
Robots.txt: la guía definitiva para SEO (edición 2021)
Publicado: 2021-06-10 Hoy vas a aprender cómo crear uno de los archivos más críticos para el SEO de un sitio web:
Hoy vas a aprender cómo crear uno de los archivos más críticos para el SEO de un sitio web:
(El archivo robots.txt).
Específicamente, le mostraré cómo usar los protocolos de exclusión de robots para bloquear bots de páginas particulares, aumentar la frecuencia de rastreo, optimizar el presupuesto de rastreo y, en última instancia, obtener una mayor clasificación de la página correcta en SERP.
estoy cubriendo:
- Qué es un archivo robots.txt
- Por qué es importante robots.txt
- Cómo funciona robots.txt
- Directivas y agentes de usuario de Robots.txt
- Robots.txt vs meta robots
- Cómo encontrar su archivo robots.txt
- Creando tu archivo robots.txt
- Mejores prácticas del archivo Robots.txt
- Ejemplos de robots.txt
- Cómo auditar tu archivo robots.txt en busca de errores
Mas, un monton mas. Vamos a sumergirnos.
¿Qué es un archivo Robots.txt? Y por qué necesitas uno
En términos simples, un archivo robots.txt es un manual de instrucciones para robots web.
Informa a los bots de todo tipo, qué secciones de un sitio deben (y no deben) rastrear.
Dicho esto, robots.txt se utiliza principalmente como un "código de conducta" para controlar la actividad de los robots de los motores de búsqueda (también conocidos como rastreadores web).

Los principales motores de búsqueda (incluidos Google, Bing y Yahoo) revisan regularmente el archivo robots.txt para obtener instrucciones sobre cómo deben rastrear el sitio web. Estas instrucciones se conocen como directivas .
Si no hay directivas, o ningún archivo robots.txt, los motores de búsqueda rastrearán todo el sitio web, las páginas privadas y todo.
Aunque la mayoría de los motores de búsqueda son obedientes, es importante tener en cuenta que cumplir con las directivas de robots.txt es opcional. Si lo desean, los motores de búsqueda pueden optar por ignorar su archivo robots.txt.
Afortunadamente, Google no es uno de esos motores de búsqueda. Google tiende a obedecer las instrucciones en un archivo robots.txt.
¿Por qué es importante Robots.txt?
Tener un archivo robots.txt no es crítico para muchos sitios web, especialmente los pequeños.
Esto se debe a que, por lo general, Google puede encontrar e indexar todas las páginas esenciales de un sitio.
Y NO indexarán automáticamente contenido duplicado o páginas que no sean importantes.
Pero aún así, no hay una buena razón para no tener un archivo robots.txt, así que te recomiendo que tengas uno.
Un archivo robots.txt le brinda un mayor control sobre lo que los motores de búsqueda pueden y no pueden rastrear en su sitio web, y eso es útil por varias razones:
Permite que las páginas no públicas se bloqueen de los motores de búsqueda
A veces tienes páginas en tu sitio que no quieres indexar.
Por ejemplo, es posible que esté desarrollando un nuevo sitio web en un entorno de prueba que desee asegurarse de que esté oculto para los usuarios hasta el lanzamiento.
O puede tener páginas de inicio de sesión del sitio web que no desea que aparezcan en los SERP.
Si este fuera el caso, podría usar robots.txt para bloquear estas páginas de los rastreadores de los motores de búsqueda.
Controla el presupuesto de rastreo del motor de búsqueda
Si tiene dificultades para indexar todas sus páginas en los motores de búsqueda, es posible que tenga un problema de presupuesto de rastreo.
En pocas palabras, los motores de búsqueda están utilizando el tiempo asignado para rastrear su contenido en las páginas de peso muerto de su sitio web.

Al bloquear las URL de poca utilidad con robots.txt, los robots de los motores de búsqueda pueden gastar más de su presupuesto de rastreo en las páginas que más importan.
Evita la indexación de recursos
Es una buena práctica utilizar la metadirectiva "sin índice" para evitar que se indexen páginas individuales.
El problema es que las directivas meta no funcionan bien para recursos multimedia, como archivos PDF y documentos de Word.
Ahí es donde robots.txt es útil.
Puede agregar una simple línea de texto a su archivo robots.txt y los motores de búsqueda no pueden acceder a estos archivos multimedia.
(Te mostraré exactamente cómo hacerlo más adelante en esta publicación)
¿Cómo (exactamente) funciona un archivo Robots.txt?
Como ya compartí, un archivo robots.txt actúa como un manual de instrucciones para los robots de los motores de búsqueda. Le dice a los robots de búsqueda dónde (y dónde no) deben rastrear.
Es por eso que un rastreador de búsqueda buscará un archivo robots.txt tan pronto como llegue a un sitio web.
Si encuentra el archivo robots.txt, el rastreador lo leerá antes de continuar con el rastreo del sitio.
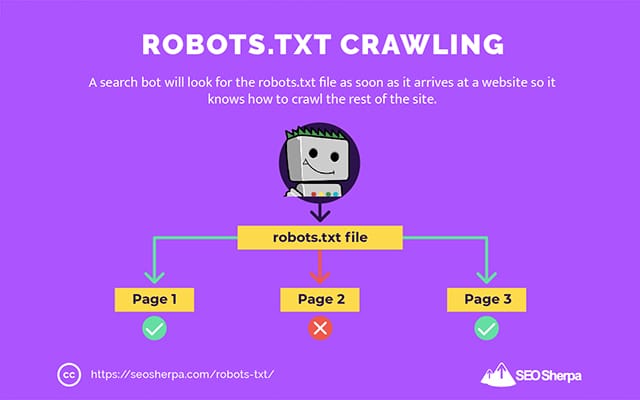
Si el rastreador web no encuentra un archivo robots.txt, o el archivo no contiene directivas que impidan la actividad de los bots de búsqueda, el rastreador continuará rastreando todo el sitio como de costumbre.
Para que los robots de búsqueda puedan encontrar y leer un archivo robots.txt, un archivo robots.txt tiene un formato muy particular.
Primero, es un archivo de texto sin código de marcado HTML (de ahí la extensión .txt).
En segundo lugar, se coloca en la carpeta raíz del sitio web, por ejemplo, https://seosherpa.com/robots.txt.
En tercer lugar, utiliza una sintaxis estándar que es común a todos los archivos robots.txt, así:
Sitemap: [URL location of sitemap] User-agent: [bot identifier] [directive 1] [directive 2] [directive ...] User-agent: [another bot identifier] [directive 1] [directive 2] [directive ...]Esta sintaxis puede parecer desalentadora a primera vista, pero en realidad es bastante simple.
En resumen, usted define el bot (agente de usuario) al que se aplican las instrucciones y luego establece las reglas (directivas) que debe seguir el bot.
Exploremos estos dos componentes con más detalle.
Agentes de usuario
Un agente de usuario es el nombre utilizado para definir rastreadores web específicos y otros programas activos en Internet.
Hay literalmente cientos de agentes de usuario, incluidos agentes para tipos de dispositivos y navegadores.
La mayoría son irrelevantes en el contexto de un archivo robots.txt y SEO. Por otro lado, estos debes saber:
- Google: robot de Google
- Imágenes de Google: Googlebot-Imagen
- Google Video: Googlebot-Video
- Google Noticias: Googlebot-Noticias
- Bing: Bingbot
- Imágenes y vídeos de Bing: MSNBot-Media
- Yahoo: Sorber
- Yandex: YandexBot
- Baidu : Baiduaraña
- PatoPatoGo: PatoPatoBot
Al indicar el agente de usuario, puede establecer diferentes reglas para diferentes motores de búsqueda.

Por ejemplo, si quisiera que una determinada página apareciera en los resultados de búsqueda de Google pero no en las búsquedas de Baidu, podría incluir dos conjuntos de comandos en su archivo robots.txt: un conjunto precedido por "User-agent: Bingbot" y otro conjunto precedido por por "Agente de usuario: Baiduspider".
También puede usar el comodín de estrella (*) si desea que sus directivas se apliquen a todos los agentes de usuario.
Por ejemplo, supongamos que desea bloquear todos los robots de los motores de búsqueda para que no rastreen su sitio, excepto DuckDuckGo. Así es como lo harías:
User-agent: * Disallow: / User-agent: DuckDuckBot Allow: /Nota al margen: si hay comandos contradictorios en el archivo robots.txt, el bot seguirá el comando más granular.
Es por eso que en el ejemplo anterior, DuckDuckBot sabe rastrear el sitio web, aunque una directiva anterior (que se aplica a todos los bots) decía no rastrear. En resumen, un bot seguirá las instrucciones que se le apliquen con mayor precisión.
Directivas
Las directivas son el código de conducta que desea que siga el agente de usuario. En otras palabras, las directivas definen cómo el robot de búsqueda debe rastrear su sitio web.
Estas son las directivas que GoogleBot admite actualmente, junto con su uso dentro de un archivo robots.txt:
Rechazar
Use esta directiva para impedir que los robots de búsqueda rastreen ciertos archivos y páginas en una ruta de URL específica.

Por ejemplo, si desea bloquear el acceso de GoogleBot a su wiki y a todas sus páginas, su archivo robots.txt debe contener esta directiva:
User-agent: GoogleBot Disallow: /wikiPuede usar la directiva disallow para bloquear el rastreo de una URL precisa, todos los archivos y páginas dentro de un directorio determinado, e incluso todo su sitio web.
Permitir
La directiva allow es útil si desea permitir que los motores de búsqueda rastreen un subdirectorio o una página específica, en una sección de su sitio que de otro modo no estaría permitida.

Supongamos que desea evitar que todos los motores de búsqueda rastreen las publicaciones de su blog excepto uno; entonces usaría la directiva allow así:
User-agent: * Disallow: /blog Allow: /blog/allowable-postDado que los bots de búsqueda siempre siguen las instrucciones más granulares proporcionadas en un archivo robots.txt, saben rastrear /blog/permitido-publicación, pero no rastrearán otras publicaciones o archivos en ese directorio como;
- /blog/post-one/
- /blog/post-dos/
- /blog/nombre-de-archivo.pdf
Tanto Google como Bing admiten esta directiva. Pero otros motores de búsqueda no lo hacen.
mapa del sitio
La directiva del mapa del sitio se usa para especificar la ubicación de su(s) mapa(s) del sitio XML para los motores de búsqueda.
Si eres nuevo en los sitemaps, se utilizan para enumerar las páginas que deseas que se rastreen e indexen en los motores de búsqueda.
Al incluir la directiva del mapa del sitio en robots.txt, ayuda a los motores de búsqueda a encontrar su mapa del sitio y, a su vez, rastrear e indexar las páginas más importantes de su sitio web.
Dicho esto, si ya envió su mapa del sitio XML a través de la Consola de búsqueda, agregar su(s) mapa(s) del sitio en robots.txt es algo redundante para Google. Aún así, es una buena práctica usar la directiva del mapa del sitio, ya que le dice a los motores de búsqueda como Ask, Bing y Yahoo dónde se pueden encontrar sus mapas del sitio.
Aquí hay un ejemplo de un archivo robots.txt que usa la directiva del mapa del sitio:
Sitemap: https://www.website.com/sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/Observe la ubicación de la directiva del mapa del sitio en el archivo robots.txt. Se ubica mejor en la parte superior de su archivo robots.txt. También se puede colocar en la parte inferior.
Si tiene varios mapas de sitio, debe incluirlos todos en su archivo robots.txt. Así es como se vería el archivo robots.txt si tuviéramos mapas de sitio XML separados para páginas y publicaciones:
Sitemap: http://website.com/post-sitemap.xml Sitemap: http://website.com/page-sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/De cualquier manera, solo necesita mencionar cada mapa del sitio XML una vez, ya que todos los agentes de usuario compatibles seguirán la directiva.
Tenga en cuenta que, a diferencia de otras directivas de robots.txt, que enumeran las rutas, la directiva del mapa del sitio debe indicar la URL absoluta de su mapa del sitio XML, incluido el protocolo, el nombre de dominio y la extensión de dominio de nivel superior.
Comentarios
La "directiva" de comentarios es útil para los humanos, pero los robots de búsqueda no la utilizan.

Puede agregar comentarios para recordar por qué existen ciertas directivas o evitar que aquellos con acceso a su archivo robots.txt eliminen directivas importantes. En resumen, los comentarios se utilizan para agregar notas a su archivo robots.txt.
Para agregar un comentario, escriba.” #" seguido del texto del comentario.
# Don't allow access to the /wp-admin/ directory for all robots. User-agent: * Disallow: /wp-admin/Puede agregar un comentario al comienzo de una línea (como se muestra arriba) o después de una directiva en la misma línea (como se muestra a continuación):
User-agent: * #Applies to all robots Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.Dondequiera que elija escribir su comentario, todo lo que esté después del hash será ignorado.
¿Siguiendo hasta ahora?
¡Excelente! Ahora hemos cubierto las directivas principales que necesitará para su archivo robots.txt; estas también son las únicas directivas admitidas por Google.
Pero, ¿qué pasa con otros motores de búsqueda? En el caso de Bing, Yahoo y Yandex, hay una directiva más que puede usar:
Retraso de rastreo
La directiva Crawl-delay es una directiva no oficial que se utiliza para evitar que los servidores se sobrecarguen con demasiadas solicitudes de rastreo.
En otras palabras, lo usa para limitar la frecuencia con la que un motor de búsqueda puede rastrear su sitio.

Eso sí, si los motores de búsqueda pueden sobrecargar su servidor al rastrear su sitio web con frecuencia, agregar la directiva Crawl-delay a su archivo robots.txt solo solucionará el problema temporalmente.
El caso puede ser que su sitio web se esté ejecutando en un alojamiento de mala calidad o en un entorno de alojamiento mal configurado, y eso es algo que debe solucionar rápidamente.
La directiva de retraso del rastreo funciona definiendo el tiempo en segundos entre los cuales un robot de búsqueda puede rastrear su sitio web.
Por ejemplo, si establece su demora de rastreo en 5, los robots de búsqueda dividirán el día en ventanas de cinco segundos, rastreando solo una página (o ninguna) en cada ventana, para un máximo de alrededor de 17,280 URL durante el día.
Siendo así, tenga cuidado al configurar esta directiva, especialmente si tiene un sitio web grande. Solo 17,280 URL rastreadas por día no es muy útil si su sitio tiene millones de páginas.
La forma en que cada motor de búsqueda maneja la directiva crawl-delay es diferente. Vamos a desglosarlo a continuación:
Crawl-delay y Bing, Yahoo y Yandex
Bing, Yahoo y Yandex admiten la directiva de retraso de rastreo en robots.txt.
Esto significa que puede establecer una directiva de retraso de rastreo para los agentes de usuario de BingBot, Slurp y YandexBot, y el motor de búsqueda acelerará su rastreo en consecuencia.
Sin embargo, tenga en cuenta que cada motor de búsqueda interpreta el retraso del rastreo de una manera ligeramente diferente , así que asegúrese de consultar su documentación:
- Bing y yahoo
- Yandex
Dicho esto, el formato de la directiva crawl-delay para cada uno de estos motores es el mismo. Debe colocarlo justo después de una directiva de rechazo O permiso. Aquí hay un ejemplo:
User-agent: BingBot Allow: /widgets/ Crawl-delay: 5Rastreo-retraso y Google
El rastreador de Google no es compatible con la directiva de retraso de rastreo, por lo que no tiene sentido configurar un retraso de rastreo para GoogleBot en robots.txt.
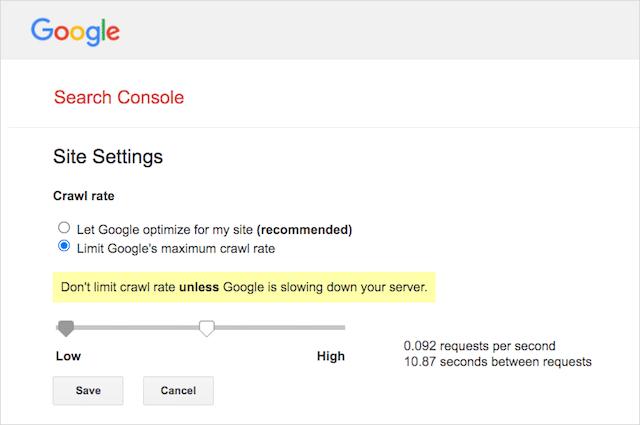
Sin embargo, Google admite la definición de una frecuencia de rastreo en Google Search Console. Aquí está cómo hacerlo:
- Vaya a la página de configuración de Google Search Console.
- Elija la propiedad para la que desea definir la frecuencia de rastreo
- Haz clic en "Limitar la tasa de rastreo máxima de Google".
- Ajuste el control deslizante a su frecuencia de rastreo preferida. De forma predeterminada, la frecuencia de rastreo tiene la configuración "Permitir que Google optimice para mi sitio (recomendado)".
Crawl-delay y Baidu
Al igual que Google, Baidu no admite la directiva de demora de rastreo. Sin embargo, es posible registrar una cuenta de Baidu Webmaster Tools en la que puede controlar la frecuencia de rastreo, similar a Google Search Console.
¿La línea de fondo? Robots.txt le dice a las arañas de los motores de búsqueda que no rastreen páginas específicas de su sitio web.
Robots.txt vs meta robots vs x-robots
Hay un montón de instrucciones de "robots" por ahí. ¿Cuáles son las diferencias, o son lo mismo?
Permítanme ofrecer una breve explicación:
En primer lugar, robots.txt es un archivo de texto real, mientras que meta y x-robots son etiquetas dentro del código de una página web.
En segundo lugar, robots.txt ofrece sugerencias a los bots sobre cómo rastrear las páginas de un sitio web. Por otro lado, las directivas meta de los robots brindan instrucciones muy firmes sobre el rastreo y la indexación del contenido de una página.
Más allá de lo que son, los tres cumplen diferentes funciones.
Robots.txt dicta el comportamiento de rastreo de todo el sitio o directorio, mientras que los robots meta y x pueden dictar el comportamiento de indexación a nivel de página individual (o elemento de página).

En general:
Si desea evitar que una página se indexe, debe usar la etiqueta de meta robots "sin índice". Deshabilitar una página en robots.txt no garantiza que no se muestre en los motores de búsqueda (después de todo, las directivas de robots.txt son sugerencias). Además, un robot de motor de búsqueda aún podría encontrar esa URL e indexarla si está vinculada desde otro sitio web.

Por el contrario, si desea evitar que se indexe un archivo multimedia, robots.txt es el camino a seguir. No puede agregar etiquetas de meta robots a archivos como jpegs o PDF.
Cómo encontrar sus robots.txt
Si ya tiene un archivo robots.txt en su sitio web, podrá acceder a él en sudominio.com/robots.txt.
Navegue a la URL en su navegador.
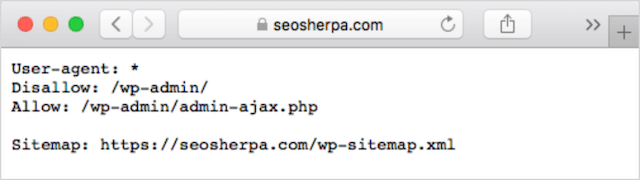
Si ve una página basada en texto como la anterior, entonces tiene un archivo robots.txt.
Cómo crear un archivo Robots.txt
Si aún no tiene un archivo robots.txt, crear uno es simple.
Primero, abra el Bloc de notas, Microsoft Word o cualquier editor de texto y guarde el archivo como 'robots'.
Asegúrese de usar minúsculas y elija .txt como la extensión del tipo de archivo:

En segundo lugar, agregue sus directivas. Por ejemplo, si desea impedir que todos los robots de búsqueda rastreen su directorio /login/, debe escribir esto:
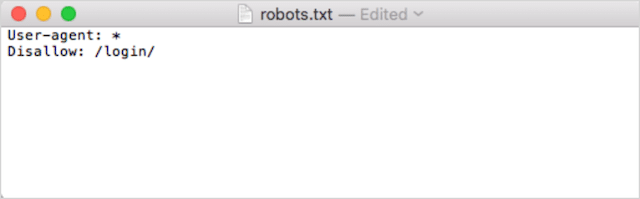
Continúe agregando directivas hasta que esté satisfecho con su archivo robots.txt.
Alternativamente, puede generar su archivo robots.txt con una herramienta como esta de Ryte.

Una ventaja de usar una herramienta es que minimiza el error humano.
Solo un pequeño error en la sintaxis de su archivo robots.txt podría terminar en un desastre de SEO.
Dicho esto, la desventaja de usar un generador de robots.txt es que la oportunidad de personalización es mínima.
Por eso te recomiendo que aprendas a escribir un archivo robot.txt tú mismo. A continuación, puede crear un archivo robots.txt exactamente según sus requisitos.
Dónde poner su archivo Robots.txt
Agregue su archivo robots.txt en el directorio de nivel superior del subdominio al que se aplica.
Por ejemplo, para controlar el comportamiento de rastreo en sudominio.com , el archivo robots.txt debe estar accesible en la ruta URL de sudominio.com/robots.txt .
Por otro lado, si desea controlar el rastreo en un subdominio como shop.yourdomain.com , se debe poder acceder a robots.txt en la ruta URL shop.yourdomain.com/robots.txt .
Las reglas de oro son:
- Asigne a cada subdominio de su sitio web su propio archivo robots.txt.
- Nombra tu(s) archivo(s) robots.txt todo en minúsculas.
- Coloque el archivo en el directorio raíz del subdominio al que hace referencia.
Si el archivo robots.txt no se puede encontrar en el directorio raíz, los motores de búsqueda asumirán que no hay directivas y rastrearán su sitio web en su totalidad.
Mejores prácticas del archivo Robots.txt
A continuación, cubramos las reglas de los archivos robots.txt. Utilice estas mejores prácticas para evitar errores comunes de robots.txt:
Use una nueva línea para cada directiva
Cada directiva en su archivo robots.txt debe estar en una nueva línea.
De lo contrario, los motores de búsqueda se confundirán sobre qué rastrear (e indexar).
Esto, por ejemplo, está mal configurado:
User-agent: * Disallow: /folder/ Disallow: /another-folder/Esto, por otro lado, es un archivo robots.txt configurado correctamente :
User-agent: * Disallow: /folder/ Disallow: /another-folder/La especificidad "casi" siempre gana
Cuando se trata de Google y Bing, gana la directiva más granular.
Por ejemplo, esta directiva Allow gana a la directiva Disallow porque su longitud de caracteres es más larga.
User-agent: * Disallow: /about/ Allow: /about/company/Google y Bing saben rastrear /acerca de/empresa/ pero no otras páginas en el directorio /acerca de/.
Sin embargo, en el caso de otros motores de búsqueda, ocurre lo contrario.
De forma predeterminada, para todos los principales motores de búsqueda que no sean Google y Bing, la primera directiva coincidente siempre gana .
En el ejemplo anterior, los motores de búsqueda seguirán la directiva Disallow e ignorarán la directiva Allow, lo que significa que no se rastreará la página /acerca de/la empresa.
Tenga esto en cuenta cuando cree reglas para todos los motores de búsqueda.
Solo un grupo de directivas por agente de usuario
Si su archivo robots.txt contenía varios grupos de directivas por agente de usuario, vaya, ¿podría volverse confuso?
No necesariamente para robots, porque combinarán todas las reglas de las diversas declaraciones en un grupo y las seguirán todas, pero sí para usted.
Para evitar la posibilidad de un error humano, indique el agente de usuario una vez y luego enumere todas las directivas que se aplican a ese agente de usuario a continuación.

Manteniendo las cosas ordenadas y simples, es menos probable que cometas un error garrafal.
Use comodines (*) para simplificar las instrucciones
¿Notó los comodines (*) en el ejemplo anterior?
Así es; puede usar comodines (*) para aplicar reglas a todos los agentes de usuario Y para hacer coincidir los patrones de URL al declarar directivas.
Por ejemplo, si desea evitar que los robots de búsqueda accedan a las URL de categorías de productos parametrizados en su sitio web, puede enumerar cada categoría de la siguiente manera:
User-agent: * Disallow: /products/watches? Disallow: /products/handbags? Disallow: /products/shoes?O bien, podría usar un comodín que aplicaría la regla a todas las categorías. Así es como se vería:
User-agent: * Disallow: /products/*?Este ejemplo impide que los motores de búsqueda rastreen todas las URL dentro de la subcarpeta /producto/ que contengan un signo de interrogación. En otras palabras, cualquier URL de categoría de producto que esté parametrizada.
Google, Bing, Yahoo admiten el uso de comodines dentro de las directivas de robots.txt y Ask.
Use "$" para especificar el final de una URL
Para indicar el final de una URL, use el signo de dólar ( $ ) después de la ruta de robots.txt.
Supongamos que desea evitar que los robots de búsqueda accedan a todos los archivos .doc de su sitio web; entonces usarías esta directiva:
User-agent: * Disallow: /*.doc$Esto evitaría que los motores de búsqueda accedan a cualquier URL que termine en .doc.
Esto significa que no rastrearían /media/file.doc, pero rastrearían /media/file.doc?id=72491 porque esa URL no termina en ".doc".
Cada subdominio obtiene su propio archivo robots.txt
Las directivas de Robots.txt solo se aplican al (sub)dominio en el que está alojado el archivo robots.txt.
Esto significa que si su sitio tiene múltiples subdominios como:
- dominio.com
- entradas.dominio.com
- eventos.dominio.com
Cada subdominio requerirá su propio archivo robots.txt.
El archivo robots.txt siempre debe agregarse en el directorio raíz de cada subdominio. Así es como se verían las rutas usando el ejemplo anterior:
- dominio.com/robots.txt
- entradas.dominio.com/robots.txt
- eventos.dominio.com/robots.txt
No uses noindex en tu archivo robots.txt
En pocas palabras, Google no admite la directiva sin índice en robots.txt.
Si bien Google lo siguió en el pasado, a partir de julio de 2019 dejó de admitirlo por completo.
Y si está pensando en usar la directiva robots.txt sin índice para contenido sin índice en otros motores de búsqueda, piénselo de nuevo:
La directiva no oficial de no indexación nunca funcionó en Bing.
De lejos, el mejor método para el contenido sin índice en los motores de búsqueda es aplicar una etiqueta de meta robots sin índice a la página que desea excluir.
Mantenga su archivo robots.txt por debajo de 512 KB
Actualmente, Google tiene un límite de tamaño de archivo robots.txt de 500 kibibytes (512 kilobytes).
Esto significa que se puede ignorar cualquier contenido después de 512 KB.

Dicho esto, dado que un carácter consume solo un byte, su archivo robots.txt tendría que ser ENORME para alcanzar ese límite de tamaño de archivo (512 000 caracteres, para ser exactos). Mantenga su archivo robots.txt reducido enfocándose menos en páginas excluidas individualmente y más en patrones más amplios que los comodines pueden controlar.
No está claro si otros motores de búsqueda tienen el tamaño de archivo máximo permitido para los archivos robots.txt.
Ejemplos de robots.txt
A continuación se muestran algunos ejemplos de archivos robots.txt.
Incluyen combinaciones de las directivas que nuestra agencia de SEO utiliza más en los archivos robots.txt para los clientes. Tenga en cuenta, sin embargo; estos son solo para fines de inspiración. Siempre deberá personalizar el archivo robots.txt para cumplir con sus requisitos.
Permitir que todos los robots accedan a todo
Este archivo robots.txt no proporciona reglas de rechazo para todos los motores de búsqueda:
User-agent: * Disallow:En otras palabras, permite que los robots de búsqueda rastreen todo. Sirve para el mismo propósito que un archivo robots.txt vacío o ningún robot.txt en absoluto.
Impedir que todos los robots accedan a todo
El archivo robots.txt de ejemplo le dice a todos los motores de búsqueda que no accedan a nada después de la barra diagonal final. En otras palabras, todo el dominio:
User-agent: * Disallow: /En resumen, este archivo robots.txt bloquea todos los robots de los motores de búsqueda y puede impedir que su sitio se muestre en las páginas de resultados de búsqueda.
Impedir que todos los robots rastreen un archivo
En este ejemplo, bloqueamos todos los robots de búsqueda para que no rastreen un archivo en particular.
User-agent: * Disallow: /directory/this-is-a-file.pdfImpedir que todos los robots rastreen un tipo de archivo (doc, pdf, jpg)
Dado que no se indexa, un archivo como 'doc' o 'pdf' no se puede hacer usando una etiqueta "sin índice" de meta robot; puede usar la siguiente directiva para evitar que se indexe un tipo de archivo en particular.
User-agent: * Disallow: /*.doc$ Disallow: /*.pdf$ Disallow: /*.jpg$Esto funcionará para desindexar todos los archivos de ese tipo, siempre que ningún archivo individual esté vinculado desde otro lugar de la web.
Impedir que Google rastree varios directorios
Es posible que desee bloquear el rastreo de varios directorios para un bot en particular o para todos los bots. En este ejemplo, estamos impidiendo que Googlebot rastree dos subdirectorios.
User-agent: Googlebot Disallow: /admin/ Disallow: /private/Tenga en cuenta que no hay límite en la cantidad de directorios que puede usar bock. Solo enumere cada uno debajo del agente de usuario al que se aplica la directiva.
Impedir que Google rastree todas las URL parametrizadas
Esta directiva es particularmente útil para sitios web que usan navegación por facetas, donde se pueden crear muchas URL parametrizadas.
User-agent: Googlebot Disallow: /*?Esta directiva evita que su presupuesto de rastreo se consuma en URL dinámicas y maximiza el rastreo de páginas importantes. Lo uso regularmente, particularmente en sitios web de comercio electrónico con funcionalidad de búsqueda.
Bloquee todos los bots para que no rastreen un subdirectorio pero permita que se rastree una página dentro
A veces, es posible que desee bloquear el acceso de los rastreadores a una sección completa de su sitio, pero dejar una página accesible. Si lo hace, use la siguiente combinación de directivas 'permitir' y 'no permitir':
User-agent: * Disallow: /category/ Allow: /category/widget/Le dice a los motores de búsqueda que no rastreen el directorio completo, excluyendo una página o archivo en particular.
Robots.txt para WordPress
Esta es la configuración básica que recomiendo para un archivo robots.txt de WordPress. Bloquea el rastreo de las páginas de administración y las etiquetas y las URL de los autores, lo que puede crear problemas innecesarios en un sitio web de WordPress.
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /wp-admin/ Disallow: /readme.html Disallow: /refer/ Disallow: /tag/ Disallow: /author/ Disallow: /404-error/ Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xmlEste archivo robots.txt funcionará bien para la mayoría de los sitios web de WordPress, pero, por supuesto, siempre debe ajustarlo a sus propios requisitos.
Cómo auditar su archivo Robots.txt en busca de errores
En mi tiempo, he visto más errores que afectan la clasificación en los archivos robots.txt que quizás cualquier otro aspecto del SEO técnico. Con tantas directivas potencialmente conflictivas, los problemas pueden ocurrir y ocurren.
Entonces, cuando se trata de archivos robots.txt, vale la pena estar atento a los problemas.
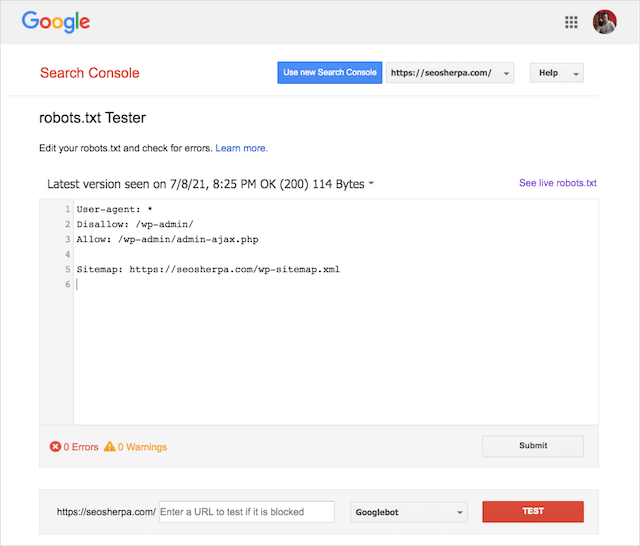
Afortunadamente, el informe de "Cobertura" dentro de Google Search Console le brinda una forma de verificar y monitorear los problemas de robots.txt.
También puede usar la ingeniosa herramienta de prueba Robots.txt de Google para buscar errores en su archivo de robots en vivo o probar un nuevo archivo robots.txt antes de implementarlo.
Terminaremos cubriendo los problemas más comunes, lo que significan y cómo abordarlos.
URL enviada bloqueada por robots.txt
Este error significa que al menos una de las URL de los mapas del sitio enviados está bloqueada por robots.txt.

Un mapa del sitio configurado correctamente debe incluir solo las URL que desea indexar en los motores de búsqueda . Como tal, no debe contener ninguna página no indexada, canonicalizada o redirigida.
Si ha seguido estas prácticas recomendadas, el archivo robots.txt no debería bloquear ninguna página enviada en su mapa del sitio.
Si ve "URL enviada bloqueada por robots.txt" en el informe de cobertura, debe investigar qué páginas están afectadas y luego cambiar su archivo robots.txt para eliminar el bloqueo de esa página.
Puede usar el probador de robots.txt de Google para ver qué directiva está bloqueando el contenido.
Bloqueado por Robots.txt
Este "error" significa que tiene páginas bloqueadas por su archivo robots.txt que actualmente no están en el índice de Google.

Si este contenido tiene utilidad y debe indexarse, elimine el bloqueo de rastreo en robots.txt.
Una breve advertencia:
"Bloqueado por robots.txt" no es necesariamente un error. De hecho, puede ser precisamente el resultado que desea.
Por ejemplo, es posible que haya bloqueado ciertos archivos en robots.txt con la intención de excluirlos del índice de Google. Por otro lado, si ha bloqueado el rastreo de ciertas páginas con la intención de no indexarlas, considere eliminar el bloqueo de rastreo y use una metaetiqueta de robot en su lugar.
Esa es la única manera de garantizar la exclusión de contenido del índice de Google.
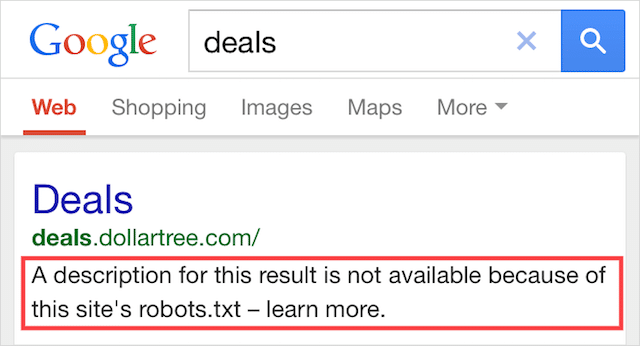
Indexado, aunque bloqueado por Robots.txt
Este error significa que parte del contenido bloqueado por robots.txt todavía está indexado en Google.
Ocurre cuando Googlebot aún puede descubrir el contenido porque está vinculado desde otra parte de la web. En resumen, Googlebot aterriza en ese contenido que rastrea y luego lo indexa antes de visitar el archivo robots.txt de su sitio web, donde ve la directiva no permitida.
Para entonces, es demasiado tarde. Y se indexa:
Déjame taladrar esta casa:
Si intenta excluir contenido de los resultados de búsqueda de Google, robots.txt no es la solución correcta.
Recomiendo eliminar el bloque de rastreo y usar una etiqueta sin índice de meta robots para evitar la indexación.
Por el contrario, si bloqueó este contenido por accidente y desea mantenerlo en el índice de Google, elimine el bloqueo de rastreo en robots.txt y déjelo así.
Esto puede ayudar a mejorar la visibilidad del contenido en la búsqueda de Google.
Pensamientos finales
Robots.txt se puede usar para mejorar el rastreo y la indexación del contenido de su sitio web, lo que lo ayuda a ser más visible en los SERP.
Cuando se usa de manera efectiva, es el texto más importante de su sitio web. Pero, cuando se usa sin cuidado, será el talón de Aquiles en el código de su sitio web.
La buena noticia es que con solo una comprensión básica de los agentes de usuario y un puñado de directivas, los mejores resultados de búsqueda están a su alcance.
La única pregunta es, ¿ qué protocolos utilizará en su archivo robots.txt?
Déjame saber abajo en los comentarios.