
Robots.txt: ostateczny przewodnik po SEO (edycja 2021)
Opublikowany: 2021-06-10 Dzisiaj dowiesz się, jak stworzyć jeden z najważniejszych plików dla SEO witryny:
Dzisiaj dowiesz się, jak stworzyć jeden z najważniejszych plików dla SEO witryny:
(Plik robots.txt).
W szczególności pokażę Ci, jak używać protokołów wykluczania robotów, aby blokować boty z określonych stron, zwiększać częstotliwość indeksowania, optymalizować budżet indeksowania i ostatecznie uzyskać więcej pozycji w rankingu odpowiedniej strony w SERP.
Zajmuję się:
- Czym jest plik robots.txt
- Dlaczego plik robots.txt jest ważny
- Jak działa robots.txt
- Klienty użytkownika i dyrektywy robots.txt
- Robots.txt kontra roboty meta
- Jak znaleźć plik robots.txt
- Tworzenie pliku robots.txt
- Najlepsze praktyki dotyczące pliku robots.txt
- Przykłady robots.txt
- Jak skontrolować plik robots.txt pod kątem błędów
Plus o wiele więcej. Zanurzmy się od razu.
Co to jest plik Robots.txt? I dlaczego go potrzebujesz?
Mówiąc prościej, plik robots.txt to instrukcja obsługi robotów internetowych.
Informuje boty wszystkich typów, które sekcje witryny powinny (a nie powinny) indeksować.
To powiedziawszy, plik robots.txt jest używany przede wszystkim jako „kodeks postępowania” do kontrolowania aktywności robotów wyszukiwarek (ang. web crawlery).

Plik robots.txt jest regularnie sprawdzany przez każdą większą wyszukiwarkę (w tym Google, Bing i Yahoo) w celu uzyskania instrukcji dotyczących sposobu indeksowania witryny. Te instrukcje są znane jako dyrektywy .
Jeśli nie ma żadnych dyrektyw – lub pliku robots.txt – wyszukiwarki będą indeksować całą witrynę, strony prywatne i wszystko.
Chociaż większość wyszukiwarek jest posłuszna, należy pamiętać, że przestrzeganie dyrektyw robots.txt jest opcjonalne. Jeśli zechcą, wyszukiwarki mogą zignorować plik robots.txt.
Na szczęście Google nie jest jedną z tych wyszukiwarek. Google ma tendencję do przestrzegania instrukcji zawartych w pliku robots.txt.
Dlaczego plik Robots.txt jest ważny?
Posiadanie pliku robots.txt nie ma kluczowego znaczenia dla wielu witryn, zwłaszcza małych.
Dzieje się tak, ponieważ Google zazwyczaj może znaleźć i zaindeksować wszystkie najważniejsze strony w witrynie.
I automatycznie NIE będą indeksować zduplikowanych treści ani stron, które są nieistotne.
Ale nadal nie ma dobrego powodu, aby nie mieć pliku robots.txt – więc polecam go mieć.
Plik robots.txt zapewnia większą kontrolę nad tym, co wyszukiwarki mogą, a czego nie mogą indeksować w Twojej witrynie. Jest to przydatne z kilku powodów:
Umożliwia blokowanie stron niepublicznych w wyszukiwarkach
Czasami masz w swojej witrynie strony, których nie chcesz indeksować.
Na przykład możesz tworzyć nową witrynę internetową w środowisku pomostowym, które chcesz mieć pewność, że jest ukryte przed użytkownikami do czasu uruchomienia.
Lub możesz mieć strony logowania do witryny, których nie chcesz wyświetlać w SERP.
W takim przypadku możesz użyć pliku robots.txt, aby zablokować te strony przed robotami wyszukiwarek.
Kontroluje budżet indeksowania wyszukiwarek
Jeśli masz trudności z zaindeksowaniem wszystkich stron w wyszukiwarkach, możesz mieć problem z budżetem indeksowania.
Mówiąc najprościej, wyszukiwarki wykorzystują czas przeznaczony na indeksowanie treści na stronach obciążających Twoją witrynę.

Blokując mało użyteczne adresy URL za pomocą pliku robots.txt, roboty wyszukiwarek mogą wydać większą część swojego budżetu na indeksowanie na stronach, które mają największe znaczenie.
Zapobiega indeksowaniu zasobów
Najlepszą praktyką jest użycie metadyrektywy „no-index”, aby uniemożliwić indeksowanie poszczególnych stron.
Problem polega na tym, że metadyrektywy nie działają dobrze w przypadku zasobów multimedialnych, takich jak pliki PDF i dokumenty Word.
Tutaj przydaje się plik robots.txt.
Możesz dodać prostą linię tekstu do pliku robots.txt, a wyszukiwarki nie będą miały dostępu do tych plików multimedialnych.
(Pokażę ci dokładnie, jak to zrobić w dalszej części tego postu)
Jak (dokładnie) działa plik Robots.txt?
Jak już wspomniałem, plik robots.txt pełni rolę instrukcji obsługi robotów wyszukiwarek. Mówi botom wyszukiwania, gdzie (i gdzie nie) powinny się czołgać.
Właśnie dlatego robot wyszukiwania będzie szukać pliku robots.txt, gdy tylko dotrze do witryny.
Jeśli znajdzie plik robots.txt, robot przeczyta go najpierw przed kontynuowaniem indeksowania witryny.
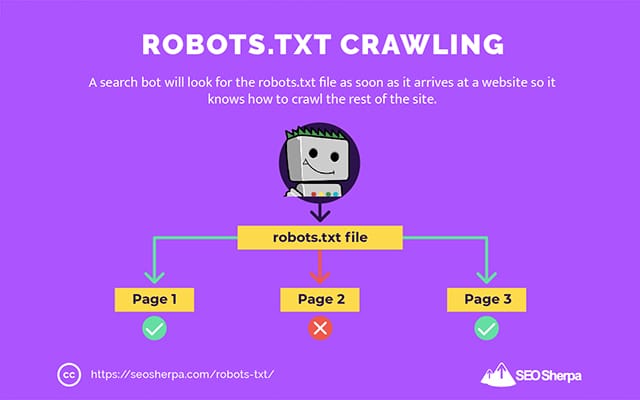
Jeśli robot indeksujący nie znajdzie pliku robots.txt lub plik nie zawiera dyrektyw, które uniemożliwiają działanie robotów wyszukiwania, robot będzie kontynuował przeszukiwanie całej witryny w zwykły sposób.
Aby plik robots.txt był możliwy do znalezienia i odczytany przez roboty wyszukujące, plik robots.txt jest formatowany w bardzo szczególny sposób.
Po pierwsze, jest to plik tekstowy bez kodu znaczników HTML (stąd rozszerzenie .txt).
Po drugie, zostaje umieszczony w folderze głównym witryny, np. https://seosherpa.com/robots.txt.
Po trzecie, używa standardowej składni, która jest wspólna dla wszystkich plików robots.txt, na przykład:
Sitemap: [URL location of sitemap] User-agent: [bot identifier] [directive 1] [directive 2] [directive ...] User-agent: [another bot identifier] [directive 1] [directive 2] [directive ...]Ta składnia może na pierwszy rzut oka wydawać się zniechęcająca, ale w rzeczywistości jest dość prosta.
W skrócie, definiujesz bota (agenta użytkownika), do którego odnoszą się instrukcje, a następnie określasz zasady (dyrektywy), których bot powinien przestrzegać.
Przyjrzyjmy się tym dwóm komponentom bardziej szczegółowo.
Agenty użytkownika
Klient użytkownika to nazwa używana do definiowania określonych robotów sieciowych – i innych programów aktywnych w Internecie.
Istnieją dosłownie setki agentów użytkownika, w tym agenty dla typów urządzeń i przeglądarek.
Większość z nich nie ma znaczenia w kontekście pliku robots.txt i SEO. Z drugiej strony powinieneś wiedzieć:
- Google: Googlebot
- Grafika Google: Googlebot-Obraz
- Google Video: Googlebot-Video
- Wiadomości Google: Googlebot-Wiadomości
- Bing: Bingbot
- Obrazy i filmy Bing: MSNBot-Media
- Yahoo: Slurp
- Yandex: YandexBot
- Baidu : Baiduspider
- DuckDuckGo: DuckDuckBot
Określając agenta użytkownika, możesz ustawić różne reguły dla różnych wyszukiwarek.

Na przykład, jeśli chcesz, aby dana strona wyświetlała się w wynikach wyszukiwania Google, ale nie w wyszukiwaniu Baidu, możesz umieścić dwa zestawy poleceń w pliku robots.txt: jeden zestaw poprzedzony przez „User-agent: Bingbot” i jeden zestaw poprzedzony przez „Agent użytkownika: Baiduspider”.
Możesz również użyć symbolu wieloznacznego gwiazdki (*), jeśli chcesz, aby dyrektywy miały zastosowanie do wszystkich programów użytkownika.
Załóżmy na przykład, że chcesz zablokować indeksowanie Twojej witryny wszystkim robotom wyszukiwarek oprócz DuckDuckGo. Oto jak możesz to zrobić:
User-agent: * Disallow: / User-agent: DuckDuckBot Allow: /Uwaga dodatkowa: jeśli w pliku robots.txt znajdują się sprzeczne polecenia, bot zastosuje się do bardziej szczegółowego polecenia.
Dlatego w powyższym przykładzie DuckDuckBot wie, jak indeksować witrynę, mimo że poprzednia dyrektywa (dotycząca wszystkich botów) mówiła, że nie należy indeksować. Krótko mówiąc, bot będzie postępować zgodnie z instrukcją, która najdokładniej ich dotyczy.
Dyrektywy
Dyrektywy to kodeks postępowania, którego ma przestrzegać klient użytkownika. Innymi słowy, dyrektywy określają, w jaki sposób robot wyszukiwania powinien indeksować Twoją witrynę.
Oto dyrektywy obsługiwane obecnie przez GoogleBot wraz z ich zastosowaniem w pliku robots.txt:
Uniemożliwić
Użyj tej dyrektywy, aby uniemożliwić botom wyszukiwania indeksowanie określonych plików i stron w określonej ścieżce adresu URL.

Na przykład, jeśli chcesz zablokować GoogleBotowi dostęp do Twojej wiki i wszystkich jej stron, Twój robots.txt powinien zawierać następującą dyrektywę:
User-agent: GoogleBot Disallow: /wikiMożesz użyć dyrektywy disallow, aby zablokować indeksowanie dokładnego adresu URL, wszystkich plików i stron w określonym katalogu, a nawet całej witryny.
Umożliwić
Dyrektywa allow jest przydatna, jeśli chcesz zezwolić wyszukiwarkom na indeksowanie określonego podkatalogu lub strony – w sekcji witryny, która w przeciwnym razie jest niedozwolona.

Załóżmy, że chcesz uniemożliwić wszystkim wyszukiwarkom indeksowanie postów na Twoim blogu z wyjątkiem jednego; wtedy użyjesz dyrektywy allow w ten sposób:
User-agent: * Disallow: /blog Allow: /blog/allowable-postPonieważ roboty wyszukujące zawsze postępują zgodnie z najbardziej szczegółowymi instrukcjami podanymi w pliku robots.txt, wiedzą, że mają indeksować /blog/allowable-post, ale nie będą indeksować innych postów lub plików w tym katalogu, takich jak;
- /blog/post-one/
- /blog/post-drugi/
- /blog/nazwa-pliku.pdf
Zarówno Google, jak i Bing wspierają tę dyrektywę. Ale inne wyszukiwarki nie.
Mapa strony
Dyrektywa sitemap służy do określania lokalizacji map witryn XML w wyszukiwarkach.
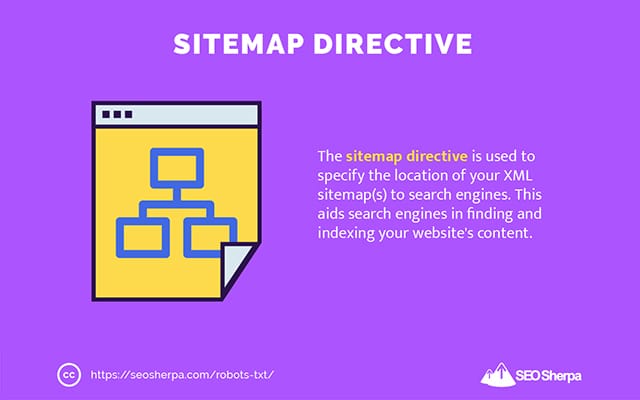
Jeśli nie masz doświadczenia z mapami witryn, są one używane do wyświetlania listy stron, które chcesz zindeksować i zaindeksować w wyszukiwarkach.
Umieszczając dyrektywę sitemap w pliku robots.txt, pomagasz wyszukiwarkom znaleźć mapę witryny, a następnie przeszukać i zindeksować najważniejsze strony witryny.
Mając to na uwadze, jeśli już przesłałeś swoją mapę witryny XML za pomocą Search Console, dodanie mapy witryny w robots.txt jest nieco zbędne dla Google. Mimo to najlepszą praktyką jest użycie dyrektywy sitemap, ponieważ informuje ona wyszukiwarki, takie jak Ask, Bing i Yahoo, gdzie można znaleźć mapy witryny.
Oto przykład pliku robots.txt wykorzystującego dyrektywę sitemap:
Sitemap: https://www.website.com/sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/Zwróć uwagę na umieszczenie dyrektywy sitemap w pliku robots.txt. Najlepiej umieścić go na samej górze pliku robots.txt. Można go również umieścić na dole.
Jeśli masz wiele map witryn, umieść je wszystkie w pliku robots.txt. Oto jak mógłby wyglądać plik robots.txt, gdybyśmy mieli oddzielne mapy witryn XML dla stron i postów:
Sitemap: http://website.com/post-sitemap.xml Sitemap: http://website.com/page-sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/Tak czy inaczej, wystarczy wspomnieć o każdej mapie witryny XML tylko raz, ponieważ wszystkie obsługiwane klienty użytkownika będą przestrzegać dyrektywy.
Pamiętaj, że w przeciwieństwie do innych dyrektyw w pliku robots.txt, które zawierają listę ścieżek, dyrektywa sitemap musi zawierać bezwzględny adres URL mapy witryny XML, w tym protokół, nazwę domeny i rozszerzenie domeny najwyższego poziomu.
Uwagi
Komentarz „dyrektywa” jest przydatny dla ludzi, ale nie jest używany przez roboty wyszukujące.

Możesz dodać komentarze, aby przypomnieć, dlaczego istnieją określone dyrektywy, lub uniemożliwić osobom mającym dostęp do pliku robots.txt usuwanie ważnych dyrektyw. W skrócie, komentarze służą do dodawania notatek do pliku robots.txt.
Aby dodać komentarz, wpisz.” #" , po którym następuje tekst komentarza.
# Don't allow access to the /wp-admin/ directory for all robots. User-agent: * Disallow: /wp-admin/Możesz dodać komentarz na początku wiersza (jak pokazano powyżej) lub po dyrektywie w tym samym wierszu (jak pokazano poniżej):
User-agent: * #Applies to all robots Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.Gdziekolwiek zdecydujesz się napisać swój komentarz, wszystko po hashu zostanie zignorowane.
Śledzisz do tej pory?
Świetny! Omówiliśmy teraz główne dyrektywy, których będziesz potrzebować w pliku robots.txt — są to również jedyne dyrektywy obsługiwane przez Google.
Ale co z innymi wyszukiwarkami? W przypadku Bing, Yahoo i Yandex jest jeszcze jedna dyrektywa, której możesz użyć:
Opóźnienie indeksowania
Dyrektywa Crawl-delay to nieoficjalna dyrektywa używana do zapobiegania przeciążaniu serwerów zbyt dużą liczbą żądań indeksowania.
Innymi słowy, używasz go do ograniczenia częstotliwości indeksowania Twojej witryny przez wyszukiwarkę.

Pamiętaj, że jeśli wyszukiwarki mogą przeciążać Twój serwer, często indeksując Twoją witrynę, dodanie dyrektywy Crawl-delay do pliku robots.txt rozwiąże problem tylko tymczasowo.
Może tak być, że Twoja witryna działa na kiepskim hostingu lub źle skonfigurowanym środowisku hostingowym i to jest coś, co powinieneś szybko naprawić.
Dyrektywa o opóźnieniu indeksowania działa poprzez zdefiniowanie czasu w sekundach, w jakim robot wyszukiwania może indeksować Twoją witrynę.
Na przykład, jeśli ustawisz opóźnienie indeksowania na 5, boty wyszukiwania podzielą dzień na pięciosekundowe okna, indeksując tylko jedną stronę (lub żadną) w każdym oknie, maksymalnie dla około 17 280 adresów URL w ciągu dnia.
W związku z tym zachowaj ostrożność podczas ustawiania tej dyrektywy, zwłaszcza jeśli masz dużą witrynę internetową. Tylko 17 280 adresów URL indeksowanych dziennie nie jest zbyt pomocne, jeśli Twoja witryna ma miliony stron.
Sposób, w jaki każda wyszukiwarka obsługuje dyrektywę o opóźnieniu indeksowania, jest różny. Podzielmy to poniżej:
Opóźnienie indeksowania i Bing, Yahoo i Yandex
Bing, Yahoo i Yandex obsługują dyrektywę crawl-delay w pliku robots.txt.
Oznacza to, że możesz ustawić dyrektywę opóźnienia indeksowania dla agentów użytkownika BingBot, Slurp i YandexBot, a wyszukiwarka odpowiednio ograniczy indeksowanie.
Pamiętaj, że każda wyszukiwarka interpretuje opóźnienie indeksowania w nieco inny sposób, więc koniecznie sprawdź ich dokumentację:
- Bing i Yahoo
- Yandex
To powiedziawszy, format dyrektywy crawl-delay dla każdego z tych silników jest taki sam. Musisz umieścić go zaraz po dyrektywie disallow OR allow. Oto przykład:
User-agent: BingBot Allow: /widgets/ Crawl-delay: 5Opóźnienie indeksowania i Google
Robot Google nie obsługuje dyrektywy o opóźnieniu indeksowania, więc ustawianie opóźnienia indeksowania dla robota GoogleBot w pliku robots.txt nie ma sensu.
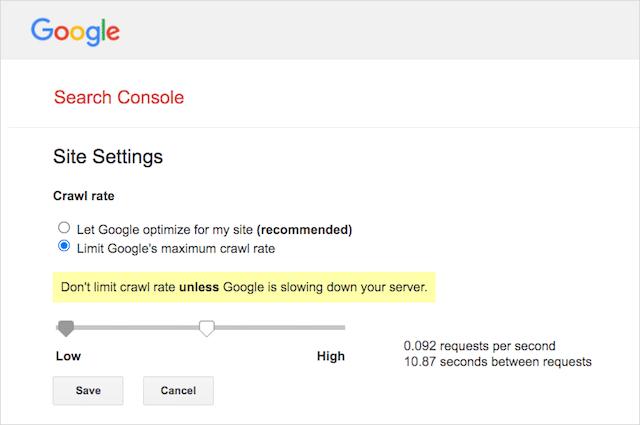
Jednak Google obsługuje definiowanie szybkości indeksowania w Google Search Console. Oto jak to zrobić:
- Przejdź do strony ustawień Google Search Console.
- Wybierz właściwość, dla której chcesz zdefiniować szybkość indeksowania
- Kliknij „Ogranicz maksymalną szybkość indeksowania Google”.
- Dostosuj suwak do preferowanej szybkości indeksowania. Domyślnie szybkość indeksowania ma ustawienie „Pozwól Google optymalizować dla mojej witryny (zalecane)”.
Opóźnienie indeksowania i Baidu
Podobnie jak Google, Baidu nie obsługuje dyrektywy o opóźnieniu indeksowania. Istnieje jednak możliwość zarejestrowania konta Baidu Webmaster Tools, w którym możesz kontrolować częstotliwość indeksowania, podobnie jak w Google Search Console.
Konkluzja? Plik robots.txt informuje roboty-pająki wyszukiwarek, aby nie indeksowały określonych stron w Twojej witrynie.
Robots.txt vs roboty meta vs roboty x
Istnieje wiele instrukcji dla „robotów”. Jakie są różnice, czy są takie same?
Pozwólcie, że przedstawię krótkie wyjaśnienie:
Po pierwsze, robots.txt to rzeczywisty plik tekstowy, podczas gdy meta i x-robots to tagi w kodzie strony internetowej.
Po drugie, plik robots.txt daje botom sugestie , jak indeksować strony witryny. Z drugiej strony metadyrektywy robotów zapewniają bardzo dokładne instrukcje dotyczące przeszukiwania i indeksowania zawartości strony.
Poza tym, czym są, wszystkie trzy pełnią różne funkcje.
Robots.txt dyktuje zachowanie indeksowania witryny lub całego katalogu, podczas gdy meta i x-robots mogą dyktować zachowanie indeksowania na poziomie pojedynczej strony (lub elementu strony).

Ogólnie:
Jeśli chcesz zatrzymać indeksowanie strony, użyj metatagu robots „no-index”. Zablokowanie strony w robots.txt nie gwarantuje, że nie zostanie ona wyświetlona w wyszukiwarkach (w końcu dyrektywy robots.txt są sugestiami). Ponadto robot wyszukiwarki może nadal znaleźć ten adres URL i zaindeksować go, jeśli jest do niego link z innej witryny.

Wręcz przeciwnie, jeśli chcesz zatrzymać indeksowanie pliku multimedialnego, najlepszym rozwiązaniem jest plik robots.txt. Nie można dodawać znaczników meta robots do plików takich jak jpeg lub PDF.
Jak znaleźć swój robots.txt
Jeśli masz już plik robots.txt w swojej witrynie, możesz uzyskać do niego dostęp pod adresem twojadomena.com/robots.txt.
Przejdź do adresu URL w przeglądarce.
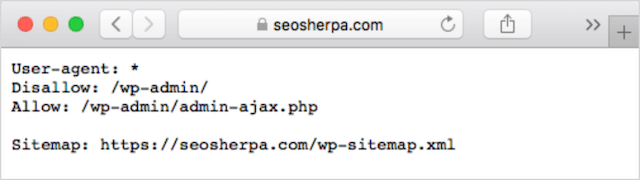
Jeśli widzisz stronę opartą na tekście, taką jak ta powyżej, oznacza to, że masz plik robots.txt.
Jak utworzyć plik Robots.txt
Jeśli nie masz jeszcze pliku robots.txt, utworzenie go jest proste.
Najpierw otwórz Notatnik, Microsoft Word lub dowolny edytor tekstu i zapisz plik jako „roboty”.
Upewnij się, że używasz małych liter i jako rozszerzenie typu pliku wybierz .txt:

Po drugie, dodaj swoje dyrektywy. Na przykład, jeśli chcesz uniemożliwić wszystkim robotom wyszukiwania indeksowanie twojego katalogu /login/, wpisz:
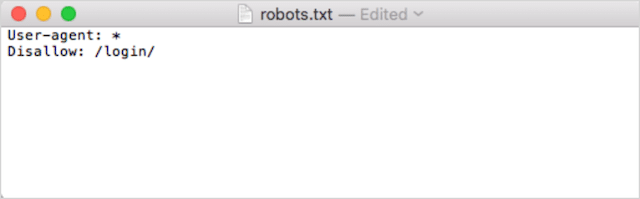
Kontynuuj dodawanie dyrektyw, aż będziesz zadowolony z pliku robots.txt.
Alternatywnie możesz wygenerować plik robots.txt za pomocą narzędzia takiego jak to z Ryte.

Jedną z zalet korzystania z narzędzia jest minimalizacja błędu ludzkiego.
Tylko jeden mały błąd w składni pliku robots.txt może zakończyć się katastrofą SEO.
To powiedziawszy, wadą korzystania z generatora robots.txt jest to, że możliwość dostosowania jest minimalna.
Dlatego polecam nauczyć się samodzielnego pisania pliku robot.txt. Następnie możesz utworzyć plik robots.txt dokładnie według swoich wymagań.
Gdzie umieścić plik Robots.txt
Dodaj plik robots.txt w katalogu najwyższego poziomu subdomeny, której dotyczy.
Aby na przykład kontrolować zachowanie indeksowania w witrynie twojadomena.com , plik robots.txt powinien być dostępny w ścieżce adresu URL twojadomena.com/robots.txt .
Z drugiej strony, jeśli chcesz kontrolować indeksowanie w subdomenie, takiej jak sklep.twojadomena.com , plik robots.txt powinien być dostępny w ścieżce URL shop.twojadomena.com/robots.txt .
Złote zasady to:
- Nadaj każdej subdomenie w swojej witrynie własny plik robots.txt.
- Nazwij swoje pliki robots.txt małymi literami.
- Umieść plik w katalogu głównym subdomeny, do której się odwołuje.
Jeśli pliku robots.txt nie można znaleźć w katalogu głównym, wyszukiwarki założą, że nie ma żadnych dyrektyw, i zaindeksują całą witrynę.
Najlepsze praktyki dotyczące pliku robots.txt
Omówmy teraz zasady plików robots.txt. Skorzystaj z tych sprawdzonych metod, aby uniknąć typowych pułapek w pliku robots.txt:
Użyj nowej linii dla każdej dyrektywy
Każda dyrektywa w pliku robots.txt musi znajdować się w nowym wierszu.
Jeśli nie, wyszukiwarki nie będą wiedziały, co indeksować (i indeksować).
To na przykład jest nieprawidłowo skonfigurowane:
User-agent: * Disallow: /folder/ Disallow: /another-folder/Z drugiej strony jest to poprawnie skonfigurowany plik robots.txt:
User-agent: * Disallow: /folder/ Disallow: /another-folder/Specyfika „prawie” zawsze wygrywa
Jeśli chodzi o Google i Bing, wygrywa bardziej szczegółowa dyrektywa.
Na przykład ta dyrektywa Allow wygrywa z dyrektywą Disallow, ponieważ jej długość w znakach jest dłuższa.
User-agent: * Disallow: /about/ Allow: /about/company/Google i Bing wiedzą, że indeksują /about/company/, ale nie mogą indeksować żadnych innych stron w katalogu /about/.
Jednak w przypadku innych wyszukiwarek jest odwrotnie.
Domyślnie we wszystkich głównych wyszukiwarkach innych niż Google i Bing zawsze wygrywa pierwsza pasująca dyrektywa .
W powyższym przykładzie wyszukiwarki zastosują się do dyrektywy Disallow i zignorują dyrektywę Allow, co oznacza, że strona /about/company nie zostanie przeszukana.
Pamiętaj o tym podczas tworzenia reguł dla wszystkich wyszukiwarek.
Tylko jedna grupa dyrektyw na klienta użytkownika
Jeśli Twój plik robots.txt zawiera wiele grup dyrektyw na klienta użytkownika, boh-oh-boy, czy może to być mylące?
Niekoniecznie dla robotów, bo połączą wszystkie zasady z różnych deklaracji w jedną grupę i będą przestrzegać wszystkich, ale dla Ciebie.
Aby uniknąć potencjalnego błędu ludzkiego, określ klienta użytkownika raz, a następnie wymień wszystkie dyrektywy, które mają zastosowanie do tego klienta użytkownika poniżej.

Utrzymując porządek i prostotę, jest mniej prawdopodobne, że popełnisz błąd.
Użyj symboli wieloznacznych (*), aby uprościć instrukcje
Czy zauważyłeś symbole wieloznaczne (*) w powyższym przykładzie?
Zgadza się; możesz użyć symboli wieloznacznych (*), aby zastosować reguły do wszystkich klientów użytkownika ORAZ dopasować wzorce adresów URL podczas deklarowania dyrektyw.
Na przykład, jeśli chcesz uniemożliwić botom wyszukiwania dostęp do sparametryzowanych adresów URL kategorii produktów w Twojej witrynie, możesz wymienić każdą kategorię w następujący sposób:
User-agent: * Disallow: /products/watches? Disallow: /products/handbags? Disallow: /products/shoes?Możesz też użyć symbolu wieloznacznego, który zastosowałby regułę do wszystkich kategorii. Oto jak by to wyglądało:
User-agent: * Disallow: /products/*?Ten przykład blokuje wyszukiwarkom możliwość indeksowania wszystkich adresów URL w podfolderze /product/, które zawierają znak zapytania. Innymi słowy, dowolne adresy URL kategorii produktów, które są sparametryzowane.
Google, Bing, Yahoo obsługują użycie symboli wieloznacznych w dyrektywach robots.txt i Ask.
Użyj „$”, aby określić koniec adresu URL
Aby wskazać koniec adresu URL, użyj znaku dolara ( $ ) po ścieżce pliku robots.txt.
Załóżmy, że chcesz uniemożliwić botom wyszukiwania dostęp do wszystkich plików .doc w Twojej witrynie; wtedy skorzystałbyś z tej dyrektywy:
User-agent: * Disallow: /*.doc$Uniemożliwiłoby to wyszukiwarkom dostęp do adresów URL kończących się na .doc.
Oznacza to, że nie będą indeksować /media/file.doc, ale będą indeksować /media/file.doc?id=72491, ponieważ ten adres URL nie kończy się na „.doc”.
Każda subdomena otrzymuje swój własny plik robots.txt
Dyrektywy robots.txt dotyczą tylko (pod)domeny, w której znajduje się plik robots.txt.
Oznacza to, że Twoja witryna ma wiele subdomen, takich jak:
- domena.com
- bilety.domena.com
- wydarzenia.domena.com
Każda subdomena będzie wymagała własnego pliku robots.txt.
Plik robots.txt należy zawsze dodawać w katalogu głównym każdej subdomeny. Oto jak wyglądałyby ścieżki w powyższym przykładzie:
- domena.com/robots.txt
- bilety.domena.com/robots.txt
- wydarzenia.domena.com/robots.txt
Nie używaj noindex w pliku robots.txt
Mówiąc najprościej, Google nie obsługuje dyrektywy o braku indeksu w pliku robots.txt.
Chociaż Google podążał za nim w przeszłości, od lipca 2019 r. Google przestał całkowicie go wspierać.
A jeśli myślisz o użyciu dyrektywy bez indeksu robots.txt do treści bez indeksowania w innych wyszukiwarkach, pomyśl jeszcze raz:
Nieoficjalna dyrektywa o braku indeksu nigdy nie działała w Bing.
Zdecydowanie najlepszą metodą na brak indeksowania treści w wyszukiwarkach jest zastosowanie metatagu robots bez indeksowania do strony, którą chcesz wykluczyć.
Zachowaj plik robots.txt poniżej 512 KB
Google ma obecnie limit rozmiaru pliku robots.txt wynoszący 500 kibibajtów (512 kilobajtów).
Oznacza to, że każda zawartość po 512 KB może zostać zignorowana.

To powiedziawszy, biorąc pod uwagę, że jeden znak zużywa tylko jeden bajt, twój robots.txt musiałby być OGROMNY, aby osiągnąć ten limit rozmiaru pliku (dokładnie 512,000 znaków). Zachowaj szczupłość pliku robots.txt, skupiając się mniej na poszczególnych wykluczonych stronach, a bardziej na szerszych wzorcach, które mogą kontrolować symbole wieloznaczne.
Nie jest jasne, czy inne wyszukiwarki mają maksymalny dozwolony rozmiar pliku robots.txt.
Przykłady pliku robots.txt
Poniżej znajduje się kilka przykładów plików robots.txt.
Zawierają one kombinacje dyrektyw, których nasza agencja SEO najczęściej używa w plikach robots.txt dla klientów. Pamiętaj jednak; służą one wyłącznie do celów inspiracyjnych. Zawsze musisz dostosować plik robots.txt do swoich wymagań.
Zezwól wszystkim robotom na dostęp do wszystkiego
Ten plik robots.txt nie zawiera reguł zakazu dla wszystkich wyszukiwarek:
User-agent: * Disallow:Innymi słowy, umożliwia robotom wyszukiwania indeksowanie wszystkiego. Służy temu samemu celowi, co pusty plik robots.txt lub w ogóle brak pliku robots.txt.
Zablokuj wszystkim robotom dostęp do wszystkiego
Przykładowy plik robots.txt mówi wszystkim wyszukiwarkom, aby nie uzyskiwały dostępu do niczego po końcowym ukośniku. Innymi słowy, cała domena:
User-agent: * Disallow: /Krótko mówiąc, ten plik robots.txt blokuje wszystkie roboty wyszukiwarek i może uniemożliwić wyświetlanie Twojej witryny na stronach wyników wyszukiwania.
Zablokuj wszystkim robotom indeksowanie jednego pliku
W tym przykładzie blokujemy wszystkie boty wyszukiwania przed indeksowaniem określonego pliku.
User-agent: * Disallow: /directory/this-is-a-file.pdfZablokuj wszystkim robotom indeksowanie plików jednego typu (doc, pdf, jpg)
Ponieważ nie ma indeksowania, plik taki jak „doc” lub „pdf” nie może być wykonany przy użyciu metatagu robota „no-index”; możesz użyć następującej dyrektywy, aby zatrzymać indeksowanie określonego typu pliku.
User-agent: * Disallow: /*.doc$ Disallow: /*.pdf$ Disallow: /*.jpg$To zadziała w przypadku deindeksowania wszystkich plików tego typu, o ile żaden pojedynczy plik nie jest połączony z innym miejscem w sieci.
Zablokuj Googleowi indeksowanie wielu katalogów
Możesz zablokować indeksowanie wielu katalogów dla konkretnego bota lub wszystkich botów. W tym przykładzie blokujemy Googlebotowi indeksowanie dwóch podkatalogów.
User-agent: Googlebot Disallow: /admin/ Disallow: /private/Pamiętaj, że nie ma ograniczeń co do liczby katalogów, których możesz użyć. Wystarczy wymienić każdy z nich poniżej agenta użytkownika, którego dotyczy dyrektywa.
Zablokuj Google indeksowanie wszystkich sparametryzowanych adresów URL
Ta dyrektywa jest szczególnie przydatna w przypadku witryn korzystających z nawigacji aspektowej, gdzie można utworzyć wiele sparametryzowanych adresów URL.
User-agent: Googlebot Disallow: /*?Ta dyrektywa zapobiega wykorzystywaniu budżetu indeksowania na dynamiczne adresy URL i maksymalizuje indeksowanie ważnych stron. Używam go regularnie, szczególnie w witrynach e-commerce z funkcją wyszukiwania.
Zablokuj wszystkim botom indeksowanie jednego podkatalogu, ale zezwól na indeksowanie jednej strony w nim
Czasami możesz chcieć zablokować robotom indeksującym dostęp do całej sekcji witryny, ale pozostawić dostęp do jednej strony. Jeśli tak, użyj następującej kombinacji dyrektyw „allow” i „disallow”:
User-agent: * Disallow: /category/ Allow: /category/widget/Mówi wyszukiwarkom, aby nie indeksowały całego katalogu, z wyjątkiem jednej konkretnej strony lub pliku.
Robots.txt dla WordPress
To jest podstawowa konfiguracja, którą polecam dla pliku robots.txt WordPress. Blokuje indeksowanie stron administracyjnych i tagów oraz adresów URL autorów, co może tworzyć niepotrzebne cruft w witrynie WordPress.
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /wp-admin/ Disallow: /readme.html Disallow: /refer/ Disallow: /tag/ Disallow: /author/ Disallow: /404-error/ Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xmlTen plik robots.txt będzie działał dobrze na większości stron WordPress, ale oczywiście zawsze powinieneś dostosować go do własnych wymagań.
Jak skontrolować plik Robots.txt pod kątem błędów
W swoim czasie widziałem więcej błędów wpływających na ranking w plikach robots.txt niż być może w jakimkolwiek innym aspekcie technicznego SEO. Przy tak wielu potencjalnie sprzecznych dyrektywach problemy mogą i występują.
Tak więc, jeśli chodzi o pliki robots.txt, opłaca się zwracać uwagę na problemy.
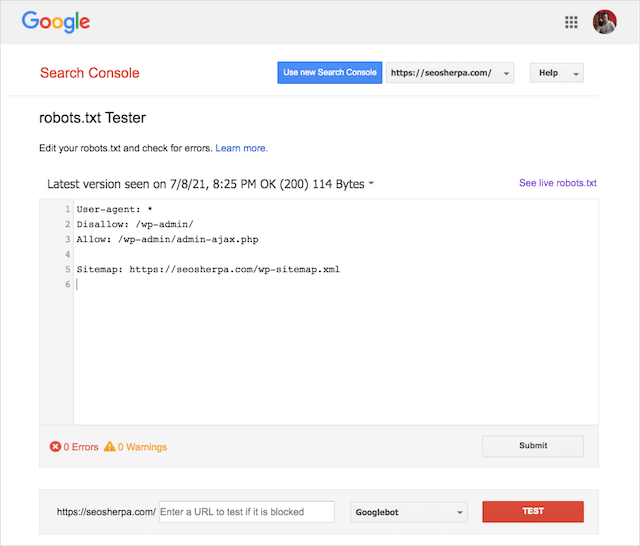
Na szczęście raport „Pokrycie” w Google Search Console umożliwia sprawdzenie i monitorowanie problemów z plikiem robots.txt.
Możesz także użyć sprytnego narzędzia Google do testowania pliku robots.txt, aby sprawdzić błędy w aktywnym pliku robots lub przetestować nowy plik robots.txt przed jego wdrożeniem.
Na koniec omówimy najczęstsze problemy, ich znaczenie i sposoby ich rozwiązania.
Przesłany adres URL zablokowany przez plik robots.txt
Ten błąd oznacza, że co najmniej jeden z adresów URL w przesłanych mapach witryn jest blokowany przez plik robots.txt.

Poprawnie skonfigurowana mapa witryny powinna zawierać tylko adresy URL, które mają być indeksowane w wyszukiwarkach . W związku z tym nie powinien zawierać żadnych stron nieindeksowanych, kanonizowanych ani przekierowywanych.
Jeśli postępujesz zgodnie z tymi sprawdzonymi metodami, żadne strony przesłane w mapie witryny nie powinny być blokowane przez plik robots.txt.
Jeśli w raporcie pokrycia zobaczysz komunikat „Przesłany adres URL zablokowany przez plik robots.txt”, sprawdź, których stron dotyczy problem, a następnie zmień plik robots.txt, aby usunąć blokadę dla tej strony.
Możesz użyć testera robots.txt Google, aby sprawdzić, która dyrektywa blokuje treść.
Zablokowany przez Robots.txt
Ten „błąd” oznacza, że masz strony zablokowane przez plik robots.txt, których obecnie nie ma w indeksie Google.

Jeśli ta treść jest przydatna i powinna być zindeksowana, usuń blokadę indeksowania z pliku robots.txt.
Krótkie słowo ostrzeżenia:
„Zablokowany przez plik robots.txt” niekoniecznie jest błędem. W rzeczywistości może to być dokładnie taki wynik, jakiego oczekujesz.
Na przykład mogłeś zablokować określone pliki w robots.txt, aby wykluczyć je z indeksu Google. Z drugiej strony, jeśli zablokowałeś indeksowanie niektórych stron z zamiarem nieindeksowania ich, rozważ usunięcie blokady indeksowania i zamiast tego użyj metatagu robota.
Tylko w ten sposób można zagwarantować wykluczenie treści z indeksu Google.
Zindeksowany, choć zablokowany przez Robots.txt
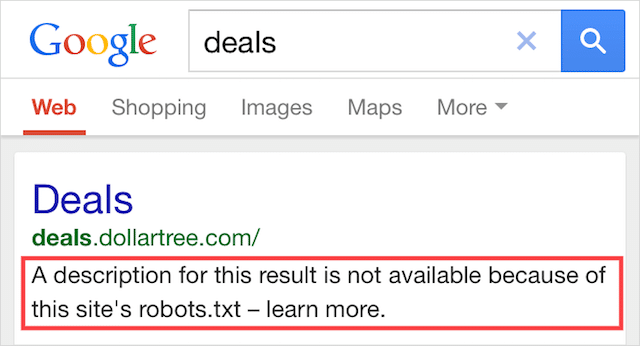
Ten błąd oznacza, że część treści zablokowanych przez plik robots.txt jest nadal indeksowana w Google.
Dzieje się tak, gdy treść jest nadal wykrywalna przez Googlebota, ponieważ prowadzi do niej link z innego miejsca w sieci. Krótko mówiąc, Googlebot ląduje na tej treści, która ją przeszukuje, a następnie indeksuje ją przed odwiedzeniem pliku robots.txt Twojej witryny, w którym widzi niedozwoloną dyrektywę.
Do tego czasu jest już za późno. I zostaje zindeksowany:
Pozwól mi wywiercić ten dom:
Jeśli próbujesz wykluczyć treść z wyników wyszukiwania Google, plik robots.txt nie jest właściwym rozwiązaniem.
Zalecam usunięcie blokady indeksowania i użycie metatagu robots no-index, aby zapobiec indeksowaniu.
Wręcz przeciwnie, jeśli przypadkowo zablokowałeś tę treść i chcesz zachować ją w indeksie Google, usuń blokadę indeksowania w robots.txt i zostaw ją na tym.
Może to pomóc w poprawie widoczności treści w wyszukiwarce Google.
Końcowe przemyślenia
Robots.txt może być używany do usprawnienia przeszukiwania i indeksowania zawartości Twojej witryny, co pomaga stać się bardziej widocznym w SERP.
Efektywnie wykorzystany jest najważniejszym tekstem na Twojej stronie. Ale użyty nieostrożnie, będzie piętą achillesową w kodzie Twojej witryny.
Dobra wiadomość, z zaledwie podstawowym zrozumieniem agentów użytkownika i kilkoma dyrektywami, lepsze wyniki wyszukiwania są w Twoim zasięgu.
Pytanie tylko, które protokoły zostaną użyte w pliku robots.txt?
Daj mi znać w komentarzach poniżej.