google».
- Установите ползунок на предпочитаемую скорость сканирования. По умолчанию скорость сканирования имеет настройку «Разрешить Google оптимизировать мой сайт (рекомендуется)».
Задержка сканирования и Baidu
Как и Google, Baidu не поддерживает директиву о задержке сканирования. Однако можно зарегистрировать учетную запись инструментов Baidu для веб-мастеров, в которой вы можете контролировать частоту сканирования, аналогично Google Search Console.
Нижняя линия? Robots.txt указывает поисковым роботам не сканировать определенные страницы вашего сайта.
Robots.txt против мета-роботов против x-роботов
Существует чертовски много инструкций для «роботов». В чем отличия или это одно и то же?
Позвольте мне предложить краткое объяснение:
Во-первых, robots.txt — это настоящий текстовый файл, тогда как meta и x-robots — это теги в коде веб-страницы.
Во-вторых, robots.txt дает ботам советы о том, как сканировать страницы веб-сайта. С другой стороны, метадирективы роботов содержат очень четкие инструкции по сканированию и индексации содержимого страницы.
Помимо того, что они есть, все три выполняют разные функции.
Robots.txt определяет поведение сканирования сайта или всего каталога, тогда как meta и x-robots могут определять поведение индексации на уровне отдельной страницы (или элемента страницы).

В целом:
Если вы хотите, чтобы страница не индексировалась, вам следует использовать метатег robots «no-index». Запрет страницы в robots.txt не гарантирует, что она не будет отображаться в поисковых системах (в конце концов, директивы robots.txt являются рекомендациями). Кроме того, робот поисковой системы все еще может найти этот URL-адрес и проиндексировать его, если на него есть ссылка с другого веб-сайта.
Наоборот, если вы хотите, чтобы медиафайл не индексировался, robots.txt — это то, что вам нужно. Вы не можете добавлять метатеги robots в такие файлы, как jpeg или PDF.

Как найти файл robots.txt
Если у вас уже есть файл robots.txt на вашем веб-сайте, вы сможете получить к нему доступ по адресу yourdomain.com/robots.txt.
Перейдите по URL-адресу в браузере.
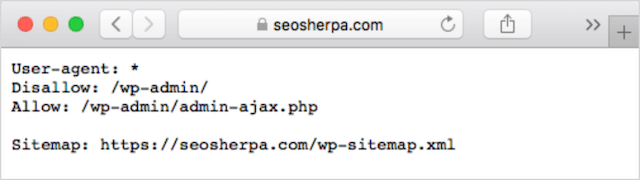
Если вы видите текстовую страницу, подобную приведенной выше, значит, у вас есть файл robots.txt.
Как создать файл robots.txt
Если у вас еще нет файла robots.txt, создать его несложно.
Сначала откройте Блокнот, Microsoft Word или любой текстовый редактор и сохраните файл как «роботы».
Обязательно используйте строчные буквы и выберите .txt в качестве расширения типа файла:

Во-вторых, добавьте свои директивы. Например, если вы хотите запретить всем поисковым ботам сканировать ваш каталог /login/, введите следующее:
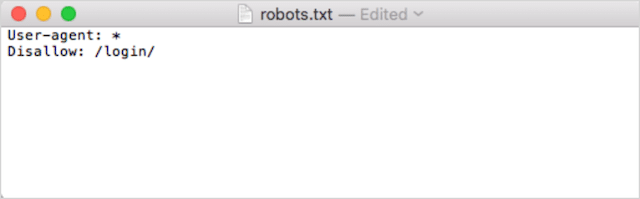
Продолжайте добавлять директивы, пока не будете удовлетворены файлом robots.txt.
Кроме того, вы можете сгенерировать файл robots.txt с помощью такого инструмента, как этот, от Ryte.

Одним из преимуществ использования инструмента является то, что он сводит к минимуму человеческий фактор.
Всего одна небольшая ошибка в синтаксисе файла robots.txt может привести к катастрофе в поисковой оптимизации.
При этом недостатком использования генератора robots.txt является минимальная возможность настройки.
Вот почему я рекомендую вам научиться писать файл robot.txt самостоятельно. Затем вы можете создать файл robots.txt в точном соответствии с вашими требованиями.
Куда поместить файл robots.txt
Добавьте файл robots.txt в каталог верхнего уровня поддомена, к которому он относится.
Например, чтобы управлять сканированием вашего домена.com , файл robots.txt должен быть доступен по URL-адресу yourdomain.com/robots.txt .
С другой стороны, если вы хотите контролировать сканирование субдоменов, таких как shop.yourdomain.com , файл robots.txt должен быть доступен по URL-адресу shop.yourdomain.com/robots.txt .
Золотые правила таковы:
- Дайте каждому поддомену на вашем сайте собственный файл robots.txt.
- Назовите ваши файлы robots.txt строчными буквами.
- Поместите файл в корневой каталог поддомена, на который он ссылается.
Если файл robots.txt не может быть найден в корневом каталоге, поисковые системы решат, что директив нет, и просканируют ваш сайт целиком.
Рекомендации по использованию файла robots.txt
Далее рассмотрим правила файлов robots.txt. Используйте эти рекомендации, чтобы избежать распространенных ошибок, связанных с файлом robots.txt:
Используйте новую строку для каждой директивы
Каждая директива в файле robots.txt должна находиться на новой строке.
В противном случае поисковые системы запутаются в том, что сканировать (и индексировать).
Это, например, неправильно настроено:
User-agent: * Disallow: /folder/ Disallow: /another-folder/Это, с другой стороны, правильно настроенный файл robots.txt:
User-agent: * Disallow: /folder/ Disallow: /another-folder/Конкретика «почти» всегда побеждает
Когда дело доходит до Google и Bing, побеждает более детальная директива.
Например, эта директива Allow превосходит директиву Disallow, поскольку ее длина символа больше.
User-agent: * Disallow: /about/ Allow: /about/company/Google и Bing знают, что нужно сканировать /about/company/, но не другие страницы в каталоге /about/.
Однако в случае с другими поисковыми системами все наоборот.
По умолчанию для всех основных поисковых систем, кроме Google и Bing, всегда побеждает первая совпадающая директива .
В приведенном выше примере поисковые системы будут следовать директиве Disallow и игнорировать директиву Allow, что означает, что страница /about/company не будет сканироваться.
Имейте это в виду, когда будете создавать правила для всех поисковых систем.
Всего одна группа директив на каждый пользовательский агент
Если ваш robots.txt содержит несколько групп директив для каждого пользовательского агента, боже мой, может ли это запутаться?
Не обязательно для роботов, потому что они будут объединять все правила из разных объявлений в одну группу и всем им следовать, а для вас.
Чтобы избежать возможности человеческой ошибки, укажите пользовательский агент один раз, а затем перечислите ниже все директивы, применимые к этому пользовательскому агенту.

Делая вещи аккуратными и простыми, вы с меньшей вероятностью совершите ошибку.
Используйте подстановочные знаки (*), чтобы упростить инструкции
Вы заметили подстановочные знаки (*) в приведенном выше примере?
Вот так; вы можете использовать подстановочные знаки (*) для применения правил ко всем пользовательским агентам И для соответствия шаблонам URL при объявлении директив.
Например, если вы хотите запретить поисковым роботам доступ к URL-адресам параметризованных категорий продуктов на вашем веб-сайте, вы можете перечислить каждую категорию следующим образом:
User-agent: * Disallow: /products/watches? Disallow: /products/handbags? Disallow: /products/shoes?Или вы можете использовать подстановочный знак, который применит правило ко всем категориям. Вот как это будет выглядеть:
User-agent: * Disallow: /products/*?В этом примере поисковые системы не могут сканировать все URL-адреса в подпапке /product/, содержащие вопросительный знак. Другими словами, любые параметризованные URL-адреса категорий продуктов.
Google, Bing, Yahoo поддерживают использование подстановочных знаков в директивах robots.txt и Ask.
Используйте «$», чтобы указать конец URL-адреса
Чтобы указать конец URL-адреса, используйте знак доллара ( $ ) после пути robots.txt.
Допустим, вы хотите запретить поисковым ботам доступ ко всем файлам .doc на вашем сайте; то вы должны использовать эту директиву:
User-agent: * Disallow: /*.doc$Это предотвратит доступ поисковых систем к любым URL-адресам, заканчивающимся на .doc.
Это означает, что они не будут сканировать /media/file.doc, но будут сканировать /media/file.doc?id=72491, поскольку этот URL-адрес не заканчивается на «.doc».
Каждый субдомен получает свой файл robots.txt.
Директивы robots.txt применяются только к (суб)домену, на котором размещен файл robots.txt.
Это означает, что если ваш сайт имеет несколько поддоменов, например:
- домен.com
- Tickets.domain.com
- events.domain.com
Для каждого поддомена потребуется свой файл robots.txt.
Файл robots.txt всегда следует добавлять в корневой каталог каждого субдомена. Вот как будут выглядеть пути в приведенном выше примере:
- домен.com/robots.txt
- ticket.domain.com/robots.txt
- events.domain.com/robots.txt
Не используйте noindex в файле robots.txt.
Проще говоря, Google не поддерживает директиву no-index в файле robots.txt.
Хотя Google и следовал ему в прошлом, с июля 2019 года Google полностью прекратил его поддержку.
И если вы думаете об использовании директивы no-index robots.txt для неиндексируемого контента в других поисковых системах, подумайте еще раз:
Неофициальная директива no-index никогда не работала в Bing.
На сегодняшний день лучший способ не индексировать контент в поисковых системах — применить метатег роботов без индекса к странице, которую вы хотите исключить.
Размер файла robots.txt не должен превышать 512 КБ.
В настоящее время у Google есть ограничение на размер файла robots.txt, равное 500 кибибайтам (512 килобайтам).
Это означает, что любой контент после 512 КБ может быть проигнорирован.

Тем не менее, учитывая, что один символ занимает всего один байт, ваш файл robots.txt должен быть ОГРОМНЫМ, чтобы достичь этого предела размера файла (точнее, 512 000 символов). Сохраняйте файл robots.txt компактным, уделяя меньше внимания отдельно исключенным страницам и больше — более широким шаблонам, которыми могут управлять подстановочные знаки.
Неясно, есть ли у других поисковых систем максимально допустимый размер файлов robots.txt.
Примеры robots.txt
Ниже приведены несколько примеров файлов robots.txt.
Они включают в себя комбинации директив, которые наше SEO-агентство чаще всего использует в файлах robots.txt для клиентов. Однако имейте в виду; это только для вдохновения. Вам всегда придется настраивать файл robots.txt в соответствии с вашими требованиями.
Разрешить всем роботам доступ ко всему
В этом файле robots.txt нет правил запрета для всех поисковых систем:
User-agent: * Disallow:Другими словами, это позволяет поисковым роботам сканировать все. Он служит той же цели, что и пустой файл robots.txt или отсутствие файла robots.txt.
Заблокировать всем роботам доступ ко всему
Пример файла robots.txt указывает всем поисковым системам не обращаться к чему-либо после завершающей косой черты. Другими словами, весь домен:
User-agent: * Disallow: /Короче говоря, этот файл robots.txt блокирует всех роботов поисковых систем и может помешать показу вашего сайта на страницах результатов поиска.
Запретить всем роботам сканировать один файл
В этом примере мы блокируем сканирование определенного файла всеми поисковыми ботами.
User-agent: * Disallow: /directory/this-is-a-file.pdfЗапретить всем роботам сканирование файлов одного типа (doc, pdf, jpg)
Из-за отсутствия индексации файл, такой как «doc» или «pdf», не может быть создан с использованием мета-тега робота «no-index»; вы можете использовать следующую директиву, чтобы запретить индексацию файлов определенного типа.
User-agent: * Disallow: /*.doc$ Disallow: /*.pdf$ Disallow: /*.jpg$Это будет работать для деиндексации всех файлов этого типа, если ни один отдельный файл не связан с каким-либо другим местом в Интернете.
Запретить Google сканирование нескольких каталогов
Вы можете заблокировать сканирование нескольких каталогов для определенного бота или всех ботов. В этом примере мы запрещаем роботу Googlebot сканировать два подкаталога.
User-agent: Googlebot Disallow: /admin/ Disallow: /private/Обратите внимание, что количество каталогов, которые вы можете использовать, не ограничено. Просто перечислите каждый из них под пользовательским агентом, к которому применяется директива.
Запретить Google сканирование всех параметризованных URL-адресов
Эта директива особенно полезна для веб-сайтов, использующих фасетную навигацию, где может быть создано множество параметризованных URL-адресов.
User-agent: Googlebot Disallow: /*?Эта директива не позволяет расходовать ваш краулинговый бюджет на динамические URL-адреса и максимизирует сканирование важных страниц. Я использую это регулярно, особенно на веб-сайтах электронной коммерции с функцией поиска.
Запретить всем ботам сканировать один подкаталог, но разрешить сканирование одной страницы внутри
Иногда вы можете захотеть запретить поисковым роботам доступ ко всему разделу вашего сайта, но оставить доступной одну страницу. Если вы это сделаете, используйте следующую комбинацию директив «разрешить» и «запретить»:
User-agent: * Disallow: /category/ Allow: /category/widget/Он говорит поисковым системам не сканировать весь каталог, за исключением одной конкретной страницы или файла.
Robots.txt для WordPress
Это базовая конфигурация, которую я рекомендую для файла robots.txt WordPress. Он блокирует сканирование административных страниц, тегов и URL-адресов авторов, что может создать ненужный мусор на веб-сайте WordPress.
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /wp-admin/ Disallow: /readme.html Disallow: /refer/ Disallow: /tag/ Disallow: /author/ Disallow: /404-error/ Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xmlЭтот файл robots.txt будет хорошо работать для большинства веб-сайтов WordPress, но, конечно, вы всегда должны настраивать его в соответствии со своими требованиями.
Как проверить файл robots.txt на наличие ошибок
В свое время я видел больше ошибок, влияющих на рейтинг, в файлах robots.txt, чем, возможно, в любом другом аспекте технического SEO. С таким количеством потенциально конфликтующих директив могут возникать проблемы.
Итак, когда дело доходит до файлов robots.txt, стоит следить за проблемами.
К счастью, отчет «Покрытие» в Google Search Console предоставляет вам возможность проверять и отслеживать проблемы с robots.txt.
Вы также можете использовать отличный инструмент тестирования Robots.txt от Google, чтобы проверить наличие ошибок в файле активных роботов или протестировать новый файл robots.txt перед его развертыванием.
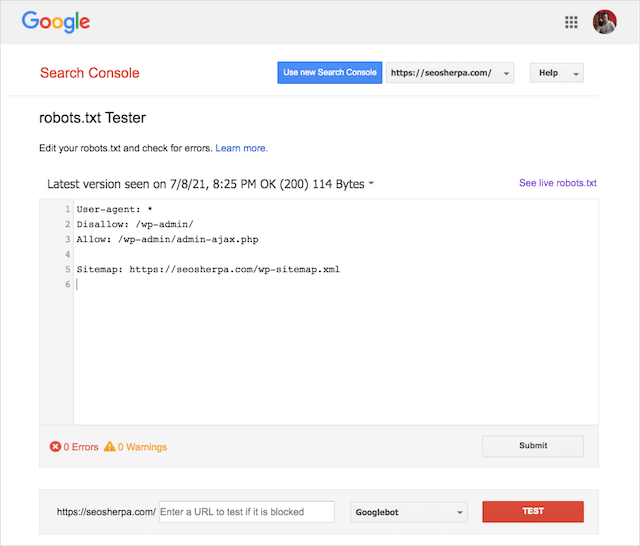
Мы закончим рассмотрением наиболее распространенных проблем, их значения и способов их решения.
Отправленный URL заблокирован файлом robots.txt
Эта ошибка означает, что по крайней мере один из URL-адресов в отправленных вами картах сайта заблокирован файлом robots.txt.

Правильно настроенная карта сайта должна включать только те URL-адреса, которые вы хотите индексировать в поисковых системах . Таким образом, он не должен содержать непроиндексированных, канонизированных или перенаправленных страниц.
Если вы следовали этим рекомендациям, никакие страницы, представленные в вашей карте сайта , не должны быть заблокированы файлом robots.txt.
Если вы видите «Отправленный URL-адрес заблокирован robots.txt» в отчете о покрытии, вам следует выяснить, какие страницы затронуты, а затем изменить файл robots.txt, чтобы снять блокировку для этой страницы.
Вы можете использовать тестер Google robots.txt, чтобы увидеть, какая директива блокирует контент.
Заблокировано файлом robots.txt
Эта «ошибка» означает, что у вас есть страницы, заблокированные вашим файлом robots.txt, которых в настоящее время нет в индексе Google.

Если этот контент полезен и должен быть проиндексирован, удалите блокировку сканирования в robots.txt.
Короткое предупреждение:
«Заблокировано robots.txt» не обязательно является ошибкой. На самом деле, это может быть именно тот результат, который вы хотите.
Например, вы могли заблокировать определенные файлы в robots.txt, чтобы исключить их из индекса Google. С другой стороны, если вы заблокировали сканирование определенных страниц с намерением не индексировать их, рассмотрите возможность снятия блокировки сканирования и вместо этого используйте метатег робота.
Это единственный способ гарантировать исключение контента из индекса Google.
Проиндексировано, но заблокировано robots.txt
Эта ошибка означает, что часть контента, заблокированного robots.txt, все еще индексируется в Google.
Это происходит, когда контент все еще может быть обнаружен роботом Googlebot, потому что на него есть ссылки из других источников в Интернете. Короче говоря, робот Googlebot сканирует этот контент, а затем индексирует его, прежде чем посетить файл robots.txt вашего веб-сайта, где он увидит запрещенную директиву.
К тому времени уже слишком поздно. И он индексируется:
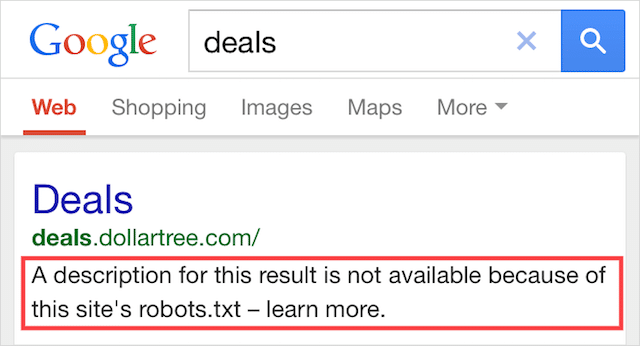
Позвольте мне просверлить это домой:
Если вы пытаетесь исключить контент из результатов поиска Google, файл robots.txt не является правильным решением.
Я рекомендую удалить блокировку сканирования и вместо этого использовать мета-тег robots no-index, чтобы предотвратить индексацию.
Напротив, если вы случайно заблокировали этот контент и хотите оставить его в индексе Google, удалите блокировку сканирования в robots.txt и оставьте все как есть.
Это может помочь улучшить видимость контента в поиске Google.
Последние мысли
Robots.txt можно использовать для улучшения сканирования и индексации содержимого вашего веб-сайта, что поможет вам стать более заметным в поисковой выдаче.
При эффективном использовании это самый важный текст на вашем сайте. Но при небрежном использовании он станет ахиллесовой пятой кода вашего сайта.
Хорошая новость: имея базовое понимание пользовательских агентов и несколько директив, лучшие результаты поиска находятся в пределах вашей досягаемости.
Вопрос только в том, какие протоколы вы будете использовать в файле robots.txt?
Позвольте мне знать в комментариях ниже.