
Przegląd głównych funkcji Google BigQuery — przećwicz pisanie próśb o analizę marketingową
Opublikowany: 2022-04-12Im więcej informacji gromadzi firma, tym ostrzejsze jest pytanie, gdzie je przechowywać. Jeśli nie masz możliwości lub chęci utrzymania własnych serwerów, Google BigQuery (GBQ) może Ci pomóc. BigQuery zapewnia szybką, ekonomiczną i skalowalną pamięć masową do pracy z dużymi zbiorami danych i umożliwia pisanie zapytań przy użyciu składni zbliżonej do SQL oraz standardowych i zdefiniowanych przez użytkownika funkcji.
W tym artykule przyjrzymy się głównym funkcjom BigQuery i pokażemy ich możliwości na konkretnych przykładach. Dowiesz się, jak pisać podstawowe zapytania i testować je na danych demonstracyjnych.
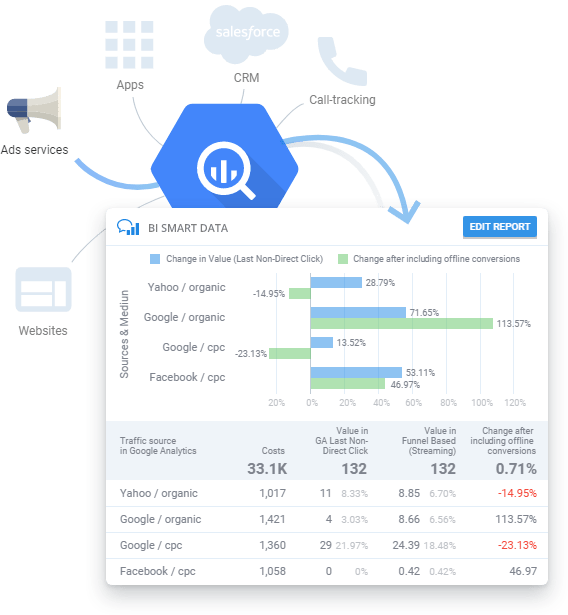
Twórz raporty na podstawie danych GBQ bez szkolenia technicznego lub znajomości języka SQL.
Potrzebujesz regularnie raportów z kampanii reklamowych, ale nie masz czasu na studiowanie SQL lub czekanie na odpowiedź analityków? Dzięki OWOX BI możesz tworzyć raporty bez konieczności rozumienia struktury danych. Po prostu wybierz parametry i dane, które chcesz zobaczyć w raporcie Smart Data. OWOX BI Smart Data natychmiast zwizualizuje Twoje dane w zrozumiały dla Ciebie sposób.
Spis treści
- Co to jest SQL i jakie dialekty obsługuje BigQuery
- Gdzie zacząć
- Funkcje Google BigQuery
- Funkcje agregujące
- Funkcje daty
- Funkcje ciągów
- Funkcje okien
- Wnioski
Co to jest SQL i jakie dialekty obsługuje BigQuery
Strukturalny język zapytań (SQL) umożliwia pobieranie danych, dodawanie i modyfikowanie danych w dużych tablicach. Google BigQuery obsługuje dwa dialekty SQL: Standardowy SQL i przestarzały Legacy SQL.
Wybór dialektu zależy od Twoich preferencji, ale Google zaleca korzystanie ze standardowego SQL w celu uzyskania następujących korzyści:
- Elastyczność i funkcjonalność dla pól zagnieżdżonych i powtarzalnych
- Obsługa języków DML i DDL, umożliwiająca zmianę danych w tabelach oraz zarządzanie tabelami i widokami w GBQ
- Szybsze przetwarzanie dużych ilości danych w porównaniu do Legacy SQL
- Obsługa wszystkich przyszłych aktualizacji BigQuery
Więcej informacji o różnicach w dialekcie znajdziesz w dokumentacji BigQuery.
Zobacz też: Jakie są zalety nowego dialektu Standard SQL w Google BigQuery w porównaniu ze starszą wersją SQL i jakie zadania biznesowe można za jego pomocą rozwiązać?
Domyślnie zapytania Google BigQuery są uruchamiane w starszej wersji SQL.
Możesz przełączyć się na Standardowy SQL na kilka sposobów:
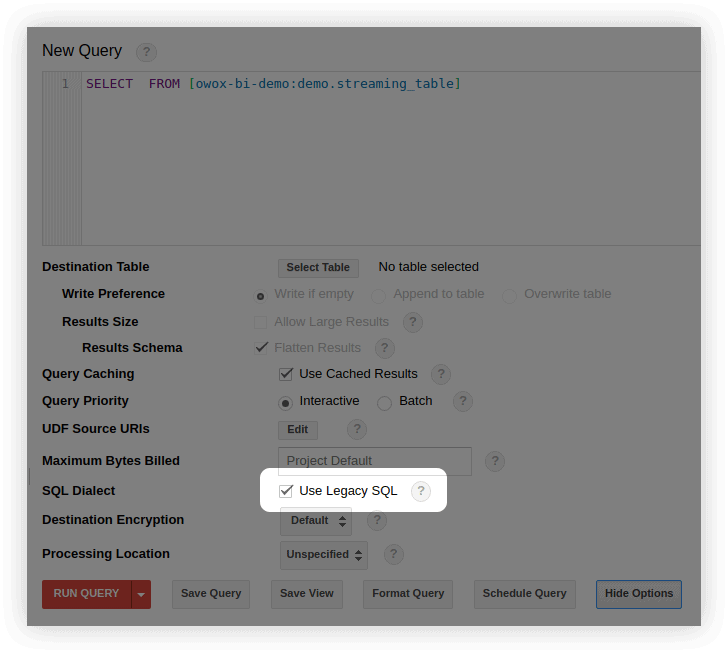
- W interfejsie BigQuery w oknie edycji zapytania wybierz Pokaż opcje i usuń zaznaczenie obok Użyj starszego SQL :
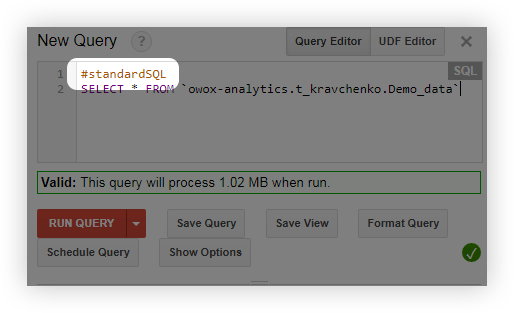
- Przed zapytaniem dodaj wiersz #standardSQL i rozpocznij zapytanie od nowego wiersza:
Gdzie zacząć
Abyś mógł ćwiczyć i uruchamiać z nami zapytania, przygotowaliśmy tabelę z danymi demonstracyjnymi. Wypełnij poniższy formularz, a wyślemy Ci go e-mailem.


Dane demonstracyjne do ćwiczenia zapytań SQL
Pobierz Aby rozpocząć, pobierz demonstracyjną tabelę danych i prześlij ją do swojego projektu Google BigQuery. Najłatwiej to zrobić za pomocą dodatku OWOX BI BigQuery Reports.
- Otwórz Arkusze Google i zainstaluj dodatek OWOX BI BigQuery Reports.
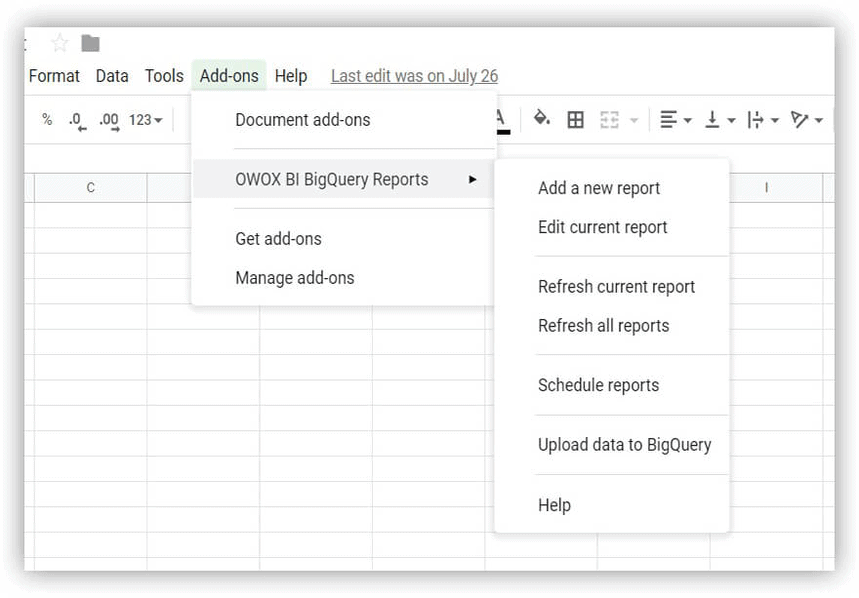
- Otwórz pobraną tabelę zawierającą dane demonstracyjne i wybierz Raporty OWOX BI BigQuery –> Prześlij dane do BigQuery :
- W oknie, które się otworzy, wybierz swój projekt Google BigQuery, zbiór danych i wymyśl nazwę tabeli, w której będą przechowywane załadowane dane.
- Określ format załadowanych danych (jak pokazano na zrzucie ekranu):

Jeśli nie masz projektu w Google BigQuery, utwórz go. Aby to zrobić, potrzebujesz aktywnego konta rozliczeniowego w Google Cloud Platform. Nie daj się przestraszyć, że musisz połączyć kartę bankową: bez Twojej wiedzy nie zostaniesz obciążony żadnymi opłatami. Ponadto po zarejestrowaniu otrzymasz 300 USD na 12 miesięcy, które możesz przeznaczyć na przechowywanie i przetwarzanie danych.
OWOX BI pomaga łączyć dane z różnych systemów w BigQuery: dane o działaniach użytkowników na Twojej stronie, połączeniach, zamówieniach z Twojego CRM, e-mailach, kosztach reklamy. Możesz używać OWOX BI do dostosowywania zaawansowanych analiz i automatyzacji raportów o dowolnej złożoności.
Zanim zaczniemy mówić o funkcjach Google BigQuery, pamiętajmy, jak wyglądają podstawowe zapytania zarówno w dialekcie Legacy SQL, jak i Standard SQL:
| Zapytanie | Starsze wersje SQL | Standardowy SQL |
|---|---|---|
| Wybierz pola z tabeli | WYBIERZ pole1,pole2 | WYBIERZ pole1,pole2 |
| Wybierz tabelę, z której chcesz wybrać pola | FROM [identyfikator projektu:zestaw danych.nazwa tabeli] | OD `IDProjektu.ZestawDanych.NazwaTabeli` |
| Wybierz parametr, według którego chcesz filtrować wartości | WHERE pole1=wartość | WHERE pole1=wartość |
| Wybierz pola, według których chcesz pogrupować wyniki | GROUP BY pole1, pole2 | GROUP BY pole1, pole2 |
| Wybierz sposób zamawiania wyników | ORDER BY pole 1 ASC (rosnąco) lub DESC (malejąco) | ORDER BY pole 1 ASC (rosnąco) lub DESC (malejąco) |
Funkcje Google BigQuery
Podczas tworzenia zapytań najczęściej będziesz używać funkcji agregacji , daty, ciągu i okna. Przyjrzyjmy się bliżej każdej z tych grup funkcji.
Zobacz też: Jak rozpocząć pracę z przechowywaniem w chmurze — utwórz zbiór danych i tabele oraz skonfiguruj import danych do Google BigQuery.
Funkcje agregujące
Funkcje agregujące dostarczają wartości podsumowania dla całej tabeli. Na przykład możesz ich użyć do obliczenia średniego rozmiaru czeku lub całkowitego przychodu na miesiąc albo do wybrania segmentu użytkowników, którzy dokonali maksymalnej liczby zakupów.
Oto najpopularniejsze funkcje agregujące:
| Starsze wersje SQL | Standardowy SQL | Co robi funkcja |
|---|---|---|
| ŚREDNIA(pole) | ŚREDNIA([ROZDZIELNE] (pole)) | Zwraca średnią wartość kolumny pola. W standardowym SQL po dodaniu warunku DISTINCT średnia jest brana pod uwagę tylko dla wierszy z unikalnymi (niepowtarzającymi się) wartościami w kolumnie pola. |
| MAX(pole) | MAX(pole) | Zwraca maksymalną wartość z kolumny pola. |
| MIN(pole) | MIN(pole) | Zwraca minimalną wartość z kolumny pola. |
| SUMA(pole) | SUMA(pole) | Zwraca sumę wartości z kolumny pola. |
| LICZBA(pole) | LICZBA(pole) | Zwraca liczbę wierszy w kolumnie pola. |
| EXACT_COUNT_DISTINCT(pole) | LICZBA([ODRÓŻNE] (pole)) | Zwraca liczbę unikalnych wierszy w kolumnie pola. |
Listę wszystkich funkcji agregujących można znaleźć w dokumentacji Legacy SQL i Standard SQL.
Spójrzmy na dane demonstracyjne, aby zobaczyć, jak działają te funkcje. Możemy obliczyć średni przychód z transakcji, zakupy dla najwyższej i najniższej kwoty, łączny przychód, łączną liczbę transakcji oraz liczbę unikalnych transakcji (aby sprawdzić, czy zakupy się duplikowały). W tym celu napiszemy zapytanie, w którym podajemy nazwę naszego projektu Google BigQuery, zbiór danych i tabelę.
#starszy SQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, EXACT_COUNT_DISTINCT(transactionId) as unique_transactions FROM [owox-analytics:t_kravchenko.Demo_data]#standardowy SQL
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`
SELECT AVG(revenue) as average_revenue, MAX(revenue) as max_revenue, MIN(revenue) as min_revenue, SUM(revenue) as whole_revenue, COUNT(transactionId) as transactions, COUNT(DISTINCT(transactionId)) as unique_transactions FROM `owox-analytics.t_kravchenko.Demo_data`W rezultacie otrzymamy:
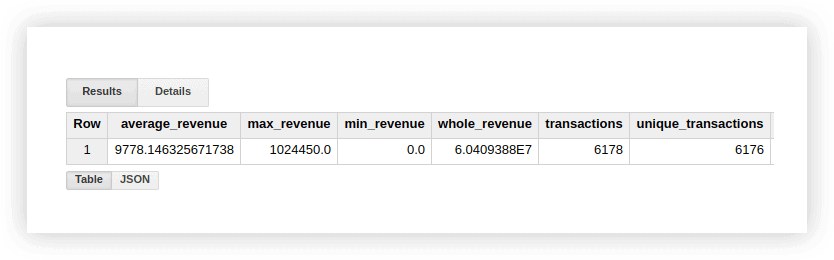
Możesz sprawdzić wyniki tych obliczeń w oryginalnej tabeli z danymi demonstracyjnymi, korzystając ze standardowych funkcji Arkuszy Google (SUM, AVG i inne) lub korzystając z tabel przestawnych.
Jak widać na powyższym zrzucie ekranu, liczba transakcji i unikalnych transakcji jest inna. Sugeruje to, że w naszej tabeli znajdują się dwie transakcje z tym samym identyfikatorem transakcji:

Jeśli interesują Cię unikalne transakcje, użyj funkcji, która zlicza unikalne ciągi. Alternatywnie możesz pogrupować dane za pomocą funkcji GROUP BY, aby pozbyć się duplikatów przed zastosowaniem funkcji agregującej.
Dane demonstracyjne do ćwiczenia zapytań SQL
PobierzFunkcje daty
Funkcje te pozwalają przetwarzać daty: zmienić ich format, wybrać potrzebne pole (dzień, miesiąc lub rok) lub przesunąć datę o określony interwał.
Mogą być przydatne, gdy:
- konwertowanie dat i godzin z różnych źródeł do jednego formatu w celu skonfigurowania zaawansowanej analityki
- tworzenie automatycznie aktualizowanych raportów lub wyzwalanie wysyłek (np. gdy potrzebujesz danych z ostatnich dwóch godzin, tygodnia lub miesiąca)
- tworzenie raportów kohortowych, w których konieczne jest pozyskanie danych za okres dni, tygodni lub miesięcy
Oto najczęściej używane funkcje daty:
| Starsze wersje SQL | Standardowy SQL | Opis funkcji |
|---|---|---|
| BIEŻĄCA DATA() | BIEŻĄCA DATA() | Zwraca bieżącą datę w formacie % RRRR -% MM-% DD. |
| DATA(sygnatura czasowa) | DATA(sygnatura czasowa) | Konwertuje datę z formatu % YYYY -% MM-% DD% H:% M:% C. na format % YYYY -% MM-% DD. |
| DATE_ADD(sygnatura czasowa, interwał, interwał_jednostki) | DATE_ADD(sygnatura czasowa, INTERVAL interwał_jednostki) | Zwraca datę znacznika czasu, zwiększając ją o określony interwał.interval_units.W Legacy SQL może przyjmować wartości ROK, MIESIĄC, DZIEŃ, GODZINA, MINUTA i SECOND, a w standardowym SQL może przyjmować wartości ROK, KWARTAŁ, MIESIĄC, TYDZIEŃ i DZIEŃ. |
| DATE_ADD(znacznik czasu, - interwał, jednostki_interwału) | DATE_SUB(sygnatura czasowa, INTERVAL interwał interwał_jednostki) | Zwraca datę znacznika czasu, zmniejszając ją o określony interwał. |
| DATEDIFF(sygnatura czasowa1, sygnatura czasowa2) | DATE_DIFF(sygnatura czasowa1, sygnatura czasowa2,część_daty) | Zwraca różnicę między datami timestamp1 i timestamp2. W Legacy SQL zwraca różnicę w dniach, aw standardowym SQL zwraca różnicę w zależności od określonej wartości date_part (dzień, tydzień, miesiąc, kwartał, rok). |
| DZIEŃ(sygnatura czasowa) | WYCIĄG (DZIEŃ OD sygnatury czasowej) | Zwraca dzień od daty sygnatury czasowej. Przyjmuje wartości od 1 do 31 włącznie. |
| MIESIĄC(sygnatura czasowa) | WYCIĄG(MIESIĄC OD sygnatury czasowej) | Zwraca numer sekwencyjny miesiąca od daty datownika. Przyjmuje wartości od 1 do 12 włącznie. |
| ROK(sygnatura czasowa) | WYCIĄG (ROK OD sygnatury czasowej) | Zwraca rok od daty sygnatury czasowej. |
Listę wszystkich funkcji daty można znaleźć w dokumentacji Legacy SQL i Standard SQL.
Rzućmy okiem na nasze dane demonstracyjne, aby zobaczyć, jak działa każda z tych funkcji. Na przykład uzyskamy aktualną datę, zmienimy datę z oryginalnej tabeli na format % RRRR -% MM-% DD, zabierzemy ją i dodamy do niej jeden dzień. Następnie obliczymy różnicę między datą bieżącą a datą z tabeli źródłowej i podzielimy datę bieżącą na oddzielne pola roku, miesiąca i dnia. Aby to zrobić, możesz skopiować poniższe przykładowe zapytania i zastąpić nazwę projektu, zestaw danych i tabelę danych własnymi.
#starszy SQL
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]
SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC,1, 'DAY') AS date_UTC_plus_one_day, DATE_ADD( date_UTC,-1, 'DAY') AS date_UTC_minus_one_day, DATEDIFF(CURRENT_DATE(), date_UTC ) AS difference_between_date, DAY( CURRENT_DATE() ) AS the_day, MONTH( CURRENT_DATE()) AS the_month, YEAR( CURRENT_DATE()) AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]#standardowy SQL
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)
SELECT today, date_UTC_in_YYYYMMDD, DATE_ADD( date_UTC_in_YYYYMMDD, INTERVAL 1 DAY) AS date_UTC_plus_one_day, DATE_SUB( date_UTC_in_YYYYMMDD,INTERVAL 1 DAY) AS date_UTC_minus_one_day, DATE_DIFF(today, date_UTC_in_YYYYMMDD, DAY) AS difference_between_date, EXTRACT(DAY FROM today ) AS the_day, EXTRACT(MONTH FROM today ) AS the_month, EXTRACT(YEAR FROM today ) AS the_year FROM ( SELECT CURRENT_DATE() AS today, DATE( date_UTC ) AS date_UTC_in_YYYYMMDD FROM `owox-analytics.t_kravchenko.Demo_data`)Po uruchomieniu zapytania otrzymasz ten raport:
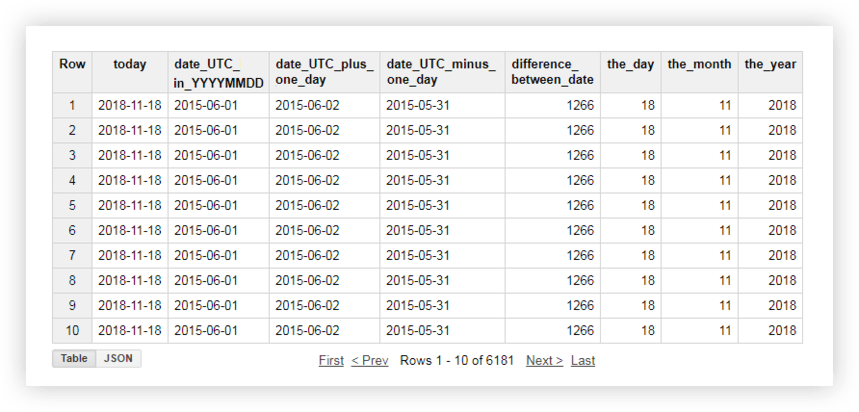
Zobacz też: Przykłady raportów, które można zbudować za pomocą zapytań SQL o dane w Google BigQuery oraz jakie unikalne metryki możesz uzupełnić danymi Google Analytics o OWOX BI.
Funkcje ciągów
Funkcje ciągów umożliwiają generowanie ciągu, wybieranie i zastępowanie podciągów oraz obliczanie długości ciągu i sekwencji indeksu podciągu w oryginalnym ciągu. Na przykład za pomocą funkcji ciągów możesz:
- filtruj raport za pomocą tagów UTM, które są przekazywane do adresu URL strony
- sprowadzić dane do jednego formatu, jeśli nazwy źródła i kampanii są zapisane w różnych rejestrach
- zastąpić nieprawidłowe dane w raporcie (na przykład, jeśli nazwa kampanii jest błędnie wydrukowana)
Oto najpopularniejsze funkcje do pracy z ciągami:
| Starsze wersje SQL | Standardowy SQL | Opis funkcji |
|---|---|---|
| CONCAT('str1', 'str2') lub 'str1'+ 'str2' | CONCAT('str1', 'str2') | Łączy „str1” i „str2” w jeden ciąg. |
| 'str1' ZAWIERA 'str2' | REGEXP_CONTAINS('str1', 'str2') lub 'str1' LIKE '%str2%' | Zwraca wartość true, jeśli łańcuch 'str1' zawiera łańcuch 'str2.'W standardowym SQL, łańcuch 'str2' można zapisać jako wyrażenie regularne przy użyciu biblioteki re2 . |
| DŁUGOŚĆ('str' ) | CHAR_LENGTH('str' ) lub CHARACTER_LENGTH('str' ) | Zwraca długość ciągu „str” (liczbę znaków). |
| SUBSTR('str', indeks [, max_len]) | SUBSTR('str', indeks [, max_len]) | Zwraca podciąg o długości max_len, zaczynając od znaku indeksu z ciągu „str”. |
| DOLNY('str') | DOLNY('str') | Konwertuje wszystkie znaki w ciągu 'str na małe litery. |
| GÓRNY(str) | GÓRNY(str) | Konwertuje wszystkie znaki w ciągu „str” na wielkie litery. |
| INSTR('str1', 'str2') | STRPOS('str1', 'str2') | Zwraca indeks pierwszego wystąpienia ciągu „str2” do ciągu „str1”; w przeciwnym razie zwraca 0. |
| ZAMIEŃ('str1', 'str2', 'str3') | ZAMIEŃ('str1', 'str2', 'str3') | Zamienia „str1” na „str2” na „str3”. |
Więcej informacji na temat wszystkich funkcji ciągów można znaleźć w dokumentacji Legacy SQL i Standard SQL.
Spójrzmy na dane demo, aby zobaczyć, jak korzystać z opisanych funkcji. Załóżmy, że mamy trzy oddzielne kolumny zawierające wartości dnia, miesiąca i roku:

Praca z datą w tym formacie nie jest zbyt wygodna, więc możemy połączyć wartości w jedną kolumnę. Aby to zrobić, użyj poniższych zapytań SQL i pamiętaj, aby zastąpić nazwę swojego projektu, zbioru danych i tabeli w Google BigQuery.
#starszy SQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY mix_string1#standardowy SQL
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1
SELECT CONCAT(the_day,'-',the_month,'-',the_year) AS mix_string1 FROM ( SELECT 31 AS the_day, 12 AS the_month, 2018 AS the_year FROM owox-analytics.t_kravchenko.Demo_data) GROUP BY mix_string1Po uruchomieniu zapytania otrzymujemy datę w jednej kolumnie:
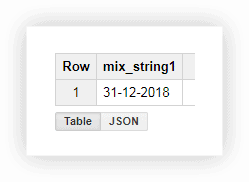
Często, gdy pobierasz stronę w witrynie, adres URL rejestruje wartości zmiennych wybranych przez użytkownika. Może to być forma płatności lub dostawy, numer transakcji, indeks fizycznego sklepu, w którym kupujący chce odebrać towar itp. Za pomocą zapytania SQL możesz wybrać te parametry z adresu strony. Rozważ dwa przykłady tego, jak i dlaczego możesz to zrobić.
Przykład 1 . Załóżmy, że chcemy poznać liczbę zakupów, w których użytkownicy odbierają towary w sklepach fizycznych. Aby to zrobić, musimy obliczyć liczbę transakcji wysłanych ze stron w adresie URL, które zawierają podłańcuch shop_id (indeks sklepu fizycznego). Możemy to zrobić za pomocą następujących zapytań:
#starszy SQL
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check
SELECT COUNT(transactionId) AS transactions, check FROM ( SELECT transactionId, page CONTAINS 'shop_id' AS check FROM [owox-analytics:t_kravchenko.Demo_data]) GROUP BY check#standardowy SQL

SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2
SELECT COUNT(transactionId) AS transactions, check1, check2 FROM ( SELECT transactionId, REGEXP_CONTAINS( page, 'shop_id') AS check1, page LIKE '%shop_id%' AS check2 FROM `owox-analytics.t_kravchenko.Demo_data`) GROUP BY check1, check2Z wynikowej tabeli widzimy, że 5502 transakcje (check = true) zostały wysłane ze stron zawierających shop_id:

Przykład 2 . Do każdej metody dostarczania przypisano identyfikator dostawy i określasz wartość tego parametru w adresie URL strony. Aby dowiedzieć się, jaką metodę dostawy wybrał użytkownik, należy w osobnej kolumnie wybrać identyfikator dostawy.
W tym celu możemy skorzystać z następujących zapytań:
#starszy SQL
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') as delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, LENGTH(page_lower_case) AS page_length, INSTR(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM [owox-analytics:t_kravchenko.Demo_data]))) ORDER BY page_lower_case ASC#standardowy SQL
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASC
SELECT page_lower_case, page_length, index_of_delivery_id, selected_delivery_id, REPLACE(selected_delivery_id, 'selected_delivery_id=', '') AS delivery_id FROM ( SELECT page_lower_case, page_length, index_of_delivery_id, SUBSTR(page_lower_case, index_of_delivery_id) AS selected_delivery_id FROM ( SELECT page_lower_case, CHAR_LENGTH(page_lower_case) AS page_length, STRPOS(page_lower_case, 'selected_delivery_id') AS index_of_delivery_id FROM ( SELECT LOWER( page) AS page_lower_case, UPPER( page) AS page_upper_case FROM `owox-analytics.t_kravchenko.Demo_data`))) ORDER BY page_lower_case ASCW rezultacie otrzymujemy w Google BigQuery taką tabelę:
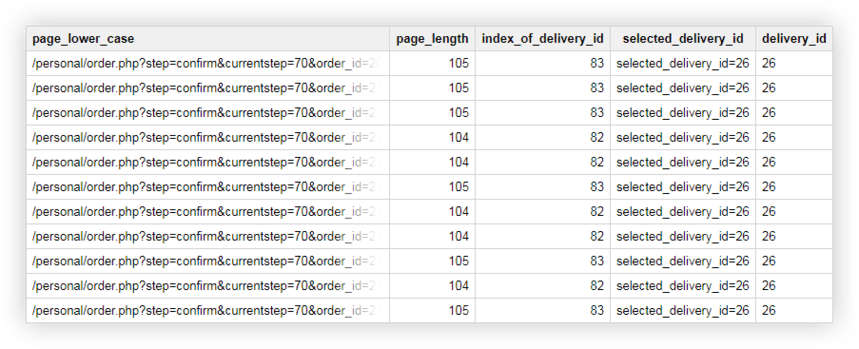
Dane demonstracyjne do ćwiczenia zapytań SQL
PobierzFunkcje okien
Funkcje te są podobne do funkcji agregujących, które omówiliśmy powyżej. Główna różnica polega na tym, że funkcje okna nie wykonują obliczeń na całym zbiorze danych wybranych za pomocą zapytania, ale tylko na części tych danych — podzbiorze lub oknie .
Korzystając z funkcji okna, można agregować dane w sekcji grupy bez użycia funkcji JOIN do łączenia wielu zapytań. Możesz na przykład obliczyć średni przychód na kampanię reklamową lub liczbę transakcji na urządzenie. Dodając kolejne pole do raportu w prosty sposób sprawdzisz np. udział przychodów z kampanii reklamowej w Czarny Piątek czy udział transakcji dokonanych z aplikacji mobilnej.
Wraz z każdą funkcją w zapytaniu należy przeliterować wyrażenie OVER, które definiuje granice okna. OVER zawiera trzy komponenty, z którymi możesz pracować:
- PARTITION BY — Określa charakterystykę, według której dzielisz oryginalne dane na podzbiory, takie jak clientId lub DayTime
- ORDER BY — Określa kolejność wierszy w podzbiorze, np. godzina DESC
- RAMKA OKNA — umożliwia przetwarzanie wierszy w podzbiorze określonej funkcji (na przykład tylko pięć wierszy przed bieżącym wierszem)
W tej tabeli zebraliśmy najczęściej używane funkcje okien:
| Starsze wersje SQL | Standardowy SQL | Opis funkcji |
|---|---|---|
| ŚREDNIA(pole) LICZBA(pole) LICZBA(pole DISTINCT) MAX() MIN() SUMA() | ŚREDNIA([ROZDZIELNE] (pole)) LICZBA(pole) LICZBA([ODRÓŻNE] (pole)) MAX(pole) MIN(pole) SUMA(pole) | Zwraca średnią, liczbę, maksymalną, minimalną i całkowitą wartość z kolumny pola w wybranym podzbiorze.DISTINCT służy do obliczania tylko unikalnych (niepowtarzalnych) wartości. |
| DENSE_RANK() | DENSE_RANK() | Zwraca numer wiersza w podzbiorze. |
| FIRST_VALUE(pole) | FIRST_VALUE (pole [{RESPECT | IGNORE} NULL]) | Zwraca wartość pierwszego wiersza z kolumny pola w podzbiorze. Domyślnie w obliczeniach uwzględniane są wiersze z pustymi wartościami z kolumny pola. RESPECT lub IGNORE NULLS określa, czy uwzględniać lub ignorować ciągi NULL. |
| LAST_VALUE(pole) | LAST_VALUE (pole [{RESPECT | IGNORE} NULL]) | Zwraca wartość ostatniego wiersza w podzbiorze z kolumny pola. Domyślnie w obliczeniach uwzględniane są wiersze z pustymi wartościami w kolumnie pola. RESPECT lub IGNORE NULLS określa, czy uwzględniać lub ignorować ciągi NULL. |
| LAG(pole) | LAG (pole [, przesunięcie [, wyrażenie_domyślne]]) | Zwraca wartość poprzedniego wiersza w odniesieniu do bieżącej kolumny pola w podzbiorze.Przesunięcie jest liczbą całkowitą, która określa liczbę wierszy do przesunięcia w dół od bieżącego wiersza.Default_expression to wartość, którą funkcja zwróci, jeśli nie jest to wymagane ciąg w podzbiorze. |
| OŁÓW(pole) | LEAD (pole [, przesunięcie [, wyrażenie_domyślne]]) | Zwraca wartość następnego wiersza względem bieżącej kolumny pola w podzbiorze. Przesunięcie to liczba całkowita, która definiuje liczbę wierszy, które chcesz przenieść w górę w odniesieniu do bieżącego wiersza.Default_expression to wartość, którą funkcja zwróci, jeśli w bieżącym podzbiorze nie ma wymaganego ciągu. |
Listę wszystkich funkcji analizy agregacji i funkcji nawigacyjnych można znaleźć w dokumentacji starszych wersji SQL i standardowej wersji SQL.
Przykład 1 . Powiedzmy, że chcemy analizować aktywność klientów w godzinach pracy i poza godzinami pracy. W tym celu musimy podzielić transakcje na dwie grupy i obliczyć interesujące nas metryki:
- Grupa 1 — zakupy w godzinach pracy od 9:00 do 18:00
- Grupa 2 — zakupy po godzinach od 00:00 do 9:00 i od 18:00 do 23:59
Oprócz godzin pracy i poza godzinami pracy, inną zmienną służącą do tworzenia okna jest clientId. Oznacza to, że dla każdego użytkownika będziemy mieć dwa okna:
| okno | Identyfikator klienta | Dzień |
|---|---|---|
| okno 1 | identyfikator klienta 1 | godziny pracy |
| okno 2 | identyfikator klienta 2 | godziny wolne od pracy |
| okno 3 | identyfikator klienta 3 | godziny pracy |
| okno 4 | identyfikator klienta 4 | godziny wolne od pracy |
| okno N | identyfikator klienta N | godziny pracy |
| okno N+1 | identyfikator klienta N+1 | godziny wolne od pracy |
Użyjmy danych demonstracyjnych, aby obliczyć średni, maksymalny, minimalny i całkowity przychód, całkowitą liczbę transakcji oraz liczbę unikalnych transakcji na użytkownika w godzinach pracy i poza godzinami pracy. Poniższe prośby pomogą nam to zrobić.
#starszy SQL
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC#standardowy SQL
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESC
#standardSQL SELECT date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions FROM ( SELECT date, clientId, DayTime, AVG(revenue) OVER (PARTITION BY date, clientId, DayTime) AS avg_revenue, MAX(revenue) OVER (PARTITION BY date, clientId, DayTime) AS max_revenue, MIN(revenue) OVER (PARTITION BY date, clientId, DayTime) AS min_revenue, SUM(revenue) OVER (PARTITION BY date, clientId, DayTime) AS sum_revenue, COUNT(transactionId) OVER (PARTITION BY date, clientId, DayTime) AS transactions, COUNT(DISTINCT(transactionId)) OVER (PARTITION BY date, clientId, DayTime) AS unique_transactions FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, avg_revenue, max_revenue, min_revenue, sum_revenue, transactions, unique_transactions ORDER BY transactions DESCZobaczmy, co się stanie w wyniku na przykładzie użytkownika o identyfikatorze klienta 102041117.1428132012. W oryginalnej tabeli dla tego użytkownika mamy następujące dane:

Po uruchomieniu zapytania otrzymujemy raport zawierający średni, minimalny, maksymalny i całkowity przychód tego użytkownika, a także całkowitą liczbę transakcji użytkownika. Jak widać na poniższym zrzucie ekranu, obie transakcje zostały wykonane przez użytkownika w godzinach pracy:

Przykład 2 . Teraz czas na bardziej skomplikowane zadanie:
- Umieść w oknie numery sekwencyjne dla wszystkich transakcji w zależności od czasu ich wykonania. Przypomnijmy, że definiujemy okno według użytkownika i roboczych/niedziałających okien czasowych.
- Zgłoś przychód z następnej/poprzedniej transakcji (w stosunku do bieżącej) w oknie.
- Wyświetl w oknie przychód z pierwszej i ostatniej transakcji.
W tym celu użyjemy następujących zapytań:
#starszy SQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM [owox-analytics:t_kravchenko.Demo_data])) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour#standardowy SQL
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour
SELECT date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour FROM ( SELECT date, clientId, DayTime, hour, DENSE_RANK() OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS rank, revenue, LEAD( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lead_revenue, LAG( revenue, 1) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS lag_revenue, FIRST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS first_revenue_by_hour, LAST_VALUE(revenue) OVER (PARTITION BY date, clientId, DayTime ORDER BY hour) AS last_revenue_by_hour FROM ( SELECT date, date_UTC, clientId, transactionId, revenue, page, hour, CASE WHEN hour>=9 AND hour<=18 THEN 'working hours' ELSE 'non-working hours' END AS DayTime FROM `owox-analytics.t_kravchenko.Demo_data`)) GROUP BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hour ORDER BY date, clientId, DayTime, hour, rank, revenue, lead_revenue, lag_revenue, first_revenue_by_hour, last_revenue_by_hourWyniki obliczeń możemy sprawdzić na przykładzie znanego nam użytkownika: clientId 102041117.1428132012:

Na powyższym zrzucie ekranu widzimy, że:
- pierwsza transakcja miała miejsce o godzinie 15:00, a druga transakcja o godzinie 16:00
- po transakcji o godzinie 15:00 nastąpiła transakcja o godzinie 16:00 z przychodem 25066 (kolumna lead_revenue)
- przed transakcją o godzinie 16:00 była transakcja o godzinie 15:00 z przychodem 3699 (kolumna lag_revenue)
- pierwsza transakcja w oknie miała miejsce o godzinie 15:00, a przychód z tej transakcji wyniósł 3699 (kolumna first_revenue_by_hour)
- zapytanie przetwarza dane linia po linii, więc dla danej transakcji ostatnia transakcja w oknie będzie sama, a wartości w kolumnach last_revenue_by_hour i tax będą takie same
Przydatne artykuły o Google BigQuery:
- 6 najlepszych narzędzi do wizualizacji BigQuery
- Jak przesłać dane do Google BigQuery
- Jak przesłać nieprzetworzone dane z Google Ads do Google BigQuery
- Oprogramowanie sprzęgające Google BigQuery Arkuszy Google
- Automatyzacja raportów w Arkuszach Google przy użyciu danych z Google BigQuery
- Automatyzacja raportów w Google Data Studio na podstawie danych z Google BigQuery
Jeśli chcesz zbierać niespróbkowane dane ze swojej witryny w Google BigQuery, ale nie wiesz, od czego zacząć, zarezerwuj demo. Opowiemy Ci o wszystkich możliwościach, jakie daje BigQuery i OWOX BI.
Nasi klienci
rosnąć 22% szybciej
Rozwijaj się szybciej, mierząc, co najlepiej sprawdza się w Twoim marketingu
Przeanalizuj swoją skuteczność marketingową, znajdź obszary wzrostu, zwiększ ROI
Pobierz demoWnioski
W tym artykule przyjrzeliśmy się najpopularniejszym grupom funkcji: agregat, data, ciąg i okno. Jednak Google BigQuery ma o wiele więcej przydatnych funkcji, w tym:
- funkcje rzutowania, które pozwalają konwertować dane do określonego formatu
- funkcje wieloznaczne tabel, które umożliwiają dostęp do wielu tabel w zbiorze danych
- funkcje wyrażeń regularnych, które pozwalają opisać model zapytania, a nie jego dokładną wartość
O tych funkcjach na pewno napiszemy na naszym blogu. W międzyczasie możesz wypróbować wszystkie funkcje opisane w tym artykule, korzystając z naszych danych demonstracyjnych.
Dane demonstracyjne do ćwiczenia zapytań SQL
Pobierz