
Identification des relations d'attribut d'entité
Publié: 2022-03-02Ce brevet, accordé le 1er mars 2022, concerne l'identification des relations entité-attribut dans les corps de texte.
Les applications de recherche, telles que les moteurs de recherche et les bases de connaissances, tentent de répondre aux besoins d'information d'un chercheur et lui présentent les ressources les plus avantageuses .
Les données structurées peuvent aider à mieux identifier les relations d'attributs
L'identification des relations d'entités d'attributs se fait dans les résultats de recherche structurés.
Les résultats de la recherche structurée présentent une liste d'attributs avec des réponses pour une entité spécifiée dans une demande d'utilisateur, telle qu'une requête .
Ainsi, les résultats de recherche structurés pour "Kevin Durant" peuvent inclure des attributs tels que le salaire, l'équipe, l'année de naissance, la famille, etc., ainsi que des réponses qui fournissent des informations sur ces attributs .
La construction de tels résultats de recherche structurés peut nécessiter l'identification de relations entité-attribut.
Une relation entité-attribut est un cas particulier de relation textuelle entre un couple de termes.
Le premier terme de la paire de termes est une entité, une personne, un lieu, une organisation ou un concept.
Le deuxième terme est un attribut ou une chaîne qui décrit un aspect de l'entité.
Les exemples comprennent:
- "Date de naissance" d'une personne
- "Population" d'un pays
- "Salaire" de l'athlète
- "PDG" d'une organisation
Fournir plus d'informations dans le contenu et le schéma (et les données structurées) sur les entités donne à un moteur de recherche plus d'informations pour explorer de meilleures informations sur les entités spécifiques, pour tester et collecter des données, lever l'ambiguïté de ce qu'il sait et avoir une confiance plus grande et meilleure sur les entités qui il est au courant.
Paires candidates entité-attribut
Ce brevet obtient un couple candidat entité-attribut pour définir une entité et un attribut, où l'attribut est un attribut candidat de l'entité . En plus d'apprendre des faits sur les entités dans les données structurées, Google peut utiliser des informations en examinant le contexte de ces informations et apprendre des vecteurs et de la cooccurrence d'autres mots et faits sur ces entités également.
Jetez un œil au brevet sur les vecteurs de mots pour avoir une idée de la façon dont un moteur de recherche peut désormais avoir une meilleure idée de la signification et du contexte des mots et des informations sur les entités. (C'est une chance d'apprendre de l'exploration des brevets sur la façon dont Google fait maintenant certaines des choses qu'il fait.) Google recueille des faits et des données sur les choses qu'il indexe et peut en apprendre davantage sur les entités qu'il a dans son index, et le attributs qu'il connaît à leur sujet.
Il le fait dans :
- Déterminer, avec des phrases qui incluent l'entité et l'attribut, si l'attribut est un attribut réel de l'entité dans la paire candidate entité-attribut
- Génération d'incorporations pour les mots dans l'ensemble de phrases qui incluent l'entité et l'attribut
- Créer, avec des paires entité-attribut connues, une intégration d'attribut distributionnel pour l'entité, où l'intégration d'attribut distributionnel pour l'entité spécifie une intégration pour l'entité basée sur d'autres attributs associés à l'entité à partir des paires entité-attribut connues
- Sur la base des incorporations de mots dans les phrases, de l'incorporation d'attribut distributionnel pour l'entité, et pour l'attribut, si la paire candidate entité-attribut est un attribut essentiel de l'entité dans la paire candidate entité-attribut.
Les plongements pour les mots sont constitués de phrases avec l'entité et l'attribut
Construire une première représentation vectorielle spécifiant le premier encastrement de mots entre l'entité et le point dans l'ensemble de phrases
- Réalisation d'une seconde représentation vectorielle définissant un double plongement de l'entité à partir de l'ensemble des phrases
- Construire une troisième représentation vectorielle pour une troisième intégration de l'attribut basé sur l'ensemble de phrases
- Choisir, avec un attribut d'entité connu, combine une incorporation d'attribut distributionnel pour l'entité, signifie faire une quatrième représentation vectorielle, en utilisant des paires entité-attribut disponibles, en spécifiant l'incorporation d'attribut distributionnel pour l'entité.
- Construire un attribut distributionnel intégrant ces paires entité-attribut connues signifie développer une cinquième représentation vectorielle avec les équipes entité-attribut disponibles et l'intégration de l'attribut distributionnel pour l'attribut .
- Décider, sur la base des intégrations de mots dans l'ensemble de phrases, de l'intégration d'attribut distributionnel pour l'entité et de l'intégration d'attribut distributionnel pour l'attribut, si l'attribut dans la paire candidate entité-attribut est un attribut essentiel de l'entité dans le paire candidate entité-attribut
- Détermination, sur la base de la première représentation vectorielle, de la deuxième représentation vectorielle, de la troisième représentation vectorielle, de la quatrième représentation vectorielle et de la cinquième représentation vectorielle, si l'attribut dans la paire candidate entité-attribut est un attribut essentiel de l'entité dans l'entité -paire de candidats d'attributs
- Choisir, à partir de la première représentation vectorielle, de la deuxième représentation vectorielle, de la troisième représentation vectorielle, de la quatrième représentation vectorielle et de la cinquième représentation vectorielle, si l'attribut dans la paire candidate entité-attribut est un attribut essentiel de l'entité dans l'entité-attribut paire de candidats d'attributs, se fait à l'aide d'un réseau d'anticipation.
- Choisir, sur la base de la première représentation vectorielle, de la deuxième représentation vectorielle, de la troisième représentation vectorielle, de la quatrième représentation vectorielle et de la cinquième représentation vectorielle, si l'attribut dans la paire candidate entité-attribut est un attribut essentiel de l'entité dans l'entité -paire d'attributs candidats, comprenant :
- générer une seule représentation vectorielle en concaténant la première représentation vectorielle, la deuxième représentation vectorielle, la troisième représentation vectorielle, la quatrième représentation vectorielle et la cinquième représentation vectorielle ; entrer la représentation vectorielle unique dans le réseau à anticipation
- Détermination, par le réseau prédictif et à l'aide de la représentation vectorielle unique, si l'attribut dans la paire candidate entité-attribut est un attribut essentiel de l'entité dans la paire candidate entité-attribut
Faire une quatrième représentation vectorielle, avec des paires entité-attribut connues, spécifiant l'incorporation d'attribut distributionnel pour l'entité comprend :
- Identification d'un ensemble d'attributs associés à l'entité dans les équipes entité-attribut connues, l'ensemble d'attributs omettant l'attribut
- Génération d'un incorporation d'attribut distributionnel pour l'entité en calculant une somme pondérée de caractéristiques dans l'ensemble d'attributs
Le choix d'une cinquième représentation vectorielle, avec des paires entité-attribut connues, spécifiant l'incorporation d'attribut distributionnel pour l'attribut comprend
- Identifier, à l'aide de l'attribut, un ensemble d'entités parmi les couples entité-attribut connus ; pour chaque entité de la collection d'entités
- Détermination d'un ensemble de caractéristiques associées à l'entité, où l'emplacement des attributs n'inclut pas l'attribut
- Génération d'un incorporation d'attribut distributionnel pour l'entité en calculant une somme pondérée de caractéristiques dans la collection d'attributs
L'avantage de relations entité-attribut plus précises par rapport à l'identification d'entité-attribut basée sur un modèle de l'art antérieur
Les techniques d'identification d'entité-attribut de l'art antérieur utilisaient des approches basées sur des modèles telles que les fonctionnalités de traitement du langage naturel (NLP), la supervision à distance et les modèles d'apprentissage automatique traditionnels, qui identifient les relations entité-attribut en représentant des entités et des attributs basés sur des phrases de données. Ces termes apparaissent .
En revanche, les innovations décrites dans cette spécification identifient les relations entité-attribut dans les ensembles de données en utilisant des informations sur la manière dont les entités et les attributs sont exprimés dans les données dans lesquelles ces termes apparaissent et en représentant les entités et les attributs à l'aide d'autres caractéristiques connues pour être associées à ces termes . Cela permet de représenter des entités et des attributs avec des détails partagés par des entités similaires, améliorant ainsi la précision de l'identification des relations entité-attribut qui autrement ne peuvent pas être discernées en considérant les phrases dans lesquelles ces termes apparaissent .
Par exemple, considérez un scénario dans lequel l'ensemble de données comprend des phrases qui ont deux entités, "Ronaldo" et "Messi", décrites à l'aide d'un attribut "record", et une pénalité dans laquelle l'entité "Messi" est décrite à l'aide d'un "objectifs". attribut . Dans un tel scénario, les techniques de l'art antérieur peuvent identifier les paires d'attributs d'entité suivantes : (Ronaldo, enregistrement), (Messi, journal) et (Messi, buts) . Les innovations décrites dans cette spécification vont au-delà de ces approches de l'art antérieur en identifiant les relations entité-attribut qui pourraient ne pas être discernées par la façon dont ces termes sont utilisés dans l'ensemble de données .
En utilisant l'exemple ci-dessus, l'innovation décrite dans cette spécification détermine que "Ronaldo" et "Messi" sont des entités similaires car ils partagent l'attribut "record" et représentent ensuite l'attribut "record" en utilisant l'attribut "goals" . De cette manière, les innovations décrites dans cette spécification, par exemple, peuvent permettre d'identifier des relations entité-attribut, par exemple (Cristiano, Goals), même si une telle relation peut ne pas être discernable à partir de l'ensemble de données .
Le brevet sur les relations d'attributs identifiants
Identification des relations d'attribut d'entité
Inventeurs : Dan Iter, Xiao Yu et Fangtao Li
Cessionnaire : Google LLC
Brevet américain : 11 263 400
Attribué : 1er mars 2022
Déposé : 5 juillet 2019
Abstrait
L'invention concerne des procédés, des systèmes et un appareil, comprenant des programmes informatiques codés sur un support de stockage informatique, qui facilitent l'identification de relations entité-attribut dans des corpus de texte .Des procédés consistent à déterminer si un attribut dans une paire candidate entité-attribut est un attribut réel de l'entité dans la paire candidate entité-attribut .Cela inclut la génération d'intégrations pour les mots dans l'ensemble de phrases qui incluent l'entité et l'attribut et la génération, à l'aide de paires entité-attribut connues .Cela comprend également la génération d'une intégration distributionnelle d'attribut pour l'entité sur la base d'autres attributs associés à l'entité à partir des paires entité-attribut connues, et la génération d'une intégration distributionnelle d'attribut pour l'attribut sur la base d'attributs connus associés à des entités connues de l'attribut dans les paires connues. paires entité-attribut .Sur la base de ces incorporations, un réseau d'anticipation détermine si l'attribut dans la paire candidate entité-attribut est un attribut réel de l'entité dans la paire candidate entité-attribut .
Identification des relations d'attribut d'entité dans le texte
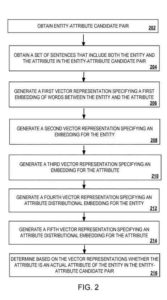
Une paire candidate entité-attribut (où l'attribut est un attribut candidat d'entité) est entrée dans un modèle de classification . Le modèle de classification utilise un moteur d'incorporation de chemin, un moteur de représentation distributionnelle, un moteur d'attributs et un réseau d'anticipation. Il détermine si l'attribut dans la paire candidate entité-attribut est une entité essentielle dans la paire candidate entité-attribut .
Le moteur d'intégration de chemin génère un vecteur représentant une intégration des chemins ou des mots qui relient les occurrences quotidiennes de l'entité et de l'attribut dans un ensemble de phrases (par exemple, 30 phrases ou plus) d'un ensemble de données . Le moteur de représentation distributionnelle génère des vecteurs représentant une imbrication pour les termes d'entité et d'attributs en fonction du contexte dans lequel ces termes apparaissent dans l'ensemble de phrases . Le moteur d'attributs distributionnel génère un vecteur représentant une intégration pour l'entité et un autre vecteur représentant une intégration pour l'attribut .
L'intégration du moteur de distribution d'attributs pour l'entité est basée sur d'autres caractéristiques (c'est-à-dire des attributs autres que l'attribut candidat) connus pour être associés à l'entité dans l'ensemble de données . L'intégration détaillée du moteur de distribution pour la qualité est basée sur différentes caractéristiques associées à des entités connues de l'attribut candidat .
Le modèle de classification concatène les représentations vectorielles du moteur d'incorporation de chemins, du moteur de représentation de distribution et du moteur d'attributs de distribution en une seule représentation vectorielle. Le modèle de classification entre ensuite la représentation vectorielle unique dans un réseau prédictif qui détermine, à l'aide de la représentation vectorielle unique, si l'attribut dans la paire entité-attribut candidate est un attribut essentiel de l'entité dans la paire entité-attribut candidate .
Supposons que le réseau prédictif détermine que le point dans la paire candidate entité-attribut est nécessaire pour l'entité dans la paire candidate entité-attribut. Dans ce cas, la paire entité-attribut candidate est stockée dans la base de connaissances avec d'autres paires entité-attribut connues/réelles .
Extraction des relations d'attribut d'entité
L'environnement comprend un modèle de classification qui, pour des paires entité-attribut candidates dans une base de connaissances, détermine si un attribut dans une paire entité-attribut candidate est un attribut essentiel de l'entité dans la paire candidate . Le modèle de classification est un modèle de réseau neuronal, et les composants sont décrits ci-dessous . Le modèle de classification peut également être utilisé à l'aide d'autres modèles d'apprentissage automatique supervisés et non supervisés .
La base de connaissances, qui peut comprendre des bases de données (ou d'autres structures de stockage de données appropriées) stockées sur des supports de stockage de données non transitoires (par exemple, disque(s) dur(s), mémoire flash, etc.), contient un ensemble de paires entité-attribut candidates . Les paires entité-attribut candidates sont obtenues à l'aide d'un ensemble de contenus dans des documents texte, tels que des pages Web et des articles de presse, obtenus à partir d'une source de données. La source de données peut inclure n'importe quelle source de contenu, telle qu'un site Web d'actualités, une plate-forme d'agrégation de données, une plate-forme de médias sociaux, etc.
La source de données obtient des articles d'actualité à partir d'une plate-forme d'agrégation de données. La source de données peut utiliser un modèle. Le modèle d'apprentissage automatique supervisé ou non supervisé (un modèle de traitement du langage naturel) génère un ensemble de paires entité-attribut candidates en extrayant des phrases des articles et en marquant et en étiquetant les phrases extraites, par exemple, en tant qu'entités et attributs, en utilisant la partie du discours. et balises d'arbre d'analyse de dépendance .
La source de données peut entrer les phrases extraites dans un modèle d'apprentissage automatique. Par exemple, il peut être entraîné à l'aide d'un ensemble de phrases d'entraînement et de leurs paires entité-attribut associées . Un tel modèle d'apprentissage automatique peut ensuite générer les équipes entité-attribut candidates pour les phrases extraites en entrée .
Dans la base de connaissances, la source de données stocke les couples entité-attribut candidats et les phrases extraites par la source de données qui incluent les mots des couples entité-attribut candidats . Les paires entité-attribut candidates ne sont stockées dans la base de connaissances que si le nombre de phrases dans lesquelles l'entité et l'attribut sont présents satisfait (par exemple, atteint ou dépasse) un nombre seuil de phrases (par exemple, 30 phrases) .
Un modèle de classification détermine si l'attribut dans une paire entité-attribut candidate (stockée dans la base de connaissances) est un attribut réel de l'entité dans la paire entité-attribut candidate . Le modèle de classification comprend un moteur d'intégration de chemin 106, une source de représentation distributionnelle, un moteur d'attributs et un réseau d'anticipation . Tel qu'il est utilisé ici, le terme moteur fait référence à un appareil de traitement de données qui exécute un ensemble de tâches. Les opérations de ces moteurs du modèle de classification pour déterminer si l'attribut dans une paire candidate entité-attribut est un attribut essentiel de l'entité .
Exemple de processus d'identification des relations d'attribut d'entité
Les opérations du processus sont décrites ci-dessous comme étant exécutées par les composants du système, et les fonctions du processus sont décrites ci-dessous à des fins d'illustration uniquement. Les opérations du processus peuvent être accomplies par n'importe quel dispositif ou système approprié, par exemple, n'importe quel appareil de traitement de données applicable . Les fonctions du processus peuvent également être mises en œuvre sous forme d'instructions stockées sur un support lisible par ordinateur non transitoire . L' exécution des instructions amène l' appareil de traitement de données à effectuer des opérations du processus .
La base de connaissances obtient une paire candidate entité-attribut à partir de la source de données.
La base de connaissances obtient un ensemble de phrases à partir de la source de données qui incluent les mots de l'entité et de l'attribut dans la paire candidate entité-attribut .
Sur la base de l'ensemble de phrases et de la paire entité candidate-attribut, le modèle de classification détermine si l'attribut candidat est un attribut réel de l'entité candidate . L'ensemble de sanctions peut être un grand nombre de phrases, par exemple 30 phrases ou plus.
Le modèle de classification effectuant les opérations suivantes
- Les intégrations de mots dans l'ensemble de phrases qui incluent l'entité et l'attribut sont décrites plus en détail ci-dessous concernant le processus ci-dessous
- Créé à l'aide de paires entité-attribut connues, un attribut distributionnel intégré pour l'entité, qui est décrit plus en détail ci-dessous concernant le fonctionnement
- Construire, en utilisant les paires entité-attribut connues et l'intégration d'attribut distributionnel pour l'attribut, qui est décrit plus en détail ci-dessous concernant le fonctionnement
- Choisir, sur la base des incorporations de mots dans l'ensemble de phrases, de l'incorporation d'attribut distributionnel pour l'entité et de l'incorporation d'attribut distributionnel pour l'attribut, si l'attribut dans la paire candidate entité-attribut est un attribut essentiel de l'entité dans le paire candidate entité-attribut, qui est décrite plus en détail ci-dessous concernant l'opération .
Le moteur d'incorporation de chemin génère une première représentation vectorielle spécifiant les premiers mots incorporés entre l'entité et l'attribut dans les phrases . Le moteur d'incorporation de chemin détecte les relations entre les termes d'entité-attribut candidats en incorporant les chemins ou les mots qui relient les occurrences quotidiennes de ces termes dans l'ensemble de phrases .
Pour l'expression "le serpent est un reptile", le moteur d'intégration de chemin génère une intégration pour la piste "est un", qui peut être utilisée pour détecter, par exemple, les relations genre-espèce, qui peuvent ensuite s'habituer à identifier d'autres attributs d'entité. paires .
Génération des mots entre l'entité et l'attribut
Le moteur d'incorporation de chemin fait ce qui suit pour générer des mots entre l'entité et l'attribut dans les phrases . Pour chaque phrase de l'ensemble de phrases, le moteur d'incorporation de chemin extrait d'abord le chemin de dépendance (qui spécifie un groupe de mots) entre l'entité et l'attribut . Le moteur d'intégration de chemin convertit la phrase d'une chaîne en une liste, où le premier terme est l'entité et le dernier terme est l'attribut (ou, le premier terme est l'attribut et le terme précédent est l'entité) .
Chaque terme (également appelé arête) du chemin de dépendance est représenté à l'aide des caractéristiques suivantes : le lemme du terme, une étiquette de partie du discours, l'étiquette de dépendance et la direction du chemin de dépendance (gauche , droite ou racine) . Chacune de ces caractéristiques est intégrée et concaténée pour produire une représentation vectorielle du terme ou de l'arête (Ve), qui comprend une séquence de vecteurs (Vl, Vpos, Vdep , Vdir), comme le montre l'équation ci-dessous : {flèche droite sur (v)}e=[{flèche droite sur (v)}l,{flèche droite sur (v)} .sub.pos,{flèche droite sur (v)}.sub.dep,{flèche droite sur (v)}.sub.dir]
Le moteur d'intégration de chemin entre ensuite la séquence de vecteurs pour les termes ou les arêtes de chaque chemin dans un réseau de mémoire longue à court terme (LSTM), qui produit une représentation vectorielle unique pour la phrase (Vs), comme indiqué par l'équation ci-dessous : {flèche droite sur (v)}.s=LSTM({flèche droite sur (v)}.e.sup.(1) . . . {flèche droite sur (v)}.sub .e.sup.(k))
Enfin, le moteur d'intégration de chemin entre la représentation vectorielle unique pour toutes les phrases de l'ensemble de phrases dans un mécanisme d'attention, qui détermine une moyenne pondérée des représentations de phrases (Vsents(e,a)), comme le montre la ci-dessous l'équation : {flèche droite sur (v)} . )}.sup.(n))
Le modèle de représentation distributionnelle génère une deuxième représentation vectorielle pour l' entité et une troisième représentation vectorielle pour l' attribut sur la base des phrases . Le moteur de représentation distributionnelle détecte les relations entre les termes candidats entité-attribut sur la base du contexte dans lequel le point et l'entité de la paire candidate entité-attribut apparaissent dans l'ensemble de phrases . Par exemple, le moteur de représentation distributionnelle peut déterminer que l'entité « New York » est utilisée dans la collection de phrases d'une manière qui suggère que cette entité fait référence à une ville ou à un État des États-Unis .
Comme autre exemple, le moteur de représentation distributionnelle peut déterminer que l'attribut "capital" est utilisé dans l'ensemble de phrases d'une manière qui suggère que cet attribut fait référence à une ville importante dans un état ou un pays . Ainsi, le moteur de représentation distributionnelle génère une représentation vectorielle spécifiant un encastrement pour l'entité (Ve) en utilisant le contexte (c'est-à-dire l'ensemble de phrases) dans lequel l'entité apparaît . Le moteur de représentation distributionnelle génère une représentation vectorielle (Va) spécifiant une imbrication pour l'attribut en utilisant l'ensemble de phrases dans lequel la caractéristique apparaît .
Le moteur d'attribut distributionnel génère une quatrième représentation vectorielle spécifiant une incorporation d'attribut distributionnel pour l'entité à l'aide de paires entité-attribut connues . Les paires entité-attribut connues, qui sont stockées dans la base de connaissances, sont des paires entité-attribut pour lesquelles il a été confirmé (par exemple, en utilisant un traitement préalable par le modèle de classification ou sur la base d'une évaluation humaine) que chaque attribut de l'entité-attribut La paire d'attributs est un attribut essentiel de l'entité dans le couple entité-attribut .
Le moteur d'attributs distributionnels effectue les opérations suivantes pour déterminer une intégration d'attributs distributionnels qui spécifie une intégration pour l'entité en utilisant certains (par exemple, les plus courants) ou tous les autres attributs connus parmi les paires entité-attribut connues auxquelles cette entité est associée .
Identification d'autres attributs pour les entités
Pour les entités dans la paire candidate entité-attribut, le moteur d'attributs de distribution identifie des attributs autres que ceux inclus dans la paire candidate entité-attribut associée à l'entité dans les équipes entité-attribut connues .
Pour une entité "Michael Jordan" dans la paire entité-attribut candidate (Michael Jordan, célèbre), le moteur de distribution d'attributs peut utiliser les paires entité-attribut connues pour Michael Jordan, telles que (Michael Jordan, riche) et (Michael Jordan, record), pour identifier des attributs tels que affluent et description .
Le moteur de distribution d'attributs génère ensuite une intégration pour l'entité en calculant une somme pondérée des attributs connus identifiés (comme décrit dans le paragraphe précédent), où les poids sont appris à l'aide d'un mécanisme d'attention, comme indiqué dans l'équation ci-dessous : {right flèche sur (v)}e=ATTN(.epsilon.(.alpha..sub.1) . . . .epsilon.(.alpha..sub.m))
Le moteur d'attribut distributionnel génère une cinquième représentation vectorielle spécifiant une incorporation d'attribut distributionnel pour l'attribut à l'aide des paires entité-attribut connues . Le moteur d'attributs de distribution effectue les opérations suivantes pour déterminer un modèle basé sur certains (qu'ils soient les plus courants) ou sur tous les attributs connus associés à des entités connues de l'attribut candidat .
Pour le point dans la paire candidate entité-attribut, le moteur d'attribut distributionnel identifie les entités connues parmi les couples entité-attribut connus qui ont la qualité .
Pour chaque entité connue identifiée, le moteur d'attributs de distribution identifie d'autres attributs (c'est-à-dire, des attributs autres que celui inclus dans la paire candidate entité-attribut) associés à l'entité dans les équipes entité-attribut connues . Le moteur d'attributs de distribution peut identifier un sous-ensemble d'attributs parmi les attributs identifiés en :
(1) Classement des attributs en fonction du nombre d'entités connues associées à chaque entité, comme l'attribution d'un rang supérieur aux attributs associés à un nombre d'entités supérieur à ceux associés à moins d'entités)
Rechercher des actualités directement dans votre boîte de réception
*Obligatoire