
Robots.txt: สุดยอดคู่มือสำหรับ SEO (รุ่น 2021)
เผยแพร่แล้ว: 2021-06-10 วันนี้ คุณจะได้เรียนรู้วิธีสร้างไฟล์ที่สำคัญที่สุดสำหรับ SEO ของเว็บไซต์:
วันนี้ คุณจะได้เรียนรู้วิธีสร้างไฟล์ที่สำคัญที่สุดสำหรับ SEO ของเว็บไซต์:
(ไฟล์ robots.txt)
โดยเฉพาะอย่างยิ่ง ฉันจะแสดงให้คุณเห็นถึงวิธีใช้โปรโตคอลการยกเว้นโรบ็อตเพื่อบล็อกบ็อตจากบางหน้า เพิ่มความถี่ในการรวบรวมข้อมูล เพิ่มประสิทธิภาพงบประมาณการรวบรวมข้อมูล และรับอันดับของหน้าที่ถูกต้องใน SERP ในท้ายที่สุด
ฉันครอบคลุม:
- ไฟล์ robots.txt คืออะไร
- เหตุใด robots.txt จึงมีความสำคัญ
- วิธีการทำงานของ robots.txt
- ตัวแทนผู้ใช้และคำสั่งของ Robots.txt
- Robots.txt Vs เมตาโรบ็อต
- วิธีค้นหา robots.txt . ของคุณ
- การสร้างไฟล์ robots.txt ของคุณ
- แนวทางปฏิบัติที่ดีที่สุดสำหรับไฟล์ Robots.txt
- ตัวอย่าง Robots.txt
- วิธีตรวจสอบข้อผิดพลาดของ robots.txt
แถมยังมีอีกมาก ไปดำน้ำกันเลย
ไฟล์ Robots.txt คืออะไร และทำไมคุณต้องมี
พูดง่ายๆ ก็คือ ไฟล์ robots.txt เป็นคู่มือการใช้งานสำหรับเว็บโรบ็อต
มันแจ้งบอททุกประเภท ว่าส่วนใดของไซต์ที่พวกเขาควร (และไม่ควร) รวบรวมข้อมูล
กล่าวคือ ใช้ robots.txt เป็น "หลักจรรยาบรรณ" เป็นหลักในการควบคุมกิจกรรมของโรบ็อตเครื่องมือค้นหา (โปรแกรมรวบรวมข้อมูลเว็บ AKA)

robots.txt ได้รับการตรวจสอบอย่างสม่ำเสมอโดยเครื่องมือค้นหาสำคัญๆ ทุกเครื่อง (รวมถึง Google, Bing และ Yahoo) เพื่อดูคำแนะนำเกี่ยวกับวิธีการรวบรวมข้อมูลเว็บไซต์ คำแนะนำเหล่านี้เรียกว่า คำสั่ง
หากไม่มีคำสั่งหรือไม่มีไฟล์ robots.txt เครื่องมือค้นหาจะรวบรวมข้อมูลเว็บไซต์ทั้งหมด หน้าส่วนตัว และทั้งหมด
แม้ว่าเสิร์ชเอ็นจิ้นส่วนใหญ่จะเชื่อฟัง แต่สิ่งสำคัญที่ควรทราบคือการปฏิบัติตามคำสั่งของ robots.txt เป็นทางเลือก หากพวกเขาต้องการ เครื่องมือค้นหาสามารถเลือกที่จะเพิกเฉยต่อไฟล์ robots.txt ของคุณได้
โชคดีที่ Google ไม่ใช่หนึ่งในเครื่องมือค้นหาเหล่านั้น Google มีแนวโน้มที่จะปฏิบัติตามคำแนะนำในไฟล์ robots.txt
ทำไม Robots.txt ถึงมีความสำคัญ?
การมีไฟล์ robots.txt นั้นไม่สำคัญสำหรับเว็บไซต์จำนวนมาก โดยเฉพาะเว็บไซต์ขนาดเล็ก
นั่นเป็นเพราะว่าโดยปกติ Google สามารถค้นหาและจัดทำดัชนีหน้าที่จำเป็นทั้งหมดบนไซต์ได้
และจะไม่สร้างดัชนีเนื้อหาที่ซ้ำกันหรือหน้าที่ไม่สำคัญโดยอัตโนมัติ
แต่ก็ยังไม่มีเหตุผลที่ดีที่จะไม่มีไฟล์ robots.txt ดังนั้นฉันจึงแนะนำให้คุณมี
robots.txt ช่วยให้คุณควบคุมสิ่งที่เครื่องมือค้นหาสามารถและไม่สามารถรวบรวมข้อมูลบนเว็บไซต์ของคุณได้มากขึ้น ซึ่งมีประโยชน์ด้วยเหตุผลหลายประการ:
อนุญาตให้บล็อกเพจที่ไม่ใช่สาธารณะจากเครื่องมือค้นหา
บางครั้ง คุณมีหน้าบนไซต์ของคุณที่คุณไม่ต้องการสร้างดัชนี
ตัวอย่างเช่น คุณอาจกำลังพัฒนาเว็บไซต์ใหม่ในสภาพแวดล้อมการแสดงละครที่คุณต้องการให้ซ่อนไม่ให้ผู้ใช้เห็นจนกว่าจะเปิดตัว
หรือคุณอาจมีหน้าเข้าสู่ระบบเว็บไซต์ที่คุณไม่ต้องการให้แสดงใน SERP
หากเป็นกรณีนี้ คุณสามารถใช้ robots.txt เพื่อบล็อกหน้าเหล่านี้จากโปรแกรมรวบรวมข้อมูลของเครื่องมือค้นหา
ควบคุมงบประมาณการรวบรวมข้อมูลของเครื่องมือค้นหา
หากคุณประสบปัญหาในการจัดทำดัชนีหน้าเว็บทั้งหมดของคุณในเครื่องมือค้นหา คุณอาจมีปัญหาเรื่องงบประมาณในการรวบรวมข้อมูล
พูดง่ายๆ ก็คือ เสิร์ชเอ็นจิ้นกำลังใช้เวลาที่จัดสรรไว้เพื่อรวบรวมข้อมูลเนื้อหาของคุณบนหน้าเว็บที่มีน้ำหนักเกินของเว็บไซต์ของคุณ

ด้วยการบล็อก URL ยูทิลิตี้ต่ำด้วย robots.txt โรบ็อตของเครื่องมือค้นหาสามารถใช้งบประมาณการรวบรวมข้อมูลมากขึ้นในหน้าเว็บที่สำคัญที่สุด
ป้องกันการจัดทำดัชนีทรัพยากร
แนวทางปฏิบัติที่ดีที่สุดคือการใช้คำสั่งเมตา "ไม่มีการจัดทำดัชนี" เพื่อหยุดแต่ละหน้าจากการจัดทำดัชนี
ปัญหาคือ meta directives ทำงานได้ไม่ดีสำหรับทรัพยากรมัลติมีเดีย เช่น PDF และเอกสาร Word
นั่นคือสิ่งที่ robots.txt มีประโยชน์
คุณสามารถเพิ่มบรรทัดข้อความง่ายๆ ลงในไฟล์ robots.txt และเครื่องมือค้นหาจะถูกบล็อกไม่ให้เข้าถึงไฟล์มัลติมีเดียเหล่านี้
(ฉันจะแสดงให้คุณเห็นอย่างชัดเจนว่าต้องทำอย่างไรในโพสต์นี้)
Robots.txt ทำงานอย่างไร (แน่นอน)
ตามที่ฉันแชร์ไปแล้ว ไฟล์ robots.txt จะทำหน้าที่เป็นคู่มือการใช้งานสำหรับโรบ็อตเครื่องมือค้นหา มันบอกบอทการค้นหาว่าพวกเขาควรรวบรวมข้อมูลที่ไหน (และไม่ควรอยู่ที่ไหน)
นี่คือเหตุผลที่โปรแกรมรวบรวมข้อมูลการค้นหาจะค้นหาไฟล์ robots.txt ทันทีที่มาถึงเว็บไซต์
หากพบ robots.txt โปรแกรมรวบรวมข้อมูลจะอ่านก่อนที่จะดำเนินการรวบรวมข้อมูลของเว็บไซต์ต่อไป
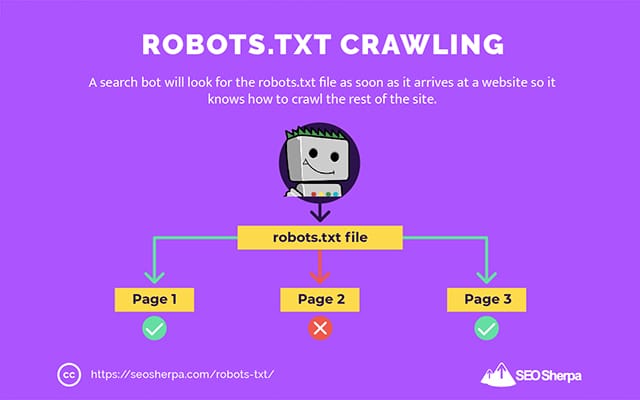
หากโปรแกรมรวบรวมข้อมูลเว็บไม่พบ robots.txt หรือไฟล์ ไม่มี คำสั่งที่ไม่อนุญาตให้มีกิจกรรมของบ็อตการค้นหา โปรแกรมรวบรวมข้อมูลจะยังคงแมงมุมทั่วทั้งเว็บไซต์ตามปกติ
เพื่อให้ไฟล์ robots.txt สามารถค้นหาและอ่านได้โดยบ็อตการค้นหา ไฟล์ robots.txt ได้รับการจัดรูปแบบในลักษณะเฉพาะ
อันดับแรก เป็นไฟล์ข้อความที่ไม่มีโค้ดมาร์กอัป HTML (จึงเป็นนามสกุล .txt)
ประการที่สอง มันจะถูกวางไว้ในโฟลเดอร์รูทของเว็บไซต์ เช่น https://seosherpa.com/robots.txt
ประการที่สาม ใช้ไวยากรณ์มาตรฐานที่เหมือนกันกับไฟล์ robots.txt ทั้งหมด เช่น:
Sitemap: [URL location of sitemap] User-agent: [bot identifier] [directive 1] [directive 2] [directive ...] User-agent: [another bot identifier] [directive 1] [directive 2] [directive ...]ไวยากรณ์นี้อาจดูน่ากลัวในแวบแรก แต่จริงๆ แล้วค่อนข้างง่าย
โดยสังเขป คุณกำหนดบอท (ตัวแทนผู้ใช้) ตามคำแนะนำที่ใช้ จากนั้นระบุกฎ (คำสั่ง) ที่บอทควรปฏิบัติตาม
มาสำรวจส่วนประกอบทั้งสองนี้โดยละเอียดกัน
ตัวแทนผู้ใช้
User-agent คือชื่อที่ใช้กำหนดโปรแกรมรวบรวมข้อมูลเว็บที่เฉพาะเจาะจง และโปรแกรมอื่นๆ ที่ทำงานอยู่บนอินเทอร์เน็ต
มีตัวแทนผู้ใช้หลายร้อยราย รวมถึงตัวแทนสำหรับประเภทอุปกรณ์และเบราว์เซอร์
ส่วนใหญ่ไม่เกี่ยวข้องในบริบทของไฟล์ robots.txt และ SEO ในทางกลับกัน สิ่งเหล่านี้ที่คุณควรรู้:
- Google: Googlebot
- Google รูปภาพ: Googlebot-Image
- Google วิดีโอ: Googlebot-Video
- Google News: Googlebot-ข่าวสาร
- Bing: บิ งบอต
- รูปภาพและวิดีโอของ Bing: MSNBot-Media
- Yahoo: Slurp
- ยานเดกซ์: YandexBot
- ไป่ตู้ : ไป่ดูสไปเดอร์
- DuckDuckGo: DuckDuckBot
เมื่อระบุตัวแทนผู้ใช้ คุณจะตั้งกฎเกณฑ์ต่างๆ สำหรับเครื่องมือค้นหาต่างๆ ได้

ตัวอย่างเช่น หากคุณต้องการให้หน้าบางหน้าปรากฏในผลการค้นหาของ Google แต่ไม่ใช่การค้นหา Baidu คุณสามารถรวมคำสั่งสองชุดในไฟล์ robots.txt ของคุณ: ชุดหนึ่งนำหน้าด้วย "ตัวแทนผู้ใช้: Bingbot" และชุดหนึ่งนำหน้า โดย “ตัวแทนผู้ใช้: Baiduspider”
คุณยังสามารถใช้สัญลักษณ์แทนรูปดาว (*) หากคุณต้องการให้คำสั่งของคุณนำไปใช้กับตัวแทนผู้ใช้ทั้งหมด
ตัวอย่างเช่น สมมติว่าคุณต้องการบล็อกโรบ็อตของเครื่องมือค้นหาทั้งหมดไม่ให้รวบรวมข้อมูลไซต์ของคุณ ยกเว้น DuckDuckGo คุณต้องดำเนินการดังนี้:
User-agent: * Disallow: / User-agent: DuckDuckBot Allow: /Sidenote: หากมีคำสั่งที่ขัดแย้งกันในไฟล์ robots.txt บอทจะทำตามคำสั่งที่ละเอียดยิ่งขึ้น
นั่นเป็นเหตุผลที่ในตัวอย่างข้างต้น DuckDuckBot รู้ว่าต้องรวบรวมข้อมูลเว็บไซต์ แม้ว่าคำสั่งก่อนหน้า (ที่ใช้กับบอททั้งหมด) จะบอกว่าห้ามรวบรวมข้อมูลก็ตาม กล่าวโดยสรุป บอทจะทำตามคำแนะนำที่ใช้กับพวกเขาได้แม่นยำที่สุด
คำสั่ง
คำสั่งคือจรรยาบรรณที่คุณต้องการให้ตัวแทนผู้ใช้ปฏิบัติตาม กล่าวอีกนัยหนึ่ง directives กำหนด วิธี ที่บอทการค้นหาควรรวบรวมข้อมูลเว็บไซต์ของคุณ
ต่อไปนี้คือคำสั่งที่ GoogleBot รองรับในปัจจุบัน พร้อมกับการใช้งานภายในไฟล์ robots.txt:
ไม่อนุญาต
ใช้คำสั่งนี้เพื่อไม่อนุญาตให้บอทการค้นหารวบรวมข้อมูลไฟล์และหน้าเว็บบางหน้าในเส้นทาง URL ที่ระบุ

ตัวอย่างเช่น หากคุณต้องการบล็อก GoogleBot ไม่ให้เข้าถึงวิกิของคุณและทุกหน้าในวิกิ robots.txt ของคุณควรมีคำสั่งนี้:
User-agent: GoogleBot Disallow: /wikiคุณสามารถใช้คำสั่ง disallow เพื่อบล็อกการรวบรวมข้อมูลของ URL ที่แม่นยำ ไฟล์และหน้าทั้งหมดภายในไดเรกทอรีหนึ่งๆ และแม้แต่เว็บไซต์ของคุณทั้งหมด
อนุญาต
คำสั่ง allow มีประโยชน์หากคุณต้องการอนุญาตให้เสิร์ชเอ็นจิ้นรวบรวมข้อมูลไดเร็กทอรีย่อยหรือหน้าที่เจาะจง – ในส่วนที่ไม่อนุญาตในไซต์ของคุณ

สมมติว่าคุณต้องการป้องกันไม่ให้เครื่องมือค้นหาทั้งหมดรวบรวมข้อมูลโพสต์ในบล็อกของคุณ ยกเว้นเพียงรายการเดียว จากนั้นคุณจะใช้คำสั่ง allow ดังนี้:
User-agent: * Disallow: /blog Allow: /blog/allowable-postเนื่องจากบอทการค้นหาปฏิบัติตามคำสั่งที่ละเอียดที่สุดที่ให้ไว้ในไฟล์ robots.txt เสมอ พวกเขาจึงรู้ว่าต้องรวบรวมข้อมูล /blog/allowable-post แต่จะไม่รวบรวมข้อมูลโพสต์หรือไฟล์อื่นๆ ในไดเรกทอรีดังกล่าว
- /บล็อก/โพสต์หนึ่ง/
- /บล็อก/โพสต์สอง/
- /blog/file-name.pdf
ทั้ง Google และ Bing สนับสนุนคำสั่งนี้ แต่เครื่องมือค้นหาอื่นไม่ทำ
แผนผังเว็บไซต์
คำสั่งแผนผังเว็บไซต์ใช้เพื่อระบุตำแหน่งของแผนผังเว็บไซต์ XML ของคุณไปยังเครื่องมือค้นหา
หากคุณเพิ่งเริ่มใช้แผนผังเว็บไซต์ แผนผังเว็บไซต์จะใช้ในการแสดงรายการหน้าเว็บที่คุณต้องการให้รวบรวมข้อมูลและจัดทำดัชนีในเครื่องมือค้นหา
การรวมคำสั่งแผนผังเว็บไซต์ใน robots.txt จะช่วยให้เครื่องมือค้นหาพบแผนผังเว็บไซต์ และในทางกลับกัน รวบรวมข้อมูลและจัดทำดัชนีหน้าที่สำคัญที่สุดของเว็บไซต์ของคุณ
ด้วยเหตุนี้ หากคุณได้ส่งแผนผังไซต์ XML ผ่าน Search Console แล้ว การเพิ่มแผนผังไซต์ใน robots.txt นั้นค่อนข้างซ้ำซ้อนสำหรับ Google อย่างไรก็ตาม แนวทางปฏิบัติที่ดีที่สุดคือการใช้คำสั่งแผนผังไซต์เนื่องจากจะบอกเครื่องมือค้นหาเช่น Ask, Bing และ Yahoo ว่าสามารถพบแผนผังไซต์ของคุณได้ที่ไหน
ต่อไปนี้คือตัวอย่างไฟล์ robots.txt โดยใช้คำสั่งแผนผังเว็บไซต์
Sitemap: https://www.website.com/sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/สังเกตตำแหน่งของคำสั่งแผนผังเว็บไซต์ในไฟล์ robots.txt ควรวางไว้ที่ด้านบนสุดของ robots.txt นอกจากนี้ยังสามารถวางไว้ที่ด้านล่าง
หากคุณมีแผนผังเว็บไซต์หลายรายการ คุณควรรวมแผนผังเว็บไซต์ทั้งหมดไว้ในไฟล์ robots.txt ไฟล์ robots.txt อาจมีลักษณะดังนี้หากเรามีแผนผังเว็บไซต์ XML แยกสำหรับหน้าและโพสต์:
Sitemap: http://website.com/post-sitemap.xml Sitemap: http://website.com/page-sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/ไม่ว่าจะด้วยวิธีใด คุณจะต้องพูดถึงแผนผังเว็บไซต์ XML แต่ละรายการเพียงครั้งเดียว เนื่องจากตัวแทนผู้ใช้ที่รองรับทั้งหมดจะปฏิบัติตามคำสั่ง
โปรดทราบว่าไม่เหมือนกับคำสั่ง robots.txt อื่นๆ ซึ่งแสดงรายการเส้นทาง คำสั่งแผนผังเว็บไซต์ต้องระบุ URL ที่สมบูรณ์ของแผนผังเว็บไซต์ XML ของคุณ รวมถึงโปรโตคอล ชื่อโดเมน และส่วนขยายโดเมนระดับบนสุด
ความคิดเห็น
ความคิดเห็น "คำสั่ง" มีประโยชน์สำหรับมนุษย์ แต่ไม่ได้ถูกใช้โดยบ็อตการค้นหา

คุณสามารถเพิ่มความคิดเห็นเพื่อเตือนคุณว่าทำไมจึงมีคำสั่งบางอย่างหรือหยุดคำสั่งที่เข้าถึง robots.txt ของคุณไม่ให้ลบคำสั่งที่สำคัญ กล่าวโดยย่อ ความคิดเห็นจะใช้เพื่อเพิ่มบันทึกย่อในไฟล์ robots.txt ของคุณ
หากต้องการเพิ่มความคิดเห็น ให้พิมพ์” #" ตามด้วยข้อความแสดงความคิดเห็น
# Don't allow access to the /wp-admin/ directory for all robots. User-agent: * Disallow: /wp-admin/คุณสามารถเพิ่มความคิดเห็นที่จุดเริ่มต้นของบรรทัด (ดังที่แสดงด้านบน) หรือหลังคำสั่งในบรรทัดเดียวกัน (ดังที่แสดงด้านล่าง):
User-agent: * #Applies to all robots Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.เมื่อใดก็ตามที่คุณเลือกที่จะเขียนความคิดเห็น ทุกอย่างที่อยู่หลังแฮชจะถูกละเว้น
ตามมาจนถึงตอนนี้?
ยอดเยี่ยม! ตอนนี้เราได้กล่าวถึงคำสั่งหลักที่คุณต้องการสำหรับไฟล์ robots.txt ของคุณแล้ว ซึ่งสิ่งเหล่านี้ก็เป็นเพียงคำสั่งเดียวที่ Google รองรับ
แล้วเสิร์ชเอ็นจิ้นอื่นๆ ล่ะ? ในกรณีของ Bing, Yahoo และ Yandex มีอีกหนึ่งคำสั่งที่คุณสามารถใช้:
ความล่าช้าในการรวบรวมข้อมูล
คำสั่งการชะลอการรวบรวมข้อมูลเป็นคำสั่งที่ไม่เป็นทางการซึ่งใช้เพื่อป้องกันไม่ให้เซิร์ฟเวอร์ทำงานหนักเกินไปโดยมีคำขอรวบรวมข้อมูลมากเกินไป
กล่าวคือ คุณใช้เพื่อจำกัดความถี่ที่เครื่องมือค้นหาสามารถรวบรวมข้อมูลไซต์ของคุณได้

โปรดทราบว่าหากเสิร์ชเอ็นจิ้นสามารถทำให้เซิร์ฟเวอร์ของคุณทำงานหนักเกินไปโดยการรวบรวมข้อมูลเว็บไซต์ของคุณบ่อยๆ การเพิ่มคำสั่งการหน่วงเวลาการรวบรวมข้อมูลลงในไฟล์ robots.txt จะช่วยแก้ไขปัญหาได้ชั่วคราวเท่านั้น
ในกรณีนี้ อาจเป็นไปได้ว่าเว็บไซต์ของคุณใช้งานโฮสติ้งที่แย่หรือสภาพแวดล้อมการโฮสต์ที่กำหนดค่าไม่ถูกต้อง และนั่นคือสิ่งที่คุณควรแก้ไขอย่างรวดเร็ว
คำสั่งการหน่วงเวลาการรวบรวมข้อมูลทำงานโดยกำหนดเวลาเป็นวินาทีระหว่างที่บอตการค้นหาสามารถรวบรวมข้อมูลเว็บไซต์ของคุณได้
ตัวอย่างเช่น หากคุณตั้งค่าการหน่วงเวลาการรวบรวมข้อมูลเป็น 5 บ็อตการค้นหาจะแบ่งวันออกเป็นหน้าต่างห้าวินาที โดยรวบรวมข้อมูลเพียงหน้าเดียว (หรือไม่มีเลย) ในแต่ละหน้าต่าง สูงสุดประมาณ 17,280 URL ในระหว่างวัน
ด้วยเหตุนี้ โปรดใช้ความระมัดระวังในการตั้งค่าคำสั่งนี้ โดยเฉพาะอย่างยิ่งหากคุณมีเว็บไซต์ขนาดใหญ่ URL เพียง 17,280 ที่รวบรวมข้อมูลต่อวันไม่เป็นประโยชน์มากนักหากไซต์ของคุณมีหน้าเว็บหลายล้านหน้า
วิธีที่เครื่องมือค้นหาแต่ละรายการจัดการกับคำสั่งการหน่วงเวลาการรวบรวมข้อมูลนั้นแตกต่างกัน มาทำลายมันลงด้านล่าง:
รวบรวมข้อมูลล่าช้าและ Bing, Yahoo และ Yandex
Bing, Yahoo และ Yandex ทั้งหมดสนับสนุนคำสั่งการชะลอการรวบรวมข้อมูลใน robots.txt
ซึ่งหมายความว่าคุณสามารถตั้งค่าคำสั่งการหน่วงเวลาการรวบรวมข้อมูลสำหรับตัวแทนผู้ใช้ BingBot, Slurp และ YandexBot และเครื่องมือค้นหาจะควบคุมการรวบรวมข้อมูลตามลำดับ
โปรดทราบว่าเครื่องมือค้นหาแต่ละรายการจะตีความความล่าช้าในการรวบรวมข้อมูลด้วยวิธีที่ แตกต่างกันเล็กน้อย ดังนั้นโปรดตรวจสอบเอกสารประกอบ:
- Bing และ Yahoo
- Yandex
ที่กล่าวว่า รูปแบบของคำสั่งการหน่วงเวลาการรวบรวมข้อมูลสำหรับแต่ละเอ็นจิ้นเหล่านี้เหมือนกัน คุณต้องวางไว้หลังคำสั่งไม่อนุญาตหรืออนุญาต นี่คือตัวอย่าง:
User-agent: BingBot Allow: /widgets/ Crawl-delay: 5รวบรวมข้อมูลล่าช้าและ Google
โปรแกรมรวบรวมข้อมูลของ Google ไม่สนับสนุนคำสั่งการชะลอการรวบรวมข้อมูล ดังนั้นจึงไม่มีประโยชน์ในการตั้งค่าความล่าช้าในการรวบรวมข้อมูลสำหรับ GoogleBot ใน robots.txt
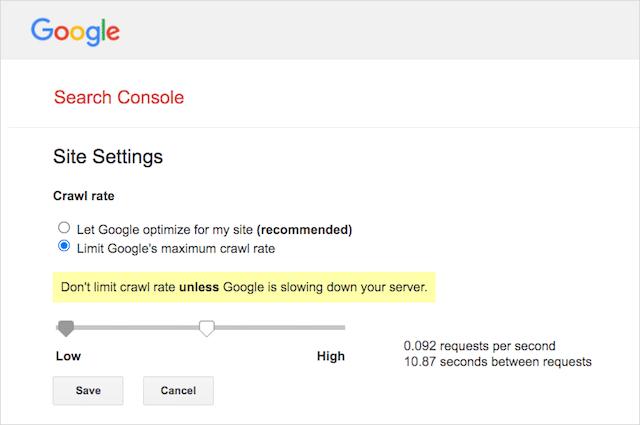
อย่างไรก็ตาม Google รองรับการกำหนดอัตราการรวบรวมข้อมูลใน Google Search Console นี่คือวิธีการ:
- ไปที่หน้าการตั้งค่าของ Google Search Console
- เลือกคุณสมบัติที่คุณต้องการกำหนดอัตราการรวบรวมข้อมูลสำหรับ
- คลิก “จำกัดอัตราการรวบรวมข้อมูลสูงสุดของ Google”
- ปรับแถบเลื่อนตามอัตราการรวบรวมข้อมูลที่คุณต้องการ โดยค่าเริ่มต้น อัตราการรวบรวมข้อมูลมีการตั้งค่า "ให้ Google เพิ่มประสิทธิภาพเว็บไซต์ของฉัน (แนะนำ)"
รวบรวมข้อมูลล่าช้าและ Baidu
เช่นเดียวกับ Google Baidu ไม่รองรับคำสั่งการหน่วงเวลาการรวบรวมข้อมูล อย่างไรก็ตาม เป็นไปได้ที่จะลงทะเบียนบัญชี Baidu Webmaster Tools ซึ่งคุณสามารถควบคุมความถี่ในการรวบรวมข้อมูลได้ เช่นเดียวกับ Google Search Console
บรรทัดล่าง? Robots.txt บอกสไปเดอร์ของเครื่องมือค้นหาไม่ให้รวบรวมข้อมูลหน้าใดหน้าหนึ่งในเว็บไซต์ของคุณ
Robots.txt เทียบกับ meta robots เทียบกับ x-robots
มีคำแนะนำเกี่ยวกับ "หุ่นยนต์" มากมาย ต่างกันอย่างไร หรือเหมือนกันอย่างไร?
ให้ฉันเสนอคำอธิบายสั้น ๆ :
ก่อนอื่น robots.txt เป็นไฟล์ข้อความจริง ในขณะที่ meta และ x-robots เป็นแท็กภายในโค้ดของหน้าเว็บ
ประการที่สอง robots.txt ให้ คำแนะนำ แก่บอทเกี่ยวกับวิธีรวบรวมข้อมูลหน้าของเว็บไซต์ ในทางกลับกัน คำสั่ง meta ของโรบ็อตจะให้ คำแนะนำ ที่ชัดเจนในการรวบรวมข้อมูลและจัดทำดัชนีเนื้อหาของหน้า
นอกเหนือจากสิ่งที่พวกเขาเป็นแล้ว ทั้งสามยังทำหน้าที่ต่างกัน
Robots.txt กำหนดพฤติกรรมการรวบรวมข้อมูลทั่วทั้งไซต์หรือไดเรกทอรี ในขณะที่ meta และ x-robots สามารถกำหนดพฤติกรรมการจัดทำดัชนีที่ระดับหน้าแต่ละหน้า (หรือองค์ประกอบของหน้า)

โดยทั่วไป:

หากคุณต้องการหยุดหน้าจากการจัดทำดัชนี คุณควรใช้แท็ก meta robots "no-index" การไม่อนุญาตหน้าใน robots.txt ไม่ได้รับประกันว่าจะไม่แสดงในเครื่องมือค้นหา (ท้ายที่สุดแล้วคำสั่งของ robots.txt ก็คือคำแนะนำ) นอกจากนี้ โรบ็อตเครื่องมือค้นหายังสามารถค้นหา URL นั้นและจัดทำดัชนีได้หากมีการเชื่อมโยงจากเว็บไซต์อื่น
ในทางตรงกันข้าม หากคุณต้องการหยุดการจัดทำดัชนีไฟล์มีเดีย robots.txt เป็นวิธีที่จะไป คุณไม่สามารถเพิ่มแท็ก meta robots ลงในไฟล์เช่น jpegs หรือ PDFs
วิธีค้นหา Robots.txt ของคุณ
หากคุณมีไฟล์ robots.txt บนเว็บไซต์อยู่แล้ว คุณจะสามารถเข้าถึงได้ที่ yourdomain.com/robots.txt
ไปที่ URL ในเบราว์เซอร์ของคุณ
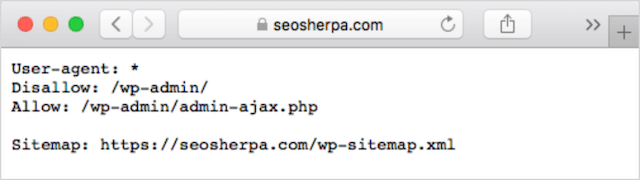
หากคุณเห็นหน้าแบบข้อความเหมือนด้านบน แสดงว่าคุณมีไฟล์ robots.txt
วิธีสร้างไฟล์ Robots.txt
หากคุณยังไม่มีไฟล์ robots.txt การสร้างไฟล์นั้นง่ายมาก
ขั้นแรก ให้เปิด Notepad, Microsoft Word หรือโปรแกรมแก้ไขข้อความใดๆ แล้วบันทึกไฟล์เป็น 'หุ่นยนต์'
อย่าลืมใช้ตัวพิมพ์เล็ก และเลือก .txt เป็นนามสกุลไฟล์:

ประการที่สอง เพิ่มคำสั่งของคุณ ตัวอย่างเช่น หากคุณต้องการไม่อนุญาตให้บอทการค้นหาทั้งหมดรวบรวมข้อมูลไดเร็กทอรี /login/ ของคุณ ให้พิมพ์ดังนี้:
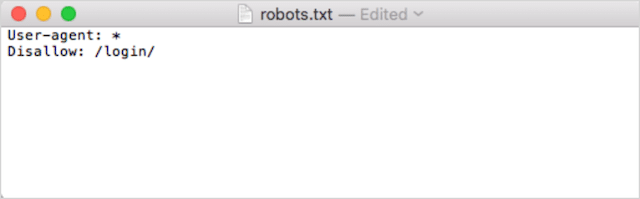
เพิ่มคำสั่งต่อไปจนกว่าคุณจะพอใจกับไฟล์ robots.txt ของคุณ
หรือคุณสามารถสร้าง robots.txt ด้วยเครื่องมือเช่นนี้จาก Ryte

ข้อดีอย่างหนึ่งของการใช้เครื่องมือคือช่วยลดข้อผิดพลาดของมนุษย์
ข้อผิดพลาดเพียงเล็กน้อยในไวยากรณ์ robots.txt ของคุณอาจจบลงด้วยหายนะ SEO
ที่กล่าวว่าข้อเสียของการใช้ตัวสร้าง robots.txt คือโอกาสในการปรับแต่งมีน้อย
นั่นเป็นเหตุผลที่ฉันแนะนำให้คุณเรียนรู้การเขียนไฟล์ robot.txt ด้วยตัวเอง จากนั้นคุณสามารถสร้าง robots.txt ได้ตรงตามความต้องการของคุณ
จะวางไฟล์ Robots.txt ของคุณไว้ที่ใด
เพิ่มไฟล์ robots.txt ของคุณในไดเรกทอรีระดับบนสุดของโดเมนย่อยที่เกี่ยวข้อง
ตัวอย่างเช่น ในการควบคุมพฤติกรรมการรวบรวมข้อมูลบน yourdomain.com ไฟล์ robots.txt ควรสามารถเข้าถึงได้บนเส้นทาง URL ของ yourdomain.com/robots.txt
ในทางกลับกัน หากคุณต้องการควบคุมการรวบรวมข้อมูลบนโดเมนย่อย เช่น shop.yourdomain.com คุณควรเข้าถึง robots.txt บนเส้นทาง URL ของ shop.yourdomain.com/robots.txt
กฎทองคือ:
- ให้ทุกโดเมนย่อยบนเว็บไซต์ของคุณเป็นไฟล์ robots.txt ของตัวเอง
- ตั้งชื่อไฟล์ของคุณว่า robots.txt เป็นตัวพิมพ์เล็กทั้งหมด
- วางไฟล์ในไดเร็กทอรีรากของโดเมนย่อยที่อ้างอิง
หากไม่พบไฟล์ robots.txt ในไดเรกทอรีราก เครื่องมือค้นหาจะถือว่าไม่มีคำสั่งและจะรวบรวมข้อมูลเว็บไซต์ของคุณอย่างครบถ้วน
แนวทางปฏิบัติที่ดีที่สุดสำหรับไฟล์ Robots.txt
ต่อไป มาพูดถึงกฎของไฟล์ robots.txt ใช้แนวทางปฏิบัติที่ดีที่สุดเหล่านี้เพื่อหลีกเลี่ยงข้อผิดพลาดทั่วไปของ robots.txt
ใช้บรรทัดใหม่สำหรับแต่ละคำสั่ง
แต่ละคำสั่งใน robots.txt ของคุณต้องอยู่ในบรรทัดใหม่
หากไม่เป็นเช่นนั้น เครื่องมือค้นหาจะสับสนว่าควรรวบรวมข้อมูลอะไร (และจัดทำดัชนี)
ตัวอย่างเช่น มีการกำหนดค่า ไม่ถูกต้อง :
User-agent: * Disallow: /folder/ Disallow: /another-folder/ในทางกลับกัน นี่เป็นไฟล์ robots.txt ที่ตั้งค่าไว้ อย่างถูกต้อง :
User-agent: * Disallow: /folder/ Disallow: /another-folder/ความจำเพาะ “เกือบ” ชนะเสมอ
เมื่อพูดถึง Google และ Bing ยิ่งได้รับคำสั่งที่ละเอียดยิ่งขึ้น
ตัวอย่างเช่น คำสั่ง Allow นี้จะชนะคำสั่ง Disallow เนื่องจากความยาวของอักขระนั้นยาวกว่า
User-agent: * Disallow: /about/ Allow: /about/company/Google และ Bing รู้จักที่จะรวบรวมข้อมูล /about/company/ แต่ไม่ใช่หน้าอื่นในไดเร็กทอรี /about/
อย่างไรก็ตาม ในกรณีของเครื่องมือค้นหาอื่นๆ สิ่งที่ตรงกันข้ามคือความจริง
โดยค่าเริ่มต้น สำหรับเครื่องมือค้นหาหลักทั้งหมดที่ไม่ใช่ Google และ Bing คำสั่งการจับคู่แรกจะชนะเสมอ
ในตัวอย่างข้างต้น เครื่องมือค้นหาจะปฏิบัติตามคำสั่ง Disallow และละเว้นคำสั่ง Allow ซึ่งหมายความว่าหน้า /about/company จะไม่มีการรวบรวมข้อมูล
พึงระลึกไว้เสมอว่าเมื่อคุณสร้างกฎสำหรับเครื่องมือค้นหาทั้งหมด
เพียงหนึ่งกลุ่มของคำสั่งต่อตัวแทนผู้ใช้
หาก robots.txt ของคุณมีกลุ่มคำสั่งหลายกลุ่มต่อตัวแทนผู้ใช้ boh-oh-boy มันจะทำให้สับสนไหม
ไม่จำเป็นสำหรับหุ่นยนต์ เพราะจะรวมกฎทั้งหมดจากการประกาศต่างๆ เข้าเป็นกลุ่มเดียวและติดตามทั้งหมด แต่สำหรับคุณ
เพื่อหลีกเลี่ยงโอกาสที่จะเกิดข้อผิดพลาดของมนุษย์ ให้ระบุ user-agent หนึ่งครั้งแล้วระบุคำสั่งทั้งหมดที่ใช้กับตัวแทนผู้ใช้นั้นด้านล่าง

การทำสิ่งต่าง ๆ ให้เรียบร้อยและเรียบง่าย คุณมีโอกาสน้อยที่จะทำผิดพลาด
ใช้สัญลักษณ์แทน (*) เพื่อทำให้คำแนะนำง่ายขึ้น
คุณสังเกตเห็นสัญลักษณ์แทน (*) ในตัวอย่างด้านบนหรือไม่
ถูกตัอง; คุณสามารถใช้สัญลักษณ์แทน (*) เพื่อใช้กฎกับตัวแทนผู้ใช้ทั้งหมด และเพื่อให้ตรงกับรูปแบบ URL เมื่อประกาศคำสั่ง
ตัวอย่างเช่น หากคุณต้องการป้องกันไม่ให้บอทการค้นหาเข้าถึง URL หมวดหมู่ผลิตภัณฑ์ที่มีการกำหนดพารามิเตอร์บนเว็บไซต์ของคุณ คุณสามารถแสดงรายการแต่ละหมวดหมู่ดังนี้:
User-agent: * Disallow: /products/watches? Disallow: /products/handbags? Disallow: /products/shoes?หรือคุณสามารถใช้สัญลักษณ์แทนที่จะใช้กฎกับทุกประเภท ซึ่งจะมีลักษณะดังนี้:
User-agent: * Disallow: /products/*?ตัวอย่างนี้บล็อกเครื่องมือค้นหาไม่ให้รวบรวมข้อมูล URL ทั้งหมดภายในโฟลเดอร์ย่อย /product/ ที่มีเครื่องหมายคำถาม กล่าวคือ URL หมวดหมู่ผลิตภัณฑ์ใดๆ ที่มีการกำหนดพารามิเตอร์
Google, Bing, Yahoo สนับสนุนการใช้สัญลักษณ์แทนภายในคำสั่งของ robots.txt และ Ask
ใช้ “$” เพื่อระบุจุดสิ้นสุดของ URL
หากต้องการระบุจุดสิ้นสุดของ URL ให้ใช้เครื่องหมายดอลลาร์ ( $ ) หลังเส้นทาง robots.txt
สมมติว่าคุณต้องการหยุดการค้นหาบอทที่เข้าถึงไฟล์ .doc ทั้งหมดบนเว็บไซต์ของคุณ จากนั้นคุณจะใช้คำสั่งนี้:
User-agent: * Disallow: /*.doc$การดำเนินการนี้จะหยุดเครื่องมือค้นหาไม่ให้เข้าถึง URL ที่ลงท้ายด้วย .doc
ซึ่งหมายความว่าจะไม่รวบรวมข้อมูล /media/file.doc แต่จะรวบรวมข้อมูล /media/file.doc?id=72491 เนื่องจาก URL นั้นไม่ได้ลงท้ายด้วย “.doc”
แต่ละโดเมนย่อยจะมี robots.txt . เป็นของตัวเอง
คำสั่ง Robots.txt ใช้กับโดเมน (ย่อย) ที่โฮสต์ไฟล์ robots.txt เท่านั้น
ซึ่งหมายความว่าหากเว็บไซต์ของคุณมีหลายโดเมนย่อย เช่น:
- domain.com
- Ticket.domain.com
- events.domain.com
แต่ละโดเมนย่อยจะต้องมีไฟล์ robots.txt ของตัวเอง
ควรเพิ่ม robots.txt ในไดเรกทอรีรากของแต่ละโดเมนย่อยเสมอ นี่คือลักษณะของเส้นทางโดยใช้ตัวอย่างข้างต้น:
- domain.com/robots.txt
- Tickets.domain.com/robots.txt
- events.domain.com/robots.txt
อย่าใช้ noindex ใน robots.txt . ของคุณ
พูดง่ายๆ คือ Google ไม่สนับสนุนคำสั่ง no-index ใน robots.txt
แม้ว่า Google จะทำตามในอดีต แต่ในเดือนกรกฎาคม 2019 Google ได้หยุดสนับสนุนทั้งหมด
และหากคุณกำลังคิดที่จะใช้คำสั่ง no-index robots.txt กับเนื้อหาที่ไม่มีดัชนีในเครื่องมือค้นหาอื่นๆ ให้คิดใหม่อีกครั้ง:
คำสั่ง no-index อย่างไม่เป็นทางการไม่เคยทำงานใน Bing
วิธีที่ดีที่สุดในการไม่สร้างดัชนีเนื้อหาในเครื่องมือค้นหาคือการใช้แท็ก meta robots ที่ไม่ทำดัชนีกับหน้าที่คุณต้องการยกเว้น
เก็บไฟล์ robots.txt ของคุณให้ต่ำกว่า 512 KB
ขณะนี้ Google มีขีดจำกัดขนาดไฟล์ robots.txt ที่ 500 กิบิไบต์ (512 กิโลไบต์)
ซึ่งหมายความว่าเนื้อหาใด ๆ หลังจาก 512 KB อาจถูก ละเว้น

ที่กล่าวว่า เนื่องจากอักขระหนึ่งตัวใช้เพียงหนึ่งไบต์ ดังนั้น robots.txt ของคุณจะต้องมีขนาดใหญ่มากจึงจะถึงขีดจำกัดขนาดไฟล์นั้น (512, 000 อักขระให้ถูกต้อง) รักษาไฟล์ robots.txt ของคุณให้น้อยลงโดยเน้นไปที่หน้าที่แยกให้น้อยลงและเน้นไปที่รูปแบบที่กว้างขึ้นซึ่งไวด์การ์ดสามารถควบคุมได้
ไม่ชัดเจนว่าเสิร์ชเอ็นจิ้นอื่นๆ มีขนาดไฟล์สูงสุดที่อนุญาตสำหรับไฟล์ robots.txt หรือไม่
Robots.txt ตัวอย่าง
ด้านล่างนี้คือตัวอย่างบางส่วนของไฟล์ robots.txt
ซึ่งรวมถึงชุดคำสั่งที่เอเจนซี SEO ของเราใช้มากที่สุดในไฟล์ robots.txt สำหรับลูกค้า พึงระลึกไว้เสมอว่า สิ่งเหล่านี้มีวัตถุประสงค์เพื่อเป็นแรงบันดาลใจเท่านั้น คุณจะต้องปรับแต่งไฟล์ robots.txt ให้ตรงตามความต้องการของคุณเสมอ
อนุญาตให้โรบ็อตทั้งหมดเข้าถึงทุกสิ่งได้
ไฟล์ robots.txt นี้ไม่มีกฎการไม่อนุญาตสำหรับเครื่องมือค้นหาทั้งหมด:
User-agent: * Disallow:กล่าวอีกนัยหนึ่งจะช่วยให้บอทการค้นหาสามารถรวบรวมข้อมูลทุกอย่างได้ มีจุดประสงค์เดียวกับไฟล์ robots.txt เปล่าหรือไม่มี robots.txt เลย
บล็อกไม่ให้หุ่นยนต์เข้าถึงทุกอย่าง
ไฟล์ตัวอย่าง robots.txt จะบอกเครื่องมือค้นหาทั้งหมดไม่ให้เข้าถึงสิ่งใดหลังจากเครื่องหมายทับต่อท้าย กล่าวอีกนัยหนึ่ง โดเมนทั้งหมด:
User-agent: * Disallow: /กล่าวโดยย่อ ไฟล์ robots.txt นี้จะบล็อกโรบ็อตของเครื่องมือค้นหาทั้งหมด และอาจหยุดเว็บไซต์ของคุณไม่ให้แสดงบนหน้าผลการค้นหา
บล็อกหุ่นยนต์ทั้งหมดจากการรวบรวมข้อมูลไฟล์เดียว
ในตัวอย่างนี้ เราบล็อกบอทการค้นหาทั้งหมดไม่ให้รวบรวมข้อมูลไฟล์ใดไฟล์หนึ่ง
User-agent: * Disallow: /directory/this-is-a-file.pdfบล็อกโรบ็อตทั้งหมดไม่ให้รวบรวมข้อมูลไฟล์ประเภทเดียว (doc, pdf, jpg)
เนื่องจากไม่มีการจัดทำดัชนี ไฟล์เช่น 'doc' หรือ 'pdf' ไม่สามารถทำได้โดยใช้แท็ก "no-index" ของเมตาโรบ็อต คุณสามารถใช้คำสั่งต่อไปนี้เพื่อหยุดการจัดทำดัชนีไฟล์บางประเภท
User-agent: * Disallow: /*.doc$ Disallow: /*.pdf$ Disallow: /*.jpg$การดำเนินการนี้จะทำงานเพื่อแยกดัชนีไฟล์ทั้งหมดที่เป็นประเภทนั้น ตราบใดที่ไม่มีการลิงก์ไฟล์แต่ละไฟล์จากที่อื่นบนเว็บ
บล็อก Google จากการรวบรวมข้อมูลหลายไดเรกทอรี
คุณอาจต้องการบล็อกการรวบรวมข้อมูลของหลายไดเร็กทอรีสำหรับบอทเฉพาะหรือบอททั้งหมด ในตัวอย่างนี้ เรากำลังบล็อก Googlebot จากการรวบรวมข้อมูลไดเรกทอรีย่อยสองรายการ
User-agent: Googlebot Disallow: /admin/ Disallow: /private/หมายเหตุ ไม่มีการจำกัดจำนวนไดเร็กทอรีที่คุณใช้ bock ได้ เพียงระบุรายการด้านล่างตัวแทนผู้ใช้ที่คำสั่งใช้
บล็อก Google จากการรวบรวมข้อมูล URL ที่มีการกำหนดพารามิเตอร์ทั้งหมด
คำสั่งนี้มีประโยชน์อย่างยิ่งสำหรับเว็บไซต์ที่ใช้การนำทางแบบเหลี่ยมเพชรพลอย ซึ่งสามารถสร้าง URL ที่มีการกำหนดพารามิเตอร์ได้จำนวนมาก
User-agent: Googlebot Disallow: /*?คำสั่งนี้จะหยุดใช้งบประมาณการรวบรวมข้อมูลของคุณใน URL แบบไดนามิกและเพิ่มการรวบรวมข้อมูลของหน้าที่สำคัญ ฉันใช้สิ่งนี้เป็นประจำ โดยเฉพาะในเว็บไซต์อีคอมเมิร์ซที่มีฟังก์ชันการค้นหา
บล็อกบอททั้งหมดจากการรวบรวมข้อมูลไดเรกทอรีย่อยหนึ่งรายการ แต่อนุญาตให้มีการรวบรวมข้อมูลหนึ่งหน้าภายใน
บางครั้ง คุณอาจต้องการบล็อกโปรแกรมรวบรวมข้อมูลไม่ให้เข้าถึงส่วนที่สมบูรณ์ของไซต์ของคุณ แต่ปล่อยให้หน้าเดียวสามารถเข้าถึงได้ หากเป็นเช่นนั้น ให้ใช้คำสั่ง 'อนุญาต' และ 'ไม่อนุญาต' ร่วมกันดังต่อไปนี้:
User-agent: * Disallow: /category/ Allow: /category/widget/มันบอกเสิร์ชเอ็นจิ้นไม่ให้รวบรวมข้อมูลไดเร็กทอรีทั้งหมด ยกเว้นหน้าหรือไฟล์หนึ่งๆ
Robots.txt สำหรับ WordPress
นี่คือการกำหนดค่าพื้นฐานที่ฉันแนะนำสำหรับไฟล์ WordPress robots.txt มันบล็อกการรวบรวมข้อมูลของหน้าผู้ดูแลระบบและแท็กและ URL ของผู้เขียนซึ่งสามารถสร้าง cruft ที่ไม่จำเป็นบนเว็บไซต์ WordPress
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /wp-admin/ Disallow: /readme.html Disallow: /refer/ Disallow: /tag/ Disallow: /author/ Disallow: /404-error/ Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xmlไฟล์ robots.txt นี้จะทำงานได้ดีสำหรับเว็บไซต์ WordPress ส่วนใหญ่ แต่แน่นอนว่า คุณ ควร ปรับให้เข้ากับความต้องการของคุณเองเสมอ
วิธีตรวจสอบไฟล์ Robots.txt ของคุณเพื่อหาข้อผิดพลาด
ในช่วงเวลาของฉัน ฉันพบข้อผิดพลาดที่ส่งผลต่ออันดับในไฟล์ robots.txt มากกว่าด้านเทคนิค SEO ด้านอื่นๆ ด้วยคำสั่งที่อาจขัดแย้งกันมากมาย ปัญหาสามารถเกิดขึ้นได้
ดังนั้น เมื่อพูดถึงไฟล์ robots.txt จะต้องคอยจับตาดูปัญหาต่างๆ
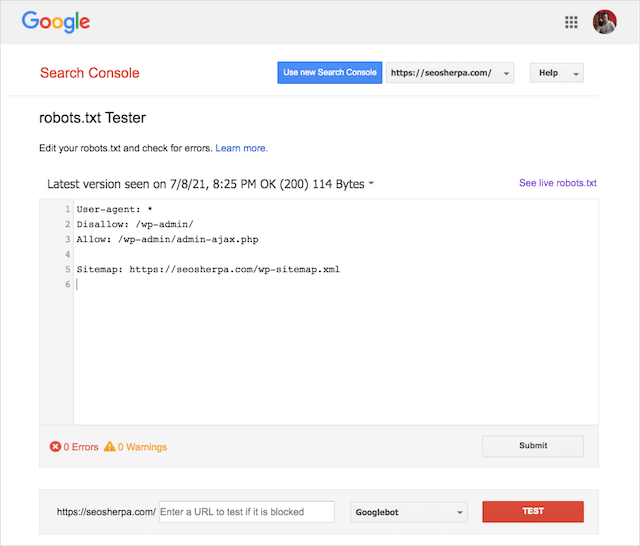
โชคดีที่รายงาน "ความครอบคลุม" ใน Google Search Console ช่วยให้คุณตรวจสอบและตรวจสอบปัญหาของ robots.txt ได้
คุณยังสามารถใช้เครื่องมือทดสอบ Robots.txt อันยอดเยี่ยมของ Google เพื่อตรวจสอบข้อผิดพลาดภายในไฟล์โรบ็อตที่ใช้งานจริงของคุณ หรือทดสอบไฟล์ robots.txt ใหม่ก่อนที่จะทำให้ใช้งานได้
เราจะปิดท้ายด้วยการกล่าวถึงปัญหาที่พบบ่อยที่สุด ความหมาย และวิธีแก้ปัญหา
URL ที่ส่งถูกบล็อกโดย robots.txt
ข้อผิดพลาดนี้หมายความว่า URL อย่างน้อยหนึ่งรายการในแผนผังเว็บไซต์ที่คุณส่งถูกบล็อกโดย robots.txt

แผนผังเว็บไซต์ที่ตั้งค่าอย่างถูกต้องควร รวมเฉพาะ URL ที่คุณต้องการสร้างดัชนีในเครื่องมือค้นหา ด้วยเหตุนี้ จึงไม่ควรประกอบด้วยหน้าที่ไม่มีการจัดทำดัชนี กำหนดรูปแบบบัญญัติ หรือเปลี่ยนเส้นทาง
หากคุณได้ปฏิบัติตามแนวทางปฏิบัติที่ดีที่สุดเหล่านี้แล้ว หน้าที่ส่งในแผนผังเว็บไซต์ ไม่ควร ถูกบล็อกโดย robots.txt
หากคุณเห็น “URL ที่ส่งถูกบล็อกโดย robots.txt” ในรายงานความครอบคลุม คุณควรตรวจสอบว่าหน้าใดได้รับผลกระทบ จากนั้นจึงเปลี่ยนไฟล์ robots.txt เพื่อลบการบล็อกสำหรับหน้านั้น
คุณสามารถใช้เครื่องมือทดสอบ robots.txt ของ Google เพื่อดูว่าคำสั่งใดที่บล็อกเนื้อหา
ถูกบล็อกโดย Robots.txt
“ข้อผิดพลาด” นี้หมายความว่าคุณมีหน้าเว็บที่ถูกบล็อกโดย robots.txt ซึ่งไม่อยู่ในดัชนีของ Google

หากเนื้อหานี้มียูทิลิตี้และควรได้รับการจัดทำดัชนี ให้นำบล็อกการรวบรวมข้อมูลใน robots.txt ออก
คำเตือนสั้น ๆ :
“บล็อกโดย robots.txt” ไม่จำเป็นต้องเป็นข้อผิดพลาด อันที่จริงอาจเป็นผลลัพธ์ที่คุณต้องการได้อย่างแม่นยำ
ตัวอย่างเช่น คุณอาจบล็อกไฟล์บาง ไฟล์ ใน robots.txt ที่ต้องการแยกไฟล์ออกจากดัชนีของ Google ในทางกลับกัน หากคุณบล็อกการรวบรวมข้อมูลของหน้าบาง หน้า โดยตั้งใจที่จะไม่สร้างดัชนี ให้พิจารณาลบบล็อกการรวบรวมข้อมูลและใช้เมตาแท็กของโรบ็อตแทน
นั่นเป็นวิธีเดียวที่จะรับประกันการยกเว้นเนื้อหาจากดัชนีของ Google
จัดทำดัชนี แม้ว่าจะถูกบล็อกโดย Robots.txt
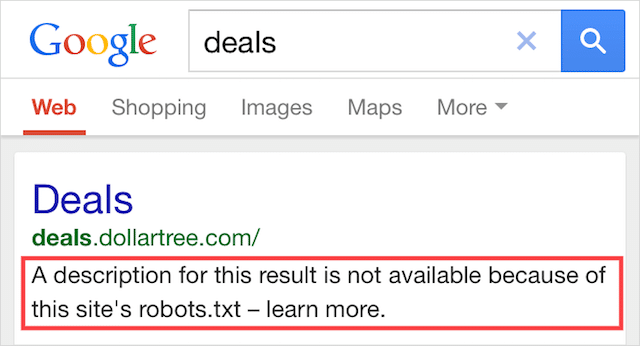
ข้อผิดพลาดนี้หมายความว่าเนื้อหาบางส่วนที่ถูกบล็อกโดย robots.txt ยังคงได้รับการจัดทำดัชนีใน Google
เกิดขึ้นเมื่อ Googlebot ยังคงสามารถค้นพบเนื้อหาได้เนื่องจากมีการเชื่อมโยงจากที่อื่นบนเว็บ กล่าวโดยย่อ Googlebot ไปที่เนื้อหานั้นรวบรวมข้อมูลแล้วจัดทำดัชนีก่อนที่จะไปที่ไฟล์ robots.txt ของเว็บไซต์ของคุณ ซึ่งจะเห็นคำสั่งที่ไม่อนุญาต
ถึงตอนนั้นก็สายเกินไป และได้รับการจัดทำดัชนี:
ให้ฉันเจาะบ้านหลังนี้:
หากคุณกำลังพยายามแยกเนื้อหาออกจากผลการค้นหาของ Google แสดงว่า robots.txt ไม่ใช่วิธีแก้ปัญหาที่ถูกต้อง
ฉันแนะนำให้ลบบล็อกการรวบรวมข้อมูลและใช้แท็ก meta robots no-index เพื่อป้องกันการสร้างดัชนีแทน
ในทางกลับกัน หากคุณบล็อกเนื้อหานี้โดยไม่ได้ตั้งใจและต้องการเก็บไว้ในดัชนีของ Google ให้นำบล็อกการรวบรวมข้อมูลใน robots.txt ออกแล้วปล่อยไว้อย่างนั้น
ซึ่งอาจช่วยปรับปรุงการมองเห็นเนื้อหาในการค้นหาของ Google
ความคิดสุดท้าย
สามารถใช้ Robots.txt เพื่อปรับปรุงการรวบรวมข้อมูลและการจัดทำดัชนีเนื้อหาเว็บไซต์ของคุณ ซึ่งจะช่วยให้คุณมองเห็นได้ใน SERPs มากขึ้น
เมื่อใช้อย่างมีประสิทธิภาพ จะเป็นข้อความที่สำคัญที่สุดในเว็บไซต์ของคุณ แต่เมื่อใช้อย่างไม่ระมัดระวัง มันจะเป็นจุดอ่อนในโค้ดของเว็บไซต์ของคุณ
ข่าวดี มีเพียงความเข้าใจพื้นฐานเกี่ยวกับตัวแทนผู้ใช้และแนวทางปฏิบัติจำนวนหนึ่ง ผลการค้นหาที่ดีขึ้นอยู่ใกล้แค่เอื้อม
คำถามเดียวคือ คุณจะใช้โปรโตคอลใดในไฟล์ robots.txt ของคุณ
แจ้งให้เราทราบในความคิดเห็นด้านล่าง