
Обзор основных возможностей Google BigQuery — попрактикуйтесь в написании запросов для маркетингового анализа
Опубликовано: 2022-04-12Чем больше информации накапливает бизнес, тем острее встает вопрос, где ее хранить. Если у вас нет возможности или желания обслуживать собственные серверы, вам может помочь Google BigQuery (GBQ). BigQuery предоставляет быстрое, экономичное и масштабируемое хранилище для работы с большими данными и позволяет писать запросы, используя синтаксис, подобный SQL, а также стандартные и определяемые пользователем функции.
В этой статье мы рассмотрим основные функции BigQuery и покажем их возможности на конкретных примерах. Вы научитесь писать базовые запросы и тестировать их на демонстрационных данных.
Создавайте отчеты по данным GBQ без технической подготовки или знания SQL.
Вам регулярно нужны отчеты по рекламным кампаниям, но нет времени на изучение SQL или ожидание ответа от ваших аналитиков? С OWOX BI вы можете создавать отчеты, не разбираясь в том, как устроены ваши данные. Просто выберите параметры и показатели, которые вы хотите видеть в отчете Smart Data. OWOX BI Smart Data мгновенно визуализирует ваши данные в понятном для вас виде.
Оглавление
- Что такое SQL и какие диалекты поддерживает BigQuery
- Когда начать
- Возможности Google BigQuery
- Агрегатные функции
- Функции даты
- Строковые функции
- Оконные функции
- Выводы
Что такое SQL и какие диалекты поддерживает BigQuery
Язык структурированных запросов (SQL) позволяет извлекать данные, добавлять данные и изменять данные в больших массивах. Google BigQuery поддерживает два диалекта SQL: стандартный SQL и устаревший устаревший SQL.
Какой диалект выбрать, зависит от ваших предпочтений, но Google рекомендует использовать стандартный SQL для следующих преимуществ:
- Гибкость и функциональность для вложенных и повторяющихся полей
- Поддержка языков DML и DDL, позволяющая изменять данные в таблицах, а также управлять таблицами и представлениями в GBQ.
- Более быстрая обработка больших объемов данных по сравнению с Legacy SQL
- Поддержка всех будущих обновлений BigQuery.
Вы можете узнать больше о различиях диалектов в документации BigQuery.
Читайте также: В чем преимущества нового диалекта Standard SQL Google BigQuery перед Legacy SQL и какие бизнес-задачи можно решить с его помощью?
По умолчанию запросы Google BigQuery выполняются на устаревшем SQL.
Вы можете переключиться на стандартный SQL несколькими способами:
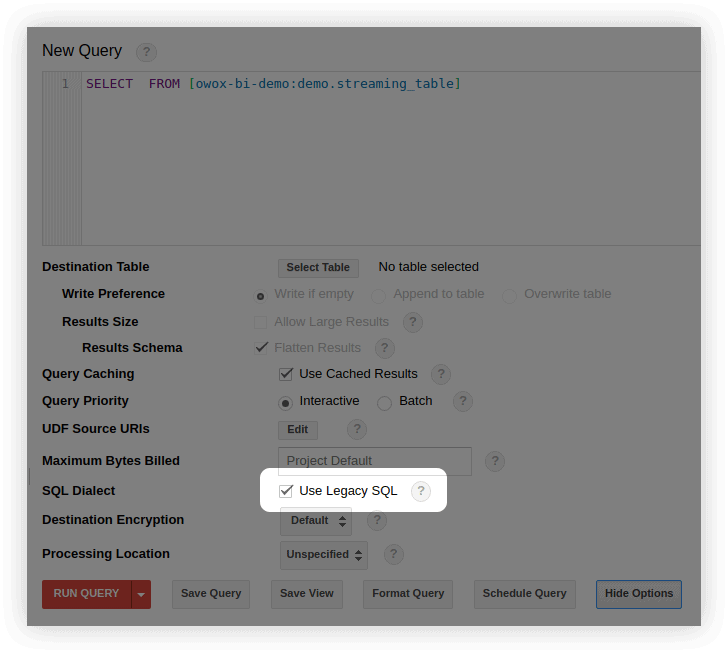
- В интерфейсе BigQuery в окне редактирования запроса выберите Show Options и снимите галочку напротив Use Legacy SQL :
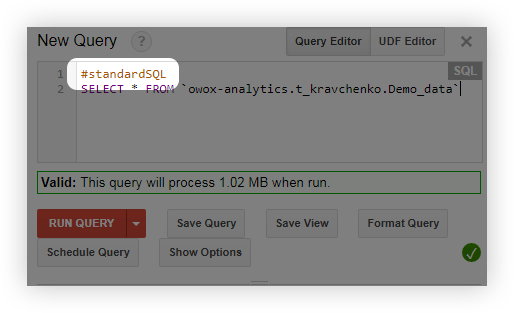
- Перед запросом добавьте строку #standardSQL и начните запрос с новой строки:
Когда начать
Чтобы вы могли потренироваться и выполнить запросы вместе с нами, мы подготовили таблицу с демонстрационными данными. Заполните форму ниже, и мы отправим ее вам по электронной почте.


Демонстрационные данные для практики запросов SQL
Скачать Для начала загрузите таблицу демонстрационных данных и загрузите ее в свой проект Google BigQuery. Проще всего это сделать с помощью модуля OWOX BI BigQuery Reports.
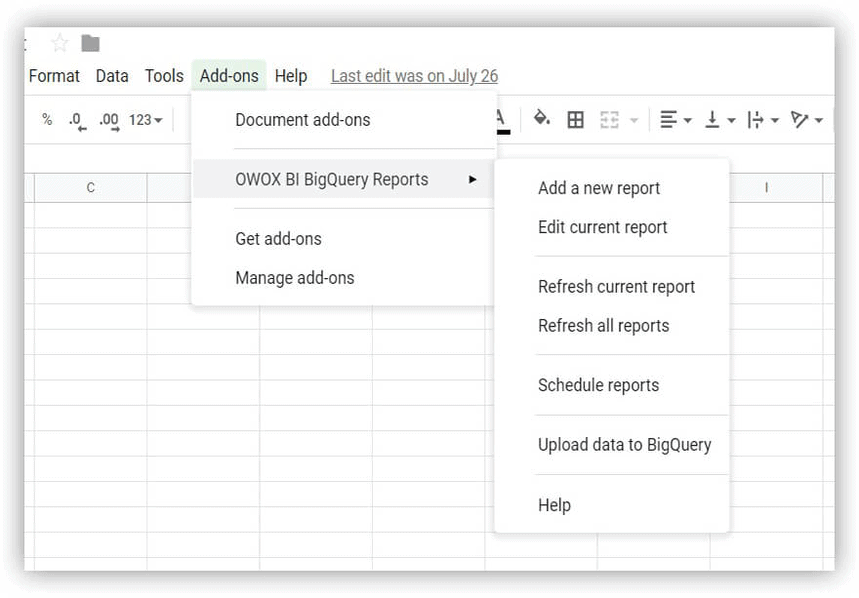
- Откройте Google Sheets и установите надстройку OWOX BI BigQuery Reports.
- Откройте загруженную вами таблицу с демо-данными и выберите OWOX BI BigQuery Reports -> Upload Data to BigQuery :
- В открывшемся окне выберите свой проект Google BigQuery, набор данных и придумайте имя для таблицы, в которой будут храниться загруженные данные.
- Укажите формат загружаемых данных (как показано на скриншоте):

Если у вас нет проекта в Google BigQuery, создайте его. Для этого вам понадобится активная платежная учетная запись в Google Cloud Platform. Пусть вас не пугает необходимость привязки банковской карты: без вашего ведома с вас ничего не спишут. Кроме того, при регистрации вы получите 300 долларов на 12 месяцев, которые сможете потратить на хранение и обработку данных.
OWOX BI помогает объединять в BigQuery данные из разных систем: данные о действиях пользователей на вашем сайте, звонках, заказах из вашей CRM, электронных письмах, расходах на рекламу. Вы можете использовать OWOX BI для настройки расширенной аналитики и автоматизации отчетов любой сложности.
Прежде чем говорить о возможностях Google BigQuery, давайте вспомним, как выглядят базовые запросы в диалектах Legacy SQL и Standard SQL:
| Запрос | Устаревший SQL | Стандартный SQL |
|---|---|---|
| Выбрать поля из таблицы | ВЫБЕРИТЕ поле1,поле2 | ВЫБЕРИТЕ поле1,поле2 |
| Выберите таблицу, из которой нужно выбрать поля | ОТ [ID_проекта:dataSet.tableName] | ИЗ `projectID.dataSet.tableName` |
| Выберите параметр, по которому следует фильтровать значения | ГДЕ поле1=значение | ГДЕ поле1=значение |
| Выберите поля, по которым следует группировать результаты | СГРУППИРОВАТЬ ПО полю1, полю2 | СГРУППИРОВАТЬ ПО полю1, полю2 |
| Выберите, как упорядочить результаты | ORDER BY field1 ASC (по возрастанию) или DESC (по убыванию) | ORDER BY field1 ASC (по возрастанию) или DESC (по убыванию) |
Возможности Google BigQuery
При построении запросов вы чаще всего будете использовать агрегатные, датовые, строковые и оконные функции. Рассмотрим подробнее каждую из этих групп функций.
Читайте также: Как начать работать с облачным хранилищем — создать набор данных и таблицы и настроить импорт данных в Google BigQuery.
Агрегатные функции
Агрегатные функции предоставляют сводные значения для всей таблицы. Например, вы можете использовать их для расчета среднего размера чека или общей выручки в месяц, а можете использовать их для выбора сегмента пользователей, совершивших максимальное количество покупок.
Вот самые популярные агрегатные функции:
| Устаревший SQL | Стандартный SQL | Что делает функция |
|---|---|---|
| СРЕДНЕЕ (поле) | AVG([DISTINCT] (поле)) | Возвращает среднее значение столбца поля. В стандартном SQL при добавлении условия DISTINCT среднее значение учитывается только для строк с уникальными (неповторяющимися) значениями в столбце поля. |
| МАКС(поле) | МАКС(поле) | Возвращает максимальное значение из столбца поля. |
| МИН(поле) | МИН(поле) | Возвращает минимальное значение из столбца поля. |
| СУММ(поле) | СУММ(поле) | Возвращает сумму значений из столбца поля. |
| СЧЕТ(поле) | СЧЕТ(поле) | Возвращает количество строк в столбце поля. |
| EXACT_COUNT_DISTINCT(поле) | COUNT([DISTINCT] (поле)) | Возвращает количество уникальных строк в столбце поля. |
Список всех агрегатных функций см. в документации по Legacy SQL и Standard SQL.
Давайте посмотрим на демонстрационные данные, чтобы увидеть, как работают эти функции. Мы можем рассчитать средний доход от транзакций, покупок на самые высокие и самые низкие суммы, общий доход, общее количество транзакций и количество уникальных транзакций (чтобы проверить, не дублировались ли покупки). Для этого напишем запрос, в котором укажем название нашего проекта Google BigQuery, набора данных и таблицы.
#устаревший SQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]#стандартный SQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`В результате получим следующее:
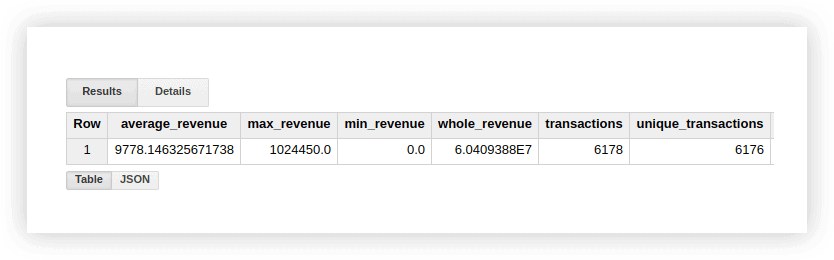
Вы можете проверить результаты этих расчетов в исходной таблице с демонстрационными данными, используя стандартные функции Google Sheets (SUM, AVG и другие) или используя сводные таблицы.
Как видно из скриншота выше, количество транзакций и уникальных транзакций разное. Это говорит о том, что в нашей таблице есть две транзакции с одинаковым идентификатором транзакции:

Если вас интересуют уникальные транзакции, используйте функцию, которая подсчитывает уникальные строки. Кроме того, вы можете сгруппировать данные с помощью функции GROUP BY, чтобы избавиться от дубликатов перед применением функции агрегирования.
Демонстрационные данные для практики запросов SQL
СкачатьФункции даты
Эти функции позволяют обрабатывать даты: изменять их формат, выбирать необходимое поле (день, месяц, год) или сдвигать дату на определенный интервал.
Они могут быть полезны, когда:
- преобразование даты и времени из разных источников в единый формат для настройки расширенной аналитики
- создание автоматически обновляемых отчетов или триггерных рассылок (например, когда вам нужны данные за последние два часа, неделю или месяц)
- создание когортных отчетов, в которых необходимо получить данные за период дней, недель или месяцев
Вот наиболее часто используемые функции даты:
| Устаревший SQL | Стандартный SQL | Описание функции |
|---|---|---|
| ТЕКУЩАЯ ДАТА() | ТЕКУЩАЯ ДАТА() | Возвращает текущую дату в формате %ГГГГ-%ММ-%ДД. |
| ДАТА(отметка времени) | ДАТА(отметка времени) | Преобразует дату из формата %ГГГГ-%ММ-%ДД%Ч:%М:%С в формат %ГГГГ-%ММ-%ДД. |
| DATE_ADD(отметка времени, интервал, интервал_единиц) | DATE_ADD(отметка времени, INTERVAL интервал interval_units) | Возвращает отметку даты, увеличивая ее на указанный интервал interval.interval_units. В устаревшем SQL он может принимать значения ГОД, МЕСЯЦ, ДЕНЬ, ЧАС, МИНУТА и СЕКУНД, а в стандартном SQL может принимать значения ГОД, КВАРТАЛ, МЕСЯЦ, НЕДЕЛЯ и ДЕНЬ. |
| DATE_ADD(отметка времени, - интервал, интервал_единиц) | DATE_SUB(отметка времени, INTERVAL интервал interval_units) | Возвращает дату метки времени, уменьшая ее на указанный интервал. |
| DATEDIFF(метка времени1, метка времени2) | DATE_DIFF (отметка времени1, отметка времени2, часть_даты) | Возвращает разницу между датами timestamp1 и timestamp2. В Legacy SQL возвращает разницу в днях, а в Standard SQL возвращает разницу в зависимости от указанного значения date_part (день, неделя, месяц, квартал, год). |
| ДЕНЬ(отметка времени) | ВЫДЕРЖКА (ДЕНЬ ИЗ метки времени) | Возвращает день из даты отметки времени. Принимает значения от 1 до 31 включительно. |
| МЕСЯЦ(отметка времени) | ВЫДЕРЖКА (МЕСЯЦ ИЗ метки времени) | Возвращает порядковый номер месяца из даты отметки времени. Принимает значения от 1 до 12 включительно. |
| ГОД(отметка времени) | ВЫДЕРЖКА (ГОД ИЗ метки времени) | Возвращает год из даты отметки времени. |
Список всех функций даты см. в документации Legacy SQL и Standard SQL.
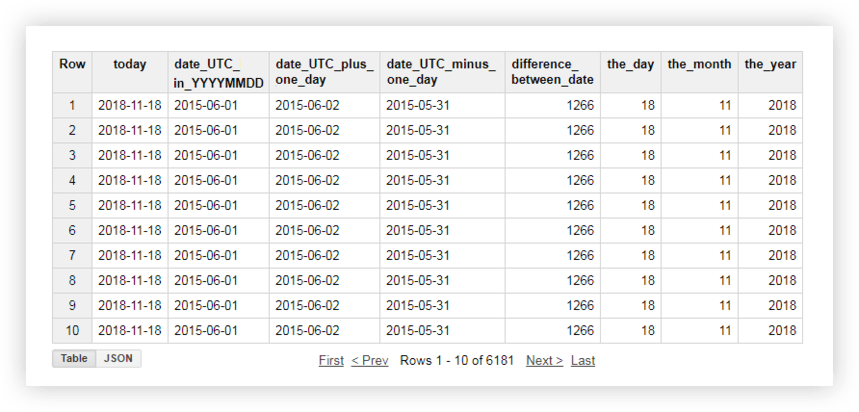
Давайте посмотрим на наши демонстрационные данные, чтобы увидеть, как работает каждая из этих функций. Например, мы получим текущую дату, превратим дату из исходной таблицы в формат %ГГГГ-%ММ-%ДД, отнимем ее и добавим к ней один день. Затем мы вычислим разницу между текущей датой и датой из исходной таблицы и разобьем текущую дату на отдельные поля года, месяца и дня. Для этого вы можете скопировать примеры запросов ниже и заменить имя проекта, набор данных и таблицу данных своими собственными.
#устаревший SQL
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]#стандартный SQL
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)После выполнения запроса вы получите этот отчет:
Читайте также: Примеры отчетов, которые можно построить с помощью SQL-запросов к данным в Google BigQuery и какими уникальными метриками можно дополнить данные Google Analytics с помощью OWOX BI.
Строковые функции
Строковые функции позволяют генерировать строку, выбирать и заменять подстроки, а также вычислять длину строки и последовательность индексов подстроки в исходной строке. Например, со строковыми функциями вы можете:
- фильтровать отчет с тегами UTM, которые передаются в URL-адрес страницы
- привести данные к единому формату, если название источника и кампании записаны в разных регистрах
- заменить неверные данные в отчете (например, если опечатка в названии кампании)
Вот самые популярные функции для работы со строками:
| Устаревший SQL | Стандартный SQL | Описание функции |
|---|---|---|
| CONCAT('str1', 'str2') или 'str1'+ 'str2' | CONCAT('строка1', 'строка2') | Объединяет «str1» и «str2» в одну строку. |
| 'str1' СОДЕРЖИТ 'str2' | REGEXP_CONTAINS('str1', 'str2') или 'str1' LIKE '%str2%' | Возвращает true, если строка «str1» содержит строку «str2». В стандартном SQL строка «str2» может быть записана как регулярное выражение с использованием библиотеки re2 . |
| ДЛИНА('ул' ) | CHAR_LENGTH('str' )или CHARACTER_LENGTH('str' ) | Возвращает длину строки 'str' (количество символов). |
| SUBSTR('str', индекс [, max_len]) | SUBSTR('str', индекс [, max_len]) | Возвращает подстроку длины max_len, начинающуюся с символа индекса из строки 'str'. |
| НИЖЕ('стр') | НИЖЕ('стр') | Преобразует все символы строки 'str в нижний регистр. |
| ВЕРХНИЙ(стр.) | ВЕРХНИЙ(стр.) | Преобразует все символы строки 'str' в верхний регистр. |
| INSTR('строка1', 'строка2') | STRPOS('строка1', 'строка2') | Возвращает индекс первого вхождения строки "str2" в строку "str1"; в противном случае возвращает 0. |
| ЗАМЕНИТЬ('строка1', 'строка2', 'строка3') | ЗАМЕНИТЬ('строка1', 'строка2', 'строка3') | Заменяет «str1» на «str2» на «str3». |
Вы можете узнать больше обо всех строковых функциях в документации Legacy SQL и Standard SQL.
Давайте посмотрим на демонстрационные данные, чтобы увидеть, как использовать описанные функции. Предположим, у нас есть три отдельных столбца, которые содержат значения дня, месяца и года:

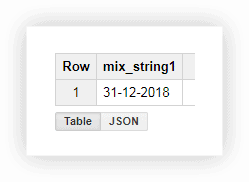
Работать с датой в таком формате не очень удобно, поэтому мы можем объединить значения в один столбец. Для этого используйте приведенные ниже SQL-запросы и не забудьте подставить название вашего проекта, набора данных и таблицы в Google BigQuery.
#устаревший SQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1#стандартный SQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1После выполнения запроса мы получаем дату в одном столбце:
Часто, когда вы загружаете страницу на веб-сайте, URL-адрес записывает значения переменных, выбранных пользователем. Это может быть способ оплаты или доставки, номер транзакции, индекс физического магазина, в котором покупатель хочет забрать товар и т. д. С помощью SQL-запроса можно выбрать эти параметры из адреса страницы. Рассмотрим два примера того, как и почему вы можете это сделать.
Пример 1 . Предположим, мы хотим узнать количество покупок, при которых пользователи забирают товары из физических магазинов. Для этого нам нужно подсчитать количество транзакций, отправленных со страниц в URL, содержащих подстроку shop_id (индекс для физического магазина). Мы можем сделать это с помощью следующих запросов:
#устаревший SQL
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check#стандартный SQL

SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2
SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2Из полученной таблицы видим, что со страниц, содержащих shop_id, было отправлено 5502 транзакции (check = true):

Пример 2 . Вы назначили delivery_id каждому способу доставки и указали значение этого параметра в URL-адресе страницы. Чтобы узнать, какой способ доставки выбрал пользователь, нужно выбрать delivery_id в отдельной колонке.
Для этого мы можем использовать следующие запросы:
#устаревший SQL
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC#стандартный SQL
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASCВ итоге получаем вот такую таблицу в Google BigQuery:
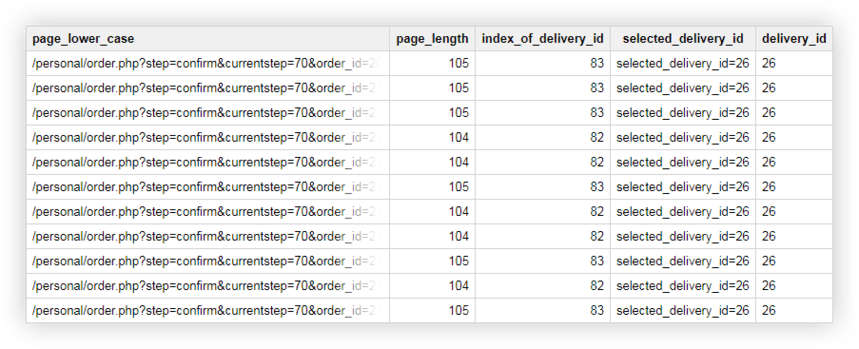
Демонстрационные данные для практики запросов SQL
СкачатьОконные функции
Эти функции аналогичны агрегатным функциям, которые мы обсуждали выше. Основное отличие состоит в том, что оконные функции выполняют вычисления не со всем набором данных, выбранным с помощью запроса, а только с частью этих данных — подмножеством или окном .
Используя оконные функции, вы можете агрегировать данные в групповом разделе без использования функции JOIN для объединения нескольких запросов. Например, вы можете рассчитать средний доход от рекламной кампании или количество транзакций на устройство. Добавив в отчет еще одно поле, вы легко сможете узнать, например, долю выручки от рекламной кампании в Черную пятницу или долю транзакций, совершенных из мобильного приложения.
Вместе с каждой функцией в запросе необходимо указать выражение OVER, определяющее границы окна. OVER содержит три компонента, с которыми вы можете работать:
- PARTITION BY — определяет характеристику, по которой вы делите исходные данные на подмножества, такие как clientId или DayTime.
- ORDER BY — определяет порядок строк в подмножестве, таком как час DESC
- РАМКА ОКНА — позволяет обрабатывать строки в подмножестве определенного объекта (например, только пять строк перед текущей строкой).
В этой таблице мы собрали наиболее часто используемые оконные функции:
| Устаревший SQL | Стандартный SQL | Описание функции |
|---|---|---|
| СРЕДНЕЕ (поле) СЧЕТ(поле) COUNT(ОТЛИЧНОЕ поле) МАКСИМУМ() МИН() СУММ() | AVG([DISTINCT] (поле)) СЧЕТ(поле) COUNT([DISTINCT] (поле)) МАКС(поле) МИН(поле) СУММ(поле) | Возвращает среднее, числовое, максимальное, минимальное и общее значение из столбца поля в выбранном подмножестве. DISTINCT используется для вычисления только уникальных (неповторяющихся) значений. |
| ПЛОТНЫЙ_РАНГ() | ПЛОТНЫЙ_РАНГ() | Возвращает номер строки в подмножестве. |
| FIRST_VALUE(поле) | FIRST_VALUE (поле[{ОТНОСИТЕЛЬНО | ИГНОРИРОВАТЬ} NULLS]) | Возвращает значение первой строки из столбца поля в подмножестве. По умолчанию в расчет включаются строки с пустыми значениями из столбца поля. RESPECT или IGNORE NULLS указывает, следует ли включать или игнорировать строки NULL. |
| LAST_VALUE(поле) | LAST_VALUE (поле [{RESPECT | IGNORE} NULLS]) | Возвращает значение последней строки в подмножестве из столбца поля. По умолчанию в расчет включаются строки с пустыми значениями в столбце поля. RESPECT или IGNORE NULLS указывает, следует ли включать или игнорировать строки NULL. |
| LAG(поле) | LAG (поле[, смещение [, default_expression]]) | Возвращает значение предыдущей строки по отношению к текущему столбцу поля в пределах подмножества. Смещение — это целое число, указывающее количество строк для смещения вниз от текущей строки. Выражение по умолчанию — это значение, которое функция вернет, если нет требуемого строка внутри подмножества. |
| ВЕДУЩИЙ(поле) | LEAD (поле[, смещение [, default_expression]]) | Возвращает значение следующей строки относительно текущего столбца поля в подмножестве. Смещение — это целое число, которое определяет количество строк, которые вы хотите переместить вверх по отношению к текущей строке. Выражение_по умолчанию — это значение, которое возвращает функция, если в текущем подмножестве нет требуемой строки. |
Вы можете увидеть список всех агрегированных аналитических функций и функций навигации в документации для Legacy SQL и Standard SQL.
Пример 1 . Допустим, мы хотим проанализировать активность клиентов в рабочее и нерабочее время. Для этого нам нужно разделить транзакции на две группы и рассчитать интересующие метрики:
- Группа 1 — Закупки в рабочее время с 9:00 до 18:00
- Группа 2 — Покупки в нерабочее время с 00:00 до 9:00 и с 18:00 до 23:59
Помимо рабочего и нерабочего времени, еще одной переменной для формирования окна является clientId. То есть для каждого пользователя у нас будет два окна:
| окно | ID клиента | Дневное время |
|---|---|---|
| окно 1 | идентификатор клиента 1 | рабочие часы |
| окно 2 | идентификатор клиента 2 | нерабочее время |
| окно 3 | идентификатор клиента 3 | рабочие часы |
| окно 4 | идентификатор клиента 4 | нерабочее время |
| окно N | идентификатор клиента N | рабочие часы |
| окно N+1 | идентификатор клиента N+1 | нерабочее время |
Давайте воспользуемся демонстрационными данными для расчета среднего, максимального, минимального и общего дохода, общего количества транзакций и количества уникальных транзакций на пользователя в рабочее и нерабочее время. Приведенные ниже запросы помогут нам в этом.
#устаревший SQL
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC#стандартный SQL
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESCПосмотрим, что получится в результате на примере пользователя с clientId 102041117.1428132012. В исходной таблице для этого пользователя имеем следующие данные:

Выполняя запрос, мы получаем отчет, который содержит средний, минимальный, максимальный и общий доход от этого пользователя, а также общее количество транзакций пользователя. Как видно на скриншоте ниже, обе транзакции были совершены пользователем в рабочее время:

Пример 2 . Теперь более сложная задача:
- Ставьте порядковые номера для всех транзакций в окне в зависимости от времени их выполнения. Напомним, что мы определяем окно по пользователю и рабочим/нерабочим временным интервалам.
- Сообщите доход от следующей/предыдущей транзакции (относительно текущей) в пределах окна.
- Отображать выручку первой и последней транзакций в окне.
Для этого воспользуемся следующими запросами:
#устаревший SQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour#стандартный SQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hourМы можем проверить результаты вычислений на примере уже известного нам пользователя: clientId 102041117.1428132012:

На скриншоте выше мы видим, что:
- первая транзакция была в 15:00, а вторая транзакция была в 16:00
- после транзакции в 15:00 была транзакция в 16:00 с доходом 25066 (столбец lead_revenue)
- перед транзакцией в 16:00 была транзакция в 15:00 с доходом 3699 (столбец lag_revenue)
- первая транзакция в окне была в 15:00, и доход по этой транзакции составил 3699 (столбец first_revenue_by_hour)
- запрос обрабатывает данные построчно, поэтому для рассматриваемой транзакции последней транзакцией в окне будет она сама, а значения в столбцах last_revenue_by_hour и доход будут одинаковыми
Полезные статьи о Google BigQuery:
- Шесть лучших инструментов визуализации BigQuery
- Как загрузить данные в Google BigQuery
- Как загрузить необработанные данные из Google Ads в Google BigQuery
- Коннектор Google Таблиц Google BigQuery
- Автоматизируйте отчеты в Google Таблицах, используя данные из Google BigQuery
- Автоматизируйте отчеты в Google Data Studio на основе данных из Google BigQuery
Если вы хотите собирать несемплированные данные со своего сайта в Google BigQuery, но не знаете, с чего начать, закажите демонстрацию. Мы расскажем вам обо всех возможностях, которые вы получаете с BigQuery и OWOX BI.
Наши клиенты
расти на 22% быстрее
Растите быстрее, измеряя, что лучше всего работает в вашем маркетинге
Проанализируйте эффективность вашего маркетинга, найдите точки роста, увеличьте рентабельность инвестиций
Получить демоВыводы
В этой статье мы рассмотрели самые популярные группы функций: агрегат, дата, строка и окно. Однако у Google BigQuery гораздо больше полезных функций, в том числе:
- функции приведения, которые позволяют преобразовывать данные в определенный формат
- функции подстановки таблиц, которые позволяют вам получить доступ к нескольким таблицам в наборе данных
- функции регулярных выражений, позволяющие описать модель поискового запроса, а не его точное значение
Об этих функциях мы обязательно напишем в нашем блоге. А пока вы можете опробовать все функции, описанные в этой статье, на наших демонстрационных данных.
Демонстрационные данные для практики запросов SQL
Скачать