
주요 Google BigQuery 기능 개요 — 마케팅 분석을 위한 요청 작성 연습
게시 됨: 2022-04-12비즈니스가 축적하는 정보가 많을수록 정보를 저장할 위치에 대한 문제는 더욱 심각해집니다. 자체 서버를 유지할 능력이나 의지가 없다면 Google BigQuery(GBQ)가 도움이 될 수 있습니다. BigQuery는 빅 데이터 작업을 위한 빠르고 비용 효율적이며 확장 가능한 스토리지를 제공하며 표준 및 사용자 정의 함수는 물론 SQL과 유사한 구문을 사용하여 쿼리를 작성할 수 있습니다.
이 문서에서는 BigQuery의 주요 기능을 살펴보고 특정 예를 사용하여 가능성을 보여줍니다. 기본 쿼리를 작성하고 데모 데이터에서 테스트하는 방법을 배우게 됩니다.
기술 교육이나 SQL 지식 없이 GBQ 데이터에 대한 보고서를 작성합니다.
정기적으로 광고 캠페인에 대한 보고서가 필요하지만 SQL을 연구하거나 분석가의 응답을 기다릴 시간이 없으십니까? OWOX BI를 사용하면 데이터 구조를 이해할 필요 없이 보고서를 작성할 수 있습니다. 스마트 데이터 보고서에서 보고 싶은 매개변수와 측정항목을 선택하기만 하면 됩니다. OWOX BI Smart Data는 당신이 이해할 수 있는 방식으로 데이터를 즉시 시각화합니다.
목차
- SQL이란 무엇이며 BigQuery가 지원하는 방언
- 어디서 시작하나요
- Google BigQuery 기능
- 집계 함수
- 날짜 함수
- 문자열 함수
- 창 기능
- 결론
SQL이란 무엇이며 BigQuery가 지원하는 방언
SQL(Structured Query Language)을 사용하면 대규모 배열에서 데이터를 검색하고 추가하고 수정할 수 있습니다. Google BigQuery는 표준 SQL과 오래된 Legacy SQL의 두 가지 SQL 언어를 지원합니다.
선택할 언어는 기본 설정에 따라 다르지만 다음과 같은 이점을 위해 표준 SQL을 사용하는 것이 좋습니다.
- 중첩 및 반복 필드에 대한 유연성 및 기능
- DML 및 DDL 언어 지원을 통해 테이블의 데이터를 변경하고 GBQ에서 테이블과 뷰를 관리할 수 있습니다.
- Legacy SQL에 비해 대용량 데이터 처리 속도 향상
- 모든 향후 BigQuery 업데이트 지원
BigQuery 문서에서 방언의 차이점에 대해 자세히 알아볼 수 있습니다.
참조: Legacy SQL에 비해 Google BigQuery의 새로운 표준 SQL 언어의 장점은 무엇이며 이를 통해 어떤 비즈니스 작업을 해결할 수 있습니까?
기본적으로 Google BigQuery 쿼리는 Legacy SQL에서 실행됩니다.
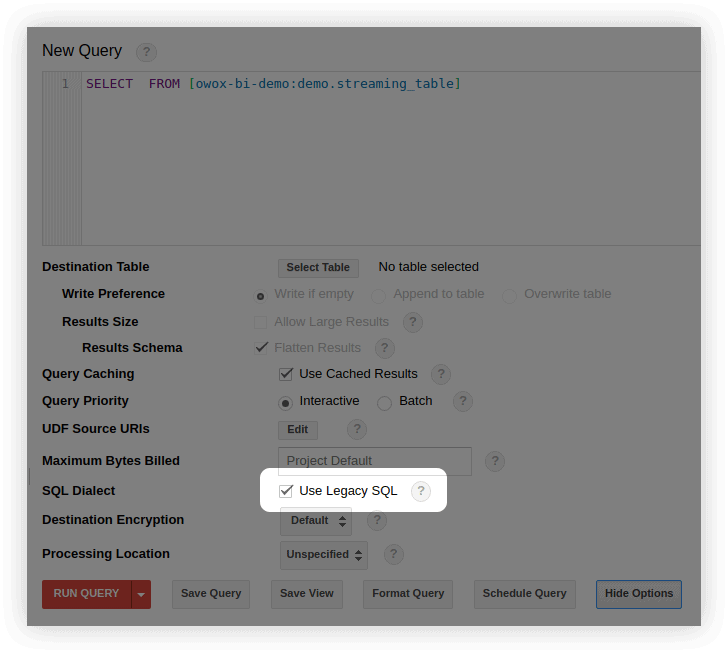
다음과 같은 여러 가지 방법으로 표준 SQL로 전환할 수 있습니다.
- BigQuery 인터페이스의 쿼리 편집 창에서 옵션 표시를 선택하고 Use Legacy SQL 옆에 있는 체크 표시를 제거합니다.
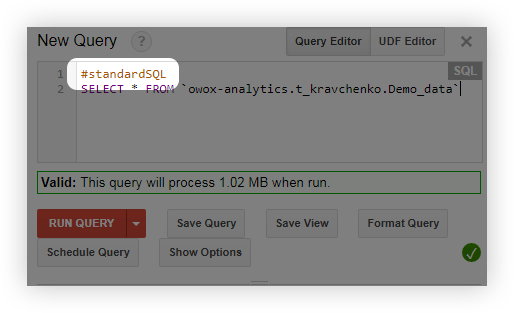
- 쿼리하기 전에 #standardSQL 줄을 추가하고 새 줄로 쿼리를 시작합니다.
어디서 시작하나요
우리와 함께 쿼리를 연습하고 실행할 수 있도록 데모 데이터가 있는 테이블을 준비했습니다. 아래 양식을 작성해 주시면 이메일로 보내드리겠습니다.


SQL 쿼리 실습을 위한 데모 데이터
다운로드 시작하려면 데모 데이터 테이블을 다운로드하여 Google BigQuery 프로젝트에 업로드하세요. 이를 수행하는 가장 쉬운 방법은 OWOX BI BigQuery 보고서 추가 기능을 사용하는 것입니다.
- Google 스프레드시트를 열고 OWOX BI BigQuery 보고서 추가 기능을 설치합니다.
- 데모 데이터가 포함된 다운로드한 테이블을 열고 OWOX BI BigQuery 보고서 -> BigQuery에 데이터 업로드를 선택합니다.
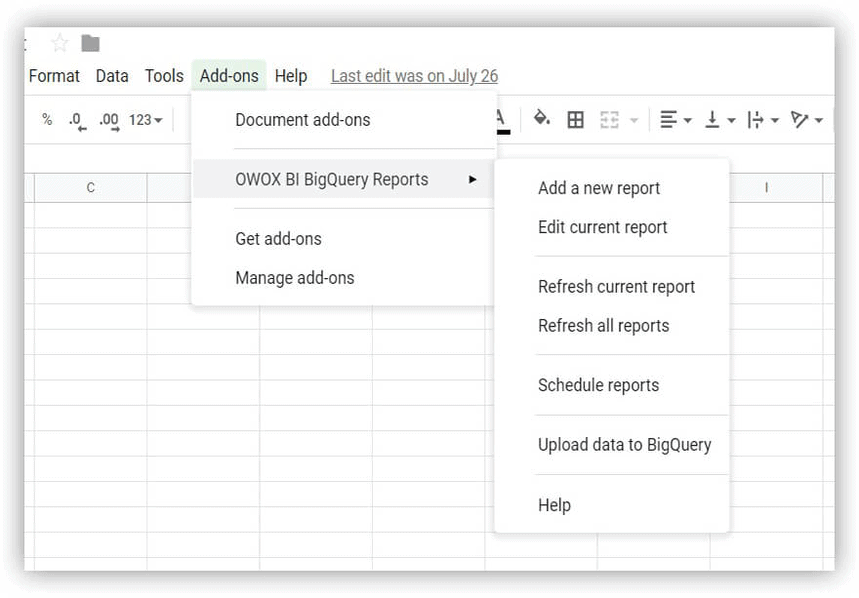
- 열리는 창에서 데이터 세트인 Google BigQuery 프로젝트를 선택하고 로드된 데이터가 저장될 테이블의 이름을 생각합니다.
- 로드된 데이터의 형식을 지정합니다(스크린샷 참조).

Google BigQuery에 프로젝트가 없으면 새로 만드세요. 이렇게 하려면 Google Cloud Platform에 활성 결제 계정이 필요합니다. 은행 카드를 연결해야 한다고 해서 걱정하지 마세요. 본인도 모르는 사이에 요금이 청구되지 않습니다. 또한 등록하면 데이터 저장 및 처리에 사용할 수 있는 12개월 동안 $300를 받게 됩니다.
OWOX BI는 다양한 시스템의 데이터를 BigQuery로 결합하는 데 도움이 됩니다. 웹사이트의 사용자 작업, 통화, CRM의 주문, 이메일, 광고 비용에 대한 데이터입니다. OWOX BI를 사용하여 고급 분석을 사용자 정의하고 복잡한 보고서를 자동화할 수 있습니다.
Google BigQuery 기능에 대해 이야기하기 전에 Legacy SQL 및 Standard SQL 언어 모두에서 기본 쿼리가 어떻게 보이는지 기억해 보겠습니다.
| 질문 | 레거시 SQL | 표준 SQL |
|---|---|---|
| 테이블에서 필드 선택 | 필드1,필드2 선택 | 필드1,필드2 선택 |
| 필드를 선택할 테이블 선택 | [프로젝트 ID:dataSet.tableName]에서 | `projectID.dataSet.tableName`에서 |
| 값을 필터링할 매개변수 선택 | WHERE 필드1=값 | WHERE 필드1=값 |
| 결과를 그룹화할 필드 선택 | GROUP BY 필드1, 필드2 | GROUP BY 필드1, 필드2 |
| 결과 주문 방법 선택 | ORDER BY field1 ASC(오름차순) 또는 DESC(내림차순) | ORDER BY field1 ASC(오름차순) 또는 DESC(내림차순) |
Google BigQuery 기능
쿼리를 작성할 때 집계, 날짜, 문자열 및 창 함수를 가장 자주 사용합니다. 이러한 각 기능 그룹에 대해 자세히 살펴보겠습니다.
참조: 클라우드 스토리지 작업을 시작하는 방법 — 데이터세트와 테이블을 만들고 Google BigQuery로 데이터 가져오기를 구성합니다.
집계 함수
집계 함수는 전체 테이블에 대한 요약 값을 제공합니다. 예를 들어, 이를 사용하여 평균 수표 크기 또는 월별 총 수익을 계산하거나 이를 사용하여 최대 구매 횟수를 한 사용자 세그먼트를 선택할 수 있습니다.
다음은 가장 널리 사용되는 집계 함수입니다.
| 레거시 SQL | 표준 SQL | 함수가 하는 일 |
|---|---|---|
| AVG(필드) | AVG([DISTINCT](필드)) | 필드 열의 평균 값을 반환합니다. 표준 SQL에서 DISTINCT 조건을 추가할 때 평균은 필드 열에 고유한(반복되지 않는) 값이 있는 행에 대해서만 고려됩니다. |
| 최대(필드) | 최대(필드) | 필드 열에서 최대값을 반환합니다. |
| 최소(필드) | 최소(필드) | 필드 열에서 최소값을 반환합니다. |
| SUM(필드) | SUM(필드) | 필드 열의 값 합계를 반환합니다. |
| COUNT(필드) | COUNT(필드) | 필드 열의 행 수를 반환합니다. |
| EXACT_COUNT_DISTINCT(필드) | COUNT([DISTINCT](필드)) | 필드 열의 고유 행 수를 반환합니다. |
모든 집계 함수 목록은 Legacy SQL 및 Standard SQL 설명서를 참조하세요.
이러한 기능이 어떻게 작동하는지 알아보기 위해 데모 데이터를 살펴보겠습니다. 거래에 대한 평균 수익, 최고 및 최저 금액 구매, 총 수익, 총 거래 및 고유 거래 수(구매가 중복되었는지 확인하기 위해)를 계산할 수 있습니다. 이를 위해 Google BigQuery 프로젝트, 데이터 세트 및 테이블의 이름을 지정하는 쿼리를 작성합니다.
#기존 SQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]#표준 SQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`결과적으로 다음을 얻습니다.
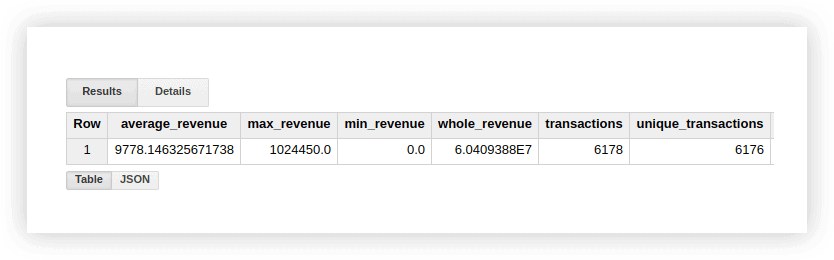
표준 Google 스프레드시트 기능(SUM, AVG 등)을 사용하거나 피벗 테이블을 사용하여 데모 데이터가 있는 원본 테이블에서 이러한 계산 결과를 확인할 수 있습니다.
위의 스크린샷에서 볼 수 있듯이 거래 건수와 고유 거래 건수가 다릅니다. 이것은 동일한 transactionId를 가진 두 개의 트랜잭션이 테이블에 있음을 나타냅니다.

고유한 트랜잭션에 관심이 있다면 고유한 문자열을 계산하는 함수를 사용하십시오. 또는 GROUP BY 함수를 사용하여 데이터를 그룹화하여 집계 함수를 적용하기 전에 중복을 제거할 수 있습니다.
SQL 쿼리 실습을 위한 데모 데이터
다운로드날짜 함수
이러한 기능을 사용하면 날짜를 처리할 수 있습니다. 형식 변경, 필요한 필드(일, 월 또는 연도) 선택 또는 특정 간격으로 날짜 이동.
다음과 같은 경우에 유용할 수 있습니다.
- 다양한 소스의 날짜와 시간을 단일 형식으로 변환하여 고급 분석 설정
- 자동으로 업데이트된 보고서 생성 또는 메일링 트리거(예: 지난 2시간, 주 또는 월에 대한 데이터가 필요한 경우)
- 며칠, 몇 주 또는 몇 달 동안 데이터를 가져와야 하는 코호트 보고서 만들기
다음은 가장 일반적으로 사용되는 날짜 함수입니다.
| 레거시 SQL | 표준 SQL | 기능 설명 |
|---|---|---|
| CURRENT_DATE() | CURRENT_DATE() | 현재 날짜를 % YYYY -% MM-% DD 형식으로 반환합니다. |
| 날짜(타임스탬프) | 날짜(타임스탬프) | 날짜를 % YYYY -% MM-% DD% H:% M:% C에서 % YYYY -% MM-% DD 형식으로 변환합니다. |
| DATE_ADD(타임스탬프, 간격, 간격_단위) | DATE_ADD(타임스탬프, INTERVAL 간격 interval_units) | 지정된 간격만큼 증가하는 타임스탬프 날짜를 반환합니다.interval_units. Legacy SQL에서는 YEAR, MONTH, DAY, HOUR, MINUTE 및 SECOND 값을 사용할 수 있고 표준 SQL에서는 YEAR, QUARTER, MONTH, 주 및 일. |
| DATE_ADD(타임스탬프, - 간격, 간격_단위) | DATE_SUB(타임스탬프, INTERVAL 간격 interval_units) | 지정된 간격만큼 감소하는 타임스탬프 날짜를 반환합니다. |
| DATEDIFF(타임스탬프1, 타임스탬프2) | DATE_DIFF(타임스탬프1, 타임스탬프2, 날짜_부분) | timestamp1과 timestamp2 날짜 간의 차이를 반환합니다. Legacy SQL에서는 일의 차이를 반환하고 Standard SQL에서는 지정된 date_part 값(일, 주, 월, 분기, 연도)에 따라 차이를 반환합니다. |
| DAY(타임스탬프) | EXTRACT(날짜 FROM 타임스탬프) | 타임스탬프 날짜에서 날짜를 반환합니다. 1부터 31까지의 값을 취합니다. |
| MONTH(타임스탬프) | 추출(타임스탬프에서 MONTH) | 타임스탬프 날짜에서 월 시퀀스 번호를 반환합니다. 1에서 12까지의 값을 사용합니다. |
| YEAR(타임스탬프) | 추출(타임스탬프의 연도) | 타임스탬프 날짜에서 연도를 반환합니다. |
모든 날짜 함수 목록은 Legacy SQL 및 Standard SQL 설명서를 참조하십시오.
이러한 각 기능이 어떻게 작동하는지 알아보기 위해 데모 데이터를 살펴보겠습니다. 예를 들어, 현재 날짜를 가져와서 원본 테이블의 날짜를 % YYYY -% MM-% DD 형식으로 변환하고 제거하고 하루를 추가합니다. 그런 다음 현재 날짜와 원본 테이블의 날짜 간의 차이를 계산하고 현재 날짜를 별도의 연도, 월 및 일 필드로 나눕니다. 이렇게 하려면 아래 샘플 쿼리를 복사하고 프로젝트 이름, 데이터 세트 및 데이터 테이블을 자신의 것으로 바꿀 수 있습니다.
#기존 SQL
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]#표준 SQL
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)쿼리를 실행하면 다음 보고서를 받게 됩니다.
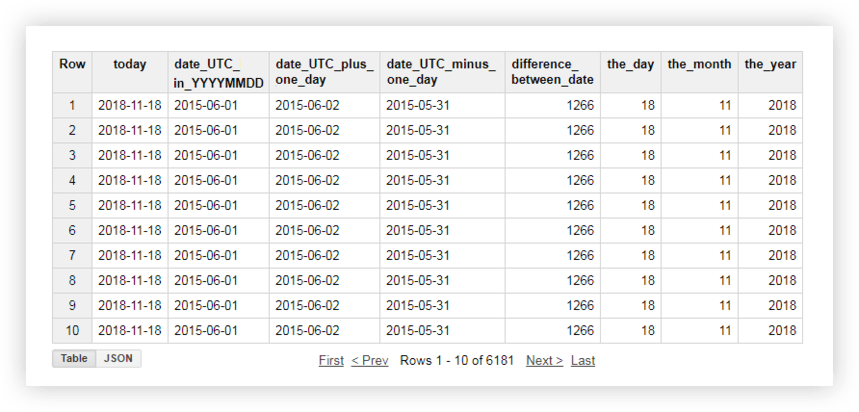
참조: Google BigQuery의 데이터에 대한 SQL 쿼리를 사용하여 작성할 수 있는 보고서의 예와 OWOX BI로 Google Analytics 데이터를 보완할 수 있는 고유한 측정항목은 무엇입니까?
문자열 함수
문자열 함수를 사용하면 문자열을 생성하고, 하위 문자열을 선택 및 대체하고, 문자열의 길이와 원래 문자열에 있는 하위 문자열의 인덱스 시퀀스를 계산할 수 있습니다. 예를 들어 문자열 함수로 다음을 수행할 수 있습니다.
- 페이지 URL에 전달되는 UTM 태그로 보고서 필터링
- 소스 및 캠페인 이름이 다른 레지스터에 기록된 경우 데이터를 단일 형식으로 가져옵니다.
- 보고서에서 잘못된 데이터 교체(예: 캠페인 이름이 잘못 인쇄된 경우)
다음은 문자열 작업에 가장 많이 사용되는 함수입니다.
| 레거시 SQL | 표준 SQL | 기능 설명 |
|---|---|---|
| CONCAT('str1', 'str2') 또는 'str1'+ 'str2' | CONCAT('str1', 'str2') | 'str1'과 'str2'를 하나의 문자열로 연결합니다. |
| 'str1'은 'str2'를 포함합니다. | REGEXP_CONTAINS('str1', 'str2') 또는 'str1' LIKE '%str2%' | 문자열 'str1'에 문자열 'str2'가 포함되어 있으면 true를 반환합니다. '표준 SQL에서 문자열 'str2'는 re2 라이브러리 를 사용하여 정규식으로 작성할 수 있습니다. |
| 길이('str' ) | CHAR_LENGTH('str') 또는 CHARACTER_LENGTH('str') | 문자열 'str'의 길이(문자 수)를 반환합니다. |
| SUBSTR('str', 인덱스 [, max_len]) | SUBSTR('str', 인덱스 [, max_len]) | 문자열 'str'의 인덱스 문자로 시작하는 길이가 max_len인 부분 문자열을 반환합니다. |
| LOWER('문자열') | LOWER('문자열') | 문자열 'str'의 모든 문자를 소문자로 변환합니다. |
| UPPER(문자열) | UPPER(문자열) | 문자열 'str'의 모든 문자를 대문자로 변환합니다. |
| INSTR('str1', 'str2') | STRPOS('str1', 'str2') | 문자열 'str1'에서 문자열 'str2'가 처음 나타나는 인덱스를 반환합니다. 그렇지 않으면 0을 반환합니다. |
| REPLACE('str1', 'str2', 'str3') | REPLACE('str1', 'str2', 'str3') | 'str1'을 'str2'로 'str3'으로 바꿉니다. |
Legacy SQL 및 Standard SQL 설명서에서 모든 문자열 함수에 대해 자세히 알아볼 수 있습니다.
설명된 기능을 사용하는 방법을 알아보기 위해 데모 데이터를 살펴보겠습니다. 일, 월 및 연도 값을 포함하는 세 개의 개별 열이 있다고 가정합니다.

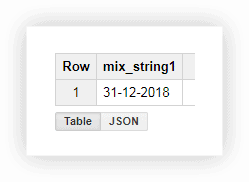
이 형식의 날짜 작업은 그다지 편리하지 않으므로 값을 하나의 열로 결합할 수 있습니다. 이렇게 하려면 아래 SQL 쿼리를 사용하고 Google BigQuery에서 프로젝트, 데이터세트 및 테이블의 이름을 대체해야 합니다.
#기존 SQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1#표준 SQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1쿼리를 실행하면 한 열에 날짜가 표시됩니다.
종종 웹 사이트에서 페이지를 다운로드할 때 URL은 사용자가 선택한 변수의 값을 기록합니다. 이것은 지불 또는 배송 방법, 거래 번호, 구매자가 항목을 픽업하려는 실제 상점의 색인 등이 될 수 있습니다. SQL 쿼리를 사용하여 페이지 주소에서 이러한 매개변수를 선택할 수 있습니다. 당신이 이것을 할 수 있는 방법과 이유에 대한 두 가지 예를 고려하십시오.
예 1 . 사용자가 실제 상점에서 상품을 픽업한 구매 횟수를 알고 싶다고 가정해 보겠습니다. 이렇게 하려면 하위 문자열 shop_id(실제 상점에 대한 인덱스)를 포함하는 URL의 페이지에서 전송된 트랜잭션 수를 계산해야 합니다. 다음 쿼리로 이를 수행할 수 있습니다.
#기존 SQL
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check#표준 SQL
SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2
SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2결과 테이블에서 shop_id가 포함된 페이지에서 5502개의 트랜잭션(check = true)이 전송되었음을 알 수 있습니다.

예 2 . 각 전달 방법에 delivery_id를 할당했으며 페이지 URL에서 이 매개변수의 값을 지정합니다. 사용자가 선택한 배송 방법을 확인하려면 별도의 열에서 delivery_id를 선택해야 합니다.

이를 위해 다음 쿼리를 사용할 수 있습니다.
#기존 SQL
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC#표준 SQL
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASC결과적으로 Google BigQuery에서 다음과 같은 테이블을 얻습니다.
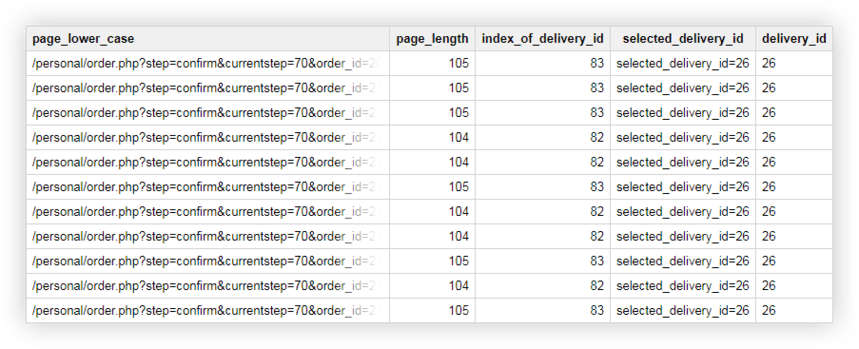
SQL 쿼리 실습을 위한 데모 데이터
다운로드창 기능
이러한 함수는 위에서 논의한 집계 함수와 유사합니다. 주요 차이점은 창 함수는 쿼리를 사용하여 선택한 전체 데이터 집합에 대해 계산을 수행하지 않고 해당 데이터의 일부(하위 집합 또는 창 )에 대해서만 계산을 수행한다는 것입니다.
창 함수를 사용하면 JOIN 함수를 사용하여 여러 쿼리를 결합하지 않고도 그룹 섹션의 데이터를 집계할 수 있습니다. 예를 들어 광고 캠페인당 평균 수익 또는 기기당 거래 수를 계산할 수 있습니다. 보고서에 다른 필드를 추가하면 블랙 프라이데이 광고 캠페인의 수익 점유율이나 모바일 애플리케이션에서 이루어진 거래 점유율 등을 쉽게 알 수 있습니다.
쿼리의 각 함수와 함께 창 경계를 정의하는 OVER 식을 철자해야 합니다. OVER에는 작업할 수 있는 세 가지 구성 요소가 포함되어 있습니다.
- PARTITION BY — 원본 데이터를 clientId 또는 DayTime과 같은 하위 집합으로 나누는 특성을 정의합니다.
- ORDER BY — 시간 DESC와 같은 하위 집합의 행 순서를 정의합니다.
- WINDOW FRAME — 특정 기능의 하위 집합 내에서 행을 처리할 수 있습니다(예: 현재 행 앞의 5개 행만).
이 표에서는 가장 자주 사용되는 창 기능을 수집했습니다.
| 레거시 SQL | 표준 SQL | 기능 설명 |
|---|---|---|
| AVG(필드) COUNT(필드) COUNT(DISTINCT 필드) 최대() 분() 합집합() | AVG([DISTINCT](필드)) COUNT(필드) COUNT([DISTINCT](필드)) 최대(필드) 최소(필드) SUM(필드) | 선택한 하위 집합 내의 필드 열에서 평균, 숫자, 최대값, 최소값 및 전체 값을 반환합니다. DISTINCT는 고유한(반복되지 않는) 값만 계산하는 데 사용됩니다. |
| DENSE_RANK() | DENSE_RANK() | 하위 집합 내의 행 번호를 반환합니다. |
| FIRST_VALUE(필드) | FIRST_VALUE(필드[{RESPECT | IGNORE} NULLS]) | 하위 집합 내의 필드 열에서 첫 번째 행의 값을 반환합니다. 기본적으로 필드 열의 값이 비어 있는 행이 계산에 포함됩니다. RESPECT 또는 IGNORE NULLS는 NULL 문자열을 포함할지 무시할지 여부를 지정합니다. |
| LAST_VALUE(필드) | LAST_VALUE(필드 [{RESPECT | IGNORE} NULLS]) | 필드 열에서 하위 집합 내의 마지막 행 값을 반환합니다. 기본적으로 필드 열에 빈 값이 있는 행이 계산에 포함됩니다. RESPECT 또는 IGNORE NULLS는 NULL 문자열을 포함할지 무시할지 여부를 지정합니다. |
| LAG(필드) | LAG(필드[, 오프셋[, default_expression]]) | 하위 집합 내의 현재 필드 열과 관련하여 이전 행의 값을 반환합니다. Offset은 현재 행에서 아래로 오프셋할 행 수를 지정하는 정수입니다. Default_expression은 필수 항목이 없는 경우 함수가 반환하는 값입니다. 하위 집합 내의 문자열입니다. |
| 리드(필드) | LEAD(필드[, 오프셋[, default_expression]]) | 하위 집합 내에서 현재 필드 열에 상대적인 다음 행의 값을 반환합니다. 오프셋은 현재 행과 관련하여 위로 이동하려는 행 수를 정의하는 정수입니다. Default_expression은 현재 하위 집합 내에 필수 문자열이 없는 경우 함수가 반환하는 값입니다. |
Legacy SQL 및 Standard SQL에 대한 설명서에서 모든 집계 분석 함수 및 탐색 함수 목록을 볼 수 있습니다.
예 1 . 근무 시간과 휴무 시간에 고객의 활동을 분석하려고 한다고 가정해 보겠습니다. 이렇게 하려면 트랜잭션을 두 그룹으로 나누고 관심 있는 메트릭을 계산해야 합니다.
- 그룹 1 — 근무 시간 9:00~18:00 구매
- 그룹 2 — 00:00~9:00 및 18:00~23:59 시간 이후 구매
근무시간과 비근무시간 외에 윈도우를 형성하는 또 다른 변수는 clientId이다. 즉, 각 사용자에 대해 두 개의 창이 있습니다.
| 창문 | 클라이언트 ID | 낮 |
|---|---|---|
| 창 1 | 클라이언트 ID 1 | 근무 시간 |
| 창 2 | 클라이언트 ID 2 | 휴무 시간 |
| 창 3 | 클라이언트 ID 3 | 근무 시간 |
| 창 4 | 클라이언트 ID 4 | 휴무 시간 |
| 창 N | 클라이언트 ID N | 근무 시간 |
| 창 N+1 | 클라이언트 ID N+1 | 휴무 시간 |
데모 데이터를 사용하여 근무 시간과 비근무 시간 동안 평균, 최대, 최소 및 총 수익, 총 거래 수, 사용자당 고유 거래 수를 계산해 보겠습니다. 아래 요청은 이를 수행하는 데 도움이 됩니다.
#기존 SQL
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC#표준 SQL
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESCclientId가 102041117.1428132012인 사용자의 예를 사용하여 결과적으로 어떤 일이 발생하는지 봅시다. 이 사용자의 원래 테이블에는 다음 데이터가 있습니다.

쿼리를 실행하면 이 사용자의 평균, 최소, 최대 및 총 수익과 사용자의 총 거래 수가 포함된 보고서를 받습니다. 아래 스크린샷에서 볼 수 있듯이 두 거래 모두 근무 시간 동안 사용자가 수행했습니다.

예 2 . 이제 더 복잡한 작업을 위해:
- 실행 시간에 따라 창의 모든 트랜잭션에 대한 시퀀스 번호를 입력합니다. 사용자 및 작업/비작업 시간 슬롯으로 창을 정의한다는 것을 기억하십시오.
- 창 내에서 (현재와 관련된) 다음/이전 거래의 수익을 보고합니다.
- 창에 첫 번째 및 마지막 거래의 수익을 표시합니다.
이를 위해 다음 쿼리를 사용합니다.
#기존 SQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour#표준 SQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour이미 알고 있는 사용자의 예를 사용하여 계산 결과를 확인할 수 있습니다. clientId 102041117.1428132012:

위의 스크린샷에서 다음을 확인할 수 있습니다.
- 첫 번째 거래는 15:00에 두 번째 거래는 16:00에 이루어졌습니다.
- 15:00에 거래 후 16:00에 거래가 있었고 수익은 25066(lead_revenue 열)이었습니다.
- 16:00에 거래하기 전에 15:00에 3699의 수익을 가진 거래가 있었습니다(열 lag_revenue).
- 창 내의 첫 번째 거래는 15:00이고 이 거래의 수익은 3699(첫 번째_수익_별_시간 열)입니다.
- 쿼리는 데이터를 한 줄씩 처리하므로 문제의 트랜잭션에 대해 창의 마지막 트랜잭션은 자체가 되고 last_revenue_by_hour 열의 값과 수익은 동일합니다.
Google BigQuery에 대한 유용한 문서:
- 상위 6개의 BigQuery 시각화 도구
- Google BigQuery에 데이터를 업로드하는 방법
- Google Ads에서 Google BigQuery로 원시 데이터를 업로드하는 방법
- Google BigQuery Google 스프레드시트 커넥터
- Google BigQuery의 데이터를 사용하여 Google 스프레드시트에서 보고서 자동화
- Google BigQuery의 데이터를 기반으로 Google 데이터 스튜디오에서 보고서 자동화
웹사이트에서 샘플링되지 않은 데이터를 Google BigQuery로 수집하고 싶지만 어디서부터 시작해야 할지 모르겠다면 데모를 예약하세요. BigQuery 및 OWOX BI로 얻을 수 있는 모든 가능성에 대해 알려 드리겠습니다.
우리의 클라이언트
자라다 22% 더 빠름
마케팅에서 가장 효과적인 것을 측정하여 더 빠르게 성장
마케팅 효율성 분석, 성장 영역 찾기, ROI 증가
데모 받기결론
이 기사에서는 가장 인기 있는 함수 그룹인 집계, 날짜, 문자열 및 창을 살펴보았습니다. 그러나 Google BigQuery에는 다음과 같은 훨씬 더 유용한 기능이 있습니다.
- 데이터를 특정 형식으로 변환할 수 있는 캐스팅 기능
- 데이터 세트의 여러 테이블에 액세스할 수 있는 테이블 와일드카드 함수
- 정확한 값이 아닌 검색 쿼리의 모델을 설명할 수 있는 정규식 함수
우리는 블로그에서 이러한 기능에 대해 확실히 쓸 것입니다. 그동안 데모 데이터를 사용하여 이 문서에 설명된 모든 기능을 사용해 볼 수 있습니다.
SQL 쿼리 실습을 위한 데모 데이터
다운로드