
Co to jest regresja logistyczna? Dowiedz się, kiedy go używać
Opublikowany: 2021-07-29Życie jest pełne trudnych wyborów binarnych.
Czy powinienem zjeść ten kawałek pizzy, czy nie? Czy powinienem nosić parasol czy nie?
Chociaż niektóre decyzje można słusznie podjąć, rozważając wady i zalety – na przykład lepiej nie jeść kawałka pizzy, ponieważ zawiera dodatkowe kalorie – niektóre decyzje mogą nie być takie proste.
Na przykład nigdy nie możesz być całkowicie pewien, czy w konkretnym dniu będzie padało. Tak więc decyzja, czy nosić parasol, czy nie, jest trudna do podjęcia.
Aby dokonać właściwego wyboru, potrzebne są zdolności przewidywania. Ta umiejętność jest bardzo lukratywna i ma wiele zastosowań w świecie rzeczywistym, zwłaszcza na komputerach. Komputery uwielbiają decyzje binarne. W końcu mówią w kodzie binarnym.
Nauczanie maszynowe algorytmy, a dokładniej algorytm regresji logistycznej , mogą pomóc w przewidywaniu prawdopodobieństwa zdarzeń na podstawie historycznych punktów danych. Na przykład może przewidzieć, czy dana osoba wygra wybory, czy dzisiaj będzie padać.
Czym jest regresja logistyczna?
Regresja logistyczna to metoda statystyczna stosowana do przewidywania wyniku zmiennej zależnej na podstawie wcześniejszych obserwacji. Jest to rodzaj analizy regresji i jest powszechnie używanym algorytmem rozwiązywania problemów klasyfikacji binarnej.
Jeśli zastanawiasz się, czym jest analiza regresji , jest to rodzaj techniki modelowania predykcyjnego używanej do znalezienia związku między zmienną zależną a jedną lub większą liczbą zmiennych niezależnych.
Przykładem zmiennych niezależnych jest czas spędzony na nauce i czas spędzony na Instagramie. W takim przypadku oceny będą zmienną zależną. Dzieje się tak, ponieważ zarówno „czas spędzony na nauce”, jak i „czas spędzony na Instagramie” miałyby wpływ na oceny; jeden pozytywnie, a drugi negatywnie.
Regresja logistyczna to algorytm klasyfikacji, który przewiduje wynik binarny na podstawie serii zmiennych niezależnych. W powyższym przykładzie oznaczałoby to przewidzenie, czy zaliczysz lub nie zaliczysz zajęć. Oczywiście regresja logistyczna może być również używana do rozwiązywania problemów regresji, ale jest używana głównie do problemów z klasyfikacją.
Wskazówka: użyj oprogramowania do uczenia maszynowego, aby zautomatyzować monotonne zadania i podejmować decyzje na podstawie danych.
Innym przykładem jest przewidywanie, czy student zostanie przyjęty na uniwersytet. W tym celu uwzględni się wiele czynników, takich jak wynik SAT, średnia ocen ucznia i liczba zajęć pozalekcyjnych. Wykorzystując dane historyczne dotyczące poprzednich wyników, algorytm regresji logistycznej posortuje uczniów na kategorie „akceptuj” lub „odrzuć”.
Regresja logistyczna jest również określana jako dwumianowa regresja logistyczna lub binarna regresja logistyczna. Jeśli istnieje więcej niż dwie klasy zmiennej odpowiedzi, nazywa się to wielomianową regresją logistyczną . Nic dziwnego, że regresja logistyczna została zapożyczona ze statystyk i jest jednym z najczęstszych algorytmów klasyfikacji binarnej w uczeniu maszynowym i nauce o danych.
Czy wiedziałeś? Reprezentacja sztucznej sieci neuronowej (ANN) może być postrzegana jako połączenie dużej liczby klasyfikatorów regresji logistycznej.
Regresja logistyczna działa poprzez pomiar relacji między zmienną zależną (co chcemy przewidzieć) a co najmniej jedną zmienną niezależną (cechy). Czyni to poprzez oszacowanie prawdopodobieństw za pomocą swojej podstawowej funkcji logistycznej.
Kluczowe terminy w regresji logistycznej
Zrozumienie terminologii ma kluczowe znaczenie dla prawidłowego odczytania wyników regresji logistycznej. Wiedza o tym, co oznaczają konkretne terminy, pomoże Ci szybko się uczyć, jeśli dopiero zaczynasz przygodę ze statystykami lub uczeniem maszynowym.
- Zmienna: Dowolna liczba, charakterystyka lub wielkość, którą można zmierzyć lub policzyć. Przykładami są wiek, szybkość, płeć i dochód.
- Współczynnik: liczba, zwykle liczba całkowita, pomnożona przez zmienną, której towarzyszy. Na przykład w 12y liczba 12 jest współczynnikiem.
- EXP: Krótka forma wykładnicza.
- Odstające: punkty danych, które znacznie różnią się od pozostałych.
- Estymator: Algorytm lub formuła generująca oszacowania parametrów.
- Test chi-kwadrat: Nazywany również testem chi-kwadrat, jest to metoda testowania hipotez, która sprawdza, czy dane są zgodne z oczekiwaniami.
- Błąd standardowy: przybliżone odchylenie standardowe statystycznej populacji próby.
- Regularyzacja: Metoda stosowana do zmniejszania błędu i overfittingu poprzez dopasowanie funkcji (odpowiednio) do zestawu danych treningowych.
- Wielokoliniowość: Występowanie korelacji między dwiema lub więcej zmiennymi niezależnymi.
- Dobroć dopasowania: opis, jak dobrze model statystyczny pasuje do zestawu obserwacji.
- Iloraz szans: Miara siły powiązania między dwoma zdarzeniami.
- Logarytmiczne funkcje prawdopodobieństwa: ocenia zgodność modelu statystycznego.
- Test Hosmera–Lemeshowa: test, który ocenia, czy zaobserwowane częstości zdarzeń odpowiadają oczekiwanym częstościom zdarzeń.
Co to jest funkcja logistyczna?
Regresja logistyczna nosi nazwę funkcji używanej w jej sercu, funkcji logistycznej . Statystycy początkowo używali go do opisu właściwości wzrostu populacji. Funkcja sigmoidalna i funkcja logitowa to niektóre odmiany funkcji logistycznej. Funkcja logit jest odwrotnością standardowej funkcji logistycznej.
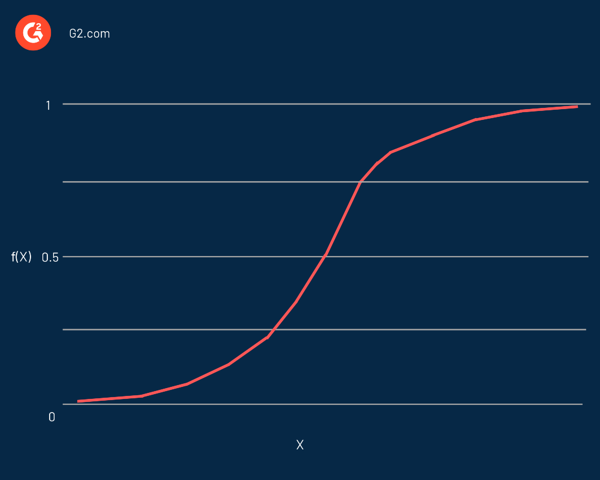
W efekcie jest to krzywa w kształcie litery S, która może przyjąć dowolną liczbę rzeczywistą i odwzorować ją na wartość z zakresu od 0 do 1, ale nigdy dokładnie w tych granicach. Przedstawia to równanie:
f(x) = L / 1 + e^-k(x - x0)
W tym równaniu:
- f(X) jest wyjściem funkcji
- L to maksymalna wartość krzywej
- e jest podstawą logarytmów naturalnych
- k jest nachyleniem krzywej
- x to liczba rzeczywista
- x0 to wartości x sigmoidalnego punktu środkowego
Jeśli przewidywana wartość jest znacznie ujemna, uważa się ją za bliską zeru. Z drugiej strony, jeśli przewidywana wartość jest istotnie dodatnią wartością, jest uważana za bliską jedności.
Regresja logistyczna jest reprezentowana podobnie jak regresja liniowa jest definiowana za pomocą równania linii prostej. Zauważalna różnica w stosunku do regresji liniowej polega na tym, że wynik będzie wartością binarną (0 lub 1), a nie wartością liczbową.
Oto przykład równania regresji logistycznej:
y = e^(b0 + b1*x) / (1 + e^(b0 + b1*x))
W tym równaniu:
- y jest przewidywaną wartością (lub wyjściem)
- b0 to stronniczość (lub termin przechwycenia)
- b1 jest współczynnikiem dla wejścia
- x jest zmienną predykcyjną (lub wejściową)
Zmienna zależna generalnie podąża za Rozkład Bernoulliego. Wartości współczynników są szacowane za pomocą estymacji maksymalnego prawdopodobieństwa (MLE) , gradientu zejścia i stochastycznego zejścia gradientu .
Podobnie jak w przypadku innych algorytmów klasyfikacji, takich jak k-najbliżsi sąsiedzi, a macierz zamieszania służy do oceny dokładności algorytmu regresji logistycznej.
Czy wiedziałeś? Regresja logistyczna jest częścią większej rodziny uogólnionych modeli liniowych (GLM).
Podobnie jak w przypadku oceny wydajności klasyfikatora, równie ważne jest, aby wiedzieć, dlaczego model sklasyfikował obserwację w określony sposób. Innymi słowy, potrzebujemy, aby decyzja klasyfikatora była możliwa do zinterpretowania.
Chociaż interpretowalność nie jest łatwa do zdefiniowania, jej głównym celem jest, aby ludzie wiedzieli, dlaczego algorytm podjął określoną decyzję. W przypadku regresji logistycznej można ją połączyć z testami statystycznymi, takimi jak Test Walda albo test ilorazu wiarygodności do interpretacji.
Kiedy stosować regresję logistyczną
Regresja logistyczna jest stosowana do przewidywania zmiennej zależnej kategorialnej. Innymi słowy, jest używany, gdy przewidywanie jest kategoryczne, na przykład tak lub nie, prawda lub fałsz, 0 lub 1. Przewidywane prawdopodobieństwo lub wynik regresji logistycznej może być jednym z nich i nie ma pośredniego punktu.
W przypadku zmiennych predykcyjnych mogą one należeć do dowolnej z następujących kategorii:
- Dane ciągłe: dane, które można zmierzyć w nieskończonej skali. Może przyjąć dowolną wartość między dwiema liczbami. Przykładami są waga w funtach lub temperatura w stopniach Fahrenheita.
- Dyskretne, nominalne dane: dane pasujące do nazwanych kategorii. Szybkim przykładem jest kolor włosów: blond, czarny lub brązowy.
- Dane dyskretne, porządkowe: Dane, które pasują do jakiejś formy porządku na skali. Przykładem jest określenie, w jakim stopniu jesteś zadowolony z produktu lub usługi w skali od jednego do pięciu.
Analiza regresji logistycznej jest przydatna do przewidywania prawdopodobieństwa zdarzenia. Pomaga określić prawdopodobieństwa między dowolnymi dwiema klasami.

Krótko mówiąc, patrząc na dane historyczne, regresja logistyczna może przewidzieć, czy:
- E-mail to spam
- Będzie dziś padać
- Guz jest śmiertelny
- Osoba fizyczna kupi samochód
- Transakcja online jest fałszywa
- Zawodnik wygra wybory
- Grupa użytkowników kupi produkt
- Ubezpieczający wygaśnie przed upływem okresu obowiązywania polisy
- Odbiorca promocyjnej poczty e-mail to osoba odpowiadająca lub nieodpowiadająca
W istocie regresja logistyczna pomaga rozwiązywać problemy z prawdopodobieństwem i klasyfikacją . Innymi słowy, z regresji logistycznej można oczekiwać jedynie wyników klasyfikacji i prawdopodobieństwa.
Na przykład można go użyć do określenia prawdopodobieństwa, że coś jest „prawdą lub fałszem”, a także do decydowania między dwoma wynikami, takimi jak „tak lub nie”.
Model regresji logistycznej może również pomóc w klasyfikowaniu danych do operacji wyodrębniania, przekształcania i ładowania (ETL). Regresji logistycznej nie należy stosować, jeśli liczba obserwacji jest mniejsza niż liczba cech. W przeciwnym razie może to prowadzić do nadmiernego dopasowania.
Regresja liniowa a regresja logistyczna
Podczas gdy regresja logistyczna przewiduje zmienną kategorialną dla jednej lub więcej zmiennych niezależnych, regresja liniowa przewiduje zmienną ciągłą. Innymi słowy, regresja logistyczna zapewnia stały wynik, podczas gdy regresja liniowa zapewnia stały wynik.
Ponieważ wynik jest ciągły w regresji liniowej, istnieje nieskończona liczba możliwych wartości wyniku. Ale w przypadku regresji logistycznej liczba możliwych wartości wyników jest ograniczona.
W regresji liniowej zmienne zależne i niezależne powinny być liniowo powiązane. W przypadku regresji logistycznej zmienne niezależne powinny być liniowo powiązane z loguj szanse (log (p/(1-p)).
Wskazówka: Regresję logistyczną można zaimplementować w dowolnym języku programowania używanym do analizy danych, takim jak R, Python, Java i MATLAB.
Podczas gdy regresja liniowa jest szacowana przy użyciu zwykłej metody najmniejszych kwadratów, regresja logistyczna jest szacowana przy użyciu podejścia estymacji największego prawdopodobieństwa.
Zarówno regresja logistyczna, jak i liniowa są nadzorowane uczenie maszynowe algorytmy i dwa główne typy analizy regresji. Podczas gdy regresja logistyczna jest używana do rozwiązywania problemów klasyfikacji, regresja liniowa jest używana głównie do problemów regresji.
Wracając do przykładu czasu spędzonego na nauce, regresja liniowa i regresja logistyczna mogą przewidywać różne rzeczy. Regresja logistyczna może pomóc przewidzieć, czy uczeń zdał egzamin, czy nie. Natomiast regresja liniowa może przewidzieć wynik ucznia.
Założenia regresji logistycznej
Korzystając z regresji logistycznej przyjmujemy kilka założeń. Założenia są niezbędne do prawidłowego wykorzystania regresji logistycznej do przewidywania i rozwiązywania problemów klasyfikacyjnych.
Oto główne założenia regresji logistycznej:
- Między zmiennymi niezależnymi występuje niewielka lub żadna współliniowość .
- Zmienne niezależne są liniowo powiązane z logarytmem szans (log (p/(1-p)).
- Zmienna zależna jest dychotomiczna lub binarna ; pasuje do dwóch odrębnych kategorii. Dotyczy to tylko binarnej regresji logistycznej, która jest omówiona później.
- Nie ma nieistotnych zmiennych , ponieważ mogą one prowadzić do błędów.
- Rozmiary próbek danych są większe , co jest integralną częścią dla lepszych wyników.
- Nie ma wartości odstających .
Rodzaje regresji logistycznej
Regresję logistyczną można podzielić na różne typy na podstawie liczby wyników lub kategorii zmiennej zależnej.
Kiedy myślimy o regresji logistycznej, najprawdopodobniej myślimy o binarnej regresji logistycznej. W większości części tego artykułu, kiedy odnosiliśmy się do regresji logistycznej, odnosiliśmy się do binarnej regresji logistycznej.
Poniżej przedstawiono trzy główne typy regresji logistycznej.
Binarna regresja logistyczna
Binarna regresja logistyczna to metoda statystyczna stosowana do przewidywania związku między zmienną zależną a zmienną niezależną. W tej metodzie zmienna zależna jest zmienną binarną, co oznacza, że może przyjmować tylko dwie wartości (tak lub nie, prawda lub fałsz, sukces lub porażka, 0 lub 1).
Prostym przykładem binarnej regresji logistycznej jest określenie, czy wiadomość e-mail jest spamem, czy nie.
Wielomianowa regresja logistyczna
Wielomianowa regresja logistyczna jest rozszerzeniem binarnej regresji logistycznej. Pozwala na więcej niż dwie kategorie wyniku lub zmiennej zależnej.
Jest podobny do binarnej regresji logistycznej, ale może mieć więcej niż dwa możliwe wyniki. Oznacza to, że zmienna wynikowa może mieć trzy lub więcej możliwych typów nieuporządkowanych – typów niemających znaczenia ilościowego. Na przykład zmienna zależna może reprezentować „Typ A”, „Typ B” lub „Typ C”.
Podobnie jak w przypadku binarnej regresji logistycznej, wielomianowa regresja logistyczna wykorzystuje również oszacowanie maksymalnego prawdopodobieństwa do określenia prawdopodobieństwa.
Na przykład wielomianowa regresja logistyczna może być wykorzystana do badania związku między wykształceniem a wyborami zawodowymi. Tutaj wybory zawodowe będą zmienną zależną, na którą składają się kategorie różnych zawodów.
Porządkowa regresja logistyczna
Porządkowa regresja logistyczna , znana również jako porządkowa regresja, jest kolejnym rozszerzeniem binarnej regresji logistycznej. Służy do przewidywania zmiennej zależnej z trzema lub więcej możliwymi typami uporządkowanymi – typami o istotności ilościowej. Na przykład zmienna zależna może reprezentować „zdecydowanie się nie zgadzam”, „nie zgadzam się”, „zgadzam się” lub „zdecydowanie się zgadzam”.
Może być używany do określenia wydajności pracy (słaba, średnia lub doskonała) oraz satysfakcji z pracy (niezadowolony, zadowolony lub bardzo zadowolony).
Zalety i wady regresji logistycznej
Wiele zalet i wad modelu regresji logistycznej dotyczy modelu regresji liniowej. Jedną z najważniejszych zalet modelu regresji logistycznej jest to, że nie tylko klasyfikuje, ale także podaje prawdopodobieństwa.
Oto niektóre z zalet algorytmu regresji logistycznej.
- Prosty do zrozumienia, łatwy do wdrożenia i wydajny w szkoleniu
- Działa dobrze, gdy zestaw danych można liniowo oddzielić
- Dobra dokładność dla mniejszych zbiorów danych
- Nie robi żadnych założeń dotyczących dystrybucji klas
- Oferuje kierunek skojarzenia (pozytywny lub negatywny)
- Przydatne do znalezienia relacji między funkcjami
- Zapewnia dobrze skalibrowane prawdopodobieństwa
- Mniej podatne na nadmierne dopasowanie w niskowymiarowych zestawach danych
- Możliwość rozszerzenia do klasyfikacji wieloklasowej
Istnieje jednak wiele wad regresji logistycznej. Jeśli istnieje funkcja, która idealnie rozdzielałaby dwie klasy, wtedy modelu nie można już trenować. Nazywa się to całkowitym oddzieleniem .
Dzieje się tak głównie dlatego, że waga tej cechy nie byłaby zbieżna, ponieważ optymalna waga byłaby nieskończona. Jednak w większości przypadków całkowite oddzielenie można rozwiązać, określając wcześniejszy rozkład prawdopodobieństwa wag lub wprowadzając penalizację wag.
Oto niektóre z wad algorytmu regresji logistycznej:
- Konstruuje granice liniowe
- Może prowadzić do nadmiernego dopasowania, jeśli liczba cech jest większa niż liczba obserwacji
- Predyktory powinny mieć średnią lub brak współliniowości
- Trudne do uzyskania złożonych relacji. Algorytmy, takie jak sieci neuronowe, są bardziej odpowiednie i wydajne
- Może być używany tylko do przewidywania funkcji dyskretnych
- Nie można rozwiązać problemów nieliniowych
- Wrażliwy na wartości odstające
Kiedy życie daje ci możliwości, pomyśl o regresji logistycznej
Wielu może twierdzić, że ludzie nie żyją w świecie binarnym, w przeciwieństwie do komputerów. Oczywiście, jeśli dostaniesz kawałek pizzy i hamburgera, możesz ugryźć oba bez konieczności wybierania tylko jednego. Ale jeśli przyjrzysz się temu bliżej, decyzja binarna jest wygrawerowana na (dosłownie) wszystkim. Możesz albo zjeść pizzę, albo nie; nie ma kompromisu.
Ocena wydajności modelu predykcyjnego może być trudna, jeśli ilość danych jest ograniczona. W tym celu można użyć techniki zwanej walidacją krzyżową, która polega na podzieleniu dostępnych danych na zbiór uczący i zbiór testowy.