
Robots.txt : le guide ultime pour le référencement (édition 2021)
Publié: 2021-06-10 Aujourd'hui, vous allez apprendre à créer l'un des fichiers les plus critiques pour le référencement d'un site Web :
Aujourd'hui, vous allez apprendre à créer l'un des fichiers les plus critiques pour le référencement d'un site Web :
(Le fichier robots.txt).
Plus précisément, je vais vous montrer comment utiliser les protocoles d'exclusion des robots pour bloquer les robots de pages particulières, augmenter la fréquence de crawl, optimiser le budget de crawl et, finalement, obtenir davantage de classement de la bonne page dans les SERP.
Je couvre :
- Qu'est-ce qu'un fichier robots.txt ?
- Pourquoi robots.txt est important
- Comment fonctionne robots.txt
- Agents utilisateurs et directives Robots.txt
- Robots.txt contre les méta-robots
- Comment trouver votre fichier robots.txt
- Création de votre fichier robots.txt
- Bonnes pratiques concernant le fichier Robots.txt
- Exemples de robots.txt
- Comment auditer votre robots.txt pour les erreurs
De plus, bien plus encore. Plongeons dedans.
Qu'est-ce qu'un fichier Robots.txt ? Et, pourquoi vous en avez besoin d'un
En termes simples, un fichier robots.txt est un manuel d'instructions pour les robots Web.
Il informe les robots de tous types des sections d'un site qu'ils doivent (et ne doivent pas) explorer.
Cela dit, robots.txt est principalement utilisé comme un "code de conduite" pour contrôler l'activité des robots des moteurs de recherche (crawlers Web AKA).

Le robots.txt est vérifié régulièrement par tous les principaux moteurs de recherche (y compris Google, Bing et Yahoo) pour obtenir des instructions sur la façon dont ils doivent explorer le site Web. Ces instructions sont appelées directives .
S'il n'y a pas de directives - ou pas de fichier robots.txt - les moteurs de recherche exploreront l'intégralité du site Web, les pages privées et tout.
Bien que la plupart des moteurs de recherche soient obéissants, il est important de noter que le respect des directives robots.txt est facultatif. S'ils le souhaitent, les moteurs de recherche peuvent choisir d'ignorer votre fichier robots.txt.
Heureusement, Google ne fait pas partie de ces moteurs de recherche. Google a tendance à obéir aux instructions d'un fichier robots.txt.
Pourquoi Robots.txt est-il important ?
Avoir un fichier robots.txt n'est pas essentiel pour de nombreux sites Web, en particulier les plus petits.
En effet, Google peut généralement trouver et indexer toutes les pages essentielles d'un site.
De plus, ils n'indexeront PAS automatiquement le contenu en double ou les pages sans importance.
Mais encore, il n'y a aucune bonne raison de ne pas avoir un fichier robots.txt - donc je vous recommande d'en avoir un.
Un robots.txt vous donne un meilleur contrôle sur ce que les moteurs de recherche peuvent et ne peuvent pas explorer sur votre site Web, et cela est utile pour plusieurs raisons :
Permet de bloquer les pages non publiques des moteurs de recherche
Parfois, vous avez des pages sur votre site que vous ne souhaitez pas indexer.
Par exemple, vous développez peut-être un nouveau site Web dans un environnement intermédiaire dont vous voulez vous assurer qu'il est caché aux utilisateurs jusqu'au lancement.
Ou vous pouvez avoir des pages de connexion à un site Web que vous ne voulez pas voir apparaître dans les SERP.
Si tel était le cas, vous pourriez utiliser robots.txt pour bloquer ces pages des robots des moteurs de recherche.
Contrôle le budget d'exploration des moteurs de recherche
Si vous rencontrez des difficultés pour indexer toutes vos pages dans les moteurs de recherche, vous avez peut-être un problème de budget de crawl.
En termes simples, les moteurs de recherche utilisent le temps imparti pour explorer votre contenu sur les pages mortes de votre site Web.

En bloquant les URL à faible utilité avec robots.txt, les robots des moteurs de recherche peuvent dépenser une plus grande partie de leur budget de crawl sur les pages qui comptent le plus.
Empêche l'indexation des ressources
Il est recommandé d'utiliser la méta-directive "no-index" pour empêcher l'indexation de pages individuelles.
Le problème est que les méta-directives ne fonctionnent pas bien pour les ressources multimédias, comme les PDF et les documents Word.
C'est là que robots.txt est pratique.
Vous pouvez ajouter une simple ligne de texte à votre fichier robots.txt et les moteurs de recherche seront bloqués pour accéder à ces fichiers multimédias.
(Je vous montrerai exactement comment faire cela plus tard dans ce post)
Comment (exactement) fonctionne un Robots.txt ?
Comme je l'ai déjà partagé, un fichier robots.txt agit comme un manuel d'instructions pour les robots des moteurs de recherche. Il indique aux robots de recherche où (et où non) ils doivent explorer.
C'est pourquoi un robot de recherche recherchera un fichier robots.txt dès qu'il arrivera sur un site Web.
S'il trouve le robots.txt, le crawler le lira d'abord avant de poursuivre son exploration du site.
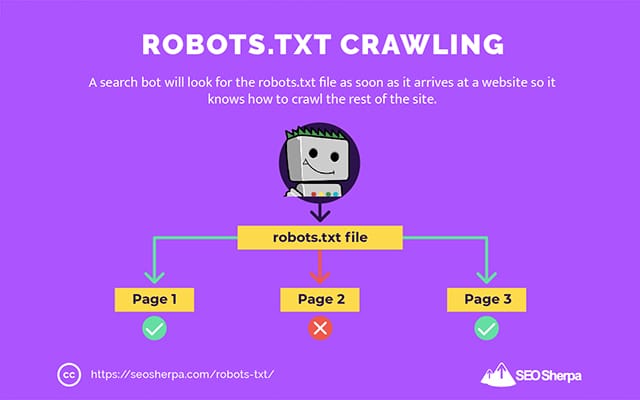
Si le robot d'exploration ne trouve pas de fichier robots.txt, ou si le fichier ne contient pas de directives interdisant l'activité des robots de recherche, le robot d'exploration continuera à parcourir l'ensemble du site comme d'habitude.
Pour qu'un fichier robots.txt soit trouvable et lisible par les robots de recherche, un robots.txt est formaté d'une manière très particulière.
Premièrement, il s'agit d'un fichier texte sans code de balisage HTML (d'où l'extension .txt).
Deuxièmement, il est placé dans le dossier racine du site Web, par exemple, https://seosherpa.com/robots.txt.
Troisièmement, il utilise une syntaxe standard commune à tous les fichiers robots.txt, comme ceci :
Sitemap: [URL location of sitemap] User-agent: [bot identifier] [directive 1] [directive 2] [directive ...] User-agent: [another bot identifier] [directive 1] [directive 2] [directive ...]Cette syntaxe peut sembler intimidante à première vue, mais elle est en fait assez simple.
En bref, vous définissez le bot (agent utilisateur) auquel les instructions s'appliquent, puis énoncez les règles (directives) que le bot doit suivre.
Explorons ces deux composants plus en détail.
Agents utilisateurs
Un agent utilisateur est le nom utilisé pour définir des robots d'exploration Web spécifiques - et d'autres programmes actifs sur Internet.
Il existe littéralement des centaines d'agents utilisateurs, y compris des agents pour les types d'appareils et les navigateurs.
La plupart ne sont pas pertinents dans le contexte d'un fichier robots.txt et du référencement. D'autre part, ceux-ci vous devez savoir:
- Google : Googlebot
- Google Images : Googlebot-Image
- Google Video : Googlebot-Vidéo
- Google Actualités : Googlebot Actualités
- Bing : Bingbot
- Images et vidéos Bing : MSNBot-Media
- Yahoo : Slurp
- Yandex : YandexBot
- Baidu : Baiduspider
- DuckDuckGo : DuckDuckBot
En indiquant l'agent utilisateur, vous pouvez définir différentes règles pour différents moteurs de recherche.

Par exemple, si vous souhaitez qu'une certaine page apparaisse dans les résultats de recherche Google mais pas dans les recherches Baidu, vous pouvez inclure deux ensembles de commandes dans votre fichier robots.txt : un ensemble précédé de "User-agent : Bingbot" et un ensemble précédé de par "User-agent : Baiduspider".
Vous pouvez également utiliser le caractère générique étoile (*) si vous souhaitez que vos directives s'appliquent à tous les agents utilisateurs.
Par exemple, supposons que vous souhaitiez empêcher tous les robots des moteurs de recherche d'explorer votre site, à l'exception de DuckDuckGo. Voici comment procéder :
User-agent: * Disallow: / User-agent: DuckDuckBot Allow: /Sidenote : S'il y a des commandes contradictoires dans le fichier robots.txt, le bot suivra la commande la plus granulaire.
C'est pourquoi dans l'exemple ci-dessus, DuckDuckBot sait explorer le site Web, même si une directive précédente (s'appliquant à tous les bots) indiquait de ne pas explorer. En bref, un bot suivra l'instruction qui s'applique le plus précisément à lui.
Directives
Les directives sont le code de conduite que vous voulez que l'agent utilisateur suive. En d'autres termes, les directives définissent comment le robot de recherche doit explorer votre site Web.
Voici les directives actuellement prises en charge par GoogleBot, ainsi que leur utilisation dans un fichier robots.txt :
Refuser
Utilisez cette directive pour empêcher les robots de recherche d'explorer certains fichiers et pages sur un chemin d'URL spécifique.

Par exemple, si vous vouliez empêcher GoogleBot d'accéder à votre wiki et à toutes ses pages, votre fichier robots.txt devrait contenir cette directive :
User-agent: GoogleBot Disallow: /wikiVous pouvez utiliser la directive disallow pour bloquer l'exploration d'une URL précise, de tous les fichiers et pages d'un certain répertoire, et même de l'ensemble de votre site Web.
Permettre
La directive allow est utile si vous souhaitez autoriser les moteurs de recherche à explorer un sous-répertoire ou une page spécifique - dans une section autrement interdite de votre site.

Supposons que vous souhaitiez empêcher tous les moteurs de recherche d'explorer les publications de votre blog, à l'exception d'un ; alors vous utiliseriez la directive allow comme ceci:
User-agent: * Disallow: /blog Allow: /blog/allowable-postÉtant donné que les robots de recherche suivent toujours les instructions les plus détaillées données dans un fichier robots.txt, ils savent explorer /blog/allowable-post, mais ils n'exploreront pas d'autres publications ou fichiers dans ce répertoire comme ;
- /blog/post-one/
- /blog/post-deux/
- /blog/nom-du-fichier.pdf
Google et Bing prennent en charge cette directive. Mais les autres moteurs de recherche ne le font pas.
Plan du site
La directive sitemap est utilisée pour spécifier l'emplacement de votre (vos) sitemap(s) XML aux moteurs de recherche.
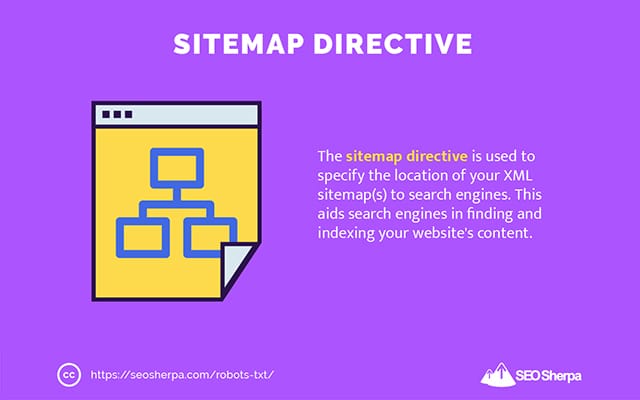
Si vous débutez avec les sitemaps, ils sont utilisés pour répertorier les pages que vous souhaitez explorer et indexer dans les moteurs de recherche.
En incluant la directive sitemap dans robots.txt, vous aidez les moteurs de recherche à trouver votre sitemap et, à leur tour, à explorer et indexer les pages les plus importantes de votre site Web.
Cela dit, si vous avez déjà soumis votre sitemap XML via la Search Console, l'ajout de votre ou vos sitemap(s) dans robots.txt est quelque peu redondant pour Google. Néanmoins, il est préférable d'utiliser la directive sitemap car elle indique aux moteurs de recherche comme Ask, Bing et Yahoo où se trouvent vos sitemaps.
Voici un exemple de fichier robots.txt utilisant la directive sitemap :
Sitemap: https://www.website.com/sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/Notez l'emplacement de la directive sitemap dans le fichier robots.txt. Il est préférable de le placer tout en haut de votre robots.txt. Il peut également être placé en bas.
Si vous avez plusieurs sitemaps, vous devez tous les inclure dans votre fichier robots.txt. Voici à quoi ressemblerait le fichier robots.txt si nous avions des sitemaps XML distincts pour les pages et les publications :
Sitemap: http://website.com/post-sitemap.xml Sitemap: http://website.com/page-sitemap.xml User-agent: * Disallow: /wiki/ Allow: /wike/article-title/Dans tous les cas, vous n'avez besoin de mentionner qu'une seule fois chaque plan de site XML, car tous les agents utilisateurs pris en charge suivront la directive.
Notez que, contrairement aux autres directives robots.txt, qui répertorient les chemins, la directive sitemap doit indiquer l'URL absolue de votre sitemap XML, y compris le protocole, le nom de domaine et l'extension de domaine de premier niveau.
commentaires
Le commentaire "directive" est utile pour les humains mais n'est pas utilisé par les robots de recherche.

Vous pouvez ajouter des commentaires pour vous rappeler pourquoi certaines directives existent ou empêcher ceux qui ont accès à votre fichier robots.txt de supprimer des directives importantes. En bref, les commentaires sont utilisés pour ajouter des notes à votre fichier robots.txt.
Pour ajouter un commentaire, tapez. #" suivi du texte du commentaire.
# Don't allow access to the /wp-admin/ directory for all robots. User-agent: * Disallow: /wp-admin/Vous pouvez ajouter un commentaire au début d'une ligne (comme indiqué ci-dessus) ou après une directive sur la même ligne (comme indiqué ci-dessous) :
User-agent: * #Applies to all robots Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.Où que vous choisissiez d'écrire votre commentaire, tout ce qui suit le hachage sera ignoré.
Vous avez suivi jusqu'ici ?
Super! Nous avons maintenant couvert les principales directives dont vous aurez besoin pour votre fichier robots.txt - ce sont également les seules directives prises en charge par Google.
Mais qu'en est-il des autres moteurs de recherche ? Dans le cas de Bing, Yahoo et Yandex, il existe une autre directive que vous pouvez utiliser :
Délai d'exploration
La directive Crawl-delay est une directive non officielle utilisée pour empêcher les serveurs de se surcharger avec trop de requêtes de crawl.
En d'autres termes, vous l'utilisez pour limiter la fréquence à laquelle un moteur de recherche peut explorer votre site.

Attention, si les moteurs de recherche peuvent surcharger votre serveur en explorant fréquemment votre site Web, l'ajout de la directive Crawl-delay à votre fichier robots.txt ne résoudra le problème que temporairement.
Le cas peut être que votre site Web fonctionne sur un hébergement merdique ou un environnement d'hébergement mal configuré, et c'est quelque chose que vous devriez corriger rapidement.
La directive de délai d'exploration fonctionne en définissant le temps en secondes entre lequel un bot de recherche peut explorer votre site Web.
Par exemple, si vous définissez votre délai d'exploration sur 5, les robots de recherche découperont la journée en fenêtres de cinq secondes, n'explorant qu'une seule page (ou aucune) dans chaque fenêtre, pour un maximum d'environ 17 280 URL au cours de la journée.
Cela étant, soyez prudent lorsque vous définissez cette directive, surtout si vous avez un grand site Web. Seulement 17 280 URL explorées par jour ne sont pas très utiles si votre site compte des millions de pages.
La façon dont chaque moteur de recherche gère la directive crawl-delay diffère. Décomposons-le ci-dessous :
Délai d'exploration et Bing, Yahoo et Yandex
Bing, Yahoo et Yandex prennent tous en charge la directive crawl-delay dans robots.txt.
Cela signifie que vous pouvez définir une directive de délai d'exploration pour les agents utilisateurs BingBot, Slurp et YandexBot, et le moteur de recherche limitera son exploration en conséquence.
Notez que chaque moteur de recherche interprète le délai d'exploration d'une manière légèrement différente , alors assurez-vous de vérifier leur documentation :
- Bing et Yahoo
- Yandex
Cela dit, le format de la directive crawl-delay pour chacun de ces moteurs est le même. Vous devez le placer juste après une directive d'interdiction OU d'autorisation. Voici un exemple:
User-agent: BingBot Allow: /widgets/ Crawl-delay: 5Délai de crawl et Google
Le robot d'exploration de Google ne prend pas en charge la directive crawl-delay, il est donc inutile de définir un délai d'exploration pour GoogleBot dans robots.txt.
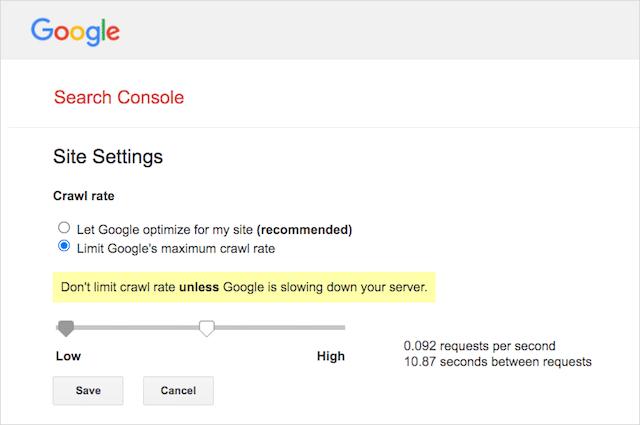
Cependant, Google prend en charge la définition d'un taux d'exploration dans Google Search Console. Voici comment procéder :
- Accédez à la page des paramètres de Google Search Console.
- Choisissez la propriété pour laquelle vous souhaitez définir la vitesse de crawl
- Cliquez sur "Limiter la vitesse d'exploration maximale de Google".
- Ajustez le curseur à votre vitesse d'exploration préférée. Par défaut, la vitesse d'exploration a le paramètre "Laisser Google optimiser pour mon site (recommandé)".
Délai d'exploration et Baidu
Comme Google, Baidu ne prend pas en charge la directive sur les délais d'exploration. Cependant, il est possible d'enregistrer un compte Baidu Webmaster Tools dans lequel vous pouvez contrôler la fréquence d'exploration, similaire à Google Search Console.
La ligne du bas? Robots.txt indique aux robots des moteurs de recherche de ne pas explorer des pages spécifiques de votre site Web.
Robots.txt vs méta-robots vs x-robots
Il y a un tas d'instructions de "robots" là-bas. Quelles sont les différences ou sont-elles identiques ?
Permettez-moi de vous proposer une brève explication :
Tout d'abord, robots.txt est un fichier texte réel, tandis que meta et x-robots sont des balises dans le code d'une page Web.
Deuxièmement, robots.txt donne aux bots des suggestions sur la façon d'explorer les pages d'un site Web. D'autre part, les méta-directives des robots fournissent des instructions très fermes sur l'exploration et l'indexation du contenu d'une page.
Au-delà de ce qu'ils sont, les trois remplissent tous des fonctions différentes.
Robots.txt dicte le comportement d'exploration à l'échelle du site ou du répertoire, tandis que les méta et x-robots peuvent dicter le comportement d'indexation au niveau de la page individuelle (ou de l'élément de page).

En général:
Si vous souhaitez empêcher l'indexation d'une page, vous devez utiliser la balise meta robots "no-index". Interdire une page dans robots.txt ne garantit pas qu'elle ne sera pas affichée dans les moteurs de recherche (les directives robots.txt sont des suggestions, après tout). De plus, un robot de moteur de recherche pourrait toujours trouver cette URL et l'indexer si elle est liée à un autre site Web.

Au contraire, si vous souhaitez empêcher l'indexation d'un fichier multimédia, robots.txt est la solution. Vous ne pouvez pas ajouter de balises meta robots à des fichiers tels que des jpegs ou des PDF.
Comment trouver votre Robots.txt
Si vous avez déjà un fichier robots.txt sur votre site Web, vous pourrez y accéder sur votredomaine.com/robots.txt.
Accédez à l'URL dans votre navigateur.
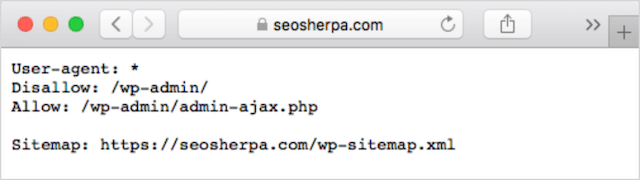
Si vous voyez une page textuelle comme celle ci-dessus, vous avez un fichier robots.txt.
Comment créer un fichier Robots.txt
Si vous n'avez pas encore de fichier robots.txt, en créer un est simple.
Tout d'abord, ouvrez le Bloc-notes, Microsoft Word ou n'importe quel éditeur de texte et enregistrez le fichier sous le nom de "robots".
Assurez-vous d'utiliser des minuscules et choisissez .txt comme extension de type de fichier :

Deuxièmement, ajoutez vos directives. Par exemple, si vous souhaitez interdire à tous les robots de recherche d'explorer votre répertoire /login/, vous devez saisir ceci :
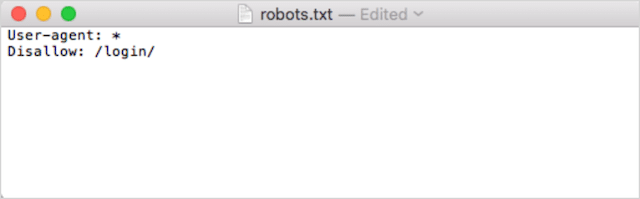
Continuez à ajouter des directives jusqu'à ce que vous soyez satisfait de votre fichier robots.txt.
Alternativement, vous pouvez générer votre robots.txt avec un outil comme celui-ci de Ryte.

L'un des avantages de l'utilisation d'un outil est qu'il minimise l'erreur humaine.
Une seule petite erreur dans la syntaxe de votre robots.txt pourrait se terminer par un désastre SEO.
Cela dit, l'inconvénient d'utiliser un générateur de robots.txt est que la possibilité de personnalisation est minime.
C'est pourquoi je vous recommande d'apprendre à écrire vous-même un fichier robot.txt. Vous pouvez ensuite créer un robots.txt exactement selon vos besoins.
Où placer votre fichier Robots.txt
Ajoutez votre fichier robots.txt dans le répertoire de niveau supérieur du sous-domaine auquel il s'applique.
Par exemple, pour contrôler le comportement d'exploration sur votredomaine.com , le fichier robots.txt doit être accessible sur le chemin d'URL de votredomaine.com/robots.txt .
D'autre part, si vous souhaitez contrôler le crawling sur un sous-domaine tel que shop.votredomaine.com , le robots.txt doit être accessible sur le chemin d'URL shop.votredomaine.com/robots.txt .
Les règles d'or sont :
- Donnez à chaque sous-domaine de votre site Web son propre fichier robots.txt.
- Nommez votre ou vos fichiers robots.txt en minuscules.
- Placez le fichier dans le répertoire racine du sous-domaine auquel il fait référence.
Si le fichier robots.txt est introuvable dans le répertoire racine, les moteurs de recherche supposeront qu'il n'y a pas de directives et exploreront votre site Web dans son intégralité.
Meilleures pratiques pour le fichier Robots.txt
Ensuite, couvrons les règles des fichiers robots.txt. Suivez ces bonnes pratiques pour éviter les pièges courants du fichier robots.txt :
Utiliser une nouvelle ligne pour chaque directive
Chaque directive de votre fichier robots.txt doit figurer sur une nouvelle ligne.
Sinon, les moteurs de recherche ne sauront plus quoi explorer (et indexer).
Ceci, par exemple, est mal configuré :
User-agent: * Disallow: /folder/ Disallow: /another-folder/Ceci, en revanche, est un fichier robots.txt correctement configuré :
User-agent: * Disallow: /folder/ Disallow: /another-folder/La spécificité gagne "presque" toujours
En ce qui concerne Google et Bing, la directive la plus granulaire l'emporte.
Par exemple, cette directive Allow l'emporte sur la directive Disallow car sa longueur en caractères est plus longue.
User-agent: * Disallow: /about/ Allow: /about/company/Google et Bing savent explorer /about/company/ mais pas les autres pages du répertoire /about/.
Cependant, dans le cas d'autres moteurs de recherche, c'est le contraire qui est vrai.
Par défaut, pour tous les principaux moteurs de recherche autres que Google et Bing, la première directive correspondante l'emporte toujours .
Dans l'exemple ci-dessus, les moteurs de recherche suivront la directive Disallow et ignoreront la directive Allow, ce qui signifie que la page /about/company ne sera pas explorée.
Gardez cela à l'esprit lorsque vous créez des règles pour tous les moteurs de recherche.
Un seul groupe de directives par user-agent
Si votre robots.txt contenait plusieurs groupes de directives par agent utilisateur, boh-oh-boy, cela pourrait-il prêter à confusion ?
Pas nécessairement pour les robots, car ils combineront toutes les règles des différentes déclarations en un seul groupe et les suivront toutes, mais pour vous.
Pour éviter tout risque d'erreur humaine, indiquez l'agent utilisateur une fois, puis répertoriez ci-dessous toutes les directives qui s'appliquent à cet agent utilisateur.

En gardant les choses propres et simples, vous êtes moins susceptible de faire une gaffe.
Utilisez des caractères génériques (*) pour simplifier les instructions
Avez-vous remarqué les caractères génériques (*) dans l'exemple ci-dessus ?
C'est vrai; vous pouvez utiliser des caractères génériques (*) pour appliquer des règles à tous les agents utilisateurs ET pour faire correspondre les modèles d'URL lors de la déclaration de directives.
Par exemple, si vous souhaitez empêcher les robots de recherche d'accéder aux URL de catégories de produits paramétrées sur votre site Web, vous pouvez répertorier chaque catégorie comme suit :
User-agent: * Disallow: /products/watches? Disallow: /products/handbags? Disallow: /products/shoes?Ou, vous pouvez utiliser un caractère générique qui appliquerait la règle à toutes les catégories. Voici à quoi cela ressemblerait :
User-agent: * Disallow: /products/*?Cet exemple empêche les moteurs de recherche d'explorer toutes les URL du sous-dossier /product/ contenant un point d'interrogation. En d'autres termes, toutes les URL de catégorie de produits qui sont paramétrées.
Google, Bing, Yahoo prennent en charge l'utilisation de caractères génériques dans les directives robots.txt et Ask.
Utilisez "$" pour spécifier la fin d'une URL
Pour indiquer la fin d'une URL, utilisez le signe dollar ( $ ) après le chemin robots.txt.
Supposons que vous souhaitiez empêcher les robots de recherche d'accéder à tous les fichiers .doc de votre site Web ; alors vous utiliseriez cette directive:
User-agent: * Disallow: /*.doc$Cela empêcherait les moteurs de recherche d'accéder aux URL se terminant par .doc.
Cela signifie qu'ils n'exploreront pas /media/file.doc, mais qu'ils exploreront /media/file.doc?id=72491 car cette URL ne se termine pas par ".doc".
Chaque sous-domaine obtient son propre fichier robots.txt
Les directives robots.txt ne s'appliquent qu'au (sous-)domaine sur lequel le fichier robots.txt est hébergé.
Cela signifie que si votre site a plusieurs sous-domaines comme :
- domaine.com
- tickets.domaine.com
- événements.domaine.com
Chaque sous-domaine nécessitera son propre fichier robots.txt.
Le robots.txt doit toujours être ajouté dans le répertoire racine de chaque sous-domaine. Voici à quoi ressembleraient les chemins en utilisant l'exemple ci-dessus :
- domaine.com/robots.txt
- tickets.domain.com/robots.txt
- events.domain.com/robots.txt
N'utilisez pas de noindex dans votre robots.txt
En termes simples, Google ne prend pas en charge la directive no-index dans robots.txt.
Bien que Google l'ait suivi dans le passé, à partir de juillet 2019, Google a cessé de le prendre entièrement en charge.
Et si vous envisagez d'utiliser la directive no-index robots.txt pour ne pas indexer le contenu sur d'autres moteurs de recherche, détrompez-vous :
La directive non officielle sans index n'a jamais fonctionné dans Bing.
De loin, la meilleure méthode pour ne pas indexer le contenu dans les moteurs de recherche consiste à appliquer une balise meta robots sans index à la page que vous souhaitez exclure.
Gardez votre fichier robots.txt en dessous de 512 Ko
Google a actuellement une limite de taille de fichier robots.txt de 500 kibioctets (512 kilo-octets).
Cela signifie que tout contenu après 512 Ko peut être ignoré.

Cela dit, étant donné qu'un caractère ne consomme qu'un octet, votre robots.txt devrait être ÉNORME pour atteindre cette limite de taille de fichier (512 000 caractères, pour être exact). Gardez votre fichier robots.txt léger en vous concentrant moins sur les pages exclues individuellement et davantage sur des modèles plus larges que les caractères génériques peuvent contrôler.
Il n'est pas clair si d'autres moteurs de recherche ont la taille de fichier maximale autorisée pour les fichiers robots.txt.
Robots.txt Exemples
Vous trouverez ci-dessous quelques exemples de fichiers robots.txt.
Ils incluent des combinaisons des directives que notre agence de référencement utilise le plus dans les fichiers robots.txt pour les clients. Gardez à l'esprit, cependant; ceux-ci sont uniquement à des fins d'inspiration. Vous devrez toujours personnaliser le fichier robots.txt pour répondre à vos besoins.
Autoriser tous les robots à accéder à tout
Ce fichier robots.txt ne fournit aucune règle d'interdiction pour tous les moteurs de recherche :
User-agent: * Disallow:En d'autres termes, cela permet aux robots de recherche de tout explorer. Il a le même objectif qu'un fichier robots.txt vide ou aucun robots.txt du tout.
Empêcher tous les robots d'accéder à tout
L'exemple de fichier robots.txt indique à tous les moteurs de recherche de ne rien accéder après la barre oblique finale. En d'autres termes, l'ensemble du domaine :
User-agent: * Disallow: /En bref, ce fichier robots.txt bloque tous les robots des moteurs de recherche et peut empêcher l'affichage de votre site sur les pages de résultats de recherche.
Empêcher tous les robots d'explorer un seul fichier
Dans cet exemple, nous empêchons tous les robots de recherche d'explorer un fichier particulier.
User-agent: * Disallow: /directory/this-is-a-file.pdfEmpêcher tous les robots d'explorer un type de fichier (doc, pdf, jpg)
Depuis la non-indexation, un fichier comme « doc » ou « pdf » ne peut pas être créé à l'aide d'une balise méta-robot « sans index » ; vous pouvez utiliser la directive suivante pour empêcher l'indexation d'un type de fichier particulier.
User-agent: * Disallow: /*.doc$ Disallow: /*.pdf$ Disallow: /*.jpg$Cela fonctionnera pour désindexer tous les fichiers de ce type, tant qu'aucun fichier individuel n'est lié à partir d'ailleurs sur le Web.
Empêcher Google d'explorer plusieurs répertoires
Vous pouvez bloquer l'exploration de plusieurs répertoires pour un bot particulier ou tous les bots. Dans cet exemple, nous empêchons Googlebot d'explorer deux sous-répertoires.
User-agent: Googlebot Disallow: /admin/ Disallow: /private/Notez qu'il n'y a pas de limite au nombre de répertoires que vous pouvez utiliser bock. Énumérez simplement chacun sous l'agent utilisateur auquel la directive s'applique.
Empêcher Google d'explorer toutes les URL paramétrées
Cette directive est particulièrement utile pour les sites Web utilisant la navigation à facettes, où de nombreuses URL paramétrées peuvent être créées.
User-agent: Googlebot Disallow: /*?Cette directive empêche votre budget de crawl d'être consommé sur les URL dynamiques et maximise le crawl des pages importantes. Je l'utilise régulièrement, notamment sur les sites e-commerce avec fonction de recherche.
Empêcher tous les bots d'explorer un sous-répertoire mais d'autoriser l'exploration d'une page à l'intérieur
Parfois, vous voudrez peut-être empêcher les robots d'exploration d'accéder à une section complète de votre site, mais laisser une page accessible. Si c'est le cas, utilisez la combinaison suivante de directives 'allow' et 'disallow' :
User-agent: * Disallow: /category/ Allow: /category/widget/Il indique aux moteurs de recherche de ne pas explorer le répertoire complet, à l'exclusion d'une page ou d'un fichier particulier.
Robots.txt pour WordPress
C'est la configuration de base que je recommande pour un fichier WordPress robots.txt. Il bloque l'exploration des pages d'administration, des balises et des URL des auteurs, ce qui peut créer des crudités inutiles sur un site Web WordPress.
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /wp-admin/ Disallow: /readme.html Disallow: /refer/ Disallow: /tag/ Disallow: /author/ Disallow: /404-error/ Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xmlCe fichier robots.txt fonctionnera bien pour la plupart des sites Web WordPress, mais bien sûr, vous devez toujours l'adapter à vos propres besoins.
Comment auditer votre fichier Robots.txt pour les erreurs
À mon époque, j'ai vu plus d'erreurs ayant un impact sur le classement dans les fichiers robots.txt que peut-être tout autre aspect du référencement technique. Avec autant de directives potentiellement contradictoires, des problèmes peuvent survenir et surviennent.
Ainsi, en ce qui concerne les fichiers robots.txt, il est utile de garder un œil sur les problèmes.
Heureusement, le rapport "Couverture" dans Google Search Console vous permet de vérifier et de surveiller les problèmes de robots.txt.
Vous pouvez également utiliser l'outil de test Robots.txt astucieux de Google pour vérifier les erreurs dans votre fichier de robots en direct ou tester un nouveau fichier robots.txt avant de le déployer.
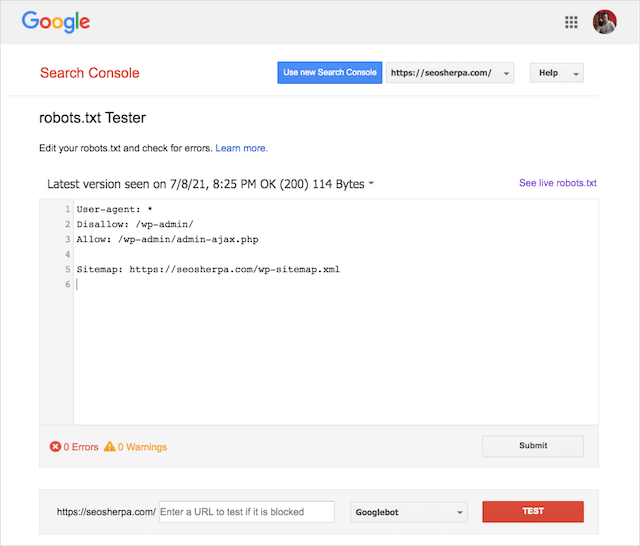
Nous terminerons en couvrant les problèmes les plus courants, ce qu'ils signifient et comment les résoudre.
URL soumise bloquée par robots.txt
Cette erreur signifie qu'au moins une des URL de votre ou vos sitemaps soumis est bloquée par robots.txt.

Un sitemap correctement configuré ne doit inclure que les URL que vous souhaitez indexer dans les moteurs de recherche . En tant que tel, il ne doit pas contenir de pages non indexées, canonisées ou redirigées.
Si vous avez suivi ces bonnes pratiques, aucune page soumise dans votre sitemap ne doit être bloquée par robots.txt.
Si vous voyez "URL soumise bloquée par robots.txt" dans le rapport de couverture, vous devez rechercher les pages concernées, puis modifier votre fichier robots.txt pour supprimer le blocage de cette page.
Vous pouvez utiliser le testeur robots.txt de Google pour voir quelle directive bloque le contenu.
Bloqué par Robots.txt
Cette "erreur" signifie que vous avez des pages bloquées par votre robots.txt qui ne sont pas actuellement dans l'index de Google.

Si ce contenu est utile et doit être indexé, supprimez le bloc d'analyse dans robots.txt.
Un petit mot d'avertissement :
"Bloqué par robots.txt" n'est pas nécessairement une erreur. En fait, c'est peut-être précisément le résultat que vous souhaitez.
Par exemple, vous avez peut-être bloqué certains fichiers dans robots.txt avec l'intention de les exclure de l'index de Google. D'autre part, si vous avez bloqué l'exploration de certaines pages avec l'intention de ne pas les indexer, envisagez de supprimer le blocage d'exploration et d'utiliser à la place la balise méta d'un robot.
C'est le seul moyen de garantir l'exclusion du contenu de l'index de Google.
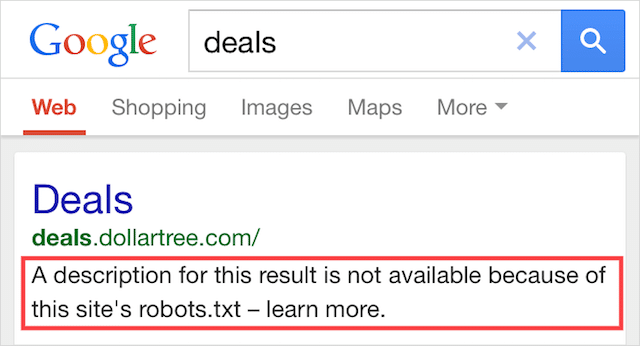
Indexé, bien que bloqué par Robots.txt
Cette erreur signifie qu'une partie du contenu bloqué par robots.txt est toujours indexé dans Google.
Cela se produit lorsque le contenu est toujours détectable par Googlebot car il est lié à partir d'ailleurs sur le Web. En bref, Googlebot atterrit sur ce contenu, l'explore, puis l'indexe avant de visiter le fichier robots.txt de votre site Web, où il voit la directive non autorisée.
À ce moment-là, il est trop tard. Et il est indexé :
Permettez-moi de forer celui-ci à la maison :
Si vous essayez d'exclure du contenu des résultats de recherche de Google, robots.txt n'est pas la bonne solution.
Je recommande de supprimer le bloc d'analyse et d'utiliser une balise meta robots no-index pour empêcher l'indexation à la place.
Au contraire, si vous avez bloqué ce contenu par accident et que vous souhaitez le conserver dans l'index de Google, supprimez le bloc d'analyse dans robots.txt et laissez-le ainsi.
Cela peut aider à améliorer la visibilité du contenu dans la recherche Google.
Dernières pensées
Robots.txt peut être utilisé pour améliorer l'exploration et l'indexation du contenu de votre site Web, ce qui vous aide à devenir plus visible dans les SERP.
Lorsqu'il est utilisé efficacement, c'est le texte le plus important de votre site Web. Mais, lorsqu'il est utilisé avec négligence, ce sera le talon d'Achille dans le code de votre site Web.
La bonne nouvelle, avec juste une compréhension de base des agents utilisateurs et quelques directives, de meilleurs résultats de recherche sont à votre portée.
La seule question est, quels protocoles allez-vous utiliser dans votre fichier robots.txt ?
Faites-le moi savoir dans les commentaires ci-dessous.