
Identificación de relaciones de atributos de entidad
Publicado: 2022-03-02Esta patente, concedida el 1 de marzo de 2022, se trata de identificar relaciones entidad-atributo en cuerpos de texto.
Las aplicaciones de búsqueda, como los motores de búsqueda y las bases de conocimiento, intentan satisfacer las necesidades de información de un buscador y mostrar los recursos más ventajosos para el buscador .
Los datos estructurados pueden ayudar a identificar mejor las relaciones de atributos
La identificación de las relaciones entre atributos y entidades se realiza en resultados de búsqueda estructurados.
Los resultados de búsqueda estructurados presentan una lista de atributos con respuestas para una entidad especificada en una solicitud de usuario, como una consulta .
Por lo tanto, los resultados de búsqueda estructurados para "Kevin Durant" pueden incluir atributos como salario, equipo, año de nacimiento, familia, etc., junto con respuestas que brindan información sobre estos atributos .
La construcción de tales resultados de búsqueda estructurados puede necesitar la identificación de relaciones entidad-atributo.
Una relación entidad-atributo es un caso particular de una relación textual entre un par de términos.
El primer término del par de términos es una entidad, una persona, un lugar, una organización o un concepto.
El segundo término es un atributo o una cadena que describe un aspecto de la entidad.
Ejemplos incluyen:
- “Fecha de nacimiento” de una persona
- “Población” de un país
- “Salario” del deportista
- “CEO” de una organización
Proporcionar más información en contenido y esquema (y datos estructurados) sobre las entidades le da a un motor de búsqueda más información para explorar mejor información sobre las entidades específicas, probar y recopilar datos, desambiguar lo que sabe y tener más y mejor confianza sobre las entidades que es consciente de.
Pares de candidatos de atributo de entidad
Esta patente obtiene un par candidato entidad-atributo para definir una entidad y un atributo, donde el atributo es un atributo candidato de la entidad . Además de aprender de hechos sobre entidades en datos estructurados, Google puede usar información observando el contexto de esa información y aprender de vectores y la co-ocurrencia de otras palabras y hechos sobre esas entidades también.
Eche un vistazo a la patente de vectores de palabras para tener una idea de cómo un motor de búsqueda ahora puede tener una mejor idea de los significados y el contexto de las palabras y la información sobre las entidades. (Esta es una oportunidad de aprender de la exploración de patentes sobre cómo Google ahora está haciendo algunas de las cosas que está haciendo). Google recopila hechos y datos sobre las cosas que indexa y puede aprender sobre las entidades que tiene en su índice, y el atributos que conoce sobre ellos.
Hace esto en:
- Determinar, con oraciones que incluyen la entidad y el atributo, si el atributo es un atributo real de la entidad en el par candidato entidad-atributo
- Generar incrustaciones de palabras en el conjunto de oraciones que incluyen la entidad y el atributo
- Crear, con pares de atributo-entidad conocidos, una incorporación de atributos de distribución para la entidad, donde la incorporación de atributos de distribución para la entidad especifica una incorporación para la entidad basada en otros atributos asociados con la entidad de los pares de atributo-entidad conocidos
- Sobre la base de incrustaciones de palabras en las oraciones, la incrustación de atributos de distribución para la entidad, y para el atributo, si el par candidato entidad-atributo es un atributo esencial de la entidad en el par candidato entidad-atributo.
Las incrustaciones de palabras se hacen de oraciones con la entidad y el atributo
Construir una primera representación vectorial especificando la primera incrustación de palabras entre la entidad y el punto en el conjunto de oraciones
- Haciendo una segunda representación vectorial definiendo una doble incrustación para la entidad basada en el conjunto de oraciones
- Construcción de una tercera representación vectorial para una tercera incrustación del atributo basada en el conjunto de oraciones
- Elegir, con un atributo de entidad conocido, combina una incorporación de atributos de distribución para la entidad, significa hacer una cuarta representación vectorial, utilizando pares de atributo-entidad disponibles, especificando la incorporación de atributos de distribución para la entidad.
- Construir un atributo de distribución incrustado con esos pares conocidos de entidad-atributo significa desarrollar una quinta representación vectorial con equipos de entidad-atributo disponibles y el atributo de distribución incrustado para el atributo .
- Decidir, con base en las incorporaciones de palabras en el conjunto de oraciones, la incorporación de atributos distributivos para la entidad y la incorporación de atributos distributivos para el atributo, si el atributo en el par candidato entidad-atributo es un atributo esencial de la entidad en el par de candidatos entidad-atributo
- Determinar, con base en la primera representación vectorial, la segunda representación vectorial, la tercera representación vectorial, la cuarta representación vectorial y la quinta representación vectorial, si el atributo en el par candidato entidad-atributo es un atributo esencial de la entidad en la entidad -atributo par de candidatos
- Elegir, a partir de la primera representación vectorial, la segunda representación vectorial, la tercera representación vectorial, la cuarta representación vectorial y la quinta representación vectorial, si el atributo en el par candidato entidad-atributo es un atributo esencial de la entidad en la entidad- par de candidatos de atributo, se realiza utilizando una red de realimentación.
- Seleccionar, en función de la primera representación vectorial, la segunda representación vectorial, la tercera representación vectorial, la cuarta representación vectorial y la quinta representación vectorial, si el atributo en el par candidato entidad-atributo es un atributo esencial de la entidad en la entidad -atributo par candidato, comprende:
- Generar una sola representación vectorial concatenando la primera representación vectorial, la segunda representación vectorial, la tercera representación vectorial, la cuarta representación vectorial y la quinta representación vectorial; ingresando la representación de un solo vector en la red feedforward
- Determinar, mediante la red feedforward y usando la representación de un solo vector, si el atributo en el par candidato entidad-atributo es un atributo esencial de la entidad en el par candidato entidad-atributo
Hacer una cuarta representación vectorial, con pares conocidos de entidad-atributo, especificando la incrustación del atributo distribucional para la entidad comprende:
- Identificar un conjunto de atributos asociados con la entidad en los equipos conocidos entidad-atributo, donde el conjunto de atributos omite el atributo
- Generar una incrustación de atributos de distribución para la entidad mediante el cálculo de una suma ponderada de características en el conjunto de atributos
Elegir una quinta representación vectorial, con pares conocidos de entidad-atributo, especificando el atributo de distribución incorporado para el atributo comprende
- Identificar, utilizando el atributo, un conjunto de entidades de entre las parejas entidad-atributo conocidas; para cada entidad en la colección de entidades
- Determinar un conjunto de características asociadas con la entidad, donde la ubicación de los atributos no incluye el atributo
- Generar una incorporación de atributos de distribución para la entidad mediante el cálculo de una suma ponderada de características en la colección de atributos
La ventaja de relaciones entidad-atributo más precisas sobre la identificación de entidad-atributo basada en modelos de la técnica anterior
Las técnicas de identificación de atributos de entidades anteriores utilizaban enfoques basados en modelos, como funciones de procesamiento de lenguaje natural (NLP), supervisión a distancia y modelos tradicionales de aprendizaje automático, que identifican relaciones de atributos de entidades mediante la representación de entidades y atributos basados en oraciones de datos. Aparecen estos términos .
Por el contrario, las innovaciones descritas en esta especificación identifican las relaciones entidad-atributo en conjuntos de datos mediante el uso de información sobre cómo se expresan las entidades y los atributos en los datos en los que aparecen estos términos y mediante la representación de entidades y atributos mediante otras características que se conocen para asociarse con ellas. estos términos Esto permite representar entidades y atributos con detalles compartidos por entidades similares, lo que mejora la precisión de la identificación de las relaciones entidad-atributo que, de otro modo, no se pueden discernir al considerar las oraciones en las que aparecen estos términos .
Por ejemplo, considere un escenario en el que el conjunto de datos incluye oraciones que tienen dos entidades, "Ronaldo" y "Messi", que se describen con un atributo de "registro" y una sanción en la que la entidad "Messi" se escribe con "goles". atributo _ En tal escenario, las técnicas de la técnica anterior pueden identificar los siguientes pares de atributos de entidad: (Ronaldo, registro), (Messi, registro) y (Messi, goles) . Las innovaciones descritas en esta especificación van más allá de estos enfoques de la técnica anterior al identificar relaciones entidad-atributo que podrían no discernirse por cómo se usan estos términos en el conjunto de datos .
Usando el ejemplo anterior, la innovación descrita en esta especificación determina que "Ronaldo" y "Messi" son entidades similares porque comparten el atributo "récord" y luego representan el atributo "récord" usando el atributo "goles" . De esta manera, las innovaciones descritas en esta especificación, por ejemplo, pueden permitir identificar relaciones entidad-atributo, por ejemplo, (Cristiano, Metas), aunque tal relación no sea discernible del conjunto de datos .
La patente de relaciones de atributos de identificación
Identificación de relaciones de atributos de entidad
Inventores: Dan Iter, Xiao Yu y Fangtao Li
Cesionario: Google LLC
Patente de EE. UU.: 11,263,400
Concedido: 1 de marzo de 2022
Archivado: 5 de julio de 2019
Resumen
Métodos, sistemas y aparatos, incluidos los programas informáticos codificados en un medio de almacenamiento informático, que facilitan la identificación de las relaciones entidad-atributo en corpus de texto .Los métodos incluyen determinar si un atributo en un par candidato entidad-atributo es un atributo real de la entidad en el par candidato entidad-atributo .Esto incluye generar incrustaciones de palabras en el conjunto de oraciones que incluyen la entidad y el atributo y generar, utilizando pares conocidos de entidad-atributo .Esto también incluye generar una incrustación de distribución de atributos para la entidad basada en otros atributos asociados con la entidad de los pares conocidos de entidad-atributo, y generar una incrustación de distribución de atributos para el atributo basada en atributos conocidos asociados con entidades conocidas del atributo en el conocido. pares entidad-atributo .Sobre la base de estas incrustaciones, una red feedforward determina si el atributo en el par candidato entidad-atributo es un atributo real de la entidad en el par candidato entidad-atributo .
Identificación de relaciones de atributos de entidad en texto
Un par candidato de entidad-atributo (donde el atributo es un candidato de atributo de entidad) se ingresa a un modelo de clasificación . El modelo de clasificación utiliza un motor de incrustación de rutas, un motor de representación distribucional, un motor de atributos y una red de avance. Determina si el atributo en el par candidato entidad-atributo es una entidad esencial en el par candidato entidad-atributo .
El motor de incrustación de rutas genera un vector que representa una incrustación de las rutas o las palabras que conectan las ocurrencias cotidianas de la entidad y el atributo en un conjunto de oraciones (por ejemplo, 30 o más oraciones) de un conjunto de datos . El motor de representación distribucional genera vectores que representan una incrustación para la entidad y atributos de términos basados en el contexto dentro del cual estos términos aparecen en el conjunto de oraciones . El motor de atributos de distribución genera un vector que representa una incorporación para la entidad y otro vector que representa una incorporación para el atributo .
La incrustación del motor de distribución de atributos para la entidad se basa en otras características (es decir, atributos distintos del atributo candidato) que se sabe que se asocian con la entidad en el conjunto de datos . La incorporación del motor de distribución detallado para la calidad se basa en diferentes características asociadas con entidades conocidas del atributo candidato .
El modelo de clasificación concatena las representaciones vectoriales del motor de incrustación de rutas, el motor de representación distribucional y el motor de atributos distribucionales en una única representación vectorial. Luego, el modelo de clasificación ingresa la representación de un solo vector en una red de avance que determina, usando la representación de un solo vector, si el atributo en el par candidato entidad-atributo es un atributo esencial de la entidad en el par candidato entidad-atributo .
Supongamos que la red feedforward determina que el punto en el par candidato entidad-atributo es necesario para la entidad en el par candidato entidad-atributo. En ese caso, el par candidato entidad-atributo se almacena en la base de conocimiento junto con otros pares entidad-atributo conocidos/reales .
Extracción de relaciones de atributos de entidad
El entorno incluye un modelo de clasificación que, para pares de atributos-entidad candidatos en una base de conocimiento, determina si un atributo en un par atributo-entidad candidato es un atributo esencial de la entidad en el par candidato . El modelo de clasificación es un modelo de red neuronal y los componentes se describen a continuación . El modelo de clasificación también se puede utilizar con otros modelos de aprendizaje automático supervisados y no supervisados .
La base de conocimientos, que puede incluir bases de datos (u otras estructuras de almacenamiento de datos apropiadas) almacenadas en medios de almacenamiento de datos no transitorios (por ejemplo, discos duros, memoria flash, etc.), contiene un conjunto de pares de entidad-atributo candidatos . Los pares de entidad-atributo candidatos se obtienen utilizando un conjunto de contenido en documentos de texto, como páginas web y artículos de noticias, obtenidos de una fuente de datos. La fuente de datos puede incluir cualquier fuente de contenido, como un sitio web de noticias, una plataforma de agregación de datos, una plataforma de redes sociales, etc.
La fuente de datos obtiene artículos de noticias de una plataforma de agregación de datos. La fuente de datos puede utilizar un modelo. El modelo de aprendizaje automático supervisado o no supervisado (un modelo de procesamiento de lenguaje natural) genera un conjunto de pares de entidad-atributo candidatos al extraer oraciones de los artículos y tokenizar y etiquetar las oraciones extraídas, por ejemplo, como entidades y atributos, utilizando parte del discurso. y etiquetas de árbol de análisis de dependencia .
La fuente de datos puede ingresar las oraciones extraídas en un modelo de aprendizaje automático. Por ejemplo, se puede entrenar usando un conjunto de oraciones de entrenamiento y sus pares de atributo de entidad asociados . Dicho modelo de aprendizaje automático puede generar los equipos de atributo de entidad candidatos para las oraciones extraídas de entrada .
En la base de conocimiento, la fuente de datos almacena los pares de entidad-atributo candidatos y las oraciones extraídas por la fuente de datos que incluyen las palabras de los pares de entidad-atributo candidatos . Los pares candidatos de entidad-atributo solo se almacenan en la base de conocimientos si el número de oraciones en las que están presentes la entidad y el atributo satisface (p. ej., alcanza o supera) un número umbral de oraciones (p. ej., 30 oraciones) .
Un modelo de clasificación determina si el atributo en un par candidato entidad-atributo (almacenado en la base de conocimiento) es un atributo real de la entidad en el par candidato entidad-atributo . El modelo de clasificación incluye un motor 106 de incrustación de rutas, una fuente de representación de distribución, un motor de atributos y una red de avance . Como se usa aquí, el término motor se refiere a un aparato de procesamiento de datos que realiza un conjunto de tareas. Las operaciones de estos motores del modelo de clasificación para determinar si el atributo en un par candidato entidad-atributo es un atributo esencial de la entidad .
Un ejemplo de proceso para identificar relaciones de atributos de entidades
Las operaciones del proceso se describen a continuación como realizadas por los componentes del sistema, y las funciones del proceso se describen a continuación solo con fines ilustrativos. Las operaciones del proceso pueden lograrse mediante cualquier dispositivo o sistema apropiado, por ejemplo, cualquier aparato de procesamiento de datos aplicable . Las funciones del proceso también pueden implementarse como instrucciones almacenadas en un medio legible por computadora no transitorio . La ejecución de las instrucciones hace que el aparato de procesamiento de datos realice operaciones del proceso .
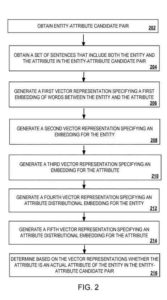
La base de conocimiento obtiene un par de candidatos entidad-atributo de la fuente de datos.
La base de conocimientos obtiene un conjunto de oraciones de la fuente de datos que incluyen las palabras de la entidad y el atributo en el par candidato entidad-atributo .
Con base en el conjunto de oraciones y el par entidad candidata-atributo, el modelo de clasificación determina si el atributo candidato es un atributo real de la entidad candidata . El conjunto de sanciones puede ser un gran número de sentencias, por ejemplo, 30 o más sentencias.
El modelo de clasificación realizando las siguientes operaciones
- Las incrustaciones de palabras en el conjunto de oraciones que incluyen la entidad y el atributo se describen con mayor detalle a continuación en relación con el proceso a continuación.
- Creado utilizando pares de atributos de entidad conocidos, un atributo de distribución incrustado para la entidad, que se describe con mayor detalle a continuación en relación con la operación
- Construir, usando los pares de atributo-entidad conocidos y la incrustación de atributo de distribución para el atributo, que se describe con mayor detalle a continuación en relación con la operación
- Elegir, con base en las incrustaciones de palabras en el conjunto de oraciones, la incrustación de atributos distributivos para la entidad y la incrustación de atributos distributivos para el atributo, si el atributo en el par candidato entidad-atributo es un atributo esencial de la entidad en el par de candidatos entidad-atributo, que se describe con mayor detalle a continuación en relación con la operación .
El motor de incrustación de rutas genera una primera representación vectorial que especifica las primeras palabras incrustadas entre la entidad y el atributo en las oraciones . El motor de incrustación de rutas detecta las relaciones entre los términos de atributo de entidad candidatos incorporando las rutas o las palabras que conectan las apariciones cotidianas de estos términos en el conjunto de oraciones .
Para la frase "serpiente es un reptil", el motor de incrustación de ruta genera una incrustación para la pista "es un", que puede usarse para detectar, por ejemplo, relaciones de género y especie, que luego pueden usarse para identificar otra entidad-atributo parejas _
Generación de las palabras entre la entidad y el atributo
El motor de incrustación de rutas hace lo siguiente para generar palabras entre la entidad y el atributo en las oraciones . Para cada oración del conjunto de oraciones, el motor de incrustación de rutas primero extrae la ruta de dependencia (que especifica un grupo de palabras) entre la entidad y el atributo . El motor de incrustación de rutas convierte la oración de una cadena a una lista, donde el primer término es la entidad y el último término es el atributo (o el primer término es el atributo y el término anterior es la entidad) .
Cada término (que también se denomina borde) en la ruta de dependencia se representa mediante las siguientes características: el lema del término, una etiqueta de parte del discurso, la etiqueta de dependencia y la dirección de la ruta de dependencia (izquierda , derecha o raíz) . Cada una de estas características se incrusta y se concatena para producir una representación vectorial para el término o borde (V.sub.e), que comprende una secuencia de vectores (V.sub.l, V.sub.pos, V.sub.dep , V.sub.dir), como se muestra en la siguiente ecuación: {flecha derecha sobre (v)}.sub.e=[{flecha derecha sobre (v)}.sub.l,{flecha derecha sobre (v)} .sub.pos,{flecha derecha sobre (v)}.sub.dep,{flecha derecha sobre (v)}.sub.dir]
El motor de incrustación de rutas luego ingresa la secuencia de vectores para los términos o aristas en cada ruta en una red de memoria a corto plazo (LSTM), que produce una representación vectorial única para la oración (V.sub.s), como se muestra por la siguiente ecuación: {flecha derecha sobre (v)}.sub.s=LSTM({flecha derecha sobre (v)}.sub.e.sup.(1) . . . {flecha derecha sobre (v)}.sub .e.sup.(k))
Finalmente, el motor de incrustación de rutas ingresa la representación de vector único para todas las oraciones en el conjunto de oraciones en un mecanismo de atención, que determina una media ponderada de las representaciones de oraciones (V.sub.sents (e,a)), como lo muestra el siguiente ecuación: {flecha derecha sobre (v)}.sub.sents(e,a)=ATTN({flecha derecha sobre (v)}.sub.s.sup.(1) . . . {flecha derecha sobre (v) )}.sub.s.sup.(n))
El modelo de representación distribucional genera una segunda representación vectorial para la entidad y una tercera representación vectorial para el atributo en base a las oraciones . El motor de representación distribucional detecta las relaciones entre los términos candidatos de entidad-atributo en función del contexto en el que el punto y la entidad del par candidato de entidad-atributo aparecen en el conjunto de oraciones . Por ejemplo, el motor de representación distribucional puede determinar que la entidad "Nueva York" se utilice en la recopilación de oraciones de una manera que sugiera que esta entidad se refiere a una ciudad o estado en los Estados Unidos .
Como otro ejemplo, el motor de representación distribucional puede determinar que el atributo "capital" se use en el conjunto de oraciones de una manera que sugiera que este atributo se refiere a una ciudad importante dentro de un estado o país . Por lo tanto, el motor de representación distribucional genera una representación vectorial que especifica una incrustación para la entidad (V.sub.e) usando el contexto (es decir, el conjunto de oraciones) dentro del cual aparece la entidad . El motor de representación distribucional genera una representación vectorial (V.sub.a) que especifica una incrustación para el atributo utilizando el conjunto de oraciones en las que aparece la característica .
El motor de atributos de distribución genera una cuarta representación vectorial que especifica una incrustación de atributos de distribución para la entidad utilizando pares de atributos de entidad conocidos . Los pares conocidos de entidad-atributo, que se almacenan en la base de conocimiento, son pares de entidad-atributo para los cuales se ha confirmado (p. ej., usando un procesamiento previo por el modelo de clasificación o basado en una evaluación humana) que cada atributo en la entidad- El par de atributos es un atributo esencial de la entidad en el par entidad-atributo .
El motor de atributos de distribución realiza las siguientes operaciones para determinar una incrustación de atributo de distribución que especifica una incrustación para la entidad utilizando algunos (por ejemplo, los más comunes) o todos los demás atributos conocidos entre los pares de atributo-entidad conocidos con los que se asocia esa entidad .
Identificación de otros atributos para entidades
Para las entidades en el par de candidatos entidad-atributo, el motor de atributos de distribución identifica atributos distintos a los incluidos en el par candidato de entidad-atributo asociados con la entidad en los equipos conocidos de entidad-atributo .
Para una entidad "Michael Jordan" en el par candidato entidad-atributo (Michael Jordan, famoso), el motor de distribución de atributos puede usar los pares de entidad-atributo conocidos para Michael Jordan, como (Michael Jordan, rico) y (Michael Jordan, record), para identificar atributos como afluente y descripción .
El motor de distribución de atributos luego genera una incrustación para la entidad al calcular una suma ponderada de los atributos conocidos identificados (como se describe en el párrafo anterior), donde los pesos se aprenden mediante un mecanismo de atención, como se muestra en la siguiente ecuación: {right flecha sobre (v)}.sub.e=ATTN(.epsilon.(.alpha..sub.1) . . . .epsilon.(.alpha..sub.m))
El motor de atributos de distribución genera una quinta representación vectorial que especifica un atributo de distribución incrustado para el atributo utilizando los pares conocidos de entidad-atributo . El motor de atributos de distribución realiza las siguientes operaciones para determinar un modelo basado en algunos (ya sea el más común) o todos los atributos conocidos asociados con entidades conocidas del atributo candidato .
Para el punto en el par candidato entidad-atributo, el motor de atributos distributivos identifica las entidades conocidas entre las parejas conocidas entidad-atributo que tienen la calidad .
Para cada entidad conocida identificada, el motor de atributos de distribución identifica otros atributos (es decir, atributos distintos del incluido en el par candidato entidad-atributo) asociados con la entidad en los equipos de entidad-atributo conocido . El motor de atributos de distribución puede identificar un subconjunto de atributos entre los atributos identificados mediante:
(1) Clasificar atributos en función del número de entidades conocidas asociadas con cada entidad, como asignar un rango más alto a los atributos asociados con un mayor número de entidades que a los asociados con menos entidades)
Busque noticias directamente en su bandeja de entrada
*Requerido