
Identificazione delle relazioni di attributo dell'entità
Pubblicato: 2022-03-02Questo brevetto, concesso il 1 marzo 2022, riguarda l'identificazione delle relazioni entità-attributo nei corpi di testo.
Le applicazioni di ricerca, come i motori di ricerca e le basi di conoscenza, cercano di soddisfare le esigenze informative di un ricercatore e mostrano le risorse più vantaggiose per il ricercatore .
I dati strutturati possono aiutare a identificare meglio le relazioni di attributo
L'identificazione delle relazioni tra entità degli attributi viene eseguita nei risultati di ricerca strutturati.
I risultati della ricerca strutturata presentano un elenco di attributi con risposte per un'entità specificata in una richiesta utente, ad esempio una query .
Pertanto, i risultati della ricerca strutturata per "Kevin Durant" possono includere attributi come stipendio, squadra, anno di nascita, famiglia e così via, insieme a risposte che forniscono informazioni su questi attributi .
La costruzione di tali risultati di ricerca strutturati può richiedere l'identificazione di relazioni entità-attributo.
Una relazione entità-attributo è un caso particolare di relazione testuale tra una coppia di termini.
Il primo termine nella coppia di termini è un'entità, una persona, un luogo, un'organizzazione o un concetto.
Il secondo termine è un attributo o una stringa che descrive un aspetto dell'entità.
Esempi inclusi:
- “Data di nascita” di una persona
- “Popolazione” di un Paese
- "Stipendio" dell'atleta
- "CEO" di un'organizzazione
Fornire più informazioni nel contenuto e nello schema (e nei dati strutturati) sulle entità fornisce a un motore di ricerca più informazioni per esplorare migliori informazioni sulle entità specifiche, per testare e raccogliere dati, chiarire ciò che sa e avere maggiore e migliore fiducia nelle entità che ne è consapevole.
Coppie di candidati entità-attributo
Questo brevetto ottiene una coppia candidata entità-attributo per definire un'entità e un attributo, dove l'attributo è un attributo candidato dell'entità . Oltre ad apprendere dai fatti sulle entità nei dati strutturati, Google può utilizzare le informazioni osservando il contesto di tali informazioni e imparare dai vettori e dalla co-occorrenza di altre parole e fatti anche su tali entità.
Dai un'occhiata al brevetto dei vettori di parole per avere un'idea di come un motore di ricerca possa ora avere un'idea migliore dei significati e del contesto delle parole e delle informazioni sulle entità. (Questa è un'opportunità per imparare dall'esplorazione dei brevetti su come Google sta ora facendo alcune delle cose che sta facendo.) Google raccoglie fatti e dati sulle cose che indicizza e potrebbe conoscere le entità che ha nel suo indice e il attributi che conosce su di loro.
Lo fa in:
- Determinare, con frasi che includono l'entità e l'attributo, se l'attributo è un attributo effettivo dell'entità nella coppia candidata entità-attributo
- Generazione di incorporamenti per parole nell'insieme di frasi che includono l'entità e l'attributo
- Creazione, con coppie entità-attributo note, un'inclusione di attributi distributivi per l'entità, in cui l'inclusione di attributi di distribuzione per l'entità specifica un'inclusione per l'entità basata su altri attributi associati all'entità dalle coppie entità-attributo note
- Basato sull'incorporamento per le parole nelle frasi, l'incorporamento dell'attributo distributivo per l'entità e per l'attributo, se la coppia candidata entità-attributo è un attributo essenziale dell'entità nella coppia candidata entità-attributo.
Gli incorporamenti per le parole sono fatti di frasi con l'entità e l'attributo
Costruire una prima rappresentazione vettoriale specificando il primo incorporamento di parole tra l'entità e il punto nell'insieme delle frasi
- Realizzare una seconda rappresentazione vettoriale definendo un doppio embedding per l'entità basata sull'insieme delle frasi
- Costruire una terza rappresentazione vettoriale per una terza incorporazione per l'attributo in base all'insieme di frasi
- Scegliere, con un attributo di entità noto, combina un incorporamento di attributo distributivo per l'entità, significa fare una quarta rappresentazione vettoriale, utilizzando le coppie entità-attributo disponibili, specificando l'incorporamento di attributo distributivo per l'entità.
- Costruire un'incorporamento di attributo distributivo con quelle coppie entità-attributo note significa sviluppare una quinta rappresentazione vettoriale con i team di entità-attributo disponibili e l'incorporamento di attributo distributivo per l'attributo .
- Decidere, sulla base dell'incorporamento delle parole nell'insieme delle frasi, dell'incorporamento dell'attributo distributivo per l'entità e dell'incorporamento dell'attributo distributivo per l'attributo, se l'attributo nella coppia candidata entità-attributo è un attributo essenziale dell'entità nel coppia candidata entità-attributo
- Determinare, in base alla prima rappresentazione vettoriale, alla seconda rappresentazione vettoriale, alla terza rappresentazione vettoriale, alla quarta rappresentazione vettoriale e alla quinta rappresentazione vettoriale, se l'attributo nella coppia candidata entità-attributo è un attributo essenziale dell'entità nell'entità -attributo coppia di candidati
- Scegliendo, dalla prima rappresentazione vettoriale, la seconda rappresentazione vettoriale, la terza rappresentazione vettoriale, la quarta rappresentazione vettoriale e la quinta rappresentazione vettoriale, se l'attributo nella coppia candidata entità-attributo è un attributo essenziale dell'entità nell'entità- attributo candidato coppia, ottenere eseguito utilizzando una rete feedforward.
- Scegliere, in base alla prima rappresentazione vettoriale, alla seconda rappresentazione vettoriale, alla terza rappresentazione vettoriale, alla quarta rappresentazione vettoriale e alla quinta rappresentazione vettoriale, se l'attributo nella coppia candidata entità-attributo è un attributo essenziale dell'entità nell'entità -attributo candidato coppia, comprende:
- Generazione di una singola rappresentazione vettoriale concatenando la prima rappresentazione vettoriale, la seconda rappresentazione vettoriale, la terza rappresentazione vettoriale, la quarta rappresentazione vettoriale e la quinta rappresentazione vettoriale; inserendo la rappresentazione del singolo vettore nella rete feedforward
- Determinare, mediante la rete feedforward e utilizzando la rappresentazione vettoriale singola, se l'attributo nella coppia candidata entità-attributo è un attributo essenziale dell'entità nella coppia candidata entità-attributo
Realizzare una quarta rappresentazione vettoriale, con coppie entità-attributo note, specificando l'incorporamento dell'attributo distributivo per l'entità comprende:
- Identificazione di un insieme di attributi associati all'entità nei team entità-attributo noti, in cui l'insieme di attributi omette l'attributo
- Generazione di un attributo distributivo incorporamento per l'entità calcolando una somma ponderata di caratteristiche nell'insieme di attributi
La scelta di una quinta rappresentazione vettoriale, con coppie entità-attributo note, specificando l'incorporamento dell'attributo distributivo per l'attributo comprende
- Identificare, utilizzando l'attributo, un insieme di entità tra le coppie entità-attributo note; per ciascuna entità nella raccolta di entità
- Determinazione di un insieme di caratteristiche associate all'entità, in cui la posizione degli attributi non include l'attributo
- Generazione di un attributo distributivo incorporamento per l'entità calcolando una somma ponderata di caratteristiche nella raccolta di attributi
Il vantaggio di relazioni entità-attributo più accurate rispetto all'identificazione di entità-attributo basata su modello della tecnica precedente
Le tecniche di identificazione entità-attributo dell'arte precedente utilizzavano approcci basati su modelli come le funzionalità di elaborazione del linguaggio naturale (NLP), la supervisione a distanza e i tradizionali modelli di apprendimento automatico, che identificano le relazioni entità-attributo rappresentando entità e attributi basati su frasi di dati. Appaiono questi termini .
Al contrario, le innovazioni descritte in questa specifica identificano le relazioni entità-attributo nei set di dati utilizzando informazioni su come le entità e gli attributi vengono espressi nei dati all'interno dei quali compaiono questi termini e rappresentando entità e attributi utilizzando altre caratteristiche che vengono conosciute per essere associate a questi termini . Ciò consente di rappresentare entità e attributi con dettagli condivisi da entità simili, migliorando l'accuratezza nell'identificare le relazioni entità-attributo che altrimenti non possono essere individuate considerando le frasi all'interno delle quali compaiono questi termini .
Ad esempio, considera uno scenario in cui il set di dati include frasi che hanno due entità, "Ronaldo" e "Messi", che vengono descritte utilizzando un attributo "record" e una penalità in cui l'entità "Messi" viene escritta utilizzando un "obiettivi" attributo . In tale scenario, le tecniche della tecnica anteriore possono identificare le seguenti coppie di attributi di entità: (Ronaldo, record), (Messi, log) e (Messi, obiettivi) . Le innovazioni descritte in questa descrizione vanno oltre questi approcci della tecnica anteriore identificando relazioni entità-attributo che potrebbero non essere individuate da come questi termini vengono utilizzati nel set di dati .
Utilizzando l'esempio sopra, l'innovazione descritta in questa specifica determina che “Ronaldo” e “Messi” sono entità simili perché condividono l'attributo “record” e quindi rappresentano l'attributo “record” utilizzando l'attributo “obiettivi” . In questo modo, le innovazioni descritte in questa specifica, ad esempio, possono consentire di identificare relazioni entità-attributo, ad esempio (Cristiano, Obiettivi), anche se tale relazione potrebbe non essere distinguibile dal dataset .
Il brevetto delle relazioni di attributo identificativo
Identificazione delle relazioni tra attributi di entità
Inventori: Dan Iter, Xiao Yu e Fangtao Li
Assegnatario: Google LLC
Brevetto USA: 11.263.400
Concesso: 1 marzo 2022
Archiviato: 5 luglio 2019
Astratto
Metodi, sistemi e apparati, inclusi programmi per computer codificati su un supporto di memorizzazione per computer, che facilitano l'identificazione delle relazioni entità-attributo nei corpora testuali .I metodi includono determinare se un attributo in una coppia candidata entità-attributo è un attributo effettivo dell'entità nella coppia candidata entità-attributo .Ciò include la generazione di incorporamenti per le parole nell'insieme di frasi che includono l'entità e l'attributo e la generazione, utilizzando coppie entità-attributo note .Ciò include anche la generazione di un'inclusione distributiva di attributo per l'entità basata su altri attributi associati all'entità dalle coppie entità-attributo note e la generazione di un'inclusione distributiva di attributo per l'attributo basato su attributi noti associati a entità note dell'attributo nel noto coppie entità-attributo .Sulla base di questi incorporamenti, una rete feedforward determina se l'attributo nella coppia candidata entità-attributo è un attributo effettivo dell'entità nella coppia candidata entità-attributo .
Identificazione delle relazioni di attributi di entità nel testo
Una coppia entità-attributo candidata (dove l'attributo è un attributo candidato di entità) viene immessa in un modello di classificazione . Il modello di classificazione utilizza un motore di incorporamento del percorso, un motore di rappresentazione distributiva, un motore di attributi e una rete feedforward. Determina se l'attributo nella coppia entità-attributo candidata è un'entità essenziale nella coppia entità-attributo candidata .
Il motore di path embedding genera un vettore che rappresenta un embedding dei percorsi o delle parole che collegano le occorrenze quotidiane dell'entità e dell'attributo in un insieme di frasi (es. 30 o più frasi) di un dataset . Il motore di rappresentazione distributiva genera vettori che rappresentano un embedding per l'entità e attribuisce i termini in base al contesto in cui questi termini compaiono nell'insieme delle frasi . Il motore degli attributi distributivi genera un vettore che rappresenta un'inclusione per l'entità e un altro vettore che rappresenta un'inclusione per l'attributo .
L'incorporamento del motore di distribuzione degli attributi per l'entità si basa su altre funzionalità (ad esempio, attributi diversi dall'attributo candidato) note per essere associate all'entità nel set di dati . L'incorporamento dettagliato del motore distributivo per la qualità si basa su diverse caratteristiche associate a entità note dell'attributo candidato .
Il modello di classificazione concatena le rappresentazioni vettoriali dal motore di incorporamento di path, dal motore di rappresentazione distributiva e dal motore di attributi di distribuzione in un'unica rappresentazione vettoriale. Il modello di classificazione quindi immette la rappresentazione del vettore singolo in una rete feedforward che determina, utilizzando la rappresentazione del vettore singolo, se l'attributo nella coppia entità-attributo candidata è un attributo essenziale dell'entità nella coppia entità-attributo candidata .
Supponiamo che la rete feedforward determini che il punto nella coppia entità-attributo candidata è necessario per l'entità nella coppia entità-attributo candidata. In tal caso, la coppia entità-attributo candidata viene archiviata nella knowledge base insieme ad altre coppie entità-attributo note/effettive .
Estrazione di relazioni di attributi di entità
L'ambiente include un modello di classificazione che, per le coppie entità-attributo candidate in una knowledge base, determina se un attributo in una coppia entità-attributo candidata è un attributo essenziale dell'entità nella coppia candidata . Il modello di classificazione è un modello di rete neurale e i componenti vengono descritti di seguito . Il modello di classificazione può essere utilizzato anche utilizzando altri modelli di apprendimento automatico supervisionati e non supervisionati .
La base di conoscenza, che può includere database (o altre strutture di archiviazione dati appropriate) archiviati in supporti di archiviazione dati non transitori (ad es. disco rigido, memoria flash, ecc.), contiene una serie di coppie entità-attributo candidate . Le coppie entità-attributo candidate vengono ottenute utilizzando una serie di contenuti in documenti di testo, come pagine Web e articoli di notizie, ottenuti da un'origine dati. L'origine dati può includere qualsiasi fonte di contenuto, come un sito Web di notizie, una piattaforma di aggregazione di dati, una piattaforma di social media, ecc .
La fonte di dati ottiene articoli di notizie da una piattaforma di aggregazione di dati. L'origine dati può utilizzare un modello. Il modello di apprendimento automatico supervisionato o non supervisionato (un modello di elaborazione del linguaggio naturale) genera un insieme di coppie entità-attributo candidate estraendo frasi dagli articoli e tokenizzando ed etichettando le frasi estratte, ad esempio, come entità e attributi, utilizzando parte del discorso e tag dell'albero di analisi delle dipendenze .
L'origine dati può inserire le frasi estratte in un modello di apprendimento automatico. Ad esempio, può essere addestrato utilizzando una serie di frasi di addestramento e le coppie entità-attributo associate . Un tale modello di apprendimento automatico può quindi produrre i team di attributi di entità candidati per le frasi estratte in input .
Nella knowledge base, l'origine dati memorizza le coppie entità-attributo candidate e le frasi estratte dall'origine dati che includono le parole delle coppie entità-attributo candidate . Le coppie entità-attributo candidate vengono memorizzate nella knowledge base solo se il numero di frasi in cui sono presenti l'entità e l'attributo soddisfa (ad esempio, soddisfa o supera) un numero soglia di frasi (ad esempio, 30 frasi) .
Un modello di classificazione determina se l'attributo in una coppia entità-attributo candidata (memorizzata nella knowledge base) è un attributo effettivo dell'entità nella coppia entità-attributo candidata . Il modello di classificazione include un motore di incorporamento di percorsi 106, una sorgente di rappresentazione distributiva, un motore di attributi e una rete feedforward . Come qui utilizzato, il termine motore si riferisce a un apparato di elaborazione dati che esegue una serie di compiti. Le operazioni di questi motori del modello di classificazione nel determinare se l'attributo in una coppia entità-attributo candidata è un attributo essenziale dell'entità .
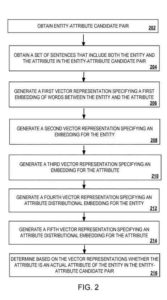
Un processo di esempio per identificare le relazioni di attributo dell'entità
Le operazioni del processo sono descritte di seguito come eseguite dai componenti del sistema e le funzioni del processo sono descritte di seguito solo a scopo illustrativo. Le operazioni del processo possono essere eseguite da qualsiasi dispositivo o sistema appropriato, ad esempio qualsiasi apparato di elaborazione dati applicabile . Le funzioni del processo possono anche essere implementate come istruzioni memorizzate su un supporto leggibile da computer non transitorio . L'esecuzione delle istruzioni fa sì che gli apparati informatici eseguano le operazioni del processo .
La knowledge base ottiene una coppia candidata entità-attributo dall'origine dati.
La base di conoscenza ottiene un insieme di frasi dall'origine dati che includono le parole dell'entità e l'attributo nella coppia entità-attributo candidata .
Sulla base dell'insieme delle frasi e della coppia entità candidata-attributo, il modello di classificazione determina se l'attributo candidato è un attributo effettivo dell'entità candidata . L'insieme delle sanzioni può essere costituito da un numero elevato di frasi, ad esempio 30 o più frasi.
Il modello di classificazione che esegue le seguenti operazioni
- Gli incorporamenti per le parole nell'insieme di frasi che includono l'entità e l'attributo vengono descritti in modo più dettagliato di seguito riguardo al processo seguente
- Creato utilizzando coppie entità-attributo note, un attributo distributivo incorporamento per l'entità, che viene descritto più dettagliatamente di seguito in merito al funzionamento
- Costruzione, utilizzando le coppie entità-attributo note e l'incorporamento dell'attributo distributivo per l'attributo, che viene descritto più dettagliatamente di seguito in merito al funzionamento
- Scegliere, in base all'incorporamento delle parole nell'insieme delle frasi, l'incorporamento dell'attributo distributivo per l'entità e l'incorporamento dell'attributo distributivo per l'attributo, se l'attributo nella coppia candidata entità-attributo è un attributo essenziale dell'entità nella coppia candidata entità-attributo, che viene descritta più dettagliatamente di seguito in merito all'operazione .
Il motore di incorporamento del percorso genera una prima rappresentazione vettoriale specificando le prime parole che si incorporano tra l'entità e l'attributo nelle frasi . Il motore di incorporamento del percorso rileva le relazioni tra i termini di attributo-entità candidati incorporando i percorsi o le parole che collegano le occorrenze quotidiane di questi termini nell'insieme delle frasi .
Per la frase "serpente è un rettile", il motore di incorporamento del percorso genera un incorporamento per la traccia "è a", che può essere utilizzato per rilevare, ad esempio, relazioni genere-specie, che può quindi essere utilizzato per identificare altri attributi entità coppie .
Generazione delle parole tra l'entità e l'attributo
Il motore di incorporamento del percorso esegue le seguenti operazioni per generare parole tra l'entità e l'attributo nelle frasi . Per ogni frase nell'insieme di frasi, il motore di incorporamento del percorso estrae prima il percorso di dipendenza (che specifica un gruppo di parole) tra l'entità e l'attributo . Il motore di incorporamento del percorso converte la frase da una stringa in un elenco, dove il primo termine è l'entità e l'ultimo termine è l'attributo (oppure, il primo termine è l'attributo e il termine precedente è l'entità) .
Ciascun termine (indicato anche come spigolo) nel percorso di dipendenza viene rappresentato utilizzando le seguenti caratteristiche: il lemma del termine, un tag di parte del discorso, l'etichetta di dipendenza e la direzione del percorso di dipendenza (a sinistra , destra o radice) . Ognuna di queste caratteristiche viene incorporata e concatenata per produrre una rappresentazione vettoriale per il termine o bordo (V.sub.e), che comprende una sequenza di vettori (V.sub.l, V.sub.pos, V.sub.dep , V.sub.dir), come mostrato dall'equazione seguente: {freccia destra sopra (v)}.sub.e=[{freccia destra sopra (v)}.sub.l,{freccia destra sopra (v)} .sub.pos,{freccia destra sopra (v)}.sub.dep,{freccia destra sopra (v)}.sub.dir]
Il motore di incorporamento del percorso immette quindi la sequenza di vettori per i termini o gli archi in ciascun percorso in una rete di memoria a breve termine (LSTM) lunga, che produce una singola rappresentazione vettoriale per la frase (V.sub.s), come mostrato da la seguente equazione: {freccia destra sopra (v)}.sub.s=LSTM({freccia destra sopra (v)}.sub.e.sup.(1) . . . {freccia destra sopra (v)}.sub .e.sup.(k))
Infine, il motore di path embedding inserisce la rappresentazione vettoriale singola per tutte le frasi nell'insieme delle frasi in un meccanismo di attenzione, che determina una media pesata delle rappresentazioni delle frasi (V.sub.sents(e,a)), come mostrato dal sotto l'equazione: {freccia destra sopra (v)}.sub.sents(e,a)=ATTN({freccia destra sopra (v)}.sub.s.sup.(1) . . . {freccia destra sopra (v )}.sub.s.sup.(n))
Il modello rappresentativo distributivo genera una seconda rappresentazione vettoriale per l'entità e una terza rappresentazione vettoriale per l'attributo in base alle frasi . Il motore di rappresentazione distributiva rileva le relazioni tra i termini entità-attributo candidati in base al contesto in cui il punto e l'entità della coppia entità-attributo candidata si trovano nell'insieme delle frasi . Ad esempio, il motore di rappresentazione distributiva può determinare che l'entità "New York" viene utilizzata nella raccolta di frasi in un modo che suggerisce che questa entità si riferisca a una città o uno stato negli Stati Uniti .
Come altro esempio, il motore di rappresentazione distributiva può determinare che l'attributo "capitale" viene utilizzato nell'insieme delle frasi in modo da suggerire che questo attributo si riferisca a una città significativa all'interno di uno stato o paese . Pertanto, il motore di rappresentazione distributiva genera una rappresentazione vettoriale specificando un embedding per l'entità (V.sub.e) utilizzando il contesto (cioè l'insieme di frasi) all'interno del quale l'entità appare . Il motore di rappresentazione distributiva genera una rappresentazione vettoriale (V.sub.a) specificando un embedding per l'attributo utilizzando l'insieme di frasi in cui appare la caratteristica .
Il motore dell'attributo distributivo genera una quarta rappresentazione vettoriale che specifica un'incorporamento dell'attributo distributivo per l'entità utilizzando coppie entità-attributo note . Le coppie entità-attributo note, che vengono archiviate nella base di conoscenza, sono coppie entità-attributo per le quali è stato confermato (ad esempio, utilizzando l'elaborazione preventiva del modello di classificazione o sulla base di una valutazione umana) che ogni attributo nell'entità- la coppia di attributi è un attributo essenziale dell'entità nella coppia entità-attributo .
Il motore degli attributi di distribuzione esegue le seguenti operazioni per determinare un incorporamento di attributi di distribuzione che specifica un incorporamento per l'entità utilizzando alcuni (ad esempio, i più comuni) o tutti gli altri attributi noti tra le coppie entità-attributo note a cui quell'entità viene associata .
Identificazione di altri attributi per le entità
Per le entità nella coppia candidata entità-attributo, il motore di attributo distributivo identifica attributi diversi da quelli inclusi nella coppia candidata entità-attributo associata all'entità nei team noti di entità-attributo .
Per un'entità "Michael Jordan" nella coppia entità-attributo candidata (Michael Jordan, famoso), il motore di distribuzione degli attributi può utilizzare le coppie entità-attributo note per Michael Jordan, come (Michael Jordan, ricco) e (Michael Jordan, record), per identificare attributi quali affluent e description .
Il motore distributivo degli attributi genera quindi un embedding per l'entità calcolando una somma ponderata degli attributi noti identificati (come descritto nel paragrafo precedente), dove i pesi vengono appresi utilizzando un meccanismo di attenzione, come mostrato nell'equazione seguente: {right freccia sopra (v)}.sub.e=ATTN(.epsilon.(.alpha..sub.1) . . . .epsilon.(.alpha..sub.m))
Il motore dell'attributo distributivo genera una quinta rappresentazione vettoriale specificando un attributo distributivo che incorpora per l'attributo utilizzando le coppie entità-attributo note . Il motore degli attributi distributivi esegue le seguenti operazioni per determinare un modello basato su alcuni (se i più comuni) o tutti gli attributi noti associati alle entità note dell'attributo candidato .
Per il punto nella coppia candidata entità-attributo, il motore di attributo distributivo identifica le entità note tra le coppie entità-attributo note che hanno la qualità .
Per ciascuna entità nota identificata, il motore di attributo distributivo identifica altri attributi (cioè attributi diversi da quello incluso nella coppia entità-attributo candidato) associati all'entità nei team entità-attributo noti . Il motore degli attributi distributivi può identificare un sottoinsieme di attributi tra gli attributi identificati tramite:
(1) Classificazione degli attributi in base al numero di entità note associate a ciascuna entità, ad esempio l'assegnazione di una posizione più elevata agli attributi associati a un numero maggiore di entità rispetto a quelli associati a un numero inferiore di entità)
Cerca notizie direttamente nella tua casella di posta
*Necessario