
Google BigQueryの主な機能の概要—マーケティング分析のリクエストを作成する練習
公開: 2022-04-12ビジネスが蓄積する情報が多ければ多いほど、それをどこに保存するかという問題はより深刻になります。 独自のサーバーを維持する能力や要望がない場合は、Google BigQuery(GBQ)が役立ちます。 BigQueryは、ビッグデータを操作するための高速で費用対効果の高いスケーラブルなストレージを提供し、SQLのような構文と標準およびユーザー定義関数を使用してクエリを記述できるようにします。
この記事では、BigQueryの主な機能を確認し、具体的な例を使用してその可能性を示します。 基本的なクエリを作成し、デモデータでテストする方法を学習します。
技術的なトレーニングやSQLの知識がなくても、GBQデータに関するレポートを作成できます。
広告キャンペーンに関するレポートが定期的に必要ですが、SQLを勉強したり、アナリストからの応答を待つ時間がありませんか? OWOX BIを使用すると、データがどのように構造化されているかを理解していなくても、レポートを作成できます。 スマートデータレポートに表示するパラメータと指標を選択するだけです。 OWOX BI Smart Dataは、理解できる方法でデータを即座に視覚化します。
目次
- SQLとは何ですか?BigQueryはどの方言をサポートしていますか
- どこから始めれば
- GoogleBigQueryの機能
- 集計関数
- 日付関数
- 文字列関数
- ウィンドウ関数
- 結論
SQLとは何ですか?BigQueryはどの方言をサポートしていますか
構造化照会言語(SQL)を使用すると、大規模な配列からデータを取得したり、データを追加したり、データを変更したりできます。 Google BigQueryは、標準SQLと古いレガシーSQLの2つのSQLダイアレクトをサポートしています。
どの方言を選択するかは好みによって異なりますが、次の利点のために標準SQLを使用することをお勧めします。
- ネストされたフィールドと繰り返しフィールドの柔軟性と機能
- DMLおよびDDL言語のサポート。これにより、テーブル内のデータを変更したり、GBQでテーブルとビューを管理したりできます。
- レガシーSQLと比較して大量のデータの処理が高速
- 今後のすべてのBigQueryアップデートのサポート
方言の違いについて詳しくは、BigQueryのドキュメントをご覧ください。
参照:レガシーSQLに対するGoogle BigQueryの新しい標準SQLダイアレクトの利点と、それを使用して解決できるビジネスタスクは何ですか。
デフォルトでは、GoogleBigQueryクエリはレガシーSQLで実行されます。
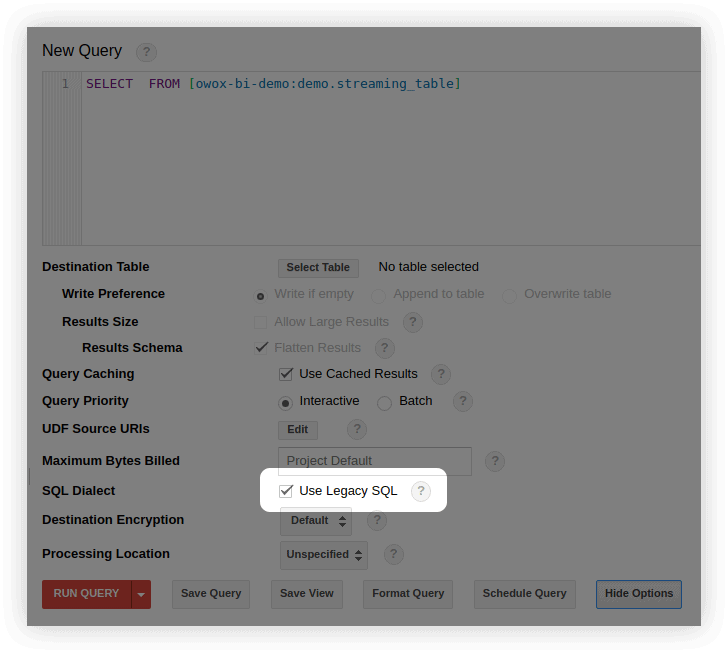
いくつかの方法で標準SQLに切り替えることができます。
- BigQueryインターフェースのクエリ編集ウィンドウで、[オプションを表示]を選択し、[レガシーSQLを使用する]の横のチェックマークを外します。
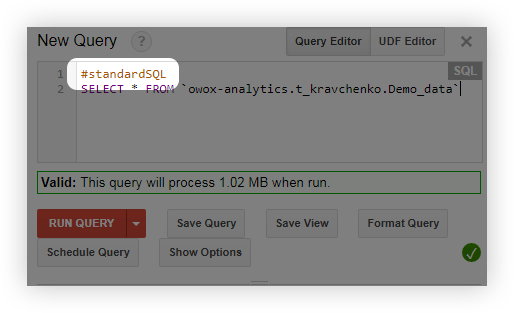
- クエリを実行する前に、#standardSQLという行を追加し、新しい行でクエリを開始します。
どこから始めれば
クエリを練習して実行できるように、デモデータを含むテーブルを用意しました。 以下のフォームに記入してください。メールでお知らせします。


SQLクエリの練習用のデモデータ
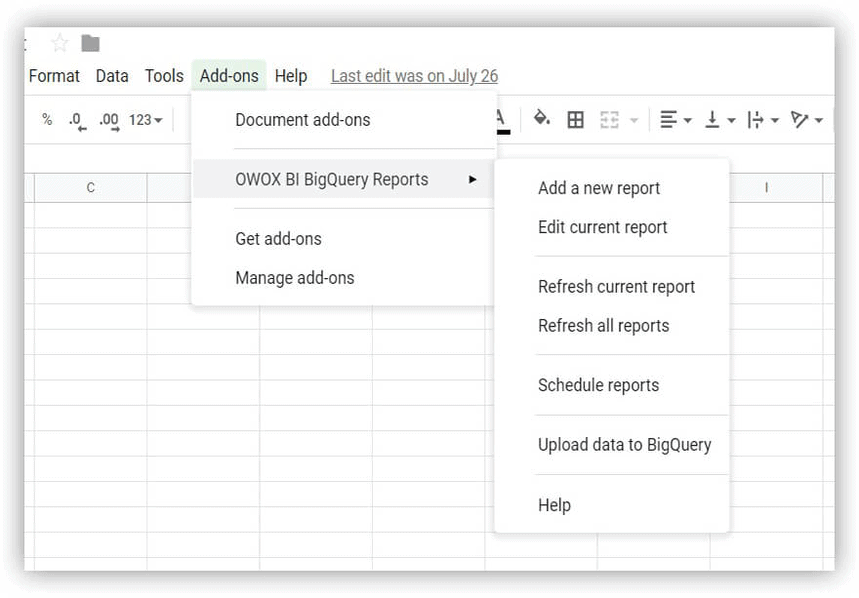
ダウンロード開始するには、デモデータテーブルをダウンロードして、GoogleBigQueryプロジェクトにアップロードします。 これを行う最も簡単な方法は、OWOX BIBigQueryReportsアドオンを使用することです。
- Googleスプレッドシートを開き、OWOX BIBigQueryReportsアドオンをインストールします。
- ダウンロードしたデモデータを含むテーブルを開き、[ OWOX BI BigQuery Reports] –> [ Upload DatatoBigQuery]を選択します。
- 開いたウィンドウで、Google BigQueryプロジェクトとデータセットを選択し、読み込まれたデータが保存されるテーブルの名前を考えます。
- ロードされたデータのフォーマットを指定します(スクリーンショットを参照)。

Google BigQueryにプロジェクトがない場合は、プロジェクトを作成します。 これを行うには、GoogleCloudPlatformにアクティブな請求先アカウントが必要です。 銀行カードをリンクする必要があることを恐れないでください。知らないうちに請求されることはありません。 さらに、登録すると、データの保存と処理に使用できる12か月間300ドルを受け取ることができます。
OWOX BIは、さまざまなシステムのデータをBigQueryに結合するのに役立ちます。ウェブサイトでのユーザーアクション、通話、CRMからの注文、メール、広告費用に関するデータです。 OWOX BIを使用して、高度な分析をカスタマイズし、複雑なレポートを自動化できます。
Google BigQueryの機能について説明する前に、レガシーSQLと標準SQLの両方の方言で基本的なクエリがどのように表示されるかを覚えておきましょう。
| クエリ | レガシーSQL | 標準SQL |
|---|---|---|
| テーブルからフィールドを選択します | SELECTフィールド1、field2 | SELECTフィールド1、field2 |
| フィールドを選択するテーブルを選択します | FROM [projectID:dataSet.tableName] | FROM `projectID.dataSet.tableName` |
| 値をフィルタリングするためのパラメータを選択します | WHEREフィールド1=値 | WHEREフィールド1=値 |
| 結果をグループ化するフィールドを選択します | GROUP BYフィールド1、フィールド2 | GROUP BYフィールド1、フィールド2 |
| 結果の注文方法を選択する | ORDER BY field1 ASC(昇順)またはDESC(降順) | ORDER BY field1 ASC(昇順)またはDESC(降順) |
GoogleBigQueryの機能
クエリを作成するときは、集計、日付、文字列、およびウィンドウ関数を最も頻繁に使用します。 これらの関数グループのそれぞれを詳しく見てみましょう。
参照:クラウドストレージの使用を開始する方法—データセットとテーブルを作成し、GoogleBigQueryへのデータのインポートを構成します。
集計関数
集計関数は、テーブル全体の要約値を提供します。 たとえば、これらを使用して1か月あたりの平均小切手サイズまたは総収益を計算したり、最大購入数を達成したユーザーのセグメントを選択したりできます。
これらは最も人気のある集計関数です。
| レガシーSQL | 標準SQL | 関数の機能 |
|---|---|---|
| AVG(フィールド) | AVG([DISTINCT](フィールド)) | フィールド列の平均値を返します。 標準SQLでは、DISTINCT条件を追加すると、フィールド列に一意の(繰り返されない)値を持つ行についてのみ平均が考慮されます。 |
| MAX(フィールド) | MAX(フィールド) | フィールド列から最大値を返します。 |
| MIN(フィールド) | MIN(フィールド) | フィールド列から最小値を返します。 |
| SUM(フィールド) | SUM(フィールド) | フィールド列から値の合計を返します。 |
| COUNT(フィールド) | COUNT(フィールド) | フィールド列の行数を返します。 |
| EXACT_COUNT_DISTINCT(フィールド) | COUNT([DISTINCT](フィールド)) | フィールド列の一意の行の数を返します。 |
すべての集計関数のリストについては、レガシーSQLおよび標準SQLのドキュメントを参照してください。
これらの関数がどのように機能するかを確認するために、デモデータを見てみましょう。 トランザクションの平均収益、最高額と最低額の購入、合計収益、合計トランザクション、および一意のトランザクションの数を計算できます(購入が重複していないかどうかを確認するため)。 これを行うには、Google BigQueryプロジェクトの名前、データセット、およびテーブルを指定するクエリを記述します。
#legacy SQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]#standard SQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`その結果、次のようになります。
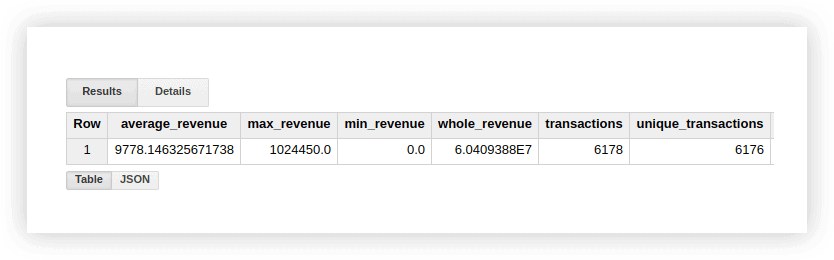
これらの計算結果は、標準のGoogleスプレッドシート関数(SUM、AVGなど)またはピボットテーブルを使用して、デモデータとともに元のテーブルで確認できます。
上のスクリーンショットからわかるように、トランザクションの数と一意のトランザクションは異なります。 これは、同じtransactionIdを持つ2つのトランザクションがテーブルにあることを示しています。

一意のトランザクションに関心がある場合は、一意の文字列をカウントする関数を使用してください。 または、GROUP BY関数を使用してデータをグループ化し、集計関数を適用する前に重複を取り除くことができます。
SQLクエリの練習用のデモデータ
ダウンロード日付関数
これらの関数を使用すると、日付を処理できます。形式を変更したり、必要なフィールド(日、月、または年)を選択したり、日付を特定の間隔でシフトしたりできます。
これらは次の場合に役立ちます。
- さまざまなソースからの日付と時刻を単一の形式に変換して、高度な分析を設定します
- 自動的に更新されるレポートを作成するか、メーリングをトリガーします(たとえば、過去2時間、週、または月のデータが必要な場合)
- 数日、数週間、または数か月のデータを取得する必要があるコホートレポートを作成する
これらは、最も一般的に使用される日付関数です。
| レガシーSQL | 標準SQL | 機能の説明 |
|---|---|---|
| 現在の日付() | 現在の日付() | 現在の日付を%YYYY-%MM-%DDの形式で返します。 |
| DATE(タイムスタンプ) | DATE(タイムスタンプ) | 日付を%YYYY-%MM-%DD%H:%M:%C。から%YYYY-%MM-%DD形式に変換します。 |
| DATE_ADD(timestamp、interval、interval_units) | DATE_ADD(タイムスタンプ、間隔間隔interval_units) | タイムスタンプの日付を返し、指定された間隔間隔で増やします。interval_units。レガシーSQLでは、YEAR、MONTH、DAY、HOUR、MINUTE、およびSECONDの値をとることができ、標準SQLでは、YEAR、QUARTER、MONTH、週、および日。 |
| DATE_ADD(timestamp、-interval、interval_units) | DATE_SUB(タイムスタンプ、間隔間隔interval_units) | 指定された間隔でタイムスタンプの日付を減らして返します。 |
| DATEDIFF(timestamp1、timestamp2) | DATE_DIFF(timestamp1、timestamp2、date_part) | タイムスタンプ1とタイムスタンプ2の日付の差を返します。 レガシーSQLでは、日数で差を返し、標準SQLでは、指定されたdate_part値(日、週、月、四半期、年)に応じて差を返します。 |
| DAY(タイムスタンプ) | EXTRACT(DAY FROMタイムスタンプ) | タイムスタンプの日付から日を返します。 1から31までの値を取ります。 |
| MONTH(タイムスタンプ) | EXTRACT(MONTH FROMタイムスタンプ) | タイムスタンプの日付から月のシーケンス番号を返します。 1から12までの値を取ります。 |
| YEAR(タイムスタンプ) | EXTRACT(YEAR FROMタイムスタンプ) | タイムスタンプの日付から年を返します。 |
すべての日付関数のリストについては、レガシーSQLおよび標準SQLのドキュメントを参照してください。
これらの各関数がどのように機能するかを確認するために、デモデータを見てみましょう。 たとえば、現在の日付を取得し、元のテーブルの日付を%YYYY-%MM-%DDの形式に変換し、それを削除して、それに1日を追加します。 次に、現在の日付とソーステーブルの日付の差を計算し、現在の日付を別々の年、月、日のフィールドに分割します。 これを行うには、以下のサンプルクエリをコピーして、プロジェクト名、データセット、およびデータテーブルを独自のものに置き換えることができます。
#legacy SQL
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]#standard SQL
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)クエリを実行すると、次のレポートが表示されます。
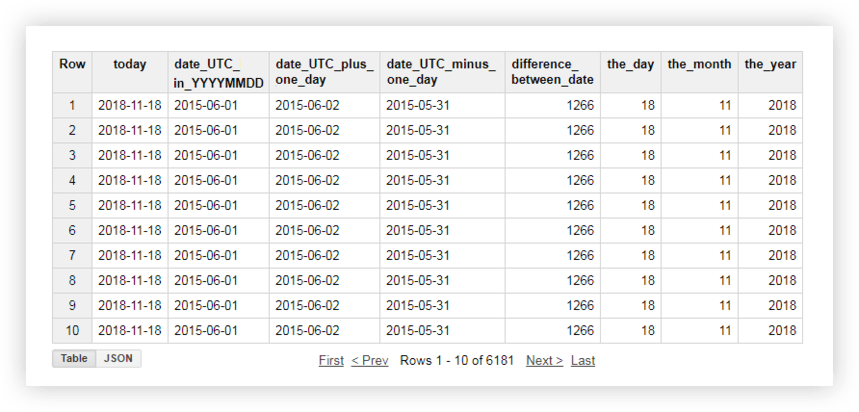
関連項目:Google BigQueryのデータに対するSQLクエリを使用して作成できるレポートの例と、OWOXBIを使用してGoogleAnalyticsデータを補足できる独自の指標。
文字列関数
文字列関数を使用すると、文字列を生成し、サブ文字列を選択して置換し、文字列の長さと元の文字列のサブ文字列のインデックスシーケンスを計算できます。 たとえば、文字列関数を使用すると、次のことができます。
- ページURLに渡されるUTMタグでレポートをフィルタリングする
- ソース名とキャンペーン名が異なるレジスタに書き込まれている場合は、データを単一の形式にします
- レポート内の誤ったデータを置き換える(たとえば、キャンペーン名が誤って印刷されている場合)
これらは、文字列を操作するための最も一般的な関数です。
| レガシーSQL | 標準SQL | 機能の説明 |
|---|---|---|
| CONCAT('str1'、'str2')または'str1' +'str2' | CONCAT('str1'、'str2') | 'str1'と'str2'を1つの文字列に連結します。 |
| 'str1' CONTAINS'str2' | REGEXP_CONTAINS('str1'、'str2')または'str1' LIKE'%str2%' | 文字列'str1'に文字列'str2が含まれている場合はtrueを返します。'標準SQLでは、文字列'str2'はre2ライブラリを使用して正規表現として記述できます。 |
| LENGTH('str') | CHAR_LENGTH('str')またはCHARACTER_LENGTH('str') | 文字列'str'(文字数)の長さを返します。 |
| SUBSTR('str'、index [、max_len]) | SUBSTR('str'、index [、max_len]) | 文字列'str'のインデックス文字で始まる長さmax_lenの部分文字列を返します。 |
| LOWER('str') | LOWER('str') | 文字列'str内のすべての文字を小文字に変換します。 |
| UPPER(str) | UPPER(str) | 文字列'str'のすべての文字を大文字に変換します。 |
| INSTR('str1'、'str2') | STRPOS('str1'、'str2') | 文字列'str2'の最初の出現のインデックスを文字列'str1'に返します。 それ以外の場合は、0を返します。 |
| REPLACE('str1'、'str2'、'str3') | REPLACE('str1'、'str2'、'str3') | 'str1'を'str2'から'str3'に置き換えます。 |
すべての文字列関数の詳細については、レガシーSQLおよび標準SQLのドキュメントを参照してください。
説明されている関数の使用方法を確認するために、デモデータを見てみましょう。 日、月、年の値を含む3つの個別の列があるとします。

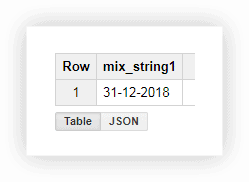
この形式で日付を操作するのはあまり便利ではないため、値を1つの列にまとめることができます。 これを行うには、以下のSQLクエリを使用し、Google BigQueryでプロジェクト、データセット、テーブルの名前を置き換えることを忘れないでください。
#legacy SQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1#standard SQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1クエリを実行すると、1つの列に日付が表示されます。
多くの場合、ウェブサイトのページをダウンロードすると、URLにはユーザーが選択した変数の値が記録されます。 これは、支払いまたは配送方法、トランザクション番号、購入者が商品を受け取りたい実店舗のインデックスなどです。SQLクエリを使用して、ページアドレスからこれらのパラメータを選択できます。 これを行う方法と理由の2つの例を考えてみましょう。
例1 。 ユーザーが実店舗から商品を受け取る購入数を知りたいとします。 これを行うには、部分文字列shop_id(実店舗のインデックス)を含むURLのページから送信されたトランザクションの数を計算する必要があります。 これは、次のクエリで実行できます。
#legacy SQL
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check#standard SQL
SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2
SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2結果のテーブルから、shop_idを含むページから5502トランザクション(チェック= true)が送信されたことがわかります。

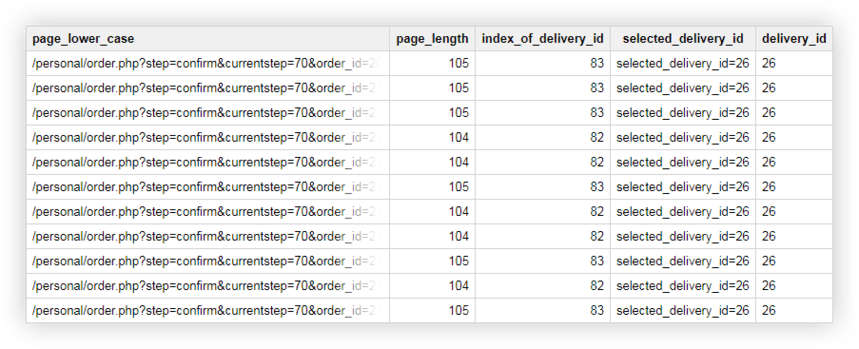
例2 。 各配信方法にdelivery_idを割り当て、ページURLでこのパラメーターの値を指定します。 ユーザーが選択した配信方法を確認するには、別の列でdelivery_idを選択する必要があります。

これには、次のクエリを使用できます。
#legacy SQL
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC#standard SQL
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASCその結果、GoogleBigQueryで次のようなテーブルが得られます。
SQLクエリの練習用のデモデータ
ダウンロードウィンドウ関数
これらの関数は、上記で説明した集計関数に似ています。 主な違いは、ウィンドウ関数は、クエリを使用して選択されたデータセット全体ではなく、そのデータの一部(サブセットまたはウィンドウ)でのみ計算を実行することです。
ウィンドウ関数を使用すると、JOIN関数を使用して複数のクエリを結合しなくても、グループセクションにデータを集約できます。 たとえば、広告キャンペーンごとの平均収益やデバイスごとのトランザクション数を計算できます。 レポートに別のフィールドを追加することで、たとえば、ブラックフライデーの広告キャンペーンからの収益のシェアやモバイルアプリケーションからのトランザクションのシェアを簡単に見つけることができます。
クエリ内の各関数とともに、ウィンドウの境界を定義するOVER式を詳しく説明する必要があります。 OVERには、操作できる3つのコンポーネントが含まれています。
- PARTITION BY —元のデータをclientIdやDayTimeなどのサブセットに分割するための特性を定義します
- ORDER BY —時間DESCなどのサブセット内の行の順序を定義します
- WINDOW FRAME —特定の機能のサブセット内の行を処理できます(たとえば、現在の行の前の5行のみ)。
この表では、最も頻繁に使用されるウィンドウ関数をまとめました。
| レガシーSQL | 標準SQL | 機能の説明 |
|---|---|---|
| AVG(フィールド) COUNT(フィールド) COUNT(DISTINCTフィールド) MAX() MIN() 和() | AVG([DISTINCT](フィールド)) COUNT(フィールド) COUNT([DISTINCT](フィールド)) MAX(フィールド) MIN(フィールド) SUM(フィールド) | 選択したサブセット内のフィールド列から平均、数、最大、最小、および合計の値を返します。DISTINCTは、一意の(繰り返されない)値のみを計算するために使用されます。 |
| DENSE_RANK() | DENSE_RANK() | サブセット内の行番号を返します。 |
| FIRST_VALUE(フィールド) | FIRST_VALUE(field [{RESPECT | IGNORE} NULLS]) | サブセット内のフィールド列から最初の行の値を返します。 デフォルトでは、フィールド列の値が空の行が計算に含まれます。 RESPECTまたはIGNORENULLSは、NULL文字列を含めるか無視するかを指定します。 |
| LAST_VALUE(フィールド) | LAST_VALUE(フィールド[{RESPECT | IGNORE} NULLS]) | フィールド列からサブセット内の最後の行の値を返します。デフォルトでは、フィールド列に空の値がある行が計算に含まれます。 RESPECTまたはIGNORENULLSは、NULL文字列を含めるか無視するかを指定します。 |
| LAG(フィールド) | LAG(field [、offset [、default_expression]]) | サブセット内の現在のフィールド列に関する前の行の値を返します。Offsetは、現在の行からオフセットする行数を指定する整数です。Default_expressionは、必要がない場合に関数が返す値です。サブセット内の文字列。 |
| LEAD(フィールド) | LEAD(field [、offset [、default_expression]]) | サブセット内の現在のフィールド列を基準にした次の行の値を返します。 オフセットは、現在の行に対して上に移動する行数を定義する整数です。Default_expressionは、現在のサブセット内に必要な文字列がない場合に関数が返す値です。 |
レガシーSQLおよび標準SQLのドキュメントで、すべての集計分析関数とナビゲーション関数のリストを確認できます。
例1 。 勤務時間中と非勤務時間中の顧客の活動を分析したいとします。 これを行うには、トランザクションを2つのグループに分割し、対象のメトリックを計算する必要があります。
- グループ1—9:00から18:00までの勤務時間中に購入
- グループ2—00:00から9:00および18:00から23:59までの営業時間外の購入
稼働時間と非稼働時間に加えて、ウィンドウを形成するための別の変数はclientIdです。 つまり、ユーザーごとに2つのウィンドウがあります。
| 窓 | クライアントID | 昼間 |
|---|---|---|
| ウィンドウ1 | clientId 1 | 労働時間 |
| ウィンドウ2 | clientId 2 | 非労働時間 |
| ウィンドウ3 | clientId 3 | 労働時間 |
| ウィンドウ4 | clientId 4 | 非労働時間 |
| ウィンドウN | clientId N | 労働時間 |
| ウィンドウN+1 | clientId N + 1 | 非労働時間 |
デモデータを使用して、平均、最大、最小、および合計の収益、トランザクションの合計数、および就業時間と非就業時間中のユーザーごとの一意のトランザクションの数を計算してみましょう。 以下のリクエストは、これを行うのに役立ちます。
#legacy SQL
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC#standard SQL
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESCclientId 102041117.1428132012のユーザーの例を使用して、結果として何が起こるかを見てみましょう。 このユーザーの元のテーブルには、次のデータがあります。

クエリを実行すると、このユーザーからの平均、最小、最大、合計の収益と、ユーザーのトランザクションの総数を含むレポートを受け取ります。 下のスクリーンショットでわかるように、両方のトランザクションは勤務時間中にユーザーによって行われました。

例2 。 次に、より複雑なタスクについて説明します。
- 実行時間に応じて、すべてのトランザクションのシーケンス番号をウィンドウに表示します。 ユーザーと稼働中/非稼働中のタイムスロットによってウィンドウを定義することを思い出してください。
- ウィンドウ内の次/前のトランザクション(現在と比較して)の収益を報告します。
- ウィンドウに最初と最後のトランザクションの収益を表示します。
これを行うには、次のクエリを使用します。
#legacy SQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour#standard SQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hourすでに知っているユーザーの例を使用して、計算結果を確認できます。clientId 102041117.1428132012:

上のスクリーンショットから、次のことがわかります。
- 最初のトランザクションは15:00で、2番目のトランザクションは16:00でした。
- 15:00のトランザクションの後、16:00に25066の収益のトランザクションがありました(列lead_revenue)
- 16:00のトランザクションの前に、15:00に3699の収益のトランザクションがありました(列lag_revenue)
- ウィンドウ内の最初のトランザクションは15:00で、このトランザクションの収益は3699(列first_revenue_by_hour)でした。
- クエリはデータを1行ずつ処理するため、問題のトランザクションの場合、ウィンドウの最後のトランザクションはそれ自体になり、last_revenue_by_hour列とrevenueの値は同じになります。
Google BigQueryに関する役立つ記事:
- トップ6のBigQuery視覚化ツール
- GoogleBigQueryにデータをアップロードする方法
- Google広告からGoogleBigQueryに生データをアップロードする方法
- GoogleBigQueryGoogleスプレッドシートコネクタ
- GoogleBigQueryのデータを使用してGoogleスプレッドシートのレポートを自動化する
- GoogleBigQueryのデータに基づいてGoogleDataStudioでレポートを自動化する
Google BigQueryのウェブサイトからサンプリングされていないデータを収集したいが、どこから始めればよいかわからない場合は、デモを予約してください。 BigQueryとOWOXBIで得られるすべての可能性について説明します。
我々の顧客
育つ 22%高速
マーケティングで最も効果的なものを測定することで、より速く成長します
マーケティング効率を分析し、成長分野を見つけ、ROIを向上させます
デモを入手結論
この記事では、最も一般的な関数のグループ(集計、日付、文字列、ウィンドウ)について説明しました。 ただし、Google BigQueryには、次のような多くの便利な関数があります。
- データを特定の形式に変換できるキャスト関数
- データセット内の複数のテーブルにアクセスできるようにするテーブルワイルドカード関数
- 正確な値ではなく、検索クエリのモデルを記述できる正規表現関数
これらの関数については、ブログで間違いなく書きます。 それまでの間、デモデータを使用して、この記事で説明されているすべての機能を試すことができます。
SQLクエリの練習用のデモデータ
ダウンロード