
Identifizieren von Entitätsattributbeziehungen
Veröffentlicht: 2022-03-02Dieses am 1. März 2022 erteilte Patent befasst sich mit der Identifizierung von Beziehungen zwischen Entitäten und Attributen in Textkörpern.
Suchanwendungen wie Suchmaschinen und Wissensdatenbanken versuchen, die Informationsbedürfnisse eines Suchenden zu erfüllen und dem Suchenden die vorteilhaftesten Ressourcen zu zeigen .
Strukturierte Daten können helfen, Attributbeziehungen besser zu identifizieren
Das Identifizieren von Attributen und Entitätsbeziehungen erfolgt in strukturierten Suchergebnissen.
Strukturierte Suchergebnisse stellen eine Liste von Attributen mit Antworten für eine Entität dar, die in einer Benutzeranforderung angegeben ist, z. B. eine Abfrage .
So können die strukturierten Suchergebnisse für „Kevin Durant“ Attribute wie Gehalt, Team, Geburtsjahr, Familie usw. enthalten, zusammen mit Antworten, die Aufschluss über diese Attribute geben .
Das Erstellen solcher strukturierter Suchergebnisse kann die Identifizierung von Entitäts-Attribut-Beziehungen erfordern.
Eine Entity-Attribut-Relation ist ein besonderer Fall einer Textrelation zwischen einem Begriffspaar.
Der erste Begriff in dem Begriffspaar ist eine Entität, eine Person, ein Ort, eine Organisation oder ein Konzept.
Der zweite Begriff ist ein Attribut oder eine Zeichenfolge, die einen Aspekt der Entität beschreibt.
Beispiele beinhalten:
- „Geburtsdatum“ einer Person
- „Bevölkerung“ eines Landes
- „Gehalt“ des Sportlers
- „CEO“ einer Organisation
Die Bereitstellung von mehr Inhalts- und Schemainformationen (und strukturierten Daten) über Entitäten gibt einer Suchmaschine mehr Informationen, um bessere Informationen über die spezifischen Entitäten zu erforschen, Daten zu testen und zu sammeln, eindeutig zu machen, was sie weiß, und mehr und besseres Vertrauen in die Entitäten zu haben es ist sich bewusst.
Entitäts-Attribut-Kandidatenpaare
Dieses Patent erhält ein Entitäts-Attribut-Kandidatenpaar, um eine Entität und ein Attribut zu definieren, wobei das Attribut ein Kandidatenattribut der Entität ist . Zusätzlich zum Lernen aus Fakten über Entitäten in strukturierten Daten kann Google Informationen verwenden, indem es den Kontext dieser Informationen betrachtet und auch aus Vektoren und dem gleichzeitigen Vorkommen anderer Wörter und Fakten über diese Entitäten lernt.
Werfen Sie einen Blick auf das Patent für Wortvektoren, um ein Gefühl dafür zu bekommen, wie eine Suchmaschine jetzt einen besseren Sinn für die Bedeutung und den Kontext von Wörtern und Informationen über Entitäten bekommen kann. (Dies ist eine Gelegenheit, aus der Patenterforschung darüber zu lernen, wie Google jetzt einige der Dinge tut, die es tut.) Google sammelt Fakten und Daten über die Dinge, die es indiziert, und kann etwas über die Entitäten erfahren, die es in seinem Index hat, und die Attribute, die es über sie kennt.
Es tut dies in:
- Bestimmen mit Sätzen, die die Entität und das Attribut enthalten, ob das Attribut ein tatsächliches Attribut der Entität in dem Entitäts-Attribut-Kandidatenpaar ist
- Generieren von Einbettungen für Wörter in dem Satz von Sätzen, die die Entität und das Attribut enthalten
- Erstellen einer Verteilungsattributeinbettung für die Entität mit bekannten Entitätsattributpaaren, wobei die Verteilungsattributeinbettung für die Entität eine Einbettung für die Entität basierend auf anderen Attributen angibt, die der Entität aus den bekannten Entitätsattributpaaren zugeordnet sind
- Basierend auf Einbettungen für Wörter in den Sätzen, der Verteilungsattributeinbettung für die Entität und für das Attribut, ob das Entitäts-Attribut-Kandidatenpaar ein wesentliches Attribut der Entität in dem Entitäts-Attribut-Kandidatenpaar ist.
Einbettungen für Wörter werden aus Sätzen mit der Entität und dem Attribut gemacht
Erstellen einer ersten Vektordarstellung, die die erste Einbettung von Wörtern zwischen der Entität und dem Punkt in dem Satz von Sätzen spezifiziert
- Erstellen einer zweiten Vektordarstellung, die eine doppelte Einbettung für die Entität basierend auf dem Satz von Sätzen definiert
- Konstruieren einer dritten Vektordarstellung für eine dritte Einbettung für das Attribut basierend auf dem Satz von Sätzen
- Das Auswählen mit einem bekannten Entitätsattribut kombiniert eine Verteilungsattribut-Einbettung für die Entität, bedeutet das Erstellen einer vierten Vektordarstellung unter Verwendung verfügbarer Entitätsattribut-Paare, wobei die Verteilungsattribut-Einbettung für die Entität spezifiziert wird.
- Das Erstellen einer Verteilungsattributeinbettung mit diesen bekannten Entitätsattributpaaren bedeutet, eine fünfte Vektordarstellung mit verfügbaren Entitätsattributteams und der Verteilungsattributeinbettung für das Attribut zu entwickeln .
- Entscheiden, basierend auf den Einbettungen für Wörter in dem Satz von Sätzen, der Einbettung des Verteilungsattributs für die Entität und der Einbettung des Verteilungsattributs für das Attribut, ob das Attribut in dem Entitäts-Attribut-Kandidatenpaar ein wesentliches Attribut der Entität in der ist Kandidatenpaar aus Entität und Attribut
- Bestimmen, basierend auf der ersten Vektordarstellung, der zweiten Vektordarstellung, der dritten Vektordarstellung, der vierten Vektordarstellung und der fünften Vektordarstellung, ob das Attribut in dem Entitäts-Attribut-Kandidatenpaar ein wesentliches Attribut der Entität in der Entität ist -Attribut-Kandidatenpaar
- Auswählen aus der ersten Vektordarstellung, der zweiten Vektordarstellung, der dritten Vektordarstellung, der vierten Vektordarstellung und der fünften Vektordarstellung, ob das Attribut in dem Entitäts-Attribut-Kandidaten-Paar ein wesentliches Attribut der Entität in der Entität ist – Attributkandidatenpaar, werden mithilfe eines Feedforward-Netzwerks ausgeführt.
- Auswählen, basierend auf der ersten Vektordarstellung, der zweiten Vektordarstellung, der dritten Vektordarstellung, der vierten Vektordarstellung und der fünften Vektordarstellung, ob das Attribut in dem Entitäts-Attribut-Kandidatenpaar ein wesentliches Attribut der Entität in der Entität ist -Attributkandidatenpaar, umfasst:
- Erzeugen einer einzelnen Vektordarstellung durch Verketten der ersten Vektordarstellung, der zweiten Vektordarstellung, der dritten Vektordarstellung, der vierten Vektordarstellung und der fünften Vektordarstellung; Eingeben der Einzelvektordarstellung in das Feedforward-Netzwerk
- Bestimmen, durch das Feedforward-Netzwerk und unter Verwendung der Einzelvektordarstellung, ob das Attribut in dem Entitäts-Attribut-Kandidatenpaar ein wesentliches Attribut der Entität in dem Entitäts-Attribut-Kandidatenpaar ist
Das Erstellen einer vierten Vektordarstellung mit bekannten Entitäts-Attribut-Paaren, die die Verteilungsattribut-Einbettung für die Entität spezifiziert, umfasst:
- Identifizieren eines Satzes von Attributen, die der Entität in den bekannten Entitäts-Attribut-Teams zugeordnet sind, wobei der Satz von Attributen das Attribut weglässt
- Generieren einer Verteilungsattributeinbettung für die Entität durch Berechnen einer gewichteten Summe von Merkmalen in dem Satz von Attributen
Auswählen einer fünften Vektordarstellung mit bekannten Entitäts-Attribut-Paaren, die die Verteilungsattributeinbettung für die Attributumfänge spezifizieren
- Identifizieren, unter Verwendung des Attributs, eines Satzes von Entitäten aus den bekannten Entitäts-Attribut-Paaren; für jede Entität in der Sammlung von Entitäten
- Bestimmen eines Satzes von Merkmalen, die der Entität zugeordnet sind, wobei die Position von Attributen das Attribut nicht enthält
- Generieren einer Verteilungsattributeinbettung für die Entität durch Berechnen einer gewichteten Summe von Merkmalen in der Sammlung von Attributen
Der Vorteil genauerer Entitäts-Attribut-Beziehungen gegenüber der modellbasierten Entitäts-Attribut-Identifizierung nach dem Stand der Technik
Frühere Techniken zur Identifizierung von Entitätsattributen in der Kunst verwendeten modellbasierte Ansätze, wie z. Diese Begriffe erscheinen .
Im Gegensatz dazu identifizieren die in dieser Spezifikation beschriebenen Innovationen Entitäts-Attribut-Beziehungen in Datensätzen, indem sie Informationen darüber verwenden, wie Entitäten und Attribute in den Daten ausgedrückt werden, in denen diese Begriffe vorkommen, und indem sie Entitäten und Attribute unter Verwendung anderer Merkmale darstellen, von denen bekannt ist, dass sie damit assoziiert werden diese Begriffe . Dies ermöglicht die Darstellung von Entitäten und Attributen mit Details, die von ähnlichen Entitäten gemeinsam genutzt werden, wodurch die Genauigkeit der Identifizierung von Entitäts-Attribut-Beziehungen verbessert wird, die sonst nicht erkannt werden können, indem die Sätze betrachtet werden, in denen diese Begriffe vorkommen .
Stellen Sie sich beispielsweise ein Szenario vor, in dem der Datensatz Sätze enthält, die zwei Entitäten haben, „Ronaldo“ und „Messi“, die mit einem „Datensatz“-Attribut beschrieben werden, und eine Strafe, bei der die Entität „Messi“ mit einem „Tore“ beschrieben wird. Attribut . In einem solchen Szenario können die Techniken des Standes der Technik die folgenden Einheitsattributpaare identifizieren: (Ronaldo, Aufzeichnung), (Messi, Protokoll) und (Messi, Tore) . Die in dieser Spezifikation beschriebenen Neuerungen gehen über diese Ansätze des Standes der Technik hinaus, indem sie Entitäts-Attribut-Beziehungen identifizieren, die möglicherweise nicht erkannt werden, wenn diese Begriffe in dem Datensatz verwendet werden .
Unter Verwendung des obigen Beispiels bestimmt die in dieser Spezifikation beschriebene Innovation, dass „Ronaldo“ und „Messi“ ähnliche Entitäten sind, weil sie das „Rekord“-Attribut teilen und dann das „Rekord“-Attribut unter Verwendung des „Ziele“-Attributs darstellen . Auf diese Weise können beispielsweise die in dieser Spezifikation beschriebenen Innovationen ermöglichen, Entitäts-Attribut-Beziehungen zu identifizieren, z. B. (Cristiano, Goals), auch wenn eine solche Beziehung möglicherweise nicht aus dem Datensatz erkennbar ist .
Das Patent zur Identifizierung von Attributbeziehungen
Identifizieren von Entitätsattributbeziehungen
Erfinder: Dan Iter, Xiao Yu und Fangtao Li
Zessionar: Google LLC
US-Patent: 11.263.400
Gewährt: 1. März 2022
Eingereicht: 5. Juli 2019
Abstrakt
Verfahren, Systeme und Geräte, einschließlich Computerprogramme, die auf einem Computerspeichermedium codiert sind, die das Identifizieren von Entitäts-Attribut-Beziehungen in Textkorpora erleichtern .Verfahren umfassen die Bestimmung, ob ein Attribut in einem Kandidaten-Entitäts-Attribut-Paar ein tatsächliches Attribut der Entität in dem Entitäts-Attribut-Kandidaten-Paar ist .Dies umfasst das Generieren von Einbettungen für Wörter in dem Satz von Sätzen, die die Entität und das Attribut enthalten, und das Generieren unter Verwendung bekannter Entitäts-Attribut-Paare .Dies umfasst auch das Generieren einer Attributverteilungseinbettung für die Entität basierend auf anderen Attributen, die der Entität aus den bekannten Entitäts-Attribut-Paaren zugeordnet sind, und das Generieren einer Attributverteilungseinbettung für das Attribut basierend auf bekannten Attributen, die bekannten Entitäten des Attributs im Bekannten zugeordnet sind Entity-Attribut-Paare .Basierend auf diesen Einbettungen bestimmt ein Feedforward-Netzwerk, ob das Attribut in dem Entitäts-Attribut-Kandidatenpaar ein tatsächliches Attribut der Entität in dem Entitäts-Attribut-Kandidatenpaar ist .
Identifizieren von Entitätsattributbeziehungen im Text
Ein Kandidaten-Entitäts-Attribut-Paar (wobei das Attribut ein Kandidaten-Attribut der Entität ist) wird in ein Klassifizierungsmodell eingegeben . Das Klassifizierungsmodell verwendet eine Pfadeinbettungsmaschine, eine Verteilungsdarstellungsmaschine, eine Attributmaschine und ein Feedforward-Netzwerk. Es bestimmt, ob das Attribut in dem Kandidaten-Entitäts-Attribut-Paar eine wesentliche Entität in dem Kandidaten-Entitäts-Attribut-Paar ist .
Die Pfadeinbettungsmaschine erzeugt einen Vektor, der eine Einbettung der Pfade oder der Wörter darstellt, die die alltäglichen Vorkommnisse der Entität und des Attributs in einem Satz von Sätzen (z. B. 30 oder mehr Sätzen) eines Datensatzes verbinden . Die Verteilungsdarstellungsmaschine erzeugt Vektoren, die eine Einbettung für die Entität darstellen, und ordnet Begriffe basierend auf dem Kontext zu, in dem diese Begriffe in dem Satz von Sätzen erscheinen . Die Verteilungsattributmaschine erzeugt einen Vektor, der eine Einbettung für die Entität darstellt, und einen anderen Vektor, der eine Einbettung für das Attribut darstellt .
Die Einbettung der Attributverteilungs-Engine für die Entität basiert auf anderen Merkmalen (d. h. anderen Attributen als dem Kandidatenattribut), von denen bekannt ist, dass sie der Entität im Datensatz zugeordnet werden . Die Einbettung der Qualität durch die detaillierte Verteilungs-Engine basiert auf verschiedenen Merkmalen, die bekannten Entitäten des Kandidatenattributs zugeordnet sind .
Das Klassifizierungsmodell verkettet die Vektordarstellungen von der Pfadeinbettungsmaschine , der Verteilungsdarstellungsmaschine und der Verteilungsattributmaschine zu einer einzigen Vektordarstellung. Das Klassifizierungsmodell gibt dann die Einzelvektordarstellung in ein Feedforward-Netzwerk ein, das unter Verwendung der Einzelvektordarstellung bestimmt, ob das Attribut in dem Kandidaten-Entitäts-Attribut-Paar ein wesentliches Attribut der Entität in dem Kandidaten-Entitäts-Attribut-Paar ist .
Angenommen, das Feedforward-Netzwerk bestimmt, dass der Punkt in dem Kandidaten-Entitäts-Attribut-Paar für die Entität in dem Kandidaten-Entitäts-Attribut-Paar notwendig ist. In diesem Fall wird das Kandidaten-Entitäts-Attribut-Paar zusammen mit anderen bekannten/tatsächlichen Entitäts-Attribut-Paaren in der Wissensbasis gespeichert .
Extrahieren von Entitätsattributbeziehungen
Die Umgebung enthält ein Klassifizierungsmodell, das für Kandidaten-Entitäts-Attribut-Paare in einer Wissensbasis bestimmt, ob ein Attribut in einem Kandidaten-Entitäts-Attribut-Paar ein wesentliches Attribut der Entität in dem Kandidaten-Paar ist . Das Klassifizierungsmodell ist ein neuronales Netzwerkmodell, und die Komponenten werden unten beschrieben . Das Klassifizierungsmodell kann auch unter Verwendung anderer Modelle für überwachtes und nicht überwachtes maschinelles Lernen verwendet werden .
Die Wissensbasis, die Datenbanken (oder andere geeignete Datenspeicherstrukturen) enthalten kann, die in nichtflüchtigen Datenspeichermedien (z. B. Festplatte(n), Flash-Speicher usw.) gespeichert sind, hält einen Satz von Kandidaten-Entitäts-Attribut-Paaren . Die Kandidaten-Entitäts-Attribut-Paare werden unter Verwendung eines Satzes von Inhalten in Textdokumenten, wie beispielsweise Webseiten und Nachrichtenartikeln, erhalten, die von einer Datenquelle erhalten werden. Die Datenquelle kann jede Inhaltsquelle umfassen, wie z. B. eine Nachrichten-Website, eine Datenaggregator-Plattform, eine Social-Media-Plattform usw.
Die Datenquelle erhält Nachrichtenartikel von einer Datenaggregatorplattform. Die Datenquelle kann ein Modell verwenden. Das überwachte oder nicht überwachte maschinelle Lernmodell (ein Verarbeitungsmodell für natürliche Sprache) erzeugt einen Satz von Kandidaten-Entitäts-Attribut-Paaren durch Extrahieren von Sätzen aus den Artikeln und Tokenisieren und Kennzeichnen der extrahierten Sätze, z. B. als Entitäten und Attribute, unter Verwendung von Wortart und Abhängigkeits-Parse-Tree-Tags .
Die Datenquelle kann die extrahierten Sätze in ein maschinelles Lernmodell eingeben. Beispielsweise kann es mit einer Reihe von Trainingssätzen und den zugehörigen Entitäts-Attribut-Paaren trainiert werden . Ein solches maschinelles Lernmodell kann dann die Kandidatenentitäts-Attribut-Teams für die eingegebenen extrahierten Sätze ausgeben .
In der Wissensbasis speichert die Datenquelle die Kandidaten-Entitäts-Attribut-Paare und die von der Datenquelle extrahierten Sätze, die die Wörter der Kandidaten-Entitäts-Attribut-Paare enthalten . Die Kandidaten-Entitäts-Attribut-Paare werden nur dann in der Wissensbasis gespeichert, wenn die Anzahl von Sätzen, in denen die Entität und das Attribut vorhanden sind, eine Schwellenanzahl von Sätzen (z. B. 30 Sätze) erfüllt (z. B. erreicht oder überschreitet) .
Ein Klassifizierungsmodell bestimmt, ob das Attribut in einem Kandidaten-Entitäts-Attribut-Paar (gespeichert in der Wissensbasis) ein tatsächliches Attribut der Entität in dem Kandidaten-Entitäts-Attribut-Paar ist . Das Klassifizierungsmodell umfasst eine Pfadeinbettungsmaschine 106 , eine Verteilungsdarstellungsquelle, eine Attributmaschine und ein Feedforward-Netzwerk . Wie hierin verwendet, bezieht sich der Begriff Maschine auf eine Datenverarbeitungsvorrichtung, die eine Reihe von Aufgaben durchführt. Die Operationen dieser Engines des Klassifizierungsmodells bei der Bestimmung, ob das Attribut in einem Kandidaten-Entitäts-Attribut-Paar ein wesentliches Attribut der Entität ist .
Ein beispielhafter Prozess zum Identifizieren von Beziehungen zwischen Entitätsattributen
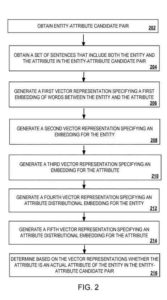
Operationen des Prozesses werden unten so beschrieben, dass sie von den Komponenten des Systems durchgeführt werden, und Funktionen des Prozesses werden unten nur zu Veranschaulichungszwecken beschrieben. Operationen des Prozesses können durch jedes geeignete Gerät oder System, z. B. jedes anwendbare Datenverarbeitungsgerät, durchgeführt werden . Funktionen des Prozesses können auch als Anweisungen implementiert werden, die auf einem nichtflüchtigen computerlesbaren Medium gespeichert sind . Die Ausführung der Anweisungen bewirkt, dass die Datenverarbeitungsvorrichtung Operationen des Prozesses durchführt .
Die Wissensbasis erhält ein Entitäts-Attribut-Kandidatenpaar von der Datenquelle.
Die Wissensbasis erhält einen Satz von Sätzen aus der Datenquelle, die die Wörter der Entität und des Attributs in dem Kandidaten-Entität-Attribut-Paar enthalten .
Basierend auf dem Satz von Sätzen und dem Kandidatenentitäts-Attribut-Paar bestimmt das Klassifizierungsmodell, ob das Kandidatenattribut ein tatsächliches Attribut der Kandidatenentität ist . Der Satz von Strafen kann eine große Anzahl von Sätzen sein, z. B. 30 oder mehr Sätze.
Das Klassifizierungsmodell, das die folgenden Operationen ausführt
- Einbettungen für Wörter in dem Satz von Sätzen, die die Entität und das Attribut enthalten, werden nachstehend in Bezug auf den nachstehenden Prozess ausführlicher beschrieben
- Erstellt unter Verwendung bekannter Entitäts-Attribut-Paare, eine Verteilungsattribut-Einbettung für die Entität, die weiter unten in Bezug auf die Funktionsweise ausführlicher beschrieben wird
- Aufbau unter Verwendung der bekannten Entitäts-Attribut-Paare und Verteilungs-Attribut-Einbettung für das Attribut, was weiter unten in Bezug auf den Betrieb ausführlicher beschrieben wird
- Auswählen, basierend auf den Einbettungen für Wörter in dem Satz von Sätzen, der Verteilungsattribut-Einbettung für die Entität und der Verteilungsattribut-Einbettung für das Attribut, ob das Attribut in dem Entitäts-Attribut-Kandidaten-Paar ein wesentliches Attribut der Entität in der ist Entitäts-Attribut-Kandidatenpaar, das weiter unten in Bezug auf die Operation ausführlicher beschrieben wird .
Die Pfadeinbettungsmaschine erzeugt eine erste Vektordarstellung, die die ersten Wörter spezifiziert, die zwischen der Entität und dem Attribut in den Sätzen eingebettet sind . Die Pfadeinbettungsmaschine erkennt Beziehungen zwischen Kandidatenentitätsattributbegriffen durch Einbetten der Pfade oder der Wörter, die die alltäglichen Vorkommen dieser Begriffe in den Satz von Sätzen verbinden .
Für den Ausdruck „Schlange ist ein Reptil“ erzeugt die Pfadeinbettungsmaschine eine Einbettung für die Spur „ist ein“, die verwendet werden kann, um z. B. Gattungs-Art-Beziehungen zu erkennen, die dann verwendet werden können, um andere Entitätsattribute zu identifizieren Paare .
Generieren der Wörter zwischen der Entität und dem Attribut
Die Engine zum Einbetten von Pfaden führt Folgendes aus, um Wörter zwischen der Entität und dem Attribut in den Sätzen zu generieren . Für jeden Satz in dem Satz von Sätzen extrahiert die Pfadeinbettungsmaschine zuerst den Abhängigkeitspfad (der eine Gruppe von Wörtern angibt) zwischen der Entität und dem Attribut . Die Pfadeinbettungsmaschine wandelt den Satz von einer Zeichenfolge in eine Liste um, wobei der erste Begriff die Entität und der letzte Begriff das Attribut ist (oder der erste Begriff das Attribut und der vorherige Begriff die Entität ist) .
Jeder Begriff (der auch als Kante bezeichnet wird) im Abhängigkeitspfad wird durch die folgenden Merkmale dargestellt: das Lemma des Begriffs, ein Wortart-Tag, die Abhängigkeitsbezeichnung und die Richtung des Abhängigkeitspfads (links , rechts oder root) . Jedes dieser Merkmale wird eingebettet und verkettet, um eine Vektordarstellung für den Term oder die Kante (V e ) zu erzeugen, die eine Folge von Vektoren (V 1 , V pos , V dep ) umfasst , V dir ), wie durch die folgende Gleichung gezeigt: {rechter Pfeil über (v)} e = [{rechter Pfeil über (v)} l, {rechter Pfeil über (v)} pos,{rechter Pfeil über (v)}dep,{rechter Pfeil über (v)}dir]
Die Pfadeinbettungsmaschine gibt dann die Folge von Vektoren für die Terme oder Kanten in jedem Pfad in ein Netzwerk mit langem Kurzzeitspeicher (LSTM) ein, das eine einzelne Vektordarstellung für den Satz (Vs) erzeugt, wie durch gezeigt die folgende Gleichung: {rechter Pfeil über (v)} s = LSTM({rechter Pfeil über (v)} e (1) . . . {rechter Pfeil über (v)} .e.sup.(k))
Schließlich gibt die Pfadeinbettungsmaschine die einzelne Vektordarstellung für alle Sätze in dem Satz von Sätzen in einen Aufmerksamkeitsmechanismus ein, der einen gewichteten Mittelwert der Satzdarstellungen (V sends (e, a)) bestimmt, wie durch gezeigt untere Gleichung: {Pfeil nach rechts über (v)}sents(e,a)=ATTN({Pfeil nach rechts über (v)}s(1) . . . {Pfeil nach rechts über (v )} s (n))
Das Verteilungsdarstellungsmodell erzeugt eine zweite Vektordarstellung für die Entität und eine dritte Vektordarstellung für das Attribut basierend auf den Sätzen . Die Verteilungsdarstellungsmaschine erkennt Beziehungen zwischen Kandidaten-Entitäts-Attribut-Begriffen basierend auf dem Kontext, in dem Punkt und die Entität des Kandidaten-Entitäts-Attribut-Paares in dem Satz von Sätzen vorkommen . Beispielsweise kann die Engine für die Verteilungsdarstellung bestimmen, dass die Entität „New York“ in der Sammlung von Sätzen auf eine Weise verwendet wird, die darauf hindeutet, dass sich diese Entität auf eine Stadt oder einen Staat in den Vereinigten Staaten bezieht .
Als weiteres Beispiel kann die Verteilungsdarstellungsmaschine bestimmen, dass das Attribut „Hauptstadt“ in dem Satz von Sätzen auf eine Weise verwendet wird, die darauf hindeutet, dass sich dieses Attribut auf eine bedeutende Stadt innerhalb eines Staates oder Landes bezieht . Somit erzeugt die Verteilungsdarstellungsmaschine eine Vektordarstellung, die eine Einbettung für die Entität (V e ) unter Verwendung des Kontexts (dh des Satzes von Sätzen) spezifiziert, in dem die Entität erscheint . Die Verteilungsdarstellungsmaschine erzeugt eine Vektordarstellung (V a ), die eine Einbettung für das Attribut spezifiziert, unter Verwendung des Satzes von Sätzen, in denen das Merkmal erscheint .
Die Verteilungsattributmaschine erzeugt eine vierte Vektordarstellung, die eine Verteilungsattributeinbettung für die Entität unter Verwendung bekannter Entitätsattributpaare spezifiziert . Die bekannten Entitäts-Attribut-Paare, die in der Wissensbasis gespeichert werden, sind Entitäts-Attribut-Paare, für die bestätigt wurde (z. B. unter Verwendung einer vorherigen Verarbeitung durch das Klassifizierungsmodell oder basierend auf einer menschlichen Bewertung), dass jedes Attribut in der Entität- Das Attributpaar ist ein wesentliches Attribut der Entität im Entitäts-Attribut-Paar .
Die Verteilungsattribut-Engine führt die folgenden Operationen durch, um eine Verteilungsattribut-Einbettung zu bestimmen, die eine Einbettung für die Entität unter Verwendung einiger (z. B. der häufigsten) oder aller anderen bekannten Attribute unter den bekannten Entitäts-Attribut-Paaren angibt, denen diese Entität zugeordnet wird .
Identifizieren anderer Attribute für Entitäten
Für Entitäten in dem Entitätsattributkandidatenpaar identifiziert die Verteilungsattributmaschine andere Attribute als diejenigen, die in dem Entitätsattributkandidatenpaar enthalten sind, das der Entität in den bekannten Entitätsattributteams zugeordnet ist .
Für eine Entität „Michael Jordan“ im Kandidaten-Entitäts-Attribut-Paar (Michael Jordan, berühmt) kann die Attributverteilungs-Engine die bekannten Entitäts-Attribut-Paare für Michael Jordan verwenden, wie z. B. (Michael Jordan, wohlhabend) und (Michael Jordan, Datensatz), um Attribute wie wohlhabend und Beschreibung zu identifizieren .
Die Attributverteilungs-Engine erzeugt dann eine Einbettung für die Entität, indem sie eine gewichtete Summe der identifizierten bekannten Attribute berechnet (wie im vorangehenden Absatz beschrieben), wobei die Gewichte durch einen Aufmerksamkeitsmechanismus gelernt werden, wie in der folgenden Gleichung gezeigt: {right Pfeil über (v)} e = ATTN(&egr;(&agr; 1 ) . . . . &egr; (&agr; m ))
Die Verteilungsattribut-Engine erzeugt eine fünfte Vektordarstellung, die eine Verteilungsattribut-Einbettung für das Attribut unter Verwendung der bekannten Entitäts-Attribut-Paare spezifiziert . Die Verteilungsattribut -Engine führt die folgenden Operationen durch, um ein Modell basierend auf einigen (egal ob den gebräuchlichsten) oder allen bekannten Attributen zu bestimmen, die bekannten Entitäten des Kandidatenattributs zugeordnet sind .
Für den Punkt in dem Entitäts-Attribut-Kandidatenpaar identifiziert die Verteilungsattribut-Engine die bekannten Entitäten unter den bekannten Entitäts-Attribut-Paaren, die die Qualität haben .
Für jede identifizierte bekannte Entität identifiziert die Verteilungsattributmaschine andere Attribute (dh andere Attribute als das in dem Entitäts-Attribut-Kandidatenpaar enthaltene), das der Entität in den bekannten Entitäts-Attribut-Teams zugeordnet ist . Die Verteilungsattribut-Engine kann eine Teilmenge von Attributen aus den identifizierten Attributen identifizieren durch:
(1) Ordnen von Attributen basierend auf der Anzahl bekannter Entitäten, die mit jeder Entität verbunden sind, wie z.
Suchen Sie Nachrichten direkt in Ihren Posteingang
*Erforderlich