
O que é regressão logística? Aprenda quando usar
Publicados: 2021-07-29A vida é cheia de escolhas binárias difíceis.
Devo comer aquela fatia de pizza ou não? Devo levar um guarda-chuva ou não?
Embora algumas decisões possam ser tomadas com razão, pesando os prós e os contras – por exemplo, é melhor não comer uma fatia de pizza, pois contém calorias extras – algumas decisões podem não ser tão fáceis.
Por exemplo, você nunca pode ter certeza se vai chover ou não em um dia específico. Portanto, a decisão de levar ou não um guarda-chuva é difícil de tomar.
Para fazer a escolha certa, são necessários recursos preditivos. Essa habilidade é altamente lucrativa e tem inúmeras aplicações no mundo real, especialmente em computadores. Os computadores adoram decisões binárias. Afinal, eles falam em código binário.
Aprendizado de máquina algoritmos, mais precisamente o algoritmo de regressão logística , podem ajudar a prever a probabilidade de eventos observando pontos de dados históricos. Por exemplo, pode prever se um indivíduo vencerá a eleição ou se choverá hoje.
O que é regressão logística?
A regressão logística é um método estatístico usado para prever o resultado de uma variável dependente com base em observações anteriores. É um tipo de análise de regressão e é um algoritmo comumente usado para resolver problemas de classificação binária.
Se você está se perguntando o que é a análise de regressão , é um tipo de técnica de modelagem preditiva usada para encontrar a relação entre uma variável dependente e uma ou mais variáveis independentes.
Um exemplo de variáveis independentes é o tempo gasto estudando e o tempo gasto no Instagram. Neste caso, as notas serão a variável dependente. Isso porque tanto o “tempo gasto estudando” quanto o “tempo gasto no Instagram” influenciariam as notas; um positivamente e outro negativamente.
A regressão logística é um algoritmo de classificação que prevê um resultado binário com base em uma série de variáveis independentes. No exemplo acima, isso significaria prever se você seria aprovado ou reprovado em uma aula. É claro que a regressão logística também pode ser usada para resolver problemas de regressão, mas é usada principalmente para problemas de classificação.
Dica: use software de aprendizado de máquina para automatizar tarefas monótonas e tomar decisões baseadas em dados.
Outro exemplo seria prever se um aluno será aceito em uma universidade. Para isso, vários fatores, como a pontuação no SAT, a média de notas do aluno e o número de atividades extracurriculares, serão considerados. Usando dados históricos sobre resultados anteriores, o algoritmo de regressão logística classificará os alunos nas categorias "aceitar" ou "rejeitar".
A regressão logística também é conhecida como regressão logística binomial ou regressão logística binária. Se houver mais de duas classes da variável de resposta, ela é chamada de regressão logística multinomial . Sem surpresa, a regressão logística foi emprestada da estatística e é um dos algoritmos de classificação binária mais comuns em aprendizado de máquina e ciência de dados.
Você sabia? Uma representação de rede neural artificial (RNA) pode ser vista como um empilhamento de um grande número de classificadores de regressão logística.
A regressão logística funciona medindo a relação entre a variável dependente (o que queremos prever) e uma ou mais variáveis independentes (as características). Ele faz isso estimando as probabilidades com a ajuda de sua função logística subjacente.
Termos-chave em regressão logística
Compreender a terminologia é crucial para decifrar corretamente os resultados da regressão logística. Saber o que significam termos específicos ajudará você a aprender rapidamente se for novo em estatísticas ou aprendizado de máquina.
- Variável: Qualquer número, característica ou quantidade que pode ser medida ou contada. Idade, velocidade, sexo e renda são exemplos.
- Coeficiente: Um número, geralmente um número inteiro, multiplicado pela variável que o acompanha. Por exemplo, em 12y, o número 12 é o coeficiente.
- EXP: Forma abreviada de exponencial.
- Outliers: pontos de dados que diferem significativamente dos demais.
- Estimador: Um algoritmo ou fórmula que gera estimativas de parâmetros.
- Teste do qui-quadrado: também chamado de teste do qui-quadrado, é um método de teste de hipóteses para verificar se os dados estão conforme o esperado.
- Erro padrão: O desvio padrão aproximado de uma população de amostra estatística.
- Regularização: Um método usado para reduzir o erro e o overfitting ajustando uma função (apropriadamente) no conjunto de dados de treinamento.
- Multicolinearidade: Ocorrência de intercorrelações entre duas ou mais variáveis independentes.
- Qualidade de ajuste: Descrição de quão bem um modelo estatístico se ajusta a um conjunto de observações.
- Odds ratio: Medida da força de associação entre dois eventos.
- Funções de probabilidade de log: avalia a qualidade de ajuste de um modelo estatístico.
- Teste de Hosmer–Lemeshow: Um teste que avalia se as taxas de eventos observadas correspondem às taxas de eventos esperadas.
O que é uma função logística?
A regressão logística tem o nome da função usada em seu coração, a função logística . Os estatísticos inicialmente o usaram para descrever as propriedades do crescimento populacional. A função sigmóide e a função logit são algumas variações da função logística. A função Logit é o inverso da função logística padrão.
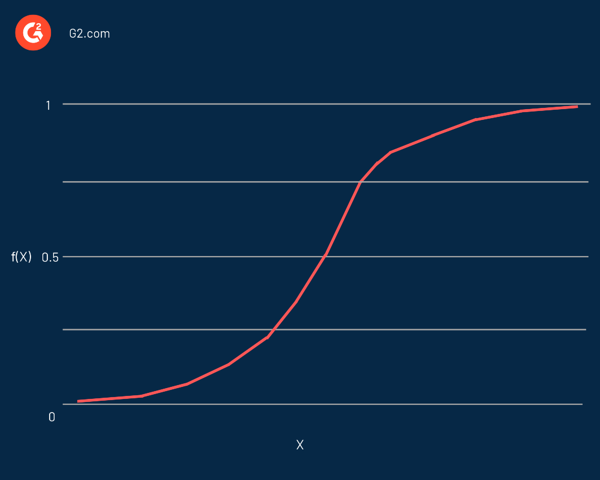
Na verdade, é uma curva em forma de S capaz de pegar qualquer número real e mapeá-lo em um valor entre 0 e 1, mas nunca precisamente nesses limites. É representado pela equação:
f(x) = L / 1 + e^-k(x - x0)
Nesta equação:
- f(X) é a saída da função
- L é o valor máximo da curva
- e é a base dos logaritmos naturais
- k é a inclinação da curva
- x é o número real
- x0 são os valores x do ponto médio sigmóide
Se o valor previsto for um valor negativo considerável, é considerado próximo de zero. Por outro lado, se o valor previsto for um valor positivo significativo, considera-se próximo de um.
A regressão logística é representada de forma semelhante a como a regressão linear é definida usando a equação de uma linha reta. Uma diferença notável da regressão linear é que a saída será um valor binário (0 ou 1) em vez de um valor numérico.
Aqui está um exemplo de uma equação de regressão logística:
y = e^(b0 + b1*x) / (1 + e^(b0 + b1*x))
Nesta equação:
- y é o valor previsto (ou a saída)
- b0 é o viés (ou o termo de interceptação)
- b1 é o coeficiente para a entrada
- x é a variável preditora (ou a entrada)
A variável dependente geralmente segue a distribuição de Bernoulli. Os valores dos coeficientes são estimados usando estimativa de máxima verossimilhança (MLE) , gradiente descendente e gradiente descendente estocástico .
Tal como acontece com outros algoritmos de classificação como o k-vizinhos mais próximos, um matriz de confusão é usado para avaliar a precisão do algoritmo de regressão logística.
Você sabia? A regressão logística é parte de uma família maior de modelos lineares generalizados (GLMs).
Assim como avaliar o desempenho de um classificador, é igualmente importante saber por que o modelo classificou uma observação de uma maneira específica. Em outras palavras, precisamos que a decisão do classificador seja interpretável.
Embora a interpretabilidade não seja fácil de definir, sua intenção principal é que os humanos saibam por que um algoritmo tomou uma decisão específica. No caso da regressão logística, ela pode ser combinada com testes estatísticos como o teste de Wald ou o teste de razão de verossimilhança para interpretabilidade.
Quando usar a regressão logística
A regressão logística é aplicada para prever a variável dependente categórica. Em outras palavras, é usado quando a previsão é categórica, por exemplo, sim ou não, verdadeiro ou falso, 0 ou 1. A probabilidade ou saída prevista da regressão logística pode ser qualquer uma delas e não há meio termo.
No caso de variáveis preditoras, elas podem fazer parte de qualquer uma das seguintes categorias:
- Dados contínuos: Dados que podem ser medidos em uma escala infinita. Pode assumir qualquer valor entre dois números. Exemplos são peso em libras ou temperatura em Fahrenheit.
- Dados discretos e nominais: Dados que se encaixam em categorias nomeadas. Um exemplo rápido é a cor do cabelo: loiro, preto ou castanho.
- Dados discretos e ordinais: Dados que se encaixam em alguma forma de ordem em uma escala. Um exemplo é dizer o quanto você está satisfeito com um produto ou serviço em uma escala de um a cinco.
A análise de regressão logística é valiosa para prever a probabilidade de um evento. Ele ajuda a determinar as probabilidades entre quaisquer duas classes.

Em poucas palavras, observando os dados históricos, a regressão logística pode prever se:
- Um e-mail é um spam
- Vai chover hoje
- Um tumor é fatal
- Um indivíduo vai comprar um carro
- Uma transação online é fraudulenta
- Um concorrente vai ganhar uma eleição
- Um grupo de usuários comprará um produto
- Um titular de apólice de seguro expirará antes que o prazo da apólice expire
- Um destinatário de e-mail promocional é um respondente ou não respondente
Em essência, a regressão logística ajuda a resolver problemas de probabilidade e classificação . Em outras palavras, você pode esperar apenas resultados de classificação e probabilidade da regressão logística.
Por exemplo, pode ser usado para determinar a probabilidade de algo ser “verdadeiro ou falso” e também para decidir entre dois resultados como “sim ou não”.
Um modelo de regressão logística também pode ajudar a classificar dados para operações de extração, transformação e carregamento (ETL). A regressão logística não deve ser usada se o número de observações for menor que o número de feições. Caso contrário, pode levar a overfitting.
Regressão linear vs. regressão logística
Enquanto a regressão logística prevê a variável categórica para uma ou mais variáveis independentes, regressão linear prevê a variável contínua. Em outras palavras, a regressão logística fornece uma saída constante, enquanto a regressão linear oferece uma saída contínua.
Como o resultado é contínuo na regressão linear, existem infinitos valores possíveis para o resultado. Mas para a regressão logística, o número de valores de resultado possíveis é limitado.
Na regressão linear, as variáveis dependentes e independentes devem estar relacionadas linearmente. No caso de regressão logística, as variáveis independentes devem estar linearmente relacionadas com a logar probabilidades (log(p/(1-p)).
Dica: A regressão logística pode ser implementada em qualquer linguagem de programação usada para análise de dados, como R, Python, Java e MATLAB.
Enquanto a regressão linear é estimada usando o método dos mínimos quadrados ordinários, a regressão logística é estimada usando a abordagem de estimativa de máxima verossimilhança.
Tanto a regressão logística quanto a linear são aprendizado de máquina supervisionado algoritmos e os dois principais tipos de análise de regressão. Enquanto a regressão logística é usada para resolver problemas de classificação, a regressão linear é usada principalmente para problemas de regressão.
Voltando ao exemplo do tempo gasto estudando, a regressão linear e a regressão logística podem prever coisas diferentes. A regressão logística pode ajudar a prever se o aluno passou ou não em um exame. Em contraste, a regressão linear pode prever a pontuação do aluno.
Suposições de regressão logística
Ao usar a regressão logística, fazemos algumas suposições. As suposições são essenciais para usar corretamente a regressão logística para fazer previsões e resolver problemas de classificação.
A seguir estão os principais pressupostos da regressão logística:
- Há pouca ou nenhuma multicolinearidade entre as variáveis independentes.
- As variáveis independentes estão linearmente relacionadas com o log das probabilidades (log (p/(1-p)).
- A variável dependente é dicotômica ou binária ; ele se encaixa em duas categorias distintas. Isso se aplica apenas à regressão logística binária, que será discutida mais adiante.
- Não há variáveis sem significado, pois elas podem levar a erros.
- Os tamanhos de amostra de dados são maiores , o que é integral para melhores resultados.
- Não há outliers .
Tipos de regressão logística
A regressão logística pode ser dividida em diferentes tipos com base no número de resultados ou categorias da variável dependente.
Quando pensamos em regressão logística, provavelmente pensamos em regressão logística binária. Na maior parte deste artigo, quando nos referimos à regressão logística, estávamos nos referindo à regressão logística binária.
A seguir estão os três principais tipos de regressão logística.
Regressão logística binária
A regressão logística binária é um método estatístico usado para prever a relação entre uma variável dependente e uma variável independente. Neste método, a variável dependente é uma variável binária, o que significa que pode assumir apenas dois valores (sim ou não, verdadeiro ou falso, sucesso ou falha, 0 ou 1).
Um exemplo simples de regressão logística binária é determinar se um email é spam ou não.
Regressão logística multinomial
A regressão logística multinomial é uma extensão da regressão logística binária. Permite mais de duas categorias do resultado ou variável dependente.
É semelhante à regressão logística binária, mas pode ter mais de dois resultados possíveis. Isso significa que a variável de resultado pode ter três ou mais tipos não ordenados possíveis – tipos sem significância quantitativa. Por exemplo, a variável dependente pode representar "Tipo A", "Tipo B" ou "Tipo C".
Semelhante à regressão logística binária, a regressão logística multinomial também usa a estimativa de máxima verossimilhança para determinar a probabilidade.
Por exemplo, a regressão logística multinomial pode ser usada para estudar a relação entre a educação e as escolhas ocupacionais. Aqui, as escolhas ocupacionais serão a variável dependente que consiste em categorias de diferentes ocupações.
Regressão logística ordinal
A regressão logística ordinal , também conhecida como regressão ordinal, é outra extensão da regressão logística binária. É usado para prever a variável dependente com três ou mais tipos ordenados possíveis – tipos com significância quantitativa. Por exemplo, a variável dependente pode representar "Discordo Fortemente", "Discordo", "Concordo" ou "Concordo Fortemente".
Ele pode ser usado para determinar o desempenho no trabalho (ruim, médio ou excelente) e a satisfação no trabalho (insatisfeito, satisfeito ou altamente satisfeito).
Vantagens e desvantagens da regressão logística
Muitas das vantagens e desvantagens do modelo de regressão logística se aplicam ao modelo de regressão linear. Uma das vantagens mais significativas do modelo de regressão logística é que ele não apenas classifica, mas também fornece probabilidades.
A seguir estão algumas das vantagens do algoritmo de regressão logística.
- Simples de entender, fácil de implementar e eficiente para treinar
- Funciona bem quando o conjunto de dados é linearmente separável
- Boa precisão para conjuntos de dados menores
- Não faz suposições sobre a distribuição de classes
- Oferece a direção da associação (positiva ou negativa)
- Útil para encontrar relacionamentos entre recursos
- Fornece probabilidades bem calibradas
- Menos propenso a overfitting em conjuntos de dados de baixa dimensão
- Pode ser estendido para classificação multiclasse
No entanto, existem inúmeras desvantagens para a regressão logística. Se houver um recurso que separaria duas classes perfeitamente, o modelo não poderá mais ser treinado. Isso é chamado de separação completa .
Isso acontece principalmente porque o peso para esse recurso não convergiria, pois o peso ideal seria infinito. No entanto, na maioria dos casos, a separação completa pode ser resolvida definindo uma distribuição de probabilidade prévia de pesos ou introduzindo uma penalização dos pesos.
A seguir estão algumas das desvantagens do algoritmo de regressão logística:
- Constrói limites lineares
- Pode levar a overfitting se o número de recursos for maior que o número de observações
- Os preditores devem ter média ou nenhuma multicolinearidade
- Desafiador para obter relacionamentos complexos. Algoritmos como redes neurais são mais adequados e poderosos
- Pode ser usado apenas para prever funções discretas
- Não pode resolver problemas não lineares
- Sensível a outliers
Quando a vida lhe der opções, pense em regressão logística
Muitos podem argumentar que os humanos não vivem em um mundo binário, ao contrário dos computadores. Claro, se você receber uma fatia de pizza e um hambúrguer, poderá comer os dois sem ter que escolher apenas um. Mas se você olhar mais de perto, uma decisão binária está gravada (literalmente) em tudo. Você pode optar por comer ou não comer uma pizza; não há meio termo.
Avaliar o desempenho de um modelo preditivo pode ser complicado se houver uma quantidade limitada de dados. Para isso, você pode usar uma técnica chamada validação cruzada, que envolve o particionamento dos dados disponíveis em um conjunto de treinamento e um conjunto de teste.