
Robots.txt: En İyi SEO Rehberi (2021 Sürümü)
Yayınlanan: 2021-06-10 Bugün bir web sitesinin SEO'su için en kritik dosyalardan birini nasıl oluşturacağınızı öğreneceksiniz:
Bugün bir web sitesinin SEO'su için en kritik dosyalardan birini nasıl oluşturacağınızı öğreneceksiniz:
(robots.txt dosyası).
Özellikle, belirli sayfalardaki botları engellemek, tarama sıklığını artırmak, tarama bütçesini optimize etmek ve sonuç olarak SERP'lerde doğru sayfanın sıralamasından daha fazlasını elde etmek için robot dışlama protokollerini nasıl kullanacağınızı göstereceğim.
ben örtüyorum:
- robots.txt dosyası nedir
- robots.txt neden önemlidir?
- robots.txt nasıl çalışır?
- Robots.txt kullanıcı aracıları ve yönergeleri
- Robots.txt ve meta robotlar
- robots.txt dosyanızı nasıl bulabilirsiniz?
- robots.txt dosyanızı oluşturma
- Robots.txt dosyası en iyi uygulamaları
- Robots.txt örnekleri
- Hatalar için robots.txt dosyanızı nasıl denetlersiniz?
Artı, bundan daha fazlası. Hemen dalalım.
Robots.txt dosyası nedir? Ve Neden Birine İhtiyacınız Var?
Basit bir ifadeyle, bir robots.txt dosyası, web robotları için bir talimat kılavuzudur.
Her türden bota, bir sitenin hangi bölümlerini taramaları (ve taramamaları) gerektiğini bildirir.
Bununla birlikte, robots.txt, öncelikle arama motoru robotlarının (AKA web tarayıcıları) etkinliğini kontrol etmek için bir "davranış kuralları" olarak kullanılır.

Robots.txt, web sitesini nasıl taramaları gerektiğine ilişkin talimatlar için her büyük arama motoru (Google, Bing ve Yahoo dahil) tarafından düzenli olarak kontrol edilir. Bu talimatlar direktifler olarak bilinir.
Yönerge yoksa - veya robots.txt dosyası yoksa - arama motorları tüm web sitesini, özel sayfaları ve tümünü tarar.
Çoğu arama motoru itaatkar olsa da, robots.txt yönergelerine uymanın isteğe bağlı olduğunu unutmamak önemlidir. Arama motorları isterlerse robots.txt dosyanızı yoksaymayı seçebilirler.
Neyse ki, Google bu arama motorlarından biri değil. Google, robots.txt dosyasındaki talimatlara uyma eğilimindedir.
Robots.txt Neden Önemli?
Bir robots.txt dosyasına sahip olmak birçok web sitesi, özellikle de küçük olanlar için kritik değildir.
Bunun nedeni, Google'ın genellikle bir sitedeki tüm önemli sayfaları bulup dizine ekleyebilmesidir.
Ayrıca, yinelenen içeriği veya önemsiz olan sayfaları otomatik olarak dizine EKLEMEZLER.
Ancak yine de bir robots.txt dosyasına sahip olmamak için iyi bir neden yok - bu yüzden bir tane olmasını tavsiye ederim.
Bir robots.txt dosyası, web sitenizde hangi arama motorlarının tarayıp tarayamayacağı konusunda size daha fazla kontrol sağlar ve bu, birkaç nedenden dolayı yararlıdır:
Herkese Açık Olmayan Sayfaların Arama Motorlarından Engellenmesine İzin Verir
Bazen sitenizde dizine eklenmesini istemediğiniz sayfalar olabilir.
Örneğin, kullanıma sunulana kadar kullanıcılardan gizlendiğinden emin olmak istediğiniz bir hazırlama ortamında yeni bir web sitesi geliştiriyor olabilirsiniz.
Veya SERP'lerde görünmesini istemediğiniz web sitesi giriş sayfalarınız olabilir.
Bu durumda, bu sayfaları arama motoru tarayıcılarından engellemek için robots.txt dosyasını kullanabilirsiniz.
Arama Motoru Tarama Bütçesini Kontrol Eder
Tüm sayfalarınızı arama motorlarında dizine eklemekte zorlanıyorsanız, bir tarama bütçesi sorununuz olabilir.
Basitçe söylemek gerekirse, arama motorları içeriğinizi web sitenizin ölü sayfalarında taramak için ayrılan süreyi kullanıyor.

Arama motoru robotları, robots.txt ile düşük yardımcı URL'leri engelleyerek, tarama bütçelerinin daha fazlasını en önemli sayfalara harcayabilir.
Kaynakların İndekslenmesini Önler
Tek tek sayfaların dizine eklenmesini durdurmak için "indeks yok" meta yönergesini kullanmak en iyi uygulamadır.
Sorun şu ki, meta yönergeler PDF'ler ve Word belgeleri gibi multimedya kaynakları için iyi çalışmıyor.
İşte burada robots.txt kullanışlıdır.
Robots.txt dosyanıza basit bir metin satırı ekleyebilirsiniz ve arama motorlarının bu multimedya dosyalarına erişimi engellenir.
(Bu yazının devamında bunu nasıl yapacağınızı size tam olarak göstereceğim)
(Tam olarak) Bir Robots.txt Nasıl Çalışır?
Daha önce paylaştığım gibi, bir robots.txt dosyası, arama motoru robotları için bir talimat kılavuzu görevi görür. Arama botlarına nerede (ve nerede taramamaları) gerektiğini söyler.
Bu nedenle, bir arama tarayıcısı, bir web sitesine ulaşır ulaşmaz bir robots.txt dosyası arayacaktır.
Robots.txt dosyasını bulursa, tarayıcı siteyi taramaya devam etmeden önce onu okuyacaktır.
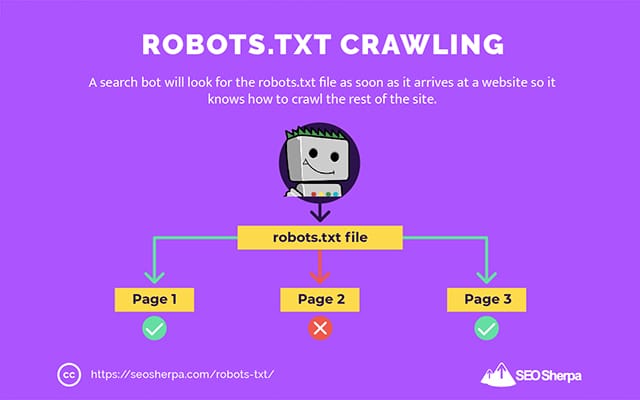
Web tarayıcısı bir robots.txt dosyası bulamazsa veya dosya, arama botlarının etkinliğine izin vermeyen yönergeler içermiyorsa, tarayıcı her zamanki gibi tüm siteyi taramaya devam edecektir.
Bir robots.txt dosyasının arama botları tarafından bulunabilmesi ve okunabilmesi için, robots.txt çok özel bir şekilde biçimlendirilir.
İlk olarak, HTML işaretleme kodu olmayan bir metin dosyasıdır (dolayısıyla .txt uzantısı).
İkinci olarak, web sitesinin kök klasörüne yerleştirilir, örneğin, https://seosherpa.com/robots.txt.
Üçüncüsü, tüm robots.txt dosyalarında ortak olan standart bir sözdizimi kullanır, örneğin:
Sitemap: [URL location of sitemap] User-agent: [bot identifier] [directive 1] [directive 2] [directive ...] User-agent: [another bot identifier] [directive 1] [directive 2] [directive ...]Bu sözdizimi ilk bakışta göz korkutucu görünebilir, ancak aslında oldukça basittir.
Kısaca, talimatların uygulanacağı botu (kullanıcı-aracı) tanımlar ve ardından botun uyması gereken kuralları (yönergeleri) belirtirsiniz.
Bu iki bileşeni daha ayrıntılı olarak inceleyelim.
Kullanıcı Aracıları
Kullanıcı aracısı, belirli web tarayıcılarını ve internette etkin olan diğer programları tanımlamak için kullanılan addır.
Cihaz türleri ve tarayıcılar için aracılar dahil olmak üzere kelimenin tam anlamıyla yüzlerce kullanıcı aracısı vardır.
Çoğu, bir robots.txt dosyası ve SEO bağlamında ilgisizdir. Öte yandan, bilmeniz gerekenler:
- Google: Googlebot
- Google Görseller: Googlebot-Resim
- Google Video: Googlebot-Video
- Google Haberler: Googlebot-Haberler
- Bing: Bingbot
- Bing Resimleri ve Videoları: MSNBot-Medya
- Yahoo: Slurp
- Yandex: YandexBot
- Baidu : Baiduspider
- DuckDuckGo: DuckDuckBot
Kullanıcı aracısını belirterek, farklı arama motorları için farklı kurallar belirleyebilirsiniz.

Örneğin, Baidu aramalarında değil de Google arama sonuçlarında belirli bir sayfanın görünmesini istiyorsanız, robots.txt dosyanıza iki komut grubu ekleyebilirsiniz: birinin önünde “User-agent: Bingbot” ve bir set öncesinde "Kullanıcı aracısı: Baiduspider."
Yönergelerinizin tüm kullanıcı aracılarına uygulanmasını istiyorsanız yıldız (*) joker karakterini de kullanabilirsiniz.
Örneğin, DuckDuckGo hariç tüm arama motoru robotlarının sitenizi taramasını engellemek istediğinizi varsayalım. Bunu nasıl yapacağınız aşağıda açıklanmıştır:
User-agent: * Disallow: / User-agent: DuckDuckBot Allow: /Sidenote: robots.txt dosyasında çelişkili komutlar varsa, bot daha ayrıntılı komutu izleyecektir.
Bu nedenle, yukarıdaki örnekte, DuckDuckBot, daha önceki bir yönerge (tüm botlar için geçerlidir) tarama yapmadığını söylese de, web sitesini taramayı bilir. Kısacası, bir bot, kendileri için en doğru şekilde geçerli olan talimatı izleyecektir.
direktifler
Yönergeler, kullanıcı aracısının izlemesini istediğiniz davranış kurallarıdır. Başka bir deyişle, direktifler, arama botunun web sitenizi nasıl taraması gerektiğini tanımlar.
GoogleBot'un şu anda desteklediği yönergeler ve bunların bir robots.txt dosyasındaki kullanımları şunlardır:
izin verme
Arama botlarının belirli bir URL yolundaki belirli dosyaları ve sayfaları taramasına izin vermemek için bu yönergeyi kullanın.

Örneğin, GoogleBot'un wikinize ve tüm sayfalarına erişmesini engellemek istiyorsanız, robots.txt dosyanız şu yönergeyi içermelidir:
User-agent: GoogleBot Disallow: /wikiKesin bir URL'nin, belirli bir dizindeki tüm dosya ve sayfaların ve hatta tüm web sitenizin taranmasını engellemek için izin vermeme yönergesini kullanabilirsiniz.
İzin vermek
İzin verme yönergesi, arama motorlarının sitenizin aksi takdirde izin verilmeyen bir bölümünde belirli bir alt dizini veya sayfayı taramasına izin vermek istiyorsanız kullanışlıdır.

Diyelim ki, biri hariç tüm arama motorlarının blogunuzdaki gönderileri taramasını engellemek istediniz; o zaman allow yönergesini şu şekilde kullanırsınız:
User-agent: * Disallow: /blog Allow: /blog/allowable-postArama botları her zaman bir robots.txt dosyasında verilen en ayrıntılı talimatı izlediğinden, /blog/allowable-post'u taramayı bilirler, ancak bu dizindeki diğer gönderileri veya dosyaları taramazlar;
- /blog/bir posta/
- /blog/post-iki/
- /blog/dosya-adı.pdf
Hem Google hem de Bing bu yönergeyi destekler. Ancak diğer arama motorları yok.
Site Haritası
Site haritası yönergesi, XML site haritanızın/haritalarınızın arama motorlarına konumunu belirtmek için kullanılır.
Site haritalarında yeniyseniz, arama motorlarında taranmasını ve dizine eklenmesini istediğiniz sayfaları listelemek için kullanılırlar.
Robots.txt dosyasına site haritası yönergesini ekleyerek, arama motorlarının site haritanızı bulmasına ve ardından web sitenizin en önemli sayfalarını taramasına ve dizine eklemesine yardımcı olursunuz.
Bununla birlikte, XML site haritanızı Search Console aracılığıyla zaten gönderdiyseniz, site haritanızı/haritalarınızı robots.txt dosyasına eklemek Google için biraz gereksizdir. Yine de, Ask, Bing ve Yahoo gibi arama motorlarına site haritalarınızın nerede bulunabileceğini bildirdiği için site haritası yönergesini kullanmak en iyi yöntemdir.
Aşağıda, site haritası yönergesini kullanan bir robots.txt dosyası örneği verilmiştir:
Sitemap: https://www.website.com/sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/Robots.txt dosyasında site haritası yönergesinin yerleşimine dikkat edin. En iyi şekilde robots.txt dosyanızın en üstüne yerleştirilir. Ayrıca alt tarafa da yerleştirilebilir.
Birden fazla site haritanız varsa hepsini robots.txt dosyanıza eklemelisiniz. Sayfalar ve gönderiler için ayrı XML site haritalarımız olsaydı robots.txt dosyasının nasıl görüneceği aşağıda açıklanmıştır:
Sitemap: http://website.com/post-sitemap.xml Sitemap: http://website.com/page-sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/Her iki durumda da, desteklenen tüm kullanıcı aracıları yönergeyi izleyeceğinden, her bir XML site haritasından yalnızca bir kez bahsetmeniz gerekir.
Yolları listeleyen diğer robots.txt yönergelerinin aksine, site haritası yönergesinin protokol, alan adı ve üst düzey alan uzantısı dahil olmak üzere XML site haritanızın mutlak URL'sini belirtmesi gerektiğini unutmayın.
Yorumlar
“Yönerge” yorumu insanlar için faydalıdır ancak arama botları tarafından kullanılmaz.

Belirli yönergelerin neden var olduğunu hatırlatmak için yorumlar ekleyebilir veya robots.txt dosyanıza erişimi olanların önemli yönergeleri silmesini engelleyebilirsiniz. Kısacası, robots.txt dosyanıza not eklemek için yorumlar kullanılır.
Yorum eklemek için yazın." #" ve ardından yorum metni.
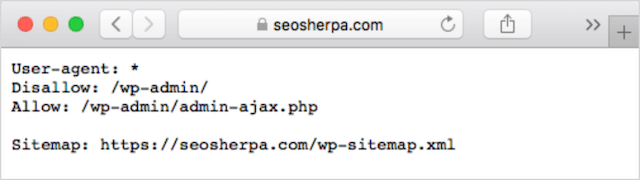
# Don't allow access to the /wp-admin/ directory for all robots. User-agent: * Disallow: /wp-admin/Bir satırın başına (yukarıda gösterildiği gibi) veya aynı satırdaki bir yönergeden sonra (aşağıda gösterildiği gibi) bir yorum ekleyebilirsiniz:
User-agent: * #Applies to all robots Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.Yorumunuzu nereye yazmayı seçerseniz seçin, karmadan sonraki her şey yok sayılır.
Şimdiye kadar takip?
Harika! Artık robots.txt dosyanız için ihtiyaç duyacağınız ana direktifleri ele aldık – bunlar aynı zamanda Google tarafından desteklenen tek direktiflerdir.
Peki ya diğer arama motorları? Bing, Yahoo ve Yandex için kullanabileceğiniz bir yönerge daha vardır:
Tarama Gecikmesi
Tarama gecikmesi yönergesi, sunucuların çok fazla tarama isteğiyle aşırı yüklenmesini önlemek için kullanılan resmi olmayan bir yönergedir.
Başka bir deyişle, bir arama motorunun sitenizi tarayabileceği sıklığı sınırlamak için kullanırsınız.

Arama motorları web sitenizi sık sık tarayarak sunucunuzu aşırı yükleyebilirse, robots.txt dosyanıza Crawl-delay yönergesini eklemek sorunu yalnızca geçici olarak çözecektir.
Durum, web siteniz berbat bir barındırma veya yanlış yapılandırılmış bir barındırma ortamı üzerinde çalışıyor olabilir ve bu, hızlı bir şekilde düzeltmeniz gereken bir şeydir.
Tarama gecikme yönergesi, bir Arama Botunun web sitenizi tarayabileceği süreyi saniye cinsinden tanımlayarak çalışır.
Örneğin, tarama gecikmenizi 5'e ayarlarsanız, arama botları, gün boyunca maksimum yaklaşık 17.280 URL için her pencerede yalnızca bir sayfa (veya hiçbir sayfa) tarayarak günü beş saniyelik pencerelere böler.
Bu nedenle, özellikle büyük bir web siteniz varsa, bu yönergeyi ayarlarken dikkatli olun. Sitenizde milyonlarca sayfa varsa, günde yalnızca 17.280 URL'nin taranması pek yardımcı olmaz.
Her arama motorunun tarama gecikmesi yönergesini işleme şekli farklıdır. Aşağıda parçalayalım:
Tarama gecikmesi ve Bing, Yahoo ve Yandex
Bing, Yahoo ve Yandex'in tümü robots.txt dosyasında gezinme gecikmesi yönergesini destekler.
Bu, BingBot, Slurp ve YandexBot kullanıcı aracıları için bir tarama gecikme yönergesi ayarlayabileceğiniz ve arama motorunun buna göre taramasını azaltacağı anlamına gelir.
Her arama motorunun tarama gecikmesini biraz farklı bir şekilde yorumladığını unutmayın, bu nedenle belgelerini kontrol ettiğinizden emin olun:
- Bing ve Yahoo
- yandex
Bununla birlikte, bu motorların her biri için tarama gecikmesi yönergesinin biçimi aynıdır. Bir izin vermeme VEYA izin verme yönergesinden hemen sonra yerleştirmelisiniz. İşte bir örnek:
User-agent: BingBot Allow: /widgets/ Crawl-delay: 5Tarama gecikmesi ve Google
Google'ın tarayıcısı, tarama gecikmesi yönergesini desteklemediğinden, robots.txt dosyasında GoogleBot için bir tarama gecikmesi ayarlamanın bir anlamı yoktur.
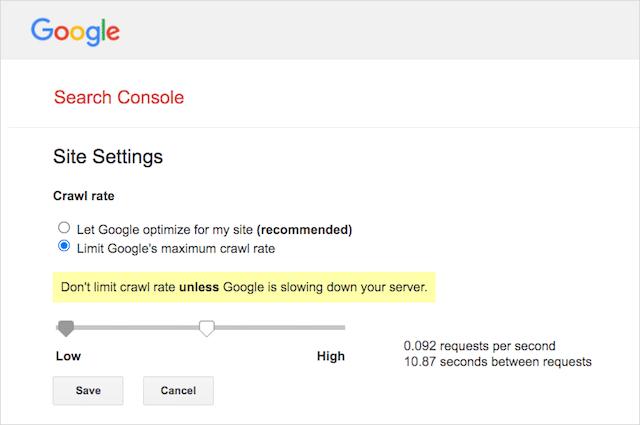
Ancak Google, Google Arama Konsolunda bir tarama hızı tanımlamayı destekler. Bunu nasıl yapacağınız aşağıda açıklanmıştır:
- Google Arama Konsolunun ayarlar sayfasına gidin.
- Tarama hızını tanımlamak istediğiniz mülkü seçin
- "Google'ın maksimum tarama hızını sınırla"yı tıklayın.
- Kaydırıcıyı tercih ettiğiniz tarama hızına ayarlayın. Varsayılan olarak, tarama hızı "Google'ın sitem için optimizasyon yapmasına izin ver (önerilir)" ayarına sahiptir.
Tarama gecikmesi ve Baidu
Google gibi Baidu da tarama gecikme yönergesini desteklemez. Ancak, Google Arama Konsolu'na benzer şekilde, tarama sıklığını kontrol edebileceğiniz bir Baidu Web Yöneticisi Araçları hesabına kaydolmak mümkündür.
Alt çizgi? Robots.txt, arama motoru örümceklerine web sitenizdeki belirli sayfaları taramamalarını söyler.
Robots.txt vs meta robotlar vs x-robotlar
Dışarıda bir sürü “robot” talimatı var. Aralarındaki farklar nelerdir, yoksa aynılar mı?
Kısa bir açıklama yapayım:
Öncelikle, robots.txt gerçek bir metin dosyasıdır, meta ve x-robot'lar ise bir web sayfasının kodundaki etiketlerdir.
İkinci olarak, robots.txt, bir web sitesinin sayfalarının nasıl taranacağı konusunda botlara önerilerde bulunur. Öte yandan, robotların meta yönergeleri, bir sayfanın içeriğini tarama ve dizine ekleme konusunda çok kesin talimatlar sağlar.
Ne olduklarının ötesinde, üçü de farklı işlevlere hizmet ediyor.
Robots.txt, site veya dizin genelinde gezinme davranışını belirlerken meta ve x-robotlar, tek tek sayfa (veya sayfa öğesi) düzeyinde dizin oluşturma davranışını belirleyebilir.

Genel olarak:
Bir sayfanın dizine eklenmesini durdurmak istiyorsanız, “index yok” meta robots etiketini kullanmalısınız. Robots.txt dosyasında bir sayfaya izin vermemek, sayfanın arama motorlarında gösterilmeyeceğini garanti etmez (sonuçta robots.txt yönergeleri önerilerdir). Ayrıca, bir arama motoru robotu yine de bu URL'yi bulabilir ve başka bir web sitesinden bağlantı verilmişse dizine ekleyebilir.

Aksine, bir medya dosyasının dizine eklenmesini durdurmak istiyorsanız, gidilecek yol robots.txt'dir. jpeg veya PDF gibi dosyalara meta robot etiketleri ekleyemezsiniz.
Robots.txt'inizi Nasıl Bulunur?
Web sitenizde zaten bir robots.txt dosyanız varsa, bu dosyaya alanınız.com/robots.txt adresinden erişebilirsiniz.
Tarayıcınızda URL'ye gidin.
Yukarıdaki gibi bir metin tabanlı sayfa görürseniz, bir robots.txt dosyanız var demektir.
Robots.txt Dosyası Nasıl Oluşturulur
Halihazırda bir robots.txt dosyanız yoksa, bir tane oluşturmak basittir.
İlk olarak, Not Defteri, Microsoft Word veya herhangi bir metin düzenleyiciyi açın ve dosyayı 'robotlar' olarak kaydedin.
Küçük harf kullandığınızdan emin olun ve dosya türü uzantısı olarak .txt'yi seçin:

İkinci olarak, direktiflerinizi ekleyin. Örneğin, tüm arama botlarının /login/ dizininizi taramasına izin vermemek istiyorsanız şunu yazarsınız:
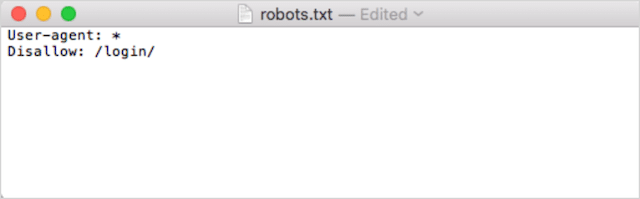
Robots.txt dosyanızdan memnun kalana kadar yönergeleri eklemeye devam edin.
Alternatif olarak, robots.txt dosyanızı Ryte'tan buna benzer bir araçla oluşturabilirsiniz.

Bir araç kullanmanın bir avantajı, insan hatasını en aza indirmesidir.
Robots.txt söz diziminizdeki küçük bir hata, bir SEO felaketiyle sonuçlanabilir.
Bununla birlikte, robots.txt oluşturucu kullanmanın dezavantajı, özelleştirme fırsatının minimum olmasıdır.
Bu yüzden robot.txt dosyasını kendiniz yazmayı öğrenmenizi öneririm. Ardından, tam olarak gereksinimlerinize göre bir robots.txt oluşturabilirsiniz.
Robots.txt Dosyanızı Nereye Koymalısınız?
robots.txt dosyanızı, geçerli olduğu alt etki alanının en üst düzey dizinine ekleyin.
Örneğin, etkialaniniz.com'daki tarama davranışını kontrol etmek için, robots.txt dosyasına etkialaniniz.com/robots.txt URL yolundan erişilebilir olmalıdır.
Öte yandan, shop.yourdomain.com gibi bir alt alanda taramayı kontrol etmek istiyorsanız, robots.txt dosyasına shop.yourdomain.com/robots.txt URL yolundan erişilebilir olmalıdır.
Altın kurallar şunlardır:
- Web sitenizdeki her alt alana kendi robots.txt dosyasını verin.
- Dosya(lar) ınıza robots.txt dosyasının tamamını küçük harfle adlandırın.
- Dosyayı, başvurduğu alt etki alanının kök dizinine yerleştirin.
Robots.txt dosyası kök dizinde bulunamazsa, arama motorları herhangi bir yönerge olmadığını varsayar ve web sitenizi bütünüyle tarar.
Robots.txt Dosyası En İyi Uygulamaları
Ardından robots.txt dosyalarının kurallarını ele alalım. Yaygın robots.txt tuzaklarından kaçınmak için bu en iyi uygulamaları kullanın:
Her yönerge için yeni bir satır kullanın
robots.txt dosyanızdaki her yönerge yeni bir satırda olmalıdır.
Aksi takdirde, arama motorları neyi tarayacakları (ve indeksleyecekleri) konusunda kafaları karışacaktır.
Bu, örneğin, yanlış yapılandırılmıştır:
User-agent: * Disallow: /folder/ Disallow: /another-folder/Öte yandan bu, doğru ayarlanmış bir robots.txt dosyasıdır:
User-agent: * Disallow: /folder/ Disallow: /another-folder/Spesifiklik "neredeyse" her zaman kazanır
Google ve Bing söz konusu olduğunda , daha ayrıntılı yönerge kazanır.
Örneğin, bu Allow yönergesi, karakter uzunluğu daha uzun olduğu için Disallow yönergesine üstün gelir.
User-agent: * Disallow: /about/ Allow: /about/company/Google ve Bing, /about/company/'yi taramayı bilir, ancak /about/ dizinindeki diğer sayfaları bilmez.
Ancak, diğer arama motorlarında bunun tersi geçerlidir.
Varsayılan olarak, Google ve Bing dışındaki tüm büyük arama motorları için ilk eşleşen yönerge her zaman kazanır .
Yukarıdaki örnekte, arama motorları Disallow yönergesini izleyecek ve Allow yönergesini yok sayacak, yani /about/company sayfası taranmayacaktır.
Tüm arama motorları için kurallar oluştururken bunu aklınızda bulundurun.
Kullanıcı aracısı başına yalnızca bir yönerge grubu
Robots.txt dosyanız kullanıcı aracısı başına birden çok yönerge grubu içeriyorsa, boh-oh-boy, kafa karıştırıcı olabilir mi?
Robotlar için değil, çünkü çeşitli bildirimlerdeki tüm kuralları tek bir grupta birleştirecek ve hepsini takip edecekler, ama sizin için.
İnsan hatası olasılığını önlemek için, kullanıcı aracısını bir kez belirtin ve ardından bu kullanıcı aracısı için geçerli olan tüm yönergeleri aşağıda listeleyin.

İşleri düzenli ve basit tutarsanız, hata yapma olasılığınız azalır.
Talimatları basitleştirmek için joker karakterler (*) kullanın
Yukarıdaki örnekteki joker karakterleri (*) fark ettiniz mi?
Doğru; Kuralları tüm kullanıcı aracılarına uygulamak VE yönergeleri bildirirken URL kalıplarını eşleştirmek için joker karakterler (*) kullanabilirsiniz.
Örneğin, arama botlarının web sitenizdeki parametreli ürün kategorisi URL'lerine erişmesini engellemek istiyorsanız, her bir kategoriyi şu şekilde listeleyebilirsiniz:
User-agent: * Disallow: /products/watches? Disallow: /products/handbags? Disallow: /products/shoes?Veya kuralı tüm kategorilere uygulayacak bir joker karakter kullanabilirsiniz. İşte nasıl görüneceği:
User-agent: * Disallow: /products/*?Bu örnek, arama motorlarının /product/ alt klasöründeki soru işareti içeren tüm URL'leri taramasını engeller. Başka bir deyişle, parametreleştirilmiş herhangi bir ürün kategorisi URL'si.
Google, Bing, Yahoo, robots.txt yönergeleri ve Ask'ta joker karakter kullanımını destekler.
Bir URL'nin sonunu belirtmek için "$" kullanın
Bir URL'nin sonunu belirtmek için robots.txt yolundan sonra dolar işaretini ( $ ) kullanın.
Diyelim ki arama botlarının web sitenizdeki tüm .doc dosyalarına erişmesini durdurmak istediniz; o zaman bu yönergeyi kullanırsınız:
User-agent: * Disallow: /*.doc$Bu, arama motorlarının .doc ile biten URL'lere erişmesini engeller.
Bu, /media/file.doc dosyasını taramayacakları, ancak bu URL “.doc” ile bitmediği için /media/file.doc?id=72491 tarayacakları anlamına gelir.
Her alt alan kendi robots.txt dosyasını alır
Robots.txt yönergeleri yalnızca robots.txt dosyasının barındırıldığı (alt) etki alanı için geçerlidir.
Bu, sitenizin aşağıdakiler gibi birden çok alt etki alanına sahip olduğu anlamına gelir:
- domain.com
- biletler.domain.com
- olaylar.domain.com
Her alt alan kendi robots.txt dosyasını gerektirir.
robots.txt her zaman her alt etki alanının kök dizinine eklenmelidir. Yukarıdaki örnek kullanıldığında yollar şöyle görünür:
- domain.com/robots.txt
- biletler.domain.com/robots.txt
- event.domain.com/robots.txt
robots.txt dosyanızda noindex kullanmayın
Basitçe söylemek gerekirse, Google, robots.txt dosyasındaki dizinsiz yönergeyi desteklemez.
Google geçmişte bunu takip ederken, Temmuz 2019 itibariyle Google onu tamamen desteklemeyi bıraktı.
Diğer arama motorlarında indekssiz içerik için indekssiz robots.txt yönergesini kullanmayı düşünüyorsanız, tekrar düşünün:
Resmi olmayan dizinsiz yönerge Bing'de hiçbir zaman çalışmadı.
Şimdiye kadar, arama motorlarında dizine eklenmemiş içeriğin en iyi yöntemi, hariç tutmak istediğiniz sayfaya dizinsiz bir meta robots etiketi uygulamaktır.
robots.txt dosyanızı 512 KB'nin altında tutun
Google'ın şu anda 500 kibibaytlık (512 kilobayt) bir robots.txt dosya boyutu sınırı vardır.
Bu, 512 KB'den sonraki herhangi bir içeriğin yoksayılabileceği anlamına gelir.

Bununla birlikte, bir karakterin yalnızca bir bayt tükettiği göz önüne alındığında, bu dosya boyutu sınırına (tam olarak 512.000 karakter) ulaşmak için robots.txt dosyanızın BÜYÜK olması gerekir. Tek tek hariç tutulan sayfalara daha az ve joker karakterlerin kontrol edebileceği daha geniş kalıplara daha fazla odaklanarak robots.txt dosyanızı yalın tutun.
Diğer arama motorlarının robots.txt dosyaları için izin verilen maksimum dosya boyutuna sahip olup olmadığı net değil.
Robots.txt Örnekleri
Aşağıda birkaç robots.txt dosyası örneği bulunmaktadır.
Müşteriler için robots.txt dosyalarında SEO ajansımızın en çok kullandığı yönergelerin kombinasyonlarını içerirler. Yine de aklınızda bulundurun; bunlar sadece ilham amaçlıdır. Gereksinimlerinizi karşılamak için her zaman robots.txt dosyasını özelleştirmeniz gerekir.
Tüm robotların her şeye erişmesine izin ver
Bu robots.txt dosyası, tüm arama motorları için izin verilmeyen kurallar sağlamaz:
User-agent: * Disallow:Başka bir deyişle, arama botlarının her şeyi taramasına izin verir. Boş bir robots.txt dosyasıyla aynı amaca hizmet eder veya hiçbir robots.txt dosyası oluşturmaz.
Tüm robotların her şeye erişmesini engelle
Örnek robots.txt dosyası, tüm arama motorlarına, sondaki eğik çizgiden sonra hiçbir şeye erişmemelerini söyler. Başka bir deyişle, tüm etki alanı:
User-agent: * Disallow: /Kısacası, bu robots.txt dosyası tüm arama motoru robotlarını engeller ve sitenizin arama sonuçları sayfalarında gösterilmesini durdurabilir.
Tüm robotların bir dosyayı taramasını engelle
Bu örnekte, tüm arama botlarının belirli bir dosyayı taramasını engelledik.
User-agent: * Disallow: /directory/this-is-a-file.pdfTüm robotların tek bir dosya türünü (doc, pdf, jpg) taramasını engelleyin
İndeksleme olmadığından, 'doc' veya 'pdf' gibi bir dosya meta robot “no-index” etiketi kullanılarak yapılamaz; belirli bir dosya türünün dizine eklenmesini durdurmak için aşağıdaki yönergeyi kullanabilirsiniz.
User-agent: * Disallow: /*.doc$ Disallow: /*.pdf$ Disallow: /*.jpg$Bu, web üzerinde başka bir yerden tek bir dosyaya bağlanmadığı sürece, bu türdeki tüm dosyaların indeksini kaldırmak için çalışacaktır.
Google'ın birden çok dizini taramasını engelle
Belirli bir bot veya tüm botlar için birden fazla dizinin taranmasını engellemek isteyebilirsiniz. Bu örnekte, Googlebot'un iki alt dizini taramasını engelliyoruz.
User-agent: Googlebot Disallow: /admin/ Disallow: /private/Bock'u kullanabileceğiniz dizin sayısında bir sınırlama olmadığını unutmayın. Direktifin geçerli olduğu kullanıcı aracısının altında her birini listeleyin.
Google'ın tüm parametreli URL'leri taramasını engelle
Bu yönerge, çok sayıda parametreli URL'nin oluşturulabildiği, yönlü gezinme kullanan web siteleri için özellikle yararlıdır.
User-agent: Googlebot Disallow: /*?Bu yönerge, tarama bütçenizin dinamik URL'lerde tüketilmesini engeller ve önemli sayfaların taranmasını en üst düzeye çıkarır. Bunu, özellikle arama işlevine sahip e-ticaret web sitelerinde düzenli olarak kullanıyorum.
Tüm botların bir alt dizini taramasını engelleyin, ancak içindeki bir sayfanın taranmasına izin verin
Bazen tarayıcıların sitenizin tam bir bölümüne erişmesini engellemek, ancak bir sayfayı erişilebilir durumda bırakmak isteyebilirsiniz. Bunu yaparsanız, aşağıdaki 'izin ver' ve 'izin verme' yönergeleri kombinasyonunu kullanın:
User-agent: * Disallow: /category/ Allow: /category/widget/Arama motorlarına belirli bir sayfa veya dosya hariç tüm dizini taramamalarını söyler.
WordPress için Robots.txt
Bu, bir WordPress robots.txt dosyası için önerdiğim temel yapılandırmadır. Yönetici sayfalarının, etiketlerin ve yazarların URL'lerinin taranmasını engeller, bu da bir WordPress web sitesinde gereksiz boşluklar oluşturabilir.
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /wp-admin/ Disallow: /readme.html Disallow: /refer/ Disallow: /tag/ Disallow: /author/ Disallow: /404-error/ Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xmlBu robots.txt dosyası çoğu WordPress web sitesinde iyi çalışır, ancak elbette her zaman kendi gereksinimlerinize göre ayarlamanız gerekir.
Hatalar için Robots.txt Dosyanızı Nasıl Denetleyebilirsiniz?
Benim zamanımda, robots.txt dosyalarında, teknik SEO'nun diğer tüm yönlerinden daha fazla sıralamayı etkileyen hata gördüm. Pek çok potansiyel olarak çelişen direktifle, sorunlar ortaya çıkabilir ve çıkabilir.
Bu nedenle, robots.txt dosyaları söz konusu olduğunda, sorunlara dikkat etmekte fayda var.
Neyse ki, Google Search Console içindeki "Kapsam" raporu, robots.txt sorunlarını kontrol etmeniz ve izlemeniz için bir yol sağlar.
Canlı robots dosyanızdaki hataları kontrol etmek veya yeni bir robots.txt dosyasını dağıtmadan önce test etmek için Google'ın şık Robots.txt Test Aracını da kullanabilirsiniz.
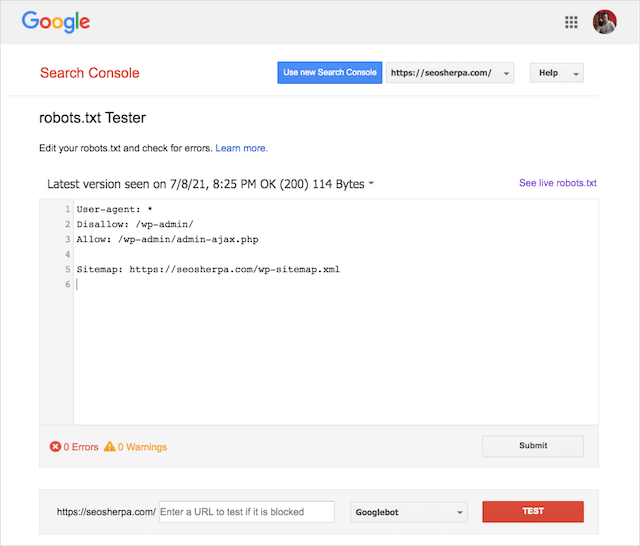
En yaygın sorunları, ne anlama geldiklerini ve nasıl ele alınacağını ele alarak bitireceğiz.
Gönderilen URL robots.txt tarafından engellendi
Bu hata, gönderdiğiniz site haritalarındaki URL'lerden en az birinin robots.txt tarafından engellendiği anlamına gelir.

Doğru ayarlanmış bir site haritası, yalnızca arama motorlarında dizine eklenmesini istediğiniz URL'leri içermelidir. Bu nedenle, dizine eklenmemiş, standart hale getirilmiş veya yeniden yönlendirilmiş sayfalar içermemelidir.
Bu en iyi uygulamaları izlediyseniz, site haritanızda gönderilen hiçbir sayfa robots.txt tarafından engellenmemelidir.
Kapsam raporunda "Gönderilen URL robots.txt tarafından engellendi" ifadesini görürseniz, hangi sayfaların etkilendiğini araştırmalı ve ardından o sayfanın engellemesini kaldırmak için robots.txt dosyanızı değiştirmelisiniz.
İçeriği hangi yönergenin engellediğini görmek için Google'ın robots.txt test aracını kullanabilirsiniz.
Robots.txt tarafından engellendi
Bu "hata", robots.txt dosyanız tarafından engellenen ve şu anda Google'ın dizininde olmayan sayfalarınız olduğu anlamına gelir.

Bu içeriğin yardımcı programı varsa ve dizine eklenmesi gerekiyorsa, robots.txt dosyasındaki gezinme bloğunu kaldırın.
Kısa bir uyarı:
"Robots.txt tarafından engellendi" mutlaka bir hata değildir. Aslında, tam olarak istediğiniz sonuç olabilir.
Örneğin, onları Google'ın dizininden hariç tutmak amacıyla robots.txt içindeki belirli dosyaları engellemiş olabilirsiniz. Öte yandan, dizine eklememek amacıyla belirli sayfaların taranmasını engellediyseniz, tarama bloğunu kaldırmayı düşünün ve bunun yerine bir robotun meta etiketini kullanın.
İçeriğin Google dizininden hariç tutulmasını garanti etmenin tek yolu budur.
Dizine Eklendi, Robots.txt Tarafından Engellendi
Bu hata, robots.txt tarafından engellenen içeriğin bir kısmının hâlâ Google'da dizine eklendiği anlamına gelir.
Bu, web'in başka bir yerinden bağlantılı olduğu için içerik Googlebot tarafından hala keşfedilebilir olduğunda gerçekleşir. Kısacası, Googlebot bu içeriği tarar ve ardından web sitenizin robots.txt dosyasını ziyaret etmeden önce izin verilmeyen yönergeyi gördüğü yerde onu dizine ekler.
O zamana kadar, çok geç. Ve indekslenir:
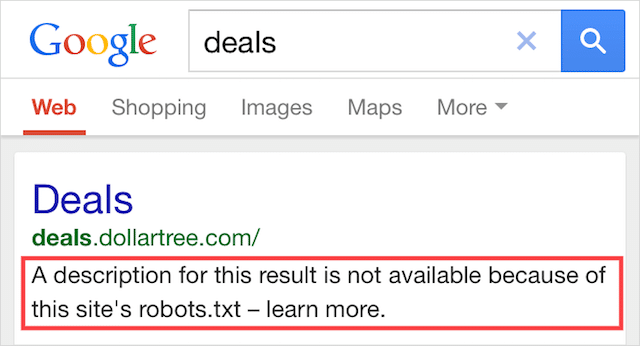
Bunu evde delmeme izin ver:
İçeriği Google'ın arama sonuçlarından çıkarmaya çalışıyorsanız, robots.txt doğru çözüm değildir.
Bunun yerine indekslemeyi önlemek için tarama bloğunu kaldırmanızı ve meta robots indekssiz etiketi kullanmanızı öneririm.
Aksine, bu içeriği yanlışlıkla engellediyseniz ve Google'ın dizininde tutmak istiyorsanız, robots.txt'deki tarama bloğunu kaldırın ve orada bırakın.
Bu, Google aramadaki içeriğin görünürlüğünü iyileştirmeye yardımcı olabilir.
Son düşünceler
Robots.txt, web sitenizin içeriğinin taranmasını ve dizine eklenmesini iyileştirmek için kullanılabilir, bu da SERP'lerde daha görünür olmanıza yardımcı olur.
Etkili kullanıldığında, web sitenizdeki en önemli metindir. Ancak dikkatsizce kullanıldığında, web sitenizin kodunda Aşil topuğu olacaktır.
İyi haber, yalnızca temel bir kullanıcı aracı anlayışı ve bir avuç yönerge ile daha iyi arama sonuçları elinizin altında.
Tek soru, robots.txt dosyanızda hangi protokolleri kullanacaksınız?
Aşağıdaki yorumlarda bana bildirin.