
Robots.txt: Ghidul suprem pentru SEO (ediția 2021)
Publicat: 2021-06-10 Astăzi veți învăța cum să creați unul dintre cele mai importante fișiere pentru SEO a unui site web:
Astăzi veți învăța cum să creați unul dintre cele mai importante fișiere pentru SEO a unui site web:
(Fișierul robots.txt).
Mai exact, vă voi arăta cum să utilizați protocoalele de excludere a roboților pentru a bloca roboții din anumite pagini, pentru a crește frecvența accesării cu crawlere, a optimiza bugetul de accesare cu crawlere și, în cele din urmă, a obține mai mult din clasarea paginii potrivite în SERP-uri.
acopăr:
- Ce este un fișier robots.txt
- De ce robots.txt este important
- Cum funcționează robots.txt
- Agenți și directive Robots.txt
- Robots.txt Vs meta-roboți
- Cum să vă găsiți robots.txt
- Se creează fișierul robots.txt
- Cele mai bune practici pentru fișierul Robots.txt
- Exemple Robots.txt
- Cum să auditați fișierul robots.txt pentru erori
În plus, mult mai mult. Să ne scufundăm direct.
Ce este un fișier Robots.txt? Și de ce ai nevoie de unul
În termeni simpli, un fișier robots.txt este un manual de instrucțiuni pentru roboții web.
Acesta informează roboții de toate tipurile, care secțiuni ale unui site ar trebui (și nu ar trebui) să le acceseze cu crawlere.
Acestea fiind spuse, robots.txt este folosit în primul rând ca un „cod de conduită” pentru a controla activitatea roboților motoarelor de căutare (AKA web crawler).

Robots.txt este verificat în mod regulat de fiecare motor de căutare major (inclusiv Google, Bing și Yahoo) pentru instrucțiuni despre cum ar trebui să acceseze cu crawlere site-ul. Aceste instrucțiuni sunt cunoscute ca directive .
Dacă nu există directive – sau niciun fișier robots.txt – motoarele de căutare vor accesa cu crawlere întregul site web, paginile private și tot.
Deși majoritatea motoarelor de căutare sunt ascultătoare, este important să rețineți că respectarea directivelor robots.txt este opțională. Dacă doresc, motoarele de căutare pot alege să ignore fișierul robots.txt.
Din fericire, Google nu este unul dintre acele motoare de căutare. Google tinde să respecte instrucțiunile dintr-un fișier robots.txt.
De ce este important Robots.txt?
A avea un fișier robots.txt nu este critic pentru multe site-uri web, în special pentru cele mici.
Asta pentru că, de obicei, Google poate găsi și indexa toate paginile esențiale de pe un site.
Și, ei NU vor indexa automat conținutul duplicat sau paginile care nu sunt importante.
Dar totuși, nu există niciun motiv întemeiat să nu aveți un fișier robots.txt – așa că vă recomand să aveți unul.
Un fișier robots.txt vă oferă un control mai mare asupra a ceea ce motoarele de căutare pot și nu pot accesa cu crawlere pe site-ul dvs. web, iar acest lucru este util din mai multe motive:
Permite blocarea paginilor non-publice din motoarele de căutare
Uneori aveți pagini pe site-ul dvs. pe care nu doriți să le indexați.
De exemplu, s-ar putea să dezvoltați un nou site web într-un mediu de pregătire pe care doriți să vă asigurați că este ascuns utilizatorilor până la lansare.
Sau este posibil să aveți pagini de conectare pe site pe care nu doriți să le apară în SERP-uri.
Dacă acesta ar fi cazul, ați putea folosi robots.txt pentru a bloca aceste pagini de crawlerele motoarelor de căutare.
Controlează bugetul de accesare cu crawlere a motorului de căutare
Dacă vă este greu să vă indexați toate paginile în motoarele de căutare, este posibil să aveți o problemă cu bugetul de accesare cu crawlere.
Mai simplu spus, motoarele de căutare folosesc timpul alocat pentru a accesa cu crawlere conținutul dvs. pe paginile de pe site-ul dvs. web.

Prin blocarea adreselor URL cu utilitate redusă cu robots.txt, roboții motoarelor de căutare își pot cheltui mai mult din bugetul de accesare cu crawlere în paginile care contează cel mai mult.
Previne indexarea resurselor
Este cea mai bună practică să folosiți directiva meta „fără index” pentru a împiedica indexarea paginilor individuale.
Problema este că metadirectivele nu funcționează bine pentru resursele multimedia, cum ar fi PDF-urile și documentele Word.
Acolo este locul în care robots.txt este la îndemână.
Puteți adăuga o linie simplă de text la fișierul dvs. robots.txt, iar motoarele de căutare vor fi blocate să acceseze aceste fișiere multimedia.
(Îți voi arăta exact cum să faci asta mai târziu în această postare)
Cum (exact) funcționează un Robots.txt?
După cum am împărtășit deja, un fișier robots.txt acționează ca un manual de instrucțiuni pentru roboții motoarelor de căutare. Le spune roboților de căutare unde (și unde nu) ar trebui să se acceseze cu crawlere.
Acesta este motivul pentru care un crawler de căutare va căuta un fișier robots.txt de îndată ce ajunge pe un site web.
Dacă găsește robots.txt, crawler-ul îl va citi mai întâi înainte de a continua accesarea cu crawlere a site-ului.
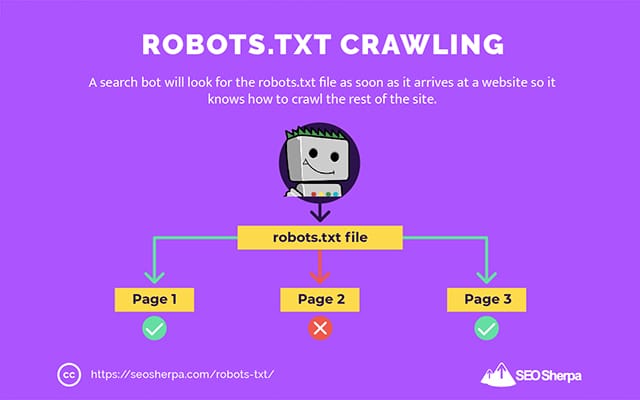
Dacă crawler-ul web nu găsește un robots.txt sau fișierul nu conține directive care interzic activitatea roboților de căutare, crawler-ul va continua să acceseze întregul site ca de obicei.
Pentru ca un fișier robots.txt să poată fi găsit și citit de către roboții de căutare, un fișier robots.txt este formatat într-un mod foarte special.
În primul rând, este un fișier text fără cod de markup HTML (de unde și extensia .txt).
În al doilea rând, este plasat în folderul rădăcină al site-ului web, de exemplu, https://seosherpa.com/robots.txt.
În al treilea rând, folosește o sintaxă standard care este comună tuturor fișierelor robots.txt, astfel:
Sitemap: [URL location of sitemap] User-agent: [bot identifier] [directive 1] [directive 2] [directive ...] User-agent: [another bot identifier] [directive 1] [directive 2] [directive ...]Această sintaxă poate părea descurajantă la prima vedere, dar de fapt este destul de simplă.
Pe scurt, definiți botul (agentul utilizator) căruia i se aplică instrucțiunile și apoi stabiliți regulile (directivele) pe care botul ar trebui să le urmeze.
Să explorăm aceste două componente mai detaliat.
User-Agenți
Un user-agent este numele folosit pentru a defini anumite crawler-uri web – și alte programe active pe internet.
Există literalmente sute de agenți utilizatori, inclusiv agenți pentru tipurile de dispozitive și browsere.
Cele mai multe sunt irelevante în contextul unui fișier robots.txt și SEO. Pe de altă parte, acestea ar trebui să știți:
- Google: Googlebot
- Imagini Google: Googlebot-Imagine
- Google Video: Googlebot-Video
- Știri Google: Googlebot-News
- Bing: Bingbot
- Imagini și videoclipuri Bing: MSNBot-Media
- Yahoo: Slurp
- Yandex: YandexBot
- Baidu : Baiduspider
- DuckDuckGo: DuckDuckBot
Declarând agentul utilizator, puteți seta reguli diferite pentru diferite motoare de căutare.

De exemplu, dacă doriți ca o anumită pagină să apară în rezultatele căutării Google, dar nu în căutările Baidu, puteți include două seturi de comenzi în fișierul robots.txt: un set precedat de „User-agent: Bingbot” și un set precedat. de către „User-agent: Baiduspider”.
De asemenea, puteți utiliza caracterul joker stea (*) dacă doriți ca directivele dvs. să se aplice tuturor agenților utilizator.
De exemplu, să presupunem că doriți să blocați toți roboții motoarelor de căutare de la accesarea cu crawlere a site-ului dvs., cu excepția DuckDuckGo. Iată cum ați proceda:
User-agent: * Disallow: / User-agent: DuckDuckBot Allow: /Notă secundară: dacă există comenzi contradictorii în fișierul robots.txt, bot-ul va urma comanda mai granulară.
De aceea, în exemplul de mai sus, DuckDuckBot știe să acceseze cu crawlere site-ul, chiar dacă o directivă anterioară (aplicabilă tuturor roboților) spunea să nu se acceseze cu crawlere. Pe scurt, un bot va urma instrucțiunile care li se aplică cel mai precis.
Directive
Directivele sunt codul de conduită pe care doriți să îl urmeze utilizatorul-agent. Cu alte cuvinte, directivele definesc modul în care botul de căutare ar trebui să acceseze cu crawlere site-ul dvs.
Iată directivele pe care GoogleBot le acceptă în prezent, împreună cu utilizarea lor într-un fișier robots.txt:
Nu permiteți
Utilizați această directivă pentru a împiedica roboții de căutare să acceseze cu crawlere anumite fișiere și pagini pe o anumită cale URL.

De exemplu, dacă doriți să blocați GoogleBot să acceseze wiki-ul și toate paginile sale, robots.txt-ul dvs. ar trebui să conțină această directivă:
User-agent: GoogleBot Disallow: /wikiPuteți folosi directiva disallow pentru a bloca accesarea cu crawlere a unei adrese URL precise, a tuturor fișierelor și paginilor dintr-un anumit director și chiar a întregului site web.
Permite
Directiva allow este utilă dacă doriți să permiteți motoarelor de căutare să acceseze cu crawlere un anumit subdirector sau pagină – într-o secțiune altfel interzisă a site-ului dvs.

Să presupunem că doriți să împiedicați toate motoarele de căutare să acceseze cu crawlere postările de pe blogul dvs., cu excepția unuia; atunci ai folosi directiva allow astfel:
User-agent: * Disallow: /blog Allow: /blog/allowable-postDeoarece roboții de căutare urmează întotdeauna cele mai detaliate instrucțiuni date într-un fișier robots.txt, ei știu să acceseze cu crawlere /blog/allowable-post, dar nu vor accesa cu crawlere alte postări sau fișiere din acel director, cum ar fi;
- /blog/post-one/
- /blog/post-doi/
- /blog/file-name.pdf
Atât Google, cât și Bing acceptă această directivă. Dar alte motoare de căutare nu.
Harta site-ului
Directiva sitemap este utilizată pentru a specifica locația sitemap-urilor dvs. XML pentru motoarele de căutare.
Dacă sunteți nou în hărțile de site, acestea sunt folosite pentru a enumera paginile pe care doriți să le accesați cu crawlere și să le indexați în motoarele de căutare.
Prin includerea directivei sitemap în robots.txt, ajutați motoarele de căutare să vă găsească harta site-ului și, la rândul lor, să acceseze cu crawlere și să indexeze cele mai importante pagini ale site-ului dvs.
Acestea fiind spuse, dacă ați trimis deja sitemap-ul dvs. XML prin Search Console, adăugarea sitemap-urilor dvs. în robots.txt este oarecum redundantă pentru Google. Cu toate acestea, este cea mai bună practică să utilizați directiva sitemap, deoarece le spune motoarele de căutare precum Ask, Bing și Yahoo unde pot fi găsite sitemap-urile dvs.
Iată un exemplu de fișier robots.txt care utilizează directiva sitemap:
Sitemap: https://www.website.com/sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/Observați plasarea directivei sitemap în fișierul robots.txt. Este cel mai bine plasat în partea de sus a fișierului robots.txt. Poate fi plasat și în partea de jos.
Dacă aveți mai multe hărți de site, ar trebui să le includeți pe toate în fișierul robots.txt. Iată cum ar putea arăta fișierul robots.txt dacă am avea sitemap-uri XML separate pentru pagini și postări:
Sitemap: http://website.com/post-sitemap.xml Sitemap: http://website.com/page-sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/În orice caz, trebuie să menționați o singură dată fiecare sitemap XML, deoarece toți agenții utilizatori acceptați vor urma directiva.
Rețineți că, spre deosebire de alte directive robots.txt, care listează căile, directiva sitemap trebuie să indice adresa URL absolută a sitemap-ului dvs. XML, inclusiv protocolul, numele domeniului și extensia de domeniu de nivel superior.
Comentarii
Comentariul „directiva” este util pentru oameni, dar nu este folosit de roboții de căutare.

Puteți adăuga comentarii pentru a vă reaminti de ce există anumite directive sau îi puteți împiedica pe cei cu acces la robots.txt să șteargă directive importante. Pe scurt, comentariile sunt folosite pentru a adăuga note în fișierul robots.txt.
Pentru a adăuga un comentariu, tastați.” #" urmat de textul comentariului.
# Don't allow access to the /wp-admin/ directory for all robots. User-agent: * Disallow: /wp-admin/Puteți adăuga un comentariu la începutul unei linii (așa cum se arată mai sus) sau după o directivă pe aceeași linie (după cum se arată mai jos):
User-agent: * #Applies to all robots Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.Oriunde ați alege să vă scrieți comentariul, totul după hash va fi ignorat.
Urmăriți până acum?
Grozav! Am acoperit acum principalele directive de care veți avea nevoie pentru fișierul robots.txt – acestea sunt, de asemenea, singurele directive acceptate de Google.
Dar cum rămâne cu alte motoare de căutare? În cazul Bing, Yahoo și Yandex, mai există o directivă pe care o puteți folosi:
Întârziere accesare cu crawlere
Directiva Crawl-delay este o directivă neoficială folosită pentru a preveni supraîncărcarea serverelor cu prea multe solicitări de accesare cu crawlere.
Cu alte cuvinte, îl folosiți pentru a limita frecvența pe care un motor de căutare poate accesa cu crawlere site-ul dvs.

Rețineți, dacă motoarele de căutare vă pot supraîncărca serverul accesând cu crawlere frecvent site-ul dvs., adăugarea directivei Crawl-delay la fișierul robots.txt va rezolva problema doar temporar.
Cazul poate fi, site-ul dvs. rulează pe găzduire proastă sau pe un mediu de găzduire configurat greșit, iar asta ar trebui să remediați rapid.
Directiva de întârziere a accesării cu crawlere funcționează prin definirea timpului în secunde între care un robot de căutare poate accesa cu crawlere site-ul dvs.
De exemplu, dacă setați întârzierea accesării cu crawlere la 5, roboții de căutare vor împărți ziua în ferestre de cinci secunde, accesând cu crawlere doar o pagină (sau niciuna) în fiecare fereastră, pentru un maximum de aproximativ 17.280 de adrese URL în timpul zilei.
Așa fiind, aveți grijă când setați această directivă, mai ales dacă aveți un site web mare. Doar 17.280 de adrese URL accesate cu crawlere pe zi nu sunt de mare ajutor dacă site-ul dvs. are milioane de pagini.
Modul în care fiecare motor de căutare gestionează directiva crawl-delay diferă. Să o detaliem mai jos:
Crawl-delay și Bing, Yahoo și Yandex
Bing, Yahoo și Yandex acceptă directiva crawl-delay în robots.txt.
Aceasta înseamnă că puteți seta o directivă de întârziere a accesului cu crawlere pentru agenții de utilizator BingBot, Slurp și YandexBot, iar motorul de căutare își va reduce accesul cu crawlere în consecință.
Rețineți că fiecare motor de căutare interpretează întârzierea accesului cu crawlere într-un mod ușor diferit , așa că asigurați-vă că verificați documentația:
- Bing și Yahoo
- Yandex
Acestea fiind spuse, formatul directivei crawl-delay pentru fiecare dintre aceste motoare este același. Trebuie să-l plasați imediat după o directivă disallow OR allow. Iată un exemplu:
User-agent: BingBot Allow: /widgets/ Crawl-delay: 5Crawl-delay și Google
Crawler-ul Google nu acceptă directiva crawl-delay, așa că nu are rost să setați o întârziere de crawl pentru GoogleBot în robots.txt.
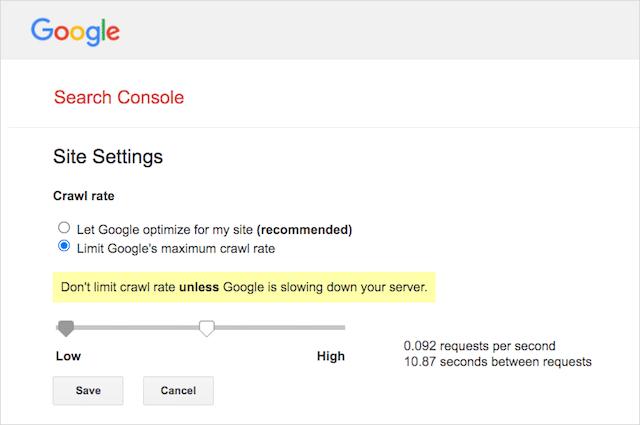
Cu toate acestea, Google acceptă definirea unei rate de accesare cu crawlere în Google Search Console. Iată cum să o faci:
- Accesați pagina de setări a Google Search Console.
- Alegeți proprietatea pentru care doriți să definiți rata de accesare cu crawlere
- Faceți clic pe „Limitați rata maximă de accesare cu crawlere a Google”.
- Ajustați glisorul la rata de accesare cu crawlere preferată. În mod implicit, rata de accesare cu crawlere are setarea „Lăsați Google să optimizeze pentru site-ul meu (recomandat).”
Crawl-delay și Baidu
La fel ca Google, Baidu nu acceptă directiva de întârziere a accesului cu crawlere. Cu toate acestea, este posibil să înregistrați un cont Baidu Webmaster Tools în care puteți controla frecvența de accesare cu crawlere, similar cu Google Search Console.
Linia de jos? Robots.txt le spune păianjenilor motoarelor de căutare să nu acceseze cu crawlere anumite pagini de pe site-ul dvs.
Robots.txt vs meta roboți vs x-roboți
Există o mulțime de instrucțiuni pentru „roboți” acolo. Care sunt diferențele sau sunt aceleași?
Permiteți-mi să ofer o scurtă explicație:
În primul rând, robots.txt este un fișier text real, în timp ce meta și x-roboții sunt etichete în codul unei pagini web.
În al doilea rând, robots.txt oferă roboților sugestii despre cum să acceseze cu crawlere paginile unui site web. Pe de altă parte, meta-directivele roboților oferă instrucțiuni foarte ferme despre accesarea cu crawlere și indexarea conținutului unei pagini.
Dincolo de ceea ce sunt, cele trei au toate funcții diferite.
Robots.txt dictează comportamentul de accesare cu crawlere la nivel de site sau director, în timp ce robotii meta și x-roboții pot dicta comportamentul de indexare la nivel de pagină individuală (sau element de pagină).

În general:
Dacă doriți să opriți indexarea unei pagini, ar trebui să utilizați eticheta meta roboti „fără index”. Interzicerea unei pagini în robots.txt nu garantează că nu va fi afișată în motoarele de căutare (directivele robots.txt sunt sugestii, până la urmă). În plus, un robot de motor de căutare ar putea găsi acea adresă URL și să o indexeze dacă este legată de un alt site web.

Dimpotrivă, dacă doriți să opriți indexarea unui fișier media, robots.txt este calea de urmat. Nu puteți adăuga etichete meta-roboți la fișiere precum jpeg sau PDF.
Cum să vă găsiți Robots.txt
Dacă aveți deja un fișier robots.txt pe site-ul dvs. web, îl veți putea accesa la yourdomain.com/robots.txt.
Navigați la adresa URL din browser.
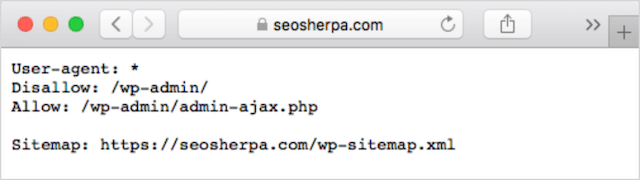
Dacă vedeți o pagină bazată pe text precum cea de mai sus, atunci aveți un fișier robots.txt.
Cum se creează un fișier Robots.txt
Dacă nu aveți deja un fișier robots.txt, crearea unuia este simplă.
Mai întâi, deschideți Notepad, Microsoft Word sau orice editor de text și salvați fișierul ca „roboți”.
Asigurați-vă că utilizați litere mici și alegeți .txt ca extensie de tip de fișier:

În al doilea rând, adăugați directivele dvs. De exemplu, dacă doriți să interziceți tuturor roboților de căutare să acceseze cu crawlere directorul dvs. /login/, ați introduce acest lucru:
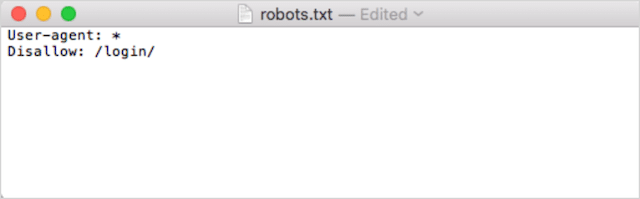
Continuați să adăugați directive până când sunteți mulțumit de fișierul robots.txt.
Alternativ, puteți genera robots.txt cu un instrument ca acesta de la Ryte.

Un avantaj al utilizării unui instrument este că minimizează erorile umane.
Doar o mică greșeală în sintaxa dvs. robots.txt s-ar putea duce la un dezastru SEO.
Acestea fiind spuse, dezavantajul utilizării unui generator robots.txt este că oportunitatea de personalizare este minimă.
De aceea, vă recomand să învățați să scrieți singur un fișier robot.txt. Apoi puteți construi un robots.txt exact conform cerințelor dvs.
Unde să puneți fișierul Robots.txt
Adăugați fișierul robots.txt în directorul de nivel superior al subdomeniului căruia i se aplică.
De exemplu, pentru a controla comportamentul de accesare cu crawlere pe domeniul yourdomain.com , fișierul robots.txt ar trebui să fie accesibil pe calea URL yourdomain.com/robots.txt .
Pe de altă parte, dacă doriți să controlați accesarea cu crawlere pe un subdomeniu precum shop.yourdomain.com , robots.txt ar trebui să fie accesibil pe calea URL shop.yourdomain.com/robots.txt .
Regulile de aur sunt:
- Oferiți fiecărui subdomeniu de pe site-ul dvs. propriul fișier robots.txt.
- Denumiți fișierele dvs. robots.txt , toate cu litere mici.
- Plasați fișierul în directorul rădăcină al subdomeniului la care face referire.
Dacă fișierul robots.txt nu poate fi găsit în directorul rădăcină, motoarele de căutare vor presupune că nu există directive și vor accesa cu crawlere site-ul dvs. în întregime.
Cele mai bune practici pentru fișierul Robots.txt
În continuare, să acoperim regulile fișierelor robots.txt. Utilizați aceste bune practici pentru a evita capcanele obișnuite ale robots.txt:
Utilizați o nouă linie pentru fiecare directivă
Fiecare directivă din robots.txt trebuie să se afle pe o nouă linie.
Dacă nu, motoarele de căutare vor deveni confuze cu privire la ce să acceseze cu crawlere (și să indexeze).
Acesta, de exemplu, este configurat incorect :
User-agent: * Disallow: /folder/ Disallow: /another-folder/Acesta, pe de altă parte, este un fișier robots.txt configurat corect :
User-agent: * Disallow: /folder/ Disallow: /another-folder/Specificitatea „aproape” câștigă întotdeauna
Când vine vorba de Google și Bing, directiva mai granulară câștigă.
De exemplu, această directivă Allow învinge directiva Disallow deoarece lungimea caracterelor sale este mai mare.
User-agent: * Disallow: /about/ Allow: /about/company/Google și Bing știu să acceseze cu crawlere /about/company/, dar nu orice alte pagini din directorul /about/.
Cu toate acestea, în cazul altor motoare de căutare, este adevărat invers.
În mod implicit, pentru toate motoarele de căutare majore, altele decât Google și Bing, prima directivă de potrivire câștigă întotdeauna .
În exemplul de mai sus, motoarele de căutare vor urma directiva Disallow și vor ignora directiva Allow, ceea ce înseamnă că pagina /about/company nu va fi accesată cu crawlere.
Țineți cont de acest lucru atunci când creați reguli pentru toate motoarele de căutare.
Doar un grup de directive per user-agent
Dacă robots.txt conține mai multe grupuri de directive pentru fiecare agent utilizator, boh-oh-boy, ar putea deveni confuz?
Nu neapărat pentru roboți, deoarece ei vor combina toate regulile din diferitele declarații într-un singur grup și le vor urma pe toate, dar pentru tine.
Pentru a evita potențialul de eroare umană, indicați user-agent o dată și apoi enumerați mai jos toate directivele care se aplică acelui user agent.

Păstrând lucrurile îngrijite și simple, este mai puțin probabil să faci o gafă.
Folosiți caracterele joker (*) pentru a simplifica instrucțiunile
Ați observat metacaracterele (*) în exemplul de mai sus?
Asta e corect; puteți folosi metacaracterele (*) pentru a aplica reguli tuturor agenților utilizator ȘI pentru a potrivi modelele URL atunci când declarați directive.
De exemplu, dacă doriți să împiedicați roboții de căutare să acceseze adrese URL ale categoriilor de produse parametrizate pe site-ul dvs., puteți enumera fiecare categorie astfel:
User-agent: * Disallow: /products/watches? Disallow: /products/handbags? Disallow: /products/shoes?Sau, puteți utiliza un wildcard care ar aplica regula tuturor categoriilor. Iată cum ar arăta:
User-agent: * Disallow: /products/*?Acest exemplu blochează motoarele de căutare să acceseze cu crawlere toate adresele URL din subdosarul /produs/ care conțin un semn de întrebare. Cu alte cuvinte, orice adrese URL ale categoriei de produse care sunt parametrizate.
Google, Bing, Yahoo acceptă utilizarea metacaracterilor în directivele robots.txt și Ask.
Utilizați „$” pentru a specifica sfârșitul unei adrese URL
Pentru a indica sfârșitul unei adrese URL, utilizați semnul dolar ( $ ) după calea robots.txt.
Să presupunem că doriți să opriți accesarea roboților de căutare a tuturor fișierelor .doc de pe site-ul dvs. web; atunci ai folosi această directivă:
User-agent: * Disallow: /*.doc$Acest lucru ar împiedica motoarele de căutare să acceseze orice URL care se termină cu .doc.
Aceasta înseamnă că nu ar accesa cu crawlere /media/file.doc, dar ar accesa cu crawlere /media/file.doc?id=72491, deoarece acea adresă URL nu se termină cu „.doc”.
Fiecare subdomeniu primește propriul său robots.txt
Directivele Robots.txt se aplică numai pentru (sub)domeniul în care este găzduit fișierul robots.txt.
Aceasta înseamnă că dacă site-ul dvs. are mai multe subdomenii, cum ar fi:
- domeniu.com
- tickets.domain.com
- events.domain.com
Fiecare subdomeniu va necesita propriul fișier robots.txt.
Robots.txt ar trebui să fie adăugat întotdeauna în directorul rădăcină al fiecărui subdomeniu. Iată cum ar arăta căile folosind exemplul de mai sus:
- domain.com/robots.txt
- tickets.domain.com/robots.txt
- events.domain.com/robots.txt
Nu utilizați noindex în robots.txt
Pur și simplu, Google nu acceptă directiva fără index în robots.txt.
Deși Google a urmat-o în trecut, din iulie 2019, Google a încetat să-l mai susțină în totalitate.
Și dacă vă gândiți să utilizați directiva no-index robots.txt pentru a nu indexa conținut pe alte motoare de căutare, gândiți-vă din nou:
Directiva neoficială fără index nu a funcționat niciodată în Bing.
De departe, cea mai bună metodă de a nu indexa conținutul în motoarele de căutare este să aplicați o etichetă meta robots fără index pe pagina pe care doriți să o excludeți.
Păstrați fișierul robots.txt sub 512 KB
În prezent, Google are o limită de dimensiune a fișierului robots.txt de 500 kibibytes (512 kilobytes).
Aceasta înseamnă că orice conținut după 512 KB poate fi ignorat.

Acestea fiind spuse, având în vedere că un caracter consumă doar un octet, robots.txt-ul dvs. ar trebui să fie URIAȘ pentru a atinge limita de dimensiune a fișierului (512.000 de caractere, pentru a fi exact). Păstrați fișierul robots.txt simplu, concentrându-vă mai puțin pe paginile excluse individual și mai mult pe modele mai ample pe care wild cardurile le pot controla.
Nu este clar dacă alte motoare de căutare au dimensiunea maximă permisă pentru fișierele robots.txt.
Exemple Robots.txt
Mai jos sunt câteva exemple de fișiere robots.txt.
Acestea includ combinații ale directivelor pe care agenția noastră SEO le folosește cel mai mult în fișierele robots.txt pentru clienți. Țineți minte, totuși; acestea sunt doar în scop de inspirație. Va trebui să personalizați întotdeauna fișierul robots.txt pentru a răspunde cerințelor dvs.
Permiteți tuturor roboților accesul la tot
Acest fișier robots.txt nu oferă reguli de interzicere pentru toate motoarele de căutare:
User-agent: * Disallow:Cu alte cuvinte, permite roboților de căutare să acceseze cu crawlere totul. Are același scop ca un fișier robots.txt gol sau fără robots.txt.
Blocați toți roboții să acceseze totul
Exemplul de fișier robots.txt le spune tuturor motoarelor de căutare să nu acceseze nimic după bara oblică finală. Cu alte cuvinte, întregul domeniu:
User-agent: * Disallow: /Pe scurt, acest fișier robots.txt blochează toți roboții motoarelor de căutare și poate împiedica afișarea site-ului dvs. în paginile cu rezultatele căutării.
Blocați toți roboții să acceseze cu crawlere un fișier
În acest exemplu, blocăm toți roboții de căutare să acceseze cu crawlere un anumit fișier.
User-agent: * Disallow: /directory/this-is-a-file.pdfBlocați toți roboții să acceseze cu crawlere un singur tip de fișier (doc, pdf, jpg)
Din moment ce nu este indexat, un fișier precum „doc” sau „pdf” nu poate fi realizat folosind o etichetă meta robot „no-index”; puteți folosi următoarea directivă pentru a opri indexarea unui anumit tip de fișier.
User-agent: * Disallow: /*.doc$ Disallow: /*.pdf$ Disallow: /*.jpg$Acest lucru va funcționa pentru a deindexa toate fișierele de acest tip, atâta timp cât niciun fișier individual nu este legat de altă parte de pe web.
Blocați Google să acceseze cu crawlere mai multe directoare
Poate doriți să blocați accesarea cu crawlere a mai multor directoare pentru un anumit bot sau pentru toți roboții. În acest exemplu, blocăm Googlebot să acceseze cu crawlere două subdirectoare.
User-agent: Googlebot Disallow: /admin/ Disallow: /private/Rețineți că nu există limită pentru numărul de directoare pe care le puteți utiliza bock. Doar enumerați fiecare sub agentul utilizator căruia i se aplică directiva.
Blocați Google să acceseze cu crawlere toate adresele URL parametrizate
Această directivă este utilă în special pentru site-urile web care utilizează navigarea fațetă, unde pot fi create multe URL-uri parametrizate.
User-agent: Googlebot Disallow: /*?Această directivă împiedică consumarea bugetului de accesare cu crawlere la adresele URL dinamice și maximizează accesarea cu crawlere a paginilor importante. Folosesc acest lucru în mod regulat, în special pe site-urile de comerț electronic cu funcționalitate de căutare.
Blocați toți roboții să acceseze cu crawlere un subdirector, dar permițând accesarea cu crawlere a unei pagini din interior
Uneori este posibil să doriți să blocați accesul crawlerelor la o secțiune completă a site-ului dvs., dar lăsați o pagină accesibilă. Dacă o faceți, utilizați următoarea combinație de directive „allow” și „disallow”:
User-agent: * Disallow: /category/ Allow: /category/widget/Le spune motoarelor de căutare să nu acceseze cu crawlere întregul director, excluzând o anumită pagină sau fișier.
Robots.txt pentru WordPress
Aceasta este configurația de bază pe care o recomand pentru un fișier WordPress robots.txt. Acesta blochează accesarea cu crawlere a paginilor de administrare și a etichetelor și a adreselor URL ale autorilor, ceea ce poate crea probleme inutile pe un site web WordPress.
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /wp-admin/ Disallow: /readme.html Disallow: /refer/ Disallow: /tag/ Disallow: /author/ Disallow: /404-error/ Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xmlAcest fișier robots.txt va funcționa bine pentru majoritatea site-urilor WordPress, dar, desigur, ar trebui să îl ajustați întotdeauna la propriile cerințe.
Cum să vă auditați fișierul Robots.txt pentru erori
Pe vremea mea, am văzut mai multe erori cu impact de rang în fișierele robots.txt decât poate orice alt aspect al SEO tehnic. Cu atât de multe directive potențial conflictuale, probleme pot apărea și apar.
Deci, când vine vorba de fișierele robots.txt, merită să fii atent la probleme.
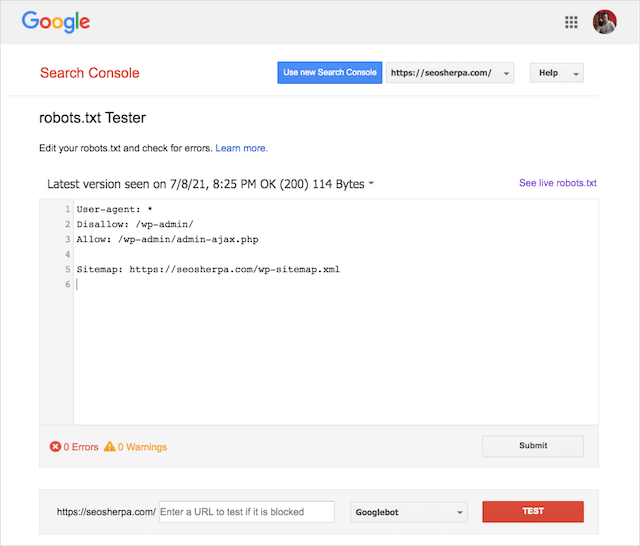
Din fericire, raportul „Acoperire” din Google Search Console vă oferă o modalitate de a verifica și monitoriza problemele robots.txt.
De asemenea, puteți utiliza instrumentul de testare Robots.txt de la Google pentru a verifica erorile din fișierul dvs. de roboți live sau pentru a testa un fișier robots.txt nou înainte de a-l implementa.
Vom încheia prin a acoperi cele mai frecvente probleme, ce înseamnă acestea și cum să le rezolvăm.
Adresa URL trimisă a fost blocată de robots.txt
Această eroare înseamnă că cel puțin una dintre adresele URL din sitemap-urile trimise este blocată de robots.txt.

O hartă a site-ului care este configurată corect ar trebui să includă numai adresele URL pe care doriți să le indexați în motoarele de căutare . Ca atare, nu ar trebui să conțină pagini neindexate, canonizate sau redirecționate.
Dacă ați urmat aceste bune practici, atunci nicio pagină trimisă în harta site-ului dvs. nu ar trebui să fie blocată de robots.txt.
Dacă vedeți „Adresa URL trimisă blocată de robots.txt” în raportul de acoperire, ar trebui să investigați ce pagini sunt afectate, apoi să schimbați fișierul robots.txt pentru a elimina blocarea paginii respective.
Puteți folosi testerul robots.txt de la Google pentru a vedea ce directivă blochează conținutul.
Blocat de Robots.txt
Această „eroare” înseamnă că aveți pagini blocate de robots.txt care nu se află în prezent în indexul Google.

Dacă acest conținut are utilitate și ar trebui indexat, eliminați blocul de accesare cu crawlere din robots.txt.
Un scurt avertisment:
„Blocat de robots.txt” nu este neapărat o eroare. De fapt, acesta poate fi tocmai rezultatul pe care îl doriți.
De exemplu, este posibil să fi blocat anumite fișiere în robots.txt cu intenția de a le exclude din indexul Google. Pe de altă parte, dacă ați blocat accesarea cu crawlere a anumitor pagini cu intenția de a nu le indexa, luați în considerare eliminarea blocului de accesare cu crawlere și utilizați în schimb metaeticheta unui robot.
Acesta este singurul mod de a garanta excluderea conținutului din indexul Google.
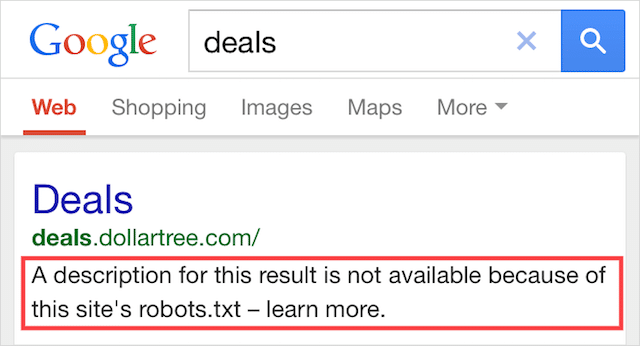
Indexat, deși blocat de Robots.txt
Această eroare înseamnă că o parte din conținutul blocat de robots.txt este încă indexat în Google.
Se întâmplă atunci când conținutul este încă descoperit de Googlebot, deoarece este conectat la din altă parte de pe web. Pe scurt, Googlebot ajunge la accesarea cu crawlere a conținutului și apoi îl indexează înainte de a vizita fișierul robots.txt al site-ului dvs. web, unde vede directiva interzisă.
Până atunci, e prea târziu. Și se indexează:
Lasă-mă să forez pe acesta acasă:
Dacă încercați să excludeți conținut din rezultatele căutării Google, robots.txt nu este soluția corectă.
Recomand eliminarea blocului de accesare cu crawlere și utilizarea unei etichete meta robots no-index pentru a preveni indexarea.
Dimpotrivă, dacă ați blocat acest conținut din întâmplare și doriți să-l păstrați în indexul Google, eliminați blocul de crawlere din robots.txt și lăsați-l așa.
Acest lucru poate ajuta la îmbunătățirea vizibilității conținutului în căutarea Google.
Gânduri finale
Robots.txt poate fi folosit pentru a îmbunătăți accesarea cu crawlere și indexarea conținutului site-ului dvs., ceea ce vă ajută să deveniți mai vizibil în SERP-uri.
Când este folosit eficient, este cel mai important text de pe site-ul dvs. Dar, atunci când este folosit cu neglijență, va fi călcâiul lui Ahile în codul site-ului tău.
Vestea bună, cu doar o înțelegere de bază a agenților utilizatori și o mână de directive, rezultate de căutare mai bune sunt la îndemâna ta.
Singura întrebare este ce protocoale veți folosi în fișierul robots.txt?
Anunță-mă în comentariile de mai jos.