
Robots.txt: o guia definitivo para SEO (edição 2021)
Publicados: 2021-06-10 Hoje você vai aprender como criar um dos arquivos mais críticos para o SEO de um site:
Hoje você vai aprender como criar um dos arquivos mais críticos para o SEO de um site:
(O arquivo robots.txt).
Especificamente, mostrarei como usar protocolos de exclusão de robôs para bloquear bots de páginas específicas, aumentar a frequência de rastreamento, otimizar o orçamento de rastreamento e, por fim, obter mais classificação da página certa em SERPs.
estou cobrindo:
- O que é um arquivo robots.txt
- Por que o robots.txt é importante
- Como o robots.txt funciona
- Agentes e diretivas do usuário Robots.txt
- Robots.txt vs meta-robôs
- Como encontrar seu robots.txt
- Criando seu arquivo robots.txt
- Práticas recomendadas do arquivo Robots.txt
- Exemplos de robots.txt
- Como auditar seu robots.txt em busca de erros
Mais, muito mais. Vamos mergulhar direto.
O que é um arquivo Robots.txt? E, por que você precisa de um
Em termos simples, um arquivo robots.txt é um manual de instruções para robôs da web.
Ele informa bots de todos os tipos, quais seções de um site eles devem (e não devem) rastrear.
Dito isto, o robots.txt é usado principalmente como um “código de conduta” para controlar a atividade dos robôs dos mecanismos de pesquisa (rastreadores da web AKA).

O robots.txt é verificado regularmente por todos os principais mecanismos de pesquisa (incluindo Google, Bing e Yahoo) para obter instruções sobre como eles devem rastrear o site. Essas instruções são conhecidas como diretivas .
Se não houver diretivas – ou nenhum arquivo robots.txt – os mecanismos de pesquisa rastrearão todo o site, páginas privadas e tudo mais.
Embora a maioria dos mecanismos de pesquisa seja obediente, é importante observar que seguir as diretivas do robots.txt é opcional. Se desejarem, os mecanismos de pesquisa podem optar por ignorar seu arquivo robots.txt.
Felizmente, o Google não é um desses motores de busca. O Google tende a obedecer às instruções em um arquivo robots.txt.
Por que o Robots.txt é importante?
Ter um arquivo robots.txt não é crítico para muitos sites, especialmente os pequenos.
Isso porque o Google geralmente pode encontrar e indexar todas as páginas essenciais de um site.
E, eles automaticamente NÃO indexarão conteúdo duplicado ou páginas que não são importantes.
Mas ainda assim, não há uma boa razão para não ter um arquivo robots.txt – então eu recomendo que você tenha um.
Um robots.txt oferece maior controle sobre o que os mecanismos de pesquisa podem e não podem rastrear em seu site, e isso é útil por vários motivos:
Permite que páginas não públicas sejam bloqueadas nos mecanismos de pesquisa
Às vezes, você tem páginas em seu site que não deseja indexar.
Por exemplo, você pode estar desenvolvendo um novo site em um ambiente de teste que deseja ter certeza de que está oculto para os usuários até o lançamento.
Ou você pode ter páginas de login do site que não deseja que apareçam nas SERPs.
Se for esse o caso, você pode usar o robots.txt para bloquear essas páginas dos rastreadores dos mecanismos de pesquisa.
Controla o orçamento de rastreamento do mecanismo de pesquisa
Se estiver com dificuldades para indexar todas as suas páginas nos mecanismos de pesquisa, você pode ter um problema de orçamento de rastreamento.
Simplificando, os mecanismos de pesquisa estão usando o tempo alocado para rastrear seu conteúdo nas páginas de peso morto do seu site.

Ao bloquear URLs de baixa utilidade com o robots.txt, os robôs dos mecanismos de pesquisa podem gastar mais de seu orçamento de rastreamento nas páginas mais importantes.
Impede a indexação de recursos
É uma prática recomendada usar a meta diretiva “no-index” para impedir que páginas individuais sejam indexadas.
O problema é que meta diretivas não funcionam bem para recursos multimídia, como PDFs e documentos do Word.
É aí que o robots.txt é útil.
Você pode adicionar uma simples linha de texto ao seu arquivo robots.txt e os mecanismos de pesquisa serão impedidos de acessar esses arquivos multimídia.
(Vou mostrar exatamente como fazer isso mais adiante neste post)
Como (exatamente) funciona um Robots.txt?
Como já compartilhei, um arquivo robots.txt funciona como um manual de instruções para robôs de mecanismos de pesquisa. Ele informa aos bots de pesquisa onde (e onde não) eles devem rastrear.
É por isso que um rastreador de pesquisa procurará um arquivo robots.txt assim que ele chegar a um site.
Se encontrar o robots.txt, o rastreador o lerá primeiro antes de continuar com o rastreamento do site.
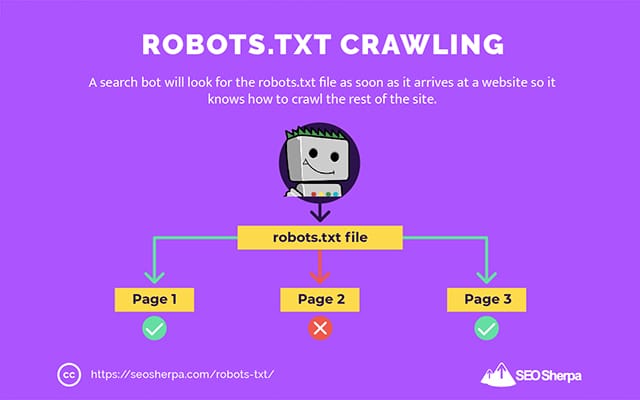
Se o rastreador da Web não encontrar um robots.txt ou o arquivo não contiver diretivas que não permitam a atividade dos bots de pesquisa, o rastreador continuará a rastrear todo o site normalmente.
Para que um arquivo robots.txt seja localizável e legível por robôs de pesquisa, um arquivo robots.txt é formatado de uma maneira muito particular.
Primeiro, é um arquivo de texto sem código de marcação HTML (daí a extensão .txt).
Segundo, ele é colocado na pasta raiz do site, por exemplo, https://seosherpa.com/robots.txt.
Terceiro, ele usa uma sintaxe padrão que é comum a todos os arquivos robots.txt, assim:
Sitemap: [URL location of sitemap] User-agent: [bot identifier] [directive 1] [directive 2] [directive ...] User-agent: [another bot identifier] [directive 1] [directive 2] [directive ...]Essa sintaxe pode parecer assustadora à primeira vista, mas na verdade é bem simples.
Em resumo, você define o bot (user-agent) ao qual as instruções se aplicam e, em seguida, declara as regras (diretivas) que o bot deve seguir.
Vamos explorar esses dois componentes com mais detalhes.
Agentes do usuário
Um agente de usuário é o nome usado para definir rastreadores da Web específicos – e outros programas ativos na Internet.
Existem literalmente centenas de agentes de usuário, incluindo agentes para tipos de dispositivos e navegadores.
A maioria é irrelevante no contexto de um arquivo robots.txt e SEO. Por outro lado, estes você deve saber:
- Google: Googlebot
- Imagens do Google: Googlebot-Image
- Google Video: Googlebot-Video
- Google Notícias: Googlebot-Notícias
- Bing: Bingbot
- Imagens e vídeos do Bing: MSNBot-Media
- Yahoo: Slurp
- Yandex: YandexBot
- Baidu : Baiduspider
- DuckDuckGo: DuckDuckBot
Ao indicar o agente do usuário, você pode definir regras diferentes para diferentes mecanismos de pesquisa.

Por exemplo, se você quiser que uma determinada página apareça nos resultados de pesquisa do Google, mas não nas pesquisas do Baidu, você pode incluir dois conjuntos de comandos em seu arquivo robots.txt: um conjunto precedido por "User-agent: Bingbot" e um conjunto precedido por “Usuário-agente: Baiduspider.”
Você também pode usar o curinga asterisco (*) se quiser que suas diretivas se apliquem a todos os agentes do usuário.
Por exemplo, digamos que você queira impedir que todos os robôs de mecanismos de pesquisa rastreiem seu site, exceto o DuckDuckGo. Veja como você faria isso:
User-agent: * Disallow: / User-agent: DuckDuckBot Allow: /Nota lateral: se houver comandos contraditórios no arquivo robots.txt, o bot seguirá o comando mais granular.
É por isso que no exemplo acima, o DuckDuckBot sabe rastrear o site, mesmo que uma diretiva anterior (aplicando-se a todos os bots) dissesse não rastrear. Em suma, um bot seguirá as instruções que se aplicam com mais precisão a eles.
Diretivas
As diretivas são o código de conduta que você deseja que o agente do usuário siga. Em outras palavras, as diretivas definem como o bot de pesquisa deve rastrear seu site.
Aqui estão as diretivas que o GoogleBot suporta atualmente, juntamente com seu uso em um arquivo robots.txt:
Não permitir
Use esta diretiva para impedir que os bots de pesquisa rastreiem determinados arquivos e páginas em um caminho de URL específico.

Por exemplo, se você quiser impedir que o GoogleBot acesse seu wiki e todas as suas páginas, seu robots.txt deve conter esta diretiva:
User-agent: GoogleBot Disallow: /wikiVocê pode usar a diretiva disallow para bloquear o rastreamento de um URL preciso, todos os arquivos e páginas em um determinado diretório e até mesmo todo o seu site.
Permitir
A diretiva allow é útil se você deseja permitir que os mecanismos de pesquisa rastreiem um subdiretório ou página específica – em uma seção não permitida do seu site.

Digamos que você queira impedir que todos os mecanismos de pesquisa rastreiem as postagens em seu blog, exceto uma; então você usaria a diretiva allow assim:
User-agent: * Disallow: /blog Allow: /blog/allowable-postComo os bots de pesquisa sempre seguem as instruções mais granulares fornecidas em um arquivo robots.txt, eles sabem rastrear /blog/allowable-post, mas não rastrearão outras postagens ou arquivos nesse diretório como;
- /blog/post-one/
- /blog/post-dois/
- /blog/nome-arquivo.pdf
Tanto o Google quanto o Bing suportam essa diretiva. Mas outros motores de busca não.
Mapa do site
A diretiva sitemap é usada para especificar a localização de seus sitemaps XML para os mecanismos de pesquisa.
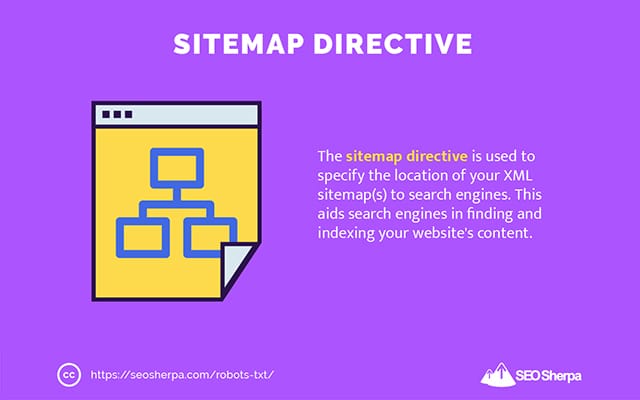
Se você é novo em sitemaps, eles são usados para listar as páginas que você deseja que sejam rastreadas e indexadas nos mecanismos de pesquisa.
Ao incluir a diretiva do sitemap no robots.txt, você ajuda os mecanismos de pesquisa a encontrar seu sitemap e, por sua vez, rastrear e indexar as páginas mais importantes do seu site.
Com isso dito, se você já enviou seu sitemap XML por meio do Search Console, adicionar seus sitemaps em robots.txt é um pouco redundante para o Google. Ainda assim, é uma prática recomendada usar a diretiva de mapa do site, pois ela informa aos mecanismos de pesquisa como Ask, Bing e Yahoo onde seus sitemaps podem ser encontrados.
Aqui está um exemplo de um arquivo robots.txt usando a diretiva sitemap:
Sitemap: https://www.website.com/sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/Observe o posicionamento da diretiva do sitemap no arquivo robots.txt. É melhor colocado no topo do seu robots.txt. Também pode ser colocado na parte inferior.
Se você tiver vários sitemaps, inclua todos eles no arquivo robots.txt. Veja como o arquivo robots.txt ficaria se tivéssemos mapas de site XML separados para páginas e postagens:
Sitemap: http://website.com/post-sitemap.xml Sitemap: http://website.com/page-sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/De qualquer forma, você só precisa mencionar cada sitemap XML uma vez, pois todos os agentes de usuário suportados seguirão a diretiva.
Observe que, diferentemente de outras diretivas robots.txt, que listam caminhos, a diretiva sitemap deve indicar o URL absoluto do seu sitemap XML, incluindo o protocolo, nome de domínio e extensão de domínio de nível superior.
Comentários
O comentário “diretiva” é útil para humanos, mas não é usado por bots de busca.

Você pode adicionar comentários para lembrá-lo da existência de determinadas diretivas ou impedir que aqueles com acesso ao seu robots.txt excluam diretivas importantes. Resumindo, os comentários são usados para adicionar notas ao seu arquivo robots.txt.
Para adicionar um comentário, digite.” #" seguido pelo texto do comentário.
# Don't allow access to the /wp-admin/ directory for all robots. User-agent: * Disallow: /wp-admin/Você pode adicionar um comentário no início de uma linha (como mostrado acima) ou após uma diretiva na mesma linha (como mostrado abaixo):
User-agent: * #Applies to all robots Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.Onde quer que você escolha escrever seu comentário, tudo após o hash será ignorado.
Acompanhando até agora?
Excelente! Agora abordamos as principais diretivas necessárias para seu arquivo robots.txt – essas também são as únicas diretivas suportadas pelo Google.
Mas e os outros motores de busca? No caso do Bing, Yahoo e Yandex, há mais uma diretiva que você pode usar:
Atraso de rastreamento
A diretiva de atraso de rastreamento é uma diretiva não oficial usada para impedir que os servidores sobrecarreguem com muitas solicitações de rastreamento.
Em outras palavras, você o usa para limitar a frequência com que um mecanismo de pesquisa pode rastrear seu site.

Lembre-se de que, se os mecanismos de pesquisa puderem sobrecarregar seu servidor rastreando seu site com frequência, adicionar a diretiva Atraso de rastreamento ao arquivo robots.txt corrigirá o problema apenas temporariamente.
O caso pode ser que seu site esteja sendo executado em uma hospedagem ruim ou em um ambiente de hospedagem mal configurado, e isso é algo que você deve corrigir rapidamente.
A diretiva de atraso de rastreamento funciona definindo o tempo em segundos entre o qual um Search Bot pode rastrear seu site.
Por exemplo, se você definir o atraso do rastreamento como 5, os bots de pesquisa dividirão o dia em janelas de cinco segundos, rastreando apenas uma página (ou nenhuma) em cada janela, para um máximo de cerca de 17.280 URLs durante o dia.
Sendo assim, tenha cuidado ao definir esta diretiva, especialmente se você tiver um site grande. Apenas 17.280 URLs rastreados por dia não são muito úteis se seu site tiver milhões de páginas.
A maneira como cada mecanismo de pesquisa lida com a diretiva de atraso de rastreamento é diferente. Vamos decompô-lo abaixo:
Atraso de rastreamento e Bing, Yahoo e Yandex
Bing, Yahoo e Yandex suportam a diretiva de atraso de rastreamento em robots.txt.
Isso significa que você pode definir uma diretiva de atraso de rastreamento para os agentes de usuário BingBot, Slurp e YandexBot, e o mecanismo de pesquisa limitará seu rastreamento de acordo.
Observe que cada mecanismo de pesquisa interpreta o atraso de rastreamento de maneira um pouco diferente , portanto, verifique sua documentação:
- Bing e Yahoo
- Yandex
Dito isso, o formato da diretiva de atraso de rastreamento para cada um desses mecanismos é o mesmo. Você deve colocá-lo logo após uma diretiva não permitir OU permitir. Aqui está um exemplo:
User-agent: BingBot Allow: /widgets/ Crawl-delay: 5Atraso de rastreamento e Google
O rastreador do Google não é compatível com a diretiva de atraso de rastreamento, portanto, não faz sentido definir um atraso de rastreamento para o GoogleBot em robots.txt.
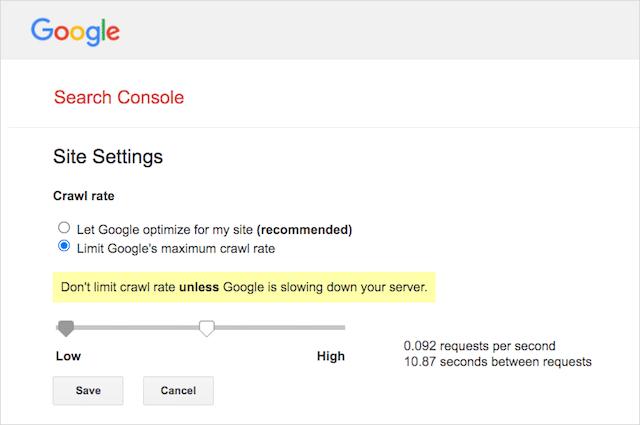
No entanto, o Google oferece suporte à definição de uma taxa de rastreamento no Google Search Console. Aqui está como fazê-lo:
- Vá para a página de configurações do Google Search Console.
- Escolha a propriedade para a qual você deseja definir a taxa de rastreamento
- Clique em "Limitar a taxa máxima de rastreamento do Google".
- Ajuste o controle deslizante para sua taxa de rastreamento preferida. Por padrão, a taxa de rastreamento tem a configuração "Permitir que o Google otimize para meu site (recomendado)".
Crawl-delay e Baidu
Assim como o Google, o Baidu não oferece suporte à diretiva de atraso de rastreamento. No entanto, é possível registrar uma conta Baidu Webmaster Tools na qual você pode controlar a frequência de rastreamento, semelhante ao Google Search Console.
A linha de fundo? Robots.txt diz aos spiders do mecanismo de pesquisa para não rastrear páginas específicas em seu site.
Robots.txt vs meta robots vs x-robots
Existem muitas instruções de “robôs” por aí. Quais são as diferenças, ou são iguais?
Deixe-me dar uma breve explicação:
Primeiramente, robots.txt é um arquivo de texto real, enquanto meta e x-robots são tags dentro do código de uma página da web.
Em segundo lugar, o robots.txt dá sugestões aos bots sobre como rastrear as páginas de um site. Por outro lado, as metadiretivas dos robôs fornecem instruções muito firmes sobre como rastrear e indexar o conteúdo de uma página.
Além do que são, os três têm funções diferentes.
Robots.txt dita o comportamento de rastreamento em todo o site ou diretório, enquanto meta e x-robots podem ditar o comportamento de indexação no nível de página individual (ou elemento de página).

No geral:
Se você quiser impedir que uma página seja indexada, use a meta-tag de robôs “no-index”. Não permitir uma página no robots.txt não garante que ela não será exibida nos mecanismos de pesquisa (afinal, as diretivas do robots.txt são sugestões). Além disso, um robô de mecanismo de pesquisa ainda pode encontrar esse URL e indexá-lo se estiver vinculado a outro site.

Pelo contrário, se você deseja impedir que um arquivo de mídia seja indexado, o robots.txt é o caminho a seguir. Você não pode adicionar meta tags de robôs a arquivos como jpegs ou PDFs.
Como encontrar seu Robots.txt
Se você já tiver um arquivo robots.txt em seu site, poderá acessá-lo em yourdomain.com/robots.txt.
Navegue até a URL em seu navegador.
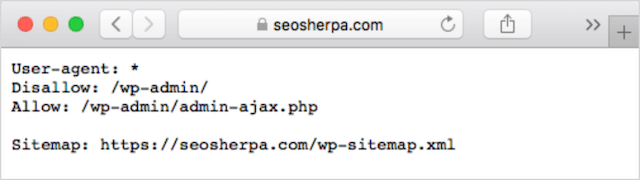
Se você vir uma página baseada em texto como a acima, então você tem um arquivo robots.txt.
Como criar um arquivo Robots.txt
Se você ainda não tem um arquivo robots.txt, criar um é simples.
Primeiro, abra o Bloco de Notas, o Microsoft Word ou qualquer editor de texto e salve o arquivo como 'robots'.
Certifique-se de usar letras minúsculas e escolha .txt como a extensão do tipo de arquivo:

Em segundo lugar, adicione suas diretivas. Por exemplo, se você quiser impedir que todos os bots de pesquisa rastreiem seu diretório /login/, digite isto:
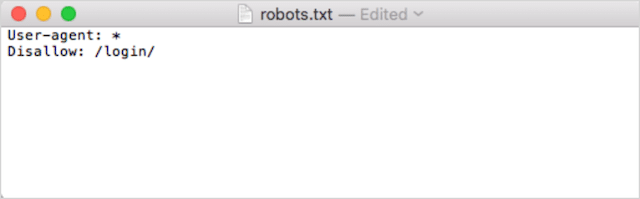
Continue a adicionar diretivas até ficar satisfeito com o arquivo robots.txt.
Alternativamente, você pode gerar seu robots.txt com uma ferramenta como esta da Ryte.

Uma vantagem de usar uma ferramenta é que ela minimiza o erro humano.
Apenas um pequeno erro na sintaxe do seu robots.txt pode terminar em um desastre de SEO.
Dito isso, a desvantagem de usar um gerador de robots.txt é que a oportunidade de personalização é mínima.
É por isso que eu recomendo que você aprenda a escrever um arquivo robot.txt você mesmo. Você pode então criar um robots.txt exatamente de acordo com seus requisitos.
Onde colocar seu arquivo Robots.txt
Adicione seu arquivo robots.txt no diretório de nível superior do subdomínio ao qual ele se aplica.
Por exemplo, para controlar o comportamento de rastreamento em yourdomain.com , o arquivo robots.txt deve estar acessível no caminho de URL yourdomain.com/robots.txt .
Por outro lado, se você deseja controlar o rastreamento em um subdomínio como shop.yourdomain.com , o arquivo robots.txt deve estar acessível no caminho de URL shop.yourdomain.com/robots.txt .
As regras de ouro são:
- Dê a cada subdomínio do seu site seu próprio arquivo robots.txt.
- Nomeie seu(s) arquivo(s) robots.txt em letras minúsculas.
- Coloque o arquivo no diretório raiz do subdomínio ao qual ele faz referência.
Se o arquivo robots.txt não puder ser encontrado no diretório raiz, os mecanismos de pesquisa assumirão que não há diretivas e rastrearão seu site em sua totalidade.
Práticas recomendadas do arquivo Robots.txt
Em seguida, vamos abordar as regras dos arquivos robots.txt. Use estas práticas recomendadas para evitar armadilhas comuns do robots.txt:
Use uma nova linha para cada diretiva
Cada diretiva em seu robots.txt deve estar em uma nova linha.
Caso contrário, os mecanismos de pesquisa ficarão confusos sobre o que rastrear (e indexar).
Isso, por exemplo, está configurado incorretamente :
User-agent: * Disallow: /folder/ Disallow: /another-folder/Este, por outro lado, é um arquivo robots.txt configurado corretamente :
User-agent: * Disallow: /folder/ Disallow: /another-folder/A especificidade “quase” sempre vence
Quando se trata de Google e Bing, a diretiva mais granular vence.
Por exemplo, esta diretiva Allow vence a diretiva Disallow porque seu comprimento de caractere é maior.
User-agent: * Disallow: /about/ Allow: /about/company/O Google e o Bing sabem rastrear /about/company/, mas não outras páginas no diretório /about/.
No entanto, no caso de outros motores de busca, o oposto é verdadeiro.
Por padrão, para todos os principais mecanismos de pesquisa, exceto Google e Bing, a primeira diretiva de correspondência sempre vence .
No exemplo acima, os mecanismos de pesquisa seguirão a diretiva Disallow e ignorarão a diretiva Allow, o que significa que a página /sobre/empresa não será rastreada.
Lembre-se disso ao criar regras para todos os mecanismos de pesquisa.
Apenas um grupo de diretivas por user agent
Se o seu robots.txt contivesse vários grupos de diretivas por agente de usuário, boh-oh-boy, poderia ficar confuso?
Não necessariamente para robôs, porque eles combinarão todas as regras das várias declarações em um grupo e seguirão todas elas, mas para você.
Para evitar a possibilidade de erro humano, indique o agente do usuário uma vez e, em seguida, liste todas as diretivas que se aplicam a esse agente do usuário abaixo.

Ao manter as coisas limpas e simples, é menos provável que você cometa um erro.
Use curingas (*) para simplificar as instruções
Você notou os curingas (*) no exemplo acima?
Isso mesmo; você pode usar curingas (*) para aplicar regras a todos os agentes de usuário E para corresponder aos padrões de URL ao declarar diretivas.
Por exemplo, se você quiser impedir que os bots de pesquisa acessem URLs de categorias de produtos parametrizados em seu site, você pode listar cada categoria assim:
User-agent: * Disallow: /products/watches? Disallow: /products/handbags? Disallow: /products/shoes?Ou você pode usar um curinga que aplicaria a regra a todas as categorias. Veja como ficaria:
User-agent: * Disallow: /products/*?Este exemplo impede que os mecanismos de pesquisa rastreiem todos os URLs na subpasta /product/ que contenham um ponto de interrogação. Em outras palavras, qualquer URL de categoria de produto parametrizado.
Google, Bing, Yahoo suportam o uso de curingas dentro das diretivas robots.txt e Ask.
Use “$” para especificar o final de um URL
Para indicar o final de um URL, use o cifrão ( $ ) após o caminho do robots.txt.
Digamos que você queira impedir que os bots de busca acessem todos os arquivos .doc em seu site; então você usaria esta diretiva:
User-agent: * Disallow: /*.doc$Isso impediria que os mecanismos de pesquisa acessassem qualquer URL que terminasse com .doc.
Isso significa que eles não rastreariam /media/file.doc, mas rastreariam /media/file.doc?id=72491 porque esse URL não termina com ".doc".
Cada subdomínio recebe seu próprio robots.txt
As diretivas Robots.txt se aplicam apenas ao (sub)domínio em que o arquivo robots.txt está hospedado.
Isso significa que se seu site tiver vários subdomínios como:
- domínio.com
- tickets.domínio.com
- eventos.domínio.com
Cada subdomínio exigirá seu próprio arquivo robots.txt.
O robots.txt deve sempre ser adicionado no diretório raiz de cada subdomínio. Veja como seriam os caminhos usando o exemplo acima:
- domain.com/robots.txt
- tickets.domain.com/robots.txt
- events.domain.com/robots.txt
Não use noindex em seu robots.txt
Simplificando, o Google não oferece suporte à diretiva no-index em robots.txt.
Embora o Google o tenha seguido no passado, em julho de 2019, o Google parou de apoiá-lo completamente.
E se você está pensando em usar a diretiva no-index robots.txt para conteúdo no-index em outros mecanismos de busca, pense novamente:
A diretiva não oficial sem índice nunca funcionou no Bing.
De longe, o melhor método para conteúdo sem índice nos mecanismos de pesquisa é aplicar uma meta-tag de robôs sem índice à página que você deseja excluir.
Mantenha seu arquivo robots.txt abaixo de 512 KB
Atualmente, o Google tem um limite de tamanho de arquivo robots.txt de 500 kibibytes (512 kilobytes).
Isso significa que qualquer conteúdo após 512 KB pode ser ignorado.

Dito isso, dado que um caractere consome apenas um byte, seu robots.txt precisaria ser ENORME para atingir esse limite de tamanho de arquivo (512.000 caracteres, para ser exato). Mantenha seu arquivo robots.txt enxuto concentrando-se menos em páginas excluídas individualmente e mais em padrões mais amplos que os curingas podem controlar.
Não está claro se outros mecanismos de pesquisa têm o tamanho máximo de arquivo permitido para arquivos robots.txt.
Exemplos de robots.txt
Abaixo estão alguns exemplos de arquivos robots.txt.
Eles incluem combinações das diretrizes que nossa agência de SEO mais usa nos arquivos robots.txt para clientes. Tenha em mente, porém; estes são apenas para fins de inspiração. Você sempre precisará personalizar o arquivo robots.txt para atender aos seus requisitos.
Permitir que todos os robôs acessem tudo
Este arquivo robots.txt não fornece regras de proibição para todos os mecanismos de pesquisa:
User-agent: * Disallow:Em outras palavras, permite que os bots de pesquisa rastreiem tudo. Ele serve ao mesmo propósito que um arquivo robots.txt vazio ou nenhum robots.txt.
Impedir que todos os robôs acessem tudo
O arquivo robots.txt de exemplo informa a todos os mecanismos de pesquisa para não acessar nada após a barra final. Em outras palavras, todo o domínio:
User-agent: * Disallow: /Resumindo, esse arquivo robots.txt bloqueia todos os robôs de mecanismos de pesquisa e pode impedir que seu site seja exibido nas páginas de resultados de pesquisa.
Impedir que todos os robôs rastreiem um arquivo
Neste exemplo, bloqueamos todos os bots de pesquisa de rastrear um arquivo específico.
User-agent: * Disallow: /directory/this-is-a-file.pdfImpedir que todos os robôs rastreiem um tipo de arquivo (doc, pdf, jpg)
Como não há indexação, um arquivo como 'doc' ou 'pdf' não pode ser feito usando uma tag meta robot “no-index”; você pode usar a diretiva a seguir para impedir que um tipo de arquivo específico seja indexado.
User-agent: * Disallow: /*.doc$ Disallow: /*.pdf$ Disallow: /*.jpg$Isso funcionará para desindexar todos os arquivos desse tipo, desde que nenhum arquivo individual esteja vinculado a outro lugar na web.
Impedir que o Google rastreie vários diretórios
Você pode querer bloquear o rastreamento de vários diretórios para um bot específico ou todos os bots. Neste exemplo, estamos impedindo o Googlebot de rastrear dois subdiretórios.
User-agent: Googlebot Disallow: /admin/ Disallow: /private/Observe que não há limite no número de diretórios que você pode usar bock. Basta listar cada um abaixo do agente do usuário ao qual a diretiva se aplica.
Impedir que o Google rastreie todos os URLs parametrizados
Essa diretiva é particularmente útil para sites que usam navegação facetada, onde muitos URLs parametrizados podem ser criados.
User-agent: Googlebot Disallow: /*?Essa diretiva impede que seu orçamento de rastreamento seja consumido em URLs dinâmicos e maximiza o rastreamento de páginas importantes. Eu uso isso regularmente, principalmente em sites de comércio eletrônico com funcionalidade de pesquisa.
Impedir que todos os bots rastreiem um subdiretório, mas permitindo que uma página seja rastreada
Às vezes, você pode querer impedir que os rastreadores acessem uma seção completa do seu site, mas deixe uma página acessível. Se você fizer isso, use a seguinte combinação de diretivas 'allow' e 'disallow':
User-agent: * Disallow: /category/ Allow: /category/widget/Ele informa aos mecanismos de pesquisa para não rastrear o diretório completo, excluindo uma página ou arquivo específico.
Robots.txt para WordPress
Esta é a configuração básica que eu recomendo para um arquivo robots.txt do WordPress. Ele bloqueia o rastreamento de páginas e tags de administração e URLs de autores, o que pode criar lixo desnecessário em um site WordPress.
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /wp-admin/ Disallow: /readme.html Disallow: /refer/ Disallow: /tag/ Disallow: /author/ Disallow: /404-error/ Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xmlEste arquivo robots.txt funcionará bem para a maioria dos sites WordPress, mas é claro que você deve sempre ajustá-lo aos seus próprios requisitos.
Como auditar seu arquivo Robots.txt quanto a erros
No meu tempo, eu vi mais erros de impacto de classificação em arquivos robots.txt do que talvez qualquer outro aspecto de SEO técnico. Com tantas diretivas potencialmente conflitantes, problemas podem ocorrer e ocorrem.
Portanto, quando se trata de arquivos robots.txt, vale a pena ficar de olho nos problemas.
Felizmente, o relatório "Cobertura" no Google Search Console fornece uma maneira de verificar e monitorar problemas de robots.txt.
Você também pode usar a Ferramenta de teste Robots.txt do Google para verificar erros em seu arquivo robots ativo ou testar um novo arquivo robots.txt antes de implantá-lo.
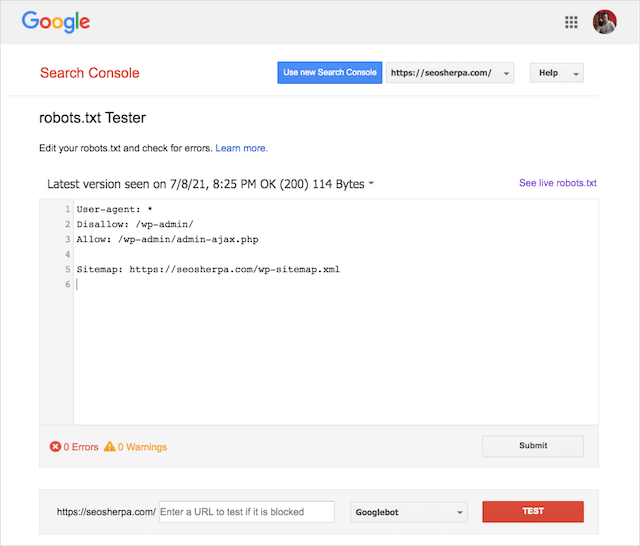
Terminaremos abordando os problemas mais comuns, o que eles significam e como resolvê-los.
URL enviado bloqueado por robots.txt
Esse erro significa que pelo menos um dos URLs nos seus sitemaps enviados está bloqueado pelo robots.txt.

Um sitemap configurado corretamente deve incluir apenas os URLs que você deseja indexar nos mecanismos de pesquisa . Como tal, não deve conter nenhuma página não indexada, canonizada ou redirecionada.
Se você seguiu essas práticas recomendadas, nenhuma página enviada em seu sitemap deverá ser bloqueada pelo robots.txt.
Se você vir "URL enviado bloqueado por robots.txt" no relatório de cobertura, deverá investigar quais páginas são afetadas e, em seguida, alterne o arquivo robots.txt para remover o bloqueio dessa página.
Você pode usar o testador robots.txt do Google para ver qual diretiva está bloqueando o conteúdo.
Bloqueado por Robots.txt
Este "erro" significa que você tem páginas bloqueadas pelo seu robots.txt que não estão atualmente no índice do Google.

Se esse conteúdo tiver utilidade e precisar ser indexado, remova o bloco de rastreamento em robots.txt.
Uma breve palavra de advertência:
"Bloqueado por robots.txt" não é necessariamente um erro. De fato, pode ser precisamente o resultado que você deseja.
Por exemplo, você pode ter bloqueado determinados arquivos no robots.txt com a intenção de excluí-los do índice do Google. Por outro lado, se você bloqueou o rastreamento de determinadas páginas com a intenção de não indexá-las, considere remover o bloqueio de rastreamento e usar a metatag de um robô.
Essa é a única maneira de garantir a exclusão de conteúdo do índice do Google.
Indexado, embora bloqueado por Robots.txt
Esse erro significa que parte do conteúdo bloqueado pelo robots.txt ainda está indexado no Google.
Isso acontece quando o conteúdo ainda pode ser descoberto pelo Googlebot porque está vinculado a outro lugar na web. Em resumo, o Googlebot acessa esse conteúdo rastreado e o indexa antes de visitar o arquivo robots.txt do seu site, onde vê a diretiva não permitida.
Até então, é tarde demais. E fica indexado:
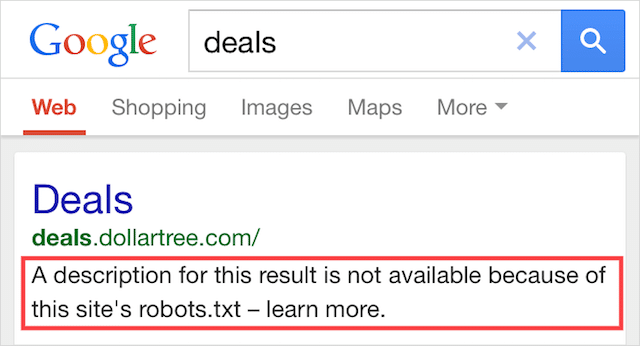
Deixe-me perfurar esta casa:
Se você estiver tentando excluir conteúdo dos resultados de pesquisa do Google, robots.txt não é a solução correta.
Eu recomendo remover o bloco de rastreamento e usar uma tag no-index meta robots para evitar a indexação.
Pelo contrário, se você bloqueou este conteúdo por acidente e deseja mantê-lo no índice do Google, remova o bloqueio de rastreamento em robots.txt e deixe por isso mesmo.
Isso pode ajudar a melhorar a visibilidade do conteúdo na pesquisa do Google.
Pensamentos finais
Robots.txt pode ser usado para melhorar o rastreamento e a indexação do conteúdo do seu site, o que ajuda você a se tornar mais visível nas SERPs.
Quando usado de forma eficaz, é o texto mais importante do seu site. Mas, quando usado de forma descuidada, será o calcanhar de Aquiles no código do seu site.
A boa notícia, com apenas uma compreensão básica dos agentes do usuário e um punhado de diretivas, melhores resultados de pesquisa estão ao seu alcance.
A única questão é: quais protocolos você usará em seu arquivo robots.txt?
Deixe-me saber nos comentários abaixo.