
Identificando Relações de Atributo de Entidade
Publicados: 2022-03-02Esta patente, concedida em 1º de março de 2022, trata da identificação de relacionamentos entidade-atributo em corpos de texto.
Aplicativos de busca, como mecanismos de busca e bases de conhecimento, tentam atender às necessidades informacionais de um pesquisador e mostrar os recursos mais vantajosos para o pesquisador .
Dados estruturados podem ajudar a identificar melhor os relacionamentos de atributos
A identificação de relacionamentos de entidade de atributos é feita em resultados de pesquisa estruturados.
Os resultados da pesquisa estruturada apresentam uma lista de atributos com respostas para uma entidade especificada em uma solicitação do usuário, como uma consulta .
Assim, os resultados da pesquisa estruturada para “Kevin Durant” podem incluir atributos como salário, equipe, ano de nascimento, família etc., além de respostas que fornecem informações sobre esses atributos .
A construção de tais resultados de pesquisa estruturados pode precisar identificar relações entidade-atributo.
Uma relação entidade-atributo é um caso particular de uma relação de texto entre um par de termos.
O primeiro termo do par de termos é uma entidade, uma pessoa, um lugar, uma organização ou um conceito.
O segundo termo é um atributo ou uma string que descreve um aspecto da entidade.
Exemplos incluem:
- “Data de nascimento” de uma pessoa
- “População” de um país
- “Salário” do atleta
- “CEO” de uma organização
Fornecer mais informações em conteúdo e esquema (e dados estruturados) sobre entidades fornece a um mecanismo de pesquisa mais informações para explorar melhor as informações sobre as entidades específicas, testar e coletar dados, desambiguar o que sabe e ter mais e melhor confiança sobre as entidades que está ciente.
Pares Candidatos Entidade-Atributo
Esta patente obtém um par candidato entidade-atributo para definir uma entidade e um atributo, onde o atributo é um atributo candidato da entidade . Além de aprender com fatos sobre entidades em dados estruturados, o Google pode usar informações observando o contexto dessas informações e aprender com vetores e coocorrência de outras palavras e fatos sobre essas entidades.
Dê uma olhada na patente de vetores de palavras para ter uma noção de como um mecanismo de busca pode agora ter uma melhor noção dos significados e contexto das palavras e informações sobre entidades. (Esta é uma chance de aprender com a exploração de patentes sobre como o Google está fazendo algumas das coisas que está fazendo.) O Google coleta fatos e dados sobre as coisas que indexa e pode aprender sobre as entidades que tem em seu índice e as atributos que conhece sobre eles.
Ele faz isso em:
- Determinar, com sentenças que incluem a entidade e o atributo, se o atributo é um atributo real da entidade no par candidato entidade-atributo
- Gerando embeddings para palavras no conjunto de frases que incluem a entidade e o atributo
- Criando, com pares entidade-atributo conhecidos, uma incorporação de atributo de distribuição para a entidade, onde a incorporação de atributo de distribuição para a entidade especifica uma incorporação para a entidade com base em outros atributos associados à entidade dos pares de entidade-atributo conhecidos
- Com base na incorporação de palavras nas frases, a incorporação de atributo de distribuição para a entidade e, para o atributo, se o par candidato entidade-atributo é um atributo essencial da entidade no par candidato entidade-atributo.
Incorporações para palavras são feitas de frases com a entidade e o atributo
Construindo uma primeira representação vetorial especificando a primeira incorporação de palavras entre a entidade e o ponto no conjunto de frases
- Fazendo uma segunda representação vetorial definindo uma incorporação dupla para a entidade com base no conjunto de frases
- Construindo uma terceira representação vetorial para uma terceira incorporação para o atributo com base no conjunto de sentenças
- Picking, com um atributo de entidade conhecido, combina uma incorporação de atributo de distribuição para a entidade, significa fazer uma quarta representação vetorial, usando pares entidade-atributo disponíveis, especificando a incorporação de atributo de distribuição para a entidade.
- Construir uma incorporação de atributo de distribuição com esses pares entidade-atributo conhecidos significa desenvolver uma quinta representação vetorial com equipes de atributo de entidade disponíveis e a incorporação de atributo de distribuição para o atributo .
- Decidir, com base nos embeddings para palavras no conjunto de sentenças, o embedding de atributo distribucional para a entidade e o embedding de atributo distribucional para o atributo, se o atributo no par candidato entidade-atributo é um atributo essencial da entidade no par candidato entidade-atributo
- Determinar, com base na primeira representação vetorial, na segunda representação vetorial, na terceira representação vetorial, na quarta representação vetorial e na quinta representação vetorial, se o atributo no par candidato entidade-atributo é um atributo essencial da entidade na entidade -atributo par candidato
- Escolhendo, a partir da primeira representação vetorial, a segunda representação vetorial, a terceira representação vetorial, a quarta representação vetorial e a quinta representação vetorial, se o atributo no par candidato entidade-atributo é um atributo essencial da entidade no par entidade-atributo. par candidato de atributo, são executados usando uma rede feedforward.
- Escolher, com base na primeira representação vetorial, na segunda representação vetorial, na terceira representação vetorial, na quarta representação vetorial e na quinta representação vetorial, se o atributo no par candidato entidade-atributo é um atributo essencial da entidade na entidade -par candidato de atributo, compreende:
- Gerar uma única representação vetorial concatenando a primeira representação vetorial, a segunda representação vetorial, a terceira representação vetorial, a quarta representação vetorial e a quinta representação vetorial; inserindo a representação de vetor único na rede feedforward
- Determinando, pela rede feedforward e usando a representação de vetor único, se o atributo no par candidato entidade-atributo é um atributo essencial da entidade no par candidato entidade-atributo
Fazer uma quarta representação vetorial, com pares entidade-atributo conhecidos, especificando a incorporação de atributo de distribuição para a entidade compreende:
- Identificando um conjunto de atributos associados à entidade nas equipes de entidade-atributo conhecidas, em que o conjunto de atributos omite o atributo
- Gerando uma incorporação de atributo de distribuição para a entidade calculando uma soma ponderada de características no conjunto de atributos
A escolha de uma quinta representação vetorial, com pares entidade-atributo conhecidos, especificando a incorporação de atributo de distribuição para o atributo compreende
- Identificar, usando o atributo, um conjunto de entidades dentre os pares entidade-atributo conhecidos; para cada entidade na coleção de entidades
- Determinando um conjunto de características associadas à entidade, onde a localização dos atributos não inclui o atributo
- Gerando uma incorporação de atributo de distribuição para a entidade calculando uma soma ponderada de características na coleção de atributos
A vantagem de relações entidade-atributo mais precisas sobre a identificação de entidade-atributo baseada em modelo da técnica anterior
Técnicas anteriores de identificação de entidade-atributo da arte usavam abordagens baseadas em modelo, como recursos de processamento de linguagem natural (NLP), supervisão à distância e modelos tradicionais de aprendizado de máquina, que identificam relações entidade-atributo representando entidades e atributos com base em sentenças de dados. Esses termos aparecem .
Em contraste, as inovações descritas nesta especificação identificam relações entidade-atributo em conjuntos de dados usando informações sobre como entidades e atributos são expressos nos dados em que esses termos aparecem e representando entidades e atributos usando outros recursos que são conhecidos por serem associados a estes termos . Isso permite representar entidades e atributos com detalhes compartilhados por entidades semelhantes, melhorando a precisão da identificação de relações entidade-atributo que, de outra forma, não podem ser discernidas considerando as sentenças nas quais esses termos aparecem .
Por exemplo, considere um cenário em que o conjunto de dados inclui sentenças que possuem duas entidades, “Ronaldo” e “Messi”, sendo descritas usando um atributo “record” e uma penalidade onde a entidade “Messi” é descrita usando um atributo “goals”. atributo . Nesse cenário, as técnicas do estado da técnica podem identificar os seguintes pares de atributos de entidade: (Ronaldo, registro), (Messi, log) e (Messi, objetivos) . As inovações descritas nesta especificação vão além dessas abordagens da técnica anterior, identificando relações entidade-atributo que podem não ser discernidas por como esses termos são usados no conjunto de dados .
Usando o exemplo acima, a inovação descrita nesta especificação determina que “Ronaldo” e “Messi” são entidades semelhantes porque compartilham o atributo “record” e então representam o atributo “record” usando o atributo “goals” . Dessa forma, as inovações descritas nesta especificação, por exemplo, podem permitir identificar relações entidade-atributo, por exemplo, (Cristiano, Objetivos), mesmo que tal relação possa não ser discernível a partir do conjunto de dados .
A Patente Identificando Relações de Atributos
Identificando relações de atributo de entidade
Inventores: Dan Iter, Xiao Yu e Fangtao Li
Responsável: Google LLC
Patente dos EUA: 11.263.400
Concedido: 1º de março de 2022
Arquivado: 5 de julho de 2019
Resumo
Métodos, sistemas e aparelhos, incluindo programas de computador codificados em um meio de armazenamento de computador, que facilitam a identificação de relacionamentos entidade-atributo em corpora de texto .Os métodos incluem determinar se um atributo em um par entidade-atributo candidato é um atributo real da entidade no par candidato entidade-atributo .Isso inclui gerar embeddings para palavras no conjunto de sentenças que incluem a entidade e o atributo e gerar, usando pares entidade-atributo conhecidos .Isso também inclui gerar uma incorporação de distribuição de atributo para a entidade com base em outros atributos associados à entidade dos pares entidade-atributo conhecidos e gerar uma incorporação de distribuição de atributo para o atributo com base em atributos conhecidos associados a entidades conhecidas do atributo no conhecido pares entidade-atributo .Com base nessas incorporações, uma rede feedforward determina se o atributo no par candidato entidade-atributo é um atributo real da entidade no par candidato entidade-atributo .
Identificando relacionamentos de atributo de entidade no texto
Um par entidade-atributo candidato (onde o atributo é um atributo candidato da entidade) é inserido em um modelo de classificação . O modelo de classificação usa um mecanismo de incorporação de caminho, um mecanismo de representação de distribuição, mecanismo de atributo e uma rede feedforward. Ele determina se o atributo no par entidade-atributo candidato é uma entidade essencial no par entidade-atributo candidato .
O mecanismo de incorporação de caminhos gera um vetor que representa uma incorporação dos caminhos ou palavras que conectam as ocorrências cotidianas da entidade e o atributo em um conjunto de sentenças (por exemplo, 30 ou mais sentenças) de um conjunto de dados . O mecanismo de representação distribucional gera vetores que representam uma incorporação para a entidade e atribui termos com base no contexto em que esses termos aparecem no conjunto de sentenças . O mecanismo de atributo de distribuição gera um vetor que representa uma incorporação para a entidade e outro vetor que representa uma incorporação para o atributo .
A incorporação do mecanismo de distribuição de atributos para a entidade é baseada em outros recursos (ou seja, atributos diferentes do atributo candidato) conhecidos por serem associados à entidade no conjunto de dados . A incorporação detalhada do mecanismo de distribuição para a qualidade é baseada em diferentes recursos associados a entidades conhecidas do atributo candidato .
O modelo de classificação concatena as representações vetoriais do mecanismo de incorporação de caminhos, o mecanismo de representação d istribucional e o mecanismo de atributo d istribucional em uma única representação vetorial. O modelo de classificação então insere a representação de vetor único em uma rede feedforward que determina, usando a representação de vetor único, se o atributo no par entidade-atributo candidato é um atributo essencial da entidade no par entidade-atributo candidato .
Suponha que a rede feedforward determine que o ponto no par entidade-atributo candidato é necessário para a entidade no par entidade-atributo candidato. Nesse caso, o par entidade-atributo candidato é armazenado na base de conhecimento junto com outros pares entidade-atributo conhecidos/reais .
Extraindo Relações de Atributo de Entidade
O ambiente inclui um modelo de classificação que, para pares entidade-atributo candidatos em uma base de conhecimento, determina se um atributo em um par entidade-atributo candidato é um atributo essencial da entidade no par candidato . O modelo de classificação é um modelo de rede neural e os componentes são descritos abaixo . O modelo de classificação também pode ser usado usando outros modelos de aprendizado de máquina supervisionados e não supervisionados .
A base de conhecimento, que pode incluir bancos de dados (ou outras estruturas de armazenamento de dados apropriadas) armazenadas em meios de armazenamento de dados não transitórios (por exemplo, disco(s) rígido(s), memória flash, etc.), contém um conjunto de pares entidade-atributo candidatos . Os pares entidade-atributo candidatos são obtidos usando um conjunto de conteúdo em documentos de texto, como páginas da Web e artigos de notícias, obtidos de uma fonte de dados. A Fonte de Dados pode incluir qualquer fonte de conteúdo, como um site de notícias, uma plataforma agregadora de dados, uma plataforma de mídia social etc.
A fonte de dados obtém artigos de notícias de uma plataforma agregadora de dados. A fonte de dados pode usar um modelo. O modelo de aprendizado de máquina supervisionado ou não supervisionado (um modelo de processamento de linguagem natural) gera um conjunto de pares entidade-atributo candidato extraindo frases dos artigos e tokenizando e rotulando as frases extraídas, por exemplo, como entidades e atributos, usando parte do discurso e tags de árvore de análise de dependência .
A fonte de dados pode inserir as frases extraídas em um modelo de aprendizado de máquina. Por exemplo, ele pode ser treinado usando um conjunto de sentenças de treinamento e seus pares entidade-atributo associados . Esse modelo de aprendizado de máquina pode gerar as equipes de atributo de entidade candidatas para as sentenças extraídas de entrada .
Na base de conhecimento, a fonte de dados armazena os pares entidade-atributo candidatas e as sentenças extraídas pela fonte de dados que incluem as palavras dos pares entidade-atributo candidatas . Os pares entidade-atributo candidatos só são armazenados na base de conhecimento se o número de sentenças em que a entidade e o atributo estão presentes satisfaz (por exemplo, atende ou excede) um número limite de sentenças (por exemplo, 30 sentenças) .
Um modelo de classificação determina se o atributo em um par entidade-atributo candidato (armazenado na base de conhecimento) é um atributo real da entidade no par entidade-atributo candidato . O modelo de classificação inclui um mecanismo de incorporação de caminho 106, uma fonte de representação de distribuição, um mecanismo de atributo e uma rede feedforward . Conforme usado neste documento, o termo mecanismo refere-se a um aparelho de processamento de dados que executa um conjunto de tarefas. As operações desses mecanismos do modelo de classificação determinam se o atributo em um par entidade-atributo candidato é um atributo essencial da entidade .
Um Processo de Exemplo para Identificar Relações de Atributos de Entidade
As operações do processo são descritas abaixo como sendo executadas pelos componentes do sistema e as funções do processo são descritas abaixo apenas para fins de ilustração. As operações do processo podem ser realizadas por qualquer dispositivo ou sistema apropriado, por exemplo, qualquer aparelho de processamento de dados aplicável . As funções do processo também podem ser implementadas como instruções armazenadas em um meio legível por computador não transitório . A execução das instruções faz com que o aparelho de processamento de dados execute as operações do processo .
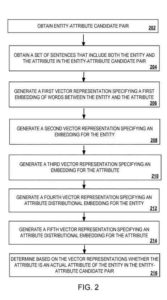
A base de conhecimento obtém um par candidato entidade-atributo da fonte de dados.
A base de conhecimento obtém um conjunto de sentenças da fonte de dados que inclui as palavras da entidade e o atributo no par entidade-atributo candidato .
Com base no conjunto de sentenças e no par entidade-atributo candidato, o modelo de classificação determina se o atributo candidato é um atributo real da entidade candidata . O conjunto de penalidades pode ser um grande número de sentenças, por exemplo, 30 ou mais sentenças.
O modelo de classificação realizando as seguintes operações
- Embeddings para palavras no conjunto de frases que incluem a entidade e o atributo são descritos em mais detalhes abaixo sobre o processo abaixo
- Criado usando pares entidade-atributo conhecidos, uma incorporação de atributo de distribuição para a entidade, que é descrita em mais detalhes abaixo sobre a operação
- Construção, usando os pares entidade-atributo conhecidos e incorporação de atributo de distribuição para o atributo, que é descrito em mais detalhes abaixo sobre a operação
- Escolher, com base nos embeddings para palavras no conjunto de sentenças, o embedding de atributo distribucional para a entidade e o embedding de atributo distribucional para o atributo, se o atributo no par candidato entidade-atributo é um atributo essencial da entidade no par candidato entidade-atributo, que é descrito em mais detalhes abaixo em relação à operação .
O mecanismo de incorporação de caminho gera uma primeira representação vetorial especificando as primeiras palavras incorporadas entre a entidade e o atributo nas frases . O mecanismo de incorporação de caminho detecta relacionamentos entre termos de atributo de entidade candidatos incorporando os caminhos ou as palavras que conectam as ocorrências cotidianas desses termos no conjunto de frases .
Para a frase “cobra é um réptil”, o mecanismo de incorporação de caminho gera uma incorporação para a trilha “é a”, que pode ser usada para detectar, por exemplo, relacionamentos gênero-espécie, que podem ser usados para identificar outros atributos de entidade pares .
Gerando as palavras entre a entidade e o atributo
O mecanismo de incorporação de caminho faz o seguinte para gerar palavras entre a entidade e o atributo nas frases . Para cada sentença no conjunto de sentenças, o mecanismo de incorporação de caminho primeiro extrai o caminho de dependência (que especifica um grupo de palavras) entre a entidade e o atributo . O mecanismo de incorporação de caminho converte a sentença de uma string para uma lista, onde o primeiro termo é a entidade e o último termo é o atributo (ou, o primeiro termo é o atributo e o termo anterior é a entidade) .
Cada termo (que também é chamado de aresta) no caminho de dependência é representado usando os seguintes recursos: o lema do termo, uma tag de parte do discurso, o rótulo de dependência e a direção do caminho de dependência (esquerda , direita ou raiz) . Cada um desses recursos é incorporado e concatenado para produzir uma representação vetorial para o termo ou aresta (V.sub.e), que compreende uma sequência de vetores (V.sub.l, V.sub.pos, V.sub.dep , V.sub.dir), conforme mostrado pela equação abaixo: {seta para a direita sobre (v)}.sub.e=[{seta para a direita sobre (v)}.sub.l,{seta para a direita sobre (v)} .sub.pos,{seta para a direita sobre (v)}.sub.dep,{seta para a direita sobre (v)}.sub.dir]
O mecanismo de incorporação de caminho então insere a sequência de vetores para os termos ou arestas em cada caminho em uma rede de memória de longo prazo (LSTM), que produz uma representação de vetor único para a sentença (V.sub.s), conforme mostrado por a equação abaixo: {seta para a direita sobre (v)}.sub.s=LSTM({seta para a direita sobre (v)}.sub.e.sup.(1) . . . {seta para a direita sobre (v)}.sub .e.sup.(k))
Finalmente, o mecanismo de incorporação de caminho insere a representação de vetor único para todas as sentenças no conjunto de sentenças em um mecanismo de atenção, que determina uma média ponderada das representações de sentença (V.sub.sents(e,a)), conforme mostrado pela equação abaixo: {seta para a direita sobre (v)}.sub.sents(e,a)=ATTN({seta para a direita sobre (v)}.sub.s.sup.(1) . . . {seta para a direita sobre (v) )}.sub.s.sup.(n))
O modelo representacional distribucional gera uma segunda representação vetorial para a entidade e uma terceira representação vetorial para o atributo com base nas sentenças . O mecanismo de representação distribucional detecta relacionamentos entre termos de entidade-atributo candidatos com base no contexto em que o ponto e a entidade do par de entidade-atributo candidato ocorrem no conjunto de sentenças . Por exemplo, o mecanismo de representação distributiva pode determinar que a entidade “Nova York” seja usada na coleção de sentenças de uma forma que sugira que essa entidade se refere a uma cidade ou estado nos Estados Unidos .
Como outro exemplo, o mecanismo de representação distribucional pode determinar que o atributo “capital” seja usado no conjunto de sentenças de forma a sugerir que esse atributo se refere a uma cidade significativa dentro de um estado ou país . Assim, o mecanismo de representação distribucional gera uma representação vetorial especificando uma incorporação para a entidade (V.sub.e) usando o contexto (ou seja, o conjunto de sentenças) dentro do qual a entidade aparece . O mecanismo de representação distribucional gera uma representação vetorial (V.sub.a) especificando uma incorporação para o atributo usando o conjunto de sentenças em que o recurso aparece .
O mecanismo de atributo de distribuição gera uma quarta representação vetorial especificando uma incorporação de atributo de distribuição para a entidade usando pares entidade-atributo conhecidos . Os pares entidade-atributo conhecidos, que são armazenados na base de conhecimento, são pares entidade-atributo para os quais foi confirmado (por exemplo, usando processamento prévio pelo modelo de classificação ou com base em uma avaliação humana) que cada atributo na entidade-atributo par de atributos é um atributo essencial da entidade no par entidade-atributo .
O mecanismo de atributo de distribuição executa as seguintes operações para determinar uma incorporação de atributo de distribuição que especifica uma incorporação para a entidade usando alguns (por exemplo, os mais comuns) ou todos os outros atributos conhecidos entre os pares entidade-atributo conhecidos com os quais essa entidade é associada .
Identificando outros atributos para entidades
Para entidades no par candidato entidade-atributo, o mecanismo de atributo de distribuição identifica outros atributos além daqueles incluídos no par candidato entidade-atributo associado à entidade nas equipes de atributo-entidade conhecidas .
Para uma entidade “Michael Jordan” no par entidade-atributo candidato (Michael Jordan, famoso), o mecanismo de distribuição de atributo pode usar os pares de entidade-atributo conhecidos para Michael Jordan, como (Michael Jordan, rico) e (Michael Jordan, registro), para identificar atributos como afluente e descrição .
O mecanismo de distribuição de atributos gera uma incorporação para a entidade calculando uma soma ponderada dos atributos conhecidos identificados (conforme descrito no parágrafo anterior), onde os pesos são aprendidos usando um mecanismo de atenção, conforme mostrado na equação abaixo: {direita seta sobre (v)}.sub.e=ATTN(.epsilon.(.alpha..sub.1) . . . .epsilon.(.alpha..sub.m))
O mecanismo de atributo de distribuição gera uma quinta representação vetorial especificando uma incorporação de atributo de distribuição para o atributo usando os pares entidade-atributo conhecidos . O mecanismo de atributo de distribuição executa as seguintes operações para determinar um modelo com base em alguns (se os mais comuns) ou em todos os atributos conhecidos associados a entidades conhecidas do atributo candidato .
Para o ponto no par candidato entidade-atributo, o mecanismo de atributo de distribuição identifica as entidades conhecidas entre os pares entidade-atributo conhecidos que têm a qualidade .
Para cada entidade conhecida identificada, o mecanismo de atributo de distribuição identifica outros atributos (ou seja, atributos diferentes daquele incluído no par candidato entidade-atributo) associados à entidade nas equipes de entidade-atributo conhecidas . O mecanismo de atributo de distribuição pode identificar um subconjunto de atributos entre os atributos identificados por:
(1) Classificar atributos com base no número de entidades conhecidas associadas a cada entidade, como atribuir uma classificação mais alta a atributos associados a um número maior de entidades do que aqueles associados a menos entidades)
Pesquisar notícias diretamente na sua caixa de entrada
*Requerido