
Robots.txt: Panduan Utama untuk SEO (Edisi 2021)
Diterbitkan: 2021-06-10 Hari ini Anda akan mempelajari cara membuat salah satu file paling penting untuk SEO situs web:
Hari ini Anda akan mempelajari cara membuat salah satu file paling penting untuk SEO situs web:
(Berkas robots.txt).
Secara khusus, saya akan menunjukkan cara menggunakan protokol pengecualian robot untuk memblokir bot dari halaman tertentu, meningkatkan frekuensi perayapan, mengoptimalkan anggaran perayapan, dan akhirnya mendapatkan lebih banyak peringkat halaman yang tepat di SERP.
saya meliputi:
- Apa itu file robots.txt?
- Mengapa robots.txt itu penting
- Cara kerja robots.txt
- Agen-pengguna dan arahan robots.txt
- Robots.txt Vs robot meta
- Cara menemukan robots.txt Anda
- Membuat file robots.txt Anda
- Praktik terbaik file robots.txt
- Contoh robots.txt
- Cara mengaudit robots.txt Anda untuk menemukan kesalahan
Plus, lebih banyak lagi. Mari kita selami.
Apa itu file Robots.txt? Dan, Mengapa Anda Membutuhkannya?
Dalam istilah sederhana, file robots.txt adalah manual instruksional untuk robot web.
Ini memberi tahu bot dari semua jenis, bagian mana dari situs yang harus (dan tidak boleh) mereka jelajahi.
Konon, robots.txt digunakan terutama sebagai "kode etik" untuk mengontrol aktivitas robot mesin pencari (perayap web AKA).

Robots.txt diperiksa secara teratur oleh setiap mesin pencari utama (termasuk Google, Bing, dan Yahoo) untuk instruksi tentang bagaimana mereka harus merayapi situs web. Instruksi ini dikenal sebagai arahan .
Jika tidak ada arahan – atau tidak ada file robots.txt – mesin pencari akan merayapi seluruh situs web, halaman pribadi, dan semuanya.
Meskipun sebagian besar mesin telusur patuh, penting untuk dicatat bahwa mematuhi arahan robots.txt adalah opsional. Jika diinginkan, mesin pencari dapat memilih untuk mengabaikan file robots.txt Anda.
Untungnya, Google bukan salah satu dari mesin pencari itu. Google cenderung mematuhi instruksi dalam file robots.txt.
Mengapa Robots.txt Penting?
Memiliki file robots.txt tidak penting untuk banyak situs web, terutama yang kecil.
Itu karena Google biasanya dapat menemukan dan mengindeks semua halaman penting di sebuah situs.
Dan, mereka secara otomatis TIDAK akan mengindeks duplikat konten atau halaman yang tidak penting.
Tapi tetap saja, tidak ada alasan bagus untuk tidak memiliki file robots.txt – jadi saya sarankan Anda memilikinya.
Robots.txt memberi Anda kendali lebih besar atas apa yang dapat dan tidak dapat dirayapi oleh mesin telusur di situs web Anda, dan itu berguna karena beberapa alasan:
Mengizinkan Halaman Non-Publik Diblokir dari Mesin Pencari
Terkadang Anda memiliki halaman di situs yang tidak ingin diindeks.
Misalnya, Anda mungkin mengembangkan situs web baru di lingkungan staging yang ingin Anda pastikan disembunyikan dari pengguna hingga diluncurkan.
Atau Anda mungkin memiliki halaman login situs web yang tidak ingin Anda tampilkan di SERP.
Jika demikian, Anda dapat menggunakan robots.txt untuk memblokir halaman ini dari perayap mesin telusur.
Mengontrol Anggaran Perayapan Mesin Pencari
Jika Anda mengalami kesulitan mendapatkan semua halaman Anda diindeks di mesin pencari, Anda mungkin memiliki masalah anggaran perayapan.
Sederhananya, mesin pencari menggunakan waktu yang dialokasikan untuk merayapi konten Anda di halaman bobot mati situs web Anda.

Dengan memblokir URL utilitas rendah dengan robots.txt, robot mesin telusur dapat menghabiskan lebih banyak anggaran perayapan mereka pada halaman yang paling penting.
Mencegah Pengindeksan Sumber Daya
Ini adalah praktik terbaik untuk menggunakan arahan meta "tanpa indeks" untuk menghentikan halaman individual agar tidak diindeks.
Masalahnya adalah, arahan meta tidak berfungsi dengan baik untuk sumber daya multimedia, seperti PDF dan dokumen Word.
Di situlah robots.txt berguna.
Anda dapat menambahkan sebaris teks sederhana ke file robots.txt Anda, dan mesin telusur diblokir untuk mengakses file multimedia ini.
(Saya akan menunjukkan kepada Anda bagaimana melakukannya nanti di posting ini)
Bagaimana (Tepatnya) Apakah Robots.txt Bekerja?
Seperti yang sudah saya bagikan, file robots.txt bertindak sebagai manual instruksional untuk robot mesin pencari. Ini memberi tahu bot pencarian di mana (dan di mana tidak) mereka harus merangkak.
Inilah sebabnya mengapa perayap pencarian akan mencari file robots.txt segera setelah tiba di situs web.
Jika menemukan robots.txt, crawler akan membacanya terlebih dahulu sebelum melanjutkan crawl situsnya.
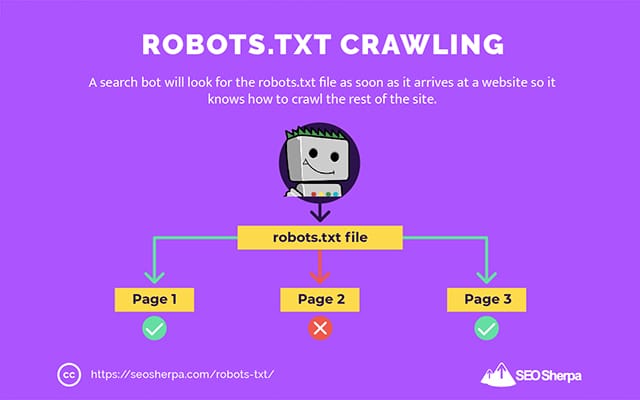
Jika perayap web tidak menemukan robots.txt, atau file tidak berisi arahan yang melarang aktivitas bot pencarian, perayap akan terus menjelajahi seluruh situs seperti biasa.
Agar file robots.txt dapat ditemukan dan dibaca oleh bot pencarian, robots.txt diformat dengan cara yang sangat khusus.
Pertama, ini adalah file teks tanpa kode markup HTML (maka ekstensi .txt).
Kedua, ditempatkan di folder root situs web, misalnya https://seosherpa.com/robots.txt.
Ketiga, ia menggunakan sintaks standar yang umum untuk semua file robots.txt, seperti:
Sitemap: [URL location of sitemap] User-agent: [bot identifier] [directive 1] [directive 2] [directive ...] User-agent: [another bot identifier] [directive 1] [directive 2] [directive ...]Sintaks ini mungkin terlihat menakutkan pada pandangan pertama, tetapi sebenarnya cukup sederhana.
Singkatnya, Anda menentukan bot (agen-pengguna) instruksi yang berlaku dan kemudian menyatakan aturan (arahan) yang harus diikuti bot.
Mari kita telusuri kedua komponen ini secara lebih rinci.
Agen-Pengguna
Agen pengguna adalah nama yang digunakan untuk mendefinisikan perayap web tertentu – dan program lain yang aktif di internet.
Ada ratusan agen pengguna, termasuk agen untuk jenis perangkat dan browser.
Sebagian besar tidak relevan dalam konteks file robots.txt dan SEO. Di sisi lain, ini yang harus Anda ketahui:
- Google: Googlebot
- Gambar Google: Googlebot-Gambar
- Google Video: Googlebot-Video
- Google Berita: Googlebot-Berita
- Bing: Bingbot
- Bing Images & Videos: MSNBot-Media
- Yahoo: Slurp
- Yandex: YandexBot
- Baidu : Baiduspider
- DuckDuckGo: DuckDuckBot
Dengan menyatakan agen pengguna, Anda dapat menetapkan aturan yang berbeda untuk mesin telusur yang berbeda.

Misalnya, jika Anda ingin halaman tertentu muncul di hasil pencarian Google tetapi bukan pencarian Baidu, Anda dapat memasukkan dua set perintah dalam file robots.txt Anda: satu set didahului oleh “User-agent: Bingbot” dan satu set didahului oleh "Agen pengguna: Baiduspider."
Anda juga dapat menggunakan wildcard bintang (*) jika Anda ingin arahan Anda berlaku untuk semua agen pengguna.
Misalnya, Anda ingin memblokir semua robot mesin telusur agar tidak merayapi situs Anda kecuali DuckDuckGo. Inilah cara Anda melakukannya:
User-agent: * Disallow: / User-agent: DuckDuckBot Allow: /Sidenote: Jika ada perintah yang kontradiktif di file robots.txt, bot akan mengikuti perintah yang lebih terperinci.
Itu sebabnya dalam contoh di atas, DuckDuckBot tahu untuk merayapi situs web, meskipun arahan sebelumnya (berlaku untuk semua bot) mengatakan jangan merangkak. Singkatnya, bot akan mengikuti instruksi yang paling akurat berlaku untuk mereka.
arahan
Arahan adalah kode etik yang Anda ingin diikuti oleh agen pengguna. Dengan kata lain, arahan menentukan bagaimana bot pencarian harus merayapi situs web Anda.
Berikut adalah arahan yang saat ini didukung oleh GoogleBot, beserta penggunaannya dalam file robots.txt:
Melarang
Gunakan arahan ini untuk melarang bot pencarian merayapi file dan halaman tertentu di jalur URL tertentu.

Misalnya, jika Anda ingin memblokir GoogleBot mengakses wiki Anda dan semua halamannya, robots.txt Anda harus berisi arahan ini:
User-agent: GoogleBot Disallow: /wikiAnda dapat menggunakan disallow directive untuk memblokir perayapan URL yang tepat, semua file dan halaman dalam direktori tertentu, dan bahkan seluruh situs web Anda.
Mengizinkan
Perintah izinkan berguna jika Anda ingin mengizinkan mesin telusur merayapi subdirektori atau halaman tertentu – di bagian situs Anda yang tidak diizinkan.

Katakanlah Anda ingin mencegah semua mesin pencari merayapi posting di blog Anda kecuali satu; maka Anda akan menggunakan direktif allow seperti ini:
User-agent: * Disallow: /blog Allow: /blog/allowable-postKarena bot pencarian selalu mengikuti instruksi paling terperinci yang diberikan dalam file robots.txt, mereka tahu untuk merayapi /blog/allowable-post, tetapi mereka tidak akan merayapi posting atau file lain di direktori itu seperti;
- /blog/posting-satu/
- /blog/posting-dua/
- /blog/nama-file.pdf
Baik Google dan Bing mendukung arahan ini. Tapi mesin pencari lainnya tidak.
peta situs
Arahan peta situs digunakan untuk menentukan lokasi peta situs XML Anda ke mesin telusur.
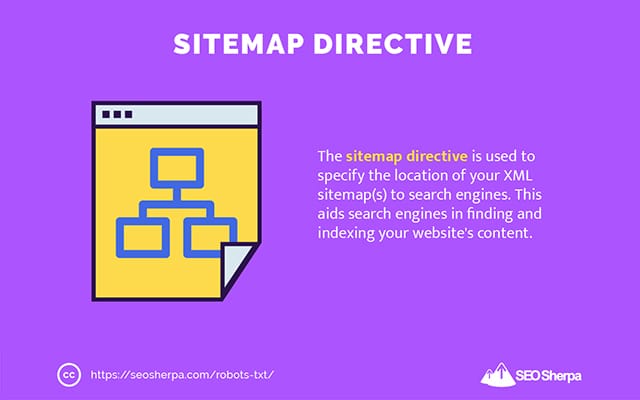
Jika Anda baru mengenal peta situs, peta situs digunakan untuk mencantumkan halaman yang ingin Anda jelajahi dan indeks di mesin telusur.
Dengan menyertakan arahan peta situs di robots.txt, Anda membantu mesin telusur menemukan peta situs Anda dan, pada gilirannya, merayapi dan mengindeks halaman terpenting situs web Anda.
Dengan demikian, jika Anda telah mengirimkan peta situs XML Anda melalui Search Console, menambahkan peta situs Anda di robots.txt agak berlebihan untuk Google. Namun, ini adalah praktik terbaik untuk menggunakan arahan peta situs karena memberi tahu mesin pencari seperti Ask, Bing, dan Yahoo di mana peta situs Anda dapat ditemukan.
Berikut ini contoh file robots.txt menggunakan arahan peta situs:
Sitemap: https://www.website.com/sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/Perhatikan penempatan arahan peta situs di file robots.txt. Ini paling baik ditempatkan di bagian paling atas robots.txt Anda. Itu juga dapat ditempatkan di bagian bawah.
Jika Anda memiliki beberapa peta situs, Anda harus memasukkan semuanya ke dalam file robots.txt Anda. Berikut tampilan file robots.txt jika kami memiliki peta situs XML terpisah untuk halaman dan postingan:
Sitemap: http://website.com/post-sitemap.xml Sitemap: http://website.com/page-sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/Either way, Anda hanya perlu menyebutkan setiap peta situs XML sekali karena semua agen pengguna yang didukung akan mengikuti arahan.
Perhatikan bahwa, tidak seperti arahan robots.txt lainnya, yang mencantumkan jalur, arahan peta situs harus menyatakan URL absolut peta situs XML Anda, termasuk protokol, nama domain, dan ekstensi domain tingkat atas.
Komentar
Komentar "direktif" berguna untuk manusia tetapi tidak digunakan oleh bot pencarian.

Anda dapat menambahkan komentar untuk mengingatkan Anda mengapa ada arahan tertentu atau menghentikan mereka yang memiliki akses ke robots.txt Anda agar tidak menghapus arahan penting. Singkatnya, komentar digunakan untuk menambahkan catatan ke file robots.txt Anda.
Untuk menambahkan komentar, ketik.” #" diikuti oleh teks komentar.
# Don't allow access to the /wp-admin/ directory for all robots. User-agent: * Disallow: /wp-admin/Anda dapat menambahkan komentar di awal baris (seperti yang ditunjukkan di atas) atau setelah arahan pada baris yang sama (seperti yang ditunjukkan di bawah):
User-agent: * #Applies to all robots Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.Di mana pun Anda memilih untuk menulis komentar, semuanya setelah hash akan diabaikan.
Mengikuti sejauh ini?
Besar! Kami sekarang telah membahas arahan utama yang Anda perlukan untuk file robots.txt Anda – ini juga merupakan satu-satunya arahan yang didukung oleh Google.
Tapi bagaimana dengan mesin pencari lainnya? Dalam kasus Bing, Yahoo, dan Yandex, ada satu lagi arahan yang dapat Anda gunakan:
Penundaan Perayapan
Arahan Perayapan-penundaan adalah direktif tidak resmi yang digunakan untuk mencegah server kelebihan beban dengan terlalu banyak permintaan perayapan.
Dengan kata lain, Anda menggunakannya untuk membatasi frekuensi mesin pencari dapat merayapi situs Anda.

Ingat, jika mesin telusur dapat membebani server Anda dengan sering merayapi situs web Anda, menambahkan perintah Penundaan Perayapan ke file robots.txt hanya akan memperbaiki masalah untuk sementara.
Kasusnya mungkin, situs web Anda berjalan pada hosting yang jelek atau lingkungan hosting yang salah konfigurasi, dan itu adalah sesuatu yang harus Anda perbaiki dengan cepat.
Arahan penundaan perayapan bekerja dengan menentukan waktu dalam hitungan detik di mana Bot Pencarian dapat merayapi situs web Anda.
Misalnya, jika Anda menyetel penundaan perayapan ke 5, bot pencarian akan membagi hari menjadi jendela lima detik, merayapi hanya satu halaman (atau tidak sama sekali) di setiap jendela, untuk maksimum sekitar 17.280 URL di siang hari.
Karena itu, berhati-hatilah saat mengatur arahan ini, terutama jika Anda memiliki situs web yang besar. Hanya 17.280 URL yang dirayapi per hari tidak terlalu membantu jika situs Anda memiliki jutaan halaman.
Cara setiap mesin telusur menangani direktif crawl-delay berbeda. Mari kita uraikan di bawah ini:
Penundaan perayapan dan Bing, Yahoo, dan Yandex
Bing, Yahoo, dan Yandex semuanya mendukung direktif crawl-delay di robots.txt.
Ini berarti Anda dapat menetapkan arahan penundaan perayapan untuk agen pengguna BingBot, Slurp, dan YandexBot, dan mesin pencari akan membatasi perayapannya.
Perhatikan bahwa setiap mesin telusur menafsirkan penundaan perayapan dengan cara yang sedikit berbeda , jadi pastikan untuk memeriksa dokumentasinya:
- Bing dan Yahoo
- Yandex
Konon, format arahan crawl-delay untuk masing-masing mesin ini sama. Anda harus meletakkannya tepat setelah disallow OR allow directive. Berikut ini contohnya:
User-agent: BingBot Allow: /widgets/ Crawl-delay: 5Penundaan perayapan dan Google
Perayap Google tidak mendukung perintah penundaan perayapan, jadi tidak ada gunanya menyetel penundaan perayapan untuk GoogleBot di robots.txt.
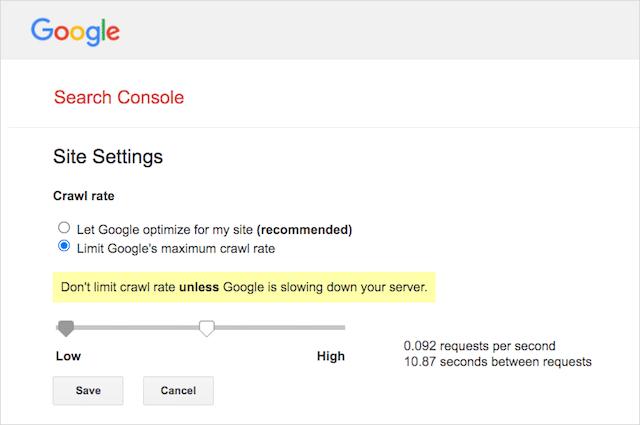
Namun, Google mendukung penentuan tingkat perayapan di Google Search Console. Berikut cara melakukannya:
- Buka halaman pengaturan Google Search Console.
- Pilih properti yang ingin Anda tentukan tingkat perayapannya
- Klik “Batasi kecepatan perayapan maksimum Google”.
- Sesuaikan penggeser ke kecepatan perayapan pilihan Anda. Secara default, kecepatan perayapan memiliki setelan "Biarkan Google mengoptimalkan situs saya (disarankan)".
Penundaan perayapan dan Baidu
Seperti Google, Baidu tidak mendukung arahan penundaan perayapan. Namun, dimungkinkan untuk mendaftarkan akun Alat Webmaster Baidu di mana Anda dapat mengontrol frekuensi perayapan, mirip dengan Google Search Console.
Garis bawah? Robots.txt memberi tahu spider mesin pencari untuk tidak merayapi halaman tertentu di situs web Anda.
Robots.txt vs robot meta vs robot x
Ada banyak sekali instruksi "robot" di luar sana. Apa perbedaannya, atau apakah mereka sama?
Izinkan saya memberikan penjelasan singkat:
Pertama, robots.txt adalah file teks yang sebenarnya, sedangkan meta dan x-robot adalah tag dalam kode halaman web.
Kedua, robots.txt memberikan saran bot tentang cara merayapi halaman situs web. Di sisi lain, arahan meta robot memberikan instruksi yang sangat tegas tentang perayapan dan pengindeksan konten halaman.
Di luar apa adanya, ketiganya memiliki fungsi yang berbeda.
Robots.txt mendikte perilaku perayapan seluruh situs atau direktori, sedangkan meta dan robot x dapat mendikte perilaku pengindeksan pada tingkat halaman individual (atau elemen halaman).

Secara umum:
Jika Anda ingin menghentikan halaman agar tidak diindeks, Anda harus menggunakan tag robot meta “tanpa indeks”. Melarang halaman di robots.txt tidak menjamin itu tidak akan ditampilkan di mesin pencari (bagaimanapun juga, arahan robots.txt adalah saran). Plus, robot mesin pencari masih dapat menemukan URL itu dan mengindeksnya jika ditautkan dari situs web lain.

Sebaliknya, jika Anda ingin menghentikan pengindeksan file media, robots.txt adalah caranya. Anda tidak dapat menambahkan tag meta robot ke file seperti jpegs atau PDF.
Cara Menemukan Robots.txt Anda
Jika Anda sudah memiliki file robots.txt di situs web Anda, Anda dapat mengaksesnya di domainAnda.com/robots.txt.
Arahkan ke URL di browser Anda.
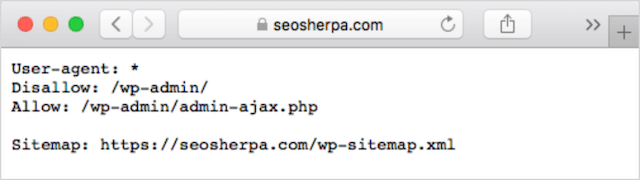
Jika Anda melihat halaman berbasis teks seperti di atas, maka Anda memiliki file robots.txt.
Cara Membuat File Robots.txt
Jika Anda belum memiliki file robots.txt, membuatnya mudah.
Pertama, buka Notepad, Microsoft Word, atau editor teks apa pun dan simpan file sebagai 'robot'.
Pastikan untuk menggunakan huruf kecil, dan pilih .txt sebagai ekstensi jenis file:

Kedua, tambahkan arahan Anda. Misalnya, jika Anda ingin melarang semua bot pencarian merayapi direktori /login/ Anda, ketik ini:
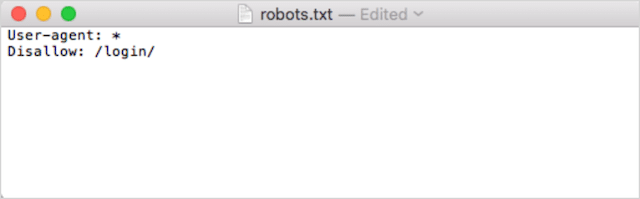
Lanjutkan untuk menambahkan arahan sampai Anda puas dengan file robots.txt Anda.
Atau, Anda dapat membuat robots.txt dengan alat seperti ini dari Ryte.

Salah satu keuntungan menggunakan alat adalah meminimalkan kesalahan manusia.
Hanya satu kesalahan kecil dalam sintaks robots.txt Anda bisa berakhir dengan bencana SEO.
Meskipun demikian, kerugian menggunakan generator robots.txt adalah bahwa peluang untuk penyesuaian sangat minim.
Itu sebabnya saya sarankan Anda belajar menulis file robot.txt sendiri. Anda kemudian dapat membuat robots.txt sesuai dengan kebutuhan Anda.
Di mana Menempatkan File Robots.txt Anda
Tambahkan file robots.txt Anda di direktori tingkat atas dari subdomain tempat file tersebut diterapkan.
Misalnya, untuk mengontrol perilaku perayapan di domainanda.com , file robots.txt harus dapat diakses di jalur URL domainanda.com/robots.txt .
Di sisi lain, jika Anda ingin mengontrol perayapan pada subdomain seperti shop.yourdomain.com , robots.txt harus dapat diakses di jalur URL shop.yourdomain.com/robots.txt .
Aturan emasnya adalah:
- Berikan setiap subdomain di situs web Anda file robots.txt-nya sendiri.
- Beri nama file Anda robots.txt semua dalam huruf kecil.
- Tempatkan file di direktori root dari subdomain yang dirujuknya.
Jika file robots.txt tidak dapat ditemukan di direktori root, mesin pencari akan menganggap tidak ada arahan dan akan merayapi situs web Anda secara keseluruhan.
Praktik Terbaik File Robots.txt
Selanjutnya, mari kita bahas aturan file robots.txt. Gunakan praktik terbaik berikut untuk menghindari perangkap robots.txt umum:
Gunakan baris baru untuk setiap arahan
Setiap arahan di robots.txt Anda harus berada di baris baru.
Jika tidak, mesin pencari akan bingung tentang apa yang harus dirayapi (dan diindeks).
Ini, misalnya, salah dikonfigurasi:
User-agent: * Disallow: /folder/ Disallow: /another-folder/Ini, di sisi lain, adalah file robots.txt yang diatur dengan benar :
User-agent: * Disallow: /folder/ Disallow: /another-folder/Kekhususan "hampir" selalu menang
Ketika datang ke Google dan Bing, arahan yang lebih terperinci menang.
Misalnya, direktif Allow ini menang atas direktif Disallow karena panjang karakternya lebih panjang.
User-agent: * Disallow: /about/ Allow: /about/company/Google dan Bing tahu untuk merayapi /about/company/ tetapi tidak semua halaman lain di direktori /about/.
Namun, dalam kasus mesin pencari lain, yang terjadi adalah kebalikannya.
Secara default, untuk semua mesin telusur utama selain Google dan Bing, arahan pencocokan pertama selalu menang .
Pada contoh di atas, mesin pencari akan mengikuti arahan Disallow dan mengabaikan arahan Allow yang berarti halaman /about/company tidak akan dirayapi.
Ingatlah hal ini saat Anda membuat aturan untuk semua mesin telusur.
Hanya satu grup arahan per agen pengguna
Jika robots.txt Anda berisi beberapa grup arahan per agen pengguna, wah, bisakah itu membingungkan?
Tidak harus untuk robot, karena mereka akan menggabungkan semua aturan dari berbagai deklarasi menjadi satu grup dan mengikuti semuanya, tetapi untuk Anda.
Untuk menghindari potensi kesalahan manusia, nyatakan agen pengguna satu kali dan kemudian daftar semua arahan yang berlaku untuk agen pengguna tersebut di bawah ini.

Dengan menjaga segala sesuatunya tetap rapi dan sederhana, Anda cenderung tidak membuat kesalahan.
Gunakan wildcard (*) untuk menyederhanakan instruksi
Apakah Anda memperhatikan wildcard (*) pada contoh di atas?
Betul sekali; anda dapat menggunakan karakter pengganti (*) untuk menerapkan aturan ke semua agen pengguna DAN untuk mencocokkan pola URL saat mendeklarasikan arahan.
Misalnya, jika Anda ingin mencegah bot pencarian mengakses URL kategori produk berparameter di situs web Anda, Anda dapat membuat daftar setiap kategori seperti:
User-agent: * Disallow: /products/watches? Disallow: /products/handbags? Disallow: /products/shoes?Atau, Anda bisa menggunakan wildcard yang akan menerapkan aturan ke semua kategori. Berikut tampilannya:
User-agent: * Disallow: /products/*?Contoh ini memblokir mesin telusur agar tidak merayapi semua URL dalam subfolder /produk/ yang berisi tanda tanya. Dengan kata lain, URL kategori produk apa pun yang diberi parameter.
Google, Bing, Yahoo mendukung penggunaan wildcard dalam arahan robots.txt dan Ask.
Gunakan "$" untuk menentukan akhir URL
Untuk menunjukkan akhir URL, gunakan tanda dolar ( $ ) setelah jalur robots.txt.
Katakanlah Anda ingin menghentikan bot pencarian yang mengakses semua file .doc di situs web Anda; maka Anda akan menggunakan arahan ini:
User-agent: * Disallow: /*.doc$Ini akan menghentikan mesin telusur mengakses URL apa pun yang diakhiri dengan .doc.
Ini berarti mereka tidak akan merayapi /media/file.doc, tetapi mereka akan merayapi /media/file.doc?id=72491 karena URL itu tidak diakhiri dengan “.doc.”
Setiap subdomain mendapatkan robots.txt sendiri
Perintah robots.txt hanya berlaku untuk domain (sub) tempat file robots.txt dihosting.
Ini berarti jika situs Anda memiliki beberapa subdomain seperti:
- domain.com
- tiket.domain.com
- event.domain.com
Setiap subdomain akan membutuhkan file robots.txt sendiri.
Robots.txt harus selalu ditambahkan di direktori root setiap subdomain. Inilah yang akan terlihat seperti jalur menggunakan contoh di atas:
- domain.com/robots.txt
- ticket.domain.com/robots.txt
- event.domain.com/robots.txt
Jangan gunakan noindex di robots.txt Anda
Sederhananya, Google tidak mendukung arahan tanpa indeks di robots.txt.
Meskipun Google mengikutinya di masa lalu, pada Juli 2019, Google berhenti mendukungnya sepenuhnya.
Dan jika Anda berpikir untuk menggunakan arahan robots.txt tanpa indeks ke konten tanpa indeks di mesin telusur lain, pikirkan lagi:
Arahan no-index tidak resmi tidak pernah berfungsi di Bing.
Sejauh ini, metode terbaik untuk konten tanpa indeks di mesin telusur adalah dengan menerapkan tag robot meta tanpa indeks ke halaman yang ingin Anda kecualikan.
Simpan file robots.txt Anda di bawah 512 KB
Google saat ini memiliki batas ukuran file robots.txt 500 kibibytes (512 kilobytes).
Ini berarti konten apa pun setelah 512 KB dapat diabaikan.

Yang mengatakan, mengingat satu karakter hanya menggunakan satu byte, robots.txt Anda harus BESAR untuk mencapai batas ukuran file itu (tepatnya 512.000 karakter). Jaga agar file robots.txt Anda tetap ramping dengan lebih sedikit fokus pada halaman yang dikecualikan satu per satu dan lebih banyak pada pola yang lebih luas yang dapat dikontrol oleh wild card.
Tidak jelas apakah mesin pencari lain memiliki ukuran file maksimum yang diizinkan untuk file robots.txt.
Contoh Robots.txt
Di bawah ini adalah beberapa contoh file robots.txt.
Mereka menyertakan kombinasi arahan yang paling sering digunakan agen SEO kami dalam file robots.txt untuk klien. Perlu diingat, meskipun; ini hanya untuk tujuan inspirasi. Anda harus selalu menyesuaikan file robots.txt untuk memenuhi kebutuhan Anda.
Izinkan semua robot mengakses semuanya
File robots.txt ini tidak memberikan aturan larangan untuk semua mesin telusur:
User-agent: * Disallow:Dengan kata lain, ini memungkinkan bot pencarian untuk merayapi semuanya. Ini melayani tujuan yang sama seperti file robots.txt kosong atau tidak ada robots.txt sama sekali.
Blokir semua robot agar tidak mengakses semuanya
Contoh file robots.txt memberitahu semua mesin pencari untuk tidak mengakses apapun setelah garis miring. Dengan kata lain, seluruh domain:
User-agent: * Disallow: /Singkatnya, file robots.txt ini memblokir semua robot mesin telusur dan dapat menghentikan tampilan situs Anda di laman hasil penelusuran.
Blokir semua robot agar tidak merayapi satu file
Dalam contoh ini, kami memblokir semua bot pencarian agar tidak merayapi file tertentu.
User-agent: * Disallow: /directory/this-is-a-file.pdfBlokir semua robot agar tidak merayapi satu jenis file (doc, pdf, jpg)
Karena tanpa pengindeksan, file seperti 'doc' atau 'pdf' tidak dapat dilakukan menggunakan tag meta robot "tanpa indeks"; anda dapat menggunakan arahan berikut untuk menghentikan jenis file tertentu agar tidak diindeks.
User-agent: * Disallow: /*.doc$ Disallow: /*.pdf$ Disallow: /*.jpg$Ini akan berfungsi untuk mendeindeks semua file jenis itu, selama tidak ada file individual yang ditautkan dari tempat lain di web.
Blokir Google agar tidak merayapi banyak direktori
Anda mungkin ingin memblokir perayapan beberapa direktori untuk bot tertentu atau semua bot. Dalam contoh ini, kami memblokir Googlebot agar tidak merayapi dua subdirektori.
User-agent: Googlebot Disallow: /admin/ Disallow: /private/Catatan, tidak ada batasan jumlah direktori yang dapat Anda gunakan bock. Cukup daftarkan masing-masing di bawah agen pengguna tempat arahan berlaku.
Blokir Google agar tidak merayapi semua URL berparameter
Arahan ini sangat berguna untuk situs web yang menggunakan navigasi segi, di mana banyak URL parameter dapat dibuat.
User-agent: Googlebot Disallow: /*?Arahan ini menghentikan anggaran perayapan Anda agar tidak digunakan pada URL dinamis dan memaksimalkan perayapan halaman-halaman penting. Saya menggunakan ini secara teratur, terutama di situs web e-niaga dengan fungsi pencarian.
Blokir semua bot agar tidak merayapi satu subdirektori tetapi mengizinkan satu halaman di dalamnya untuk dirayapi
Terkadang Anda mungkin ingin memblokir perayap mengakses bagian lengkap situs Anda, tetapi biarkan satu halaman dapat diakses. Jika ya, gunakan kombinasi arahan 'allow' dan 'disallow' berikut:
User-agent: * Disallow: /category/ Allow: /category/widget/Ini memberitahu mesin pencari untuk tidak merayapi direktori lengkap, tidak termasuk satu halaman atau file tertentu.
Robots.txt untuk WordPress
Ini adalah konfigurasi dasar yang saya rekomendasikan untuk file robots.txt WordPress. Ini memblokir perayapan halaman admin dan tag dan URL penulis yang dapat membuat kerusakan yang tidak perlu di situs WordPress.
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /wp-admin/ Disallow: /readme.html Disallow: /refer/ Disallow: /tag/ Disallow: /author/ Disallow: /404-error/ Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xmlFile robots.txt ini akan bekerja dengan baik untuk sebagian besar situs WordPress, tetapi tentu saja, Anda harus selalu menyesuaikannya dengan kebutuhan Anda sendiri.
Cara Mengaudit File Robots.txt Anda untuk Kesalahan
Selama ini, saya telah melihat lebih banyak kesalahan yang memengaruhi peringkat dalam file robots.txt daripada aspek teknis SEO lainnya. Dengan begitu banyak arahan yang berpotensi bertentangan, masalah dapat dan memang terjadi.
Jadi, ketika berbicara tentang file robots.txt, ada baiknya untuk memperhatikan masalah.
Untungnya, laporan "Cakupan" di dalam Google Search Console menyediakan cara bagi Anda untuk memeriksa dan memantau masalah robots.txt.
Anda juga dapat menggunakan Alat Pengujian Robots.txt Google yang bagus untuk memeriksa kesalahan dalam file robots langsung Anda atau menguji file robots.txt baru sebelum Anda menerapkannya.
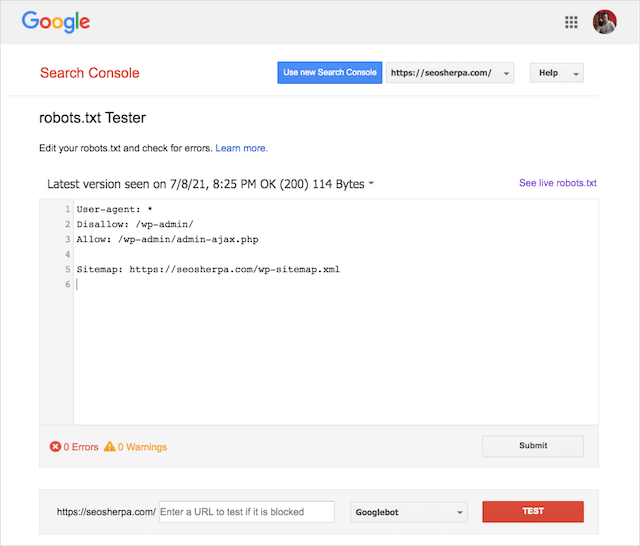
Kami akan menyelesaikannya dengan membahas masalah yang paling umum, apa artinya dan bagaimana mengatasinya.
URL yang dikirimkan diblokir oleh robots.txt
Kesalahan ini berarti bahwa setidaknya satu URL di peta situs yang Anda kirimkan diblokir oleh robots.txt.

Peta situs yang disiapkan dengan benar harus menyertakan hanya URL yang ingin Anda indeks di mesin telusur . Dengan demikian, halaman tersebut tidak boleh berisi halaman yang tidak diindeks, dikanonikalisasi, atau dialihkan.
Jika Anda telah mengikuti praktik terbaik ini, maka tidak ada halaman yang dikirimkan di peta situs Anda yang harus diblokir oleh robots.txt.
Jika Anda melihat "URL yang dikirim diblokir oleh robots.txt" dalam laporan cakupan, Anda harus menyelidiki halaman mana yang terpengaruh, lalu alihkan file robots.txt Anda untuk menghapus pemblokiran halaman tersebut.
Anda dapat menggunakan penguji robots.txt Google untuk melihat perintah mana yang memblokir konten.
Diblokir oleh Robots.txt
“Kesalahan” ini berarti Anda memiliki halaman yang diblokir oleh robots.txt yang saat ini tidak ada dalam indeks Google.

Jika konten ini memiliki utilitas dan harus diindeks, hapus blok perayapan di robots.txt.
Sebuah kata peringatan singkat:
“Diblokir oleh robots.txt” belum tentu merupakan kesalahan. Infact, mungkin justru hasil yang Anda inginkan.
Misalnya, Anda mungkin telah memblokir file tertentu di robots.txt dengan maksud untuk mengecualikannya dari indeks Google. Di sisi lain, jika Anda telah memblokir perayapan halaman tertentu dengan tujuan untuk tidak mengindeksnya, pertimbangkan untuk menghapus blok perayapan dan gunakan tag meta robot sebagai gantinya.
Itulah satu-satunya cara untuk menjamin pengecualian konten dari indeks Google.
Diindeks, Meskipun Diblokir oleh Robots.txt
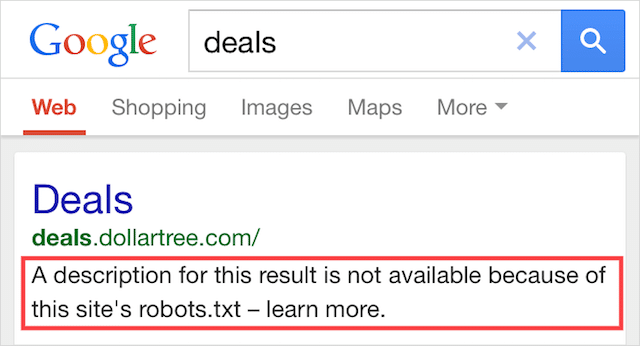
Kesalahan ini berarti bahwa beberapa konten yang diblokir oleh robots.txt masih terindeks di Google.
Itu terjadi saat konten masih dapat ditemukan oleh Googlebot karena ditautkan dari tempat lain di web. Singkatnya, Googlebot mendarat di konten yang dirayapi dan kemudian mengindeksnya sebelum mengunjungi file robots.txt situs web Anda, di mana ia melihat arahan yang tidak diizinkan.
Saat itu, sudah terlambat. Dan itu akan diindeks:
Biarkan saya mengebor rumah yang satu ini:
Jika Anda mencoba mengecualikan konten dari hasil penelusuran Google, robots.txt bukanlah solusi yang tepat.
Saya sarankan menghapus blok perayapan dan menggunakan tag meta robots no-index untuk mencegah pengindeksan.
Sebaliknya, jika Anda memblokir konten ini secara tidak sengaja dan ingin menyimpannya di indeks Google, hapus blok perayapan di robots.txt dan biarkan saja.
Ini dapat membantu meningkatkan visibilitas konten dalam pencarian Google.
Pikiran Akhir
Robots.txt dapat digunakan untuk meningkatkan perayapan dan pengindeksan konten situs web Anda, yang membantu Anda menjadi lebih terlihat di SERP.
Ketika digunakan secara efektif, itu adalah teks terpenting di situs web Anda. Tapi, bila digunakan sembarangan, itu akan menjadi kelemahan dalam kode situs web Anda.
Kabar baiknya, hanya dengan pemahaman dasar tentang agen pengguna dan beberapa arahan, hasil pencarian yang lebih baik ada dalam jangkauan Anda.
Satu-satunya pertanyaan adalah, protokol mana yang akan Anda gunakan dalam file robots.txt Anda?
Beri tahu saya di komentar di bawah.