
Robots.txt: الدليل النهائي لتحسين محركات البحث (إصدار 2021)
نشرت: 2021-06-10 ستتعلم اليوم كيفية إنشاء أحد أكثر الملفات أهمية لتحسين محركات البحث لموقع الويب:
ستتعلم اليوم كيفية إنشاء أحد أكثر الملفات أهمية لتحسين محركات البحث لموقع الويب:
(ملف robots.txt).
على وجه التحديد ، سأوضح لك كيفية استخدام بروتوكولات استبعاد الروبوتات لحظر برامج الروبوت من صفحات معينة ، وزيادة وتيرة الزحف ، وتحسين ميزانية الزحف ، والحصول في النهاية على المزيد من ترتيب الصفحة الصحيحة في SERPs.
أنا أغطي:
- ما هو ملف robots.txt
- لماذا يعتبر ملف robots.txt مهمًا
- كيف يعمل ملف robots.txt
- وكلاء المستخدم والتوجيهات في ملف robots.txt
- Robots.txt مقابل الروبوتات الوصفية
- كيف تجد ملف robots.txt الخاص بك
- إنشاء ملف robots.txt الخاص بك
- أفضل ممارسات ملف Robots.txt
- أمثلة على ملف robots.txt
- كيفية تدقيق ملف robots.txt الخاص بك بحثًا عن الأخطاء
بالإضافة إلى الكثير. دعنا نتعمق في الأمر.
ما هو ملف Robots.txt؟ ولماذا تحتاج واحد
بعبارات بسيطة ، يعد ملف robots.txt دليلًا إرشاديًا لروبوتات الويب.
تُعلم برامج الروبوت بجميع أنواعها ، وأقسام الموقع التي يجب (ولا ينبغي) الزحف إليها.
ومع ذلك ، يتم استخدام ملف robots.txt بشكل أساسي باعتباره "مدونة سلوك" للتحكم في نشاط روبوتات محرك البحث (برامج زحف الويب AKA).

يتم فحص ملف robots.txt بانتظام بواسطة كل محرك بحث رئيسي (بما في ذلك Google و Bing و Yahoo) للحصول على إرشادات حول كيفية الزحف إلى موقع الويب. تُعرف هذه التعليمات باسم التوجيهات .
إذا لم تكن هناك توجيهات - أو لم يكن هناك ملف robots.txt - فستقوم محركات البحث بالزحف إلى موقع الويب بأكمله والصفحات الخاصة وكل شيء.
على الرغم من أن معظم محركات البحث مطيعة ، فمن المهم ملاحظة أن الالتزام بتوجيهات robots.txt أمر اختياري. إذا رغبوا في ذلك ، يمكن لمحركات البحث اختيار تجاهل ملف robots.txt الخاص بك.
لحسن الحظ ، Google ليس أحد محركات البحث تلك. يميل Google إلى الامتثال للتعليمات الواردة في ملف robots.txt.
ما سبب أهمية ملف robots.txt؟
لا يعد وجود ملف robots.txt أمرًا بالغ الأهمية للعديد من مواقع الويب ، خاصة المواقع الصغيرة جدًا.
ذلك لأن Google يمكنها عادةً العثور على جميع الصفحات الأساسية على الموقع وفهرستها.
ولن يقوموا تلقائيًا بفهرسة المحتوى المكرر أو الصفحات غير المهمة.
ولكن مع ذلك ، لا يوجد سبب وجيه لعدم امتلاك ملف robots.txt - لذا أوصيك أن يكون لديك ملف.
يمنحك ملف robots.txt تحكمًا أكبر في ما يمكن لمحركات البحث الزحف إليه وما لا يمكنها الزحف إليه على موقع الويب الخاص بك ، وهذا مفيد لعدة أسباب:
يسمح بحظر الصفحات غير العامة من محركات البحث
في بعض الأحيان يكون لديك صفحات على موقعك لا تريد فهرستها.
على سبيل المثال ، قد تقوم بتطوير موقع ويب جديد في بيئة مرحلية تريد التأكد من إخفاؤها عن المستخدمين حتى الإطلاق.
أو قد يكون لديك صفحات تسجيل دخول إلى مواقع الويب لا تريدها أن تظهر في SERPs.
إذا كان الأمر كذلك ، يمكنك استخدام ملف robots.txt لمنع هذه الصفحات من برامج الزحف لمحركات البحث.
ضوابط محرك البحث الزحف الميزانية
إذا كنت تواجه صعوبة في فهرسة جميع صفحاتك في محركات البحث ، فقد تواجه مشكلة ميزانية الزحف.
ببساطة ، تستخدم محركات البحث الوقت المخصص للزحف إلى المحتوى الخاص بك على صفحات موقع الويب الخاص بك.

من خلال حظر عناوين URL منخفضة الفائدة باستخدام ملف robots.txt ، يمكن لروبوتات محركات البحث أن تنفق المزيد من ميزانية الزحف الخاصة بها على الصفحات الأكثر أهمية.
يمنع فهرسة الموارد
من أفضل الممارسات استخدام التوجيه الوصفي "no-index" لمنع فهرسة الصفحات الفردية.
تكمن المشكلة في أن التوجيهات الوصفية لا تعمل بشكل جيد مع موارد الوسائط المتعددة ، مثل ملفات PDF ومستندات Word.
هذا هو المكان الذي يكون فيه ملف robots.txt مفيدًا.
يمكنك إضافة سطر نصي بسيط إلى ملف robots.txt الخاص بك ، ويتم حظر محركات البحث من الوصول إلى ملفات الوسائط المتعددة هذه.
(سأوضح لك بالضبط كيفية القيام بذلك لاحقًا في هذا المنشور)
كيف (بالضبط) يعمل ملف Robots.txt؟
كما شاركت بالفعل ، يعمل ملف robots.txt كدليل إرشادي لروبوتات محرك البحث. إنه يخبر روبوتات البحث أين (وأين لا) يجب عليهم الزحف.
هذا هو السبب في أن زاحف البحث سيبحث عن ملف robots.txt بمجرد وصوله إلى موقع ويب.
إذا عثر على ملف robots.txt ، فسيقرأه الزاحف أولاً قبل متابعة الزحف إلى الموقع.
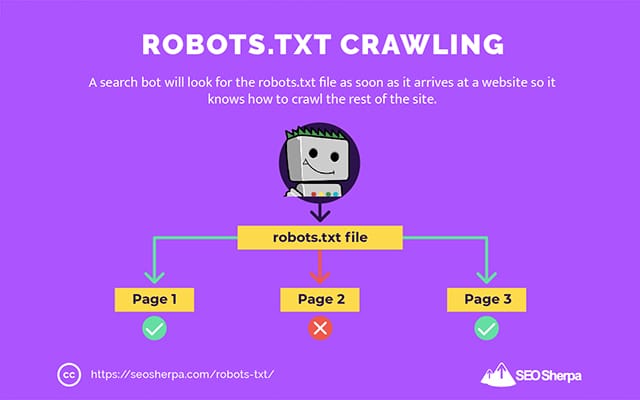
إذا لم يعثر زاحف الويب على ملف robots.txt ، أو إذا كان الملف لا يحتوي على توجيهات تمنع نشاط روبوتات البحث ، فسيستمر الزاحف في تعقب الموقع بالكامل كالمعتاد.
لكي يتم العثور على ملف robots.txt وقراءته بواسطة روبوتات البحث ، يتم تنسيق ملف robots.txt بطريقة خاصة جدًا.
أولاً ، هو ملف نصي لا يحتوي على كود ترميز HTML (ومن هنا يأتي ملحق .txt).
ثانيًا ، يتم وضعه في المجلد الجذر لموقع الويب ، على سبيل المثال ، https://seosherpa.com/robots.txt.
ثالثًا ، يستخدم بنية قياسية مشتركة لجميع ملفات robots.txt ، مثل:
Sitemap: [URL location of sitemap] User-agent: [bot identifier] [directive 1] [directive 2] [directive ...] User-agent: [another bot identifier] [directive 1] [directive 2] [directive ...]قد تبدو هذه الصيغة شاقة للوهلة الأولى ، لكنها في الواقع بسيطة للغاية.
باختصار ، أنت تحدد الروبوت (وكيل المستخدم) الذي تنطبق عليه الإرشادات ثم تحدد القواعد (التوجيهات) التي يجب أن يتبعها الروبوت.
دعنا نستكشف هذين المكونين بمزيد من التفصيل.
وكلاء المستخدم
وكيل المستخدم هو الاسم المستخدم لتعريف برامج زحف ويب معينة - وبرامج أخرى نشطة على الإنترنت.
هناك المئات من وكلاء المستخدم ، بما في ذلك وكلاء لأنواع الأجهزة والمتصفحات.
معظمها غير ذي صلة في سياق ملف robots.txt وتحسين محركات البحث. من ناحية أخرى ، يجب أن تعرف هذه:
- جوجل: Googlebot
- صور جوجل: Googlebot-Image
- فيديو Google: Googlebot-Video
- أخبار Google: Googlebot-News
- بنج: بينجبوت
- صور ومقاطع فيديو بنج: MSNBot-Media
- ياهو: سلورب
- ياندكس: YandexBot
- بايدو : بايدوسبيدير
- DuckDuckGo: DuckDuckBot
من خلال ذكر وكيل المستخدم ، يمكنك تعيين قواعد مختلفة لمحركات البحث المختلفة.

على سبيل المثال ، إذا أردت أن تظهر صفحة معينة في نتائج بحث Google وليس في عمليات بحث Baidu ، فيمكنك تضمين مجموعتين من الأوامر في ملف robots.txt: مجموعة مسبوقة بـ "User-agent: Bingbot" ومجموعة أخرى مسبوقة بواسطة "User-agent: Baiduspider."
يمكنك أيضًا استخدام حرف البدل النجم (*) إذا كنت تريد تطبيق توجيهاتك على جميع وكلاء المستخدم.
على سبيل المثال ، لنفترض أنك تريد منع جميع روبوتات محركات البحث من الزحف إلى موقعك باستثناء DuckDuckGo. إليك كيف تفعل ذلك:
User-agent: * Disallow: / User-agent: DuckDuckBot Allow: /Sidenote: إذا كانت هناك أوامر متناقضة في ملف robots.txt ، فسيتبع الروبوت الأمر الأكثر دقة.
لهذا السبب في المثال أعلاه ، يعرف DuckDuckBot أنه يقوم بالزحف إلى موقع الويب ، على الرغم من أن التوجيه السابق (ينطبق على جميع برامج الروبوت) ينص على عدم الزحف. باختصار ، سوف يتبع الروبوت التعليمات التي تنطبق عليهم بدقة أكبر.
التوجيهات
التوجيهات هي قواعد السلوك التي تريد أن يتبعها وكيل المستخدم. بمعنى آخر ، تحدد التوجيهات كيفية قيام روبوت البحث بالزحف إلى موقع الويب الخاص بك.
فيما يلي التوجيهات التي يدعمها GoogleBot حاليًا ، بالإضافة إلى استخدامها في ملف robots.txt:
عدم السماح
استخدم هذا التوجيه لمنع روبوتات البحث من الزحف إلى ملفات وصفحات معينة على مسار URL محدد.

على سبيل المثال ، إذا أردت منع GoogleBot من الوصول إلى موقع wiki الخاص بك وجميع صفحاته ، فيجب أن يحتوي ملف robots.txt الخاص بك على هذا التوجيه:
User-agent: GoogleBot Disallow: /wikiيمكنك استخدام الأمر disallow لمنع الزحف إلى عنوان URL دقيق ، وجميع الملفات والصفحات الموجودة في دليل معين ، وحتى موقع الويب بالكامل.
السماح
يكون التوجيه allow مفيدًا إذا كنت تريد السماح لمحركات البحث بالزحف إلى دليل فرعي أو صفحة معينة - في قسم غير مسموح به من موقعك.

لنفترض أنك أردت منع جميع محركات البحث من الزحف إلى المنشورات في مدونتك باستثناء واحدة ؛ عندها يمكنك استخدام الأمر allow مثل هذا:
User-agent: * Disallow: /blog Allow: /blog/allowable-postنظرًا لأن روبوتات البحث تتبع دائمًا التعليمات الأكثر دقة الواردة في ملف robots.txt ، فإنهم يعرفون الزحف إلى / blog / allowable-post ، لكنهم لن يزحفوا إلى المنشورات أو الملفات الأخرى في هذا الدليل مثل ؛
- / blog / post-one /
- / blog / post-two /
- /blog/file-name.pdf
يدعم كل من Google و Bing هذا التوجيه. لكن محركات البحث الأخرى لا تفعل ذلك.
خريطة الموقع
يتم استخدام توجيه خريطة الموقع لتحديد موقع ملف (خرائط) موقع XML لمحركات البحث.
إذا كنت مستخدمًا جديدًا لملفات Sitemap ، يتم استخدامها لسرد الصفحات التي تريد الزحف إليها وفهرستها في محركات البحث.
بتضمين توجيه خريطة الموقع في ملف robots.txt ، فإنك تساعد محركات البحث في العثور على خريطة موقعك ، وبالتالي ، تقوم بالزحف إلى أهم صفحات موقعك على الويب وفهرستها.
مع ذلك ، إذا كنت قد قدمت بالفعل خريطة موقع XML الخاصة بك من خلال Search Console ، فإن إضافة خريطة (خرائط) الموقع الخاصة بك في ملف robots.txt تعد زائدة عن الحاجة إلى حد ما بالنسبة لـ Google. ومع ذلك ، فمن الأفضل استخدام توجيه خريطة الموقع لأنه يخبر محركات البحث مثل Ask و Bing و Yahoo أين يمكن العثور على خريطة (خرائط) الموقع الخاصة بك.
فيما يلي مثال على ملف robots.txt باستخدام توجيه خريطة الموقع:
Sitemap: https://www.website.com/sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/لاحظ موضع توجيه خريطة الموقع في ملف robots.txt. من الأفضل وضعها في أعلى ملف robots.txt الخاص بك. يمكن أيضًا وضعها في الأسفل.
إذا كانت لديك خرائط مواقع متعددة ، فيجب عليك تضمينها جميعًا في ملف robots.txt الخاص بك. إليك الشكل الذي قد يبدو عليه ملف robots.txt إذا كان لدينا خرائط مواقع XML منفصلة للصفحات والمشاركات:
Sitemap: http://website.com/post-sitemap.xml Sitemap: http://website.com/page-sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/في كلتا الحالتين ، ما عليك سوى ذكر كل خريطة موقع XML مرة واحدة لأن جميع وكلاء المستخدم المدعومين سيتبعون التوجيه.
لاحظ أنه على عكس توجيهات robots.txt الأخرى ، التي تسرد المسارات ، يجب أن يذكر توجيه خريطة الموقع عنوان URL المطلق لخريطة موقع XML ، بما في ذلك البروتوكول واسم المجال وامتداد نطاق المستوى الأعلى.
تعليقات
يعد التعليق "التوجيه" مفيدًا للبشر ولكن لا يتم استخدامه بواسطة روبوتات البحث.

يمكنك إضافة تعليقات لتذكيرك بسبب وجود توجيهات معينة أو منع أولئك الذين لديهم حق الوصول إلى ملف robots.txt من حذف التوجيهات المهمة. باختصار ، تُستخدم التعليقات لإضافة ملاحظات إلى ملف robots.txt الخاص بك.
لإضافة تعليق ، اكتب ". #" متبوعًا بنص التعليق.
# Don't allow access to the /wp-admin/ directory for all robots. User-agent: * Disallow: /wp-admin/يمكنك إضافة تعليق في بداية السطر (كما هو موضح أعلاه) أو بعد توجيه على نفس السطر (كما هو موضح أدناه):
User-agent: * #Applies to all robots Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.أينما اخترت كتابة تعليقك ، فسيتم تجاهل كل شيء بعد التجزئة.
متابعة على طول حتى الآن؟
رائعة! لقد غطينا الآن التوجيهات الرئيسية التي ستحتاجها لملف robots.txt الخاص بك - وهذه أيضًا هي التوجيهات الوحيدة التي تدعمها Google.
لكن ماذا عن محركات البحث الأخرى؟ في حالة Bing و Yahoo و Yandex ، هناك توجيه آخر يمكنك استخدامه:
تأخير الزحف
يعد توجيه "تأجيل الزحف" توجيهًا غير رسمي يُستخدم لمنع الخوادم من التحميل الزائد مع عدد كبير جدًا من طلبات الزحف.
بمعنى آخر ، يمكنك استخدامه للحد من التردد الذي يمكن لمحرك البحث فيه الزحف إلى موقعك.

ضع في اعتبارك ، إذا كان بإمكان محركات البحث تحميل الخادم الخاص بك بشكل زائد عن طريق الزحف إلى موقع الويب الخاص بك بشكل متكرر ، فإن إضافة توجيه تأخير الزحف إلى ملف robots.txt الخاص بك لن يؤدي إلا إلى حل المشكلة مؤقتًا.
قد تكون الحالة ، موقع الويب الخاص بك يعمل على استضافة سيئة أو بيئة استضافة خاطئة ، وهذا شيء يجب عليك إصلاحه بسرعة.
يعمل توجيه تأخير الزحف من خلال تحديد الوقت بالثواني الذي يمكن لروبوت البحث الزحف خلاله إلى موقعك على الويب.
على سبيل المثال ، إذا قمت بتعيين تأخير الزحف الخاص بك إلى 5 ، فإن روبوتات البحث ستقسم اليوم إلى نوافذ مدتها خمس ثوان ، وتزحف إلى صفحة واحدة فقط (أو لا شيء) في كل نافذة ، بحد أقصى 17280 عنوان URL خلال اليوم.
مع ذلك ، كن حذرًا عند تعيين هذا التوجيه ، خاصةً إذا كان لديك موقع ويب كبير. فقط 17،280 عنوان URL يتم الزحف إليها يوميًا ليست مفيدة جدًا إذا كان موقعك يحتوي على ملايين الصفحات.
تختلف الطريقة التي يتعامل بها كل محرك بحث مع توجيه تأخير الزحف. دعنا نقسمها أدناه:
تتبع الزحف و Bing و Yahoo و Yandex
يدعم كل من Bing و Yahoo و Yandex توجيه تأخير الزحف في ملف robots.txt.
هذا يعني أنه يمكنك تعيين توجيه تأخير الزحف لوكلاء مستخدم BingBot و Slurp و YandexBot ، وسوف يخنق محرك البحث عملية الزحف وفقًا لذلك.
لاحظ أن كل محرك بحث يفسر تأخير الزحف بطريقة مختلفة قليلاً ، لذا تأكد من مراجعة الوثائق الخاصة به:
- بنج وياهو
- ياندكس
ومع ذلك ، فإن تنسيق توجيه تأخير الزحف لكل من هذه المحركات هو نفسه. يجب عليك وضعه مباشرة بعد توجيه عدم السماح أو السماح. هنا مثال:
User-agent: BingBot Allow: /widgets/ Crawl-delay: 5تأخير الزحف وجوجل
لا يدعم زاحف Google توجيه تأخير الزحف ، لذلك لا فائدة من تعيين تأخير الزحف لـ GoogleBot في ملف robots.txt.
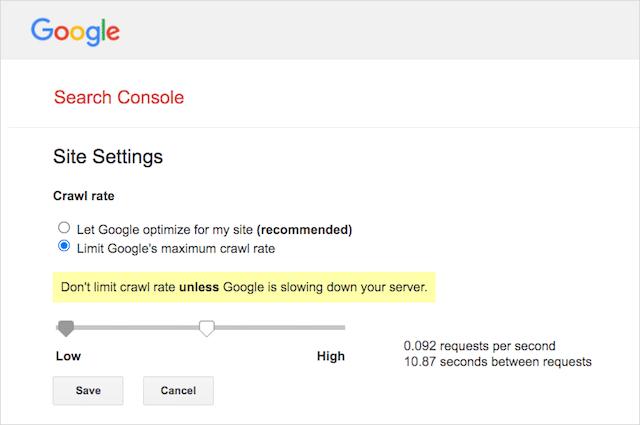
ومع ذلك ، تدعم Google تحديد معدل الزحف في Google Search Console. هيريس كيفية القيام بذلك:
- انتقل إلى صفحة الإعدادات في Google Search Console.
- اختر الخاصية التي تريد تحديد معدل الزحف لها
- انقر فوق "الحد الأقصى لمعدل الزحف من Google".
- اضبط شريط التمرير على معدل الزحف المفضل لديك. بشكل افتراضي ، يحتوي معدل الزحف على الإعداد "السماح لـ Google بالتحسين لموقعي (موصى به)".
تأخير الزحف وبايدو
مثل Google ، لا تدعم Baidu توجيه تأخير الزحف. ومع ذلك ، من الممكن تسجيل حساب Baidu Webmaster Tools حيث يمكنك التحكم في تكرار الزحف ، على غرار Google Search Console.
الخط السفلي؟ يخبر ملف robots.txt عناكب محركات البحث بعدم الزحف إلى صفحات معينة على موقع الويب الخاص بك.
Robots.txt مقابل meta robots مقابل x-robots
هناك الكثير من إرشادات "الروبوتات" الموجودة هناك. ما هي الاختلافات ، أم أنها متشابهة؟
اسمحوا لي أن أقدم شرحًا موجزًا:
أولاً ، يعد ملف robots.txt ملفًا نصيًا فعليًا ، في حين أن meta و x-robots عبارة عن علامات داخل شفرة صفحة الويب.
ثانيًا ، يقدم ملف robots.txt اقتراحات روبوتات حول كيفية الزحف إلى صفحات موقع الويب. من ناحية أخرى ، توفر التوجيهات الوصفية لبرامج الروبوت إرشادات صارمة للغاية حول الزحف إلى محتوى الصفحة وفهرسته.
وبخلاف ما هم عليه ، فإن الثلاثة يخدمون وظائف مختلفة.
يفرض ملف robots.txt سلوك الزحف على مستوى الموقع أو الدليل ، بينما يمكن لبرامج meta و x-robots إملاء سلوك الفهرسة على مستوى الصفحة الفردية (أو عنصر الصفحة).

على العموم:
إذا كنت ترغب في منع فهرسة صفحة ما ، فيجب عليك استخدام العلامة الوصفية لبرامج الروبوت "no-index". لا يضمن عدم السماح بإحدى الصفحات في ملف robots.txt عدم ظهورها في محركات البحث (توجيهات robots.txt هي اقتراحات في النهاية). بالإضافة إلى ذلك ، لا يزال بإمكان روبوت محرك البحث العثور على عنوان URL هذا وفهرسته إذا كان مرتبطًا من موقع ويب آخر.

على العكس من ذلك ، إذا كنت تريد إيقاف فهرسة ملف وسائط ، فإن ملف robots.txt هو السبيل للذهاب. لا يمكنك إضافة علامات meta robots إلى ملفات مثل jpegs أو PDF.
كيفية البحث عن ملف robots.txt
إذا كان لديك بالفعل ملف robots.txt على موقع الويب الخاص بك ، فستتمكن من الوصول إليه على yourdomain.com/robots.txt.
انتقل إلى URL في متصفحك.
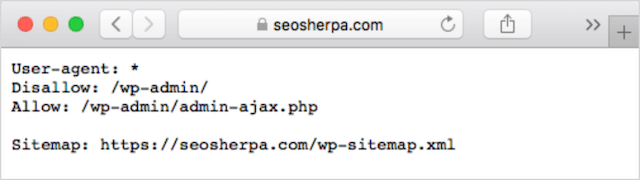
إذا رأيت صفحة نصية مثل الصفحة أعلاه ، فهذا يعني أن لديك ملف robots.txt.
كيفية إنشاء ملف Robots.txt
إذا لم يكن لديك ملف robots.txt بالفعل ، فسيكون إنشاء ملف أمرًا بسيطًا.
أولاً ، افتح Notepad أو Microsoft Word أو أي محرر نصوص واحفظ الملف باسم "robots".
تأكد من استخدام الأحرف الصغيرة ، واختر .txt كملحق لنوع الملف:

ثانيًا ، أضف توجيهاتك. على سبيل المثال ، إذا أردت عدم السماح لجميع روبوتات البحث بالزحف إلى الدليل / تسجيل الدخول / الدليل ، فاكتب هذا:
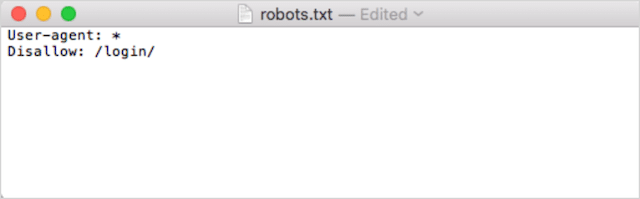
استمر في إضافة التوجيهات حتى تصبح راضيًا عن ملف robots.txt الخاص بك.
بدلاً من ذلك ، يمكنك إنشاء ملف robots.txt الخاص بك باستخدام أداة مثل هذه من Ryte.

تتمثل إحدى ميزات استخدام الأداة في أنها تقلل الخطأ البشري.
قد ينتهي خطأ واحد صغير في بنية ملف robots.txt بكارثة تحسين محركات البحث.
ومع ذلك ، فإن عيب استخدام منشئ robots.txt هو أن فرصة التخصيص ضئيلة للغاية.
لهذا السبب أوصيك بتعلم كتابة ملف robot.txt بنفسك. يمكنك بعد ذلك إنشاء ملف robots.txt وفقًا لمتطلباتك تمامًا.
أين تضع ملف Robots.txt الخاص بك
أضف ملف robots.txt الخاص بك في دليل المستوى الأعلى للنطاق الفرعي الذي ينطبق عليه.
على سبيل المثال ، للتحكم في سلوك الزحف على yourdomain.com ، يجب أن يكون ملف robots.txt يمكن الوصول إليه من مسار عنوان URL الخاص بـ yourdomain.com/robots.txt .
من ناحية أخرى ، إذا كنت تريد التحكم في الزحف على نطاق فرعي مثل shop.yourdomain.com ، فيجب أن يكون ملف robots.txt متاحًا في shop.yourdomain.com/robots.txt مسار URL.
القواعد الذهبية هي:
- امنح كل مجال فرعي على موقع الويب الخاص بك ملف robots.txt الخاص به.
- قم بتسمية ملف (ملفات) robots.txt كلها بأحرف صغيرة.
- ضع الملف في الدليل الجذر للنطاق الفرعي الذي يشير إليه.
إذا تعذر العثور على ملف robots.txt في الدليل الجذر ، فستفترض محركات البحث عدم وجود توجيهات وستقوم بالزحف إلى موقع الويب الخاص بك بالكامل.
أفضل ممارسات ملف Robots.txt
بعد ذلك ، دعنا نتناول قواعد ملفات robots.txt. استخدم أفضل الممارسات هذه لتجنب الأخطاء الشائعة في ملف robots.txt:
استخدم سطرًا جديدًا لكل توجيه
يجب وضع كل أمر في ملف robots.txt في سطر جديد.
إذا لم يكن الأمر كذلك ، فسوف يتم الخلط بين محركات البحث حول ما يتم الزحف إليه (والفهرسة).
هذا ، على سبيل المثال ، تم تكوينه بشكل غير صحيح :
User-agent: * Disallow: /folder/ Disallow: /another-folder/من ناحية أخرى ، يعد هذا ملف robots.txt تم إعداده بشكل صحيح :
User-agent: * Disallow: /folder/ Disallow: /another-folder/الخصوصية "تقريبًا" تفوز دائمًا
عندما يتعلق الأمر بـ Google و Bing ، يفوز التوجيه الأكثر دقة.
على سبيل المثال ، يتفوق الأمر Allow هذا على الأمر Disallow لأن طول حرفه أطول.
User-agent: * Disallow: /about/ Allow: /about/company/يعرف كل من Google و Bing كيفية الزحف إلى / about / company / ولكن ليس أي صفحات أخرى في الدليل / about /.
ومع ذلك ، في حالة محركات البحث الأخرى ، فإن العكس هو الصحيح.
بشكل افتراضي ، بالنسبة لجميع محركات البحث الرئيسية بخلاف Google و Bing ، فإن التوجيه المطابق الأول هو الفائز دائمًا .
في المثال أعلاه ، ستتبع محركات البحث التوجيه Disallow وتتجاهل الأمر Allow الذي يعني أنه لن يتم الزحف إلى صفحة / about / company.
ضع ذلك في الاعتبار عند إنشاء قواعد لجميع محركات البحث.
مجموعة واحدة فقط من التوجيهات لكل وكيل مستخدم
إذا احتوى ملف robots.txt على مجموعات متعددة من التوجيهات لكل وكيل مستخدم ، هل يمكن أن يكون الأمر محيرًا؟
ليس بالضرورة للروبوتات ، لأنها ستجمع كل القواعد من الإعلانات المختلفة في مجموعة واحدة وتتبعها جميعًا ، ولكن من أجلك.
لتجنب احتمال حدوث خطأ بشري ، حدد وكيل المستخدم مرة واحدة ثم قم بإدراج جميع التوجيهات التي تنطبق على وكيل المستخدم أدناه.

بالحفاظ على الأشياء مرتبة وبسيطة ، فأنت أقل عرضة لارتكاب خطأ فادح.
استخدم أحرف البدل (*) لتبسيط التعليمات
هل لاحظت أحرف البدل (*) في المثال أعلاه؟
هذا صحيح؛ يمكنك استخدام أحرف البدل (*) لتطبيق القواعد على جميع وكلاء المستخدم ولمطابقة أنماط عنوان URL عند إعلان التوجيهات.
على سبيل المثال ، إذا كنت ترغب في منع روبوتات البحث من الوصول إلى عناوين URL لفئات المنتجات ذات المعلمات على موقع الويب الخاص بك ، فيمكنك سرد كل فئة على النحو التالي:
User-agent: * Disallow: /products/watches? Disallow: /products/handbags? Disallow: /products/shoes?أو يمكنك استخدام حرف بدل يطبق القاعدة على جميع الفئات. إليك كيف سيبدو:
User-agent: * Disallow: /products/*?يمنع هذا المثال محركات البحث من الزحف إلى جميع عناوين URL داخل / product / المجلد الفرعي الذي يحتوي على علامة استفهام. بعبارة أخرى ، أي عناوين URL لفئة المنتج محددة بمعلمات.
تدعم Google و Bing و Yahoo استخدام أحرف البدل ضمن توجيهات robots.txt و Ask.
استخدم “$” لتحديد نهاية عنوان URL
للإشارة إلى نهاية عنوان URL ، استخدم علامة الدولار ( $ ) بعد مسار ملف robots.txt.
لنفترض أنك تريد إيقاف روبوتات البحث عن الوصول إلى جميع ملفات .doc على موقع الويب الخاص بك ؛ ثم يمكنك استخدام هذا التوجيه:
User-agent: * Disallow: /*.doc$سيؤدي هذا إلى منع محركات البحث من الوصول إلى أي عناوين URL تنتهي بامتداد doc.
هذا يعني أنهم لن يقوموا بالزحف إلى /media/file.doc ، لكنهم سيزحفون إلى /media/file.doc؟id=72491 لأن عنوان URL هذا لا ينتهي بـ ".doc."
يحصل كل نطاق فرعي على ملف robots.txt الخاص به
تنطبق توجيهات Robots.txt فقط على المجال (الفرعي) الذي يتم استضافة ملف robots.txt عليه.
هذا يعني إذا كان موقعك يحتوي على نطاقات فرعية متعددة مثل:
- domain.com
- Tickets.domain.com
- events.domain.com
سيتطلب كل نطاق فرعي ملف robots.txt الخاص به.
يجب دائمًا إضافة ملف robots.txt في الدليل الجذر لكل نطاق فرعي. إليك ما ستبدو عليه المسارات باستخدام المثال أعلاه:
- domain.com/robots.txt
- Tickets.domain.com/robots.txt
- events.domain.com/robots.txt
لا تستخدم noindex في ملف robots.txt الخاص بك
ببساطة ، لا يدعم Google أمر no-index في ملف robots.txt.
بينما اتبعتها Google في الماضي ، اعتبارًا من يوليو 2019 ، توقفت Google عن دعمها بالكامل.
وإذا كنت تفكر في استخدام التوجيه no-index robots.txt للمحتوى بدون فهرسة على محركات البحث الأخرى ، ففكر مرة أخرى:
لم يعمل توجيه no-index غير الرسمي مطلقًا في Bing.
إلى حد بعيد ، فإن أفضل طريقة لعدم فهرسة المحتوى في محركات البحث هي تطبيق علامة meta robots بدون فهرسة على الصفحة التي تريد استبعادها.
احتفظ بملف robots.txt الخاص بك أقل من 512 كيلوبايت
لدى Google حاليًا حد لحجم ملف robots.txt يبلغ 500 كيلو بايت (512 كيلو بايت).
هذا يعني أنه قد يتم تجاهل أي محتوى بعد 512 كيلوبايت.

ومع ذلك ، نظرًا لأن حرفًا واحدًا يستهلك بايتًا واحدًا فقط ، فيجب أن يكون ملف robots.txt الخاص بك ضخمًا للوصول إلى الحد الأقصى لحجم الملف (512000 حرف ، على وجه الدقة). اجعل ملف robots.txt منخفضًا عن طريق التركيز بشكل أقل على الصفحات المستبعدة بشكل فردي والمزيد على الأنماط الأوسع التي يمكن أن تتحكم بها البطاقات البدل.
ليس من الواضح ما إذا كانت محركات البحث الأخرى لديها أقصى حجم مسموح به لملفات robots.txt.
أمثلة على ملف robots.txt
فيما يلي بعض الأمثلة على ملفات robots.txt.
وهي تشمل مجموعات من التوجيهات التي تستخدمها وكالة تحسين محركات البحث (SEO) الأكثر استخدامًا في ملفات robots.txt للعملاء. ضع في اعتبارك ، على الرغم من ؛ هذه لأغراض الإلهام فقط. ستحتاج دائمًا إلى تخصيص ملف robots.txt لتلبية متطلباتك.
السماح لجميع الروبوتات بالوصول إلى كل شيء
لا يوفر ملف robots.txt هذا قواعد عدم السماح لجميع محركات البحث:
User-agent: * Disallow:بمعنى آخر ، يسمح لروبوتات البحث بالزحف إلى كل شيء. إنه يخدم نفس الغرض كملف robots.txt فارغ أو لا يوجد ملف robots.txt على الإطلاق.
منع جميع الروبوتات من الوصول إلى كل شيء
يخبر ملف robots.txt كمثال جميع محركات البحث بعدم الوصول إلى أي شيء بعد الشرطة المائلة اللاحقة. بمعنى آخر ، المجال بأكمله:
User-agent: * Disallow: /باختصار ، يحظر ملف robots.txt هذا جميع روبوتات محركات البحث وقد يمنع ظهور موقعك على صفحات نتائج البحث.
منع جميع برامج الروبوت من الزحف إلى ملف واحد
في هذا المثال ، نحظر جميع روبوتات البحث من الزحف إلى ملف معين.
User-agent: * Disallow: /directory/this-is-a-file.pdfمنع جميع برامج الروبوت من الزحف إلى نوع ملف واحد (doc ، pdf ، jpg)
نظرًا لعدم الفهرسة ، لا يمكن عمل ملف مثل "doc" أو "pdf" باستخدام علامة meta robot "no-index" ؛ يمكنك استخدام التوجيه التالي لإيقاف فهرسة نوع ملف معين.
User-agent: * Disallow: /*.doc$ Disallow: /*.pdf$ Disallow: /*.jpg$سيعمل هذا على فك جميع الملفات من هذا النوع ، طالما لم يتم ربط أي ملف فردي من مكان آخر على الويب.
منع Google من الزحف إلى أدلة متعددة
قد ترغب في منع الزحف إلى أدلة متعددة لروبوت معين أو جميع برامج الروبوت. في هذا المثال ، نحظر Googlebot من الزحف إلى دليلين فرعيين.
User-agent: Googlebot Disallow: /admin/ Disallow: /private/لاحظ أنه لا يوجد حد لعدد الأدلة التي يمكنك استخدامها bock. ما عليك سوى سرد كل واحد أسفل وكيل المستخدم الذي ينطبق عليه التوجيه.
منع Google من الزحف إلى جميع عناوين URL ذات المعلمات
هذا التوجيه مفيد بشكل خاص لمواقع الويب التي تستخدم التنقل متعدد الأوجه ، حيث يمكن إنشاء العديد من عناوين URL ذات المعلمات.
User-agent: Googlebot Disallow: /*?يمنع هذا التوجيه استهلاك ميزانية الزحف الخاصة بك في عناوين URL الديناميكية ويزيد من الزحف إلى الصفحات المهمة. أستخدم هذا بانتظام ، لا سيما على مواقع التجارة الإلكترونية ذات وظائف البحث.
منع جميع برامج الروبوت من الزحف إلى دليل فرعي واحد مع السماح بالزحف إلى صفحة واحدة بداخله
قد ترغب في بعض الأحيان في منع برامج الزحف من الوصول إلى قسم كامل من موقعك ، ولكن اترك صفحة واحدة يمكن الوصول إليها. إذا قمت بذلك ، فاستخدم المجموعة التالية من الأمرين "allow" و "disallow":
User-agent: * Disallow: /category/ Allow: /category/widget/يخبر محركات البحث بعدم الزحف إلى الدليل الكامل ، باستثناء صفحة أو ملف معين.
ملف Robots.txt لبرنامج WordPress
هذا هو التكوين الأساسي الذي أوصي به لملف WordPress robots.txt. إنه يحظر الزحف إلى صفحات المسؤول والعلامات وعناوين URL للمؤلفين والتي يمكن أن تخلق تلاعبًا غير ضروري على موقع WordPress على الويب.
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /wp-admin/ Disallow: /readme.html Disallow: /refer/ Disallow: /tag/ Disallow: /author/ Disallow: /404-error/ Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xmlسيعمل ملف robots.txt هذا بشكل جيد مع معظم مواقع WordPress ، ولكن بالطبع ، يجب عليك دائمًا تعديله وفقًا لمتطلباتك الخاصة.
كيفية تدقيق ملف Robots.txt الخاص بك بحثًا عن الأخطاء
في وقتي ، رأيت المزيد من الأخطاء التي تؤثر على الترتيب في ملفات robots.txt أكثر من أي جانب آخر من جوانب تحسين محركات البحث الفنية. مع وجود العديد من التوجيهات المتضاربة ، يمكن أن تحدث المشكلات وتحدث بالفعل.
لذلك ، عندما يتعلق الأمر بملفات robots.txt ، فإنه من المفيد ترقب المشكلات.
لحسن الحظ ، يوفر تقرير "التغطية" داخل Google Search Console طريقة للتحقق من مشكلات robots.txt ومراقبتها.
يمكنك أيضًا استخدام أداة اختبار Robots.txt الأنيقة من Google للتحقق من وجود أخطاء في ملف robots المباشر الخاص بك أو اختبار ملف robots.txt جديد قبل نشره.
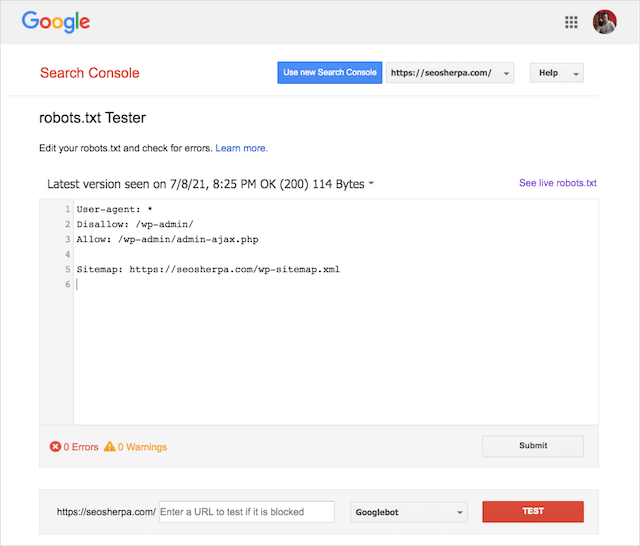
سننتهي من خلال تغطية المشكلات الأكثر شيوعًا ، وما تعنيه وكيفية معالجتها.
تم حظر عنوان URL الذي تم إرساله بواسطة ملف robots.txt
يعني هذا الخطأ أنه تم حظر عنوان واحد على الأقل من عناوين URL الموجودة في ملف (خرائط) الموقع الذي أرسلته بواسطة ملف robots.txt.

يجب أن يتضمن ملف Sitemap الذي تم إعداده بشكل صحيح فقط عناوين URL التي تريد فهرستها في محركات البحث . على هذا النحو ، يجب ألا يحتوي على أي صفحات غير مفهرسة أو متعارف عليها أو معاد توجيهها.
إذا كنت قد اتبعت أفضل الممارسات هذه ، فلن يتم حظر أي صفحات يتم إرسالها في ملف Sitemap الخاص بك بواسطة ملف robots.txt.
إذا رأيت "تم حظر عنوان URL الذي تم إرساله بواسطة ملف robots.txt" في تقرير التغطية ، فيجب عليك التحقق من الصفحات المتأثرة ، ثم تبديل ملف robots.txt لإزالة الحظر لتلك الصفحة.
يمكنك استخدام أداة اختبار ملف robots.txt من Google لمعرفة التوجيه الذي يحظر المحتوى.
تم الحظر بواسطة ملف robots.txt
يعني هذا "الخطأ" أنه لديك صفحات محظورة بواسطة ملف robots.txt الخاص بك غير الموجودة حاليًا في فهرس Google.

إذا كان هذا المحتوى يحتوي على أداة مساعدة ويجب فهرسته ، فقم بإزالة منع الزحف في ملف robots.txt.
كلمة تحذير قصيرة:
"محظور بواسطة ملف robots.txt" ليس بالضرورة خطأ. في الواقع ، قد تكون النتيجة التي تريدها بالضبط.
على سبيل المثال ، ربما تكون قد حظرت بعض الملفات في ملف robots.txt بغرض استبعادها من فهرس Google. من ناحية أخرى ، إذا كنت قد منعت الزحف إلى صفحات معينة بقصد عدم فهرستها ، ففكر في إزالة منع الزحف واستخدام العلامة الوصفية للروبوت بدلاً من ذلك.
هذه هي الطريقة الوحيدة لضمان استبعاد المحتوى من فهرس Google.
مفهرس ، بالرغم من أنه محظور بواسطة ملف robots.txt
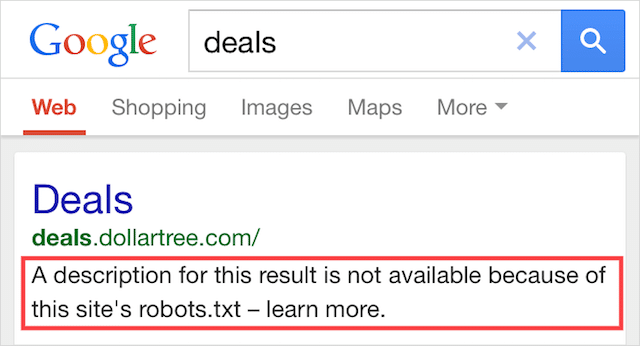
يعني هذا الخطأ أن بعض المحتوى المحظور بواسطة ملف robots.txt لا يزال مفهرسًا في Google.
يحدث ذلك عندما يظل المحتوى قابلاً للاكتشاف بواسطة Googlebot لأنه مرتبط به من مكان آخر على الويب. باختصار ، يقوم Googlebot بالزحف إلى هذا المحتوى ثم فهرسته قبل زيارة ملف robots.txt الخاص بموقعك ، حيث يرى الأمر غير المسموح به.
بحلول ذلك الوقت ، يكون الوقت قد فات. ويتم فهرستها:
دعني أحفر هذا المنزل:
إذا كنت تحاول استبعاد محتوى من نتائج بحث Google ، فإن ملف robots.txt ليس هو الحل الصحيح.
أوصي بإزالة منع الزحف واستخدام علامة no-index tag الوصفية لبرامج الروبوت لمنع الفهرسة بدلاً من ذلك.
على العكس من ذلك ، إذا قمت بحظر هذا المحتوى عن طريق الخطأ وأردت الاحتفاظ به في فهرس Google ، فقم بإزالة حظر الزحف في ملف robots.txt واتركه عند هذا الحد.
قد يساعد هذا في تحسين رؤية المحتوى في بحث Google.
افكار اخيرة
يمكن استخدام ملف robots.txt لتحسين عملية الزحف إلى محتوى موقع الويب الخاص بك وفهرسته ، مما يساعدك على أن تصبح أكثر وضوحًا في SERPs.
عند استخدامه بشكل فعال ، فهو أهم نص على موقع الويب الخاص بك. ولكن عند استخدامه بلا مبالاة ، سيكون كعب أخيل في كود موقع الويب الخاص بك.
الأخبار السارة ، مع الفهم الأساسي لوكلاء المستخدم وحفنة من التوجيهات ، ستكون نتائج البحث الأفضل في متناول يدك.
السؤال الوحيد هو ، ما هي البروتوكولات التي ستستخدمها في ملف robots.txt الخاص بك؟
اسمحوا لي أن نعرف في التعليقات أدناه.