
Robots.txt: Der ultimative Leitfaden für SEO (Ausgabe 2021)
Veröffentlicht: 2021-06-10 Heute lernen Sie, wie Sie eine der wichtigsten Dateien für die SEO einer Website erstellen:
Heute lernen Sie, wie Sie eine der wichtigsten Dateien für die SEO einer Website erstellen:
(Die robots.txt-Datei).
Insbesondere zeige ich Ihnen, wie Sie Robots-Ausschlussprotokolle verwenden, um Bots von bestimmten Seiten zu blockieren, die Crawl-Frequenz zu erhöhen, das Crawl-Budget zu optimieren und letztendlich mehr vom Ranking der richtigen Seite in SERPs zu erhalten.
Ich decke ab:
- Was eine robots.txt-Datei ist
- Warum robots.txt wichtig ist
- Wie robots.txt funktioniert
- Robots.txt-Benutzeragenten und -Anweisungen
- Robots.txt Vs Meta-Roboter
- So finden Sie Ihre robots.txt
- Erstellen Ihrer robots.txt-Datei
- Best Practices für die Robots.txt-Datei
- Robots.txt-Beispiele
- So prüfen Sie Ihre robots.txt auf Fehler
Außerdem eine ganze Menge mehr. Lassen Sie uns gleich eintauchen.
Was ist eine Robots.txt-Datei? Und warum Sie einen brauchen
Einfach ausgedrückt ist eine robots.txt-Datei eine Bedienungsanleitung für Web-Roboter.
Es informiert Bots aller Art darüber, welche Bereiche einer Website sie crawlen sollen (und welche nicht).
Die robots.txt wird jedoch hauptsächlich als „Verhaltenskodex“ verwendet, um die Aktivität von Suchmaschinenrobotern (AKA-Webcrawlern) zu kontrollieren.

Die robots.txt wird regelmäßig von allen großen Suchmaschinen (einschließlich Google, Bing und Yahoo) auf Anweisungen zum Crawlen der Website überprüft. Diese Anweisungen werden als Direktiven bezeichnet.
Wenn es keine Anweisungen gibt – oder keine robots.txt-Datei – werden Suchmaschinen die gesamte Website, private Seiten und alles durchsuchen.
Obwohl die meisten Suchmaschinen gehorsam sind, ist es wichtig zu beachten, dass die Einhaltung der robots.txt-Anweisungen optional ist. Auf Wunsch können Suchmaschinen Ihre robots.txt-Datei ignorieren.
Zum Glück ist Google keine dieser Suchmaschinen. Google neigt dazu, die Anweisungen in einer robots.txt-Datei zu befolgen.
Warum ist robots.txt wichtig?
Eine robots.txt-Datei ist für viele Websites nicht kritisch, insbesondere für kleine.
Das liegt daran, dass Google normalerweise alle wichtigen Seiten einer Website finden und indizieren kann.
Und sie indizieren automatisch KEINE doppelten Inhalte oder Seiten, die unwichtig sind.
Trotzdem gibt es keinen guten Grund, keine robots.txt-Datei zu haben – also empfehle ich Ihnen, eine zu haben.
Eine robots.txt gibt Ihnen mehr Kontrolle darüber, was Suchmaschinen auf Ihrer Website crawlen können und was nicht, und das ist aus mehreren Gründen hilfreich:
Ermöglicht das Blockieren nicht öffentlicher Seiten für Suchmaschinen
Manchmal gibt es Seiten auf Ihrer Website, die Sie nicht indizieren möchten.
Beispielsweise könnten Sie eine neue Website in einer Staging-Umgebung entwickeln, von der Sie sicher sein möchten, dass sie bis zum Start vor Benutzern verborgen bleibt.
Oder Sie haben Anmeldeseiten für Websites, die Sie nicht in den SERPs anzeigen möchten.
Wenn dies der Fall wäre, könnten Sie die robots.txt verwenden, um diese Seiten für Suchmaschinen-Crawler zu blockieren.
Steuert das Crawling-Budget der Suchmaschine
Wenn Sie Schwierigkeiten haben, alle Ihre Seiten in Suchmaschinen zu indizieren, haben Sie möglicherweise ein Problem mit dem Crawl-Budget.
Einfach ausgedrückt: Suchmaschinen verbrauchen die Zeit, die zum Crawlen Ihrer Inhalte auf den Totgewichtsseiten Ihrer Website vorgesehen ist.

Durch das Blockieren von URLs mit geringem Nutzen mit robots.txt können Suchmaschinen-Robots mehr von ihrem Crawling-Budget für die Seiten ausgeben, die am wichtigsten sind.
Verhindert die Indizierung von Ressourcen
Es hat sich bewährt, die Meta-Direktive „no-index“ zu verwenden, um zu verhindern, dass einzelne Seiten indexiert werden.
Das Problem ist, dass Meta-Direktiven nicht gut für Multimedia-Ressourcen wie PDFs und Word-Dokumente funktionieren.
Hier ist robots.txt praktisch.
Sie können Ihrer robots.txt-Datei eine einfache Textzeile hinzufügen, und Suchmaschinen werden daran gehindert, auf diese Multimediadateien zuzugreifen.
(Wie das genau geht, zeige ich dir später in diesem Beitrag)
Wie (genau) funktioniert eine Robots.txt?
Wie ich bereits erwähnt habe, dient eine robots.txt-Datei als Anleitung für Suchmaschinen-Roboter. Es teilt Such-Bots mit, wo (und wo nicht) sie crawlen sollen.
Aus diesem Grund sucht ein Such-Crawler nach einer robots.txt-Datei, sobald sie auf einer Website ankommt.
Wenn er die robots.txt findet, liest der Crawler sie zuerst, bevor er mit dem Crawlen der Website fortfährt.
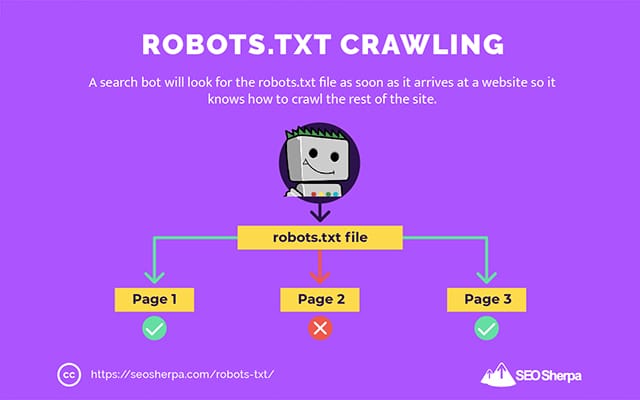
Wenn der Web-Crawler keine robots.txt findet oder die Datei keine Anweisungen enthält, die die Aktivität der Such-Bots verbieten, wird der Crawler die gesamte Website wie gewohnt durchsuchen.
Damit eine robots.txt-Datei von Such-Bots gefunden und gelesen werden kann, ist eine robots.txt-Datei auf eine ganz bestimmte Weise formatiert.
Erstens ist es eine Textdatei ohne HTML-Markup-Code (daher die Erweiterung .txt).
Zweitens wird es im Stammordner der Website abgelegt, z. B. https://seosherpa.com/robots.txt.
Drittens verwendet es eine Standard-Syntax, die allen robots.txt-Dateien gemeinsam ist, etwa so:
Sitemap: [URL location of sitemap] User-agent: [bot identifier] [directive 1] [directive 2] [directive ...] User-agent: [another bot identifier] [directive 1] [directive 2] [directive ...]Diese Syntax mag auf den ersten Blick abschreckend wirken, ist aber eigentlich ganz einfach.
Kurz gesagt, Sie definieren den Bot (User-Agent), für den die Anweisungen gelten, und geben dann die Regeln (Anweisungen) an, denen der Bot folgen soll.
Lassen Sie uns diese beiden Komponenten genauer untersuchen.
Benutzeragenten
Ein User-Agent ist der Name, der verwendet wird, um bestimmte Webcrawler – und andere im Internet aktive Programme – zu definieren.
Es gibt buchstäblich Hunderte von Benutzeragenten, einschließlich Agenten für Gerätetypen und Browser.
Die meisten sind im Zusammenhang mit einer robots.txt-Datei und SEO irrelevant. Diese sollten Sie hingegen kennen:
- Google: Googlebot
- Google Bilder: Googlebot-Bild
- Google Video: Googlebot-Video
- Google News: Googlebot-News
- Bing: Binbot
- Bing-Bilder und -Videos: MSNBot-Media
- Yahoo: Schlürfen
- Yandex: YandexBot
- Baidu : Baiduspinne
- DuckDuckGo: DuckDuckBot
Durch die Angabe des User Agents können Sie unterschiedliche Regeln für verschiedene Suchmaschinen festlegen.

Wenn Sie beispielsweise möchten, dass eine bestimmte Seite in den Google-Suchergebnissen angezeigt wird, aber nicht in Baidu-Suchen, können Sie zwei Sätze von Befehlen in Ihre robots.txt-Datei aufnehmen: einen Satz mit vorangestelltem „User-agent: Bingbot“ und einen vorangestellten Satz von „User-Agent: Baiduspider.“
Sie können auch den Platzhalter Stern (*) verwenden, wenn Sie möchten, dass Ihre Anweisungen für alle Benutzeragenten gelten.
Angenommen, Sie möchten alle Suchmaschinen-Roboter daran hindern, Ihre Website zu durchsuchen, mit Ausnahme von DuckDuckGo. So würden Sie es tun:
User-agent: * Disallow: / User-agent: DuckDuckBot Allow: /Nebenbemerkung: Wenn die robots.txt-Datei widersprüchliche Befehle enthält, folgt der Bot dem detaillierteren Befehl.
Aus diesem Grund weiß DuckDuckBot im obigen Beispiel, dass die Website gecrawlt werden soll, obwohl eine frühere Anweisung (die für alle Bots gilt) besagt, dass sie nicht crawlen soll. Kurz gesagt, ein Bot folgt der Anweisung, die am genauesten auf ihn zutrifft.
Richtlinien
Richtlinien sind der Verhaltenskodex, den der User-Agent befolgen soll. Mit anderen Worten, Richtlinien definieren, wie der Suchbot Ihre Website durchsuchen soll.
Hier sind Anweisungen, die der GoogleBot derzeit unterstützt, zusammen mit ihrer Verwendung in einer robots.txt-Datei:
Nicht zulassen
Verwenden Sie diese Anweisung, um zu verhindern, dass Such-Bots bestimmte Dateien und Seiten auf einem bestimmten URL-Pfad durchsuchen.

Wenn Sie beispielsweise den GoogleBot daran hindern möchten, auf Ihr Wiki und alle seine Seiten zuzugreifen, sollte Ihre robots.txt diese Anweisung enthalten:
User-agent: GoogleBot Disallow: /wikiSie können die Direktive disallow verwenden, um das Crawlen einer bestimmten URL, aller Dateien und Seiten in einem bestimmten Verzeichnis und sogar Ihrer gesamten Website zu blockieren.
Erlauben
Die Allow-Direktive ist nützlich, wenn Sie Suchmaschinen erlauben möchten, ein bestimmtes Unterverzeichnis oder eine Seite zu crawlen – in einem ansonsten unzulässigen Bereich Ihrer Website.

Angenommen, Sie wollten verhindern, dass alle Suchmaschinen Beiträge in Ihrem Blog mit Ausnahme von einem durchsuchen. dann würden Sie die Allow-Direktive wie folgt verwenden:
User-agent: * Disallow: /blog Allow: /blog/allowable-postDa Such-Bots immer den detailliertesten Anweisungen in einer robots.txt-Datei folgen, wissen sie, dass sie /blog/allowable-post crawlen müssen, aber sie crawlen keine anderen Posts oder Dateien in diesem Verzeichnis wie;
- /blog/post-one/
- /blog/post-zwei/
- /blog/dateiname.pdf
Sowohl Google als auch Bing unterstützen diese Richtlinie. Aber andere Suchmaschinen nicht.
Seitenverzeichnis
Die Sitemap-Direktive wird verwendet, um den Speicherort Ihrer XML-Sitemap(s) für Suchmaschinen anzugeben.
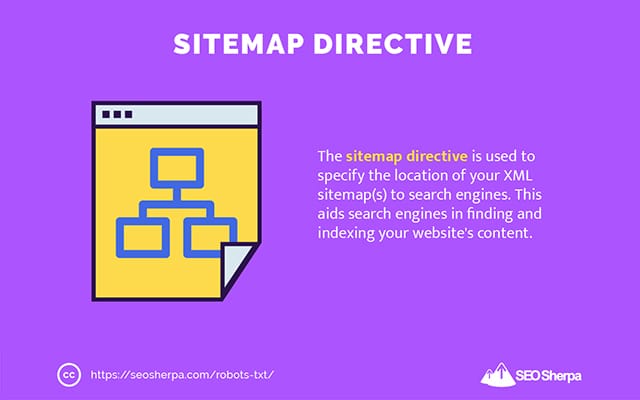
Wenn Sie mit Sitemaps noch nicht vertraut sind, werden sie verwendet, um die Seiten aufzulisten, die in Suchmaschinen gecrawlt und indexiert werden sollen.
Indem Sie die Sitemap-Anweisung in die robots.txt-Datei aufnehmen, helfen Sie Suchmaschinen, Ihre Sitemap zu finden und im Gegenzug die wichtigsten Seiten Ihrer Website zu crawlen und zu indizieren.
Wenn Sie Ihre XML-Sitemap bereits über die Search Console eingereicht haben, ist das Hinzufügen Ihrer Sitemap(s) in robots.txt für Google etwas überflüssig. Dennoch ist es am besten, die Sitemap-Direktive zu verwenden, da sie Suchmaschinen wie Ask, Bing und Yahoo mitteilt, wo Ihre Sitemap(s) zu finden sind.
Hier ist ein Beispiel für eine robots.txt-Datei, die die Sitemap-Direktive verwendet:
Sitemap: https://www.website.com/sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/Beachten Sie die Platzierung der Sitemap-Anweisung in der robots.txt-Datei. Platzieren Sie es am besten ganz oben in Ihrer robots.txt. Es kann auch unten platziert werden.
Wenn Sie mehrere Sitemaps haben, sollten Sie alle in Ihre robots.txt-Datei aufnehmen. So könnte die robots.txt-Datei aussehen, wenn wir separate XML-Sitemaps für Seiten und Beiträge hätten:
Sitemap: http://website.com/post-sitemap.xml Sitemap: http://website.com/page-sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/In jedem Fall müssen Sie jede XML-Sitemap nur einmal erwähnen, da alle unterstützten Benutzeragenten der Anweisung folgen.
Beachten Sie, dass im Gegensatz zu anderen robots.txt-Anweisungen, die Pfade auflisten, die Sitemap-Anweisung die absolute URL Ihrer XML-Sitemap angeben muss, einschließlich des Protokolls, des Domänennamens und der Domänenerweiterung der obersten Ebene.
Kommentare
Der Kommentar „directive“ ist für Menschen nützlich, wird aber nicht von Suchbots verwendet.

Sie können Kommentare hinzufügen, um Sie daran zu erinnern, warum bestimmte Anweisungen existieren, oder diejenigen mit Zugriff auf Ihre robots.txt daran hindern, wichtige Anweisungen zu löschen. Kurz gesagt, Kommentare werden verwendet, um Notizen zu Ihrer robots.txt-Datei hinzuzufügen.
Um einen Kommentar hinzuzufügen, geben Sie ein.“ #" gefolgt vom Kommentartext.
# Don't allow access to the /wp-admin/ directory for all robots. User-agent: * Disallow: /wp-admin/Sie können einen Kommentar am Anfang einer Zeile (wie oben gezeigt) oder nach einer Anweisung in derselben Zeile (wie unten gezeigt) hinzufügen:
User-agent: * #Applies to all robots Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.Wo auch immer Sie Ihren Kommentar schreiben, alles nach dem Hash wird ignoriert.
So weit mitkommen?
Groß! Wir haben jetzt die wichtigsten Anweisungen behandelt, die Sie für Ihre robots.txt-Datei benötigen – dies sind auch die einzigen Anweisungen, die von Google unterstützt werden.
Aber was ist mit anderen Suchmaschinen? Im Fall von Bing, Yahoo und Yandex gibt es eine weitere Anweisung, die Sie verwenden können:
Crawl-Verzögerung
Die Crawl-Delay-Direktive ist eine inoffizielle Direktive, die verwendet wird, um zu verhindern, dass Server mit zu vielen Crawl-Anfragen überlastet werden.
Mit anderen Worten, Sie verwenden es, um die Häufigkeit zu begrenzen, mit der eine Suchmaschine Ihre Website durchsuchen kann.

Wohlgemerkt, wenn Suchmaschinen Ihren Server durch häufiges Crawlen Ihrer Website überlasten können, wird das Hinzufügen der Crawl-Delay-Direktive zu Ihrer robots.txt-Datei das Problem nur vorübergehend beheben.
Der Fall kann sein, dass Ihre Website auf einem beschissenen Hosting oder einer falsch konfigurierten Hosting-Umgebung läuft, und das sollten Sie schnell beheben.
Die Crawl-Verzögerungsanweisung funktioniert, indem sie die Zeit in Sekunden definiert, zwischen der ein Suchbot Ihre Website crawlen kann.
Wenn Sie beispielsweise Ihre Crawl-Verzögerung auf 5 einstellen, werden Such-Bots den Tag in Fünf-Sekunden-Fenster unterteilen und in jedem Fenster nur eine Seite (oder keine) für maximal etwa 17.280 URLs während des Tages crawlen.
Seien Sie daher vorsichtig, wenn Sie diese Anweisung festlegen, insbesondere wenn Sie eine große Website haben. Nur 17.280 gecrawlte URLs pro Tag sind nicht sehr hilfreich, wenn Ihre Website Millionen von Seiten hat.
Die Art und Weise, wie jede Suchmaschine mit der Crawl-Delay-Direktive umgeht, ist unterschiedlich. Lassen Sie es uns unten aufschlüsseln:
Crawl-Verzögerung und Bing, Yahoo und Yandex
Bing, Yahoo und Yandex unterstützen alle die Crawl-Delay-Direktive in robots.txt.
Das bedeutet, dass Sie eine Crawl-Delay-Anweisung für die User-Agents BingBot, Slurp und YandexBot festlegen können, und die Suchmaschine wird ihr Crawling entsprechend drosseln.
Beachten Sie jedoch, dass jede Suchmaschine die Crawl-Verzögerung etwas anders interpretiert, also überprüfen Sie unbedingt ihre Dokumentation:
- Bing und Yahoo
- Jandex
Allerdings ist das Format der Crawl-Delay-Anweisung für jede dieser Engines gleich. Sie müssen es direkt nach einer disallow OR allow-Anweisung platzieren. Hier ist ein Beispiel:
User-agent: BingBot Allow: /widgets/ Crawl-delay: 5Crawl-Verzögerung und Google
Der Crawler von Google unterstützt die Richtlinie zur Crawl-Verzögerung nicht, daher ist es sinnlos, eine Crawl-Verzögerung für den GoogleBot in robots.txt festzulegen.
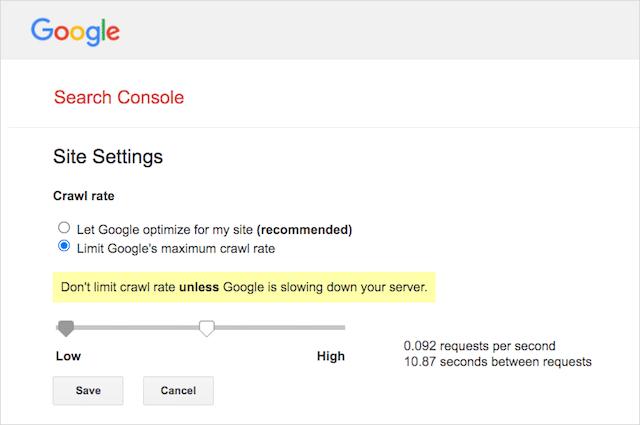
Google unterstützt jedoch die Definition einer Crawling-Rate in der Google Search Console. So geht's:
- Gehen Sie zur Einstellungsseite der Google Search Console.
- Wählen Sie die Property aus, für die Sie die Crawling-Rate definieren möchten
- Klicken Sie auf „Maximale Crawling-Rate von Google begrenzen“.
- Stellen Sie den Schieberegler auf Ihre bevorzugte Crawling-Rate ein. Standardmäßig hat die Crawling-Rate die Einstellung „Google für meine Website optimieren lassen (empfohlen)“.
Kriechverzögerung und Baidu
Wie Google unterstützt Baidu die Crawl-Verzögerungsrichtlinie nicht. Es ist jedoch möglich, ein Baidu Webmaster Tools-Konto zu registrieren, in dem Sie die Crawling-Frequenz steuern können, ähnlich wie in der Google Search Console.
Die Quintessenz? Robots.txt weist Suchmaschinen-Spider an, bestimmte Seiten Ihrer Website nicht zu crawlen.
Robots.txt vs. Meta-Roboter vs. X-Roboter
Es gibt verdammt viele „Roboter“-Anweisungen da draußen. Was sind die Unterschiede oder sind sie gleich?
Lassen Sie mich eine kurze Erklärung anbieten:
Zunächst einmal ist robots.txt eine eigentliche Textdatei, während meta und x-robots Tags im Code einer Webseite sind.
Zweitens gibt robots.txt Bots Vorschläge , wie die Seiten einer Website gecrawlt werden können. Andererseits geben die Meta-Direktiven von Robots sehr genaue Anweisungen zum Crawlen und Indexieren des Inhalts einer Seite.
Abgesehen davon, was sie sind, erfüllen die drei alle unterschiedliche Funktionen.
Robots.txt diktiert das Website- oder verzeichnisweite Crawling-Verhalten, während Meta- und X-Robots das Indexierungsverhalten auf der Ebene einzelner Seiten (oder Seitenelemente) diktieren können.

Im Algemeinen:
Wenn Sie verhindern möchten, dass eine Seite indexiert wird, sollten Sie das Meta-Robots-Tag „no-index“ verwenden. Das Verbieten einer Seite in robots.txt garantiert nicht, dass sie nicht in Suchmaschinen angezeigt wird (robots.txt-Anweisungen sind schließlich Vorschläge). Außerdem könnte ein Suchmaschinenroboter diese URL immer noch finden und indizieren, wenn sie von einer anderen Website verlinkt wird.

Im Gegenteil, wenn Sie verhindern möchten, dass eine Mediendatei indiziert wird, ist robots.txt der richtige Weg. Sie können keine Meta-Roboter-Tags zu Dateien wie JPEGs oder PDFs hinzufügen.
So finden Sie Ihre Robots.txt
Wenn Sie bereits eine robots.txt-Datei auf Ihrer Website haben, können Sie unter yourdomain.com/robots.txt darauf zugreifen.
Navigieren Sie in Ihrem Browser zu der URL.
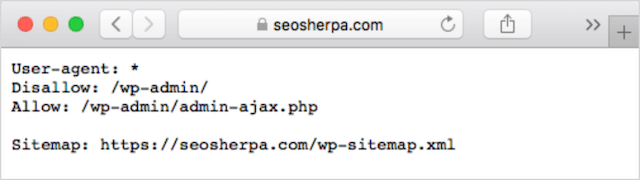
Wenn Sie eine textbasierte Seite wie die obige sehen, dann haben Sie eine robots.txt-Datei.
So erstellen Sie eine Robots.txt-Datei
Wenn Sie noch keine robots.txt-Datei haben, können Sie ganz einfach eine erstellen.
Öffnen Sie zunächst Notepad, Microsoft Word oder einen beliebigen Texteditor und speichern Sie die Datei als „Roboter“.
Achten Sie darauf, Kleinbuchstaben zu verwenden, und wählen Sie .txt als Dateityperweiterung:

Zweitens, fügen Sie Ihre Anweisungen hinzu. Wenn Sie beispielsweise verhindern möchten, dass alle Such-Bots Ihr /login/-Verzeichnis durchsuchen, geben Sie Folgendes ein:
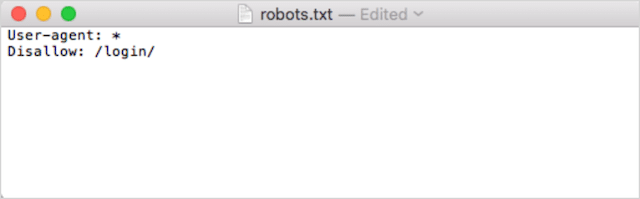
Fügen Sie weitere Anweisungen hinzu, bis Sie mit Ihrer robots.txt-Datei zufrieden sind.
Alternativ kannst du deine robots.txt mit einem Tool wie diesem von Ryte generieren.

Ein Vorteil der Verwendung eines Tools besteht darin, dass menschliche Fehler minimiert werden.
Nur ein kleiner Fehler in Ihrer robots.txt-Syntax könnte in einem SEO-Desaster enden.
Der Nachteil bei der Verwendung eines robots.txt-Generators besteht jedoch darin, dass die Möglichkeiten zur Anpassung minimal sind.
Deshalb empfehle ich Ihnen, selbst eine robot.txt-Datei schreiben zu lernen. Sie können dann eine robots.txt genau nach Ihren Anforderungen erstellen.
Wohin mit Ihrer Robots.txt-Datei
Fügen Sie Ihre robots.txt-Datei im Verzeichnis der obersten Ebene der Subdomain hinzu, für die sie gilt.
Um beispielsweise das Crawling-Verhalten auf yourdomain.com zu steuern, sollte die robots.txt-Datei über den URL-Pfad yourdomain.com/robots.txt zugänglich sein.
Wenn Sie andererseits das Crawling auf einer Subdomain wie shop.yourdomain.com steuern möchten, sollte die robots.txt über den URL-Pfad shop.yourdomain.com/robots.txt zugänglich sein.
Die goldenen Regeln lauten:
- Geben Sie jeder Subdomain auf Ihrer Website eine eigene robots.txt-Datei.
- Benennen Sie Ihre Datei(en) robots.txt in Kleinbuchstaben.
- Platzieren Sie die Datei im Stammverzeichnis der Subdomain, auf die sie verweist.
Wenn die robots.txt-Datei nicht im Stammverzeichnis gefunden werden kann, gehen Suchmaschinen davon aus, dass keine Anweisungen vorhanden sind, und durchsuchen Ihre Website vollständig.
Robots.txt-Datei Best Practices
Lassen Sie uns als Nächstes die Regeln von robots.txt-Dateien behandeln. Verwenden Sie diese Best Practices, um häufige Fallstricke in robots.txt-Dateien zu vermeiden:
Verwenden Sie für jede Anweisung eine neue Zeile
Jede Anweisung in Ihrer robots.txt muss in einer neuen Zeile stehen.
Wenn nicht, werden Suchmaschinen verwirrt darüber sein, was gecrawlt (und indexiert) werden soll.
Dies ist beispielsweise falsch konfiguriert:
User-agent: * Disallow: /folder/ Disallow: /another-folder/Dies hingegen ist eine korrekt eingerichtete robots.txt-Datei:
User-agent: * Disallow: /folder/ Disallow: /another-folder/Spezifität gewinnt „fast“ immer
Wenn es um Google und Bing geht, gewinnt die granularere Richtlinie.
Beispielsweise gewinnt diese Allow-Direktive die Disallow-Direktive, weil ihre Zeichenlänge länger ist.
User-agent: * Disallow: /about/ Allow: /about/company/Google und Bing können /about/company/ crawlen, aber keine anderen Seiten im /about/-Verzeichnis.
Bei anderen Suchmaschinen ist jedoch das Gegenteil der Fall.
Standardmäßig gewinnt bei allen großen Suchmaschinen außer Google und Bing immer die erste übereinstimmende Direktive .
Im obigen Beispiel folgen die Suchmaschinen der Disallow-Anweisung und ignorieren die Allow-Anweisung, was bedeutet, dass die /about/company-Seite nicht gecrawlt wird.
Denken Sie daran, wenn Sie Regeln für alle Suchmaschinen erstellen.
Nur eine Gruppe von Anweisungen pro User-Agent
Wenn Ihre robots.txt mehrere Gruppen von Anweisungen pro Benutzeragent enthielte, boh-oh-boy, könnte es verwirrend werden?
Nicht unbedingt für Roboter, weil sie alle Regeln aus den verschiedenen Erklärungen in einer Gruppe zusammenfassen und ihnen alle folgen, aber für Sie.
Um mögliche menschliche Fehler zu vermeiden, geben Sie den Benutzeragenten einmal an und listen Sie dann unten alle Anweisungen auf, die für diesen Benutzeragenten gelten.

Indem Sie die Dinge ordentlich und einfach halten, ist es weniger wahrscheinlich, dass Sie einen Fehler machen.
Verwenden Sie Platzhalter (*), um Anweisungen zu vereinfachen
Haben Sie die Platzhalter (*) im obigen Beispiel bemerkt?
Das stimmt; Sie können Platzhalter (*) verwenden, um Regeln auf alle Benutzeragenten anzuwenden UND URL-Muster beim Deklarieren von Anweisungen abzugleichen.
Wenn Sie beispielsweise verhindern möchten, dass Such-Bots auf parametrisierte Produktkategorie-URLs auf Ihrer Website zugreifen, können Sie jede Kategorie wie folgt auflisten:
User-agent: * Disallow: /products/watches? Disallow: /products/handbags? Disallow: /products/shoes?Oder Sie könnten einen Platzhalter verwenden, der die Regel auf alle Kategorien anwendet. So würde es aussehen:
User-agent: * Disallow: /products/*?Dieses Beispiel hindert Suchmaschinen daran, alle URLs im Unterordner /product/ zu crawlen, die ein Fragezeichen enthalten. Mit anderen Worten, alle Produktkategorie-URLs, die parametrisiert sind.
Google, Bing, Yahoo unterstützen die Verwendung von Platzhaltern in robots.txt-Anweisungen und Ask.
Verwenden Sie „$“, um das Ende einer URL anzugeben
Um das Ende einer URL anzugeben, verwenden Sie das Dollarzeichen ( $ ) nach dem robots.txt-Pfad.
Angenommen, Sie wollten verhindern, dass Suchbots auf alle .doc-Dateien auf Ihrer Website zugreifen. dann würden Sie diese Direktive verwenden:
User-agent: * Disallow: /*.doc$Dies würde Suchmaschinen daran hindern, auf URLs zuzugreifen, die mit .doc enden.
Das bedeutet, dass sie /media/file.doc nicht crawlen würden, aber sie würden /media/file.doc?id=72491 crawlen, da diese URL nicht auf „.doc“ endet.
Jede Subdomain bekommt ihre eigene robots.txt
Robots.txt-Anweisungen gelten nur für die (Sub-)Domain, auf der die robots.txt-Datei gehostet wird.
Das bedeutet, wenn Ihre Website mehrere Subdomains hat wie:
- domain.com
- tickets.domain.com
- events.domain.com
Jede Subdomain benötigt eine eigene robots.txt-Datei.
Die robots.txt sollte immer im Stammverzeichnis jeder Subdomain hinzugefügt werden. So würden die Pfade im obigen Beispiel aussehen:
- domain.com/robots.txt
- tickets.domain.com/robots.txt
- events.domain.com/robots.txt
Verwenden Sie noindex nicht in Ihrer robots.txt
Einfach ausgedrückt, Google unterstützt die No-Index-Anweisung in robots.txt nicht.
Während Google es in der Vergangenheit befolgt hat, hat Google die Unterstützung ab Juli 2019 vollständig eingestellt.
Und wenn Sie daran denken, die Anweisung no-index robots.txt zu verwenden, um Inhalte in anderen Suchmaschinen nicht zu indizieren, denken Sie noch einmal darüber nach:
Die inoffizielle No-Index-Anweisung hat in Bing nie funktioniert.
Die bei weitem beste Methode, Inhalte in Suchmaschinen nicht zu indizieren, besteht darin, ein No-Index-Meta-Robots-Tag auf die Seite anzuwenden, die Sie ausschließen möchten.
Halten Sie Ihre robots.txt-Datei unter 512 KB
Google hat derzeit eine Größenbeschränkung für robots.txt-Dateien von 500 Kibibyte (512 Kilobyte).
Das bedeutet, dass alle Inhalte nach 512 KB ignoriert werden können .

Angesichts der Tatsache, dass ein Zeichen nur ein Byte verbraucht, müsste Ihre robots.txt RIESIG sein, um diese Dateigrößenbeschränkung zu erreichen (512.000 Zeichen, um genau zu sein). Halten Sie Ihre robots.txt-Datei schlank, indem Sie sich weniger auf einzeln ausgeschlossene Seiten und mehr auf breitere Muster konzentrieren, die durch Platzhalter kontrolliert werden können.
Es ist unklar, ob andere Suchmaschinen die maximal zulässige Dateigröße für robots.txt-Dateien haben.
Robots.txt-Beispiele
Nachfolgend finden Sie einige Beispiele für robots.txt-Dateien.
Sie enthalten Kombinationen der Anweisungen, die unsere SEO-Agentur am häufigsten in den robots.txt-Dateien für Kunden verwendet. Denken Sie jedoch daran; diese dienen nur zu Inspirationszwecken. Sie müssen die robots.txt-Datei immer an Ihre Anforderungen anpassen.
Erlauben Sie allen Robotern den Zugriff auf alles
Diese robots.txt-Datei enthält keine Verbotsregeln für alle Suchmaschinen:
User-agent: * Disallow:Mit anderen Worten, es ermöglicht Suchbots, alles zu crawlen. Es dient dem gleichen Zweck wie eine leere robots.txt-Datei oder gar keine robots.txt-Datei.
Verhindern Sie, dass alle Roboter auf alles zugreifen
Die Beispieldatei robots.txt weist alle Suchmaschinen an, auf nichts nach dem abschließenden Schrägstrich zuzugreifen. Mit anderen Worten, die gesamte Domäne:
User-agent: * Disallow: /Kurz gesagt, diese robots.txt-Datei blockiert alle Suchmaschinen-Robots und kann verhindern, dass Ihre Website auf den Suchergebnisseiten angezeigt wird.
Alle Robots daran hindern, eine Datei zu crawlen
In diesem Beispiel hindern wir alle Such-Bots daran, eine bestimmte Datei zu crawlen.
User-agent: * Disallow: /directory/this-is-a-file.pdfAlle Robots daran hindern, einen Dateityp zu crawlen (doc, pdf, jpg)
Da es keine Indexierung gibt, kann eine Datei wie „doc“ oder „pdf“ nicht mit einem Meta-Roboter „no-index“-Tag erstellt werden; Sie können die folgende Direktive verwenden, um zu verhindern, dass ein bestimmter Dateityp indiziert wird.
User-agent: * Disallow: /*.doc$ Disallow: /*.pdf$ Disallow: /*.jpg$Dies funktioniert, um alle Dateien dieses Typs zu deindexieren, solange keine einzelne Datei mit einer anderen Stelle im Web verlinkt ist.
Google daran hindern, mehrere Verzeichnisse zu crawlen
Möglicherweise möchten Sie das Crawlen mehrerer Verzeichnisse für einen bestimmten Bot oder alle Bots blockieren. In diesem Beispiel hindern wir den Googlebot daran, zwei Unterverzeichnisse zu crawlen.
User-agent: Googlebot Disallow: /admin/ Disallow: /private/Beachten Sie, dass die Anzahl der Verzeichnisse, die Sie verwenden können, unbegrenzt ist. Listen Sie einfach jeden unter dem Benutzeragenten auf, für den die Anweisung gilt.
Google daran hindern, alle parametrisierten URLs zu crawlen
Diese Anweisung ist besonders nützlich für Websites mit facettierter Navigation, bei denen viele parametrisierte URLs erstellt werden können.
User-agent: Googlebot Disallow: /*?Diese Anweisung verhindert, dass Ihr Crawling-Budget für dynamische URLs verbraucht wird, und maximiert das Crawling wichtiger Seiten. Ich verwende dies regelmäßig, insbesondere auf E-Commerce-Websites mit Suchfunktion.
Alle Bots daran hindern, ein Unterverzeichnis zu crawlen, aber das Crawlen einer Seite darin zuzulassen
Manchmal möchten Sie vielleicht verhindern, dass Crawler auf einen vollständigen Abschnitt Ihrer Website zugreifen, aber eine Seite zugänglich lassen. Verwenden Sie in diesem Fall die folgende Kombination aus den Anweisungen „allow“ und „disallow“:
User-agent: * Disallow: /category/ Allow: /category/widget/Es weist Suchmaschinen an, nicht das gesamte Verzeichnis zu crawlen, mit Ausnahme einer bestimmten Seite oder Datei.
Robots.txt für WordPress
Dies ist die grundlegende Konfiguration, die ich für eine WordPress robots.txt-Datei empfehle. Es blockiert das Crawlen von Admin-Seiten und -Tags sowie Autoren-URLs, die auf einer WordPress-Website unnötigen Cruft verursachen können.
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /wp-admin/ Disallow: /readme.html Disallow: /refer/ Disallow: /tag/ Disallow: /author/ Disallow: /404-error/ Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xmlDiese robots.txt-Datei wird für die meisten WordPress-Websites gut funktionieren, aber Sie sollten sie natürlich immer an Ihre eigenen Anforderungen anpassen.
So prüfen Sie Ihre Robots.txt-Datei auf Fehler
In meiner Zeit habe ich in robots.txt-Dateien mehr Fehler mit Auswirkungen auf den Rang gesehen als vielleicht in jedem anderen Aspekt der technischen SEO. Bei so vielen potenziell widersprüchlichen Richtlinien können Probleme auftreten und werden es auch.
Wenn es also um robots.txt-Dateien geht, lohnt es sich, nach Problemen Ausschau zu halten.
Glücklicherweise bietet Ihnen der „Coverage“-Bericht in der Google Search Console eine Möglichkeit, robots.txt-Probleme zu überprüfen und zu überwachen.
Sie können auch das raffinierte Robots.txt-Testtool von Google verwenden, um Ihre Live-Robots-Datei auf Fehler zu überprüfen oder eine neue robots.txt-Datei zu testen, bevor Sie sie bereitstellen.
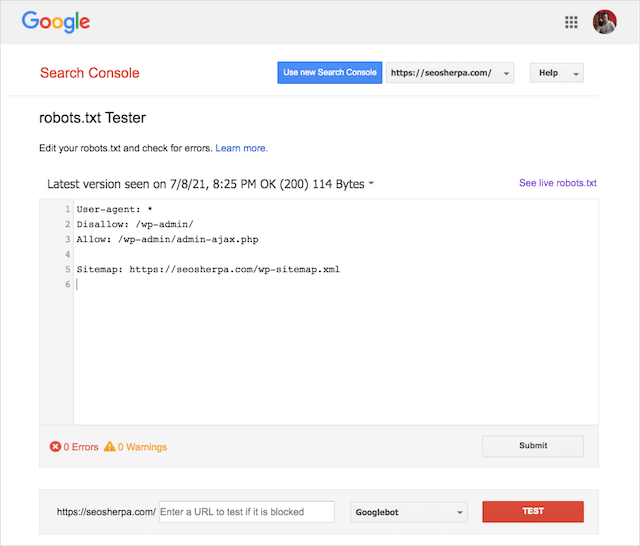
Abschließend behandeln wir die häufigsten Probleme, was sie bedeuten und wie sie behoben werden können.
Eingesendete URL durch robots.txt blockiert
Dieser Fehler bedeutet, dass mindestens eine der URLs in Ihren eingereichten Sitemaps durch robots.txt blockiert wird.

Eine korrekt eingerichtete Sitemap sollte nur die URLs enthalten, die in Suchmaschinen indexiert werden sollen . Daher sollte sie keine nicht-indizierten, kanonisierten oder umgeleiteten Seiten enthalten.
Wenn Sie diese Best Practices befolgt haben, sollten keine in Ihrer Sitemap eingereichten Seiten durch robots.txt blockiert werden.
Wenn Sie im Abdeckungsbericht „Eingereichte URL blockiert durch robots.txt“ sehen, sollten Sie untersuchen, welche Seiten betroffen sind, und dann Ihre robots.txt-Datei ändern, um die Blockierung für diese Seite aufzuheben.
Sie können den robots.txt-Tester von Google verwenden, um zu sehen, welche Richtlinie den Inhalt blockiert.
Von Robots.txt blockiert
Dieser „Fehler“ bedeutet, dass Seiten von Ihrer robots.txt-Datei blockiert wurden, die derzeit nicht im Google-Index enthalten sind.

Wenn dieser Inhalt nützlich ist und indiziert werden sollte, entfernen Sie den Crawl-Block in robots.txt.
Ein kurzes Wort der Warnung:
„Von robots.txt blockiert“ ist nicht unbedingt ein Fehler. Tatsächlich kann es genau das Ergebnis sein, das Sie wollen.
Möglicherweise haben Sie beispielsweise bestimmte Dateien in robots.txt blockiert, um sie aus dem Google-Index auszuschließen. Wenn Sie andererseits das Crawlen bestimmter Seiten mit der Absicht blockiert haben, sie nicht zu indizieren, sollten Sie den Crawl-Block entfernen und stattdessen das Meta-Tag eines Roboters verwenden.
Nur so kann der Ausschluss von Inhalten aus dem Google-Index gewährleistet werden.
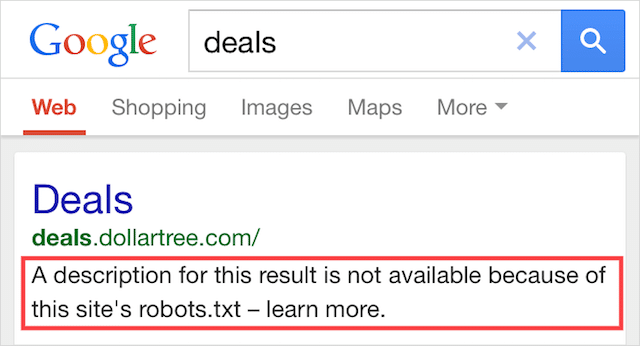
Indiziert, obwohl von Robots.txt blockiert
Dieser Fehler bedeutet, dass einige der von robots.txt blockierten Inhalte immer noch in Google indexiert sind.
Dies geschieht, wenn der Inhalt noch vom Googlebot gefunden werden kann, weil er von einer anderen Stelle im Web verlinkt ist. Kurz gesagt, der Googlebot landet darauf, dass der Inhalt gecrawlt wird, und indiziert ihn dann, bevor er die robots.txt-Datei Ihrer Website besucht, wo er die unzulässige Anweisung sieht.
Bis dahin ist es zu spät. Und es wird indiziert:
Lassen Sie mich dieses nach Hause bohren:
Wenn Sie versuchen, Inhalte aus den Suchergebnissen von Google auszuschließen, ist robots.txt nicht die richtige Lösung.
Ich empfehle, den Crawl-Block zu entfernen und stattdessen ein Meta-Robots-No-Index-Tag zu verwenden, um die Indexierung zu verhindern.
Im Gegenteil, wenn Sie diesen Inhalt versehentlich blockiert haben und ihn im Google-Index behalten möchten, entfernen Sie den Crawl-Block in der robots.txt und belassen Sie es dabei.
Dies kann dazu beitragen, die Sichtbarkeit des Inhalts in der Google-Suche zu verbessern.
Abschließende Gedanken
Robots.txt kann verwendet werden, um das Crawlen und Indizieren des Inhalts Ihrer Website zu verbessern, wodurch Sie in SERPs besser sichtbar werden.
Bei effektiver Verwendung ist es der wichtigste Text auf Ihrer Website. Bei unvorsichtiger Verwendung wird es jedoch zur Achillesferse im Code Ihrer Website.
Die gute Nachricht: Mit nur einem grundlegenden Verständnis von Benutzeragenten und einer Handvoll Anweisungen sind bessere Suchergebnisse in Reichweite.
Die einzige Frage ist, welche Protokolle Sie in Ihrer robots.txt-Datei verwenden werden?
Lass es mich in den Kommentaren unten wissen.