
识别实体属性关系
已发表: 2022-03-02该专利于 2022 年 3 月 1 日授予,旨在识别文本正文中的实体-属性关系。
搜索应用程序,如搜索引擎和知识库,试图满足搜索者的信息需求,并向搜索者展示最有利的资源。
结构化数据可能有助于更好地识别属性关系
识别属性实体关系在结构化搜索结果中完成。
结构化搜索结果显示属性列表,其中包含用户请求中指定的实体的答案,例如查询。
因此,“Kevin Durant”的结构化搜索结果可能包括薪水、团队、出生年份、家庭等属性,以及提供有关这些属性信息的答案。
构建这样的结构化搜索结果可能需要识别实体-属性关系。
实体-属性关系是一对术语之间的文本关系的特例。
这对术语中的第一个术语是实体、人、地点、组织或概念。
第二项是描述实体方面的属性或字符串。
示例包括:
- 一个人的“出生日期”
- 一个国家的“人口”
- 运动员的“薪水”
- 组织的“CEO”
在有关实体的内容和模式(以及结构化数据)中提供更多信息,可为搜索引擎提供更多信息,以探索有关特定实体的更好信息,测试和收集数据,消除其所知道的歧义,并对实体有更多更好的信心它知道。
实体-属性候选对
本专利获取实体-属性候选对来定义实体和属性,其中属性为实体的候选属性。 除了从结构化数据中有关实体的事实中学习之外,Google 还可以通过查看该信息的上下文来使用信息,并从向量以及其他单词和有关这些实体的事实的共现中学习。
查看单词向量专利,了解搜索引擎现在如何更好地了解单词的含义和上下文以及有关实体的信息。 (这是一个从专利探索中了解谷歌现在如何做它正在做的事情的机会。)谷歌收集关于它索引的事物的事实和数据,并可能了解它在其索引中拥有的实体,以及它知道的关于它们的属性。
它在:
- 用包含实体和属性的句子确定该属性是否是实体-属性候选对中实体的实际属性
- 为包含实体和属性的句子集中的单词生成嵌入
- 使用已知实体-属性对创建实体的分布式属性嵌入,其中实体的分布式属性嵌入基于与来自已知实体-属性对的实体相关联的其他属性指定实体的嵌入
- 基于句子中单词的嵌入,实体的分布属性嵌入,以及属性,实体-属性候选对是否是实体-属性候选对中实体的本质属性。
词的嵌入由带有实体和属性的句子组成
构建第一个向量表示,指定实体和句子集中的点之间的单词的第一个嵌入
- 制作第二个向量表示,根据句子集为实体定义双重嵌入
- 基于句子集为属性的第三个嵌入构造第三个向量表示
- Picking 与已知的实体属性相结合,结合实体的分布属性嵌入,意味着使用可用的实体-属性对制作第四个向量表示,指定实体的分布属性嵌入。
- 使用那些已知的实体-属性对构建分布式属性嵌入意味着开发第五个向量表示,其中包含可用的实体-属性团队和属性的分布式属性嵌入。
- 根据句子集中词的嵌入、实体的分布属性嵌入和属性的分布属性嵌入,判断实体-属性候选对中的属性是否是实体中实体的本质属性实体属性候选对
- 基于第一向量表示、第二向量表示、第三向量表示、第四向量表示和第五向量表示确定实体-属性候选对中的属性是否是实体中实体的本质属性- 属性候选对
- 从第一个向量表示、第二个向量表示、第三个向量表示、第四个向量表示和第五个向量表示中选择实体-属性候选对中的属性是否是实体-属性中的实体的本质属性-属性候选对,使用前馈网络执行。
- 根据第一个向量表示、第二个向量表示、第三个向量表示、第四个向量表示和第五个向量表示来挑选实体-属性候选对中的属性是否是实体中实体的本质属性-属性候选对,包括:
- 通过连接第一向量表示、第二向量表示、第三向量表示、第四向量表示和第五向量表示来生成单个向量表示; 将单个向量表示输入到前馈网络中
- 通过前馈网络,使用单向量表示来确定实体-属性候选对中的属性是否是实体-属性候选对中实体的本质属性
使用已知的实体-属性对制作第四个向量表示,指定实体的分布属性嵌入包括:
- 识别与已知实体-属性组中的实体相关联的一组属性,其中该组属性省略了该属性
- 通过计算属性集中特征的加权和来为实体生成分布属性嵌入
选择具有已知实体-属性对的第五个向量表示,指定属性的分布属性嵌入包括
- 使用属性从已知的实体-属性对中识别一组实体; 对于实体集合中的每个实体
- 确定与实体关联的一组特征,其中属性的位置不包括属性
- 通过计算属性集合中特征的加权和来为实体生成分布属性嵌入
更准确的实体-属性关系相对于现有技术的基于模型的实体-属性识别的优势
早期艺术实体属性识别技术使用基于模型的方法,例如自然语言处理 (NLP) 特征、远程监督和传统机器学习模型,这些方法通过基于数据句子表示实体和属性来识别实体-属性关系。 这些术语出现。
相比之下,本规范中描述的创新通过使用有关实体和属性如何在出现这些术语的数据中表达的信息以及通过使用已知与之相关联的其他特征来表示实体和属性来识别数据集中的实体-属性关系这些条款。 这使得能够用相似实体共享的细节来表示实体和属性,从而提高识别实体-属性关系的准确性,否则这些关系无法通过考虑这些术语出现的句子来辨别。
例如,考虑一个场景,其中数据集包含具有两个实体的句子,“罗纳尔多”和“梅西”,使用“记录”属性进行描述,以及使用“目标”描述实体“梅西”的惩罚属性。 在这种情况下,现有技术可以识别以下实体属性对:(罗纳尔多,记录)、(梅西,日志)和(梅西,进球) 。 本规范中描述的创新超越了这些现有技术方法,通过识别可能无法通过这些术语在数据集中的使用方式来识别的实体-属性关系。
使用上面的例子,本说明书中描述的创新确定“C罗”和“梅西”是相似的实体,因为它们共享“记录”属性,然后使用“进球”属性表示“记录”属性。 以这种方式,例如,本说明书中描述的创新能够识别实体-属性关系,例如(Cristiano,Goals),即使这种关系可能无法从数据集中辨别。
识别属性关系专利
识别实体属性关系
发明人:丹伊特尔、肖宇、李方涛
受让人:谷歌有限责任公司
美国专利:11,263,400
授予:2022 年 3 月 1 日
提交日期:2019 年 7 月 5 日
抽象的
方法、系统和装置,包括在计算机存储介质上编码的计算机程序,可轻松识别文本语料库中的实体-属性关系。方法包括确定候选实体-属性对中的属性是否是实体-属性候选对中的实体的实际属性。这包括为包含实体和属性的句子集中的单词生成嵌入,并使用已知的实体-属性对生成。这还包括基于与来自已知实体-属性对的实体相关联的其他属性为实体生成属性分布嵌入,以及基于与已知实体中的属性的已知实体相关联的已知属性为属性生成属性分布嵌入。实体-属性对。基于这些嵌入,前馈网络确定实体-属性候选对中的属性是否是实体-属性候选对中实体的实际属性。
识别文本中的实体属性关系
候选实体-属性对(其中属性是实体的候选属性)被输入到分类模型。 分类模型使用路径嵌入引擎、分布表示引擎、属性引擎和前馈网络。 它确定候选实体-属性对中的属性是否是候选实体-属性对中的必要实体。
路径嵌入引擎生成一个向量,该向量表示连接数据集的一组句子(例如,30 个或更多句子)中实体和属性的日常出现的路径或词的嵌入。 分布式表示引擎基于这些术语出现在句子集中的上下文生成表示实体和属性术语嵌入的向量。 分布式属性引擎生成一个表示实体嵌入的向量和另一个表示属性嵌入的向量。
实体的属性分布引擎嵌入基于已知与数据集中的实体相关联的其他特征(即,候选属性以外的属性) 。 质量的详细分布引擎嵌入基于与候选属性的已知实体相关联的不同特征。
分类模型将来自路径嵌入引擎、分布表示引擎和分布属性引擎的向量表示连接成单个向量表示。 然后分类模型将单个向量表示输入到前馈网络中,该网络使用单个向量表示确定候选实体-属性对中的属性是否是候选实体-属性对中实体的本质属性。
假设前馈网络确定候选实体-属性对中的点对于候选实体-属性对中的实体是必要的。 在这种情况下,候选实体-属性对与其他已知/实际实体-属性对一起存储在知识库中。
提取实体属性关系
该环境包括分类模型,对于知识库中的候选实体-属性对,该分类模型确定候选实体-属性对中的属性是否是候选对中实体的本质属性。 分类模型是神经网络模型,组件描述如下。 分类模型也可以使用其他有监督和无监督机器学习模型。
可以包括存储在非暂时性数据存储介质(例如,硬盘驱动器、闪存等)中的数据库(或其他适当的数据存储结构)的知识库保存一组候选实体-属性对。 候选实体-属性对是使用从数据源获得的文本文档(例如网页和新闻文章)中的一组内容获得的。 数据源可以包括任何内容源,例如新闻网站、数据聚合平台、社交媒体平台等。
数据源从数据聚合平台获取新闻文章。 数据源可以使用模型。 监督或非监督机器学习模型(自然语言处理模型)通过从文章中提取句子并使用词性将提取的句子标记和标记为实体和属性来生成一组候选实体-属性对和依赖解析树标签。
数据源可以将提取的句子输入到机器学习模型中。 例如,它可以使用一组训练句子及其关联的实体属性对进行训练。 然后,这样的机器学习模型可以为输入提取的句子输出候选实体属性团队。
在知识库中,数据源存储候选实体-属性对和数据源提取的包含候选实体-属性对单词的句子。 只有存在实体和属性的句子数量满足(例如,满足或超过)句子的阈值数量(例如,30个句子)时,才将候选实体-属性对存储在知识库中。
分类模型确定候选实体-属性对中的属性(存储在知识库中)是否是候选实体-属性对中实体的实际属性。 分类模型包括路径嵌入引擎106、分布表示源、属性引擎和前馈网络。 如本文所用,术语引擎指的是执行一组任务的数据处理装置。 分类模型的这些引擎在确定候选实体-属性对中的属性是否是实体的本质属性时的操作。
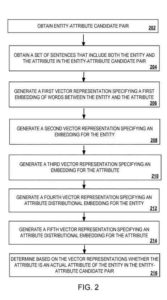
识别实体属性关系的示例过程
该过程的操作在下文描述为由系统的组件执行,并且该过程的功能在下文描述仅用于说明目的。 该过程的操作可以通过任何适当的设备或系统来完成,例如任何适用的数据处理装置。 该过程的功能也可以作为存储在非暂时性计算机可读介质上的指令来实现。 指令的执行导致数据处理设备执行处理的操作。
知识库从数据源中获取实体-属性候选对。
知识库从数据源中获取一组句子,其中包括实体的词和候选实体-属性对中的属性。
基于句子集合和候选实体-属性对,分类模型确定候选属性是否是候选实体的实际属性。 惩罚的集合可以是大量的句子,例如30个或更多的句子。
执行以下操作的分类模型
- 包含实体和属性的句子集中词的嵌入将在下面关于以下过程进行更详细的描述
- 使用已知的实体-属性对创建,实体的分布属性嵌入,下面将更详细地描述有关操作
- 构建,使用已知的实体-属性对和属性的分布属性嵌入,下面将更详细地描述操作
- 根据句子集中词的嵌入、实体的分布属性嵌入和属性的分布属性嵌入,选择实体-属性候选对中的属性是否是实体中实体的本质属性实体属性候选对,下面将更详细地描述操作。
路径嵌入引擎生成第一个向量表示,指定句子中实体和属性之间嵌入的第一个词。 路径嵌入引擎通过嵌入连接句子集中这些术语的日常出现的路径或单词来检测候选实体属性术语之间的关系。
对于短语“snake is a reptile”,路径嵌入引擎为轨道“is a”生成一个嵌入,可以用来检测例如属-种关系,然后可以用来识别其他实体-属性对。
在实体和属性之间生成单词
路径嵌入引擎执行以下操作以在句子中的实体和属性之间生成单词。 对于句子集中的每个句子,路径嵌入引擎首先提取实体和属性之间的依赖路径(指定一组词) 。 路径嵌入引擎将句子从字符串转换为列表,其中第一项是实体,最后一项是属性(或者,第一项是属性,前一项是实体) 。
依赖路径中的每个术语(也称为边)使用以下特征表示:术语的引理、词性标签、依赖标签和依赖路径的方向(左, 右或根) . 这些特征中的每一个都被嵌入并连接起来以产生术语或边 (V.sub.e) 的向量表示,它包含一系列向量 (V.sub.l, V.sub.pos, V.sub.dep , V.sub.dir),如下式所示: {右箭头在 (v)}.sub.e=[{右箭头在 (v)}.sub.l,{右箭头在 (v)} .sub.pos,{右箭头越过 (v)}.sub.dep,{右箭头越过 (v)}.sub.dir]
然后,路径嵌入引擎将每条路径中的术语或边的向量序列输入到长短期记忆 (LSTM) 网络中,该网络为句子 (V.sub.s) 生成单个向量表示,如下所示下面的等式: {右箭头在 (v)}.sub.s=LSTM({右箭头在 (v)}.sub.e.sup.(1) . . . {右箭头在 (v)}.sub .e.sup.(k))
最后,路径嵌入引擎将句子集中所有句子的单个向量表示输入到注意力机制中,该机制确定句子表示的加权平均值 (V.sub.sents(e,a)),如下面的等式: {右箭头在 (v)}.sub.sents(e,a)=ATTN({右箭头在 (v)}.sub.s.sup.(1) . . . {右箭头在 (v ) )}.sub.s.sup.(n))
分布表示模型基于句子生成实体的第二个向量表示和属性的第三个向量表示。 分布表示引擎基于上下文中的点和候选实体-属性对的实体在句子集中出现的上下文来检测候选实体-属性项之间的关系。 例如,分布式表示引擎可以确定实体“纽约”在句子集合中的使用方式表明该实体指的是美国的一个城市或州。
作为另一个示例,分布表示引擎可以确定属性“capital”在句子集中以暗示该属性指的是州或国家内的重要城市的方式被使用。 因此,分布式表示引擎使用实体出现的上下文(即句子集)生成一个向量表示,指定实体(V.sub.e)的嵌入。 分布式表示引擎生成一个向量表示(V.sub.a),使用出现该特征的句子集为该属性指定一个嵌入。
分布属性引擎使用已知的实体-属性对生成第四个向量表示,指定实体的分布属性嵌入。 存储在知识库中的已知实体-属性对是实体-属性对,已确认(例如,使用分类模型的先前处理或基于人工评估)实体中的每个属性-属性对是实体-属性对中实体的本质属性。
分布属性引擎执行以下操作以确定分布属性嵌入,该分布属性嵌入使用与该实体相关联的已知实体-属性对中的一些(例如,最常见的)或所有其他已知属性来指定实体的嵌入。
识别实体的其他属性
对于实体-属性候选对中的实体,分布属性引擎识别与已知实体-属性团队中的实体相关联的实体-属性候选对之外的属性。
对于候选实体-属性对(Michael Jordan, Famous)中的一个实体“Michael Jordan”,属性分布引擎可以使用Michael Jordan的已知实体-属性对,例如(Michael Jordan, richy)和(Michael Jordan,记录),以识别属性,例如 affluent 和 description 。
然后,属性分布引擎通过计算已识别已知属性的加权和(如前一段所述)为实体生成嵌入,其中权重通过注意力机制学习,如下面的等式所示:箭头 (v)}.sub.e=ATTN(.epsilon.(.alpha..sub.1) . . . .epsilon.(.alpha..sub.m))
分布属性引擎使用已知的实体-属性对生成第五个向量表示,指定属性的分布属性嵌入。 分布属性引擎执行以下操作以基于与候选属性的已知实体相关联的一些(无论是最常见的)或所有已知属性来确定模型。
对于实体-属性候选对中的点,分布属性引擎识别已知实体-属性对中具有质量的已知实体。
对于每个识别的已知实体,分布属性引擎识别与已知实体-属性团队中的实体相关联的其他属性(即,除了包含在实体-属性候选对中的属性之外的属性) 。 分布式属性引擎可以通过以下方式从已识别属性中识别属性子集:
(1)根据与每个实体关联的已知实体的数量对属性进行排名,例如为与更多实体关联的属性比与更少实体关联的属性分配更高的等级)
直接在您的收件箱中搜索新闻
*必需的