
Идентификация отношений атрибутов сущностей
Опубликовано: 2022-03-02Этот патент, выданный 1 марта 2022 г., касается идентификации отношений объект-атрибут в тексте.
Поисковые приложения, такие как поисковые системы и базы знаний, стараются удовлетворить информационные потребности искателя и показать ему наиболее выгодные ресурсы .
Структурированные данные могут помочь лучше идентифицировать отношения атрибутов
Идентификация отношений сущностей атрибутов выполняется в структурированных результатах поиска.
Структурированные результаты поиска представляют собой список атрибутов с ответами для сущности, указанной в запросе пользователя, например запросе .
Так, структурированные результаты поиска по запросу «Кевин Дюрант» могут включать в себя такие атрибуты, как зарплата, команда, год рождения, семья и т. д., а также ответы, предоставляющие информацию об этих атрибутах .
Для построения таких структурированных результатов поиска может потребоваться определение отношений объект-атрибут.
Отношение объект-атрибут — это частный случай текстового отношения между парой терминов.
Первый термин в паре терминов — это объект, лицо, место, организация или концепция.
Второй термин — это атрибут или строка, описывающая аспект сущности.
Примеры включают:
- «Дата рождения» человека
- «Население» страны
- «Зарплата» спортсмена
- «генеральный директор» организации
Предоставление большего количества информации в содержании и схеме (и структурированных данных) о сущностях дает поисковой системе больше информации, чтобы лучше изучить информацию о конкретных сущностях, протестировать и собрать данные, устранить неоднозначность того, что ей известно, и иметь больше и больше уверенности в сущностях, которые это известно.
Пары кандидатов сущность-атрибут
Этот патент получает пару кандидатов объект-атрибут для определения объекта и атрибута, где атрибут является потенциальным атрибутом объекта . Помимо изучения фактов о сущностях в структурированных данных, Google может использовать информацию, изучая контекст этой информации, а также извлекать уроки из векторов и совпадений других слов и фактов об этих сущностях.
Взгляните на патент на вектор слов, чтобы понять, как поисковая система теперь может лучше понимать значения и контекст слов и информацию о сущностях. (Это возможность узнать из патентных исследований о том, как Google сейчас делает некоторые вещи, которые он делает.) Google собирает факты и данные о том, что он индексирует, и может узнать о объектах, которые он имеет в своем индексе, и атрибуты, о которых он знает.
Он делает это в:
- Определение с помощью предложений, включающих сущность и атрибут, является ли атрибут фактическим атрибутом сущности в паре кандидатов сущность-атрибут.
- Создание вложений для слов в наборе предложений, включающих сущность и атрибут
- Создание с известными парами объект-атрибут внедрения атрибута распределения для объекта, где внедрение атрибута распределения для объекта указывает внедрение объекта на основе других атрибутов, связанных с объектом из известных пар объект-атрибут
- На основе вложений слов в предложениях, внедрения атрибута распределения для объекта и для атрибута, является ли пара кандидатов объект-атрибут существенным атрибутом объекта в паре кандидатов объект-атрибут.
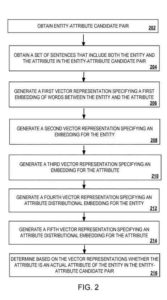
Вложения для слов получаются из предложений с сущностью и атрибутом
Построение первого векторного представления, указывающего первое вложение слов между сущностью и точкой в наборе предложений
- Создание второго векторного представления, определяющего двойное вложение для объекта на основе набора предложений
- Построение третьего векторного представления для третьего вложения атрибута на основе набора предложений
- Выбор с известным атрибутом объекта объединяет внедрение атрибута распределения для объекта, что означает создание четвертого векторного представления с использованием доступных пар объект-атрибут, определяющее внедрение атрибута распределения для объекта.
- Построение встраивания атрибута распределения с этими известными парами сущность-атрибут означает разработку пятого векторного представления с доступными командами сущность-атрибут и внедрением атрибута распределения для атрибута .
- Решение, основанное на вложениях слов в наборе предложений, встраивании атрибута распределения для сущности и встраивании атрибута распределения для атрибута, является ли атрибут в паре кандидатов сущность-атрибут существенным атрибутом сущности в пара кандидатов сущность-атрибут
- Определение на основе первого векторного представления, второго векторного представления, третьего векторного представления, четвертого векторного представления и пятого векторного представления того, является ли атрибут в паре кандидатов объект-атрибут существенным атрибутом объекта в объекте -атрибутная пара кандидатов
- Выбор из первого векторного представления, второго векторного представления, третьего векторного представления, четвертого векторного представления и пятого векторного представления того, является ли атрибут в паре кандидатов объект-атрибут существенным атрибутом объекта в объекте- пару атрибутов-кандидатов, выполняемых с использованием сети прямой связи.
- Выбор на основе первого векторного представления, второго векторного представления, третьего векторного представления, четвертого векторного представления и пятого векторного представления того, является ли атрибут в паре кандидатов объект-атрибут существенным атрибутом объекта в объекте -пара кандидатов атрибутов, включает:
- Генерирование одного векторного представления путем объединения первого векторного представления, второго векторного представления, третьего векторного представления, четвертого векторного представления и пятого векторного представления; ввод одного векторного представления в сеть прямой связи
- Определение с помощью сети прямой связи и с использованием представления с одним вектором того, является ли атрибут в паре кандидатов объект-атрибут существенным атрибутом объекта в паре кандидатов объект-атрибут
Создание четвертого векторного представления с известными парами объект-атрибут, определяющее внедрение атрибута распределения для объекта, включает:
- Идентификация набора атрибутов, связанных с объектом в известных командах атрибутов объекта, при этом в наборе атрибутов отсутствует атрибут
- Генерация внедрения атрибута распределения для объекта путем вычисления взвешенной суммы характеристик в наборе атрибутов
Выбор пятого векторного представления с известными парами объект-атрибут, определяющий внедрение атрибута распределения для атрибута, включает
- Идентификация с помощью атрибута набора сущностей из числа известных пар сущность-атрибут; для каждой сущности в коллекции сущностей
- Определение набора функций, связанных с сущностью, где расположение атрибутов не включает атрибут
- Генерация внедрения атрибута распределения для объекта путем вычисления взвешенной суммы характеристик в наборе атрибутов
Преимущество более точных взаимосвязей объект-атрибут по сравнению с предшествующей идентификацией объекта-атрибута на основе модели
В более ранних методах идентификации атрибутов объекта использовались подходы на основе моделей, такие как функции обработки естественного языка (NLP), дистанционное наблюдение и традиционные модели машинного обучения, которые идентифицируют отношения объект-атрибут путем представления объектов и атрибутов на основе предложений данных. Появляются эти термины .
Напротив, инновации, описанные в этой спецификации, идентифицируют отношения объект-атрибут в наборах данных, используя информацию о том, как объекты и атрибуты выражаются в данных, в которых появляются эти термины, и путем представления объектов и атрибутов с использованием других функций, которые, как известно, связаны с эти термины . Это позволяет представлять сущности и атрибуты с деталями, общими для подобных сущностей, повышая точность идентификации отношений сущность-атрибут, которые в противном случае невозможно различить, рассматривая предложения, в которых появляются эти термины .
Например, рассмотрим сценарий, в котором набор данных включает предложения с двумя сущностями, «Роналдо» и «Месси», описываемыми с использованием атрибута «запись», и наказанием, в котором сущность «Месси» описывается с помощью «целей». атрибут . В таком сценарии методы предшествующего уровня техники могут идентифицировать следующие пары атрибутов объекта: (Роналдо, рекорд), (Месси, бревно) и (Месси, голы) . Инновации, описанные в этой спецификации, выходят за рамки этих подходов предшествующего уровня техники, определяя отношения объект-атрибут, которые могут быть неразличимы по тому, как эти термины используются в наборе данных .
Используя приведенный выше пример, новшество, описанное в этой спецификации, определяет, что «Роналду» и «Месси» являются похожими объектами, поскольку они имеют общий атрибут «рекорд», а затем представляют атрибут «рекорд», используя атрибут «голы» . Таким образом, новшества, описанные в этой спецификации, могут, например, позволить идентифицировать отношения объект-атрибут, например (Криштиану, Цели), даже если такие отношения могут быть неразличимы из набора данных .
Патент на определение отношений атрибутов
Идентификация отношений атрибутов объекта
Изобретатели: Дэн Итер, Сяо Ю и Фангтао Ли.
Правопреемник: Google LLC
Патент США: 11 263 400
Выдано: 1 марта 2022 г.
Подано: 5 июля 2019 г.
Абстрактный
Методы, системы и устройства, включая компьютерные программы, закодированные на компьютерном носителе данных, которые упрощают идентификацию взаимосвязей объект-атрибут в текстовых корпусах .Методы включают в себя определение того, является ли атрибут в паре кандидатов объект-атрибут фактическим атрибутом объекта в паре кандидатов объект-атрибут .Это включает в себя создание вложений для слов в наборе предложений, которые включают сущность и атрибут, а также генерацию с использованием известных пар сущность-атрибут .Это также включает в себя создание распределения распределения атрибутов для объекта на основе других атрибутов, связанных с объектом из известных пар объект-атрибут, и создание распределения распределения атрибутов для атрибута на основе известных атрибутов, связанных с известными объектами атрибута в известной пары сущность-атрибут .На основе этих вложений сеть прямого распространения определяет, является ли атрибут в паре кандидатов объект-атрибут фактическим атрибутом объекта в паре кандидатов объект-атрибут .
Идентификация отношений атрибутов объекта в тексте
Пара объект-атрибут-кандидат (где атрибут является атрибутом-кандидатом объекта) вводится в модель классификации . Модель классификации использует механизм внедрения пути, механизм распределения распределения, механизм атрибутов и сеть прямой связи. Он определяет, является ли атрибут в паре объект-атрибут-кандидат существенным объектом в паре атрибут-кандидат .
Механизм встраивания путей генерирует вектор, представляющий встраивание путей или слов, которые соединяют повседневные случаи появления объекта и атрибута в наборе предложений (например, 30 или более предложений) набора данных . Механизм представления распределения генерирует векторы, представляющие вложение объекта, и атрибуты терминов на основе контекста, в котором эти термины появляются в наборе предложений . Механизм распределения атрибутов генерирует вектор, представляющий вложение объекта, и другой вектор, представляющий вложение атрибута .
Внедрение механизма распределения атрибутов для объекта основано на других функциях (т. е. атрибутах, отличных от атрибута-кандидата), которые, как известно, связаны с объектом в наборе данных . Подробное встраивание механизма распределения для качества основано на различных функциях, связанных с известными объектами атрибута-кандидата .
Классификационная модель объединяет векторные представления из механизма встраивания пути, механизма распределения распределения и механизма распределения атрибутов в единое векторное представление. Затем модель классификации вводит одно векторное представление в сеть прямой связи, которая определяет, используя одно векторное представление, является ли атрибут в паре объект-атрибут-кандидат существенным атрибутом объекта в паре атрибут-кандидат .
Предположим, что сеть прямой связи определяет, что точка в потенциальной паре объект-атрибут необходима для объекта в потенциальной паре объект-атрибут. В этом случае пара «объект-атрибут-кандидат» сохраняется в базе знаний вместе с другими парами «известный/фактический объект-атрибут» .
Извлечение отношений атрибутов объекта
Среда включает в себя модель классификации, которая для пар "объект-атрибут-кандидат" в базе знаний определяет, является ли атрибут в паре "объект-атрибут-кандидат" существенным атрибутом объекта в паре-кандидате . Модель классификации представляет собой модель нейронной сети, компоненты которой описаны ниже . Модель классификации также можно использовать с другими моделями машинного обучения с учителем и без учителя .
База знаний, которая может включать в себя базы данных (или другие подходящие структуры хранения данных), хранящиеся на долговременных носителях данных (например, на жестких дисках, флэш-памяти и т. д.), содержит набор возможных пар объект-атрибут . Пары-кандидаты объект-атрибут получаются с использованием набора содержимого в текстовых документах, таких как веб-страницы и новостные статьи, полученные из источника данных. Источник данных может включать любой источник контента, например новостной веб-сайт, платформу агрегатора данных, платформу социальных сетей и т . д .
Источник данных получает новостные статьи с платформы агрегатора данных. Источник данных может использовать модель. Модель контролируемого или неконтролируемого машинного обучения (модель обработки естественного языка) генерирует набор возможных пар объект-атрибут путем извлечения предложений из статей, маркировки и маркировки извлеченных предложений, например, как объектов и атрибутов, с использованием частей речи. и теги дерева синтаксического анализа зависимостей .
Источник данных может вводить извлеченные предложения в модель машинного обучения. Например, его можно обучить, используя набор обучающих предложений и связанные с ними пары сущность-атрибут . Затем такая модель машинного обучения может выводить команды-кандидаты сущностей-атрибутов для извлеченных входных предложений .
В базе знаний источник данных хранит возможные пары объект-атрибут и предложения, извлеченные источником данных, которые включают слова возможных пар объект-атрибут . Пары-кандидаты объект-атрибут сохраняются в базе знаний только в том случае, если количество предложений, в которых присутствует объект и атрибут, удовлетворяет (например, соответствует или превышает) пороговое количество предложений (например, 30 предложений) .
Модель классификации определяет, является ли атрибут в потенциальной паре объект-атрибут (хранящейся в базе знаний) фактическим атрибутом объекта в потенциальной паре объект-атрибут . Модель классификации включает в себя механизм 106 внедрения пути, источник распределения распределения, механизм атрибутов и сеть 10 прямой связи . Используемый здесь термин «механизм» относится к устройству обработки данных, которое выполняет набор задач. Операции этих механизмов модели классификации при определении того, является ли атрибут в потенциальной паре объект-атрибут существенным атрибутом объекта .
Пример процесса идентификации отношений атрибутов объекта
Операции процесса описаны ниже как выполняемые компонентами системы, а функции процесса описаны ниже только в иллюстративных целях. Операции процесса могут выполняться любым подходящим устройством или системой, например любым применимым устройством обработки данных . Функции процесса также могут быть реализованы в виде инструкций, хранящихся на энергонезависимом машиночитаемом носителе . Выполнение инструкций заставляет устройство обработки данных выполнять операции процесса .
База знаний получает пару кандидатов объект-атрибут из источника данных.
База знаний получает набор предложений из источника данных, которые включают слова сущности и атрибута в потенциальной паре сущность-атрибут .
На основе набора предложений и пары объект-атрибут-кандидат модель классификации определяет, является ли атрибут-кандидат фактическим атрибутом объекта-кандидата . Набор наказаний может состоять из большого количества предложений, например, 30 или более предложений.
Модель классификации, выполняющая следующие операции
- Вложения слов в набор предложений, которые включают объект и атрибут, более подробно описаны ниже в отношении процесса, описанного ниже.
- Созданный с использованием известных пар объект-атрибут, внедрение атрибута распределения для объекта, который более подробно описан ниже в отношении операции.
- Построение с использованием известных пар объект-атрибут и внедрение атрибута распределения для атрибута, которое более подробно описано ниже в отношении операции.
- Выбор, основанный на вложениях слов в наборе предложений, внедрении атрибута распределения для объекта и внедрении атрибута распределения для атрибута, является ли атрибут в паре кандидатов объект-атрибут существенным атрибутом объекта в кандидатная пара сущность-атрибут, которая более подробно описана ниже в отношении операции .
Механизм встраивания пути генерирует первое векторное представление, определяющее первые слова, вложенные между сущностью и атрибутом в предложениях . Механизм встраивания путей определяет отношения между терминами-атрибутами-кандидатами путем встраивания путей или слов, которые соединяют повседневные вхождения этих терминов в набор предложений .
Для фразы «змея — это рептилия» механизм встраивания пути генерирует вложение для трека «является а», которое можно использовать для обнаружения, например, отношений род-вид, которые затем можно использовать для идентификации других атрибутов объекта. пары .
Создание слов между сущностью и атрибутом
Механизм встраивания пути делает следующее для создания слов между сущностью и атрибутом в предложениях . Для каждого предложения в наборе предложений механизм встраивания пути сначала извлекает путь зависимости (который определяет группу слов) между сущностью и атрибутом . Механизм встраивания пути преобразует предложение из строки в список, где первый термин — это сущность, а последний термин — это атрибут (или первый термин — это атрибут, а предыдущий термин — это сущность) .
Каждый термин (который также называется ребром) в пути зависимости представляется с использованием следующих функций: леммы термина, тега части речи, метки зависимости и направления пути зависимости (слева). , право или корень) . Каждый из этих признаков встраивается и объединяется для создания векторного представления термина или ребра (Ve), которое содержит последовательность векторов (V1, Vpos, Vdep , V.sub.dir), как показано в приведенном ниже уравнении: {стрелка вправо над (v)}.sub.e=[{стрелка вправо над (v)}.sub.l, {стрелка вправо над (v)} .sub.pos, {стрелка вправо над (v)}.sub.dep, {стрелка вправо над (v)}.sub.dir]
Затем механизм встраивания путей вводит последовательность векторов для терминов или ребер в каждом пути в сеть с долговременной кратковременной памятью (LSTM), которая создает единое векторное представление для предложения (V s ), как показано на приведенное ниже уравнение: {стрелка вправо над (v)}.sub.s=LSTM({стрелка вправо над (v)}.sub.e.sup.(1) ... {стрелка вправо над (v)}.sub .e.sup.(k))
Наконец, механизм встраивания пути вводит одно векторное представление для всех предложений в наборе предложений в механизм внимания, который определяет средневзвешенное значение представлений предложений (Vsents(e,a)), как показано ниже уравнения: {стрелка вправо над (v)}.sub.sents(e,a)=ATTN({стрелка вправо над (v)}.sub.s.sup.(1) . . . {стрелка вправо над (v )}.sub.sup.(n))
Репрезентативная модель распределения генерирует второе векторное представление для объекта и третье векторное представление для атрибута на основе предложений . Механизм представления распределения выявляет взаимосвязи между терминами-кандидатами объект-атрибут на основе контекста, в котором точка и объект потенциальной пары объект-атрибут встречаются в наборе предложений . Например, механизм представления распределения может определить, что объект «Нью-Йорк» используется в наборе предложений таким образом, чтобы предположить, что этот объект относится к городу или штату в Соединенных Штатах .
В качестве другого примера, механизм представления распределения может определить, что атрибут «столица» используется в наборе предложений таким образом, который предполагает, что этот атрибут относится к важному городу в штате или стране . Таким образом, механизм распределенного представления генерирует векторное представление, определяющее вложение объекта (V e ), используя контекст (т. е. набор предложений), в котором появляется объект . Механизм представления распределения генерирует векторное представление (V.sub.a), определяющее вложение для атрибута, используя набор предложений, в которых появляется функция .
Механизм атрибутов распределения генерирует четвертое векторное представление, определяющее внедрение атрибутов распределения для объекта с использованием известных пар объект-атрибут . Известные пары объект-атрибут, которые сохраняются в базе знаний, являются парами объект-атрибут, для которых было подтверждено (например, с использованием предшествующей обработки моделью классификации или на основе оценки человеком), что каждый атрибут в объекте- Пара атрибутов является существенным атрибутом сущности в паре сущность-атрибут .
Механизм атрибутов распределения выполняет следующие операции для определения внедрения атрибутов распределения, которое задает внедрение для объекта с использованием некоторых (например, наиболее распространенных) или всех других известных атрибутов среди известных пар объект-атрибут, с которыми этот объект связывается .
Определение других атрибутов сущностей
Для сущностей в паре кандидатов сущность-атрибут механизм распределения атрибутов идентифицирует атрибуты, отличные от включенных в пару кандидатов сущность-атрибут, связанную с сущностью в известных командах сущность-атрибут .
Для сущности «Майкл Джордан» в паре-кандидате сущность-атрибут (Майкл Джордан, известный) механизм распределения атрибутов может использовать известные пары сущность-атрибут для Майкла Джордана, такие как (Майкл Джордан, богатый) и (Майкл Джордан, запись), чтобы идентифицировать такие атрибуты, как богатый и описание .
Затем механизм распределения атрибутов создает вложение для объекта, вычисляя взвешенную сумму идентифицированных известных атрибутов (как описано в предыдущем абзаце), где веса изучаются с использованием механизма внимания, как показано в следующем уравнении: стрелка над (v)}.sub.e=ATTN(.epsilon.(.alpha..sub.1) . . . .epsilon.(.alpha..sub.m))
Механизм атрибутов распределения генерирует пятое векторное представление, определяющее внедрение атрибута распределения для атрибута с использованием известных пар объект-атрибут . Механизм атрибутов распределения выполняет следующие операции для определения модели на основе некоторых (будь то наиболее распространенных) или всех известных атрибутов, связанных с известными объектами атрибута-кандидата .
Для точки в паре кандидатов объект-атрибут механизм атрибутов распределения идентифицирует известные объекты среди известных пар объект-атрибут, которые имеют качество .
Для каждого идентифицированного известного объекта механизм атрибутов распределения идентифицирует другие атрибуты (т. е. атрибуты, отличные от одного, включенного в пару кандидатов объект-атрибут), связанные с объектом в известных командах объект-атрибут . Механизм атрибутов распределения может идентифицировать подмножество атрибутов среди идентифицированных атрибутов следующим образом:
(1) Атрибуты ранжирования на основе количества известных объектов, связанных с каждым объектом, например присвоение более высокого ранга атрибутам, связанным с большим количеством объектов, чем атрибутам, связанным с меньшим количеством объектов)
Поиск новостей прямо в папку «Входящие»
*Необходимый