
Ana Google BigQuery özelliklerine genel bakış — pazarlama analizi için istek yazma alıştırması yapın
Yayınlanan: 2022-04-12Bir işletme ne kadar çok bilgi biriktirirse, nerede saklanacağı sorusu o kadar keskin olur. Kendi sunucularınızın bakımını yapma yeteneğiniz veya isteğiniz yoksa, Google BigQuery (GBQ) size yardımcı olabilir. BigQuery, büyük verilerle çalışmak için hızlı, uygun maliyetli ve ölçeklenebilir depolama sağlar ve SQL benzeri sözdiziminin yanı sıra standart ve kullanıcı tanımlı işlevleri kullanarak sorgular yazmanıza olanak tanır.
Bu makalede, BigQuery'nin ana işlevlerine bakıyoruz ve belirli örnekler kullanarak olanaklarını gösteriyoruz. Temel sorguları nasıl yazacağınızı ve bunları demo verilerinde nasıl test edeceğinizi öğreneceksiniz.
Teknik eğitim veya SQL bilgisi olmadan GBQ verileriyle ilgili raporlar oluşturun.
Reklam kampanyaları hakkında düzenli olarak raporlara ihtiyacınız var, ancak SQL çalışmak veya analistlerinizden yanıt beklemek için zamanınız yok mu? OWOX BI ile verilerinizin nasıl yapılandırıldığını anlamanıza gerek kalmadan raporlar oluşturabilirsiniz. Akıllı Veri raporunuzda görmek istediğiniz parametreleri ve metrikleri seçmeniz yeterlidir. OWOX BI Smart Data, verilerinizi anlayabileceğiniz şekilde anında görselleştirecektir.
İçindekiler
- SQL nedir ve BigQuery hangi lehçeleri destekler?
- nereden başlamalı
- Google BigQuery özellikleri
- Toplama işlevleri
- Tarih fonksiyonları
- dize işlevleri
- Pencere fonksiyonları
- Sonuçlar
SQL nedir ve BigQuery hangi lehçeleri destekler?
Yapılandırılmış Sorgu Dili (SQL), büyük dizilerdeki verileri almanıza, bunlara veri eklemenize ve bu dizilerdeki verileri değiştirmenize olanak tanır. Google BigQuery, iki SQL lehçesini destekler: Standart SQL ve güncelliğini yitirmiş Eski SQL.
Hangi lehçeyi seçeceğiniz tercihlerinize bağlıdır, ancak Google, şu avantajlar için Standart SQL kullanmanızı önerir:
- İç içe geçmiş ve yinelenen alanlar için esneklik ve işlevsellik
- Tablolardaki verileri değiştirmenize ve GBQ'daki tabloları ve görünümleri yönetmenize olanak tanıyan DML ve DDL dilleri için destek
- Eski SQL'e kıyasla büyük miktarda verinin daha hızlı işlenmesi
- Gelecekteki tüm BigQuery güncellemeleri için destek
BigQuery belgelerinde lehçe farklılıkları hakkında daha fazla bilgi edinebilirsiniz.
Ayrıca bkz: Google BigQuery'nin yeni Standart SQL lehçesinin Eski SQL'e göre avantajları nelerdir ve bununla hangi iş görevlerini çözebilirsiniz?
Varsayılan olarak, Google BigQuery sorguları Eski SQL üzerinde çalışır.
Standart SQL'e birkaç şekilde geçebilirsiniz:
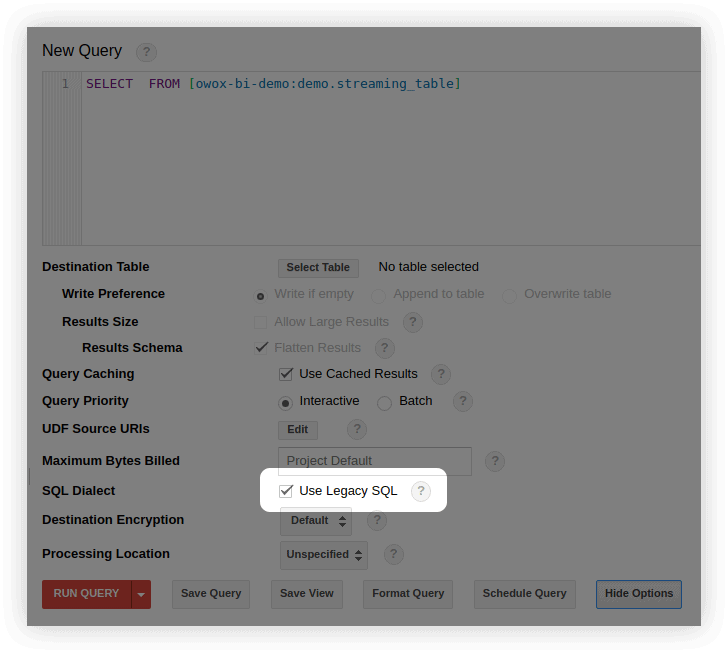
- BigQuery arayüzünde, sorgu düzenleme penceresinde, Seçenekleri Göster'i seçin ve Eski SQL Kullan seçeneğinin yanındaki onay işaretini kaldırın:
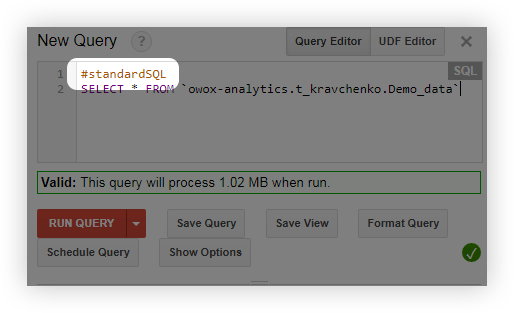
- Sorgulamadan önce #standartSQL satırını ekleyin ve sorgunuzu yeni bir satırla başlatın:
nereden başlamalı
Bizimle pratik yapıp sorguları çalıştırabilmeniz için, demo verileri içeren bir tablo hazırladık. Aşağıdaki formu doldurun, size e-posta ile gönderelim.


SQL sorguları uygulaması için demo verileri
indir Başlamak için demo veri tablonuzu indirin ve Google BigQuery projenize yükleyin. Bunu yapmanın en kolay yolu OWOX BI BigQuery Reports eklentisidir.
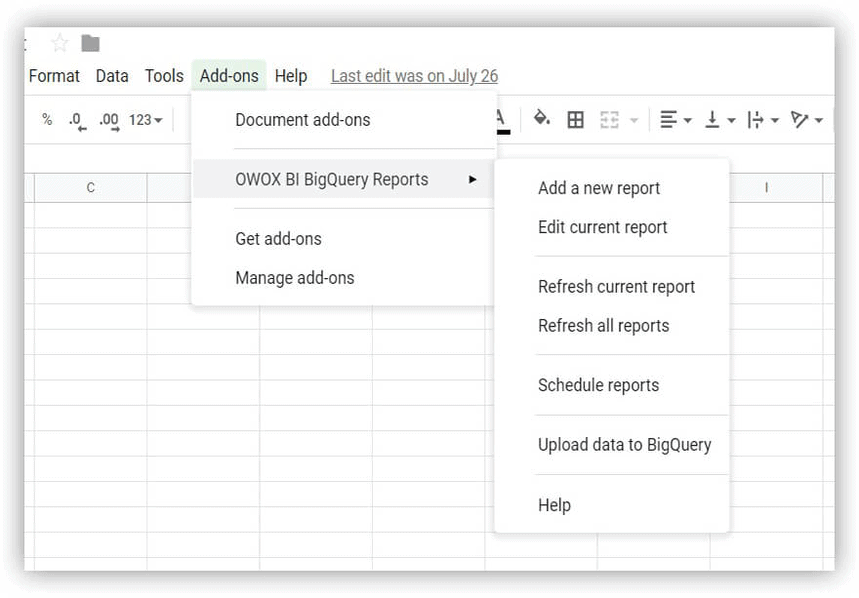
- Google E-Tablolar'ı açın ve OWOX BI BigQuery Reports eklentisini yükleyin.
- İndirdiğiniz, demo verilerini içeren tabloyu açın ve OWOX BI BigQuery Raporları -> Verileri BigQuery'ye Yükle'yi seçin:
- Açılan pencerede, bir veri seti olan Google BigQuery projenizi seçin ve yüklenen verilerin depolanacağı tablo için bir isim düşünün.
- Yüklenen veriler için bir biçim belirtin (ekran görüntüsünde gösterildiği gibi):

Google BigQuery'de bir projeniz yoksa bir tane oluşturun. Bunu yapmak için Google Cloud Platform'da etkin bir faturalandırma hesabına ihtiyacınız olacak. Bir banka kartı bağlamanız gerekmesi sizi korkutmasın: Bilginiz dışında sizden herhangi bir ücret alınmayacaktır. Ayrıca, kayıt olduğunuzda, 12 ay boyunca veri depolama ve işleme için harcayabileceğiniz 300$ alacaksınız.
OWOX BI, farklı sistemlerden gelen verileri BigQuery'de birleştirmenize yardımcı olur: web sitenizdeki kullanıcı eylemleri, aramalar, CRM'nizden gelen siparişler, e-postalar, reklam maliyetleri hakkındaki veriler. Gelişmiş analitiği özelleştirmek ve her türlü karmaşıklığa ilişkin raporları otomatikleştirmek için OWOX BI'ı kullanabilirsiniz.
Google BigQuery özelliklerinden bahsetmeden önce, hem Eski SQL hem de Standart SQL lehçelerinde temel sorguların nasıl göründüğünü hatırlayalım:
| Sorgu | Eski SQL | standart SQL |
|---|---|---|
| Tablodan alanları seçin | SEÇ alan1, alan2 | SEÇ alan1, alan2 |
| Alanların seçileceği bir tablo seçin | [proje kimliği:dataSet.tableName] | "projectID.dataSet.tableName"den |
| Değerlerin filtreleneceği parametreyi seçin | NEREDE alan 1=değer | NEREDE alan 1=değer |
| Sonuçların gruplanacağı alanları seçin | GROUP BY alan1, alan2 | GROUP BY alan1, alan2 |
| Sonuçların nasıl sipariş edileceğini seçin | SİPARİŞ BY alan1 ASC (artan) veya DESC (azalan) | SİPARİŞ BY alan1 ASC (artan) veya DESC (azalan) |
Google BigQuery özellikleri
Sorgular oluştururken en sık olarak toplama , tarih, dize ve pencere işlevlerini kullanırsınız. Bu işlev gruplarının her birine daha yakından bakalım.
Ayrıca bkz.: Bulut depolama ile çalışmaya nasıl başlanır — bir veri kümesi ve tablolar oluşturun ve verilerin Google BigQuery'ye aktarılmasını yapılandırın.
Toplama işlevleri
Toplama işlevleri, tüm tablo için özet değerler sağlar. Örneğin, ortalama çek boyutunu veya aylık toplam geliri hesaplamak için bunları kullanabilir veya maksimum sayıda satın alma gerçekleştiren kullanıcı segmentini seçmek için kullanabilirsiniz.
Bunlar en popüler toplama işlevleridir:
| Eski SQL | standart SQL | fonksiyon ne işe yarar |
|---|---|---|
| AVG(alan) | AVG([DISTINCT] (alan)) | Alan sütununun ortalama değerini döndürür. Standart SQL'de, bir DISTINCT koşulu eklediğinizde, yalnızca alan sütununda benzersiz (tekrarlanmayan) değerlere sahip satırlar için ortalama dikkate alınır. |
| MAKS(alan) | MAKS(alan) | Alan sütunundan maksimum değeri döndürür. |
| MIN(alan) | MIN(alan) | Alan sütunundaki minimum değeri döndürür. |
| TOPLA(alan) | TOPLA(alan) | Alan sütunundaki değerlerin toplamını döndürür. |
| COUNT(alan) | COUNT(alan) | Alan sütunundaki satır sayısını döndürür. |
| EXACT_COUNT_DISTINCT(alan) | COUNT([DISTINCT] (alan)) | Alan sütunundaki benzersiz satırların sayısını döndürür. |
Tüm toplu işlevlerin listesi için Eski SQL ve Standart SQL belgelerine bakın.
Bu işlevlerin nasıl çalıştığını görmek için demo verilerine bakalım. İşlemler için ortalama geliri, en yüksek ve en düşük tutarlar için satın almaları, toplam geliri, toplam işlemleri ve benzersiz işlem sayısını (satın almaların tekrarlanıp tekrarlanmadığını kontrol etmek için) hesaplayabiliriz. Bunun için Google BigQuery projemizin adını, veri setini ve tabloyu belirttiğimiz bir sorgu yazacağız.
#eski SQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]#standart SQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`Sonuç olarak, aşağıdakileri alacağız:
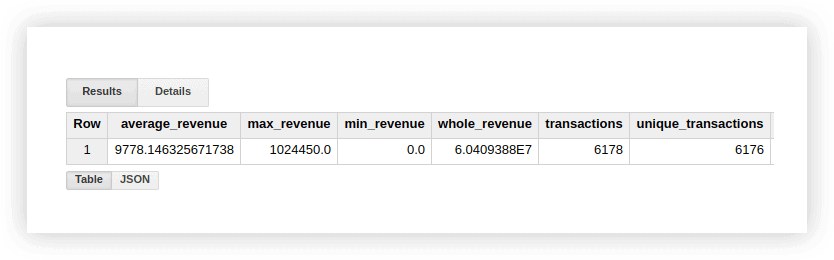
Bu hesaplamaların sonuçlarını, standart Google E-Tablolar işlevlerini (SUM, AVG ve diğerleri) veya özet tabloları kullanarak demo verileriyle orijinal tabloda kontrol edebilirsiniz.
Yukarıdaki ekran görüntüsünden de görebileceğiniz gibi, işlem sayısı ve benzersiz işlem sayısı farklıdır. Bu, tablomuzda aynı işlem kimliğine sahip iki işlem olduğunu gösterir:

Benzersiz işlemlerle ilgileniyorsanız, benzersiz dizeleri sayan bir işlev kullanın. Alternatif olarak, toplama işlevini uygulamadan önce yinelenenlerden kurtulmak için GROUP BY işlevini kullanarak verileri gruplayabilirsiniz.
SQL sorguları uygulaması için demo verileri
indirTarih fonksiyonları
Bu işlevler, tarihleri işlemenize olanak tanır: biçimlerini değiştirin, gerekli alanı seçin (gün, ay veya yıl) veya tarihi belirli bir aralıkta kaydırın.
Şu durumlarda faydalı olabilirler:
- gelişmiş analitik kurmak için farklı kaynaklardan tarihleri ve saatleri tek bir biçime dönüştürmek
- otomatik olarak güncellenen raporlar oluşturmak veya postaları tetiklemek (örneğin, son iki saat, hafta veya ay için verilere ihtiyacınız olduğunda)
- günler, haftalar veya aylar için veri elde etmenin gerekli olduğu kohort raporları oluşturmak
Bunlar en sık kullanılan tarih işlevleridir:
| Eski SQL | standart SQL | İşlev açıklaması |
|---|---|---|
| GEÇERLİ TARİH() | GEÇERLİ TARİH() | Geçerli tarihi % YYYY -% MM-% DD biçiminde döndürür. |
| DATE(zaman damgası) | DATE(zaman damgası) | Tarihi % YYYY -% MM-% DD% H:% M:% C.'den % YYYY -% MM-% DD biçimine dönüştürür. |
| DATE_ADD(zaman damgası, aralık, aralık_birimleri) | DATE_ADD(zaman damgası, ARALIK aralığı aralık_birimleri) | Belirtilen aralık aralığı kadar artırarak zaman damgası tarihini döndürür.interval_units.Eski SQL'de YIL, AY, GÜN, SAAT, DAKİKA ve SECOND değerlerini alabilir ve Standart SQL'de YIL, ÇEYREK, AY, HAFTA ve GÜN. |
| DATE_ADD(zaman damgası, - aralık, aralık_birimleri) | DATE_SUB(zaman damgası, ARALIK aralığı aralık_birimleri) | Belirtilen aralığa göre azaltarak zaman damgası tarihini döndürür. |
| DATEDIFF(zaman damgası1, zaman damgası2) | DATE_DIFF(zaman damgası1, zaman damgası2, tarih_bölümü) | Zaman damgası1 ve zaman damgası2 tarihleri arasındaki farkı döndürür. Eski SQL'de farkı gün olarak, Standart SQL'de ise belirtilen tarih_bölümü değerine (gün, hafta, ay, çeyrek, yıl) bağlı olarak farkı döndürür. |
| GÜN(zaman damgası) | ÖZET(zaman damgasından BAŞLANGIÇ GÜNÜ) | Zaman damgası tarihinden itibaren günü döndürür. 1'den 31'e kadar değerler alır. |
| MONTH(zaman damgası) | ÖZET(zaman damgasından AY) | Zaman damgası tarihinden itibaren ay sıra numarasını döndürür. 1'den 12'ye kadar değerler alır. |
| YIL(zaman damgası) | ÖZET(zaman damgasından itibaren YIL) | Zaman damgası tarihinden itibaren yılı döndürür. |
Tüm tarih işlevlerinin listesi için Eski SQL ve Standart SQL belgelerine bakın.
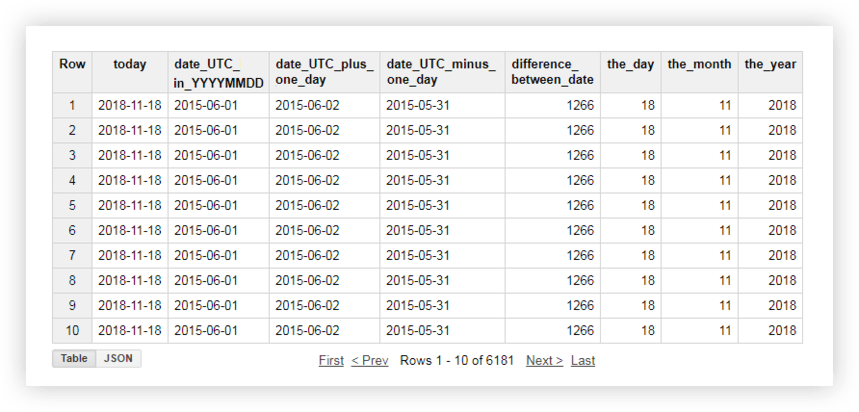
Bu işlevlerin her birinin nasıl çalıştığını görmek için demo verilerimize bir göz atalım. Örneğin, geçerli tarihi alacağız, orijinal tablodaki tarihi % YYYY -% MM-% GG formatına çevireceğiz, alıp bir gün ekleyeceğiz. Ardından, kaynak tablodan geçerli tarih ile tarih arasındaki farkı hesaplayacağız ve geçerli tarihi ayrı yıl, ay ve gün alanlarına böleceğiz. Bunu yapmak için aşağıdaki örnek sorguları kopyalayabilir ve proje adını, veri kümesini ve veri tablosunu kendi sorgunuzla değiştirebilirsiniz.
#eski SQL
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]#standart SQL
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)Sorguyu çalıştırdıktan sonra şu raporu alacaksınız:
Ayrıca bkz.: Google BigQuery'deki veriler üzerinde SQL sorguları kullanılarak oluşturulabilecek rapor örnekleri ve Google Analytics verilerini OWOX BI ile tamamlayabileceğiniz benzersiz metrikler.
dize işlevleri
Dize işlevleri, bir dize oluşturmanıza, alt dizeleri seçip değiştirmenize ve orijinal dizedeki bir dizenin uzunluğunu ve alt dizenin dizin dizisini hesaplamanıza olanak tanır. Örneğin, dize işlevleriyle şunları yapabilirsiniz:
- sayfa URL'sine iletilen UTM etiketleriyle bir raporu filtreleyin
- kaynak ve kampanya adları farklı kayıtlarda yazılmışsa verileri tek bir formata getirin
- bir rapordaki yanlış verileri değiştirin (örneğin, kampanya adı yanlış basılmışsa)
Dizelerle çalışmak için en popüler işlevler şunlardır:
| Eski SQL | standart SQL | İşlev açıklaması |
|---|---|---|
| CONCAT('str1', 'str2') veya 'str1'+ 'str2' | BİRLEŞTİR('str1', 'str2') | 'str1' ve 'str2'yi tek bir dizgede birleştirir. |
| 'str1' 'str2' İÇERİR | REGEXP_CONTAINS('str1', 'str2') veya 'str1' GİBİ '%str2%' | 'str1' dizesi 'str2' dizesini içeriyorsa true döndürür.' Standart SQL'de, 'str2' dizesi re2 kitaplığı kullanılarak normal bir ifade olarak yazılabilir. |
| UZUNLUK('str' ) | CHAR_LENGTH('str' )veya CHARACTER_LENGTH('str' ) | 'str' dizesinin uzunluğunu (karakter sayısı) döndürür. |
| SUBSTR('str', dizin [, max_len]) | SUBSTR('str', dizin [, max_len]) | 'str' dizesinden bir dizin karakteriyle başlayan max_len uzunluğunda bir alt dize döndürür. |
| LOWER('str') | LOWER('str') | 'str' dizesindeki tüm karakterleri küçük harfe dönüştürür. |
| ÜST(str) | ÜST(str) | 'str' dizesindeki tüm karakterleri büyük harfe dönüştürür. |
| INSTR('str1', 'str2') | STRPOS('str1', 'str2') | 'str2' dizesinin ilk oluşumunun dizinini 'str1' dizesine döndürür; aksi halde 0 döndürür. |
| DEĞİŞTİR('str1', 'str2', 'str3') | DEĞİŞTİR('str1', 'str2', 'str3') | 'str1'i 'str2' ile 'str3' ile değiştirir. |
Eski SQL ve Standart SQL belgelerinde tüm dize işlevleri hakkında daha fazla bilgi edinebilirsiniz.
Açıklanan işlevlerin nasıl kullanılacağını görmek için demo verilerine bakalım. Gün, ay ve yıl değerlerini içeren üç ayrı sütunumuz olduğunu varsayalım:

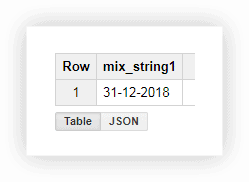
Bu biçimde bir tarihle çalışmak pek uygun değildir, bu nedenle değerleri tek bir sütunda birleştirebiliriz. Bunu yapmak için aşağıdaki SQL sorgularını kullanın ve projenizin, veri kümenizin ve tablonuzun adını Google BigQuery'de değiştirmeyi unutmayın.
#eski SQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1#standart SQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1Sorguyu çalıştırdıktan sonra tarihi bir sütunda alırız:
Genellikle, bir web sitesinde bir sayfa indirdiğinizde, URL, kullanıcının seçtiği değişkenlerin değerlerini kaydeder. Bu bir ödeme veya teslimat yöntemi, işlem numarası, alıcının ürünü almak istediği fiziksel mağazanın indeksi vb. olabilir. Bir SQL sorgusu kullanarak bu parametreleri sayfa adresinden seçebilirsiniz. Bunu nasıl ve neden yapabileceğinize dair iki örnek düşünün.
Örnek 1 . Kullanıcıların fiziksel mağazalardan mal aldığı satın alma sayısını bilmek istediğimizi varsayalım. Bunu yapmak için, URL'deki shop_id alt dizesini (fiziksel bir mağaza için bir dizin) içeren sayfalardan gönderilen işlemlerin sayısını hesaplamamız gerekir. Bunu aşağıdaki sorgularla yapabiliriz:
#eski SQL
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check#standart SQL

SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2
SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2Ortaya çıkan tablodan, shop_id içeren sayfalardan 5502 işlemin (check = true) gönderildiğini görüyoruz:

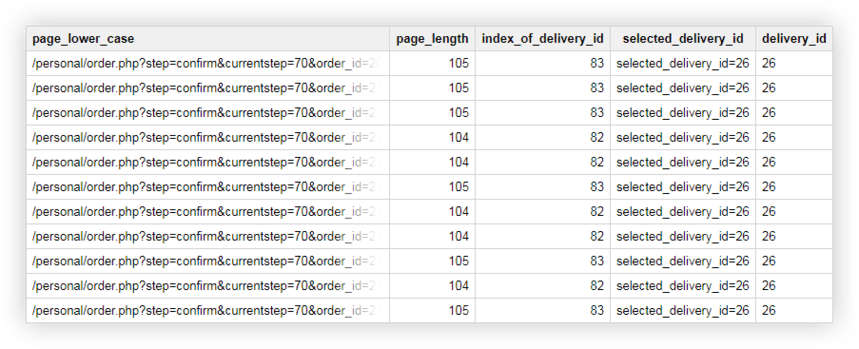
Örnek 2 . Her teslimat yöntemine bir teslimat_kimliği atadınız ve bu parametrenin değerini sayfa URL'sinde belirttiniz. Kullanıcının hangi teslimat yöntemini seçtiğini öğrenmek için ayrı bir sütunda teslimat_kimliğini seçmeniz gerekir.
Bunun için aşağıdaki sorguları kullanabiliriz:
#eski SQL
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC#standart SQL
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASCSonuç olarak, Google BigQuery'de şöyle bir tablo elde ederiz:
SQL sorguları uygulaması için demo verileri
indirPencere fonksiyonları
Bu işlevler, yukarıda tartıştığımız toplu işlevlere benzer. Temel fark, pencere işlevlerinin, sorgu kullanılarak seçilen tüm veri kümesi üzerinde hesaplamalar yapmaması, ancak bu verilerin yalnızca bir kısmı üzerinde (bir alt küme veya pencere ) hesaplama yapmasıdır.
Pencere işlevlerini kullanarak, birden çok sorguyu birleştirmek için JOIN işlevini kullanmadan verileri bir grup bölümünde toplayabilirsiniz. Örneğin, reklam kampanyası başına ortalama geliri veya cihaz başına işlem sayısını hesaplayabilirsiniz. Rapora bir alan daha ekleyerek, örneğin Kara Cuma günü bir reklam kampanyasından elde edilen gelirin payını veya bir mobil uygulamadan yapılan işlemlerin payını kolayca öğrenebilirsiniz.
Sorgudaki her işlevle birlikte, pencere sınırlarını tanımlayan OVER ifadesini hecelemelisiniz. OVER, birlikte çalışabileceğiniz üç bileşen içerir:
- BÖLÜM BY — Orijinal verileri clientId veya DayTime gibi alt kümelere böldüğünüz özelliği tanımlar.
- ORDER BY — Saat DESC gibi bir alt kümedeki satırların sırasını tanımlar
- PENCERE ÇERÇEVESİ — Belirli bir özelliğin alt kümesindeki satırları işlemenize olanak tanır (örneğin, geçerli satırdan yalnızca beş satır önce)
Bu tabloda, en sık kullanılan pencere işlevlerini topladık:
| Eski SQL | standart SQL | İşlev açıklaması |
|---|---|---|
| AVG(alan) COUNT(alan) COUNT(FARKLI alan) MAKS() MIN() TOPLA() | AVG([DISTINCT] (alan)) COUNT(alan) COUNT([DISTINCT] (alan)) MAKS(alan) MIN(alan) TOPLA(alan) | Seçili altküme içindeki alan sütunundan ortalama, sayı, maksimum, minimum ve toplam değeri döndürür.DISTINCT, yalnızca benzersiz (tekrarlanmayan) değerleri hesaplamak için kullanılır. |
| DENSE_RANK() | DENSE_RANK() | Bir alt küme içindeki satır numarasını döndürür. |
| FIRST_VALUE(alan) | FIRST_VALUE (alan[{SAYGI | IGNORE} NULLS]) | Bir alt küme içindeki alan sütunundan ilk satırın değerini döndürür. Varsayılan olarak, alan sütunundaki boş değerlere sahip satırlar hesaplamaya dahil edilir. RESPECT veya IGNORE NULLS, NULL dizelerin dahil edilip edilmeyeceğini belirtir. |
| LAST_VALUE(alan) | LAST_VALUE (alan [{SAYGI | IGNORE} NULLS]) | Alan sütunundaki bir alt küme içindeki son satırın değerini döndürür.Varsayılan olarak, alan sütununda boş değerlere sahip satırlar hesaplamaya dahil edilir. RESPECT veya IGNORE NULLS, NULL dizelerin dahil edilip edilmeyeceğini belirtir. |
| GECİKME(alan) | LAG (alan[, offset [, default_expression]]) | Alt küme içindeki geçerli alan sütununa göre önceki satırın değerini döndürür.Offset, geçerli satırdan aşağı kaydırılacak satır sayısını belirten bir tamsayıdır.Varsayılan_ifade, gerekli değilse işlevin döndüreceği değerdir. alt küme içindeki dize. |
| KURŞUN(alan) | KURŞUN (alan[, offset [, default_expression]]) | Alt küme içindeki geçerli alan sütununa göre sonraki satırın değerini döndürür. Ofset, geçerli satıra göre yukarı taşımak istediğiniz satır sayısını tanımlayan bir tamsayıdır.Varsayılan_ifade, geçerli altkümede gerekli bir dize yoksa işlevin döndüreceği değerdir. |
Eski SQL ve Standart SQL belgelerinde tüm toplu analitik işlevlerin ve gezinme işlevlerinin bir listesini görebilirsiniz.
Örnek 1 . Diyelim ki müşterilerin mesai saatleri ve mesai saatleri dışındaki aktivitelerini analiz etmek istiyoruz. Bunu yapmak için işlemleri iki gruba ayırmamız ve ilgilenilen metrikleri hesaplamamız gerekiyor:
- Grup 1 — Çalışma saatleri içinde 9:00 - 18:00 arası satın almalar
- 2. Grup — 00:00 - 9:00 ve 18:00 - 23:59 saatleri arasındaki satın almalar
Çalışma ve çalışma dışı saatlere ek olarak, bir pencere oluşturmak için başka bir değişken de clientId'dir. Yani, her kullanıcı için iki penceremiz olacak:
| pencere | Müşteri Kimliği | Gündüz |
|---|---|---|
| pencere 1 | müşteri kimliği 1 | çalışma saatleri |
| pencere 2 | müşteri kimliği 2 | çalışma dışı saatler |
| pencere 3 | müşteri kimliği 3 | çalışma saatleri |
| pencere 4 | müşteri kimliği 4 | çalışma dışı saatler |
| N penceresi | müşteri kimliği N | çalışma saatleri |
| pencere N+1 | müşteri kimliği N+1 | çalışma dışı saatler |
Çalışma ve çalışma saatleri dışında ortalama, maksimum, minimum ve toplam geliri, toplam işlem sayısını ve kullanıcı başına benzersiz işlem sayısını hesaplamak için demo verilerini kullanalım. Aşağıdaki istekler bunu yapmamıza yardımcı olacaktır.
#eski SQL
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC#standart SQL
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESCClientId 102041117.1428132012 ile kullanıcı örneğini kullanarak sonuç olarak ne olduğunu görelim. Bu kullanıcının orijinal tablosunda aşağıdaki verilere sahibiz:

Sorguyu çalıştırarak, bu kullanıcıdan elde edilen ortalama, minimum, maksimum ve toplam gelirin yanı sıra kullanıcının toplam işlem sayısını içeren bir rapor alırız. Aşağıdaki ekran görüntüsünde de görebileceğiniz gibi her iki işlem de kullanıcı tarafından mesai saatleri içerisinde yapılmıştır:

Örnek 2 . Şimdi daha karmaşık bir görev için:
- Yürütme zamanına bağlı olarak tüm işlemler için sıra numaralarını pencereye koyun. Pencereyi kullanıcı ve çalışma/çalışmayan zaman dilimlerine göre tanımladığımızı hatırlayın.
- Pencerede sonraki/önceki işlemin (geçerli olana göre) gelirini rapor edin.
- Pencerede ilk ve son işlemlerin gelirini görüntüleyin.
Bunu yapmak için aşağıdaki sorguları kullanacağız:
#eski SQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour#standart SQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hourHesaplamaların sonuçlarını zaten bildiğimiz bir kullanıcı örneğini kullanarak kontrol edebiliriz: clientId 102041117.1428132012:

Yukarıdaki ekran görüntüsünden şunu görebiliriz:
- ilk işlem saat 15:00'te ikinci işlem 16:00'da yapıldı.
- 15:00'teki işlemden sonra, 16:00'da 25066 gelirli bir işlem gerçekleşti (sütun lead_revenue)
- 16:00'daki işlemden önce, saat 15:00'te 3699 gelirli bir işlem vardı (sütun gecikme_geliri)
- pencere içindeki ilk işlem saat 15:00'teydi ve bu işlem için gelir 3699'du (ilk_revenue_by_hour sütunu)
- sorgu, verileri satır satır işler, bu nedenle söz konusu işlem için penceredeki son işlemin kendisi olacak ve last_revenue_by_hour sütunlarındaki değerler ve gelir aynı olacaktır.
Google BigQuery hakkında faydalı makaleler:
- En İyi 6 BigQuery Görselleştirme Aracı
- Google BigQuery'ye Nasıl Veri Yüklenir?
- Google Ads'den Google BigQuery'ye Ham Veri Nasıl Yüklenir
- Google BigQuery Google E-Tablolar Bağlayıcı
- Google BigQuery'den Verileri Kullanarak Google E-Tablolardaki Raporları Otomatikleştirin
- Google BigQuery'den Alınan Verilere Dayalı Google Data Studio'daki raporları otomatikleştirin
Google BigQuery'de web sitenizden örneklenmemiş veriler toplamak istiyorsanız ancak nereden başlayacağınızı bilmiyorsanız, bir demo rezervasyonu yapın. BigQuery ve OWOX BI ile elde edebileceğiniz tüm olasılıkları size anlatacağız.
Müşterilerimiz
büyümek %22 daha hızlı
Pazarlamanızda en çok neyin işe yaradığını ölçerek daha hızlı büyüyün
Pazarlama verimliliğinizi analiz edin, büyüme alanlarını bulun, yatırım getirisini artırın
Demo alınSonuçlar
Bu makalede, en popüler işlev gruplarına baktık: toplama, tarih, dize ve pencere. Ancak, Google BigQuery'nin aşağıdakiler de dahil olmak üzere daha birçok yararlı işlevi vardır:
- verileri belirli bir biçime dönüştürmenize izin veren döküm işlevleri
- bir veri kümesindeki birden çok tabloya erişmenizi sağlayan tablo joker işlevleri
- bir arama sorgusunun tam değerini değil modelini tanımlamanıza izin veren normal ifade işlevleri
Bu işlevler hakkında kesinlikle blogumuzda yazacağız. Bu arada, demo verilerimizi kullanarak bu makalede açıklanan tüm işlevleri deneyebilirsiniz.
SQL sorguları uygulaması için demo verileri
indir