
Identyfikacja relacji atrybutu podmiotu
Opublikowany: 2022-03-02Ten patent, przyznany 1 marca 2022 r., dotyczy identyfikowania relacji jednostka-atrybut w treści tekstu.
Aplikacje wyszukujące, takie jak wyszukiwarki i bazy wiedzy, starają się zaspokoić potrzeby informacyjne osoby wyszukującej i pokazać jej najkorzystniejsze zasoby .
Dane strukturalne mogą pomóc w lepszym identyfikowaniu relacji atrybutów
Identyfikowanie relacji między jednostkami atrybutów odbywa się w ustrukturyzowanych wynikach wyszukiwania.
Wyniki wyszukiwania strukturalnego przedstawiają listę atrybutów z odpowiedziami dla jednostki określonej w żądaniu użytkownika, takiej jak zapytanie .
Tak więc ustrukturyzowane wyniki wyszukiwania hasła „Kevin Durant” mogą zawierać atrybuty, takie jak wynagrodzenie, zespół, rok urodzenia, rodzina itp., wraz z odpowiedziami zawierającymi informacje o tych atrybutach .
Konstruowanie takich ustrukturyzowanych wyników wyszukiwania może wymagać zidentyfikowania relacji jednostka-atrybut.
Relacja encja-atrybut jest szczególnym przypadkiem relacji tekstowej między parą terminów.
Pierwszy termin w parze terminów to jednostka, osoba, miejsce, organizacja lub pojęcie.
Drugi termin to atrybut lub ciąg znaków opisujący aspekt jednostki.
Przykłady obejmują:
- „Data urodzenia” osoby
- „Ludność” kraju
- „Wynagrodzenie” sportowca
- „CEO” organizacji
Dostarczenie większej ilości informacji w treści i schemacie (oraz danych strukturalnych) o podmiotach daje wyszukiwarce więcej informacji do wyszukiwania lepszych informacji o konkretnych podmiotach, testowania i zbierania danych, uściślania tego, co wie, oraz do coraz większego zaufania do podmiotów, które jest tego świadomy.
Pary jednostka-atrybut kandydat
Ten patent pozwala uzyskać parę kandydującą jednostka-atrybut w celu zdefiniowania jednostki i atrybutu, przy czym atrybut jest atrybutem kandydującym jednostki . Oprócz uczenia się na podstawie faktów na temat podmiotów w danych strukturalnych, Google może wykorzystywać informacje, analizując kontekst tych informacji i uczyć się na podstawie wektorów oraz współwystępowania innych słów i faktów dotyczących tych podmiotów.
Przyjrzyj się patentowi na wektory słów, aby dowiedzieć się, w jaki sposób wyszukiwarka może teraz lepiej rozumieć znaczenia i kontekst słów oraz informacje o podmiotach. (Jest to szansa, aby dowiedzieć się z badania patentów o tym, jak Google obecnie robi niektóre z tych rzeczy, które robi.) Google gromadzi fakty i dane o rzeczach, które indeksuje, i może dowiedzieć się o podmiotach, które ma w swoim indeksie, oraz atrybuty, które o nich wie.
Robi to w:
- Określanie za pomocą zdań zawierających encję i atrybut, czy atrybut jest rzeczywistym atrybutem encji w parze encja-atrybut kandydata
- Generowanie osadzeń dla słów w zbiorze zdań, które zawierają encję i atrybut
- Tworzenie, ze znanymi parami encja-atrybut, osadzanie atrybutów dystrybucyjnych dla encji, gdzie osadzanie atrybutów dystrybucyjnych dla encji określa osadzanie dla encji na podstawie innych atrybutów skojarzonych z encją ze znanych par encja-atrybut
- Na podstawie osadzania słów w zdaniach, osadzania atrybutu dystrybucyjnego dla encji oraz dla atrybutu, czy para kandydująca encja-atrybut jest podstawowym atrybutem jednostki w parze kandydującej encja-atrybut.
Osadzania słów tworzą zdania z jednostką i atrybutem
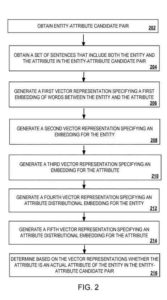
Budowanie pierwszej reprezentacji wektorowej określającej pierwsze osadzenie słów między jednostką a punktem w zbiorze zdań
- Tworzenie drugiej reprezentacji wektorowej definiującej podwójne osadzenie dla encji na podstawie zbioru zdań
- Konstruowanie trzeciej reprezentacji wektorowej dla trzeciego osadzenia atrybutu na podstawie zbioru zdań
- Wybieranie, ze znanym atrybutem encji, łączy osadzanie atrybutu dystrybucyjnego dla encji, oznacza utworzenie czwartej reprezentacji wektorowej, używając dostępnych par encja-atrybut, określając osadzanie atrybutu dystrybucyjnego dla encji.
- Tworzenie osadzania atrybutów dystrybucyjnych za pomocą tych znanych par encja-atrybut oznacza opracowanie piątej reprezentacji wektorowej z dostępnymi zespołami encja-atrybut oraz osadzanie atrybutów dystrybucyjnych dla atrybutu .
- Decydowanie, na podstawie osadzeń słów w zbiorze zdań, osadzenia atrybutu dystrybucyjnego dla encji i osadzenia atrybutu dystrybucyjnego dla atrybutu, czy atrybut w parze encja-kandydat atrybutu jest istotnym atrybutem jednostki w para encja-atrybut kandydat
- Określanie, na podstawie pierwszej reprezentacji wektorowej, drugiej reprezentacji wektorowej, trzeciej reprezentacji wektorowej, czwartej reprezentacji wektorowej i piątej reprezentacji wektorowej, czy atrybut w parze encja-atrybut kandydujący jest podstawowym atrybutem encji w encji -atrybut pary kandydatów
- Wybór, z pierwszej reprezentacji wektorowej, drugiej reprezentacji wektorowej, trzeciej reprezentacji wektorowej, czwartej reprezentacji wektorowej i piątej reprezentacji wektorowej, czy atrybut w parze encja-atrybut kandydujący jest niezbędnym atrybutem encji w encji- para kandydujących atrybutów, wykonaj przy użyciu sieci sprzężenia zwrotnego.
- Wybór, w oparciu o pierwszą reprezentację wektorową, drugą reprezentację wektorową, trzecią reprezentację wektorową, czwartą reprezentację wektorową i piątą reprezentację wektorową, czy atrybut w parze encja-atrybut kandydujący jest istotnym atrybutem encji w encji - para kandydatów atrybutów obejmuje:
- Generowanie pojedynczej reprezentacji wektorowej przez połączenie pierwszej reprezentacji wektorowej, drugiej reprezentacji wektorowej, trzeciej reprezentacji wektorowej, czwartej reprezentacji wektorowej i piątej reprezentacji wektorowej; wprowadzanie reprezentacji pojedynczego wektora do sieci sprzężenia do przodu
- Określanie, przez sieć sprzężenia do przodu i przy użyciu reprezentacji pojedynczego wektora, czy atrybut w parze jednostka-kandydat atrybutu jest podstawowym atrybutem jednostki w parze jednostka-kandydat atrybutu
Tworzenie czwartej reprezentacji wektorowej, ze znanymi parami jednostka-atrybut, określająca osadzenie atrybutu dystrybucyjnego dla jednostki obejmuje:
- Identyfikowanie zestawu atrybutów powiązanych z podmiotem w znanych zespołach podmiot-atrybut, przy czym zestaw atrybutów pomija atrybut
- Generowanie osadzenia atrybutu dystrybucyjnego dla podmiotu poprzez obliczenie sumy ważonej cech w zbiorze atrybutów
Wybór piątej reprezentacji wektorowej, ze znanymi parami encja-atrybut, określający osadzenie atrybutu dystrybucyjnego dla atrybutu obejmuje
- Identyfikowanie za pomocą atrybutu zbioru encji spośród znanych par encja-atrybut; dla każdego podmiotu w zbiorze podmiotów
- Ustalenie zbioru cech powiązanych z podmiotem, gdzie lokalizacja atrybutów nie obejmuje atrybutu
- Generowanie osadzenia atrybutu dystrybucyjnego dla podmiotu poprzez obliczenie sumy ważonej cech w zbiorze atrybutów
Przewaga dokładniejszych relacji jednostka-atrybut nad identyfikacją jednostek i atrybutów opartą na modelu ze stanu techniki
Wcześniejsze techniki identyfikacji encji i atrybutów w sztuce wykorzystywały podejścia oparte na modelach, takie jak funkcje przetwarzania języka naturalnego (NLP), zdalny nadzór i tradycyjne modele uczenia maszynowego, które identyfikują relacje encja-atrybut poprzez reprezentowanie encji i atrybutów na podstawie zdań danych. Pojawiają się te terminy .
W przeciwieństwie do tego, innowacje opisane w tej specyfikacji identyfikują relacje encja-atrybut w zbiorach danych, wykorzystując informacje o tym, jak encje i atrybuty są wyrażane w danych, w których pojawiają się te terminy, oraz reprezentując encje i atrybuty przy użyciu innych cech, o których wiadomo, że są kojarzone z te warunki . Umożliwia to reprezentowanie encji i atrybutów ze szczegółami współdzielonymi przez podobne encje, poprawiając dokładność identyfikowania relacji encja-atrybut, których inaczej nie można by rozpoznać, biorąc pod uwagę zdania, w których występują te terminy .
Rozważmy na przykład scenariusz, w którym zbiór danych zawiera zdania, które mają dwie encje, „Ronaldo” i „Messi”, opisane za pomocą atrybutu „rekord” oraz karę, w której encja „Messi” zostaje opisana za pomocą „celi” atrybut . W takim scenariuszu techniki ze stanu techniki mogą identyfikować następujące pary atrybutów jednostki: (Ronaldo, zapis), (Messi, log) i (Messi, cele) . Innowacje opisane w tej specyfikacji wykraczają poza te podejścia ze stanu techniki, identyfikując relacje jednostka-atrybut, których nie można rozróżnić na podstawie tego, jak te terminy są używane w zbiorze danych .
Korzystając z powyższego przykładu, innowacja opisana w tej specyfikacji określa, że „Ronaldo” i „Messi” są podobnymi podmiotami, ponieważ mają wspólny atrybut „rekord”, a następnie reprezentują atrybut „rekord” za pomocą atrybutu „goals” . W ten sposób innowacje opisane w tej specyfikacji mogą na przykład umożliwić identyfikację relacji encja-atrybut, np. (Cristiano, Goals), nawet jeśli taka relacja może nie być dostrzegalna ze zbioru danych .
Patent na powiązania atrybutów identyfikujących
Identyfikowanie relacji atrybutów encji
Wynalazcy: Dan Iter, Xiao Yu i Fangtao Li
Pełnomocnik: Google LLC
Patent USA: 11 263 400
Przyznano: 1 marca 2022
Złożono: 5 lipca 2019 r.
Abstrakcyjny
Metody, systemy i aparatura, w tym programy komputerowe zakodowane na komputerowym nośniku pamięci, które ułatwiają identyfikację relacji jednostka-atrybut w korpusach tekstowych .Metody obejmują określenie, czy atrybut w parze kandydująca jednostka-atrybut jest rzeczywistym atrybutem jednostki w parze kandydująca jednostka-atrybut .Obejmuje to generowanie osadzeń dla słów w zbiorze zdań zawierających encję i atrybut oraz generowanie przy użyciu znanych par encja-atrybut .Obejmuje to również generowanie osadzania dystrybucyjnego atrybutu dla jednostki na podstawie innych atrybutów powiązanych z jednostką ze znanych par jednostka-atrybut oraz generowanie osadzania dystrybucyjnego atrybutu dla atrybutu na podstawie znanych atrybutów powiązanych ze znanymi jednostkami atrybutu w znanym pary jednostka-atrybut .Na podstawie tych osadzeń sieć feedforward określa, czy atrybut w parze jednostka-kandydat atrybutu jest rzeczywistym atrybutem jednostki w parze jednostka-kandydat atrybutu .
Identyfikowanie relacji atrybutów encji w tekście
Para encja-atrybut kandydata (gdzie atrybut jest atrybutem kandydata encji) jest wprowadzana do modelu klasyfikacji . Model klasyfikacji wykorzystuje aparat osadzania ścieżki, aparat reprezentacji dystrybucji, aparat atrybutów i sieć przekazywania. Określa, czy atrybut w parze encja-atrybut kandydujący jest jednostką podstawową w parze encja-atrybut kandydujący .
Mechanizm osadzania ścieżek generuje wektor reprezentujący osadzanie ścieżek lub słów łączących codzienne wystąpienia jednostki i atrybutu w zestawie zdań (np. 30 lub więcej zdań) zestawu danych . Mechanizm reprezentacji dystrybucyjnej generuje wektory reprezentujące osadzanie dla jednostki i terminy atrybutów na podstawie kontekstu, w którym te terminy pojawiają się w zbiorze zdań . Dystrybucyjny aparat atrybutów generuje wektor reprezentujący osadzanie dla jednostki i inny wektor reprezentujący osadzanie dla atrybutu .
Osadzanie aparatu dystrybucji atrybutów dla jednostki jest oparte na innych cechach (tj. atrybutach innych niż atrybut kandydata), o których wiadomo, że są powiązane z jednostką w zbiorze danych . Osadzanie szczegółowego silnika dystrybucyjnego dla jakości jest oparte na różnych cechach powiązanych ze znanymi encjami atrybutu kandydata .
Model klasyfikacji łączy reprezentacje wektorowe z mechanizmu osadzania ścieżki, mechanizmu reprezentacji dystrybucyjnej i mechanizmu atrybutów dystrybucyjnych w jedną reprezentację wektorową. Model klasyfikacji następnie wprowadza reprezentację pojedynczego wektora do sieci sprzężenia do przodu, która za pomocą reprezentacji pojedynczego wektora określa, czy atrybut w kandydującej parze jednostka-atrybut jest podstawowym atrybutem jednostki w kandydującej parze jednostka-atrybut .
Załóżmy, że sieć feedforward określa, że punkt w kandydującej parze jednostka-atrybut jest niezbędny dla jednostki w kandydującej parze jednostka-atrybut. W takim przypadku kandydująca para encja-atrybut jest przechowywana w bazie wiedzy wraz z innymi znanymi/rzeczywistymi parami encja-atrybut .
Wyodrębnianie relacji atrybutów encji
Środowisko obejmuje model klasyfikacji, który w przypadku kandydujących par encja-atrybut w bazie wiedzy określa, czy atrybut w kandydującej parze encja-atrybut jest podstawowym atrybutem encji w parze kandydującej . Model klasyfikacji jest modelem sieci neuronowej, a komponenty zostały opisane poniżej . Model klasyfikacji może być również używany z innymi nadzorowanymi i nienadzorowanymi modelami uczenia maszynowego .
Baza wiedzy, która może obejmować bazy danych (lub inne odpowiednie struktury przechowywania danych) przechowywane na nośnikach przechowywania danych nieprzemijających (np. dyskach twardych, pamięci flash itp.), zawiera zestaw kandydujących par encja-atrybut . Kandydujące pary jednostka-atrybut są uzyskiwane przy użyciu zestawu treści w dokumentach tekstowych, takich jak strony internetowe i artykuły z wiadomościami, uzyskanego ze źródła danych. Źródło danych może obejmować dowolne źródło treści, takie jak witryna z wiadomościami, platforma agregatorów danych, platforma mediów społecznościowych itp .
Źródło danych pozyskuje artykuły prasowe z platformy agregatora danych. Źródło danych może korzystać z modelu. Nadzorowany lub nienadzorowany model uczenia maszynowego (model przetwarzania języka naturalnego) generuje zestaw kandydujących par encja-atrybut, wyodrębniając zdania z artykułów oraz tokenizując i oznaczając wyodrębnione zdania, np. jako encje i atrybuty, przy użyciu części mowy i zależności analizują tagi drzewa .
Źródło danych może wprowadzić wyodrębnione zdania do modelu uczenia maszynowego. Na przykład może zostać przeszkolony za pomocą zestawu zdań szkoleniowych i powiązanych z nimi par encja-atrybut . Taki model uczenia maszynowego może następnie wyprowadzać kandydujące zespoły encji i atrybutów dla danych wejściowych wyodrębnionych zdań .
W bazie wiedzy źródło danych przechowuje kandydujące pary jednostka-atrybut oraz zdania wyodrębnione ze źródła danych, które zawierają słowa kandydujących par jednostka-atrybut . Kandydujące pary encja-atrybut są przechowywane w bazie wiedzy tylko wtedy, gdy liczba zdań, w których występuje encja i atrybut, spełnia (np. spełnia lub przekracza) progową liczbę zdań (np. 30 zdań) .
Model klasyfikacji określa, czy atrybut w kandydującej parze encja-atrybut (przechowywany w bazie wiedzy) jest rzeczywistym atrybutem encji w kandydującej parze encja-atrybut . Model klasyfikacji obejmuje mechanizm osadzania ścieżki 106, dystrybucyjne źródło reprezentacji, mechanizm atrybutów i sieć ze sprzężeniem do przodu . Stosowany tu termin silnik odnosi się do urządzenia do przetwarzania danych, które wykonuje zestaw zadań. Operacje tych aparatów modelu klasyfikacji podczas określania, czy atrybut w parze encja-atrybut kandydata jest podstawowym atrybutem encji .
Przykładowy proces identyfikacji relacji atrybutów jednostek
Operacje procesu są opisane poniżej jako wykonywane przez komponenty systemu, a funkcje procesu są opisane poniżej wyłącznie w celach ilustracyjnych. Operacje procesu mogą być realizowane przez dowolne odpowiednie urządzenie lub system, np. dowolne odpowiednie urządzenie do przetwarzania danych . Funkcje procesu mogą również zostać zaimplementowane jako instrukcje przechowywane na trwałym nośniku do odczytu komputerowego . Wykonanie instrukcji powoduje, że aparat przetwarzający dane wykonuje operacje procesu .
Baza wiedzy uzyskuje parę kandydatów encja-atrybut ze źródła danych.
Baza wiedzy uzyskuje zestaw zdań ze źródła danych, które zawierają słowa encji i atrybut w kandydującej parze encja-atrybut .
Na podstawie zestawu zdań i pary encja-atrybut kandydata model klasyfikacji określa, czy atrybut kandydata jest rzeczywistym atrybutem encji kandydata . Zestaw kar może składać się z dużej liczby zdań, np. 30 lub więcej zdań.
Model klasyfikacji wykonujący następujące operacje
- Osadzania słów w zbiorze zdań, które zawierają encję i atrybut, opisano bardziej szczegółowo poniżej w odniesieniu do poniższego procesu
- Utworzony przy użyciu znanych par encja-atrybut, osadzenie atrybutu dystrybucyjnego dla encji, który zostanie szczegółowo opisany poniżej dotyczący operacji
- Budowanie przy użyciu znanych par encja-atrybut oraz osadzenie atrybutu dystrybucyjnego dla atrybutu, który zostanie szczegółowo opisany poniżej dotyczący działania
- Wybór, w oparciu o osadzania słów w zbiorze zdań, osadzanie atrybutu dystrybucyjnego dla encji i osadzanie atrybutu dystrybucyjnego dla atrybutu, czy atrybut w parze encja-kandydat atrybutu jest istotnym atrybutem jednostki w para kandydująca jednostka-atrybut, która zostanie szczegółowo opisana poniżej w odniesieniu do operacji .
Mechanizm osadzania ścieżki generuje pierwszą reprezentację wektorową, określając pierwsze słowa osadzone między jednostką a atrybutem w zdaniach . Mechanizm osadzania ścieżek wykrywa relacje między kandydującymi terminami atrybutów encji, osadzając ścieżki lub słowa, które łączą codzienne wystąpienia tych terminów w zestawie zdań .
W przypadku wyrażenia „wąż jest gadem” silnik osadzania ścieżki generuje osadzanie dla ścieżki „jest a”, które można wykorzystać do wykrywania np. relacji rodzaj-gatunek, które można następnie przyzwyczaić do identyfikacji innej jednostki-atrybutu pary .
Generowanie słów między bytem a atrybutem
Mechanizm osadzania ścieżki wykonuje następujące czynności, aby wygenerować słowa między jednostką a atrybutem w zdaniach . Dla każdego zdania w zestawie zdań aparat osadzania ścieżki najpierw wyodrębnia ścieżkę zależności (która określa grupę słów) między jednostką a atrybutem . Mechanizm osadzania ścieżki konwertuje zdanie z ciągu na listę, gdzie pierwszy termin to jednostka, a ostatni to atrybut (lub pierwszy termin to atrybut, a poprzedni to jednostka) .
Każdy termin (nazywany również krawędzią) na ścieżce zależności jest reprezentowany za pomocą następujących funkcji: lemat terminu, znacznik części mowy, etykieta zależności i kierunek ścieżki zależności (po lewej , prawo lub korzeń) . Każda z tych cech zostaje osadzona i połączona w celu wytworzenia reprezentacji wektorowej terminu lub krawędzi (Ve), która zawiera sekwencję wektorów (Vl, Vpos, Vdep , Vdir), jak pokazano w poniższym równaniu: {strzałka w prawo nad (v)}.e=[{strzałka w prawo nad (v)}.l,{strzałka w prawo nad (v)} .sub.pos,{strzałka w prawo nad (v)}.sub.dep,{strzałka w prawo nad (v)}.sub.dir]
Silnik osadzania ścieżki następnie wprowadza sekwencję wektorów dla terminów lub krawędzi w każdej ścieżce do sieci pamięci długo-krótkotrwałej (LSTM), która tworzy pojedynczą reprezentację wektorową dla zdania (Vs), jak pokazano za pomocą poniższe równanie: {strzałka w prawo nad (v)}.s=LSTM({strzałka w prawo nad (v)}.e(1) .. {strzałka w prawo nad (v)}.sub np.(k))
Wreszcie, mechanizm osadzania ścieżki wprowadza reprezentację pojedynczego wektora dla wszystkich zdań w zbiorze zdań do mechanizmu uwagi, który określa średnią ważoną reprezentacji zdań (Vsub.sents(e,a)), jak pokazano poniżej równanie: {strzałka w prawo nad (v)}.sents(e,a)=ATTN({strzałka w prawo nad (v)}.ssup.(1) ... {strzałka w prawo nad (v ) )}.sub.sup.(n))
Dystrybucyjny model reprezentacyjny generuje drugą reprezentację wektorową dla encji i trzecią reprezentację wektorową dla atrybutu na podstawie zdań . Aparat reprezentacji dystrybucyjnej wykrywa relacje między kandydującymi terminami encja-atrybut na podstawie kontekstu, w którym punkt i encja kandydującej pary encja-atrybut występują w zbiorze zdań . Na przykład mechanizm reprezentacji dystrybucji może określić, że encja „Nowy Jork” zostanie użyta w zbiorze zdań w sposób sugerujący, że ta encja odnosi się do miasta lub stanu w Stanach Zjednoczonych .
Jako inny przykład, mechanizm reprezentacji dystrybucji może określić, że atrybut „kapitał” jest używany w zbiorze zdań w sposób sugerujący, że ten atrybut odnosi się do znaczącego miasta w stanie lub kraju . W ten sposób silnik reprezentacji dystrybucyjnej generuje reprezentację wektorową określającą osadzenie jednostki (Ve) przy użyciu kontekstu (tj. zbioru zdań), w którym pojawia się jednostka . Mechanizm reprezentacji dystrybucyjnej generuje reprezentację wektorową (Va) określając osadzanie atrybutu przy użyciu zestawu zdań, w których pojawia się cecha .
Aparat atrybutów dystrybucyjnych generuje czwartą reprezentację wektorową, określając osadzanie atrybutów dystrybucyjnych dla jednostki przy użyciu znanych par jednostka-atrybut . Znane pary encja-atrybut, które są przechowywane w bazie wiedzy, są parami encja-atrybut, dla których potwierdzono (np. przy użyciu wcześniejszego przetwarzania przez model klasyfikacji lub na podstawie oceny przez człowieka), że każdy atrybut w encji- para atrybutów jest podstawowym atrybutem jednostki w parze jednostka-atrybut .
Aparat atrybutów dystrybucyjnych wykonuje następujące operacje w celu określenia osadzania atrybutów dystrybucyjnych, które określa osadzanie dla jednostki przy użyciu niektórych (np. najbardziej powszechnych) lub wszystkich innych znanych atrybutów spośród znanych par jednostka-atrybut, z którymi ta jednostka jest skojarzona .
Identyfikacja innych atrybutów jednostek
W przypadku jednostek w parze jednostka-atrybut aparat atrybutów dystrybucyjnych identyfikuje atrybuty inne niż te, które znajdują się w parze jednostka-atrybut skojarzona z jednostką w znanych zespołach jednostka-atrybut .
W przypadku encji „Michael Jordan” w kandydującej parze encja-atrybut (Michael Jordan, sławny) aparat dystrybucji atrybutów może używać znanych par encja-atrybut dla Michaela Jordana, takich jak (Michael Jordan, bogaty) i (Michael Jordan, rekord), aby zidentyfikować atrybuty, takie jak zamożność i opis .
Silnik dystrybucji atrybutów generuje następnie osadzanie dla jednostki, obliczając ważoną sumę zidentyfikowanych znanych atrybutów (jak opisano w poprzednim akapicie), gdzie wagi są poznawane za pomocą mechanizmu uwagi, jak pokazano w poniższym równaniu: {right strzałka nad (v)}.e=ATTN(.epsilon.(alfa.1) .....epsilon .(.alfa.m))
Aparat atrybutów dystrybucyjnych generuje piątą reprezentację wektora, określając osadzanie atrybutu dystrybucyjnego dla atrybutu przy użyciu znanych par jednostka-atrybut . Aparat atrybutów dystrybucyjnych wykonuje następujące operacje w celu określenia modelu na podstawie niektórych (najczęstszych) lub wszystkich znanych atrybutów skojarzonych ze znanymi jednostkami atrybutu kandydata .
Dla punktu w parze encja-atrybut aparat atrybutów dystrybucyjnych identyfikuje znane encje wśród znanych par encja-atrybut, które mają jakość .
Dla każdej zidentyfikowanej znanej jednostki mechanizm atrybutów dystrybucyjnych identyfikuje inne atrybuty (tj. atrybuty inne niż te zawarte w parze encja-atrybut kandydata) powiązane z encją w znanych zespołach jednostka-atrybut . Mechanizm atrybutów dystrybucyjnych może identyfikować podzbiór atrybutów spośród zidentyfikowanych atrybutów poprzez:
(1) Atrybuty rankingowe oparte na liczbie znanych podmiotów powiązanych z każdym podmiotem, takie jak przypisanie wyższej rangi atrybutom powiązanym z większą liczbą podmiotów niż atrybutom powiązanym z mniejszą liczbą podmiotów)
Przeszukaj wiadomości prosto do skrzynki odbiorczej
*Wymagany